") 線程和進(jìn)程的區(qū)別是什么?進(jìn)程狀態(tài)之間如何相互轉(zhuǎn)化?
線程和進(jìn)程的區(qū)別是什么?進(jìn)程狀態(tài)之間如何相互轉(zhuǎn)化?
大家好,我是小林。
針對(duì)校招同學(xué),我是推薦在秋招之前多積累實(shí)習(xí)經(jīng)歷,或者多做一些有含金量的項(xiàng)目,除了能增加簡歷競(jìng)爭(zhēng)之外,還有一個(gè)好處,就是能減少面試八股文題量。
因?yàn)槊嬖嚨臅r(shí)間基本都是固定的,一般互聯(lián)網(wǎng)公司是 40-60 分鐘,如果這個(gè)時(shí)間里,問了你很多實(shí)習(xí)經(jīng)歷和項(xiàng)目經(jīng)歷方面的問題,那么所剩的時(shí)間就不多了,這樣面試官索性就隨便問幾個(gè)八股文,來結(jié)束這次面試了,這種面試相當(dāng)于在你的主場(chǎng)進(jìn)行面試,準(zhǔn)備起來的壓力也不會(huì)太大。
相反,如果無實(shí)習(xí)經(jīng)歷, 項(xiàng)目也是比較爛大街了,面試官對(duì)簡歷上的內(nèi)容沒什么興趣的,那整場(chǎng)面試只能圍繞八股文來問了,這時(shí)候主場(chǎng)就是在面試官那,他問什么你回答什么,面試官容易問到你沒學(xué)過的內(nèi)容。
比如,這位同學(xué)字節(jié)面經(jīng),全程基本上就是八股文的拷打,范圍就是操作系統(tǒng)、網(wǎng)絡(luò)協(xié)議、mysql、redis、編程語言、算法、場(chǎng)景題。
操作系統(tǒng)
線程和進(jìn)程的區(qū)別?
老八股文,這個(gè)都不會(huì),說不過去了。從定義、地址空間、通信、安全性這幾個(gè)方面對(duì)比回答。
調(diào)度和資源:進(jìn)程是操作系統(tǒng)進(jìn)行資源分配和調(diào)度的基本單位,而線程是進(jìn)程的執(zhí)行單元,共享進(jìn)程的資源。
地址空間:每個(gè)進(jìn)程都有獨(dú)立的地址空間,而線程共享所屬進(jìn)程的地址空間,包括代碼段、數(shù)據(jù)段、堆。
通信:進(jìn)程間通信需要額外的機(jī)制,如管道、消息隊(duì)列、共享內(nèi)存等,而線程間通信可以直接共享全局變量等數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)。
安全性:多線程編程需要更小心地處理共享資源,避免出現(xiàn)競(jìng)態(tài)條件和死鎖等問題,而多進(jìn)程編程由于各進(jìn)程有獨(dú)立的地址空間,相對(duì)更容易實(shí)現(xiàn)并發(fā)安全性,一個(gè)進(jìn)程崩潰不會(huì)影響其他進(jìn)程而一個(gè)線程崩潰可能影響整個(gè)進(jìn)程。
進(jìn)程狀態(tài)之間的相互轉(zhuǎn)化?
一個(gè)完整的進(jìn)程狀態(tài)的變遷如下圖:
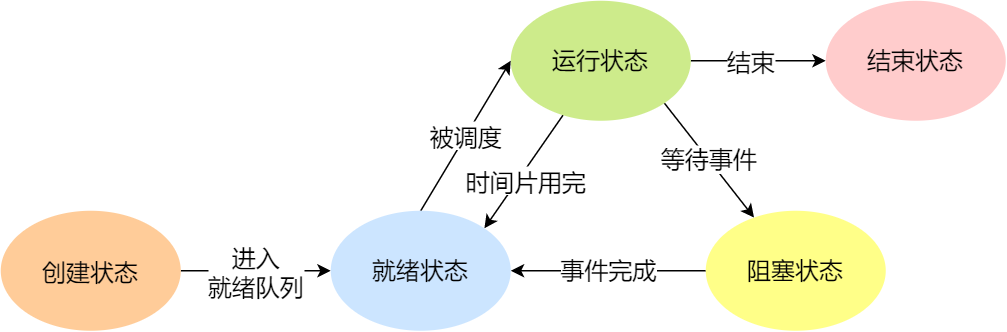 進(jìn)程五種狀態(tài)的變遷
進(jìn)程五種狀態(tài)的變遷
再來詳細(xì)說明一下進(jìn)程的狀態(tài)變遷:
NULL -> 創(chuàng)建狀態(tài):一個(gè)新進(jìn)程被創(chuàng)建時(shí)的第一個(gè)狀態(tài);
創(chuàng)建狀態(tài) -> 就緒狀態(tài):當(dāng)進(jìn)程被創(chuàng)建完成并初始化后,一切就緒準(zhǔn)備運(yùn)行時(shí),變?yōu)榫途w狀態(tài),這個(gè)過程是很快的;
就緒態(tài) -> 運(yùn)行狀態(tài):處于就緒狀態(tài)的進(jìn)程被操作系統(tǒng)的進(jìn)程調(diào)度器選中后,就分配給 CPU 正式運(yùn)行該進(jìn)程;
運(yùn)行狀態(tài) -> 結(jié)束狀態(tài):當(dāng)進(jìn)程已經(jīng)運(yùn)行完成或出錯(cuò)時(shí),會(huì)被操作系統(tǒng)作結(jié)束狀態(tài)處理;
運(yùn)行狀態(tài) -> 就緒狀態(tài):處于運(yùn)行狀態(tài)的進(jìn)程在運(yùn)行過程中,由于分配給它的運(yùn)行時(shí)間片用完,操作系統(tǒng)會(huì)把該進(jìn)程變?yōu)榫途w態(tài),接著從就緒態(tài)選中另外一個(gè)進(jìn)程運(yùn)行;
運(yùn)行狀態(tài) -> 阻塞狀態(tài):當(dāng)進(jìn)程請(qǐng)求某個(gè)事件且必須等待時(shí),例如請(qǐng)求 I/O 事件;
阻塞狀態(tài) -> 就緒狀態(tài):當(dāng)進(jìn)程要等待的事件完成時(shí),它從阻塞狀態(tài)變到就緒狀態(tài);
你了解過哪些io模型?
阻塞I/O模型:應(yīng)用程序發(fā)起I/O操作后會(huì)被阻塞,直到操作完成才返回結(jié)果。適用于對(duì)實(shí)時(shí)性要求不高的場(chǎng)景。
非阻塞I/O模型:應(yīng)用程序發(fā)起I/O操作后立即返回,不會(huì)被阻塞,但需要不斷輪詢或者使用select/poll/epoll等系統(tǒng)調(diào)用來檢查I/O操作是否完成。適合于需要進(jìn)行多路復(fù)用的場(chǎng)景,例如需要同時(shí)處理多個(gè)socket連接的服務(wù)器程序。
I/O復(fù)用模型:通過select、poll、epoll等系統(tǒng)調(diào)用,應(yīng)用程序可以同時(shí)等待多個(gè)I/O操作,當(dāng)其中任何一個(gè)I/O操作準(zhǔn)備就緒時(shí),應(yīng)用程序會(huì)被通知。適合于需要同時(shí)處理多個(gè)I/O操作的場(chǎng)景,比如高并發(fā)的服務(wù)端程序。
信號(hào)驅(qū)動(dòng)I/O模型:應(yīng)用程序發(fā)起I/O操作后,可以繼續(xù)做其他事情,當(dāng)I/O操作完成時(shí),操作系統(tǒng)會(huì)向應(yīng)用程序發(fā)送信號(hào)來通知其完成。適合于需要異步I/O通知的場(chǎng)景,可以提高系統(tǒng)的并發(fā)能力。
異步I/O模型:應(yīng)用程序發(fā)起I/O操作后可以立即做其他事情,當(dāng)I/O操作完成時(shí),應(yīng)用程序會(huì)得到通知。異步I/O模型由操作系統(tǒng)內(nèi)核完成I/O操作,應(yīng)用程序只需等待通知即可。適合于需要大量并發(fā)連接和高性能的場(chǎng)景,能夠減少系統(tǒng)調(diào)用次數(shù),提高系統(tǒng)效率。
有了解過io多路復(fù)用嗎?
select 實(shí)現(xiàn)多路復(fù)用的方式是,將已連接的 Socket 都放到一個(gè)文件描述符集合,然后調(diào)用 select 函數(shù)將文件描述符集合拷貝到內(nèi)核里,讓內(nèi)核來檢查是否有網(wǎng)絡(luò)事件產(chǎn)生,檢查的方式很粗暴,就是通過遍歷文件描述符集合的方式,當(dāng)檢查到有事件產(chǎn)生后,將此 Socket 標(biāo)記為可讀或可寫, 接著再把整個(gè)文件描述符集合拷貝回用戶態(tài)里,然后用戶態(tài)還需要再通過遍歷的方法找到可讀或可寫的 Socket,然后再對(duì)其處理。
所以,對(duì)于 select 這種方式,需要進(jìn)行 2 次「遍歷」文件描述符集合,一次是在內(nèi)核態(tài)里,一個(gè)次是在用戶態(tài)里 ,而且還會(huì)發(fā)生 2 次「拷貝」文件描述符集合,先從用戶空間傳入內(nèi)核空間,由內(nèi)核修改后,再傳出到用戶空間中。
select 使用固定長度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的個(gè)數(shù)是有限制的,在 Linux 系統(tǒng)中,由內(nèi)核中的 FD_SETSIZE 限制, 默認(rèn)最大值為 1024,只能監(jiān)聽 0~1023 的文件描述符。
poll 不再用 BitsMap 來存儲(chǔ)所關(guān)注的文件描述符,取而代之用動(dòng)態(tài)數(shù)組,以鏈表形式來組織,突破了 select 的文件描述符個(gè)數(shù)限制,當(dāng)然還會(huì)受到系統(tǒng)文件描述符限制。
但是 poll 和 select 并沒有太大的本質(zhì)區(qū)別,都是使用「線性結(jié)構(gòu)」存儲(chǔ)進(jìn)程關(guān)注的 Socket 集合,因此都需要遍歷文件描述符集合來找到可讀或可寫的 Socket,時(shí)間復(fù)雜度為 O(n),而且也需要在用戶態(tài)與內(nèi)核態(tài)之間拷貝文件描述符集合,這種方式隨著并發(fā)數(shù)上來,性能的損耗會(huì)呈指數(shù)級(jí)增長。
poll 通過兩個(gè)方面,很好解決了 select/poll 的問題。
第一點(diǎn),epoll 在內(nèi)核里使用紅黑樹來跟蹤進(jìn)程所有待檢測(cè)的文件描述字,把需要監(jiān)控的 socket 通過 epoll_ctl() 函數(shù)加入內(nèi)核中的紅黑樹里,紅黑樹是個(gè)高效的數(shù)據(jù)結(jié)構(gòu),增刪改一般時(shí)間復(fù)雜度是 O(logn)。而 select/poll 內(nèi)核里沒有類似 epoll 紅黑樹這種保存所有待檢測(cè)的 socket 的數(shù)據(jù)結(jié)構(gòu),所以 select/poll 每次操作時(shí)都傳入整個(gè) socket 集合給內(nèi)核,而 epoll 因?yàn)樵趦?nèi)核維護(hù)了紅黑樹,可以保存所有待檢測(cè)的 socket ,所以只需要傳入一個(gè)待檢測(cè)的 socket,減少了內(nèi)核和用戶空間大量的數(shù)據(jù)拷貝和內(nèi)存分配。
第二點(diǎn), epoll 使用事件驅(qū)動(dòng)的機(jī)制,內(nèi)核里維護(hù)了一個(gè)鏈表來記錄就緒事件,當(dāng)某個(gè) socket 有事件發(fā)生時(shí),通過回調(diào)函數(shù)內(nèi)核會(huì)將其加入到這個(gè)就緒事件列表中,當(dāng)用戶調(diào)用 epoll_wait() 函數(shù)時(shí),只會(huì)返回有事件發(fā)生的文件描述符的個(gè)數(shù),不需要像 select/poll 那樣輪詢掃描整個(gè) socket 集合,大大提高了檢測(cè)的效率。
從下圖你可以看到 epoll 相關(guān)的接口作用:
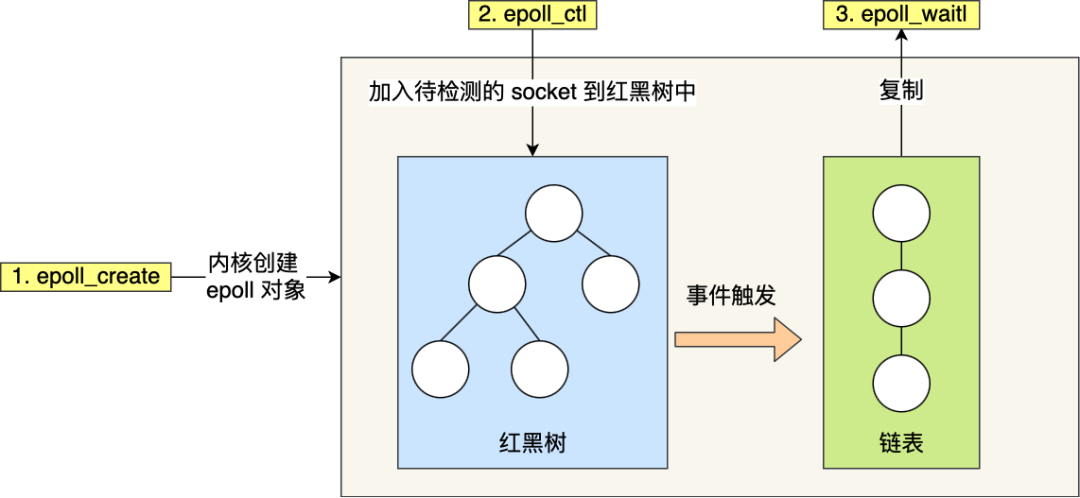
epoll 的方式即使監(jiān)聽的 Socket 數(shù)量越多的時(shí)候,效率不會(huì)大幅度降低,能夠同時(shí)監(jiān)聽的 Socket 的數(shù)目也非常的多了,上限就為系統(tǒng)定義的進(jìn)程打開的最大文件描述符個(gè)數(shù)。因而,epoll 被稱為解決 C10K 問題的利器。
管道有幾種方式?
