 用語言對齊多模態信息,北大騰訊等提出LanguageBind,刷新多個榜單
用語言對齊多模態信息,北大騰訊等提出LanguageBind,刷新多個榜單
在博士畢業就有10篇ACL一作的師兄指導下是種什么體驗
北京大學與騰訊等機構的研究者們提出了多模態對齊框架 ——LanguageBind。該框架在視頻、音頻、文本、深度圖和熱圖像等五種不同模態的下游任務中取得了卓越的性能,刷榜多項評估榜單,這標志著多模態學習領域向著「大一統」理念邁進了重要一步。
在現代社會,信息傳遞和交流不再局限于單一模態。我們生活在一個多模態的世界里,聲音、視頻、文字和深度圖等模態信息相互交織,共同構成了我們豐富的感知體驗。這種多模態的信息交互不僅存在于人類社會的溝通中,同樣也是機器理解世界所必須面對的挑戰。
如何讓機器像人類一樣理解和處理這種多模態的數據,成為了人工智能領域研究的前沿問題。
在過去的十年里,隨著互聯網和智能設備的普及,視頻內容的數量呈爆炸式增長。視頻平臺如 YouTube、TikTok 和 Bilibili 等匯聚了億萬用戶上傳和分享的視頻內容,涵蓋了娛樂、教育、新聞報道、個人日志等各個方面。如此龐大的視頻數據量為人類提供了前所未有的信息和知識。為了解決這些視頻理解任務,人們采用了視頻 - 語言(VL)預訓練方法,將計算機視覺和自然語言處理結合起來,這些模型能夠捕捉視頻語義并解決下游任務。
然而,目前的 VL 預訓練方法通常僅適用于視覺和語言模態,而現實世界中的應用場景往往包含更多的模態信息,如深度圖、熱圖像等。如何整合和分析不同模態的信息,并且能夠在多個模態之間建立準確的語義對應關系,成為了多模態領域的一個新的挑戰。
為了應對這一難題,北大與騰訊的研究人員提出了一種新穎的多模態對齊框架 ——LanguageBind。與以往依賴圖像作為主導模態的方法不同,LanguageBind 采用語言作為多模態信息對齊的紐帶。

