


摘要
在過去幾年中,如何擴展Transformer使之能夠處理更長的序列一直是一個重要問題,因為這能提高Transformer語言建模性能和高分辨率圖像理解能力,以及解鎖代碼、音頻和視頻生成等新應用。然而增加序列長度,注意力層是主要瓶頸,因為它的運行時間和內存會隨序列長度的增加呈二次(平方)增加。FlashAttention利用GPU非勻稱的存儲器層次結構,實現了顯著的內存節省(從平方增加轉為線性增加)和計算加速(提速2-4倍),而且計算結果保持一致。但是,FlashAttention仍然不如優化的矩陣乘法(GEMM)操作快,只達到理論最大FLOPs/s的25-40%。作者觀察到,這種低效是由于GPU對不同thread blocks和warps工作分配不是最優的,造成了利用率低和不必要的共享內存讀寫。因此,本文提出了FlashAttention-2以解決這些問題。
簡介
如何擴展Transformer使之能夠處理更長的序列一直是一個挑戰,**因為其核心注意力層的運行時間和內存占用量隨輸入序列長度成二次增加。**我們希望能夠打破2k序列長度限制,從而能夠訓練書籍、高分辨率圖像和長視頻。此外,寫作等應用也需要模型能夠處理長序列。過去一年中,業界推出了一些遠超之前長度的語言模型:GPT-4為32k,MosaicML的MPT為65k,以及Anthropic的Claude為100k。
雖然相比標準Attention,FlashAttention快了2~4倍,節約了10~20倍內存,但是離設備理論最大throughput和flops還差了很多。本文提出了FlashAttention-2,它具有更好的并行性和工作分區。實驗結果顯示,FlashAttention-2在正向傳遞中實現了約2倍的速度提升,達到了理論最大吞吐量的73%,在反向傳遞中達到了理論最大吞吐量的63%。在每個A100 GPU上的訓練速度可達到225 TFLOPs/s。
本文主要貢獻和創新點為:
1. 減少了non-matmul FLOPs的數量(消除了原先頻繁rescale)。雖然non-matmul FLOPs僅占總FLOPs的一小部分,但它們的執行時間較長,這是因為GPU有專用的矩陣乘法計算單元,其吞吐量高達非矩陣乘法吞吐量的16倍。因此,減少non-matmul FLOPs并盡可能多地執行matmul FLOPs非常重要。
2. 提出了在序列長度維度上并行化。該方法在輸入序列很長(此時batch size通常很小)的情況下增加了GPU利用率。即使對于單個head,也在不同的thread block之間進行并行計算。
3. 在一個attention計算塊內,將工作分配在一個thread block的不同warp上,以減少通信和共享內存讀/寫。
動機
為了解決這個問題,研究者們也提出了很多近似的attention算法,然而目前使用最多的還是標準attention。FlashAttention利用tiling、recomputation等技術顯著提升了計算速度(提升了2~4倍),并且將內存占用從平方代價將為線性代價(節約了10~20倍內存)。雖然FlashAttention效果很好,但是仍然不如其他基本操作(如矩陣乘法)高效。例如,其前向推理僅達到GPU(A100)理論最大FLOPs/s的30-50%(下圖);反向傳播更具挑戰性,在A100上僅達到最大吞吐量的25-35%。相比之下,優化后的GEMM(矩陣乘法)可以達到最大吞吐量的80-90%。通過觀察分析,這種低效是由于GPU對不同thread blocks和warps工作分配不是最優的,造成了利用率低和不必要的共享內存讀寫。
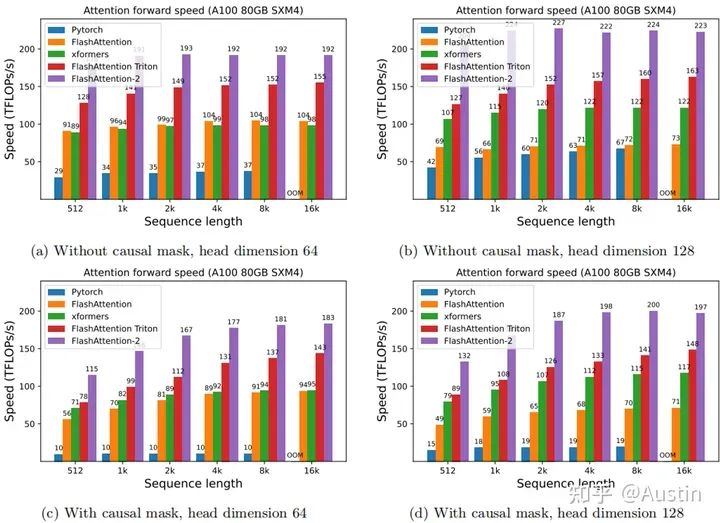
Attention forward speed on A100 GPU. (Source: Figure 5 of the paper.)
背景知識
下面介紹一些關于GPU的性能和計算特點,有關Attention和FlashAttention的詳細內容請參考第一篇文章
FlashAttention圖解(如何加速Attention)
GPU
GPU performance characteristics.GPU主要計算單元(如浮點運算單元)和內存層次結構。大多數現代GPU包含專用的低精度矩陣乘法單元(如Nvidia GPU的Tensor Core用于FP16/BF16矩陣乘法)。內存層次結構分為高帶寬內存(High Bandwidth Memory, HBM)和片上SRAM(也稱為shared memory)。以A100 GPU為例,它具有40-80GB的HBM,帶寬為1.5-2.0TB/s,每個108個streaming multiprocessors共享的SRAM為192KB,帶寬約為19TB/s。
這里忽略了L2緩存,因為不能直接被由程序員控制。
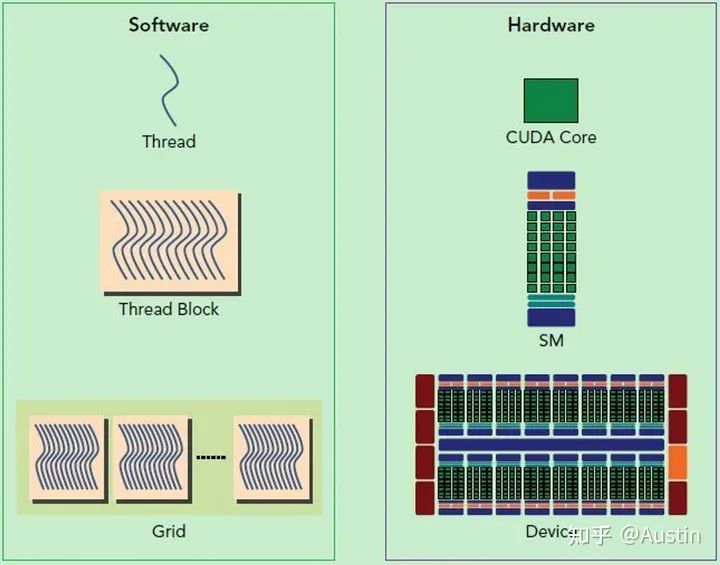
CUDA的軟件和硬件架構
從Hardware角度來看:
Streaming Processor(SP):是最基本的處理單元,從fermi架構開始被叫做CUDA core。
Streaming MultiProcessor(SM):一個SM由多個CUDA core(SP)組成,每個SM在不同GPU架構上有不同數量的CUDA core,例如Pascal架構中一個SM有128個CUDA core。
SM還包括特殊運算單元(SFU),共享內存(shared memory),寄存器文件(Register File)和調度器(Warp Scheduler)等。register和shared memory是稀缺資源,這些有限的資源就使每個SM中active warps有非常嚴格的限制,也就限制了并行能力。
從Software(編程)角度來看:
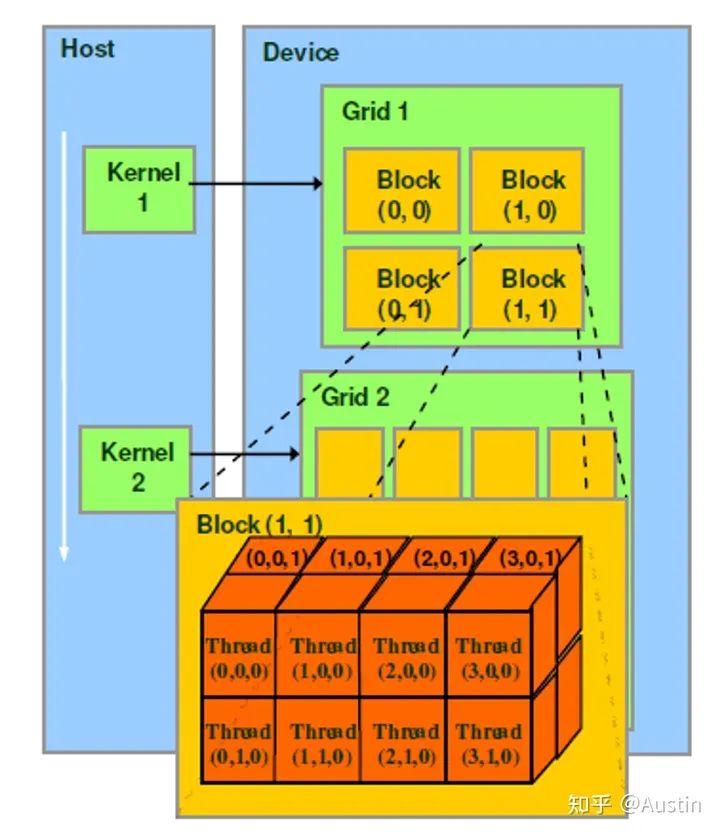
CUDA軟件示例
thread是最基本的執行單元(the basic unit of execution)。