管道在Linux中有兩種方式:匿名管道和命名管道。
匿名管道:是一種在父子進(jìn)程或者兄弟進(jìn)程之間進(jìn)行通信的機(jī)制,只能用于具有親緣關(guān)系的進(jìn)程間通信,通常通過pipe系統(tǒng)調(diào)用創(chuàng)建。
命名管道:是一種允許無關(guān)的進(jìn)程間進(jìn)行通信的機(jī)制,基于文件系統(tǒng),可以在不相關(guān)的進(jìn)程之間進(jìn)行通信。
網(wǎng)絡(luò)
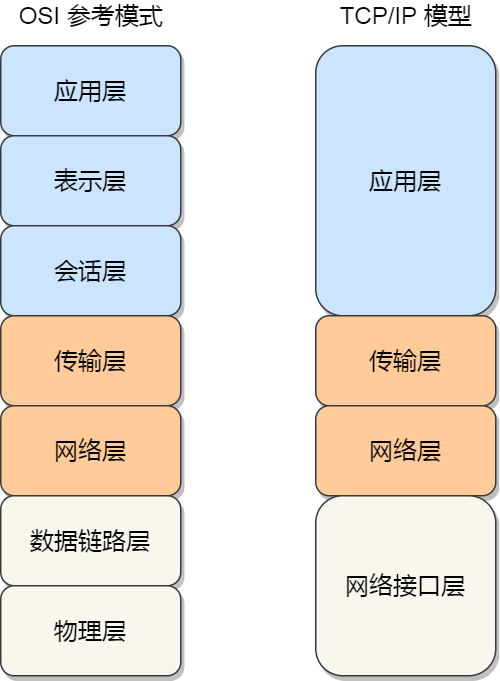
網(wǎng)絡(luò)模型每一層作用是什么?
 img
img
OSI 網(wǎng)絡(luò)模型,該模型主要有 7 層,分別是應(yīng)用層、表示層、會(huì)話層、傳輸層、網(wǎng)絡(luò)層、數(shù)據(jù)鏈路層以及物理層。
應(yīng)用層,負(fù)責(zé)給應(yīng)用程序提供統(tǒng)一的接口;
表示層,負(fù)責(zé)把數(shù)據(jù)轉(zhuǎn)換成兼容另一個(gè)系統(tǒng)能識(shí)別的格式;
會(huì)話層,負(fù)責(zé)建立、管理和終止表示層實(shí)體之間的通信會(huì)話;
傳輸層,負(fù)責(zé)端到端的數(shù)據(jù)傳輸;
網(wǎng)絡(luò)層,負(fù)責(zé)數(shù)據(jù)的路由、轉(zhuǎn)發(fā)、分片;
數(shù)據(jù)鏈路層,負(fù)責(zé)數(shù)據(jù)的封幀和差錯(cuò)檢測(cè),以及 MAC 尋址;
物理層,負(fù)責(zé)在物理網(wǎng)絡(luò)中傳輸數(shù)據(jù)幀;
TCP/IP 網(wǎng)絡(luò)模型共有 4 層,分別是應(yīng)用層、傳輸層、網(wǎng)絡(luò)層和網(wǎng)絡(luò)接口層,每一層負(fù)責(zé)的職能如下:
應(yīng)用層,負(fù)責(zé)向用戶提供一組應(yīng)用程序,比如 HTTP、DNS、FTP 等;
傳輸層,負(fù)責(zé)端到端的通信,比如 TCP、UDP 等;
網(wǎng)絡(luò)層,負(fù)責(zé)網(wǎng)絡(luò)包的封裝、分片、路由、轉(zhuǎn)發(fā),比如 IP、ICMP 等;
網(wǎng)絡(luò)接口層,負(fù)責(zé)網(wǎng)絡(luò)包在物理網(wǎng)絡(luò)中的傳輸,比如網(wǎng)絡(luò)包的封幀、 MAC 尋址、差錯(cuò)檢測(cè),以及通過網(wǎng)卡傳輸網(wǎng)絡(luò)幀等;
tcp 和 udp區(qū)別?
連接:TCP 是面向連接的傳輸層協(xié)議,傳輸數(shù)據(jù)前先要建立連接;UDP 是不需要連接,即刻傳輸數(shù)據(jù)。
服務(wù)對(duì)象:TCP 是一對(duì)一的兩點(diǎn)服務(wù),即一條連接只有兩個(gè)端點(diǎn)。UDP 支持一對(duì)一、一對(duì)多、多對(duì)多的交互通信
可靠性:TCP 是可靠交付數(shù)據(jù)的,數(shù)據(jù)可以無差錯(cuò)、不丟失、不重復(fù)、按序到達(dá)。UDP 是盡最大努力交付,不保證可靠交付數(shù)據(jù)。但是我們可以基于 UDP 傳輸協(xié)議實(shí)現(xiàn)一個(gè)可靠的傳輸協(xié)議,比如 QUIC 協(xié)議
擁塞控制、流量控制:TCP 有擁塞控制和流量控制機(jī)制,保證數(shù)據(jù)傳輸?shù)陌踩浴DP 則沒有,即使網(wǎng)絡(luò)非常擁堵了,也不會(huì)影響 UDP 的發(fā)送速率。
首部開銷:TCP 首部長度較長,會(huì)有一定的開銷,首部在沒有使用「選項(xiàng)」字段時(shí)是 20 個(gè)字節(jié),如果使用了「選項(xiàng)」字段則會(huì)變長的。UDP 首部只有 8 個(gè)字節(jié),并且是固定不變的,開銷較小。
傳輸方式:TCP 是流式傳輸,沒有邊界,但保證順序和可靠。UDP 是一個(gè)包一個(gè)包的發(fā)送,是有邊界的,但可能會(huì)丟包和亂序。
應(yīng)用場(chǎng)景:TCP 是面向連接,能保證數(shù)據(jù)的可靠性交付,因此經(jīng)常用于:FTP、HTTP/HTTPS協(xié)議。UDP 面向無連接,它可以隨時(shí)發(fā)送數(shù)據(jù),再加上 UDP 本身的處理既簡單又高效,經(jīng)常用于視頻、音頻等多媒體通信等。
怎么用udp實(shí)現(xiàn)http?
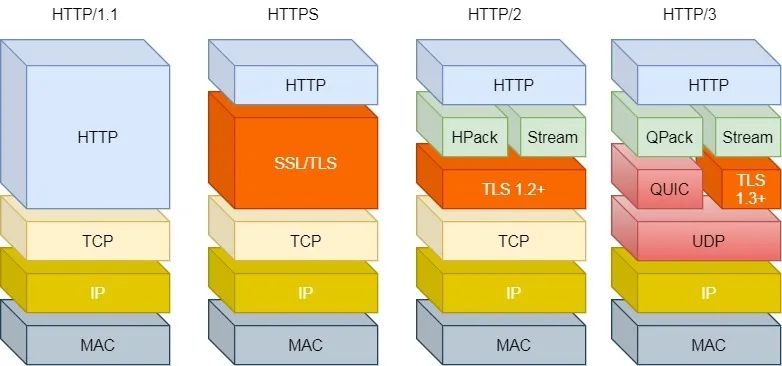 HTTP/1 ~ HTTP/3
HTTP/1 ~ HTTP/3
UDP 是不可靠傳輸?shù)模?UDP 的 QUIC 協(xié)議 可以實(shí)現(xiàn)類似 TCP 的可靠性傳輸,在http3 就用了 quic 協(xié)議。
連接遷移:QUIC支持在網(wǎng)絡(luò)變化時(shí)快速遷移連接,例如從WiFi切換到移動(dòng)數(shù)據(jù)網(wǎng)絡(luò),以保持連接的可靠性。
重傳機(jī)制:QUIC使用重傳機(jī)制來確保丟失的數(shù)據(jù)包能夠被重新發(fā)送,從而提高數(shù)據(jù)傳輸?shù)目煽啃浴?/p>
前向糾錯(cuò):QUIC可以使用前向糾錯(cuò)技術(shù),在接收端修復(fù)部分丟失的數(shù)據(jù),降低重傳的需求,提高可靠性和傳輸效率。
擁塞控制:QUIC內(nèi)置了擁塞控制機(jī)制,可以根據(jù)網(wǎng)絡(luò)狀況動(dòng)態(tài)調(diào)整數(shù)據(jù)傳輸速率,以避免網(wǎng)絡(luò)擁塞和丟包,提高可靠性。
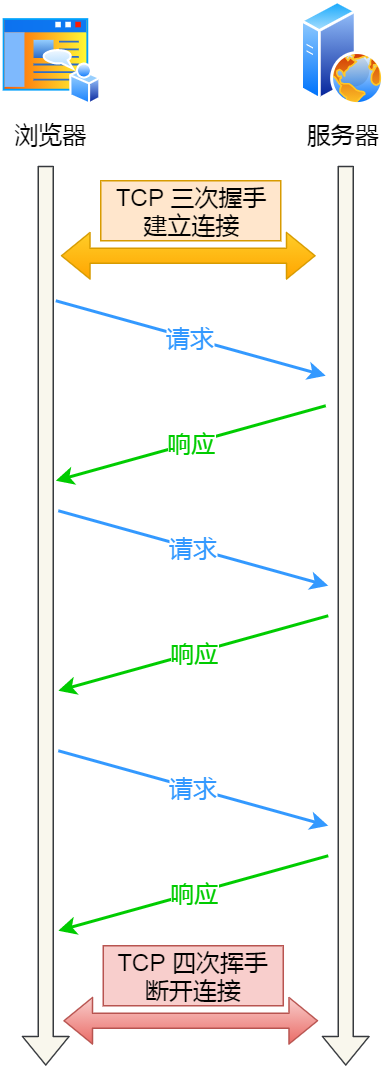
http長連接是什么?
