 C語言在單片機中是如何執行的
C語言在單片機中是如何執行的
或許我們平時大多數學習C語言都是在Windows環境下學習的,對于程序執行的底層邏輯了解的不是非常清楚,所以本文在這里給大家介紹一下,C語言在單片機中是如何執行的。
Part1CPU與外設
我們知道,單片機也是有CPU的,它負責執行代碼,運算數據,以及發出控制信號等功能,而與CPU直接相連的設備我們稱之為外設(就是集成芯片)。
本文以STM32F103ZET6為例來講解,該芯片使用的是ARM架構,該架構采用的是哈弗結構。
- 哈弗結構:內存和外設統一編址。
ARM芯片屬于精簡指令集計算機(RISC:Reduced Instruction Set Computing),它所用的指令比較簡單,有如下特點:
- 對內存只有讀、寫指令;
- 對于數據的運算是在CPU內部實現;
- 使用RISC指令的CPU復雜度小一點,易于設計。
比如對于a=a+b這樣的算式,需要經過下面4個步驟才可以實現:
 細看這幾個步驟,有些疑問,a的值讀出來后保存在CPU里面哪里?b的值讀出來后保存在CPU里面哪里?a+b的結果又保存在哪里?
細看這幾個步驟,有些疑問,a的值讀出來后保存在CPU里面哪里?b的值讀出來后保存在CPU里面哪里?a+b的結果又保存在哪里?
 如上圖所示,CPU也是由多個部分組成的,包括
如上圖所示,CPU也是由多個部分組成的,包括ALU邏輯運算單元,控制單元,以及多個寄存器等等。
假設變量a的地址是0x12,變量b的地址是0x34,第一步的匯編代碼LDR R0, [a]的意思就是將0x12地址中的值讀取到R0寄存器中,第二步讀取b變量同理。
- LDR + 第一操作數 + 第二操作數:就是將第二操作數的值賦第一操作數。
當變量a和變量b都被讀到了CPU的寄存器中后,執行第三步匯編代碼ADDR R0, R0, R1,意思是將R0和R1中的值相加,然后將結果保存到R0中。
- ADD:相加的匯編指令,可以有三個操作數也可以有兩個操作數,三個操作數則后兩個操作數相加,得的結構均保存到第一個操作數。
最后就是將R0中的計算結果再寫回到內存中,執行第四步匯編代碼STR R0,[a],意思是將R0中的值寫入到變量a的地址處0x12。
 如上圖所示,由于有32根地址線,所以CPU可訪問的地址范圍就是
如上圖所示,由于有32根地址線,所以CPU可訪問的地址范圍就是0x0000 0000 ~ 0xFFFF FFFF,就拿我們熟知的Flash和SRAM來說,它倆和CPU直接相連,所以也可以看成是外設。
- Flash:用來存放用戶燒錄的程序,掉電數據不丟失(硬件特性)。
- SRAM:用來存放程序執行過程中的臨時數據,掉電數據丟失。
Flash的地址范圍是0x0800 0000 ~ 0x0807 FFFF,SRAM的地址范圍是0x2000 0000 ~ 0x2000 FFFF,這是我們根據上面的圖才知道的。
