 EmerNeRF:全面基于NeRF的自動駕駛仿真框架,無需分割
EmerNeRF:全面基于NeRF的自動駕駛仿真框架,無需分割
0. 筆者個人體會
在自動駕駛中,感知、表示和重建動態場景對于代理程序理解并與其環境進行交互至關重要。傳統的仿真框架大多強依賴于識別跟蹤等感知模塊的有監督學習,這樣在數據集層面上限制了模型表示各種復雜場景的能力。這幾年中NeRF(神經輻射場)的爆炸式發展也逐漸融入了自動駕駛行業,然而當前端到端的以NeRF為基礎自動駕駛方針框架并不多。
本文將介紹最近英偉達開源的框架EmerNeRF。不同于之前依然需要實例分割標簽的框架,EmerNeRF進一步擺脫了圖像以外訓練標簽的需求。這里也推薦工坊推出的新課程《深度剖析面向自動駕駛領域的車載傳感器空間同步(標定)》。
1. 效果展示
EmerNeRF 可以模擬車靜止、高速時的場景,在相機曝光不匹配、復雜的天氣干擾、以及復雜光照差異下都可以工作。
EmerNeRF剛剛開源,并提供了復雜場景數據集NOTR,有多種玩法。
2. 摘要
本文提出的EmerNeRF基于NeRF,可以自監督地同時捕獲野外場景的幾何形狀、外觀、運動和語義。EmerNeRF將場景分層為靜態場和動態場,在instant-NGP對三維空間進行Hash的基礎上,多尺度增強動態對象的渲染精度。通過結合靜態場、動態場和光流(場景流)場,EmerNeRF能夠在不依賴于有監督動態對象分割或光流估計的前提下表示高度動態的場景,并實現了最先進的性能。
3. 算法解析
EmerNeRF為得到四維的時空表示,將整體場景分解為一個表征背景的靜態場,一個構成動態前景的動態場,一個表征運動的光流場和一個天空預測的模塊構成。具體地,所有分解后的輻射場都以instant-NGP為backbone,也即使用可微的hash grids參數化每個神經輻射場。靜態場的輸入僅有位置,動態場與光流場的輸入則為位置與相應的時間。
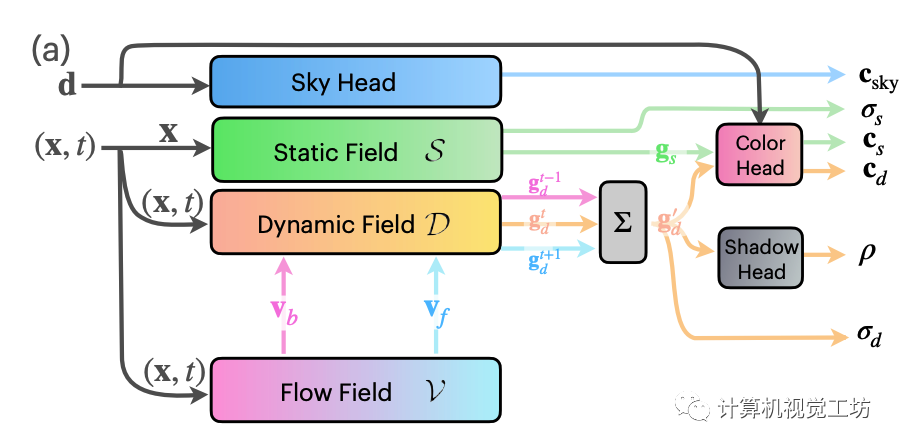
后半部分的多頭解碼器則全部由MLP完成,這里為了達到合成的目的,比instant-NGP多出了一個預測shadow ratio的頭。這個0到1之間的shadow ratio 用來控制動態前景體素與靜態背景體素間的合成比例。另外,基于靜態場的體素占比總體場景體素較大的假設,EmerNeRF在NeRF的基礎損失上額外加了一項動態體素密度的約束。這種設計不再需要預先做額外的實例分割,充分利用了NeRF本身的特性。
場景流估計
為了進一步解除密集的光流標簽監督,EmerNeRF使用了假設,多幀特征聚合只對temporally-consistent的特征有效。因此,額外的場景流分支不僅要學習動態物體間的關系,還要能夠有效聚合幀間關系,以便讓RGB信息能夠監督光流。具體地,還是采取hash grid + MLP的組合,這里的MLP輸出為6維,包含前向3維和反向3維的轉移預測。而特征聚合則是采用了當前時間戳與前后共三步的特征加權平均值。