使用同一個(gè) TCP 連接來發(fā)送和接收多個(gè) HTTP 請(qǐng)求/應(yīng)答,避免了連接建立和釋放的開銷,這個(gè)方法稱為 HTTP 長連接。
 HTTP 長連接
HTTP 長連接
HTTP 長連接的特點(diǎn)是,只要任意一端沒有明確提出斷開連接,則保持 TCP 連接狀態(tài)。
MySQL數(shù)據(jù)庫
mysql為什么選擇b+樹?
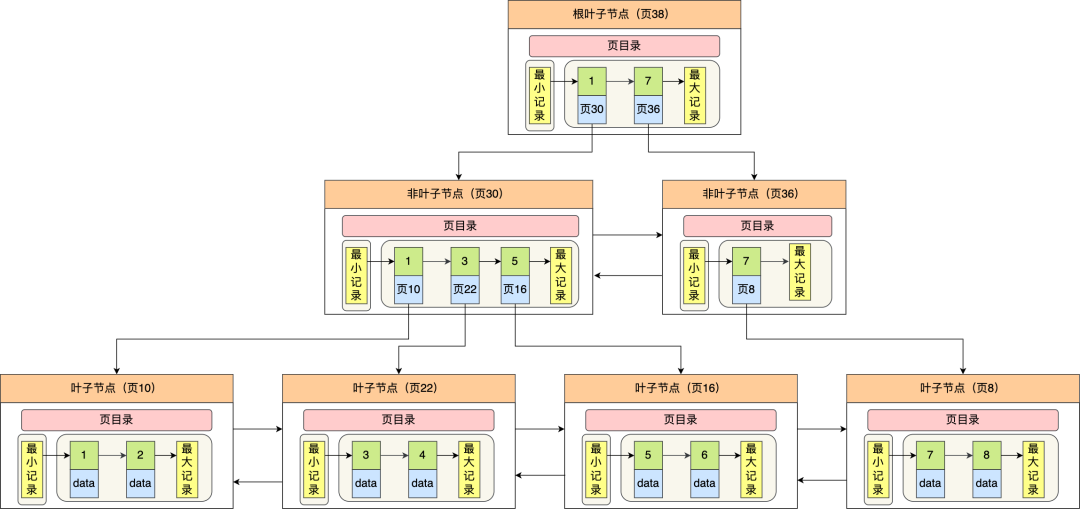
MySQL 是會(huì)將數(shù)據(jù)持久化在硬盤,而存儲(chǔ)功能是由 MySQL 存儲(chǔ)引擎實(shí)現(xiàn)的,所以討論 MySQL 使用哪種數(shù)據(jù)結(jié)構(gòu)作為索引,實(shí)際上是在討論存儲(chǔ)引使用哪種數(shù)據(jù)結(jié)構(gòu)作為索引,InnoDB 是 MySQL 默認(rèn)的存儲(chǔ)引擎,它就是采用了 B+ 樹作為索引的數(shù)據(jù)結(jié)構(gòu)。
要設(shè)計(jì)一個(gè) MySQL 的索引數(shù)據(jù)結(jié)構(gòu),不僅僅考慮數(shù)據(jù)結(jié)構(gòu)增刪改的時(shí)間復(fù)雜度,更重要的是要考慮磁盤 I/0 的操作次數(shù)。因?yàn)樗饕陀涗浂际谴娣旁谟脖P,硬盤是一個(gè)非常慢的存儲(chǔ)設(shè)備,我們?cè)诓樵償?shù)據(jù)的時(shí)候,最好能在盡可能少的磁盤 I/0 的操作次數(shù)內(nèi)完成。
二分查找樹雖然是一個(gè)天然的二分結(jié)構(gòu),能很好的利用二分查找快速定位數(shù)據(jù),但是它存在一種極端的情況,每當(dāng)插入的元素都是樹內(nèi)最大的元素,就會(huì)導(dǎo)致二分查找樹退化成一個(gè)鏈表,此時(shí)查詢復(fù)雜度就會(huì)從 O(logn)降低為 O(n)。
為了解決二分查找樹退化成鏈表的問題,就出現(xiàn)了自平衡二叉樹,保證了查詢操作的時(shí)間復(fù)雜度就會(huì)一直維持在 O(logn) 。但是它本質(zhì)上還是一個(gè)二叉樹,每個(gè)節(jié)點(diǎn)只能有 2 個(gè)子節(jié)點(diǎn),隨著元素的增多,樹的高度會(huì)越來越高。
而樹的高度決定于磁盤 I/O 操作的次數(shù),因?yàn)闃涫谴鎯?chǔ)在磁盤中的,訪問每個(gè)節(jié)點(diǎn),都對(duì)應(yīng)一次磁盤 I/O 操作,也就是說樹的高度就等于每次查詢數(shù)據(jù)時(shí)磁盤 IO 操作的次數(shù),所以樹的高度越高,就會(huì)影響查詢性能。
B 樹和 B+ 都是通過多叉樹的方式,會(huì)將樹的高度變矮,所以這兩個(gè)數(shù)據(jù)結(jié)構(gòu)非常適合檢索存于磁盤中的數(shù)據(jù)。
但是 MySQL 默認(rèn)的存儲(chǔ)引擎 InnoDB 采用的是 B+ 作為索引的數(shù)據(jù)結(jié)構(gòu)。原因有:
B+ 樹的非葉子節(jié)點(diǎn)不存放實(shí)際的記錄數(shù)據(jù),僅存放索引,因此數(shù)據(jù)量相同的情況下,相比存儲(chǔ)即存索引又存記錄的 B 樹,B+樹的非葉子節(jié)點(diǎn)可以存放更多的索引,因此 B+ 樹可以比 B 樹更「矮胖」,查詢底層節(jié)點(diǎn)的磁盤 I/O次數(shù)會(huì)更少。
B+ 樹有大量的冗余節(jié)點(diǎn)(所有非葉子節(jié)點(diǎn)都是冗余索引),這些冗余索引讓 B+ 樹在插入、刪除的效率都更高,比如刪除根節(jié)點(diǎn)的時(shí)候,不會(huì)像 B 樹那樣會(huì)發(fā)生復(fù)雜的樹的變化;
B+ 樹葉子節(jié)點(diǎn)之間用鏈表連接了起來,有利于范圍查詢,而 B 樹要實(shí)現(xiàn)范圍查詢,因此只能通過樹的遍歷來完成范圍查詢,這會(huì)涉及多個(gè)節(jié)點(diǎn)的磁盤 I/O 操作,范圍查詢效率不如 B+ 樹。
mysql acid 特性
原子性(Atomicity):一個(gè)事務(wù)中的所有操作,要么全部完成,要么全部不完成,不會(huì)結(jié)束在中間某個(gè)環(huán)節(jié),而且事務(wù)在執(zhí)行過程中發(fā)生錯(cuò)誤,會(huì)被回滾到事務(wù)開始前的狀態(tài),就像這個(gè)事務(wù)從來沒有執(zhí)行過一樣,就好比買一件商品,購買成功時(shí),則給商家付了錢,商品到手;購買失敗時(shí),則商品在商家手中,消費(fèi)者的錢也沒花出去。
一致性(Consistency):是指事務(wù)操作前和操作后,數(shù)據(jù)滿足完整性約束,數(shù)據(jù)庫保持一致性狀態(tài)。比如,用戶 A 和用戶 B 在銀行分別有 800 元和 600 元,總共 1400 元,用戶 A 給用戶 B 轉(zhuǎn)賬 200 元,分為兩個(gè)步驟,從 A 的賬戶扣除 200 元和對(duì) B 的賬戶增加 200 元。一致性就是要求上述步驟操作后,最后的結(jié)果是用戶 A 還有 600 元,用戶 B 有 800 元,總共 1400 元,而不會(huì)出現(xiàn)用戶 A 扣除了 200 元,但用戶 B 未增加的情況(該情況,用戶 A 和 B 均為 600 元,總共 1200 元)。
隔離性(Isolation):數(shù)據(jù)庫允許多個(gè)并發(fā)事務(wù)同時(shí)對(duì)其數(shù)據(jù)進(jìn)行讀寫和修改的能力,隔離性可以防止多個(gè)事務(wù)并發(fā)執(zhí)行時(shí)由于交叉執(zhí)行而導(dǎo)致數(shù)據(jù)的不一致,因?yàn)槎鄠€(gè)事務(wù)同時(shí)使用相同的數(shù)據(jù)時(shí),不會(huì)相互干擾,每個(gè)事務(wù)都有一個(gè)完整的數(shù)據(jù)空間,對(duì)其他并發(fā)事務(wù)是隔離的。也就是說,消費(fèi)者購買商品這個(gè)事務(wù),是不影響其他消費(fèi)者購買的。
持久性(Durability):事務(wù)處理結(jié)束后,對(duì)數(shù)據(jù)的修改就是永久的,即便系統(tǒng)故障也不會(huì)丟失。
InnoDB 引擎通過什么技術(shù)來保證事務(wù)的這四個(gè)特性的呢?
持久性是通過 redo log (重做日志)來保證的;
原子性是通過 undo log(回滾日志) 來保證的;
隔離性是通過 MVCC(多版本并發(fā)控制) 或鎖機(jī)制來保證的;
一致性則是通過持久性+原子性+隔離性來保證;
mysql事務(wù)的隔離級(jí)別有哪些
四個(gè)隔離級(jí)別如下:
讀未提交),指一個(gè)事務(wù)還沒提交時(shí),它做的變更就能被其他事務(wù)看到;
讀提交,指一個(gè)事務(wù)提交之后,它做的變更才能被其他事務(wù)看到;
可重復(fù)讀,指一個(gè)事務(wù)執(zhí)行過程中看到的數(shù)據(jù),一直跟這個(gè)事務(wù)啟動(dòng)時(shí)看到的數(shù)據(jù)是一致的,MySQL InnoDB 引擎的默認(rèn)隔離級(jí)別;
串行化;會(huì)對(duì)記錄加上讀寫鎖,在多個(gè)事務(wù)對(duì)這條記錄進(jìn)行讀寫操作時(shí),如果發(fā)生了讀寫沖突的時(shí)候,后訪問的事務(wù)必須等前一個(gè)事務(wù)執(zhí)行完成,才能繼續(xù)執(zhí)行;
按隔離水平高低排序如下:
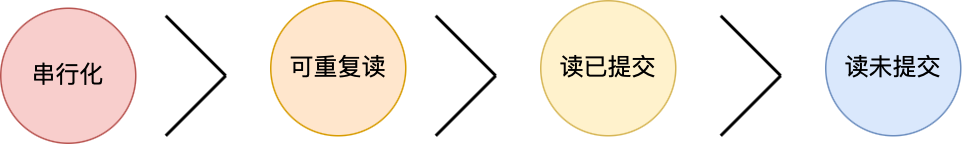 圖片
圖片
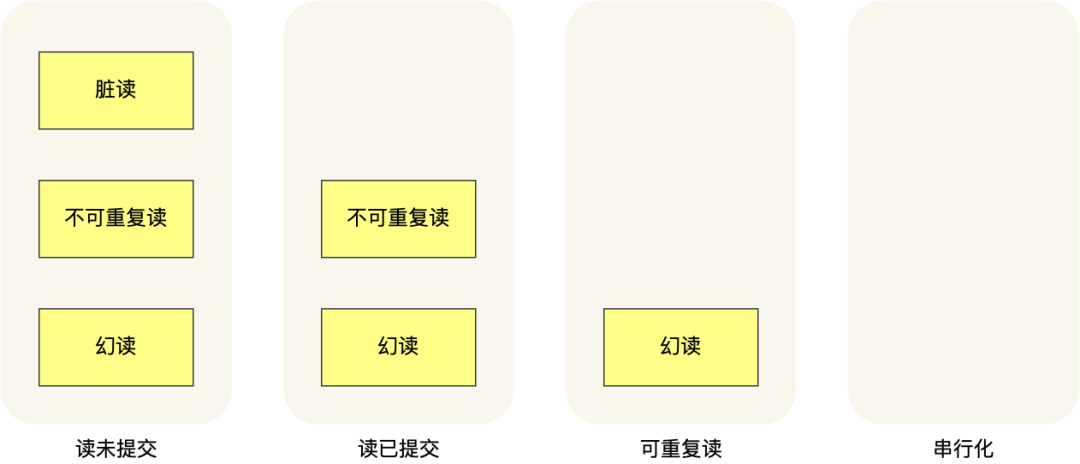
針對(duì)不同的隔離級(jí)別,并發(fā)事務(wù)時(shí)可能發(fā)生的現(xiàn)象也會(huì)不同。
 圖片
圖片
也就是說:
在「讀未提交」隔離級(jí)別下,可能發(fā)生臟讀、不可重復(fù)讀和幻讀現(xiàn)象;
在「讀提交」隔離級(jí)別下,可能發(fā)生不可重復(fù)讀和幻讀現(xiàn)象,但是不可能發(fā)生臟讀現(xiàn)象;
在「可重復(fù)讀」隔離級(jí)別下,可能發(fā)生幻讀現(xiàn)象,但是不可能臟讀和不可重復(fù)讀現(xiàn)象;
在「串行化」隔離級(jí)別下,臟讀、不可重復(fù)讀和幻讀現(xiàn)象都不可能會(huì)發(fā)生。
讀已提交和可重復(fù)讀的區(qū)別是什么?
