 數據庫orderby 和groupby用法
數據庫orderby 和groupby用法
數據庫是指將數據按照一定規則組織并存儲起來,以實現高效的數據管理和訪問。在使用數據庫時,我們經常需要對數據進行排序和分組。數據庫中的ORDER BY和GROUP BY是兩個常用的關鍵詞,可以幫助我們實現對數據的排序和分組操作。本文將詳細介紹ORDER BY和GROUP BY的用法及其原理。
一、ORDER BY的用法及原理
- 語法:
SELECT 列名 FROM 表名 ORDER BY 列名 [ASC | DESC];
其中,列名表示我們希望按照哪一列進行排序,ASC表示升序排列,DESC表示降序排列。
- 功能:
ORDER BY關鍵詞用于對查詢結果進行排序操作。通過ORDER BY可以實現對一個或多個列進行排序,按照特定的順序展示查詢結果。通常情況下,ORDER BY關鍵詞緊跟在SELECT語句的最后。
- 實例:
假設我們有一個學生表student,包含字段id、name、score,我們想要按學生成績降序排列,可以使用以下SQL語句:
SELECT * FROM student ORDER BY score DESC;
該語句將會按照學生成績的降序排列展示查詢結果。
- 原理:
在排序的過程中,數據庫通過遍歷要排序的列,將每一行數據與其他行的數據進行比較,然后按照比較結果進行排序。對于較小的數據集,數據庫可能會使用快速排序算法進行排序;對于較大的數據集,數據庫可能會使用外部排序算法進行排序。
二、GROUP BY的用法及原理
- 語法:
SELECT 列名 FROM 表名 GROUP BY 列名;
其中,列名表示我們希望按照哪一列進行分組操作。
- 功能:
GROUP BY關鍵詞用于對查詢結果進行分組操作。通過GROUP BY可以將具有相同值的行歸為一組,并針對每個組進行匯總計算或過濾操作。
- 實例:
仍假設我們有一個學生表student,包含字段id、name、score,我們想要按學生分數分組統計平均分數,可以使用以下SQL語句:
SELECT name, AVG(score) FROM student GROUP BY name;
該語句將會按照學生姓名進行分組,并計算每個分組(即每個學生)的平均分數。
- 原理:
在分組的過程中,數據庫先按照GROUP BY子句指定的列進行分組,將具有相同值的行歸為一組。然后,對于每個分組,數據庫會進行聚合操作,如計算平均值(AVG)、求和(SUM)、統計數量(COUNT)等。最后,將每個分組的聚合結果返回。
三、ORDER BY和GROUP BY的關系
在實際應用中,ORDER BY和GROUP BY經常同時使用,以實現更精確的數據排序和分組。在這種情況下,ORDER BY通常會位于GROUP BY之后,用于對分組結果進行排序。例如:
SELECT name, AVG(score) FROM student GROUP BY name ORDER BY AVG(score) DESC;
該語句會首先按照學生姓名進行分組,并計算每個分組(每個學生)的平均分數,然后按照平均分數降序排列結果。
綜上所述,ORDER BY和GROUP BY是數據庫中常用的關鍵詞,用于實現對數據的排序和分組操作。ORDER BY用于對查詢結果進行排序,而GROUP BY用于對查詢結果進行分組。兩者可以組合使用,以實現更準確的數據處理。了解和掌握ORDER BY和GROUP BY的用法和原理對于數據庫的使用非常重要。
-
存儲
+關注
關注
13文章
4320瀏覽量
85897 -
數據庫
+關注
關注
7文章
3816瀏覽量
64448
發布評論請先 登錄
相關推薦
數據庫使用教程下載
什么是支持數據庫,什么是中宏數據庫
數據庫,數據庫是什么意思
數據庫教程之如何進行數據庫設計
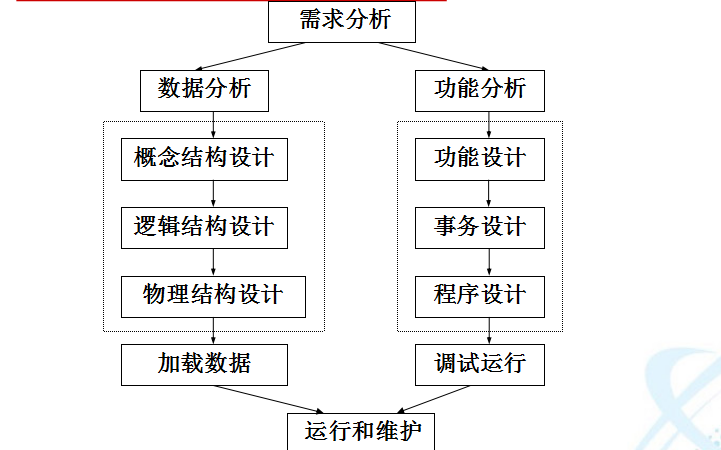
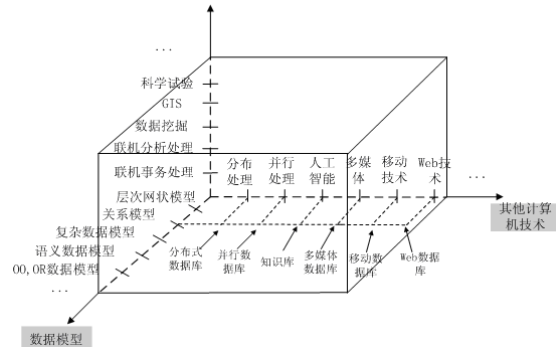
數據庫學習教程之數據庫的發展狀況如何數據庫有什么新發展
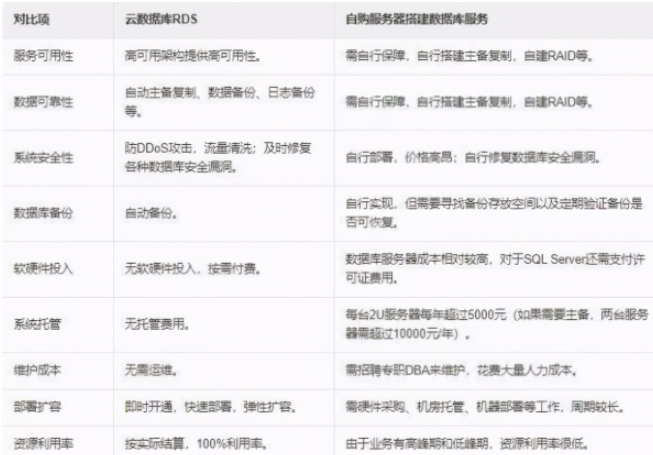
云數據庫和自建數據庫的區別及應用
ACS數據庫與RSC數據庫比較研究

華為云數據庫-RDS for MySQL數據庫
云數據庫和普通數據庫區別?|PetaExpress云端數據庫
python讀取數據庫數據 python查詢數據庫 python數據庫連接
數據庫應用及其特點 數據庫數據的基本特點
數據庫select語句的基本用法

數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫






 工商網監
工商網監
評論