解決一下使用ViT中位置編碼的問題
單純使用NeRF輸出顏色場和體素密度場,還達不到仿真的要求。為了能給有關語義場景理解任務鋪好路,EmerNeRF將2D視覺基礎模型(Vision Foundation Model)應用到4D的時空數據。然而在使用目前最先進的模型例如DINOv2時,Positional Embedding(PE)的feature pattern 不太正常:
無論 3D 視點如何變化,feature pattern卻在圖像中保持固定,從而破壞了3D 多視圖一致性。
EmerNeRF基于 ViT 提取特征的觀察 逐圖像進行映射,并且這些 PE pattern在不同圖像中顯示(幾乎)一致。這表明單個PE pattern可能足以表示此共享的現象。因此,這里假設PE pattern為一個加性噪聲模型,這樣從原始特征中減去就能獲得無PE特征。有了這個假設,我們構造可學習且全局共享的 2D 特征圖 U 來作為補償。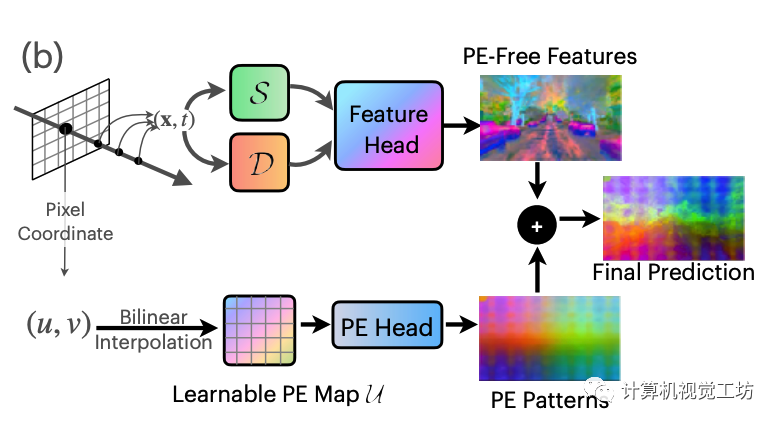
對于目標像素坐標(u, v),首先對無 PE 特征進行體積渲染,然后對U進行雙線性插值并使用單層MLP解碼得到PE pattern特征,然后將其添加到無PE特征中。
4. 實驗
在Waymo公開數據集的基礎上,本文提出新數據集NeRF On-The-Road (NOTR)。
NOTR包含120個獨特的駕駛序列,分為32個靜態場景、32個動態場景和56個包含七種挑戰條件的場景:靜態、高速、曝光不匹配、黃昏/黎明、陰天、多雨和夜間。
駕駛感知任務:動態物體的邊界框,地面真實的3D場景流動以及3D語義占用。我們希望這個數據集能夠促進NeRF在駕駛場景中的研究,將NeRF的應用從僅僅的視圖合成擴展到運動理解,例如3D流動,以及場景理解,比如語義。
場景分類NOTR 靜態場景遵循StreetSuRF中提出的劃分,其中包含沒有移動物體的干凈場景。動態場景,這些場景在駕駛記錄中經常出現,是根據光照條件選擇的,以區分它們與“多樣化”類別中的場景。Diverse-56樣本也可能包含動態物體,但它們主要基于自車狀態(例如,自車靜止、高速、相機曝光不匹配)、天氣條件(例如,雨天、昏暗)、以及光照差異(例如,夜晚、黃昏/黎明)進行劃分。
渲染實驗包含了靜態,動態的新視角合成評估
在場景分解上,EmerNeRF主要與D^2 NeRF 與HyperNeRF相比較,在靜態和動態的圖像合成任務上均領先。
隱式場景流任務
在場景流估計任務上, EmerNeRF主要與目前僅有的工作NSFP(Neural scene flow prior)相比較,并采用相同的評估指標:
3D端點誤差(EPE3D),計算為所有點預測值與實際地面真實值之間的平均L2距離;
Acc5,代表EPE3D小于5厘米或相對誤差在5%以下的點的比例;
Acc10,表示EPE3D小于10厘米或相對誤差在10%以下的點的比例;
θ,表示預測值與地面真實值之間的平均角度誤差。比較結果如下: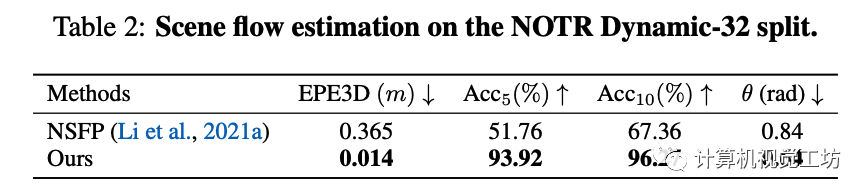