warp是SM中最小的調度單位(the smallest scheduling unit on an SM),一個SM可以同時處理多個warp
thread block是GPU執行的最小單位(the smallest unit of execution on the GPU)。
一個warp中的threads必然在同一個block中,如果block所含thread數量不是warp大小的整數倍,那么多出的那個warp中會剩余一些inactive的thread。也就是說,即使warp的thread數量不足,硬件也會為warp湊足thread,只不過這些thread是inactive狀態,但也會消耗SM資源。
thread:一個CUDA并行程序由多個thread來執行
warp:一個warp通常包含32個thread。每個warp中的thread可以同時執行相同的指令,從而實現SIMT(單指令多線程)并行。
thread block:一個thread block可以包含多個warp,同一個block中的thread可以同步,也可以通過shared memory進行通信。
grid:在GPU編程中,grid是一個由多個thread block組成的二維或三維數組。grid的大小取決于計算任務的規模和thread block的大小,通常根據計算任務的特點和GPU性能來進行調整。
Hardware和Software的聯系:
SM采用的是Single-Instruction Multiple-Thread(SIMT,單指令多線程)架構,warp是最基本的執行單元,一個warp包含32個并行thread,這些thread以不同數據資源執行相同的指令。
當一個kernel被執行時,grid中的thread block被分配到SM上,大量的thread可能被分到不同的SM上,但是一個線程塊的thread只能在一個SM上調度,SM一般可以調度多個block。每個thread擁有自己的程序計數器和狀態寄存器,并且可以使用不同的數據來執行指令,從而實現并行計算,這就是所謂的Single Instruction Multiple Thread。
一個CUDA core可以執行一個thread,一個SM中的CUDA core會被分成幾個warp,由warp scheduler負責調度。GPU規定warp中所有thread在同一周期執行相同的指令,盡管這些thread執行同一程序地址,但可能產生不同的行為,比如分支結構。一個SM同時并發的warp是有限的,由于資源限制,SM要為每個block分配共享內存,也要為每個warp中的thread分配獨立的寄存器,所以SM的配置會影響其所支持的block和warp并發數量。
GPU執行模型小結:
GPU有大量的threads用于執行操作(an operation,也稱為a kernel)。這些thread組成了thread block,接著這些blocks被調度在SMs上運行。在每個thread block中,threads被組成了warps(32個threads為一組)。一個warp內的threads可以通過快速shuffle指令進行通信或者合作執行矩陣乘法。在每個thread block內部,warps可以通過讀取/寫入共享內存進行通信。每個kernel從HBM加載數據到寄存器和SRAM中,進行計算,最后將結果寫回HBM中。
FlashAttention
FlashAttention應用了tiling技術來減少內存訪問,具體來說:
1. 從HBM中加載輸入數據(K,Q,V)的一部分到SRAM中
2. 計算這部分數據的Attention結果
3. 更新輸出到HBM,但是無需存儲中間數據S和P
下圖展示了一個示例:首先將K和V分成兩部分(K1和K2,V1和V2,具體如何劃分根據數據大小和GPU特性調整),根據K1和Q可以計算得到S1和A1,然后結合V1得到O1。接著計算第二部分,根據K2和Q可以計算得到S2和A2,然后結合V2得到O2。最后O2和O1一起得到Attention結果。
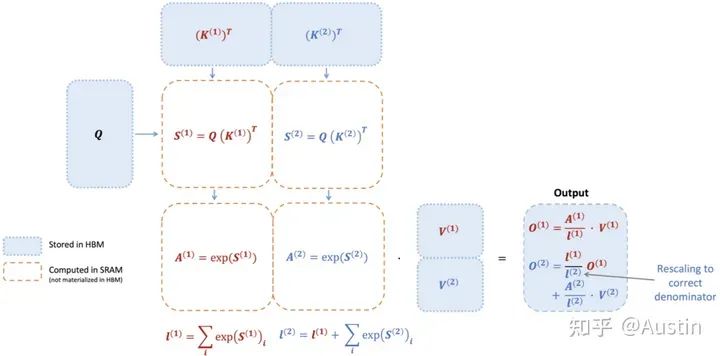
值得注意的是,輸入數據K、Q、V是存儲在HBM上的,中間結果S、A都不需要存儲到HBM上。通過這種方式,FlashAttention可以將內存開銷降低到線性級別,并實現了2-4倍的加速,同時避免了對中間結果的頻繁讀寫,從而提高了計算效率。
FlashAttention-2
經過鋪墊,正式進入正文。我們先講述FlashAttention-2對FlashAttention的改進,從而減少了非矩陣乘法運算(non-matmul)的FLOPs。然后說明如何將任務分配給不同的thread block進行并行計算,充分利用GPU資源。最后描述了如何在一個thread block內部分配任務給不同的warps,以減少訪問共享內存次數。這些優化方案使得FlashAttention-2的性能提升了2-3倍。
Algorithm
FlashAttention在FlashAttention算法基礎上進行了調整,減少了非矩陣乘法運算(non-matmul)的FLOPs。這是因為現代GPU有針對matmul(GEMM)專用的計算單元(如Nvidia GPU上的Tensor Cores),效率很高。以A100 GPU為例,其FP16/BF16矩陣乘法的最大理論吞吐量為312 TFLOPs/s,但FP32非矩陣乘法僅有19.5 TFLOPs/s,即每個no-matmul FLOP比mat-mul FLOP昂貴16倍。為了確保高吞吐量(例如超過最大理論TFLOPs/s的50%),我們希望盡可能將時間花在matmul FLOPs上。
Forward pass
通常實現Softmax算子為了數值穩定性(因為指數增長太快,數值會過大甚至溢出),會減去最大值:
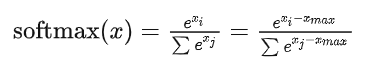
這樣帶來的代價就是要對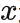 遍歷3次。
遍歷3次。
為了減少non-matmul FLOPs,本文在FlashAttention基礎上做了兩點改進:



