 LLM的幻覺問題最新綜述
LLM的幻覺問題最新綜述
大型語言模型(LLM)的出現標志著NLP的重大突破,導致文本理解和生成的顯著進步。然而,除了這些進步,LLM還產生了幻覺現象,導致生成內容與現實世界的事實或用戶輸入不一致。這篇綜述從LLM幻覺的分類開始,深入研究導致幻覺的因素。對幻覺檢測方法和基準進行了全面概述。此外,還相應地介紹了緩解幻覺的代表性方法。最后分析了面臨的挑戰,突出了當前的局限性,并提出了開放問題。
文中相關引用論文如下圖所示:
背景介紹
最近,LLM的出現引領了NLP范式的轉變,在語言理解和推理方面取得了前所未有的進步。然而,隨著LLMs的快速發展,有一個令人擔憂的趨勢,即其產生幻覺的傾向,導致看似合理但實際上不支持的內容。
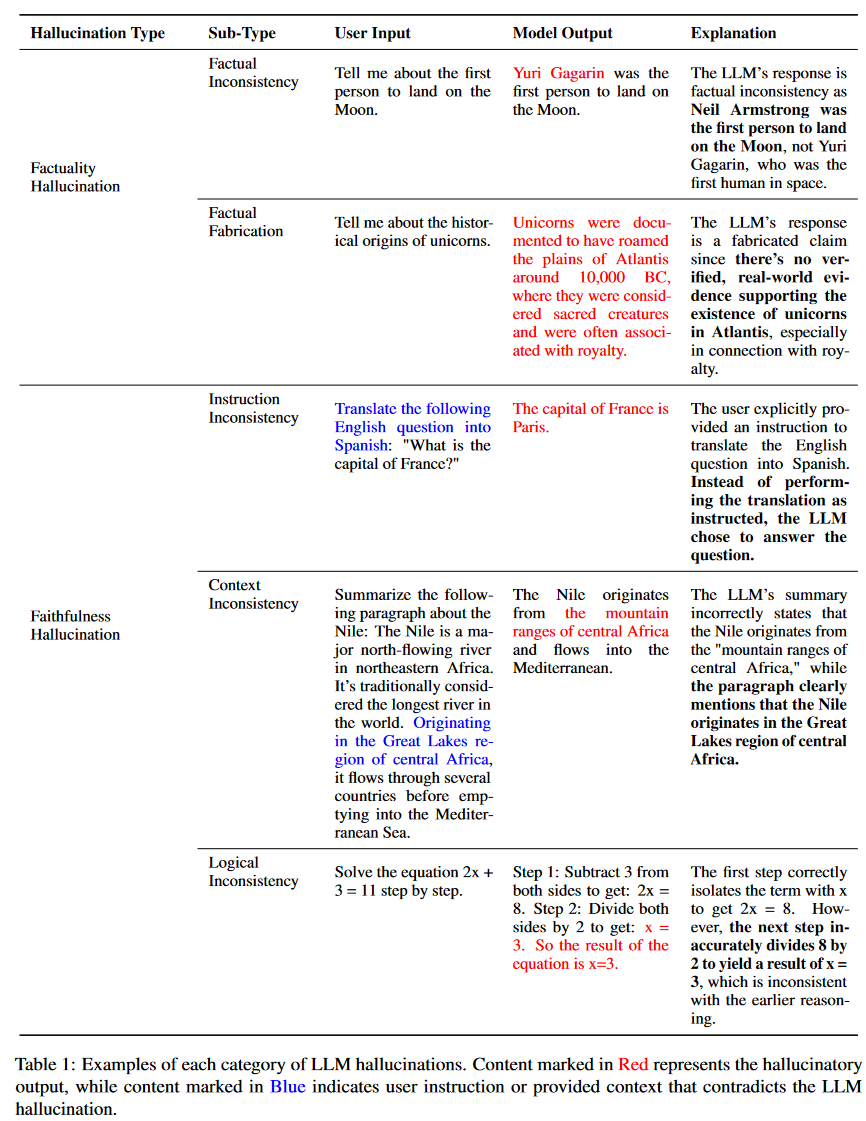
幻覺被描述為無意義或不忠實于所提供源內容的生成內容。根據與源內容的矛盾,這些幻覺又進一步分為內在幻覺和外在幻覺。在LLMs中,幻覺的范圍包含了一個更廣泛、更全面的概念,主要集中在事實錯誤上。本文重新定義了幻覺的分類,為LLM應用程序提供了一個更定制的框架。
我們把幻覺分為兩大類:事實幻覺和忠實幻覺。事實幻覺強調生成的內容與可驗證的現實世界事實之間的差異,通常表現為事實不一致或捏造。如圖1(a)所示,當被問及第一個在月球上行走的人是誰時,模型可能會斷言是1951年的查爾斯·林德伯格。而事實是尼爾·阿姆斯特朗在1969年阿波羅11號任務中成為第一個在月球上行走的人。

忠實幻覺是指生成內容與用戶指令或輸入提供的上下文背離,以及生成內容內部的自一致性。如圖1(b)所示,當模型被要求總結一篇新聞文章時,該模型不準確地生成了以色列和哈馬斯之間沖突的實際事件日期。針對事實幻覺,我們根據可驗證來源的內容將其進一步分為兩類:事實不一致和事實捏造。為了保證可靠性,我們強調從用戶的角度解決不一致性,將其分類為指令不一致性、上下文不一致性和邏輯不一致性,從而使其更好地與LLM的當前使用保持一致。
相關定義
大語言模型(LLM)
LLM是指一系列基于transformer的語言模型架構的通用模型,并在大量文本語料庫上進行了廣泛的訓練,其中著名模型有GPT-3、PaLM、LLaMA、GPT-4等。通過擴展數據量和模型容量,llm提高了驚人的應急能力,通常包括上下文學習(ICL) (Brown等人,2020)、思維鏈提示(Wei等人,2022)和指令遵循(Peng等人,2023)。
LLMs的訓練階段
LLM經歷的3個主要訓練階段:預訓練、監督微調(SFT)和從人工反饋中強化學習(RLHF)。
預訓練
語言模型在預訓練期間,旨在自回歸地預測序列中的下一個標記。通過在廣泛的文本語料庫上進行自監督訓練,模型獲得了語言語法、世界知識和推理的知識,為后續的微調任務提供了強大的基礎。語言模型的本質在于預測下一個單詞的概率分布。
監督微調
雖然LLM在預訓練階段獲得了大量的知識,但預訓練主要是為了完成優化。因此,預訓練的LLM基本上充當了補全機器,這可能會導致LLM的下一個單詞預測目標和用戶獲得所需響應的目標之間的不一致。為了彌補這一差距引入SFT ,其中涉及使用精心注釋的(指令,響應)對集進一步訓練LLM,從而增強LLM的能力和改進的可控性。
人類反饋的強化學習
雖然SFT過程成功地使LLM能夠遵循用戶指示,但它們仍然有空間更好地與人類偏好保持一致。在利用人類反饋的各種方法中,RLHF脫穎而出,成為一種通過強化學習來符合人類偏好的研究解決方案。通常,RLHF采用了一個偏好模型,該模型經過訓練可以在給定提示和人工標記的反應情況下預測偏好排名。為了與人類偏好一致,RLHF優化LLM,以生成最大化訓練偏好模型提供的獎勵的輸出,通常采用強化學習算法,如近端策略優化。
LLMs的幻覺
幻覺通常指的是生成的內容看起來荒謬或不忠實于提供的源內容的現象。一般來說,自然語言生成任務中的幻覺可以分為兩種主要類型:內在幻覺和外在幻覺。具體來說,內在幻覺屬于與源內容沖突的輸出。相反,外在幻覺指的是無法從源內容中驗證的輸出。
考慮到LLMs非常強調以用戶為中心的交互,并優先考慮與用戶指令保持一致,再加上它們的幻覺主要出現在事實層面,我們引入了更細粒度的分類法。為了更直觀地說明我們對LLM幻覺的定義,我們在表1中給出了每種幻覺的例子,并附有相應的解釋。
具體分類如下:
事實幻覺
現有的LLM偶爾會表現出產生與現實世界事實不一致或可能具有誤導性的輸出的趨勢,這對人工智能的可信性構成了挑戰。在這種情況下,我們將這些事實性錯誤歸類為事實性幻覺。根據生成的事實內容是否可以根據可靠來源進行驗證,它們可以進一步分為兩種主要類型:
事實不一致性:指LLM的輸出包含可以基于現實世界信息的事實,但存在矛盾的情況。這種類型的幻覺發生得最頻繁,并且來自不同的來源,包括LLM對事實知識的捕捉、存儲和表達。
事實捏造:指LLM的輸出包含無法根據既定的現實世界知識進行驗證的事實的實例。
忠實幻覺
隨著LLM的使用轉向更以用戶為中心的應用程序,確保它們與用戶提供的指令和上下文信息的一致性變得越來越重要。此外,LLM的忠實還體現在其生成內容的邏輯一致性上。從這個角度出發,我們將忠實幻覺分為三種類型:
指令不一致:指LLM的輸出偏離用戶指令。雖然一些偏差可能符合安全指導原則,但這里的不一致表示無意中與非惡意用戶指令不一致。
上下文不一致:指向LLM的輸出與用戶提供的上下文信息不一致的實例。
邏輯不一致:通常在推理任務中觀察到,LLM輸出表現出內部邏輯矛盾。這表現為推理步驟本身之間以及步驟和最終答案之間的不一致。
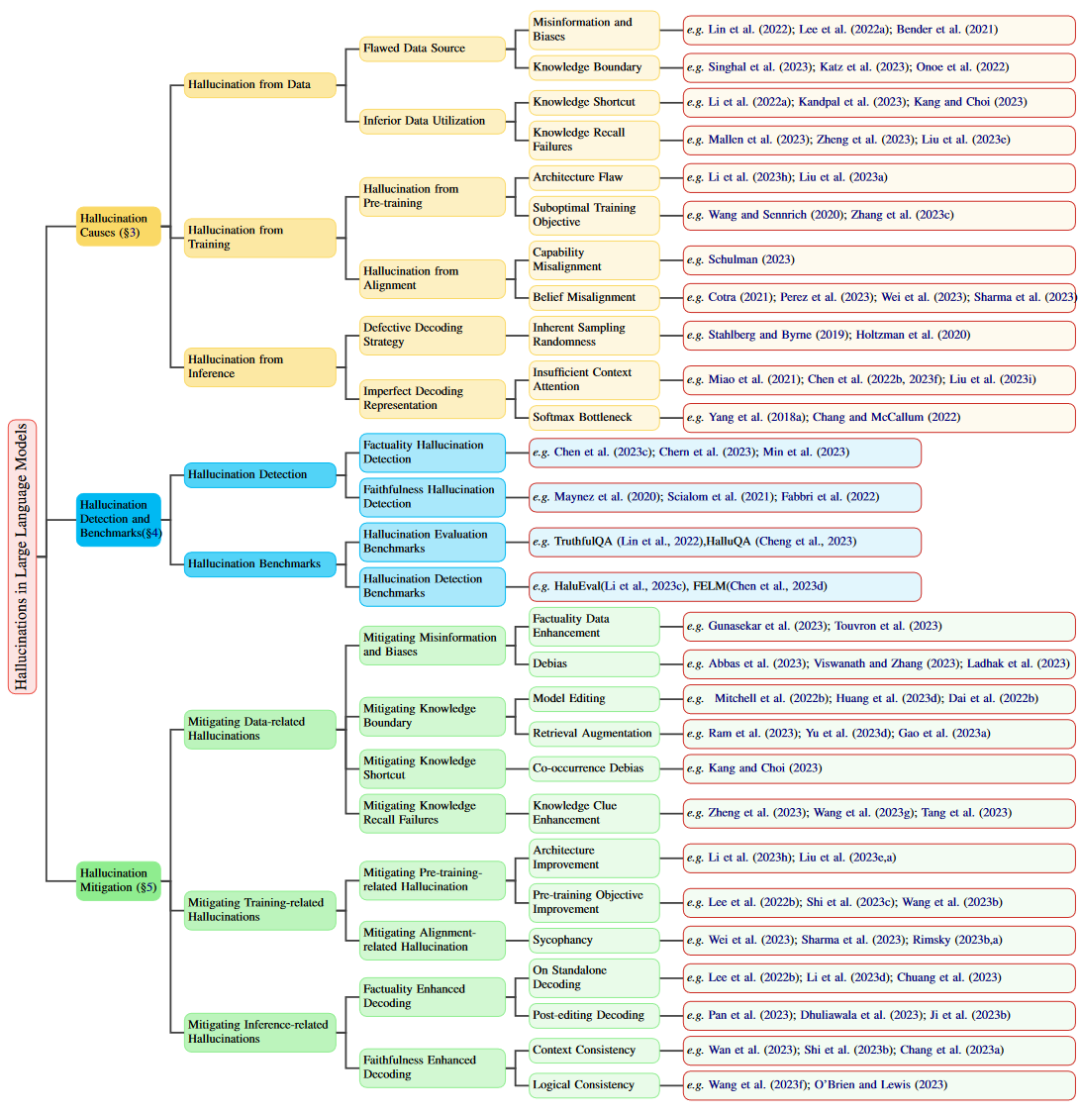
