") 澎峰科技發(fā)布大模型推理引擎PerfXLLM
澎峰科技發(fā)布大模型推理引擎PerfXLLM
自從2020年6月OpenAI發(fā)布chatGPT之后,基于Transformer網(wǎng)絡(luò)結(jié)構(gòu)的語言大模型(LLM)引發(fā)了全世界的注意與追捧,成為了人工智能領(lǐng)域的里程碑事件。
但大模型推理所需要的巨額開銷也引發(fā)了相關(guān)研究者的關(guān)注。如何高效地進(jìn)行推理,并盡可能地減少成本,從而促進(jìn)大模型應(yīng)用的落地成為了目前的關(guān)鍵問題。
于是,澎峰科技研發(fā)了一款大模型推理引擎—PerfXLLM,并且已經(jīng)在高通的驍龍8Gen2平臺(tái)實(shí)現(xiàn)了應(yīng)用。接下來將分為四個(gè)部分進(jìn)行介紹,第一部分將介紹PerfXLLM的整體架構(gòu)設(shè)計(jì),第二部分將展示手機(jī)端的性能表現(xiàn),第三部分將詳細(xì)地闡述手機(jī)端的推理優(yōu)化方案,最后在第四部分將介紹PerfXLLM的未來規(guī)劃。
一、PerfXLLM整體架構(gòu)
目前大模型推理過程主要放在服務(wù)器或者云上進(jìn)行處理。用戶發(fā)出請(qǐng)求,服務(wù)器進(jìn)行響應(yīng),通過GPU等高性能計(jì)算部件完成推理計(jì)算,并通過網(wǎng)絡(luò)將結(jié)果傳輸給用戶。而隨著移動(dòng)端設(shè)備硬件能力的不斷進(jìn)步,并且用戶原始數(shù)據(jù)可能存在敏感隱私信息導(dǎo)致對(duì)安全問題有所顧慮,大模型在移動(dòng)端的應(yīng)用和落地也成為了實(shí)際需求之一。為了兼顧兩部分的需求,PerfXLLM設(shè)計(jì)上采用了云端一體的架構(gòu)理念。
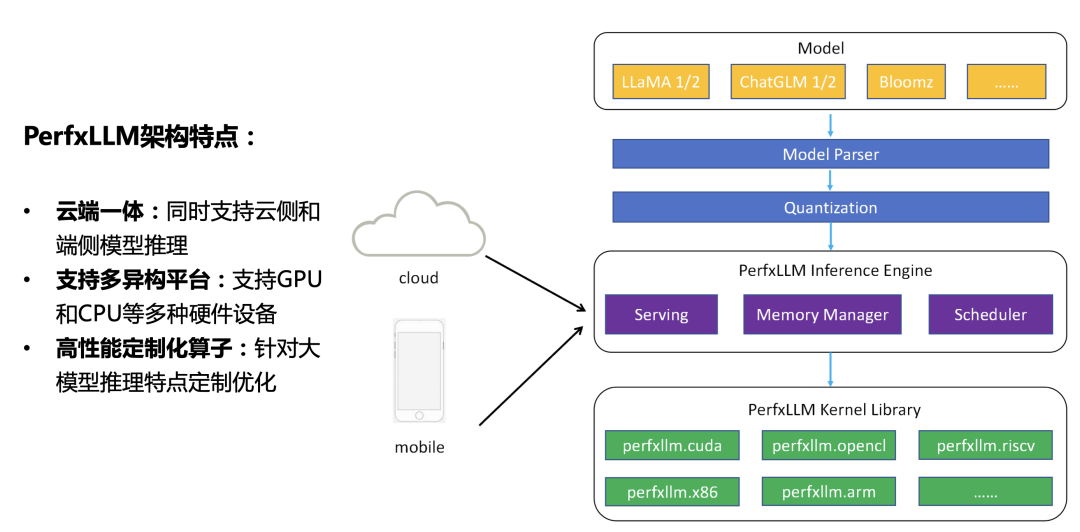