可重復(fù)讀隔離級(jí)別是啟動(dòng)事務(wù)時(shí)生成一個(gè) Read View,然后整個(gè)事務(wù)期間都在用這個(gè) Read View。這樣就保證了在事務(wù)期間讀到的數(shù)據(jù)都是事務(wù)啟動(dòng)前的記錄。
讀提交隔離級(jí)別是在每次讀取數(shù)據(jù)時(shí),都會(huì)生成一個(gè)新的 Read View。也意味著,事務(wù)期間的多次讀取同一條數(shù)據(jù),前后兩次讀的數(shù)據(jù)可能會(huì)出現(xiàn)不一致,因?yàn)榭赡苓@期間另外一個(gè)事務(wù)修改了該記錄,并提交了事務(wù)。
mvcc怎么實(shí)現(xiàn)的?
MVCC 是多版本并發(fā)控制,MVCC保證了事務(wù)之間的隔離性,事務(wù)只能看到已經(jīng)提交的數(shù)據(jù)版本,從而保證了數(shù)據(jù)的一致性,并且避免了事務(wù)讀寫并發(fā)的問題,因?yàn)?select 快照讀是不會(huì)加鎖的。
可重復(fù)讀隔離級(jí)別是開啟事務(wù),執(zhí)行第一個(gè) select 查詢的時(shí)候,會(huì)創(chuàng)建 Read View,然后整個(gè)事務(wù)期間都在用這個(gè) Read View。讀提交隔離級(jí)別是在每次select 查詢時(shí),都會(huì)生成一個(gè)新的 Read View。
在創(chuàng)建 Read View 后,我們可以將記錄中的 trx_id 劃分這三種情況:
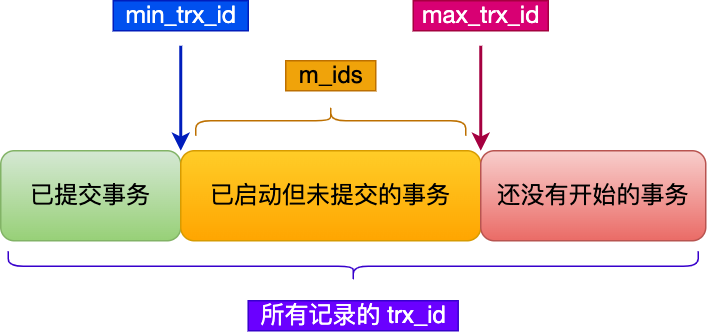
一個(gè)事務(wù)去訪問記錄的時(shí)候,除了自己的更新記錄總是可見之外,還有這幾種情況:
如果記錄的 trx_id 值小于 Read View 中的 min_trx_id 值,表示這個(gè)版本的記錄是在創(chuàng)建 Read View 前已經(jīng)提交的事務(wù)生成的,所以該版本的記錄對(duì)當(dāng)前事務(wù)可見。
如果記錄的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示這個(gè)版本的記錄是在創(chuàng)建 Read View 后才啟動(dòng)的事務(wù)生成的,所以該版本的記錄對(duì)當(dāng)前事務(wù)不可見。
如果記錄的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id之間,需要判斷 trx_id 是否在 m_ids 列表中:
如果記錄的 trx_id 在 m_ids 列表中,表示生成該版本記錄的活躍事務(wù)依然活躍著(還沒提交事務(wù)),所以該版本的記錄對(duì)當(dāng)前事務(wù)不可見。
如果記錄的 trx_id 不在 m_ids列表中,表示生成該版本記錄的活躍事務(wù)已經(jīng)被提交,所以該版本的記錄對(duì)當(dāng)前事務(wù)可見。
binlog,redolog,undolog有什么區(qū)別?
binlog(二進(jìn)制日志):記錄了對(duì)數(shù)據(jù)庫的所有更新操作,包括insert、update、delete等,用于數(shù)據(jù)恢復(fù)、主從復(fù)制和數(shù)據(jù)庫的增量備份。
redo log(重做日志):記錄了數(shù)據(jù)庫引擎對(duì)數(shù)據(jù)頁的物理修改操作,用于在數(shù)據(jù)庫發(fā)生異常情況時(shí)進(jìn)行恢復(fù),保證數(shù)據(jù)庫的一致性。
undo log(撤銷日志):記錄了事務(wù)執(zhí)行前的數(shù)據(jù)版本,用于事務(wù)的回滾和MVCC(多版本并發(fā)控制),在事務(wù)提交前,可以使用undo log還原數(shù)據(jù)狀態(tài)。
mysql 主從復(fù)制的過程
MySQL 的主從復(fù)制依賴于 binlog ,也就是記錄 MySQL 上的所有變化并以二進(jìn)制形式保存在磁盤上。復(fù)制的過程就是將 binlog 中的數(shù)據(jù)從主庫傳輸?shù)綇膸焐稀?/p>
這個(gè)過程一般是異步的,也就是主庫上執(zhí)行事務(wù)操作的線程不會(huì)等待復(fù)制 binlog 的線程同步完成。
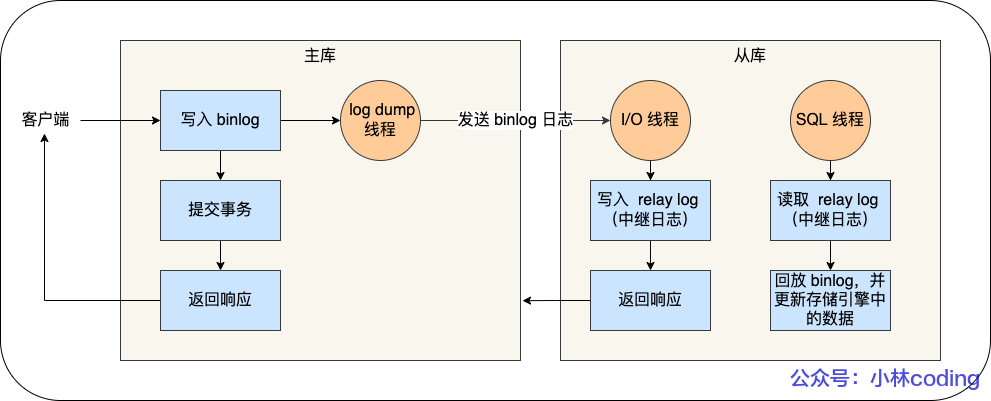 MySQL 主從復(fù)制過程
MySQL 主從復(fù)制過程
MySQL 集群的主從復(fù)制過程梳理成 3 個(gè)階段:
寫入 Binlog:主庫寫 binlog 日志,提交事務(wù),并更新本地存儲(chǔ)數(shù)據(jù)。
同步 Binlog:把 binlog 復(fù)制到所有從庫上,每個(gè)從庫把 binlog 寫到暫存日志中。
回放 Binlog:回放 binlog,并更新存儲(chǔ)引擎中的數(shù)據(jù)。
具體詳細(xì)過程如下:
MySQL 主庫在收到客戶端提交事務(wù)的請(qǐng)求之后,會(huì)先寫入 binlog,再提交事務(wù),更新存儲(chǔ)引擎中的數(shù)據(jù),事務(wù)提交完成后,返回給客戶端“操作成功”的響應(yīng)。
從庫會(huì)創(chuàng)建一個(gè)專門的 I/O 線程,連接主庫的 log dump 線程,來接收主庫的 binlog 日志,再把 binlog 信息寫入 relay log 的中繼日志里,再返回給主庫“復(fù)制成功”的響應(yīng)。
從庫會(huì)創(chuàng)建一個(gè)用于回放 binlog 的線程,去讀 relay log 中繼日志,然后回放 binlog 更新存儲(chǔ)引擎中的數(shù)據(jù),最終實(shí)現(xiàn)主從的數(shù)據(jù)一致性。
在完成主從復(fù)制之后,你就可以在寫數(shù)據(jù)時(shí)只寫主庫,在讀數(shù)據(jù)時(shí)只讀從庫,這樣即使寫請(qǐng)求會(huì)鎖表或者鎖記錄,也不會(huì)影響讀請(qǐng)求的執(zhí)行。
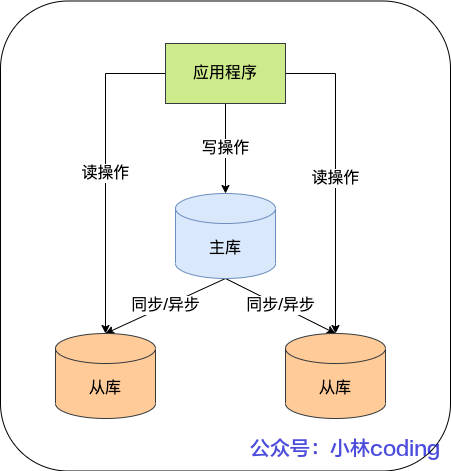 MySQL 主從架構(gòu)
MySQL 主從架構(gòu)
binlog 兩階段提交過程是怎么樣的?