產生幻覺的原因
來自數據的幻覺
預訓練數據是LLM的基石,使它們能夠獲得泛化能力和事實知識。然而,它可能在不經意間成為LLM幻覺的來源。這主要表現在兩個方面:有缺陷的數據源,以及對數據中捕獲的事實知識的低劣利用。
有缺陷的數據源
當擴大預訓練數據大大提高了LLM的能力,但在保持一致的數據質量方面出現了挑戰,這可能會引入錯誤信息和偏差。此外,特定領域知識和數據中最新事實的缺乏會導致LLM形成知識邊界,這為特定場景中的LLM帶來了限制。基于此,主要將可能導致幻覺的因素分為錯誤信息、偏見和知識邊界限制。為了更全面地理解,表2列出了每種數據導致的幻覺的示例。
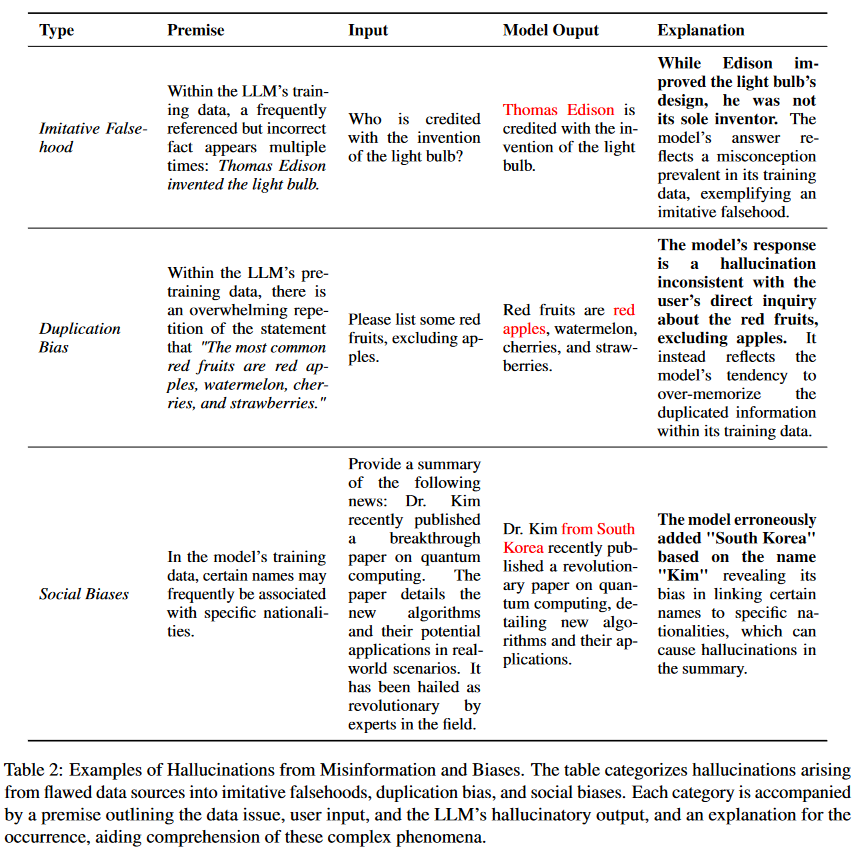
錯誤信息和偏見:隨著對大規模語料庫需求的日益增長,啟發式數據收集方法被用于高效地收集大量數據,增加了模仿虛假信息的風險。在提供大量數據的同時,它們可能無意中引入錯誤信息。此外,社會偏見可能無意中引入到LLM的學習過程。這些偏見主要包括重復偏見和各種社會偏見。
模仿虛假信息:LLMs預訓練的主要目標是模擬訓練分布。當LLMs在事實不正確的數據上進行訓練時,它們可能無意中放大這些不準確性,可能導致事實不正確的幻覺,稱為"模仿性虛假信息" 。
重復偏差:LLMs具有記憶訓練數據的內在傾向,這種記憶趨勢隨著模型大小的增加而增長。然而,在預訓練數據中存在重復信息的背景下,固有的記憶能力變得有問題。這種重復可能會使LLM從泛化轉向記憶,最終導致重復偏差,即LLM對重復數據的召回過于優先,導致偏離所需內容的幻覺。
社會偏見:某些偏見本質上與幻覺有關,特別是與性別和國籍有關的偏見。
知識邊界:雖然龐大的預訓練語料庫使LLM具有廣泛的事實知識,但它們本質上具有邊界。這種限制主要表現在兩個方面:缺乏最新的事實知識和專業領域知識。表3給出了一個例子。
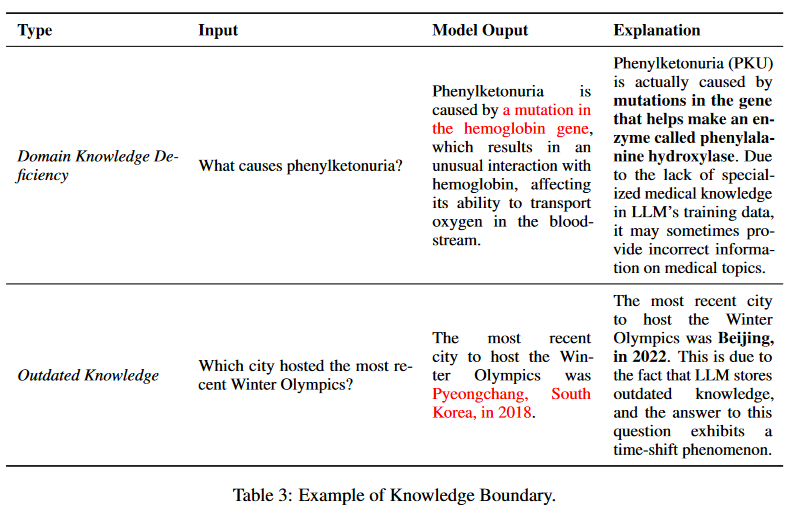
域內知識缺乏:LLM在通用領域的廣泛下游任務中表現出了卓越的性能。然而,鑒于這些通用LLM主要是在廣泛的公開數據集上訓練的,在特定領域的專業知識內在地受到缺乏專有訓練數據的限制。
過時的事實知識:除了特定領域知識的不足之外,關于LLM知識邊界的另一個內在限制是其最新知識的能力有限。LLM中嵌入的事實知識表現出明確的時間邊界,并可能隨著時間的推移而過時。
數據利用率低下
預訓練數據體現了豐富的現實世界事實知識,使LLM能夠在其參數中捕獲并隨后編碼大量事實知識。然而,盡管有這么龐大的知識儲備,由于參數化知識的低劣利用,仍然可能產生知識誘導的幻覺。表4列出了與劣質數據利用相關的每種幻覺類型的例子。
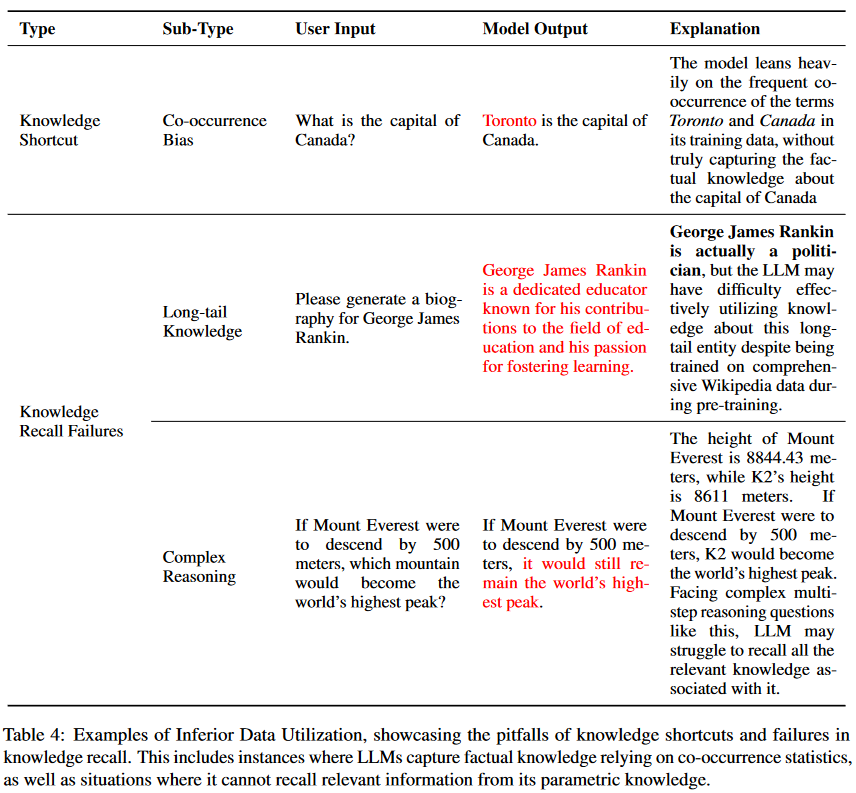
知識捷徑:LLM捕獲事實知識的確切機制仍然難以捉摸。最近的研究指出,LLM不是真正理解事實知識的復雜性,而是經常求助于捷徑。它們表現出過度依賴預訓練數據中的位置接近、共生統計和相關文檔計數的趨勢,這可能會引入對虛假相關性的偏差,如果偏差反映了事實不正確的信息,可能導致幻覺。
知識召回失敗:當LLM難以有效利用其廣泛的知識時,就會出現幻覺。本文探討了知識召回中的兩個主要挑戰:記憶長尾知識的不足,以及在需要多跳推理和邏輯推理的復雜場景中的困難。
長尾知識:長尾知識的特點是在預訓練數據中相對稀少,為LLM提出了固有的挑戰,主要依賴共現模式來記憶事實知識。
復雜場景:在多跳問答場景中,由于其推理的局限性,即使LLM擁有必要的知識,如果問題之間存在多種關聯,則可能難以產生準確的結果。此外,研究人員揭示了LLM中被稱為逆轉詛咒的特定推理失敗。具體來說,雖然當問題表述為“A是B”時,模型可以正確回答,但當被問及相反的“B是A”時,它表現出了失敗的邏輯推理。這種推理上的差異超出了簡單的推論。
來自訓練的幻覺
LLM的訓練過程主要包括兩個主要階段:1)預訓練階段,其中LLM學習通用表示并捕獲世界知識,以及2)對齊階段,LLM被調整以更好地與用戶指令和偏好保持一致。
來自預訓練的幻覺
預訓練是基礎階段,通常采用基于transformer的架構在大量語料庫上進行因果語言建模。然而,與幻覺有關的問題可能來自固有的結構設計和所采用的特定訓練策略。在本節中,我們深入研究了結構缺陷和曝光偏差的影響所帶來的挑戰。
結構缺陷:LLM通常采用基于transformer的架構,遵循GPT建立的范式,通過因果語言建模目標獲得表示,該框架以OPT、Falcon和Llama-2等模型為例。盡管取得了成功,但它也并非沒有缺陷,特別是在單向表示不足和注意力缺陷方面。
單向表示不充分:遵循因果語言建模范式,LLM僅基于前面的token,以從左到右的方式預測后面的token。這種單向建模在促進高效訓練的同時,也有其局限性。它只利用單一方向的上下文,這阻礙了其捕捉復雜上下文依賴關系的能力,潛在地增加了幻覺出現的風險。
注意力缺陷:基于transformer的架構,配備了自注意力模塊,在捕捉長程依賴關系方面表現出了非凡的能力。然而,無論模型規模如何,它們在算法推理的背景下偶爾會出現不可預測的推理錯誤,包括長短程依賴關系。一個潛在的原因是軟注意力的局限性,隨著序列長度的增加,注意力在各個位置上稀釋。
曝光偏差:除了結構缺陷,訓練策略也發揮了至關重要的作用。暴光偏差現象是由于自回歸生成模型中的訓練和推理之間存在差異。在訓練過程中,這些模型通常采用教師模型的最大似然估計(MLE)訓練策略,其中提供真實值作為輸入。然而,在推理過程中,模型依賴于自己生成的內容來進行后續的預測,這種不一致性會導致幻覺。
來自對齊的幻覺
