

想象一下,你正在機場和朋友通電話。你周圍有很多人在交談,飛機在起飛/降落,數十個行李箱的滾輪滾過瓷磚地板,可能還有幾個嬰兒在哭鬧。而電話那頭的朋友,在一家熱鬧的餐廳。你的朋友需要應對自己的環境噪音:餐具和盤子叮當作響,食客們聊得起勁,餐廳播放著背景音樂,可能還有一些嬰兒在哭鬧。而在電話的兩端,你們聽到的都是平靜而清晰的話語,而不是含混不清的聲音。
這都得益于噪音抑制和主動降噪 (ANC)。這兩項功能近來在音頻產品中很常見,但它們不僅是流行詞而已。這兩項技術有助于以不同的重要方式減輕噪音的影響。本文將解釋二者的區別,同時更深入地探討其中的噪音抑制技術。
噪音抑制
來看看上述情景的第一部分:你在嘈雜的環境中對著麥克風講話。
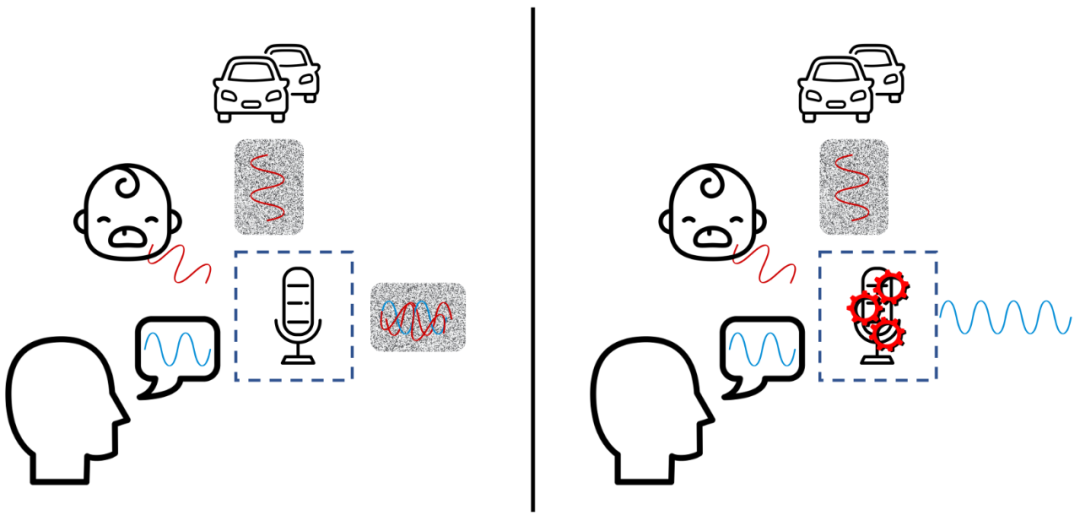
在此示例中,汽車在發出持續的背景噪音。這就是所謂的穩態噪聲,它會呈現我們關注的語音信號里面并不存在的周期性特性。空調、飛機、汽車發動機和風扇的聲音都是穩態噪聲的例子。但是,嬰兒的哭聲并不是持續的,這種聲音有一個很恰當的名字:非穩態噪聲。這類噪聲的其他示例包括哈士奇的吠叫、電鉆或錘子工作的聲音、敲擊鍵盤的咔嗒聲或餐廳中銀制餐具碰撞的叮當聲。這些噪音發生得很突然,同時存在的時間很短暫。
麥克風會捕捉這兩種類型的噪音;在不做任何處理的情況下,會產生同樣嘈雜的輸出,蓋過你期望傳遞的語音信息。圖的左半部分顯示了這種情況。但是,通過噪音抑制處理,可以消除背景噪音以便傳輸(而且僅傳輸)你的聲音。
主動降噪
現在,你清晰的聲音已經通過無線電傳輸給你的朋友,但這不代表對方就能清晰的接收你的信息。這時就需要主動降噪。
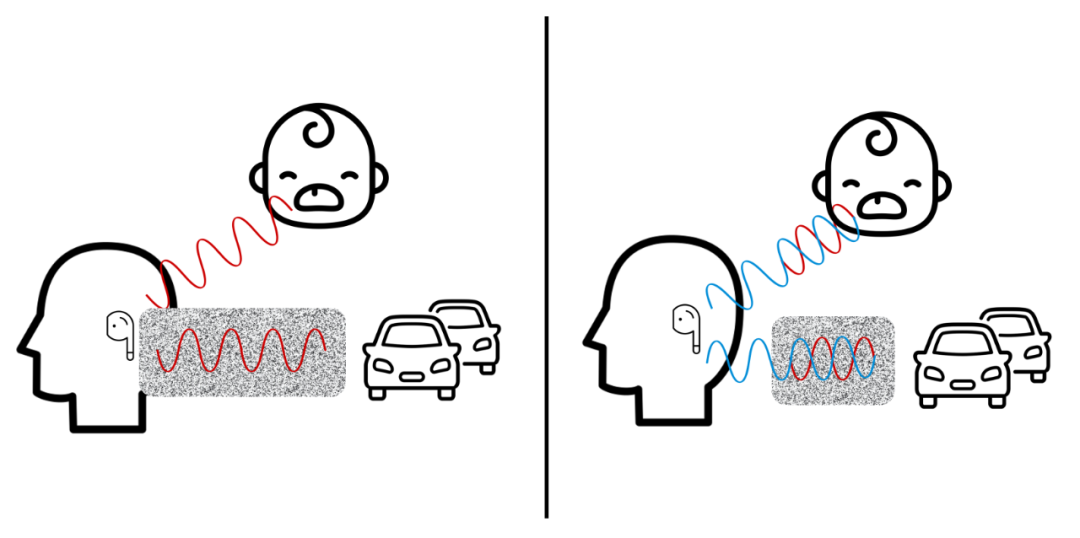
像之前一樣,有穩態和非穩態噪聲會影響傳入耳塞的聲音。與之前處理掉噪音的情況不同,主動降噪的目標是完全抵消外部噪音。麥克風捕捉傳入的聲音,生成外部噪音的反向信號,并通過將反向信號疊加到入耳的聲波中盡可能的抵消外部噪聲。概括性地說,這在概念上類似于將 +5 和 -5 這兩個數字相加得到 0。
在硬件中,基于上述的這種基本原則,可以通過兩種主要方式應用主動降噪。一種是前饋式 ANC,即在可聽設備外使用麥克風;另一種是反饋式 ANC,即在更靠近耳朵的可聽設備內使用麥克風。
前饋式 ANC 位于耳朵以外,所以對噪音更敏感。它可以在噪音傳向可聽設備時清晰地捕捉到噪音。然后,它可以處理該噪音并輸出其相位抵消信號。這使其能夠隔離特定的聲音,尤其是中頻聲音。這包括我們在本帖前面部分提到的穩態聲音,但也包括語音。但是,前饋式 ANC 位于設備外部,因此更容易受到外部噪音的影響,例如風聲或耳塞在兜帽內側不斷摩擦的聲音(這絕對不是經驗之談)。