事務(wù)提交后,redo log 和 binlog 都要持久化到磁盤,但是這兩個(gè)是獨(dú)立的邏輯,可能出現(xiàn)半成功的狀態(tài),這樣就造成兩份日志之間的邏輯不一致。
在 MySQL 的 InnoDB 存儲(chǔ)引擎中,開啟 binlog 的情況下,MySQL 會(huì)同時(shí)維護(hù) binlog 日志與 InnoDB 的 redo log,為了保證這兩個(gè)日志的一致性,MySQL 使用了內(nèi)部 XA 事務(wù)(是的,也有外部 XA 事務(wù),跟本文不太相關(guān),我就不介紹了),內(nèi)部 XA 事務(wù)由 binlog 作為協(xié)調(diào)者,存儲(chǔ)引擎是參與者。
當(dāng)客戶端執(zhí)行 commit 語句或者在自動(dòng)提交的情況下,MySQL 內(nèi)部開啟一個(gè) XA 事務(wù),分兩階段來完成 XA 事務(wù)的提交,如下圖:
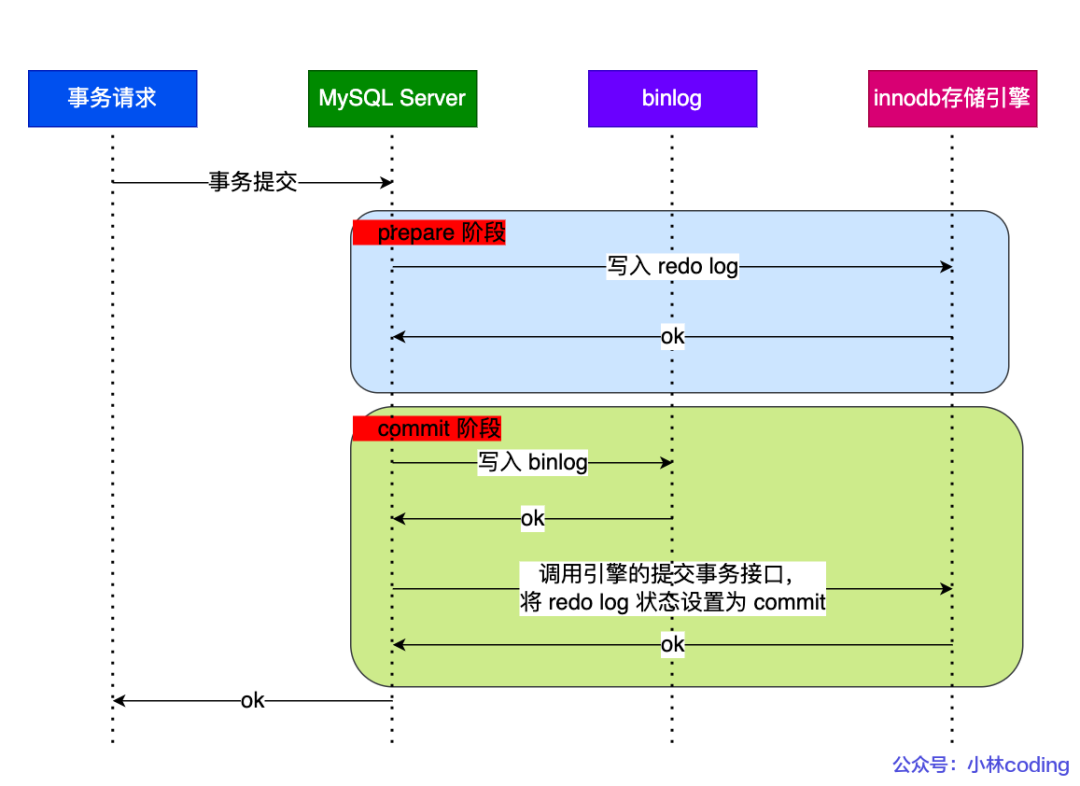 兩階段提交
兩階段提交
從圖中可看出,事務(wù)的提交過程有兩個(gè)階段,就是將 redo log 的寫入拆成了兩個(gè)步驟:prepare 和 commit,中間再穿插寫入binlog,具體如下:
prepare 階段:將 XID(內(nèi)部 XA 事務(wù)的 ID) 寫入到 redo log,同時(shí)將 redo log 對(duì)應(yīng)的事務(wù)狀態(tài)設(shè)置為 prepare,然后將 redo log 持久化到磁盤(innodb_flush_log_at_trx_commit = 1 的作用);
commit 階段:把 XID 寫入到 binlog,然后將 binlog 持久化到磁盤(sync_binlog = 1 的作用),接著調(diào)用引擎的提交事務(wù)接口,將 redo log 狀態(tài)設(shè)置為 commit,此時(shí)該狀態(tài)并不需要持久化到磁盤,只需要 write 到文件系統(tǒng)的 page cache 中就夠了,因?yàn)橹灰?binlog 寫磁盤成功,就算 redo log 的狀態(tài)還是 prepare 也沒有關(guān)系,一樣會(huì)被認(rèn)為事務(wù)已經(jīng)執(zhí)行成功;
我們來看看在兩階段提交的不同時(shí)刻,MySQL 異常重啟會(huì)出現(xiàn)什么現(xiàn)象?下圖中有時(shí)刻 A 和時(shí)刻 B 都有可能發(fā)生崩潰:
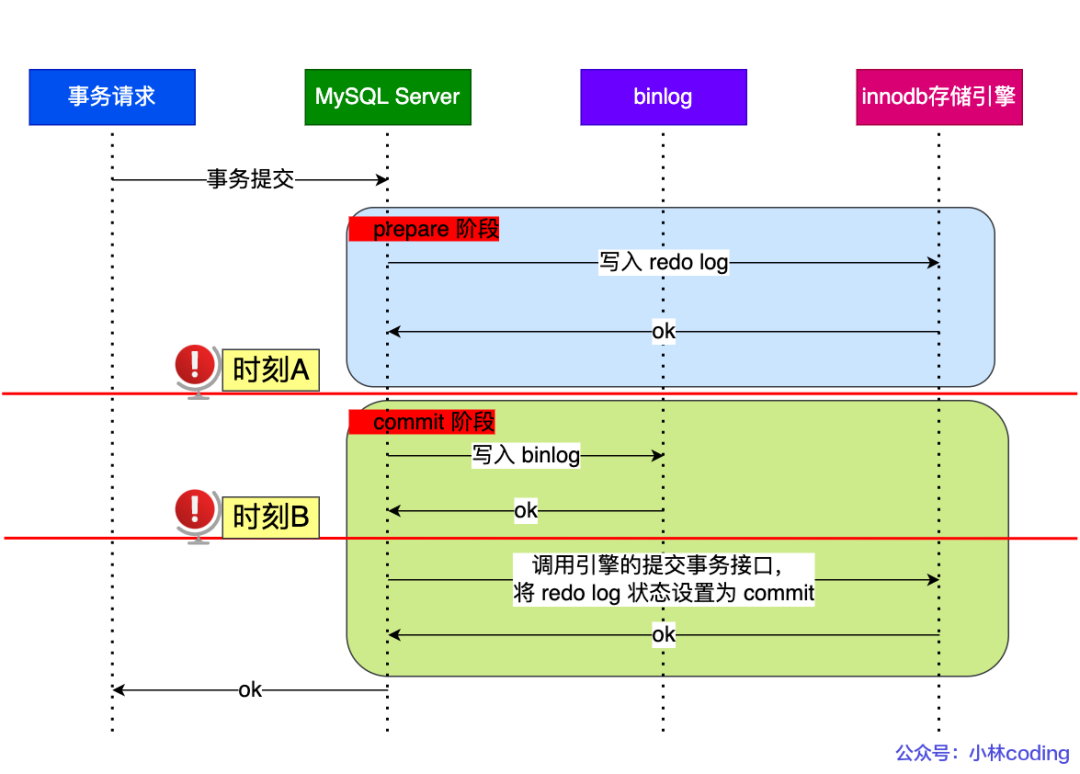 時(shí)刻 A 與時(shí)刻 B
時(shí)刻 A 與時(shí)刻 B
不管是時(shí)刻 A(redo log 已經(jīng)寫入磁盤, binlog 還沒寫入磁盤),還是時(shí)刻 B (redo log 和 binlog 都已經(jīng)寫入磁盤,還沒寫入 commit 標(biāo)識(shí))崩潰,此時(shí)的 redo log 都處于 prepare 狀態(tài)。
在 MySQL 重啟后會(huì)按順序掃描 redo log 文件,碰到處于 prepare 狀態(tài)的 redo log,就拿著 redo log 中的 XID 去 binlog 查看是否存在此 XID:
如果 binlog 中沒有當(dāng)前內(nèi)部 XA 事務(wù)的 XID,說明 redolog 完成刷盤,但是 binlog 還沒有刷盤,則回滾事務(wù)。對(duì)應(yīng)時(shí)刻 A 崩潰恢復(fù)的情況。
如果 binlog 中有當(dāng)前內(nèi)部 XA 事務(wù)的 XID,說明 redolog 和 binlog 都已經(jīng)完成了刷盤,則提交事務(wù)。對(duì)應(yīng)時(shí)刻 B 崩潰恢復(fù)的情況。
可以看到,對(duì)于處于 prepare 階段的 redo log,即可以提交事務(wù),也可以回滾事務(wù),這取決于是否能在 binlog 中查找到與 redo log 相同的 XID,如果有就提交事務(wù),如果沒有就回滾事務(wù)。這樣就可以保證 redo log 和 binlog 這兩份日志的一致性了。
所以說,兩階段提交是以 binlog 寫成功為事務(wù)提交成功的標(biāo)識(shí),因?yàn)?binlog 寫成功了,就意味著能在 binlog 中查找到與 redo log 相同的 XID。
Redis
redis分布式鎖實(shí)現(xiàn)
分布式鎖是用于分布式環(huán)境下并發(fā)控制的一種機(jī)制,用于控制某個(gè)資源在同一時(shí)刻只能被一個(gè)應(yīng)用所使用。如下圖所示:
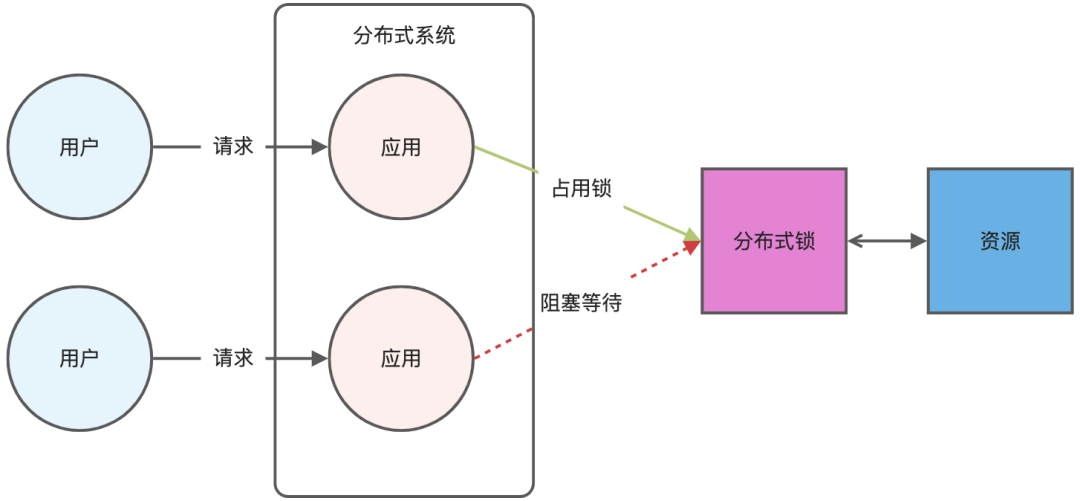 img
img
Redis 本身可以被多個(gè)客戶端共享訪問,正好就是一個(gè)共享存儲(chǔ)系統(tǒng),可以用來保存分布式鎖,而且 Redis 的讀寫性能高,可以應(yīng)對(duì)高并發(fā)的鎖操作場(chǎng)景。
Redis 的 SET 命令有個(gè) NX 參數(shù)可以實(shí)現(xiàn)「key不存在才插入」,所以可以用它來實(shí)現(xiàn)分布式鎖:
如果 key 不存在,則顯示插入成功,可以用來表示加鎖成功;
如果 key 存在,則會(huì)顯示插入失敗,可以用來表示加鎖失敗。
基于 Redis 節(jié)點(diǎn)實(shí)現(xiàn)分布式鎖時(shí),對(duì)于加鎖操作,我們需要滿足三個(gè)條件。
加鎖包括了讀取鎖變量、檢查鎖變量值和設(shè)置鎖變量值三個(gè)操作,但需要以原子操作的方式完成,所以,我們使用 SET 命令帶上 NX 選項(xiàng)來實(shí)現(xiàn)加鎖;
鎖變量需要設(shè)置過期時(shí)間,以免客戶端拿到鎖后發(fā)生異常,導(dǎo)致鎖一直無法釋放,所以,我們?cè)?SET 命令執(zhí)行時(shí)加上 EX/PX 選項(xiàng),設(shè)置其過期時(shí)間;
鎖變量的值需要能區(qū)分來自不同客戶端的加鎖操作,以免在釋放鎖時(shí),出現(xiàn)誤釋放操作,所以,我們使用 SET 命令設(shè)置鎖變量值時(shí),每個(gè)客戶端設(shè)置的值是一個(gè)唯一值,用于標(biāo)識(shí)客戶端;
滿足這三個(gè)條件的分布式命令如下:
SETlock_keyunique_valueNXPX10000
lock_key 就是 key 鍵;
unique_value 是客戶端生成的唯一的標(biāo)識(shí),區(qū)分來自不同客戶端的鎖操作;
NX 代表只在 lock_key 不存在時(shí),才對(duì) lock_key 進(jìn)行設(shè)置操作;
PX 10000 表示設(shè)置 lock_key 的過期時(shí)間為 10s,這是為了避免客戶端發(fā)生異常而無法釋放鎖。
而解鎖的過程就是將 lock_key 鍵刪除(del lock_key),但不能亂刪,要保證執(zhí)行操作的客戶端就是加鎖的客戶端。所以,解鎖的時(shí)候,我們要先判斷鎖的 unique_value 是否為加鎖客戶端,是的話,才將 lock_key 鍵刪除。
可以看到,解鎖是有兩個(gè)操作,這時(shí)就需要 Lua 腳本來保證解鎖的原子性,因?yàn)?Redis 在執(zhí)行 Lua 腳本時(shí),可以以原子性的方式執(zhí)行,保證了鎖釋放操作的原子性。
//釋放鎖時(shí),先比較unique_value是否相等,避免鎖的誤釋放
ifredis.call("get",KEYS[1])==ARGV[1]then
returnredis.call("del",KEYS[1])
else
return0
end
這樣一來,就通過使用 SET 命令和 Lua 腳本在 Redis 單節(jié)點(diǎn)上完成了分布式鎖的加鎖和解鎖。
redis緩存問題 穿透 雪崩 擊穿?