如上圖所示,當(dāng)模型經(jīng)過解析量化之后被PerfXLLM的推理引擎加載至內(nèi)存中。不管是云側(cè)還是端側(cè)都是調(diào)用同樣的一套推理引擎代碼。有所區(qū)別的地方在于云側(cè)需要進(jìn)行額外的Serving模塊,從而獲得更高的硬件利用率和QPS響應(yīng)。再聚焦到底層Kernel,PerfXLLM中開發(fā)了一套針對(duì)大模型推理的算子庫,可以支持GPU、CPU等多種硬件設(shè)備。
二、PerfXLLM應(yīng)用在手機(jī)端
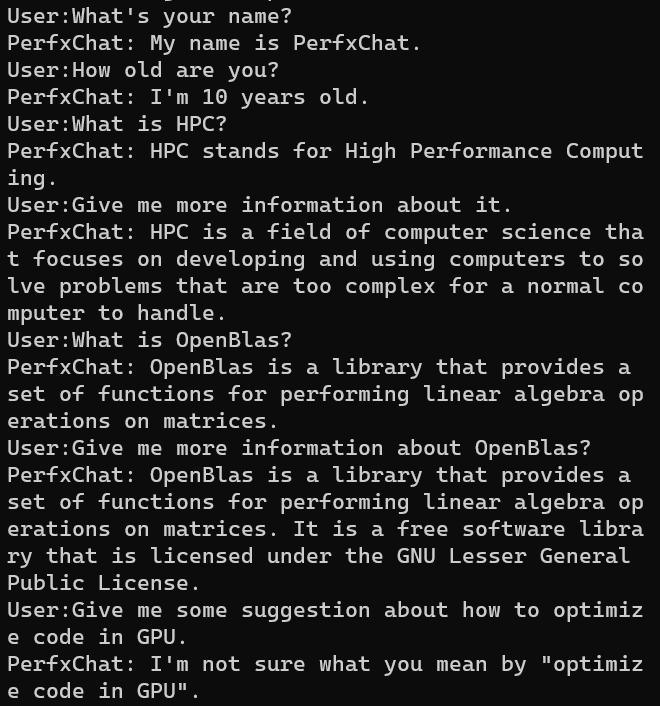
目前,PerfXLLM針對(duì)高通驍龍8Gen2芯片進(jìn)行了定制優(yōu)化,高通8Gen2芯片進(jìn)行了定制優(yōu)化,對(duì)LlaMA模型采用了AWQ的int4量化方法,并為模型開發(fā)了PerfXChat APP。生成速度為6.7 token/s。模型內(nèi)存占用為3.7GB。而llama.cpp的生成速度僅為3.2 token/s。
具體而言,通過芯片上的Andreno GPU進(jìn)行加速,使用了OpenCL編程模型。首先對(duì)LlaMA模型進(jìn)行int4量化,所采用的方式是AWQ量化方法。而后針對(duì)LlaMA模型中最耗時(shí)的Kernel進(jìn)行了優(yōu)化。手機(jī)端的輸入token和生成token較少時(shí),模型主要瓶頸在于GEMM算子和GEMV算子,研發(fā)團(tuán)隊(duì)對(duì)這兩個(gè)算子進(jìn)行了手工調(diào)優(yōu)。模型使用效果如下。
三、手機(jī)端推理優(yōu)化方案介紹
由于手機(jī)端的硬件性能與服務(wù)器端差距較大,因而在手機(jī)端如何將大模型運(yùn)行起來,并帶給用戶流暢的使用體驗(yàn)并不是一件容易的事情。為了對(duì)手機(jī)端的大模型推理進(jìn)行優(yōu)化,PerfXLLM目前主要采用的手段有低精度量化、算子融合以及核心算子調(diào)優(yōu)。
3.1.低精度量化