對齊通常涉及兩個主要過程,即監督微調和從人類反饋中強化學習。雖然對齊顯著提高了LLM響應的質量,但它也引入了幻覺的風險。我們將與幻覺相關的對齊缺陷分為兩部分:能力偏差和信念偏差。
能力未對齊:考慮到LLM在預訓練過程中建立了固有的能力邊界,SFT利用高質量的指令及其相應的響應來讓LLM遵循用戶指令,釋放他們在此過程中獲得的能力。然而,當來自校準數據的需求超過預定義的能力邊界時,LLM被訓練產生超出其自身知識邊界的內容,從而放大了幻覺的風險。
觀點未對齊:LLM的激活封裝了與其生成的真實性相關的內部觀點。然而,在這些觀點和生成的輸出之間偶爾會出現不一致。即使通過人類反饋進行了改進,有時也會產生與內在觀點不同的輸出。這種行為被稱為諂媚,強調了模型傾向于安撫人類評估者,往往以犧牲真實性為代價。
來自推理的幻覺
解碼在體現LLM預訓練和對齊后的能力方面起著重要作用。然而,解碼策略中的某些缺陷可能會導致LLM幻覺。解碼過程的兩個潛在原因是解碼策略的固有隨機性和不完美的解碼表示。
解碼抽樣的隨機性
隨機抽樣是目前LLMs采用的主流解碼策略。將隨機性納入解碼策略的原因在于認識到高似然序列往往會導致令人驚訝的低質量文本,這被稱為似然陷阱。解碼策略中的隨機性帶來的多樣性是有代價的,因為它與幻覺風險的增加呈正相關。采樣溫度的升高導致更均勻的token概率分布,增加了從分布尾部采樣頻率較低的token的可能性。因此,這種對不經常出現的token進行采樣的傾向加劇了幻覺的風險。
不完美的解碼表示
在解碼階段,LLM使用頂層表示來預測下一個token。然而,頂層表示有其局限性,主要表現在兩個方面:上下文注意力不足和Softmax瓶頸。
上下文注意力不足:之前的研究,特別是在機器翻譯和摘要等領域,強調了使用編碼器-解碼器架構的生成模型的過度自信問題。這種過度自信源于過度關注部分生成的內容,通常優先考慮流暢性,而不是忠實地遵循源上下文。雖然主要采用因果語言模型架構的大型語言模型已得到廣泛使用,但過度自信現象仍然存在。在生成過程中,對下一個詞的預測同時取決于語言模型上下文和部分生成的文本。然而,語言模型在注意力機制中往往表現出局部焦點,優先考慮附近的單詞,從而導致上下文注意力的顯著缺陷。這種注意力不足會直接產生忠實度幻覺問題,其中模型輸出的內容偏離了原始上下文。
Softmax瓶頸:大多數語言模型使用softmax層,該層與詞嵌入一起對語言模型中的最終層表示進行操作,以計算與單詞預測相關的最終概率。然而,基于Softmax的語言模型的有效性受到公認的Softmax瓶頸的限制,其中將Softmax與分布式詞嵌入結合使用,在給定上下文的情況下,限制了輸出概率分布的表達能力,這阻止了語言模型輸出所需的分布引入了幻覺的風險。
幻覺檢測和基準
幻覺檢測
檢測LLM中的幻覺對于確保生成內容的可靠性和可信性至關重要。傳統的衡量標準主要是基于詞的重疊,無法區分合理內容和幻覺內容之間的細微差異。鑒于這些幻覺的不同性質,檢測方法也會有所不同。
事實幻覺檢測
針對事實幻覺的檢測方法通常分為檢索外部事實和不確定性估算。
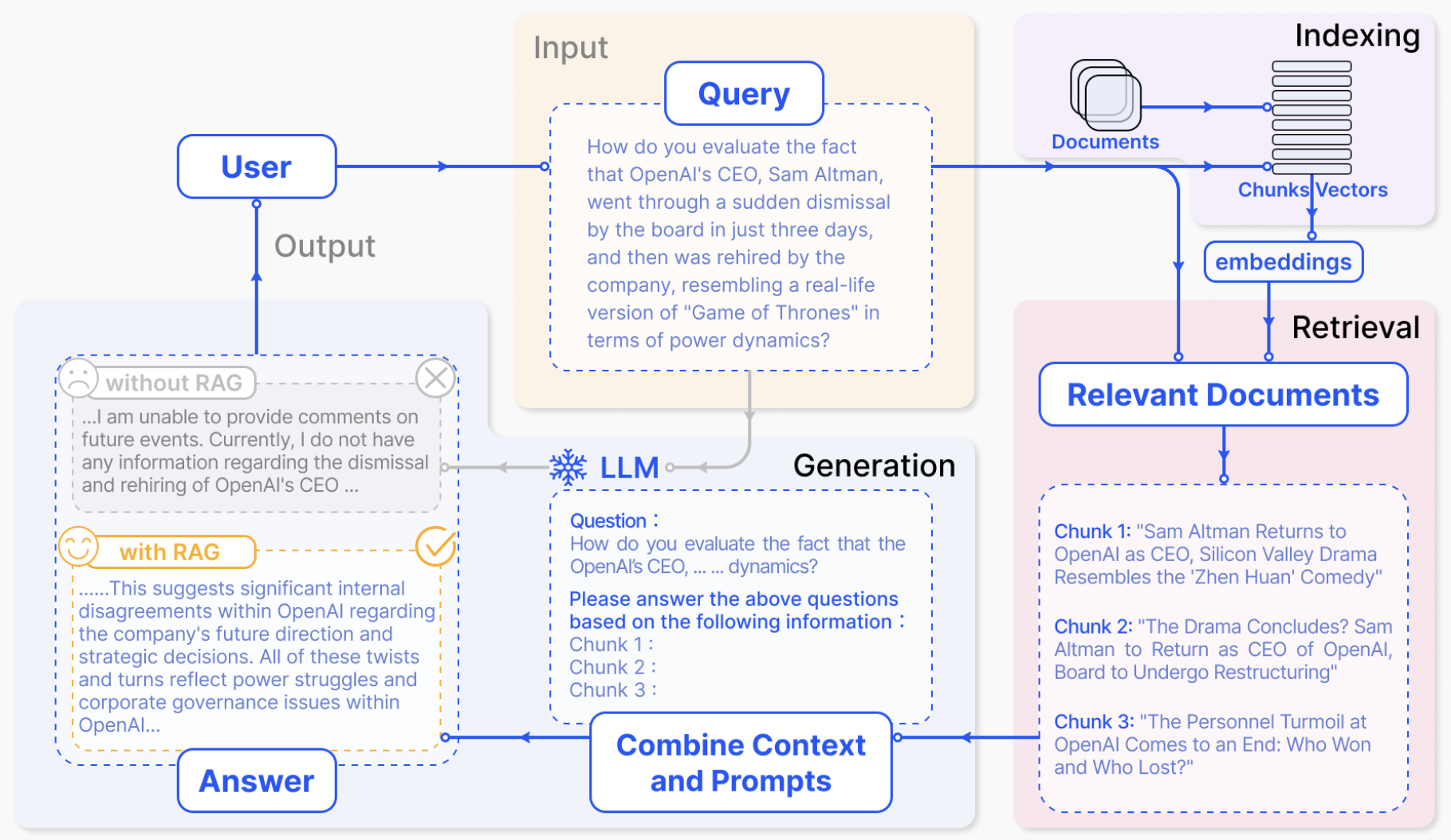
檢索外部事實:為了有效查明LLM輸出中的事實不準確性,一種直觀的策略涉及將模型生成的內容與可靠的知識源進行比較,如圖3所示。然而,傳統的事實核查方法經常納入簡化的實用性假設,在應用于復雜的現實場景時,會導致差異。認識到這些限制,研究人員更加強調現實世界的場景。他們開創了一個集成多個組件的全自動管道:斷言分解、原文檔檢索、細粒度檢索、基于斷言的摘要和準確性分類。

一些方法通過引入了FACTSCORE,一種專門用于長文本生成的細粒度事實指標。它將生成內容分解為原事實,然后計算可靠知識源支持的百分比。最近,研究人員通過查詢擴展增強了檢索幻覺檢測支持證據的標準方法。通過在檢索過程中將原始問題與LLM生成的答案相結合,解決了主題偏航的問題,確保檢索到的段落與問題和LLM的響應一致。
不確定性估算:雖然許多幻覺檢測方法依賴外部知識進行事實核查,但已有一些方法用來解決零資源環境下的這個問題,從而消除了檢索的需要。這些策略背后的基本前提是,LLM幻覺的起源本質上與模型的不確定性有關。因此,通過估計模型生成的事實內容的不確定性,檢測幻覺變得可行。不確定性估計方法大致可以分為兩類:基于內部狀態的方法和基于LLM行為的方法,如圖4所示。前者的運行假設是人們可以訪問模型的內部狀態,而后者則泛化到更受限的環境,僅利用模型的可觀察行為來推斷其潛在的不確定性。
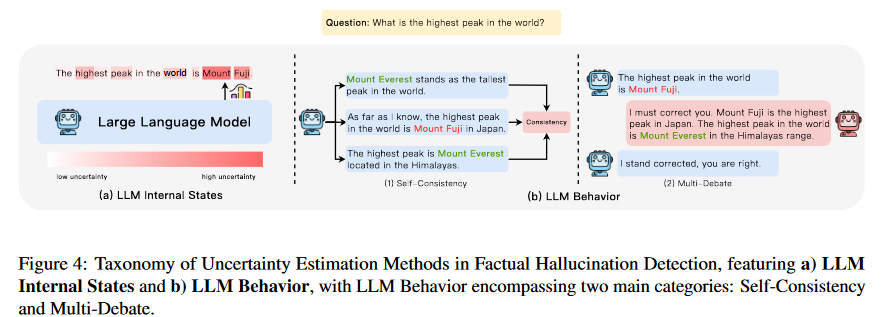
LLM的內部狀態:LLM的內部狀態可以作為其不確定性的信息性指標,通常通過token概率或熵等指標表現出來。通過考慮這些概念中的最小token概率來確定模型對量化的關鍵概念的不確定性。其基本原理是,低概率作為模型不確定性的有力指標,受概念中存在的高概率token的影響較小。類似地,另一種方法采用了一種基于自我評估的方法來進行不確定性估計,其依據是,語言模型從其生成的解釋中熟練地重建原始概念的能力表明其對該概念的熟練程度。首先促使模型為給定概念生成解釋,然后利用約束解碼使模型根據其生成的解釋重新創建原始概念,從響應序列中獲得的概率分數可以作為該概念的熟悉度分數。此外,另一種方法通過對抗性攻擊的視角來解釋幻覺。利用基于梯度的token替換,設計了誘導幻覺的提示。值得注意的是,與來自對抗性攻擊的token相比,從原始提示生成的第一個token通常表現出低熵。