簡單示例的FlashAttention完整計算步驟(紅色部分表示V1和V2區別):
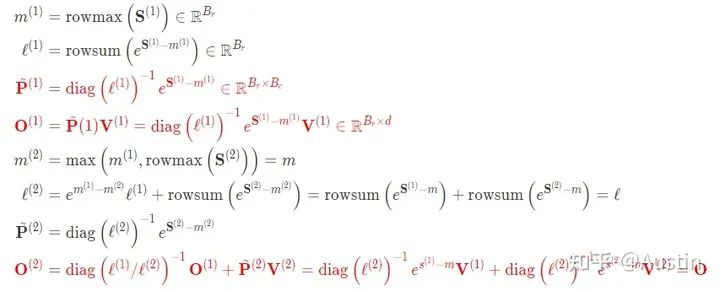
FlashAttention-2的完整計算步驟(紅色部分表示V1和V2區別):
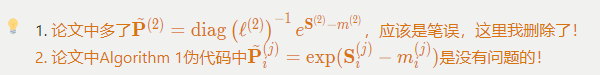
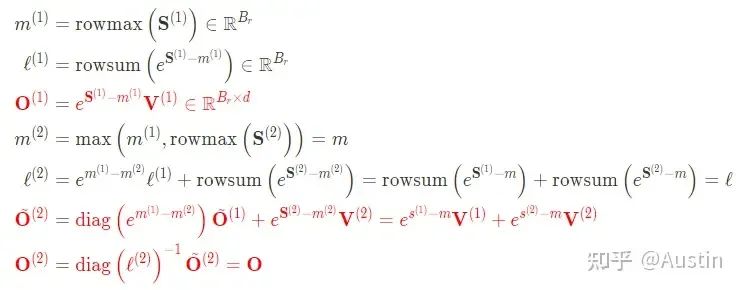
有了上面分析和之前對FlashAttention的講解,再看下面偽代碼就沒什么問題了。