低精度量化指的是將更高精度的數(shù)據(jù)表示類型轉(zhuǎn)化成低精度的數(shù)據(jù)表示類型來加快計(jì)算過程。常用的低精度量化有fp16、int8、int4等。通過低精度的量化,可以減少訪存開銷和內(nèi)存空間,通過特殊計(jì)算單元加快運(yùn)算。因而可以獲得比原精度更高的性能表現(xiàn)。PerfXLLM需要將7B的模型運(yùn)行在手機(jī)上。如果是fp16的模型,則需要大概14GB的內(nèi)存占用。但是目前市面上手機(jī)內(nèi)存一般不超過16GB,再減去系統(tǒng)本身所需要的內(nèi)存占用以及其他APP可能需要的內(nèi)存空間,必須使用低精度量化才能滿足。
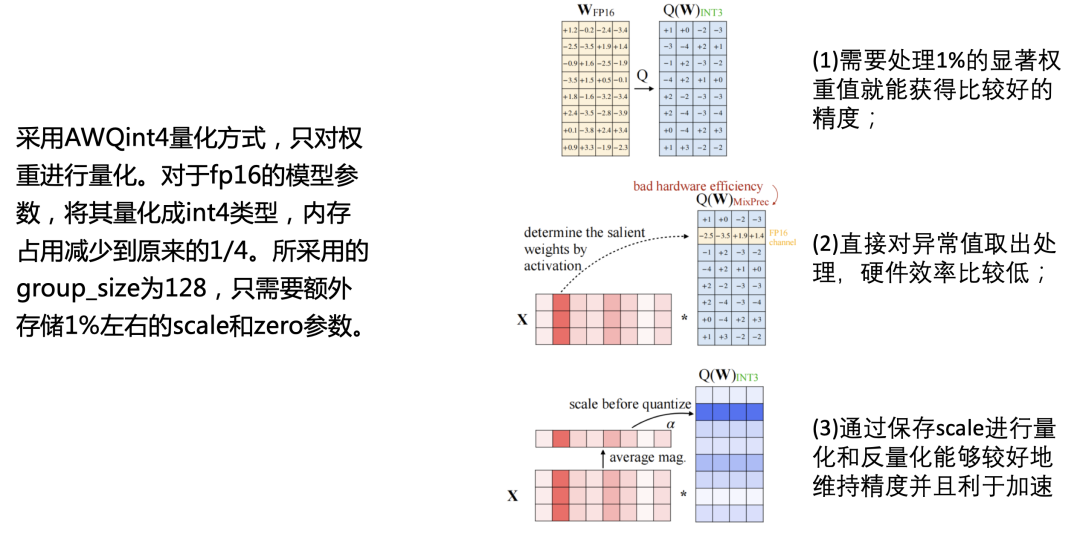
PerfXLLM采用的是AWQ量化方法,只對(duì)權(quán)重進(jìn)行量化。對(duì)于fp16的模型參數(shù),將其量化成int4類型,內(nèi)存占用減少到原來的1/4。所采用的group_size為128,只需要額外存儲(chǔ)1%左右的scale和zero參數(shù)。
3.2.算子融合
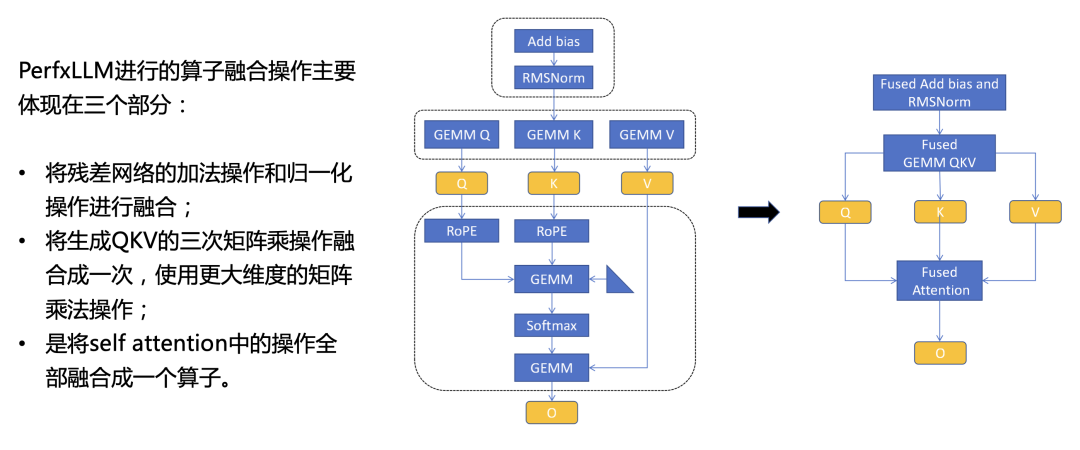
算子融合是將多個(gè)算子融合成一個(gè),從而減少中間結(jié)果的數(shù)據(jù)讀取和寫入操作,并且也能有效地減少Kernel launch所需要的開銷。為了提高推理速度,PerfXLLM進(jìn)行的算子融合操作主要體現(xiàn)在三個(gè)部分。第一部分是將殘差網(wǎng)絡(luò)的加法操作和歸一化操作進(jìn)行融合,避免了中間結(jié)果在全局內(nèi)存中的搬運(yùn);第二部分是將生成QKV的三次矩陣乘操作融合成一次,使用更大維度的矩陣乘法操作,從而更充分地利用硬件性能;第三部分是將self attention中的操作全部融合成一個(gè)算子,這些操作包含針對(duì)QK的旋轉(zhuǎn)編碼,QKV的兩次矩陣乘法以及中間的Softmax操作。具體的示意圖如下。
3.3.核心算子調(diào)優(yōu)