論文地址:https://arxiv.org/pdf/2310.01852.pdf
GitHub 地址:https://github.com/PKU-YuanGroup/LanguageBind
Huggingface 地址:https://huggingface.co/LanguageBind
語言因其內在的語義豐富性和表現力,被賦予了整合和引導其他模態信息對齊的能力。在這個框架下,語言不再是附屬于視覺信息的標注或說明,而是成為了聯合視覺、音頻和其他模態的中心通道。
LanguageBind 通過將所有模態的信息映射到一個統一的語言導向的嵌入空間,實現了不同模態之間的語義對齊。這種對齊方法避免了通過圖像中介可能引入的信息損失,提高了多模態信息處理的準確性和效率。更重要的是,這種方法為未來的擴展提供了靈活性,允許簡單地添加新的模態,而無需重新設計整個系統。
此外,該研究團隊構建了 VIDAL-10M 數據集,這是一個大規模、包含多模態數據對的數據集。
VIDAL-10M 涵蓋了視頻 - 語言、紅外 - 語言、深度 - 語言和音頻 - 語言配對,以確保跨模態的信息是完整且一致的。通過在該數據集上進行訓練,LanguageBind 在視頻、音頻、深度和紅外等 15 個廣泛的基準測試中取得了卓越的性能表現。
方法介紹
在多模態信息處理領域,主流的對齊技術,如 ImageBind,主要依賴圖像作為橋梁來實現不同模態之間的間接對齊。這種方法在對其他模態和語言模態的對齊上可能會導致性能次優化,因為它需要兩步轉換過程 —— 首先是從目標模態到圖像模態,然后是從圖像模態到語言模態。這種間接對齊可能導致語義信息在轉換過程中的衰減,從而影響最終的性能表現。
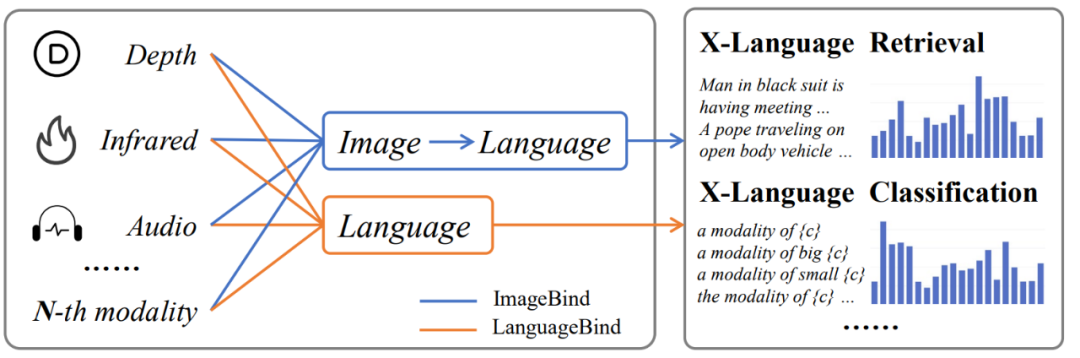
針對這一問題,該團隊提出了一種名為 LanguageBind 的多模態語義對齊預訓練框架。該框架摒棄了依賴圖像作為中介的傳統模式,而是直接利用語言模態作為不同模態之間的紐帶。語言模態因其天然的語義豐富性,成為連接視覺、音頻、深度等模態的理想選擇。LanguageBind 框架通過利用對比學習機制,將不同模態的數據映射到一個共享的語義嵌入空間中。在這個空間里,不同模態的信息可以直接進行語義層面的理解與對齊。
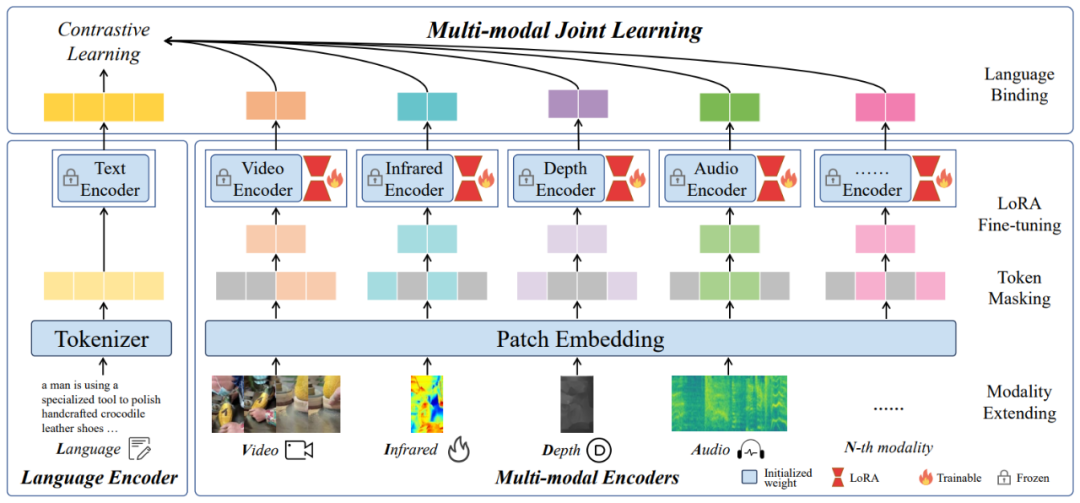
LanguageBind 概覽圖
具體而言,LanguageBind 通過錨定語言模態,采用一系列優化的對比學習策略,對多模態數據進行預訓練。這一過程中,模型學習將來自不同模態的數據編碼到與語言模態相兼容的表征中,確保了模態間的語義一致性。這種直接的跨模態語義對齊避免了傳統方法中的性能損失,同時提高了模型在下游多模態任務中的泛化能力和適用性。
LanguageBind 框架的另一個優點是其擴展性。由于直接使用語言作為核心對齊模態,當引入新的模態時,無需重構整個對齊機制,只需通過相同的對比學習過程,將新模態的數據映射到已經建立的語言導向嵌入空間。這使得 LanguageBind 不僅適用于現有的模態,也能輕松適應未來可能出現的新模態,為多模態預訓練技術的發展奠定了堅實基礎。
數據集介紹
在跨模態預訓練領域,數據集的構建及其質量對于預訓練模型的性能與應用效能具有決定性影響。傳統的多模態數據集大多局限于二模態或三模態的配對數據,這種限制導致了對更豐富模態對齊數據集的需求。
因而,該團隊開發了 VIDAL-10M 數據集,這是一個創新的五模態數據集,包含了視頻 - 語言(VL)、紅外 - 語言(IL)、深度 - 語言(DL)、音頻 - 語言(AL)等數據對。每個數據對都經過了精心的質量篩選,旨在為跨模態預訓練領域提供一個高品質、高完整性的訓練基礎。