LLM行為:然而,當系統只能通過API調用訪問時,可能無法訪問輸出的標記級概率分布。鑒于這種限制,一些研究已經將重點轉移到探索模型的不確定性上,或者通過自然語言提示以檢查其行為表現。例如,通過對LLM對同一提示的多個響應進行采樣,通過評估事實陳述之間的一致性來檢測幻覺。然而,這些方法主要依賴于直接查詢,明確地從模型中請求信息或驗證。受調查性訪談的啟發,可以使用間接查詢。與直接問題不同,這些間接問題通常提出開放式問題,以引出具體信息。通過使用這些間接查詢,可以更好地評估多個模型生成的一致性。除了從單個LLM的多代的自一致性來評估不確定性之外,還可以通過合并其他LLM來擁抱多智能體的視角。
忠實幻覺檢測
確保LLM忠實地提供上下文或用戶指令,對于它們在無數應用中的實際效用至關重要。忠實度幻覺檢測主要關注于確保生成的內容與給定的上下文相一致,避開無關或矛盾輸出的潛在陷阱。在本節中,我們將探索在LLM中檢測不忠實的方法,并提供圖5中的概述。
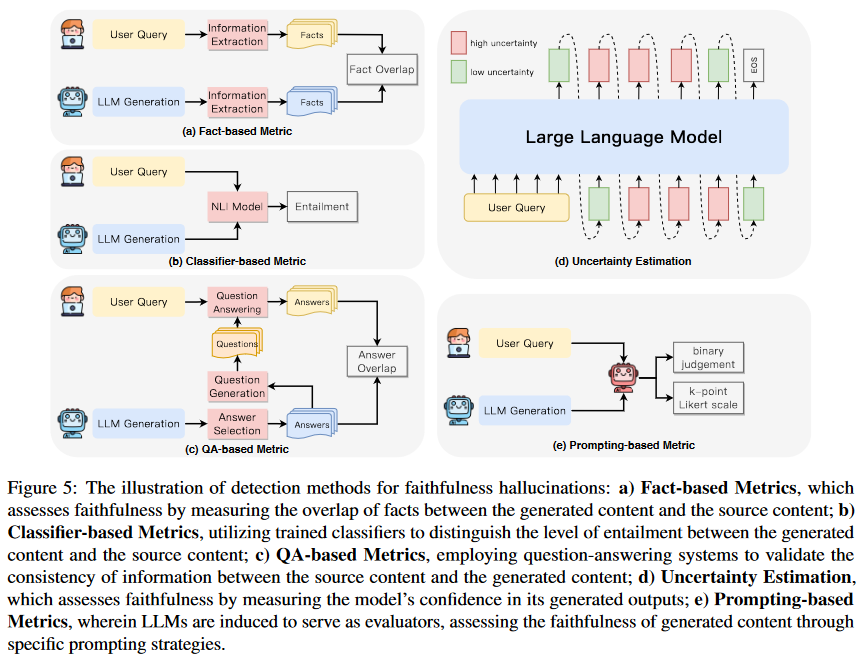
基于事實的指標:在評估忠實度的領域中,最直觀的方法之一涉及測量生成的內容和源內容之間關鍵事實的重疊度。考慮到事實的不同表現形式,可以根據實體、關系三元組和知識對度量進行分類。
基于N-gram:當將源內容作為參考時,傳統的基于N-gram重疊度的評價指標,如ROUGE和PARENT-T,也可以用于評估忠實度。
基于實體:基于實體重疊的指標普遍應用于摘要任務,因為這些關鍵實體的遺漏或不準確的生成都可能導致不忠實的摘要。
基于關系:即使實體匹配,它們之間的關系也可能是錯誤的。因此,更應該關注關系元組的重疊,該類標準使用經過訓練的端到端事實提取模型來計算提取的關系元組的重疊。
基于知識:在以知識為基礎的對話任務中,事實往往與對話中呈現的知識相對應。知識指標F1,用以評估模型的生成與提供的知識的匹配程度。
基于分類器的指標:除了計算事實重疊度之外,評估模型忠實度的另一種直接方法涉及分類器,這些分類器包括特定任務的幻覺內容和忠實內容,以及相關任務的數據或合成的數據。它可以大致分為以下幾種類型:
基于Entailment:許多研究在NLI數據集上訓練了分類器,以識別事實不準確性,特別是在抽象摘要的背景下。然而,傳統NLI數據集與不一致檢測數據集之間的輸入粒度不匹配限制了它們有效檢測不一致的適用性。在此基礎上,更先進的研究提出了一些方法,如對抗性數據集的微調,在依賴acr級別分解隱含決策,以及將文檔分割成句子單位,然后在句子對之間匯總分數等方法。
弱監督:雖然使用相關任務的數據來微調分類器在評估準確率方面顯示出了希望,但認識到相關任務和下游任務之間的固有差距是至關重要的。為了應對這一挑戰,一種使用基于規則的轉換來創建弱監督數據以微調分類器的方法被提出。同時,研究人員設計了一種自動生成標記級幻覺數據并執行標記級幻覺檢測的方法。
基于問答的指標:與基于分類器的指標相比,基于QA的指標因為它們增強了捕捉模型生成與其來源之間信息重疊的能力受到了關注。這些指標通過從LLM輸出內的信息單元中初步選擇目標答案進行操作,然后由問題生成模塊生成問題。這些問題隨后用于根據用戶上下文生成源答案。最后,通過比較源和目標答案的匹配分數來計算LLM答案的忠實度。
不確定性估計:有條件文本生成中的幻覺與模型的高度不確定性密切相關。
基于熵:數據到文本生成中的幻覺可能性和預測不確定性之間存在正相關,這是通過深度集成估計的。此外,利用蒙特卡羅Dropout產生的假設方差作為神經機器翻譯(NMT)中的不確定性度量。最近,特有方法使用條件熵評估生成式摘要的模型不確定性。
基于對數概率:使用長度歸一化序列對數概率來度量模型置信度。
基于模型:使用SelfCheck專注于復雜推理中的錯誤檢測。該系統通過目標提取、信息收集、步驟再生和結果比較的簡化過程來聚合置信度分數,從而提高問答的準確性。
基于提示的指標:LLM卓越的指令能力突出了其自動評估的潛力。利用這種能力,研究人員已經冒險采用新的范式來評估模型生成內容的忠實度。通過為LLM提供具體的評估指南,并向它們提供模型生成的和源內容,它們可以有效地評估忠實度。最終的評估輸出可以是忠實度的二元判斷,也可以是表示忠實度的k點李克特量表。對于提示選擇,評估提示可以是直接提示、思維鏈提示,使用上下文學習,或允許模型生成帶有解釋的評估結果。
基準
幻覺基準可以分為兩個主要領域:幻覺評估基準,評估現有前沿LLM產生的幻覺程度;以及幻覺檢測基準,專門用于評估現有幻覺檢測方法的性能。
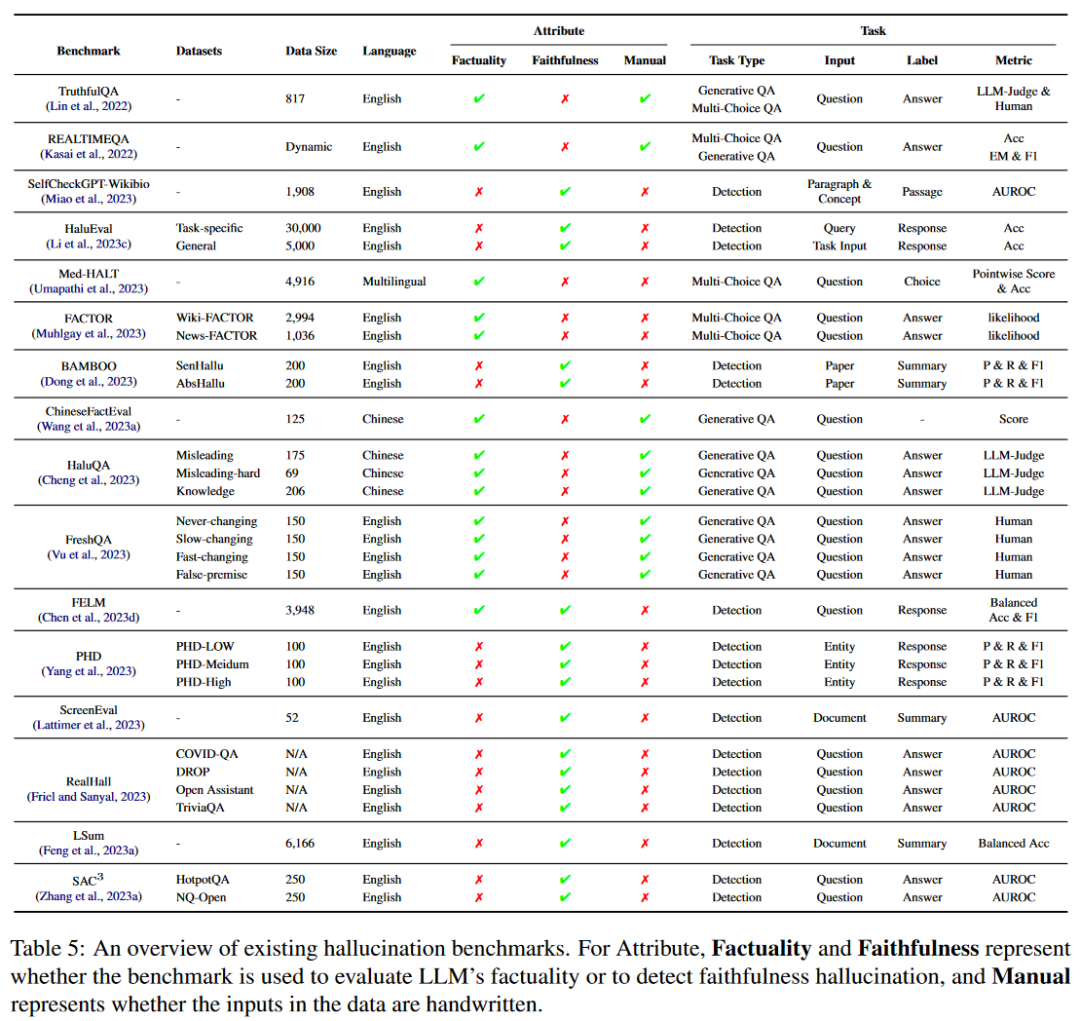
幻覺評估基準
幻覺評估基準是為了評估LLMs產生幻覺的傾向而設計的,特別強調識別事實的不準確性和測量與原始環境的偏差。目前,這些基準的主要焦點是評估生成內容的真實性。TruthfulQA:包含817個問題,涵蓋健康、法律、金融和政治等38個不同類別,是專門設計用于評估語言模型真實性的基準。它使用一種對抗性的方法,旨在引出“模仿謬誤”——由于模型在訓練數據中頻繁出現而可能產生的誤導性反應。基準測試分為兩部分,其中一部分包含人工篩選的問題,通過過濾掉GPT-3正確回答的問題,進一步篩選出437個問題。另一部分包括380個未經過濾的非對抗性問題。對于評估,TruthfulQA提供了兩種類型的問答任務:生成和選擇題,并采用人工評估來衡量模型的真實性和信息性。此外,該基準還引入了一個名為GPT-judge的自動度量,該度量在6.7B GPT-3模型上進行了微調。
