 基于嵌入式ASIL D產品的開發經驗
基于嵌入式ASIL D產品的開發經驗
軟件開發始于需求卻不能終于需求,我們在滿足需求的同時,還需要考慮代碼本身的質量,包括可讀性、可維護性、可擴展性、可移植性、安全性、高效性等。
上一篇文章《汽車軟件單元測試的要點與意義》提到了諸如靜態分析與覆蓋度測試的一些代碼評價手段,這一篇講一些具體指標。
這些指標主要來自于ASIL D軟件的實踐經驗。
1
每個函數的語句數
該指標是指函數內部語句的個數,是一種基礎的代碼復雜度度量方式。在多數語言中,我們可以使用工具自動計算語句個數。
常見語句包含以下類型:
以分號(;)結尾的簡單語句
語句個數應盡量維持在10~20,最多不要超過50。
2
return語句的數量
為了提高代碼的可讀性,我們最好遵循“單一出口原則”,也就是盡量保證一個函數只有一個出口點(函數結束執行的地方)。
出口點通常是return語句,所以我們也建議盡量減少其數量,比如,一個函數的return維持在1~2個之內。
3
代碼行長度
寫文章要短句,是為了便于閱讀。代碼也是一樣,太長的代碼行會明顯增加閱讀代碼的難度,很現實的問題是,需要開發人員左右滾動屏幕。
在保證合理的邏輯、換行和縮進的前提下,要盡可能將長代碼拆分。通常,低于160個字符的代碼行可以認為是一個合理目標。
4
圈復雜度
圈復雜度是指通過源代碼線性獨立路徑的個數,也是用來衡量代碼復雜度。
如何計算呢?我們可以通過以下3個代碼控制流圖來看。
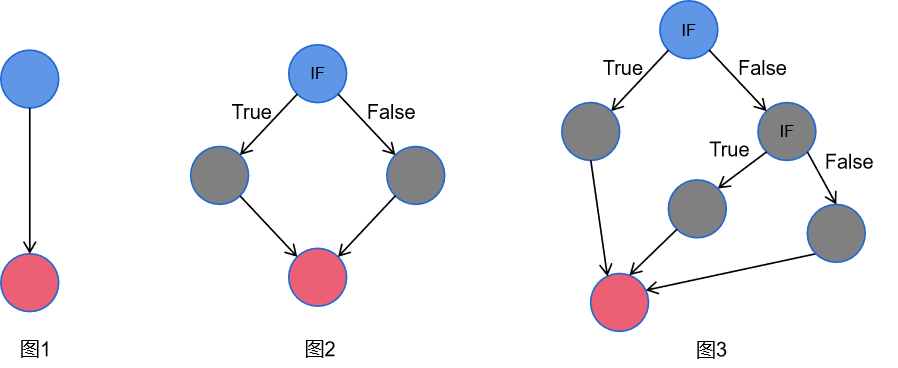
一種計算公式為,圈復雜度M=控制流圖邊數E-節點N+2
故,
圖1:M=1-2+2=1,即無判定節點,圈復雜度為1。
圖2:M=4-4+2=2,即一個判定節點,圈復雜度為2。
圖3:M=7-6+2=3,即兩個判定節點,圈復雜度為3。
除了評價本身代碼判定邏輯的復雜性之外,圈復雜度還能夠用來確定最少需要多少個測試用例來滿足分支和路徑的覆蓋度。
一般經驗是,圈復雜度應小于10,以達到較好的可測性。
5
非循環路徑數
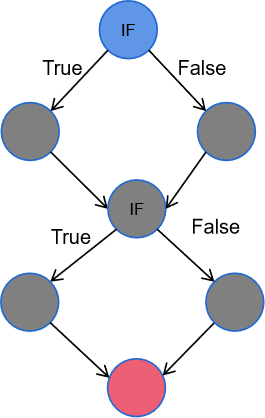
這個指標也被稱為NPATH,是指通過軟件所有可能路徑的數量。其中,循環中的循環(for, while, do-while)只訪問一次。
因此,NPATH也給出了達到路徑覆蓋所需的測試用例的最大數量。而圈復雜度給出了測試用例的最小數量。
如下圖,對應的圈復雜度和NPATH分別為2和4。NPATH建議限制在80個以內。
6
每個函數的嵌套級別
嵌套級別用來描述函數之間調用的深度層次。
當引入控制結構(if, while…)時,就會發生嵌套,每將控制結構放置在其他控制結構內部一次,嵌套級別就會增加一次。
以下為一個嵌套級別為2的代碼段示意。
if(a < K) {
if(b > L) {
function);
}
}
嵌套級別建議不超過4。
7
調用圖遞歸
調用圖是軟件工程中用于表示函數調用關系的有向圖,它顯示了哪個函數調用了哪個函數。
調用圖內部的遞歸是一個函數直接或間接(通過至少一個其他函數)再次調用自身的模式。
要想停止遞歸時,必須有一個結束條件,否則,遞歸將導致應用程序崩潰,但是,無論是直接遞歸還是間接遞歸,確定結束條件并不容易。
此外,由于遞歸算法需要更多的函數調用和堆棧操作,其使用會造成性能阻塞、可讀性差或堆棧溢出等問題。
一般不建議使用遞歸。
8
不同函數的調用次數
更多的函數調用必然帶來更大的復雜性,整體最好不超過7次。
9
參數數量
參數的數量是函數復雜性和接口復雜性的另一個指標。存在的參數越多,就越容易在調用函數時出錯,比如,參數順序錯誤。
如果函數參數超過了5個,可以試著把函數分成使用較少參數的邏輯部分。
10
goto語句
goto語句可以使程序直接跳轉到同一函數中的預定義位置。
goto是一個很有爭議的語句。在處理錯誤或跳出多層循環時,有很直接的效果,但非邏輯性的跳轉會讓代碼很難理解、出了錯誤也很難追蹤。
所以,通常強烈建議不要使用goto語句。
11
注釋密度
除了從語句結構上降低外,代碼復雜度還有一種應對方式是代碼注釋。
函數功能的文本化描述就是注釋,這顯然有助于理解代碼。特別地,代碼已經長時間沒有被修改,或者代碼必須由原始編寫人分析或修改時,這些注釋更加有用。
一種算法是,注釋密度是指第一個語句之后找到的注釋數量與語句數量之間的比率,20%是一個可參考的下限。
審核編輯:黃飛
-
嵌入式
+關注
關注
5086文章
19140瀏覽量
305862 -
函數
+關注
關注
3文章
4333瀏覽量
62708
原文標題:評價ASIL D軟件代碼的11個指標
文章出處:【微信號:eng2mot,微信公眾號:汽車ECU開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式系統開發實踐經驗分享
Linux嵌入式產品開發有哪些注意事項
嵌入式產品開發不同階段的解析
嵌入式產品開發有哪些不同的階段
嵌入式開發(一):嵌入式開發新手入門

新手怎么學習嵌入式開發?嵌入式培訓怎么學?
嵌入式產品開發流程





 工商網監
工商網監
評論