但是對于CPU而言,它并不知道哪里是FLASH哪里是SRAM,它只是被動地在執行代碼。CPU在一上電以后就從0x0000 0000處開始執行代碼(可以進行設置,以后再講解),直到調用了我們C代碼中必須有的main函數,然后進入我們自己的邏輯當中。
1.1 Flash
 如上圖啟動文件所示,CPU會通過
如上圖啟動文件所示,CPU會通過BL匯編語句來調用main函數,但是在這之前,還會執行LDR匯編語句來給棧頂指針SP賦值。
- BL:跳轉指令,也就是讓程序跳轉到指定位置處執行,相當于函數調用。
我們知道,代碼最終會被轉換成機器碼讓CPU去執行,而存放這些機器碼也需要空間,所以代碼也是有地址的。
 如上圖所示,無論是調用
如上圖所示,無論是調用main函數之前的匯編代碼,還是main函數的代碼,它們的地址都是0x0800 0xxx,距離FLASH的起始地址0x0800 0000不是很遠,說明我們燒錄到單片機中的代碼就是存放在FLASH中的。
- 無論是
main中的代碼,還是前面的匯編代碼,只要是從FLASH起始處開始的,都屬于我們程序員寫的代碼。- 芯片廠家在
FLASH起始地址之前,固化了一些代碼,這個暫不作說明。
1.2 SRAM(內存)
1.2.1 棧
當main執行起來以后,運算數據得到的臨時結果或者中間數據就都會暫存到SRAM上,也就是我們平常所說的內存中。

如上圖所示,在使用BL調用main函數之前,還使用了LDR給棧頂指針SP賦了初值,紅色箭頭指向的位置就是棧頂指針指向的位置。
代碼中的局部變量,函數棧幀等等數據,全部都存放在SP開始往下的位置,因為 棧的開辟是從高地址向低地址 。

如上圖所示,在main函數中創建兩個變量a和b,加volatile的作用是防止編譯器將這兩個變量優化掉導致在這里無法演示現象。
main函數也是被調用的,所以在其內部創建的變量也屬于局部變量,局部變量就統統存放在棧上。
匯編代碼中,在創建變量a之前先執行了一句PUSH {r2-r3,lr}匯編語句,意思是將寄存器lr,寄存器r2和r3中的值壓入棧中。
lr:寄存器存放的是函數的返回地址,其實就是CPU中的r15寄存器。PUSH:執行壓棧操作,將數據壓入到棧中后,棧頂指針向下移動。
此時向棧中壓入了三個個數據,每個數據都是4字節的,所以SP向下移動了12個字節,這12個字節就可以看作當前main函數的棧幀大小。
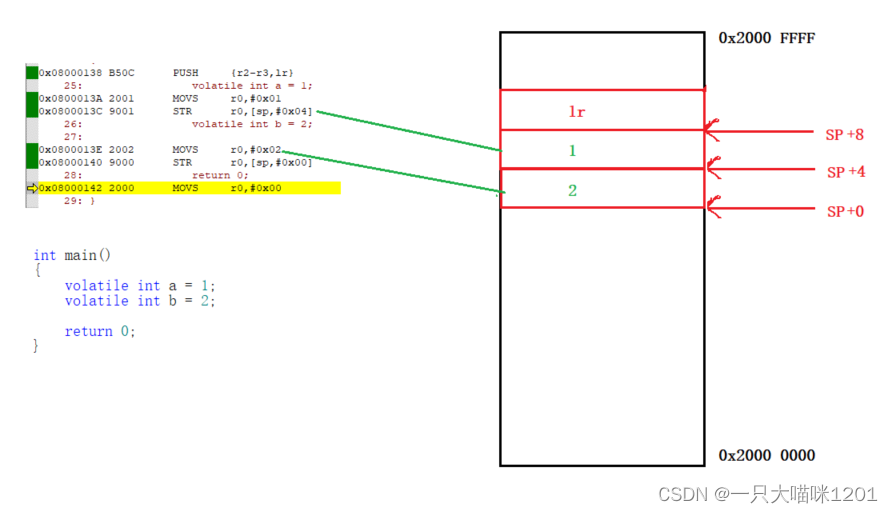
如上圖,當執行到給變量a賦值1時,執行了匯編代碼MOVS r0,#0x01,表示將數值1賦值給寄存器r0。然后再執行匯編代碼STR r0,[sp,#0x04],表示將寄存器r0中的值,寫入到sp + 0x04地址處。
- MOVS:將后一個操作數賦值給前一個操作數。
給變量b賦值2的時候,原理同上。所以此時在內存中就存在了1和2兩個值,分別存在于sp+4和sp+0的位置處,后面用到變量a和b的時候,也是通過棧頂指針sp來找這兩個值。