Causal masking是attention的一個常見操作,特別是在自回歸語言建模中,需要對注意力矩陣S應用因果掩碼(即任何S ,其中 > 的條目都設置為?∞)。
1. 由于FlashAttention和FlashAttention-2已經通過塊操作來實現,對于所有列索引都大于行索引的塊(大約占總塊數的一半),我們可以跳過該塊的計算。這比沒有應用因果掩碼的注意力計算速度提高了1.7-1.8倍。
2. 不需要對那些行索引嚴格小于列索引的塊應用因果掩碼。這意味著對于每一行,我們只需要對1個塊應用因果掩碼。
Parallelism
FlashAttention在batch和heads兩個維度上進行了并行化:使用一個thread block來處理一個attention head,總共需要thread block的數量等于batch size × number of heads。每個block被調到到一個SM上運行,例如A100 GPU上有108個SMs。當block數量很大時(例如≥80),這種調度方式是高效的,因為幾乎可以有效利用GPU上所有計算資源。
但是在處理長序列輸入時,由于內存限制,通常會減小batch size和head數量,這樣并行化成都就降低了。因此,FlashAttention-2還在序列長度這一維度上進行并行化,顯著提升了計算速度。此外,當batch size和head數量較小時,在序列長度上增加并行性有助于提高GPU占用率。