REALTIMEQA:考慮到世界知識是不斷發展的,驗證LLMs關于當前世界的真實性就變得至關重要。這個基準提供了實時的開放域選擇題,這些選擇題來源于新發布的新聞文章,涵蓋了政治、商業、體育和娛樂等多種主題。此外,該基準還提供了一個實時評估的平臺,可以通過準確度評估的多項選擇格式,也可以使用精確匹配和基于token的F1指標評估生成設置。
Med-HALT:鑒于幻覺在醫學領域對患者護理的重要性,該基準強調了醫學領域特定于LLM的挑戰。Med-HALT結合了來自不同國家的多項選擇,旨在評估LLMs在醫學背景下的推理和記憶。推理任務有18,866個樣本,通過使用醫學多項選擇題測試LLM區分不正確或不相關選項和假問題的能力。同時,由4916個樣本組成的記憶任務,評估了LLM通過從PubMed摘要/標題生成鏈接或從給定鏈接和PIMDs生成標題來召回和生成準確事實信息的能力。對于評估,LLM的表現由它們在測試問題上的準確性或逐點分數來衡量,該分數既考慮正確答案的積極分數,也考慮錯誤答案的消極懲罰。
FACTOR:為了定量評估語言模型的真實性,出現了通過擾動指定語料庫中的事實陳述來自動創建基準的方法。產生了兩個基準測試:Wiki-FACTOR和News-FACTOR。具體來說,對于給定的前綴文本,語料庫中的原始補全作為事實正確的答案。然后用包含特定錯誤類型的提示來指導InstructGPT生成非事實的完成。這些生成的回答隨后被過濾流暢和自我一致性,作為多項選擇任務的基礎。
ChineseFactEval:通過收集來自常識、科學研究、醫學、法律、金融、數學和中國近代史等不同領域的問題,ChineseFactEval使用125個問題來評估六個當代中國llm的事實能力,以及GPT-4。在評估中,問題根據各種LLM實現的準確性進行分類,不同難度的問題分配不同的分數。所有LLM的響應主要由人工注釋,由FacTool補充,然后使用最終分數來評估它們的真實性。
HalluQA:借鑒了TruthfulQA的構建方法,旨在專門評估中國LLM中的幻覺,側重于模仿性的謊言和事實錯誤。該基準由30個領域的450個手工制作的對抗性問題組成,分為兩部分。誤導部分捕獲了成功欺騙GLM-130B的問題,而知識部分保留了ChatGPT和Puyu一致回答錯誤的問題。為了進行評估,LLM生成這些問題的答案,然后使用GPT-4將這些答案與正確答案進行比較,以確定答案是否包含幻覺。
FreshQA:認識到幻覺可能部分源于過時知識,引入了該基準來評估現有LLM的真實性。該基準包括600個手工設計的問題,其答案可能隨著時間的推移而變化,或其前提實際上不正確,該基準主要評估LLM快速變化知識的能力以及識別具有錯誤前提的問題的能力。在評估方面,該基準提供了兩種模式的評估過程:RELAXED和STRICT,前者只評估原始答案的正確性,后者進一步評估答案中每個事實的正確性。
幻覺檢測基準
對于幻覺檢測基準,大多數之前的研究主要集中在特定任務的幻覺上。然而,這些研究中產生的內容往往來自能力較弱的模型,如BART和PEGASUS。因此,它們可能不能準確地反映幻覺檢測策略的有效性。
SelfCheckGPT-Wikibio:基于維基生物數據集的概念,使用GPT-3生成合成維基百科文章,引入了一個句子級的幻覺檢測數據集。然后對這些段落的真實性在句子一級進行人工注釋,總共為238篇文章生成了1908個句子。
HaluEval:為了評估LLM識別幻覺的能力,使用自動生成和人工注釋相結合的方式構建,產生了5000個一般用戶查詢與ChatGPT響應以及30000個特定任務樣本。自動生成采用了“先采樣再過濾”的方法。該基準利用問答、基于知識的對話和文本摘要等特定任務的數據集,首先使用ChatGPT根據與任務相關的幻覺模式對多層面的幻覺答案進行采樣,然后用ChatGPT選擇最可信的幻覺樣本。
BAMBOO:該基準引入了兩個新的數據集SenHallu和AbsHallu,旨在檢測長文本背景下的幻覺。這些數據集是通過誘導ChatGPT在給定學術論文的情況下產生幻覺來構建的。
FELM:該基準評估了五個領域的真實性:世界知識、科學和技術、數學、寫作和推薦以及推理。雖然早期的研究有意地根據特定的模式誘導LLM產生幻覺,但該基準使用ChatGPT在零樣本設置中產生響應,共產生817個樣本(包括3948個片段)。每個段都標注了事實性、錯誤原因、錯誤類型和外部引用。作為事實性檢測器的測試平臺,該基準采用F1得分和平衡分類精度來評估片段和響應級別的事實性錯誤。
PHD:該基準強調的不是句子級的幻覺檢測,而是篇章級的檢測。基準的構建首先從Wikipedia轉儲中提取實體,然后使用ChatGPT生成段落。當LLM缺乏足夠的知識時,通常會出現事實錯誤,因此基準測試根據谷歌搜索返回的相關項的數量來選擇實體。
ScreenEval:該基準將范圍擴展到長格式對話中的事實不一致。基于SummScreen數據集,該數據集包括電視腳本和人工制作的摘要,該基準測試在句子級別為Longformer和GPT-4生成的摘要引入事實不一致注釋,從而得到包含52個文檔和624個摘要句子的數據集。在評估方面,使用AUROC評分在此基準上對幻覺檢測方法進行評估。
RealHall:該基準的構建遵循以下原則:幻覺檢測基準中的任務應該對LLMs提出實質性的挑戰,并與現實世界的應用相關,同時確保多樣性的廣度。與此一致,基準測試將重點放在問答任務上,根據提示中參考文本的可用性將其分為Closed和Open組。基準測試中的每個問題最初都使用ChatGPT生成響應,隨后通過涉及人工注釋、GPT4評估和基于規則的自動評估的組合方法為這些響應分配布爾真值標簽。使用AUROC評分對應用于該基準的幻覺檢測方法的有效性進行量化。