在這個過程中我們發現,寄存器r2和r3的的作用就是 占坑 ,現在棧中給變量a和b占兩個位置,等到STR賦值的時候將這兩個位置覆蓋即可。
那如果我創建100字節大小的數組呢?難道用100個寄存器來占坑嗎?顯然不可能,CPU一共也沒那么多寄存器。

如上圖所示,創建100字節大小的數組,先開辟100個字節大小的棧空間,執行匯編語句SUB sp,sp,#0x64,表示用當前的sp值減去0X64(100的16進制),將結果再賦值到sp中。
- SUB:用法和ADD相似,只是作用是后兩個操作數做減法,得到的結果賦值給第一個操作數。
此時在SRAM(內存)上就存在一個100字節大小的棧用來存放這個str數組,此時它不使用占坑的方式了,而是直接改變SP的值來改變棧區的大小。
1.2.2 數據段
 如上圖所示,創建兩個全局變量a和b,還有一個靜態變量c,在調試窗口中可以看到,變量a的地址是
如上圖所示,創建兩個全局變量a和b,還有一個靜態變量c,在調試窗口中可以看到,變量a的地址是0x20000 0000,變量b的地址是0x20000 0004,變量c的地址是0x2000 0008,這三個變量緊挨著。
- 在C語言學習中我們知道,全局變量和靜態變量是存放在數據段的。
- 先忽略為什么它們的初始值都是0這個問題。
在本文最前面放了一張內存地址映射圖,其中SRAM的地址范圍是0x2000 0000 ~ 0x20000 FFFF,也就是說內存的起始地址就是0x2000 0000,而變量a,b,c從起始位置開始存放,所以說這個位置就是數據段起始位置。

如上圖所示,當給變量a賦值時,先執行MOVS r0,#0x01,將數值1賦值給寄存器r0,然后執行LDR r1,[pc,#20]語句,表示從PC + 20的地址處讀取數據放入到寄存器r1中。
- PC:程序計數器,實際上就是CPU寄存器中的R15,它存放程序的地址,其值永遠是當前語句的下一條語句的地址。
- CPU會根據PC值去執行對應的指令。
PC + 20的值是0x0800 0016C,這是一個Flash處的地址,而該地址處的值是0x0000,由于LDR一次取四個字節的數據,所以要連0x0800 0016E處的值0x2000也要讀走,兩個值按照大端存儲模式復原(高地址存放高字節序),得到的值就是0x2000 0000。
所以此時寄存器r1中的值就是0x2000 0000,再執行STR r0,[r1,#0x00]匯編語句,將r0中的1寫入到0x20000 0000處,也就是數據段變量a的地址處,此時就成功改變了它的值。
1.2.3 堆
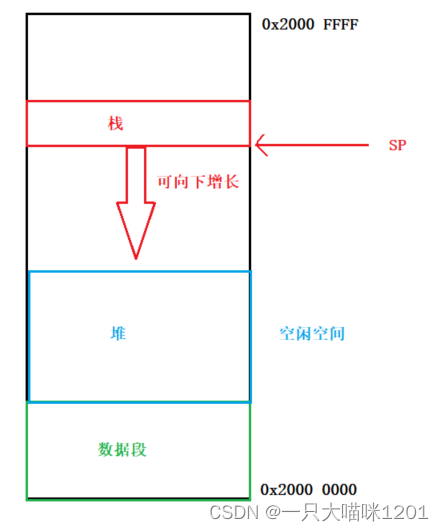 如上圖,整個
如上圖,整個SRAM上,棧占用一部分空間,它的大小隨著的SP的變化而變化,數據段占用一部分空間,但是還沒有全部使用完畢,還有剩余的空閑空間,堆就建立在這部分空間上。
- 堆空間的大小并不會發生變化,它就是一塊固定大小的空間,用戶可以去申請使用,用完了還必須歸還。