緩存雪崩:當(dāng)大量緩存數(shù)據(jù)在同一時(shí)間過期(失效)或者 Redis 故障宕機(jī)時(shí),如果此時(shí)有大量的用戶請(qǐng)求,都無法在 Redis 中處理,于是全部請(qǐng)求都直接訪問數(shù)據(jù)庫,從而導(dǎo)致數(shù)據(jù)庫的壓力驟增,嚴(yán)重的會(huì)造成數(shù)據(jù)庫宕機(jī),從而形成一系列連鎖反應(yīng),造成整個(gè)系統(tǒng)崩潰,這就是緩存雪崩的問題。
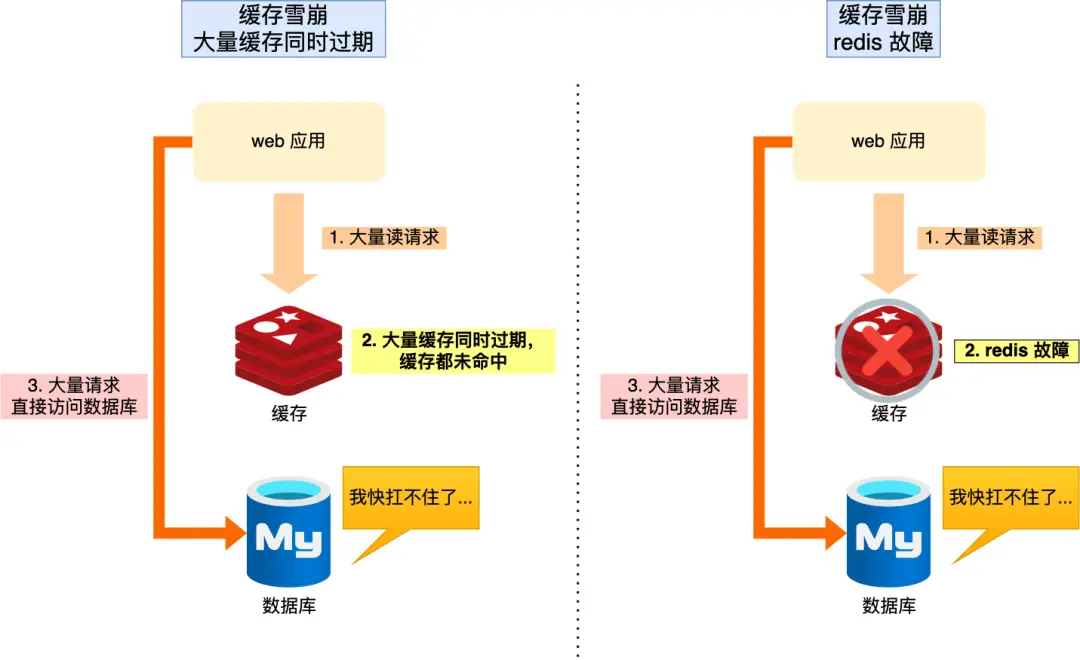 image.png
image.png
緩存擊穿:如果緩存中的某個(gè)熱點(diǎn)數(shù)據(jù)過期了,此時(shí)大量的請(qǐng)求訪問了該熱點(diǎn)數(shù)據(jù),就無法從緩存中讀取,直接訪問數(shù)據(jù)庫,數(shù)據(jù)庫很容易就被高并發(fā)的請(qǐng)求沖垮,這就是緩存擊穿的問題。
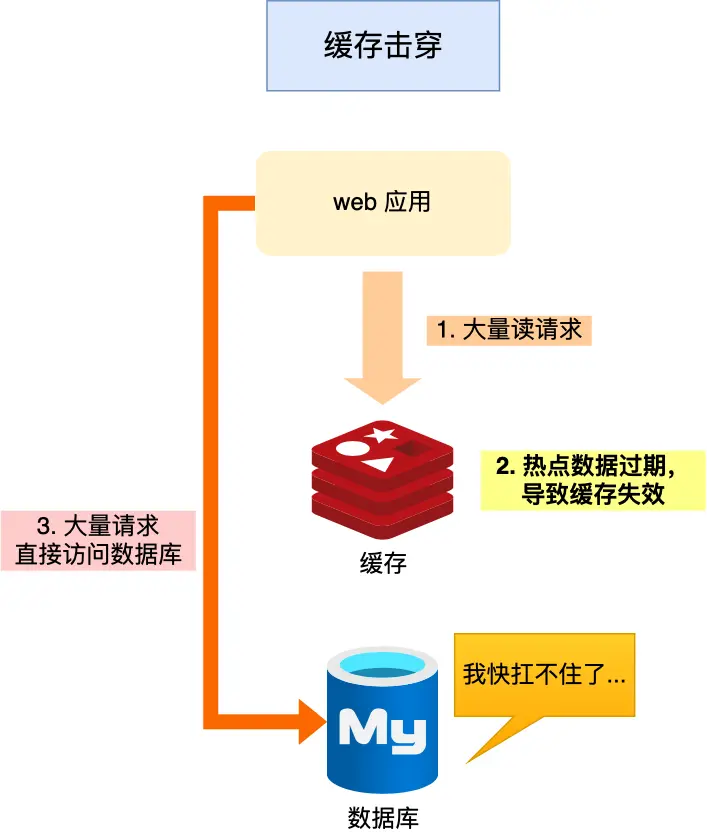 image.png
image.png
緩存穿透:當(dāng)用戶訪問的數(shù)據(jù),既不在緩存中,也不在數(shù)據(jù)庫中,導(dǎo)致請(qǐng)求在訪問緩存時(shí),發(fā)現(xiàn)緩存缺失,再去訪問數(shù)據(jù)庫時(shí),發(fā)現(xiàn)數(shù)據(jù)庫中也沒有要訪問的數(shù)據(jù),沒辦法構(gòu)建緩存數(shù)據(jù),來服務(wù)后續(xù)的請(qǐng)求。那么當(dāng)有大量這樣的請(qǐng)求到來時(shí),數(shù)據(jù)庫的壓力驟增,這就是緩存穿透的問題。
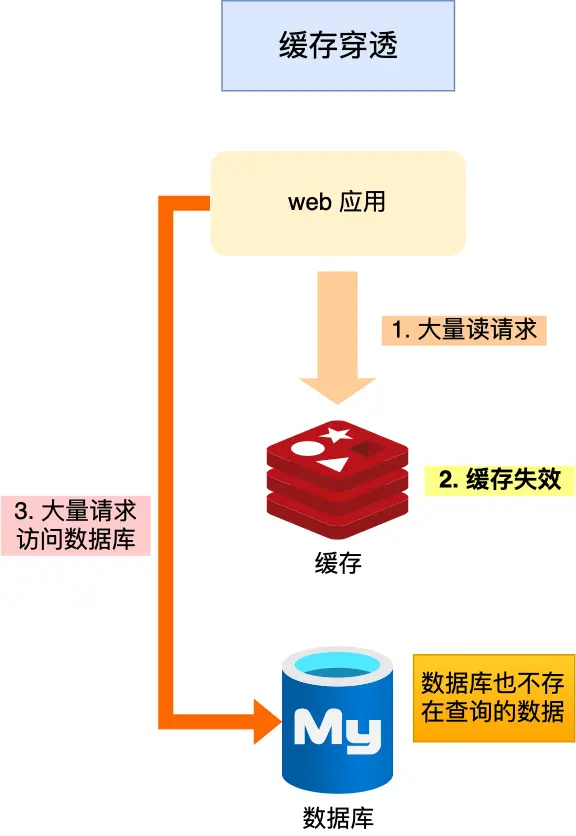
緩存雪崩解決方案:
均勻設(shè)置過期時(shí)間:如果要給緩存數(shù)據(jù)設(shè)置過期時(shí)間,應(yīng)該避免將大量的數(shù)據(jù)設(shè)置成同一個(gè)過期時(shí)間。我們可以在對(duì)緩存數(shù)據(jù)設(shè)置過期時(shí)間時(shí),給這些數(shù)據(jù)的過期時(shí)間加上一個(gè)隨機(jī)數(shù),這樣就保證數(shù)據(jù)不會(huì)在同一時(shí)間過期。
互斥鎖:當(dāng)業(yè)務(wù)線程在處理用戶請(qǐng)求時(shí),如果發(fā)現(xiàn)訪問的數(shù)據(jù)不在 Redis 里,就加個(gè)互斥鎖,保證同一時(shí)間內(nèi)只有一個(gè)請(qǐng)求來構(gòu)建緩存(從數(shù)據(jù)庫讀取數(shù)據(jù),再將數(shù)據(jù)更新到 Redis 里),當(dāng)緩存構(gòu)建完成后,再釋放鎖。未能獲取互斥鎖的請(qǐng)求,要么等待鎖釋放后重新讀取緩存,要么就返回空值或者默認(rèn)值。實(shí)現(xiàn)互斥鎖的時(shí)候,最好設(shè)置超時(shí)時(shí)間,不然第一個(gè)請(qǐng)求拿到了鎖,然后這個(gè)請(qǐng)求發(fā)生了某種意外而一直阻塞,一直不釋放鎖,這時(shí)其他請(qǐng)求也一直拿不到鎖,整個(gè)系統(tǒng)就會(huì)出現(xiàn)無響應(yīng)的現(xiàn)象。
后臺(tái)更新緩存:業(yè)務(wù)線程不再負(fù)責(zé)更新緩存,緩存也不設(shè)置有效期,而是讓緩存“永久有效”,并將更新緩存的工作交由后臺(tái)線程定時(shí)更新。
緩存擊穿解決方案:
互斥鎖方案,保證同一時(shí)間只有一個(gè)業(yè)務(wù)線程更新緩存,未能獲取互斥鎖的請(qǐng)求,要么等待鎖釋放后重新讀取緩存,要么就返回空值或者默認(rèn)值。
不給熱點(diǎn)數(shù)據(jù)設(shè)置過期時(shí)間,由后臺(tái)異步更新緩存,或者在熱點(diǎn)數(shù)據(jù)準(zhǔn)備要過期前,提前通知后臺(tái)線程更新緩存以及重新設(shè)置過期時(shí)間;
緩存穿透解決方案:
非法請(qǐng)求的限制:當(dāng)有大量惡意請(qǐng)求訪問不存在的數(shù)據(jù)的時(shí)候,也會(huì)發(fā)生緩存穿透,因此在 API 入口處我們要判斷求請(qǐng)求參數(shù)是否合理,請(qǐng)求參數(shù)是否含有非法值、請(qǐng)求字段是否存在,如果判斷出是惡意請(qǐng)求就直接返回錯(cuò)誤,避免進(jìn)一步訪問緩存和數(shù)據(jù)庫。
緩存空值或者默認(rèn)值:當(dāng)我們線上業(yè)務(wù)發(fā)現(xiàn)緩存穿透的現(xiàn)象時(shí),可以針對(duì)查詢的數(shù)據(jù),在緩存中設(shè)置一個(gè)空值或者默認(rèn)值,這樣后續(xù)請(qǐng)求就可以從緩存中讀取到空值或者默認(rèn)值,返回給應(yīng)用,而不會(huì)繼續(xù)查詢數(shù)據(jù)庫。
布隆過濾器:我們可以在寫入數(shù)據(jù)庫數(shù)據(jù)時(shí),使用布隆過濾器做個(gè)標(biāo)記,然后在用戶請(qǐng)求到來時(shí),業(yè)務(wù)線程確認(rèn)緩存失效后,可以通過查詢布隆過濾器快速判斷數(shù)據(jù)是否存在,如果不存在,就不用通過查詢數(shù)據(jù)庫來判斷數(shù)據(jù)是否存在。即使發(fā)生了緩存穿透,大量請(qǐng)求只會(huì)查詢 Redis 和布隆過濾器,而不會(huì)查詢數(shù)據(jù)庫,保證了數(shù)據(jù)庫能正常運(yùn)行,Redis 自身也是支持布隆過濾器的。
redis寫回策略你了解哪些?