VIDAL-10M 數據集示例
VIDAL-10M 數據集的構建主要包括三步:
視覺相關搜索詞庫構建。設計一種創新的搜索詞獲取策略,該策略綜合利用了各類視覺任務數據集中的文本信息,如標簽和標題,以構建一個豐富視覺概念且多樣化的視頻數據集,從而增強了數據多樣性和覆蓋度。
視頻和音頻數據的收集、清洗與篩選:在數據的收集過程中,該研究采取了基于文本、視覺和音頻內容的多種過濾機制,這些機制確保收集到的視頻和音頻數據與搜索詞高度相關,并且滿足高標準的質量要求。這一步驟是確保數據集質量的關鍵環節,它直接影響模型訓練的效果和后續任務的性能。
紅外、深度模態數據生成與多視角文本增強。此階段,利用多種先進的生成模型技術合成了紅外和深度模態數據,并對文本內容進行了多角度的生成和增強。多視角文本增強包括了標題、標簽、關鍵幀描述、視頻概要等多個維度,它為視頻內容提供了全面且細致的描述,增強了數據的語義豐富性和描述的細粒度。

VIDAL-10M 數據集的構建過程
實驗
LanguageBind 框架被應用于多個模態的零樣本分類任務,并與其他模型進行了性能比較。實驗結果顯示,LanguageBind 方法在包括視頻、音頻、深度圖像、熱成像等多模態數據上的 15 個零樣本分類與檢索任務中均展示了顯著的性能提升。這些實驗成果強調了 LanguageBind 方法在理解和處理不同模態數據中的潛在能力,尤其是在沒有先前樣本可供學習的情況下。為了更深入地了解 LanguageBind 方法的性能,可以參照以下詳細的實驗結果。
表 2 顯示,LanguageBind 的性能在 MSR-VTT 上超過 VideoCoca 和 OmniVL ,盡管僅使用 300 萬個視頻 - 文本對。
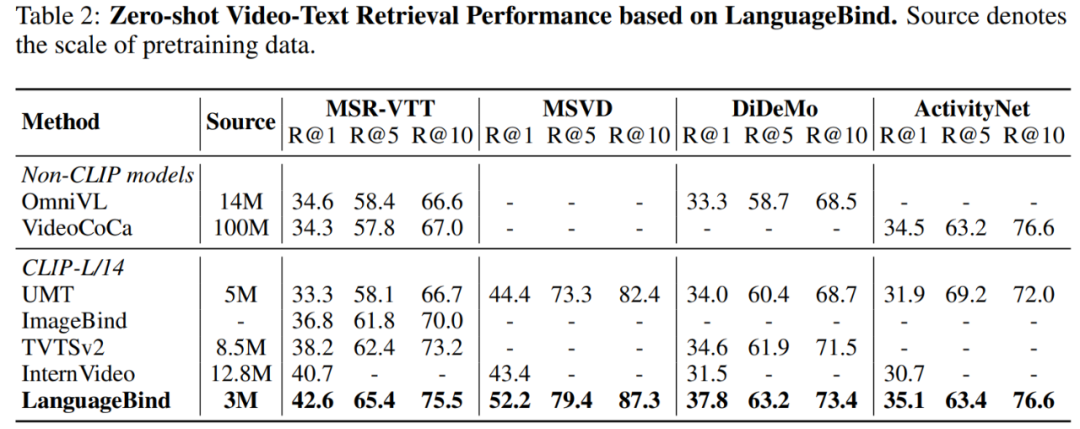