所以可以用一個大的全局數組來管理這塊空間,因為全局數組存放在數據段,它的大小并不會隨著SP的變化而變化,從而堆空間的大小也不會變化。
- 雖然叫做堆,但是這部分空間仍然屬于數據段,只是提供了接操作這部分空間的接口。
 如上圖所示,在此定義了一個全局數組
如上圖所示,在此定義了一個全局數組char buffer[500]來充當堆,還有一個全局的index用來記錄堆的使用情況,又實現了一個mymalloc用來向堆區申請空間。
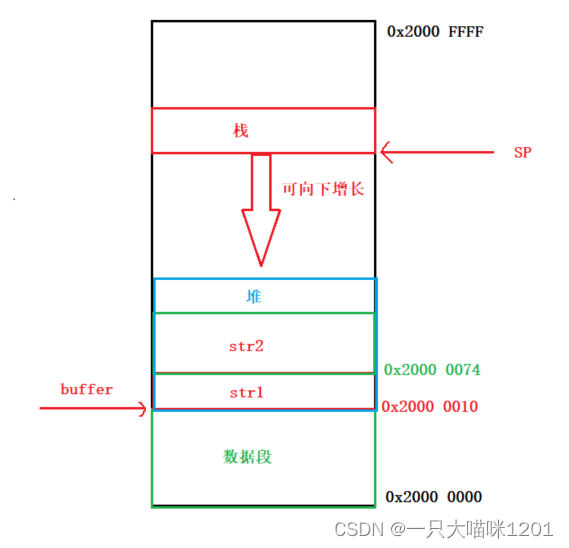
圖
全局數組buffer的地址是0x2000 0010,排在a,b,c,index后面,第一次mymalloc以后,得到的地址是0x2000 0010,大小是100個字節,第二次mymalloc以后,得到的地址是0x2000 0074,地址相差0x64也就是100,說明這是在第一次申請的基礎上再次申請的。index的值是0x12C也就是300,說明一共申請了300個字節的空間。
自定義的釋放函數myfree在此就不寫了,各位小伙伴可以自行嘗試。所以說, 堆本質上就是就是一塊空閑內存,可以使用malloc/free函數來管理它 。
為什么Flash的起始地址就是0x0800 0000,SRAM的起始地址就是0x2000 0000?不能是別的嗎?

如上圖所示,在MDK中,連接器選項中R/O Base是Flash基地址,用來設置Flash的起始地址,R/W Base是SRAM基地址,用來設置SRAM的起始地址。
下面藍色框中的是連接器控制信息,里面的內容是我們程序員寫的,目的是告訴連接器要做什么。
默認情況下,紅色框中的SRAM起始地址是0x2000 0000,本文將其改成了0x2000 8000,來看一下會發生什么?
 如上圖所示,此時代碼里只有一個全局變量a,它位于數據段的起始位置,也就是
如上圖所示,此時代碼里只有一個全局變量a,它位于數據段的起始位置,也就是SRAM的起始位置,其地址是0x2000 8000,本文成功地修改了SRAM的起始地址。
Flash的地址也是同理,也可以通過連接器R/O Base進行修改。
Part2變量的初始化
- 變量:能改變的量,它一定在內存上占據空間,
2.1 局部變量
 如上圖所示,在
如上圖所示,在main函數中創建了局部變量a并賦值0x11223344,創建了局部變量b并賦值0x11。在匯編代碼中,首先移動SP,由于只有兩個變量,所以壓棧r2和r3來占位。
初始化變量a的時候,先執行LDR r0,[pc,#12]匯編語句,取地址為0x0800140的Flash中取值,讀取了該地址及下個地址供四個字節數據0x11223344,賦值給寄存器r0。然后再執行STR r0,[sp,#0x04]匯編語句,將r0中的0x11223344賦值給變量a所在處。
初始化變量b的時候,先執行MOVS r0,#0x11匯編語句,直接將立即數#0x11賦值給寄存器r0,然后再執行STR r0,[sp,#0x00]匯編語句,將r0中的0x11賦值給變量b所在處。