常見的緩存更新策略共有3種:
Cache Aside(旁路緩存)策略;
Read/Write Through(讀穿 / 寫穿)策略;
Write Back(寫回)策略;
實(shí)際開發(fā)中,Redis 和 MySQL 的更新策略用的是 Cache Aside,另外兩種策略應(yīng)用不了。
Cache Aside(旁路緩存)策略
Cache Aside(旁路緩存)策略是最常用的,應(yīng)用程序直接與「數(shù)據(jù)庫、緩存」交互,并負(fù)責(zé)對(duì)緩存的維護(hù),該策略又可以細(xì)分為「讀策略」和「寫策略」。
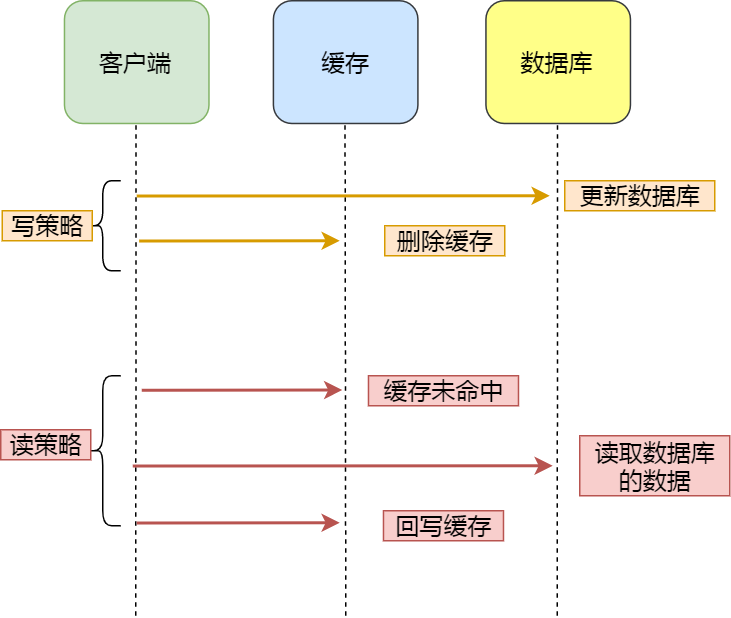
寫策略的步驟:
先更新數(shù)據(jù)庫中的數(shù)據(jù),再刪除緩存中的數(shù)據(jù)。
讀策略的步驟:
如果讀取的數(shù)據(jù)命中了緩存,則直接返回?cái)?shù)據(jù);
如果讀取的數(shù)據(jù)沒有命中緩存,則從數(shù)據(jù)庫中讀取數(shù)據(jù),然后將數(shù)據(jù)寫入到緩存,并且返回給用戶。
注意,寫策略的步驟的順序不能倒過來,即不能先刪除緩存再更新數(shù)據(jù)庫,原因是在「讀+寫」并發(fā)的時(shí)候,會(huì)出現(xiàn)緩存和數(shù)據(jù)庫的數(shù)據(jù)不一致性的問題。
舉個(gè)例子,假設(shè)某個(gè)用戶的年齡是 20,請(qǐng)求 A 要更新用戶年齡為 21,所以它會(huì)刪除緩存中的內(nèi)容。這時(shí),另一個(gè)請(qǐng)求 B 要讀取這個(gè)用戶的年齡,它查詢緩存發(fā)現(xiàn)未命中后,會(huì)從數(shù)據(jù)庫中讀取到年齡為 20,并且寫入到緩存中,然后請(qǐng)求 A 繼續(xù)更改數(shù)據(jù)庫,將用戶的年齡更新為 21。
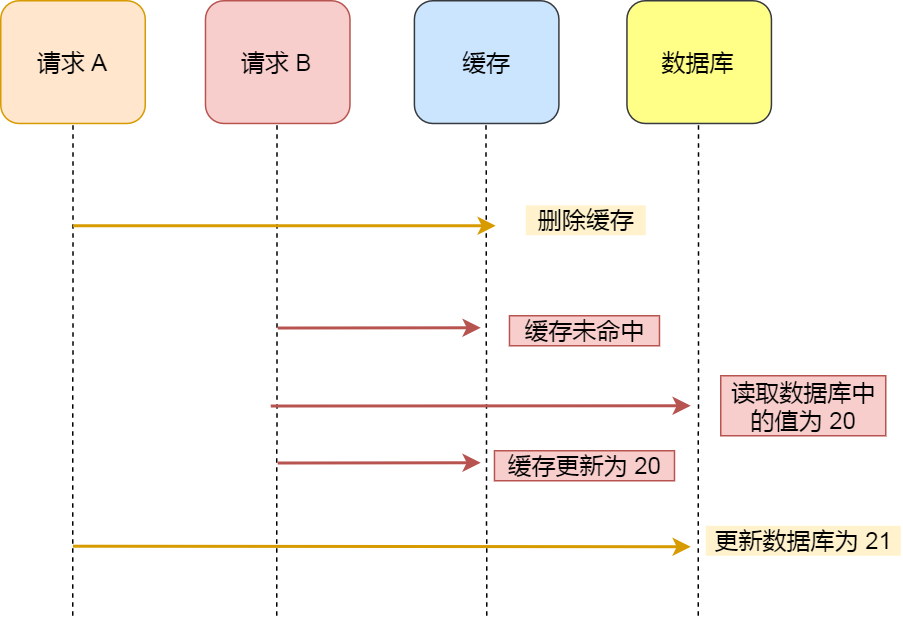
最終,該用戶年齡在緩存中是 20(舊值),在數(shù)據(jù)庫中是 21(新值),緩存和數(shù)據(jù)庫的數(shù)據(jù)不一致。
為什么「先更新數(shù)據(jù)庫再刪除緩存」不會(huì)有數(shù)據(jù)不一致的問題?
繼續(xù)用「讀 + 寫」請(qǐng)求的并發(fā)的場(chǎng)景來分析。
假如某個(gè)用戶數(shù)據(jù)在緩存中不存在,請(qǐng)求 A 讀取數(shù)據(jù)時(shí)從數(shù)據(jù)庫中查詢到年齡為 20,在未寫入緩存中時(shí)另一個(gè)請(qǐng)求 B 更新數(shù)據(jù)。它更新數(shù)據(jù)庫中的年齡為 21,并且清空緩存。這時(shí)請(qǐng)求 A 把從數(shù)據(jù)庫中讀到的年齡為 20 的數(shù)據(jù)寫入到緩存中。
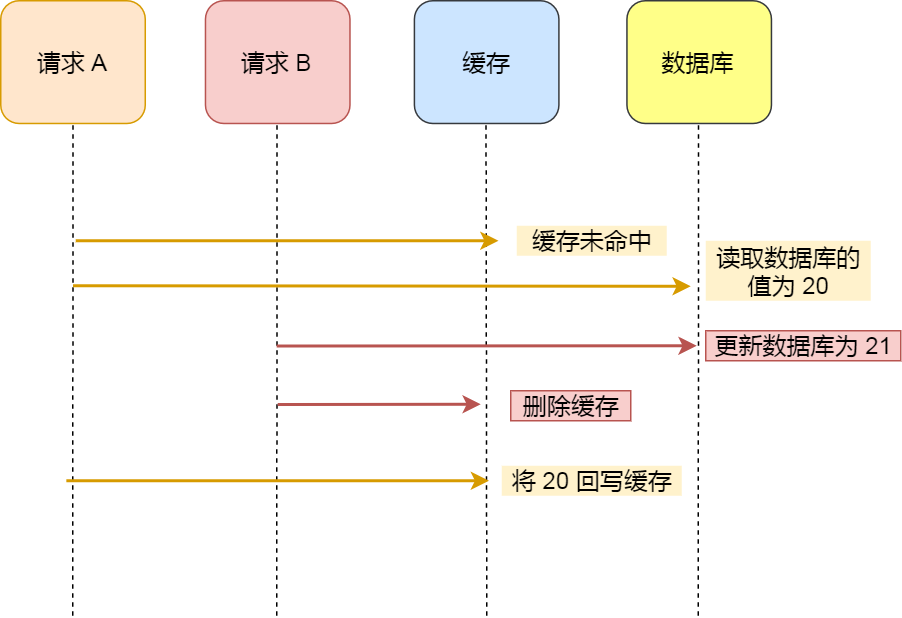
最終,該用戶年齡在緩存中是 20(舊值),在數(shù)據(jù)庫中是 21(新值),緩存和數(shù)據(jù)庫數(shù)據(jù)不一致。從上面的理論上分析,先更新數(shù)據(jù)庫,再刪除緩存也是會(huì)出現(xiàn)數(shù)據(jù)不一致性的問題,但是在實(shí)際中,這個(gè)問題出現(xiàn)的概率并不高。
因?yàn)榫彺娴膶懭胪ǔRh(yuǎn)遠(yuǎn)快于數(shù)據(jù)庫的寫入,所以在實(shí)際中很難出現(xiàn)請(qǐng)求 B 已經(jīng)更新了數(shù)據(jù)庫并且刪除了緩存,請(qǐng)求 A 才更新完緩存的情況。而一旦請(qǐng)求 A 早于請(qǐng)求 B 刪除緩存之前更新了緩存,那么接下來的請(qǐng)求就會(huì)因?yàn)榫彺娌幻卸鴱臄?shù)據(jù)庫中重新讀取數(shù)據(jù),所以不會(huì)出現(xiàn)這種不一致的情況。
Cache Aside 策略適合讀多寫少的場(chǎng)景,不適合寫多的場(chǎng)景,因?yàn)楫?dāng)寫入比較頻繁時(shí),緩存中的數(shù)據(jù)會(huì)被頻繁地清理,這樣會(huì)對(duì)緩存的命中率有一些影響。如果業(yè)務(wù)對(duì)緩存命中率有嚴(yán)格的要求,那么可以考慮兩種解決方案:
一種做法是在更新數(shù)據(jù)時(shí)也更新緩存,只是在更新緩存前先加一個(gè)分布式鎖,因?yàn)檫@樣在同一時(shí)間只允許一個(gè)線程更新緩存,就不會(huì)產(chǎn)生并發(fā)問題了。當(dāng)然這么做對(duì)于寫入的性能會(huì)有一些影響;
另一種做法同樣也是在更新數(shù)據(jù)時(shí)更新緩存,只是給緩存加一個(gè)較短的過期時(shí)間,這樣即使出現(xiàn)緩存不一致的情況,緩存的數(shù)據(jù)也會(huì)很快過期,對(duì)業(yè)務(wù)的影響也是可以接受。
Read/Write Through(讀穿 / 寫穿)策略
Read/Write Through(讀穿 / 寫穿)策略原則是應(yīng)用程序只和緩存交互,不再和數(shù)據(jù)庫交互,而是由緩存和數(shù)據(jù)庫交互,相當(dāng)于更新數(shù)據(jù)庫的操作由緩存自己代理了。
1、Read Through 策略