反饋式 ANC 不受亂動的兜帽影響,因為它在可聽設備內部,能抵抗其他各類偶然干擾。這種隔音效果很好,但成功傳入耳塞的較高頻聲音則較難抵消。同樣,內部反饋麥克風需要區分播放的音樂和噪音。而且,因為其反饋更靠近耳朵,它還需要更快地處理此信息,才能保持與前饋設置相同的延遲。
最后,還有混合主動降噪 - 你猜對了,這種方法就是結合前饋和反饋式 ANC,以功耗和硬件為代價,實現兩方面的最佳效果。
深入了解噪音抑制
了解噪音抑制(抑制說話人環境噪音以便遠端聽話人聽清)與主動降噪(抵消聽話人自身的環境噪音)的基本區別后,讓我們重點關注如何實現噪音抑制。
一種方法是使用多個麥克風抑制數據。從多個位置收集數據,設備會獲得相似(但仍有區別)的信號。靠近說話人口部的麥克風接收到的語音信號明顯比次要麥克風強。兩個麥克風會接收到相近信號強度的非語音背景音。將較強語音麥克風和次要麥克風收集到的聲音信息相減,剩下的大部分就是語音信息。麥克風之間的距離越大,較近和較遠的麥克風之間的信號差就越大,也就越容易使用這種簡單算法抑制噪音。但是,當你不說話時,或預期語音數據隨時間變化時(例如當你走路或跑步,手機不斷搖晃時),此方法的效果會下降。多麥克風噪音抑制當然是可靠的,但額外的硬件和處理存在缺點。
那么,如果只有一個麥克風,又會怎么樣呢?如果不使用額外聲源進行驗證/比較,單麥克風解決方案將依賴于理解接收到的噪音特性并將其濾除。這又與此前提到的穩態和非穩態噪聲定義有關。穩態噪聲可以通過 DSP 算法有效濾除,非穩態噪聲帶來了一個挑戰,但深度神經網絡 (DNN) 可以幫助解決問題。
此方法需要一個用于訓練網絡的數據集。該數據集由不同的(穩態和非穩態)噪聲以及清晰的語音組成,創造出合成的嘈雜語音模式。將該數據集作為輸入饋送給 DNN,并以清晰的語音作為輸出。這將創建一個神經網絡模型,它會消除噪音,僅輸出清晰的語音。
即使使用經訓練的 DNN,仍有一些挑戰和指標需要考慮。如果要以低延遲實時運行,就需要很強的處理能力或較小的 DNN。DNN 中的參數越多,其運行速度越慢。音頻采樣率對聲音抑制有類似的影響。較高的采樣率意味著 DNN 需要處理更多參數,但連帶地會獲得更優質的輸出。為實現實時噪音抑制,窄帶語音通信是理想之選。
這種處理全部都是密集型任務,云計算非常擅長完成這類任務,但這種方法會顯著增加延遲。考慮到人類可以可靠地分辨大約 108 毫秒以上的延遲,云計算處理帶來的延額外遲顯然不是理想的結果。但是,在邊緣運行 DNN 需要進行一些巧妙的調整。CEVA 始終致力于完善我們的聲音和語音處理能力。這包括經過實際驗證的語音清晰度和命令識別算法 - 通過這些算法,即使在邊緣也能提供明確的通信和語音控制。歡迎聯系我們,親自聆聽。
文章來源:CEVA
審核編輯 黃宇
-
ANC
+關注
關注
0文章
48瀏覽量
19044 -
主動降噪
+關注
關注
10文章
52瀏覽量
19009 -
噪音抑制
+關注
關注
0文章
9瀏覽量
1754
發布評論請先 登錄





 工商網監
工商網監

評論