- 兩個局部變量的初始化過程并不一樣,初始值為4字節的變量需要去
Flash中取初值,初始值為1字節的變量,直接就給賦值了。
指令也是有大小的,如0x08000132 4803 LDR r0,[pc,#12]中,0x08000132是代碼所在的Flash地址,4803是代碼匯編之后的機器碼,大小是2字節(CPU執行的是機器碼,匯編語句是為了方便我們看的,剩下的就是匯編語句)。
對于初始值為0x#11的初始化,兩個字節的指令足夠容納一個字節的初值,所以直接就賦值初始化了。
對于初始值為0x11223344的初始化,兩個字節的指令無法容納四個字節的初值,所以必須取Flash中取初值到寄存器中,然后再進行賦值。
 如上圖,創建一個
如上圖,創建一個char buffer[500]數組全部用1初始化,使用BL.W指令跳轉到__aeabi_memclr4處進行初始化,相當于調用了一個函數來初始化這個數組,這個函數是由編譯器生成的,也是一堆匯編語句,這里暫不做介紹。
 如上圖,當
如上圖,當main函數執行完,執行了return 0以后,會執行POP {r2-r3,pc}匯編語句,將前面壓棧時向下生長的空間回收,也就是SP向上移動。
- POP:出棧操作,將棧中的數據彈出,并且
SP棧頂指針向上移動。
此時原本存放變量a和b的空間就位于棧外面了,原本的值彈出給了r0和r1,PC拿到函數的返回地址lr。
雖然a和b的內存空間還存在,但是已經不再被維護了,當有新的局部變量需要棧的時候,SP會重新向下移動,并且使用新的值覆蓋掉這部分空間。
2.2 全局變量和靜態變量

如上圖所示,定義兩個全局變量a和b,初始值分別為10和20,定義一個全局靜態變量,初始值為30,定義一個局部靜態變量,初始值為40,當程序執行到main中時,通過調試窗口看到它們的值都是0,并沒有被初始化。
 如上圖,在啟動文件中使用
如上圖,在啟動文件中使用BL跳轉到main函數之前,需要先跳轉到copy函數,將全局變量的初始值全部復制到對應數據段的地址。但是這里并沒有實現copy函數,所以全局變量沒有被初始化。
- 全局變量的初始值是存放在
Flash中的,注意是只存放初始值,不存放變量名,因為CPU執行的是機器碼,機器碼中并沒有變量名這么一說。
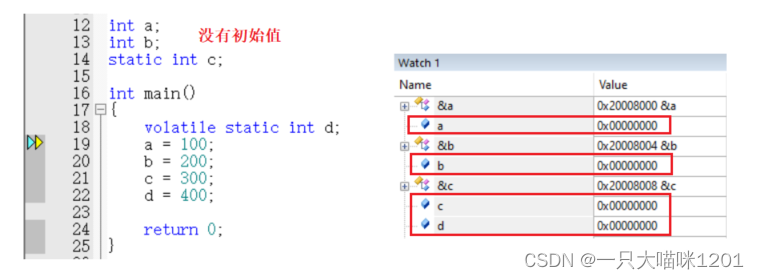 如上圖,仍然是這四個變量,但是在定義都是時候都沒有給初始值,沒有進行初始化,但是在調試窗口看到它們的值仍然是0。
如上圖,仍然是這四個變量,但是在定義都是時候都沒有給初始值,沒有進行初始化,但是在調試窗口看到它們的值仍然是0。
- 對于沒有初始值的數據段變量,在編譯的時候,編譯器會用0將這些變量初始化,也就是將對應地址寫0。
相當于會調用一個memset函數將這部分變量全部初始化為0。這些變量處于數據段的 未初始化數據段 ,而前面有初始值的處于 已初始化數據段 。