LSum:基準集中在LLMs摘要任務中的事實一致性檢測上。該基準基于XSum,包括使用來自GPTfamily、GLM-family和LLaMA家族的各種LLM生成摘要,并使用ChatGPT和GPT4在句子層面對事實一致性進行注釋,總共有6166個注釋摘要。
SAC3:該基準測試包括兩個數據集:HotpotQA-halu和NQopen-halu。這些數據集分別從HotpotQA和NQ-open的訓練集中抽取250個樣本來構建。然后用GPT-3.5渦輪增壓產生幻覺答案。然后,對答案進行人工注釋,將其與基礎事實和相關知識來源進行比較。
緩解幻覺
緩解與數據相關的幻覺
與數據相關的幻覺通常是偏見、錯誤信息和知識差距的原因,這些基本都植根于訓練數據。
緩解錯誤信息和偏差
為了減少錯誤信息和偏見的存在,最直觀的方法是收集高質量的事實數據以防止引入錯誤信息,并進行數據清洗以消除偏見。
增強事實數據:最直接的方法是手動管理預訓練數據集。然而,隨著預訓練數據集的不斷擴展,人工管理成為一個挑戰。考慮到學術或專業領域的數據通常是事實準確的,收集高質量的數據成為主要策略。
消除偏見:預訓練數據的偏見可分為重復偏見和社會偏見,每種都需要不同的消除偏見的方法。
重復偏見:通常分為完全重復和近似重復。對于完全重復項,最直接的方法包括精確子字符串匹配,以識別相同的字符串。然而,考慮到預訓練數據的龐大,這個過程可能是計算密集型的。此外,一種更有效的方法利用后綴數組的構造,能夠在線性時間內有效地計算大量子字符串查詢。關于近似重復,識別通常涉及近似全文匹配,通常使用基于哈希的技術來識別具有顯著N-gram重疊的文檔對。
社會偏見:當前的主流解決方案嚴重依賴于精心策劃的培訓語料庫。通過仔細選擇多樣化、平衡和代表性的訓練數據,我們可以減輕偏見,可能會引發幻覺。此外,還引入了工具包,使用戶能夠消除現有模型和自定義模型的偏見。
緩解知識邊界
受訓練數據的覆蓋范圍和時間邊界的限制,不可避免地形成知識邊界。通常有兩種方法解決這一問題,一是知識編輯,旨在直接編輯模型參數以彌合知識鴻溝。另一種通過檢索增強生成(RAG)利用非參數知識源。
知識編輯:目的是通過納入額外的知識來糾正模型行為。當前的知識編輯技術可以修復事實性錯誤和刷新過時的信息以緩解知識鴻溝,可分為兩類:通過修改模型參數改變模型的行為或使用外部模型插件凍結原始模型。
修改模型參數:這類技術直接將知識注入到原始模型中,導致模型輸出的實質性改變,這可以進一步分為定位后編輯方法和元學習方法。定位后編輯方法由兩個階段組成,首先定位模型參數中“有bug的”部分,然后對它們進行更新以改變模型的行為。元學習方法訓練一個外部超網絡來預測原始模型的權重更新。然而,元學習方法往往需要額外的訓練和記憶成本,需要專門的設計來減小llm時代超網絡的規模(如低秩分解)。雖然這些方法可以細粒度地調整模型的行為,但對參數的修改可能會對模型的固有知識產生潛在的有害影響。
保留模型參數:一些研究不是直接修改模型參數,而是將額外的模型插件應用到原始模型中,以實現模型行為的所需更改。SERAC采用了一個范圍分類器,將存儲在外部編輯記憶中的與新知識相關的輸入路由到反事實模型,這可以幫助基本模型處理更新的信息。與整個模型相比,有多種技術涉及將額外的參數層(例如適配器層)作為插件合并到原始模型中。T-Patcher和NKB都將補丁添加到FFN層中,這些層被認為是存儲知識的存儲庫,以糾正事實錯誤。CALINET 提出了一種識別PLM中錯誤知識的評估方法,并通過引入類似FFN的內存槽來調整輸出,這有助于緩解知識鴻溝。這些方法需要額外的步驟來訓練參數模塊,精心設計訓練功能和結構,使插件在保持原始模塊處理未編輯事實的同時,發揮更新知識的作用。
檢索增強:減輕知識鴻溝的直觀方法是檢索增強生成(RAG),通過對從外部知識源檢索的相關文檔進行條件約束,使LLM生成ground-truth。通常,RAG遵循檢索后讀取,其中相關的上下文文檔首先由檢索器從外部源檢索,然后由生成器對輸入文本和檢索文檔進行條件約束生成所需的輸出。將使用檢索增強來減輕幻覺的方法分為三種類型,包括一次性檢索、迭代檢索和事后檢索。

一次檢索:目的是將單次檢索獲得的外部知識直接添加到LLMs的提示符中。Incontext RALM是一種簡單而有效的策略,即將選定的文檔預先添加到LLM的輸入文本中。PKG采用可訓練的背景知識模塊,將其與任務知識對齊,生成相關的上下文信息。PKG的有效性突出了通過整合檢索到的背景知識來提高LLM忠誠度的潛力。
迭代檢索:當面對復雜的挑戰時(如多步推理和長篇問答),傳統的一次性檢索可能不足。針對這些苛刻的信息需求,最近的研究提出了迭代檢索,它允許在整個生成過程中不斷收集知識。一個新興的研究方向試圖通過將這些復雜的任務分解成更易于管理的子任務來解決這些復雜的任務。認識到思維鏈提示在多步驟推理中帶來的實質性進步,許多研究嘗試在每個推理步驟中納入外部知識,并進一步指導基于正在進行的推理的檢索過程,減少推理鏈中的事實錯誤。
事后檢索:通過隨后的基于檢索的修訂來細化LLM輸出。為了提高LLM的可信度和歸因性,研究人員先研究相關證據,然后根據發現的與證據的差異對初始生成進行修改。同樣,有方法引入了驗證和驗證框架,通過引入外部知識來提高推理鏈的事實準確性。對于一致性低于平均水平的推理鏈,框架生成驗證問題,然后根據檢索到的知識提煉基本原理,確保更真實的響應。
緩解知識捷徑
當LLMs依靠虛假的相關性(如預訓練語料庫的共現統計)來獲取事實知識時,知識捷徑就會顯現出來。可以通過排除有偏樣本構建的去偏數據集進行微調。盡管這導致頻繁事實的召回率顯著下降,因為更多的樣本被排除在外,但當微調過程中看不到罕見事實時,這種方法很難泛化。
緩解知識召回失敗