Work Partitioning Between Warps
上一節討論了如何分配thread block,然而在每個thread block內部,我們也需要決定如何在不同的warp之間分配工作。我們通常在每個thread block中使用4或8個warp,如下圖所示。
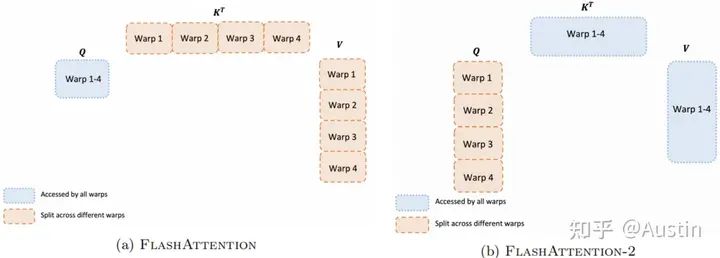
Work partitioning between different warps in the forward pass

論文中原話是”However, this is inefficient since all warps need to write their intermediate results out toshared memory, synchronize, then add up the intermediate results.”,說的是shared memory而非HBM,但是結合下圖黃色框部分推斷,我認為是HBM。



-
存儲器
+關注
關注
38文章
7653瀏覽量
167576 -
gpu
+關注
關注
28文章
4956瀏覽量
131404 -
矩陣
+關注
關注
1文章
434瀏覽量
35274
原文標題:FlashAttention2詳解(性能比FlashAttention提升200%)
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是共模抑制比?

進迭時空第三代高性能核X200研發進展

直線電機與旋轉電機性能比較
ADS1212、ADS1231和ADS1230這3種AD芯片性能比較
臺積電2納米制程技術細節公布:性能功耗雙提升
臺積電2nm制成細節公布:性能提升15%,功耗降低35%
如何提升漆包線的導電性能
汽車制動系統如何提升剎車性能
不同材質的阻尼器性能比較
聯發科天璣9400發布:能效比與端側AI引領移動芯片行業革新







 工商網監
工商網監

評論