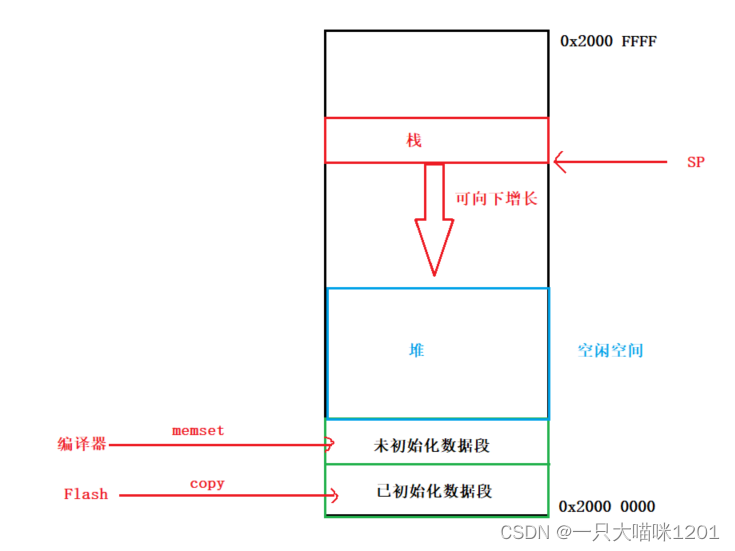 如上圖所示,便是整個數據段的內存示意圖。
如上圖所示,便是整個數據段的內存示意圖。
在STM32F103中,代碼是在FLASH中運行的,并不會加載到內存中,而且代碼和數據段的初始值是混合存放在Flash中的。
Part3函數
如上圖所示,
Add函數其實就是8條匯編指令,調用函數就是讓CPU的PC寄存器等于8條指令的首地址,也就是函數地址。如上圖,
main函數開辟一次棧,SP位于上圖紅色位置,棧里有變量a和b以及main函數的返回地址lr。
在調用Add函數的時候,會再壓一次棧,SP位于上圖綠色位置,這次壓入了Add函數的返回地址lr,以及形參v,再執行SUB語句為局部變量a開辟空間,SP位于上圖藍色位置。
- 函數傳參通過寄存器
r0實現,在PUSH的時候,r0中已經有了實參,然后將實參壓入調用函數的棧中成為形參。
然后執行LDR和STR將形參的值拿到局部變量a中,再進行加一操作,操作完畢后將結果再度寫入到形參v的位置,當函數返回時,執行LDR將運算結果存入r0寄存器中,然后POP出棧操作,SP重新位于上圖紅色位置。
- 函數返回值的時候,同樣通過
r0實現,SP雖然向上移動了,但是r0中有返回值。
調用函數結束后,執行STR將r0中的運算結果寫入到變量b。
 如上圖,
如上圖,main函數在調用Add_Sum函數的時候,一次傳入了八個變量,賦了初值以后,將其中的四個變量交給了寄存器r3-r7,然后執行STM sp,[r8-r11],將剩下的四個變量繼續壓棧。
- STM:一次存儲多個寄存器中的值到指定位置。
在執行Add_Sum函數的時候,執行LDM r5,[r5-r7,r12],從棧中將后四個變量取出來,再與寄存器r3-r7中的四個值一起求和,最后將結果返回。
- LDM:一次讀取多個值到多個寄存器中。
調用函數時,如果傳入的變量比較多,或者是數組的話,由于沒有那么多的寄存器可以做中間人,所以會將這些變量繼續壓入調用方的棧中,被調用函數在用的時候從調用方的棧中拿走進行拷貝。
這就是為什么我們在函數中改變形參,并不影響實參的原因,因為在函數中形參是實參的拷貝,它位于函數的棧中,調用方的棧并不受影響。
Part4指針變量
 如上圖,創建了一個int類型的變量,一個char類型的變量,一個int* 類型的變量,一個char* 類型的變量,從匯編處可以看出,指針變量同樣要在棧中占用空間,只是初始化的時候,指針變量賦值的是地址,如
如上圖,創建了一個int類型的變量,一個char類型的變量,一個int* 類型的變量,一個char* 類型的變量,從匯編處可以看出,指針變量同樣要在棧中占用空間,只是初始化的時候,指針變量賦值的是地址,如ADD r2,sp,#0x04,就是將棧頂指針向上移動4個字節后的地址賦值給為int* pa變量占坑的r2。
- 指針變量仍然是變量,是變量就要占據內存空間,和普通的變量沒有區別,只是它的值是地址而已。