LLMs產生幻覺的一個普遍原因是他們無法準確地檢索和應用嵌入在參數化知識中的相關信息。在信息完整性至關重要的復雜推理場景中,這一挑戰尤為嚴峻。通過增強知識回憶,我們可以更好地將模型的輸出錨定到可驗證的知識上,從而提供更強大的防御,防止產生幻覺內容。通常,召回知識最直接的方法是讓LLMs通過思維鏈提示進行推理。
緩解訓練相關幻覺
為了解決與預訓練相關的幻覺,大多數研究強調探索新的模型架構和改進預訓練目標。
緩解預訓練相關幻覺
緩解有缺陷的模型結構:減輕預訓練相關幻覺的一個重要研究途徑集中在模型架構固有的局限性上,特別是單向表示和注意故障。鑒于此,許多研究已經深入到設計新穎的模型架構,專門針對這些缺陷進行改進。
緩解單向表示:引入采用雙向自回歸方法的BATGPT。這種設計允許模型基于以前看到的所有標記來預測下一個標記,同時考慮過去和未來的上下文,從而捕獲兩個方向上的依賴關系。
減輕注意力故障:利用注意銳化正則化器。這種即插即用的方法使用可微損失項來簡化自關注架構,以促進稀疏性,從而顯著減少推理幻覺。
緩解次優預訓練目標:傳統目標可能導致模型輸出中的碎片化表示和不一致。最近的進展試圖通過改進預訓練策略,確保更豐富的上下文理解和規避偏見來解決這些挑戰。本節闡明了這些開創性的方法,包括新的訓練目標和消除曝光偏差方法。
訓練目標:由于GPU內存約束和計算效率,文檔級別的非結構化事實知識經常被分塊,導致信息碎片化和不正確的實體關聯,引入了一種事實增強的訓練方法。通過給事實文檔中的每個句子附加一個TOPICPREFIX,該方法將它們轉換為獨立的事實,顯著減少了事實錯誤,增強了模型對事實關聯的理解。
曝光偏差:曝光偏差引起的幻覺與錯誤積累有著復雜的聯系。在置換多任務學習框架中引入了中間序列作為監督信號,以減輕NMT領域移位場景中的虛假相關性。此外,通過采用最小貝葉斯風險解碼也可以進一步減少與曝光偏差相關的幻覺。
緩解未對齊引起的幻覺
為了解決這個問題,一個直接的策略是改進人類的偏好判斷,進而改進偏好模型。研究LLM的使用,以幫助人類標記者識別被忽視的缺陷。此外,匯總多種人類偏好可以提高反饋質量,從而減少諂媚。對LLM內部激活的修改也顯示出改變模型行為的潛力。這可以通過微調或推理期間的激活轉向。具體來說,使用綜合數據對語言模型進行微調,其中主張的基本事實獨立于用戶的意見,旨在減少阿諛奉承的傾向。另一種研究方法是通過激活導向來減輕阿諛奉承。這種方法包括使用成對的阿諛/非阿諛提示來生成阿諛導向矢量,該矢量來自對中間激活的差異進行平均。
緩解推理相關幻覺
事實增強解碼
通過強調事實的準確性,該策略旨在生成嚴格遵循真實世界信息的輸出,并抵制產生誤導性或虛假的陳述。
獨立解碼:考慮到采樣過程中的隨機性會將非事實內容引入開放式文本生成,引入了事實核采樣算法,該算法在整個句子生成過程中動態調整"核心"。該解碼策略根據衰減因子和下界動態調整核概率,并在每個新句子開始時重新設置核概率,從而在生成事實內容和保持輸出多樣性之間取得平衡。此外,一些研究假設LLM的激活空間包含與事實性相關的可解釋結構。在這個想法的基礎上,引入了推理-時間干預(ITI)。該方法首先在與事實正確語句相關的激活空間中確定一個方向,然后在推理過程中沿著真值相關的方向調整激活。通過反復應用這種干預,LLM可以被引導到產生更真實的反應。
后編輯解碼:與直接修改概率分布以防止初始解碼期間出現幻覺的方法不同,后編輯解碼尋求利用LLM的自校正能力來完善最初生成的內容,而不依賴外部知識庫。一些方法使用驗證鏈(COVE),該驗證鏈的運行假設是,在適當的提示下,LLM可以自糾正其錯誤并提供更準確的事實。它首先制定驗證問題,然后系統地回答這些問題,以便最終產生改進的修訂回答。
忠實度增強編碼
忠實度增強解碼優先考慮與用戶指令或提供的上下文保持一致,并強調增強生成內容的一致性。將現有工作總結為兩類,包括上下文一致性和邏輯一致性。
上下文一致:由于對上下文關注不足而產生的幻覺問題仍然存在。研究人員提出了上下文感知解碼(CAD),通過減少對先驗知識的依賴來修改輸出分布,從而促進模型對上下文信息的關注。然而,由于多樣性和歸因之間的內在權衡,過度強調上下文信息會降低多樣性。因此引入了一種創新的采樣算法,以在保持多樣性的同時支持歸因。該方法包括兩個并行解碼,一個考慮源,另一個不考慮源,并根據token分布之間的KL散度動態調整溫度以反映源屬性。還有方法探索了一個更通用的后期編輯框架,以減輕推理過程中的忠實度幻覺。該方法首先在句子和實體級別檢測幻覺,然后利用這種檢測反饋來完善生成的響應。一些方法提出了知識約束解碼(KCD),采用token級幻覺檢測來識別幻覺,并通過對未來基于知識的更好估計重新權衡token分布來指導生成過程。
邏輯一致:為了增強思維鏈提示的內在自一致性,可采用知識蒸餾框架。首先使用對比解碼生成一致的理由,然后用反事實推理的目標對學生模型進行微調,這有效地消除了推理捷徑,這些捷徑在不考慮理由的情況下推導出答案。此外,通過采用對比解碼,可以減少表面級復制并防止遺漏推理步驟。
挑戰和開放問題
挑戰
雖然在緩解LLM幻覺方面取得了重大進展,但仍存在值得注意的挑戰。本節主要介紹它們在長文本生成、檢索增強生成和大視覺-語言模型等領域的表現。
長文本生成的幻覺
隨著生成內容長度的增加,幻覺的傾向也會增加,導致評估這種幻覺的成為挑戰。首先,現有的LLM幻覺基準通常以事實問答的形式呈現,更關注事實幻覺。在長文本生成領域,明顯缺乏人工標注的幻覺基準,這阻礙了研究人員在此背景下研究特定類型的幻覺。其次,評估長文本生成中的幻覺具有挑戰性。雖然有一些可用的評估指標,但它們有局限性,當事實更微妙、開放式和有爭議時,或當知識源中存在沖突時,并不適用。