下游感知任務
為了調查ViT位置編碼模式對三維感知和特征合成的影響,這里的ablation study主要比較是否帶有本文提出的位置編碼分解模塊對于下游任務的影響。這里采用了few-shot的occupancy估計,這里使用的Occ3D數據集為不同尺寸occupancy 提供了語義標注。對于每個序列,妹隔10幀允許帶著標簽,這樣產生10%的有標簽數據。占用的坐標是輸入到預訓練的EmerNeRF模型以計算每個類的特征centroid。然后剩余 90% 的幀用于query,并根據其最近的特征質心進行分類。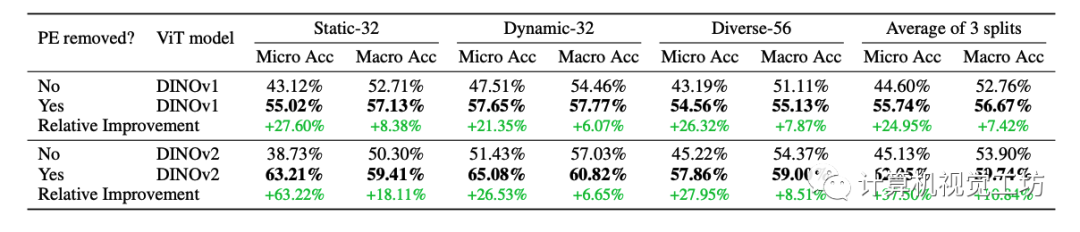
PE改進的ablation study
通過比較包含 PE 和無 PE 模型的特征 PSNR,能夠發現使用EmerNeRF中提出的PE分解方法時特征合成質量顯著提高,尤其對于 DINOv2。而DINOv1受 PE 模式的影響較小。這里也推薦工坊推出的新課程《深度剖析面向自動駕駛領域的車載傳感器空間同步(標定)》。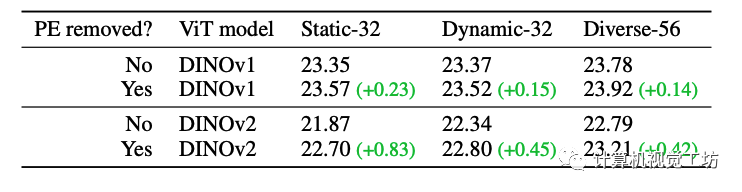
5. 總結
今天筆者為大家介紹了一種基于NeRF的簡單而強大的自動駕駛仿真框架 EmerNeRF。EmerNeRF 解決了基于 Transformer 的框架中特征時出現的問題性位置嵌入模式。由于使用NeRF的思路,EmerNeRF在靜態場景重建、新視角合成還是場景流估計方面都是以自監督的方式學習的,而無需依賴于地面真實對象標注或預先訓練的模型。同時,EmerNeRF 在傳感器模擬方面表現出色,可以處理文中提出的NOTR數據集中具有挑戰性的駕駛場景。
審核編輯:劉清
-
RGB
+關注
關注
4文章
798瀏覽量
58461 -
自動駕駛
+關注
關注
784文章
13784瀏覽量
166389 -
Hash算法
+關注
關注
0文章
43瀏覽量
7382 -
車載傳感器
+關注
關注
0文章
44瀏覽量
4353 -
MLP
+關注
關注
0文章
57瀏覽量
4241
原文標題:英偉達最新開源|EmerNeRF:全面基于NeRF的自動駕駛仿真框架,無需分割
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在自動駕駛領域有哪些應用?
FPGA在自動駕駛領域有哪些優勢?
【話題】特斯拉首起自動駕駛致命車禍,自動駕駛的冬天來了?
自動駕駛真的會來嗎?
自動駕駛的到來
AI/自動駕駛領域的巔峰會議—國際AI自動駕駛高峰論壇
如何讓自動駕駛更加安全?
自動駕駛汽車的處理能力怎么樣?
自動駕駛系統要完成哪些計算機視覺任務?
自動駕駛系統設計及應用的相關資料分享
自動駕駛技術的實現
美國自動駕駛政策框架發布,自動駕駛立法國際呼聲高漲
自動駕駛仿真工具

Autoware自動駕駛框架介紹
自動駕駛場景圖像分割(Unet)





 工商網監
工商網監
評論