在訪問這兩個指針變量時,*pa = 20,執行了STR r0,[r2,0x00],一次給變量a寫入四個字節,*pb = 'B',執行了STRB r0,[r11#0x00],一次給變量b寫入一個字節。
- STRB:存儲一個字節數據,作用和STR一樣,只是寫入字節是一個字節。
訪問不同類型的指針,底層會有不同的策略,讓CPU以對應的視角去操作對應的內存。如*pa,CPU就會認為它現在訪問地址處的變量是一個int類型,而不是一個char類型。
 如上圖,創建函數指針變量
如上圖,創建函數指針變量int(*pf)(volatile int),將函數Add地址賦值給變量pf。執行LDR r4,[pc,#12]到Flash的0x0800 0158處取函數地址為0x0800 0131。
但是我們看到函數的8條指令的起始地址是0x0800 0130,與r4中取到的函數地址相差1,這是因為在0x0800 0158處存放的0x0800 0131代表兩層意思。
- 函數地址的最低位為1表示該函數使用的是
Thumb指令集,這個1和實際地址沒有關系。- 該值減去1才是真正的函數起始地址,也就是
0x0800 0130。
無論什么類型的指針變量,它里面存放的都是相應變量的首地址,包括函數指針變量,再通過策略決定CPU讀寫該首地址后面幾個字節。
Part5結構體和聯合體
 如上圖,創建一個局部結構體變量,有三個成員變量int age,char sex,int score,并且給它們初始化。先執行
如上圖,創建一個局部結構體變量,有三個成員變量int age,char sex,int score,并且給它們初始化。先執行LDR拿到在Flash中存放初始值的地址0x0800 0144到r2中,然后再執行LDM從初值起始地址開始讀取初值0x0000 18,0x0000 00001,0x0000 0064,對應著24,1,100。
- 結構體初始化時,初值存放在
Flash中,需要讀取到寄存器中,然后再賦值給結構體各個成員。
通過調試窗口查看三個成員的地址,發現成員之間的地址相差4個字節,其中int age和int score是四字節變量占用4個空間,但是char sex是一字節變量也占用四個空間。
如上圖中SRAM示意圖所示,此時sex的四個字節中只用了一個字節,浪費了三個字節。
- 為了提高結構體的訪問效率,結構體變量在存放時會進行內存對齊。

如上圖,數據線和地址線都是32位的,也就是4字節,除此之外還有四根控制線be0,be1,be2,be3。無論是訪問還是寫入,CPU一次操作都是四個字節的內存。
當be0有效時,CPU操作4個字節中第1個字節的空間,be1有效就操作第2個字節的空間,be2有效就操作第3個字節的空間,be3有效就操作第4個字節的空間。
如果操作的是第一個4字節中的3個字節和第二個4字節的1個字節組成的四字節空間,CPU就需要操作兩次,第一次操作時be1,be2,be3有效,第二次操作時be0有效,最后組合得到需要的數據。