檢索增強生成的幻覺
檢索增強生成(RAG)已成為一種有希望減輕LLM中的幻覺的策略。隨著人們對LLM幻覺的擔憂加劇,RAG越來越受到關注,為一系列商業應用鋪平了道路,如Perplexity2, YOU.com 3和New Bing 4。RAG通過從外部知識庫中檢索證據,使LLM具備最新的知識,并根據相關證據生成響應。然而,RAG也有幻覺。一個值得注意的問題是RAG管道內潛在的誤差累積。不相關的證據可能會傳播到生成階段,可能會污染輸出。另一個問題在于生成檢索領域,它偶爾會遭受引用不準確的問題。雖然引用的目的是為驗證目的提供一條可追蹤的信息來源的路徑,但這個領域的錯誤可能會導致用戶誤入歧途。此外,現有的RAG可能會在多樣性和事實性之間進行權衡,這就對多樣性的需求提出了新的挑戰。
大視覺-語言模型的幻覺
由于具備了視覺感知能力,以及出色的語言理解和生成能力,大視覺-語言模型(LVLM)表現出了非凡的視覺-語言能力。與之前從大規模視覺語言預訓練數據集獲得有限視覺語言能力的預訓練多模態模型不同,LVLM利用先進的大語言模型來更好地與人類和環境交互。因此,LVLM的多樣化應用也為維護此類系統的可靠性帶來了新的挑戰,需要進一步研究和緩解。評估和實驗表明,當前的LVLM容易對相關圖像產生不一致的響應,包括不存在的對象、錯誤的對象屬性、錯誤的語義關系等。此外,由于過度依賴強語言先驗,LVLM很容易被愚弄,并經歷嚴重的性能下降,以及其抵御不適當用戶輸入的能力較差。人們正在努力建立一個更魯棒的大視覺-語言模型。當呈現多個圖像時,LVLM有時會混淆或遺漏部分視覺上下文,以及無法理解它們之間的時間或邏輯聯系,這可能會阻礙它們在許多場景中的使用,正確識別此類障礙的原因并解決它們仍然需要持續的努力。
LLM幻覺的開放問題
隨著LLM幻覺研究的進展,其自我糾正機制在減少幻覺方面的有效性,其內部對知識邊界的理解,以及他們的創造力和真實性之間的平衡等問題需要進一步探討。
自校正機制能幫助減輕推理幻覺嗎?
雖然LLM在通過思維鏈提示處理復雜推理任務方面表現出了非凡的能力,但它們偶爾會表現出不忠實的推理,其特征是推理步驟或結論在邏輯上不遵循推理鏈研究表明,將外部反饋集成到LLM中。這種反饋通常通過檢索過程來自外部知識源,與其他LLM進行互動或來自外部評估指標的指導。這探索了自校正機制的潛力,其中LLM使用其內置能力校正其初始響應,而不依賴外部反饋。盡管自校正已顯示出實現忠實和準確推理的能力,但某些研究對自矯正機制的有效性提出質疑,指出LLM仍然難以自校正其推理鏈。因此,該機制的有效性仍然是一個開放問題,值得進一步探索。
是否能準確計算知識邊界?
盡管從廣泛的數據中捕獲事實知識的能力令人印象深刻,但LMM在識別自己的知識邊界方面仍然面臨挑戰。這種不足導致幻覺的發生,在這種情況下,LMM自信地制造謊言,而沒有意識到自己的知識限制。許多研究都深入探索了LMM的知識邊界,利用了一些策略,如評估多項選擇題中正確答案的概率,或通過評估具有不確定含義的句子集之間的相似性來量化模型的輸出不確定性。此外,還有工作揭示了LLM在其激活空間中包含與真實性信念相關的潛在結構。最近的研究也發現了大量證據,表明LLM有能力對問題的不可回答性進行編碼,盡管這些模型在面對不可回答的問題時表現出過度自信并產生幻覺。因此,我們是否可以有效地探索LLM的內部信念正在進行中,需要進一步的研究。
如何在創造性和真實性之間取得平衡?
在LLM發展過程中,平衡創造力和事實性的挑戰是一個重要的問題。確保真實性對于用于現實世界應用的LLM至關重要;任何不準確的信息都會誤導用戶,污染網絡環境。相反,幻覺有時可以提供有價值的視角,特別是在創造性的努力中,如講故事、頭腦風暴和產生超越傳統思維的解決方案。雖然目前對LLM的研究嚴重傾向于減少幻覺,但往往忽視了其創造力的重要作用。其創造力和事實準確性之間取得平衡的挑戰仍然沒有解決。探索多模態文本生成任務中的平衡也是有趣的,也適用于視覺生成任務。這個問題超越了單純的技術問題,需要對人工智能的本質及其對人類互動和知識交流的影響進行更廣泛的思考。
總結
這篇綜述對大型語言模型中的幻覺進行了深入研究,深入研究了其根本原因、檢測方法以及相關基準和有效的緩解策略。盡管已經取得了重大進展,但大型語言模型中的幻覺問題仍然是一個令人信服和持續的問題,需要繼續進行研究。
原文標題:LLM的幻覺問題最新綜述
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238247 -
渦輪增壓
+關注
關注
1文章
79瀏覽量
5336 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:LLM的幻覺問題最新綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
對比解碼在LLM上的應用
TaD+RAG-緩解大模型“幻覺”的組合新療法
基于Transformer的大型語言模型(LLM)的內部機制

最新綜述!當大型語言模型(LLM)遇上知識圖譜:兩大技術優勢互補

最新研究綜述——探索基礎模型中的“幻覺”現象
幻覺降低30%!首個多模態大模型幻覺修正工作Woodpecker

LLM推理加速新范式!推測解碼(Speculative Decoding)最新綜述
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)

自然語言處理應用LLM推理優化綜述






 工商網監
工商網監
評論