先查詢緩存中數(shù)據(jù)是否存在,如果存在則直接返回,如果不存在,則由緩存組件負(fù)責(zé)從數(shù)據(jù)庫查詢數(shù)據(jù),并將結(jié)果寫入到緩存組件,最后緩存組件將數(shù)據(jù)返回給應(yīng)用。
2、Write Through 策略
當(dāng)有數(shù)據(jù)更新的時(shí)候,先查詢要寫入的數(shù)據(jù)在緩存中是否已經(jīng)存在:
如果緩存中數(shù)據(jù)已經(jīng)存在,則更新緩存中的數(shù)據(jù),并且由緩存組件同步更新到數(shù)據(jù)庫中,然后緩存組件告知應(yīng)用程序更新完成。
如果緩存中數(shù)據(jù)不存在,直接更新數(shù)據(jù)庫,然后返回;
下面是 Read Through/Write Through 策略的示意圖:
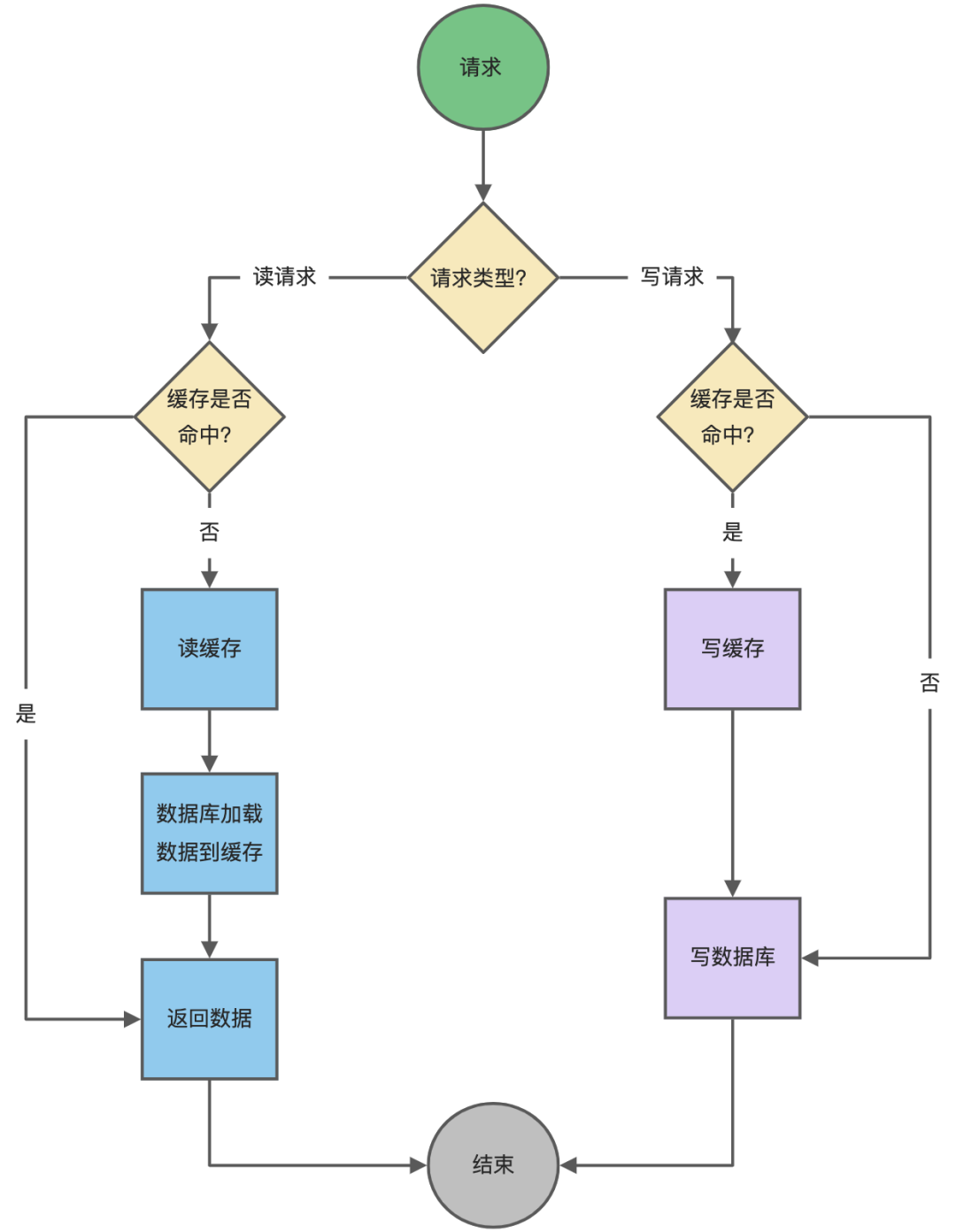 img
img
Read Through/Write Through 策略的特點(diǎn)是由緩存節(jié)點(diǎn)而非應(yīng)用程序來和數(shù)據(jù)庫打交道,在我們開發(fā)過程中相比 Cache Aside 策略要少見一些,原因是我們經(jīng)常使用的分布式緩存組件,無論是 Memcached 還是 Redis 都不提供寫入數(shù)據(jù)庫和自動(dòng)加載數(shù)據(jù)庫中的數(shù)據(jù)的功能。而我們?cè)谑褂帽镜鼐彺娴臅r(shí)候可以考慮使用這種策略。
Write Back(寫回)策略
Write Back(寫回)策略在更新數(shù)據(jù)的時(shí)候,只更新緩存,同時(shí)將緩存數(shù)據(jù)設(shè)置為臟的,然后立馬返回,并不會(huì)更新數(shù)據(jù)庫。對(duì)于數(shù)據(jù)庫的更新,會(huì)通過批量異步更新的方式進(jìn)行。
實(shí)際上,Write Back(寫回)策略也不能應(yīng)用到我們常用的數(shù)據(jù)庫和緩存的場(chǎng)景中,因?yàn)?Redis 并沒有異步更新數(shù)據(jù)庫的功能。
Write Back 是計(jì)算機(jī)體系結(jié)構(gòu)中的設(shè)計(jì),比如 CPU 的緩存、操作系統(tǒng)中文件系統(tǒng)的緩存都采用了 Write Back(寫回)策略。
Write Back 策略特別適合寫多的場(chǎng)景,因?yàn)榘l(fā)生寫操作的時(shí)候, 只需要更新緩存,就立馬返回了。比如,寫文件的時(shí)候,實(shí)際上是寫入到文件系統(tǒng)的緩存就返回了,并不會(huì)寫磁盤。
但是帶來的問題是,數(shù)據(jù)不是強(qiáng)一致性的,而且會(huì)有數(shù)據(jù)丟失的風(fēng)險(xiǎn),因?yàn)榫彺嬉话闶褂脙?nèi)存,而內(nèi)存是非持久化的,所以一旦緩存機(jī)器掉電,就會(huì)造成原本緩存中的臟數(shù)據(jù)丟失。所以你會(huì)發(fā)現(xiàn)系統(tǒng)在掉電之后,之前寫入的文件會(huì)有部分丟失,就是因?yàn)?Page Cache 還沒有來得及刷盤造成的。
這里貼一張 CPU 緩存與內(nèi)存使用 Write Back 策略的流程圖:
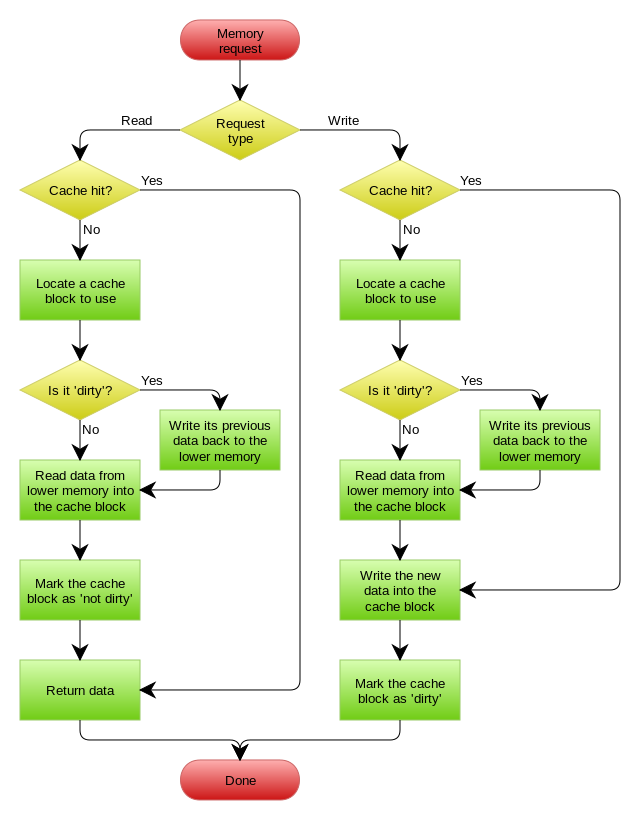 img
img
其他
Go:
context是否線程安全?
slice底層實(shí)現(xiàn)?
GMP模型介紹一下
場(chǎng)景題:
設(shè)計(jì)短鏈系統(tǒng)
算法:
最長公共前綴
三數(shù)之和
審核編輯:湯梓紅
-
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6801瀏覽量
123285 -
網(wǎng)絡(luò)協(xié)議
+關(guān)注
關(guān)注
3文章
267瀏覽量
21534 -
編程語言
+關(guān)注
關(guān)注
10文章
1942瀏覽量
34707 -
MySQL
+關(guān)注
關(guān)注
1文章
804瀏覽量
26531 -
線程
+關(guān)注
關(guān)注
0文章
504瀏覽量
19675
原文標(biāo)題:不愧是字節(jié),把我吊打了。。。
文章出處:【微信號(hào):小林coding,微信公眾號(hào):小林coding】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
進(jìn)程和線程的概念及其區(qū)別

進(jìn)程和線程的區(qū)別
進(jìn)程和線程區(qū)別
線程、進(jìn)程、程序的區(qū)別
進(jìn)程和線程得區(qū)別在哪?
進(jìn)程和線程的區(qū)別是什么
數(shù)模、模數(shù)相互轉(zhuǎn)化
線程與進(jìn)程有哪些區(qū)別?
線程和進(jìn)程的區(qū)別和聯(lián)系,線程和進(jìn)程通信方式
進(jìn)程和線程分別是什么,它們的區(qū)別是什么
進(jìn)程切換與線程切換有啥區(qū)別
程序中進(jìn)程和線程的區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論