采用結構體內存對齊方案,雖然char sex浪費了三個字節的空間,但是在操作int score的時候,可以一次性操作完畢,不需要第二次。
- 結構體對齊利用了以空間換時間的思想。
 如上圖,創建一個位段結構體,成員
如上圖,創建一個位段結構體,成員age和sex都只占用int的32個比特位中的1個比特位,成員score占4個字節32個比特位。
先執行LDR取數據,然后執行BIC r0,r0,#0x01將r0中的32個比特位的第一個比特位清0,然后再執行ADDS r0,r0,#1讓第一個比特位的值成為1,此時給int age:1初始化完成。
- BIC:清除指定比特位,讓該位為0。
同理,再給int sex:1初始化為1,也就是讓32個比特位中的第二個比特位為1。此時還剩下30個比特位被浪費掉了,下一個int score占用完整的32個比特位,同樣是為了提高效率。
 如上圖,結構體中又增加了一個聯合體成員
如上圖,結構體中又增加了一個聯合體成員union weight,char kg和int g兩種類型的變量共用這一個空間。而且可以看到,weight,kg,g三者的地址都是0x2000 FFF8。
在給成員kg賦值80的時候,整個weight空間的值是0x0000 0050,在給成員g賦值的時候,整個weight空間的值是0x0001 3880。操作char類型成員,只改變4個字節中的一個字節,操作int類型成員,則4個字節全部改變。
對應的匯編代碼中,操作char成員使用的是STRB,操作int成員使用的是STR。
Part6總結
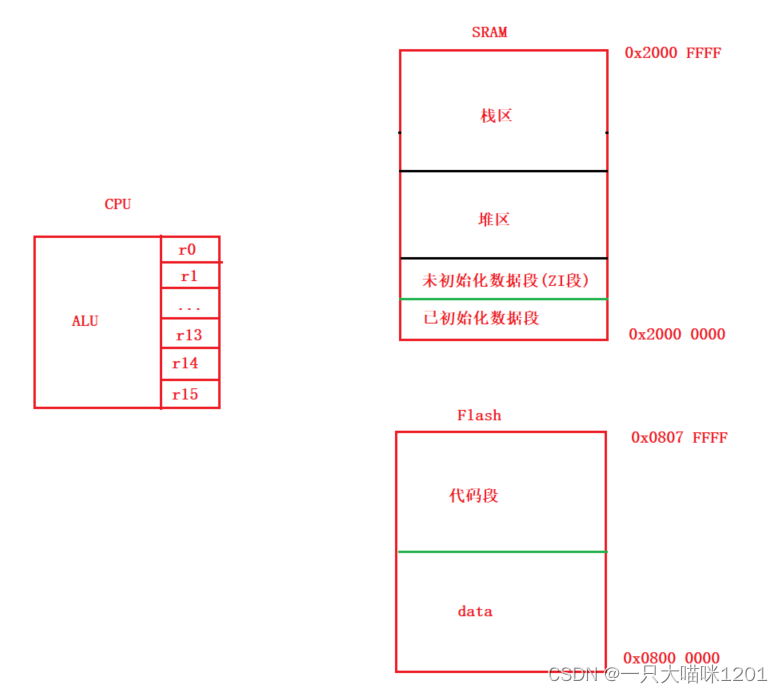 如上圖便是在這篇文章中講解的ARM架構部分模型,以及常用C語言知識在ARM架構中是如何體現的。
如上圖便是在這篇文章中講解的ARM架構部分模型,以及常用C語言知識在ARM架構中是如何體現的。
程序在經過預處理,編譯,匯編,最后再經過連接器分配地址形成.axf,.bin,或者.hex等類型的文件,這幾種文件中的內容全部都是機器碼。
將最終的機器碼燒錄到單片機中,單片機一上電就開始執行這些機器碼,執行過程中是沒有編譯器,電腦系統的參與的,無論是變量的定義,初始化,還是內存空間的分配,你還能說是自動完成的嗎?
所以說,當程序在單片機中開始運行的時候,它的一切就早被安排好了,就是按照前面所講述的去安排設計的,CPU只需要按照機器碼執行即可。
-
單片機
+關注
關注
6035文章
44554瀏覽量
634668 -
WINDOWS
+關注
關注
3文章
3541瀏覽量
88628 -
C語言
+關注
關注
180文章
7604瀏覽量
136696 -
程序
+關注
關注
117文章
3785瀏覽量
81005
發布評論請先 登錄
相關推薦
什么是C語言?單片機有什么特點?為什么要用C語言編程?







 工商網監
工商網監
評論