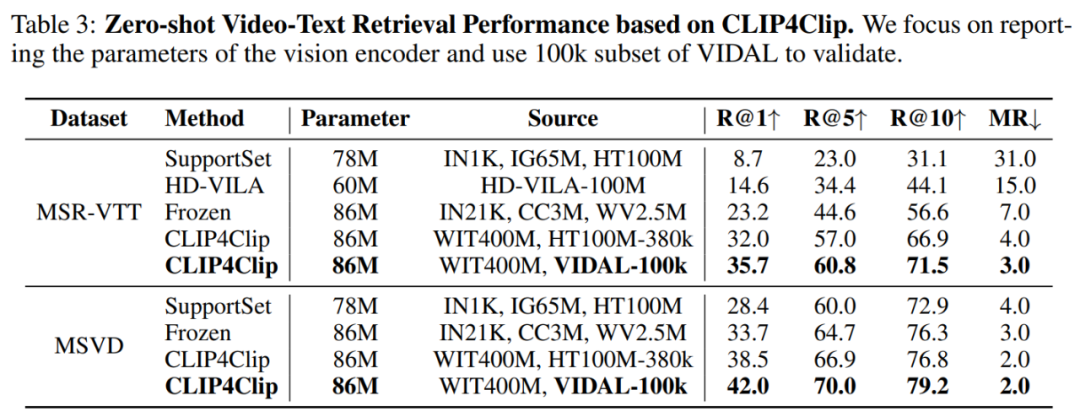
在兩個經典數據集 MSR-VTT 和 MSVD 上進行的零樣本視頻 - 文本檢索實驗結果如表 3 所示:
該研究還將本文模型與 SOTA 多模態預訓練模型 OpenCLIP、ImageBind 在多模態理解任務上進行了比較,結果如表 4 所示:
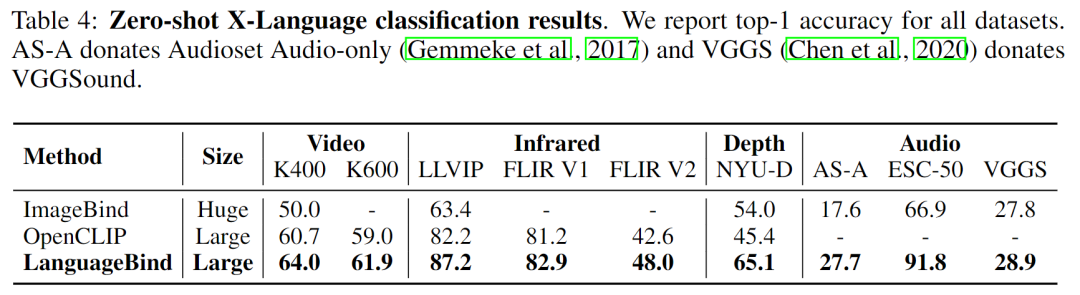
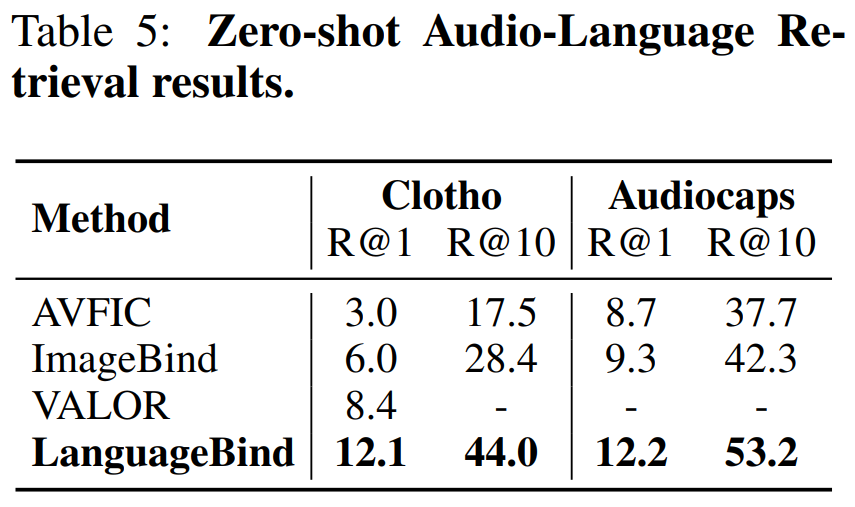
表 5 比較了在 Clotho 數據集和 Audiocaps 數據集上的零樣本文本 - 音頻檢索性能:
-
圖像
+關注
關注
2文章
1091瀏覽量
40669 -
模型
+關注
關注
1文章
3406瀏覽量
49457 -
智能設備
+關注
關注
5文章
1076瀏覽量
50984 -
數據集
+關注
關注
4文章
1212瀏覽量
24964
原文標題:用語言對齊多模態信息,北大騰訊等提出LanguageBind,刷新多個榜單
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦


胡瀚接棒騰訊多模態大模型研發
商湯日日新多模態大模型權威評測第一
一文理解多模態大語言模型——下

一文理解多模態大語言模型——上

利用OpenVINO部署Qwen2多模態模型
云知聲山海多模態大模型UniGPT-mMed登頂MMMU測評榜首

Meta發布多模態LLAMA 3.2人工智能模型
云知聲推出山海多模態大模型
智譜AI發布全新多模態開源模型GLM-4-9B
智譜AI領跑司南OpenCompass 2.0月度榜單,GLM-4展示強大實力
李未可科技正式推出WAKE-AI多模態AI大模型






 工商網監
工商網監
評論