語言大模型中所需要的算子較少,并且絕大部分性能開銷都集中在1-2個(gè)算子上,因而針對(duì)核心算子的細(xì)致調(diào)優(yōu)便顯得尤為關(guān)鍵。在手機(jī)端,當(dāng)生成token數(shù)量較少時(shí),Attention相關(guān)算子的耗時(shí)占比非常少,而GEMM(通用矩陣乘法)類的算子耗時(shí)幾乎占據(jù)了整個(gè)推理過程。對(duì)于大模型推理而言,一般會(huì)分為兩個(gè)過程。在第一個(gè)過程中,輸入的token數(shù)量大于1,對(duì)應(yīng)的算子即GEMM。第二個(gè)過程中,輸入的token數(shù)量恒定為1,對(duì)應(yīng)的算子即GEMV(矩陣向量乘法)。因此,推理優(yōu)化的核心問題在于如何提高GEMM和GEMV的性能。PerxLLM對(duì)這兩個(gè)算子進(jìn)行了細(xì)致的優(yōu)化。
1)針對(duì)GEMM算子。首先介紹GEMM算子的定義,給定矩陣A和B,其維度分別為[m, k]和[k,n],將兩者相乘得到矩陣C,維度為[m, n]。根據(jù)輸入token數(shù)量的不同,PerfXLLM將其分為兩種情況進(jìn)行優(yōu)化。當(dāng)輸入token數(shù)量較少時(shí),矩陣B是一個(gè)高瘦矩陣,GEMM變成訪存密集型算子。當(dāng)輸入token數(shù)量較多時(shí),GEMM是一個(gè)計(jì)算密集型算子。針對(duì)兩種不同的情況,PerfXLLM采用了兩種不同的分塊模式,將所需要的數(shù)據(jù)放置在共享內(nèi)存之中,以盡可能地減少對(duì)全局內(nèi)存的數(shù)據(jù)讀取。此外,采用了向量化訪存來提高訪存效率,通過循環(huán)展開來避免流水線阻塞提高指令并行度,進(jìn)行參數(shù)調(diào)優(yōu)來獲得更好的并行能力和分塊配置參數(shù)。具體的性能表現(xiàn)如下。固定M為12288,K為4096,N變化。
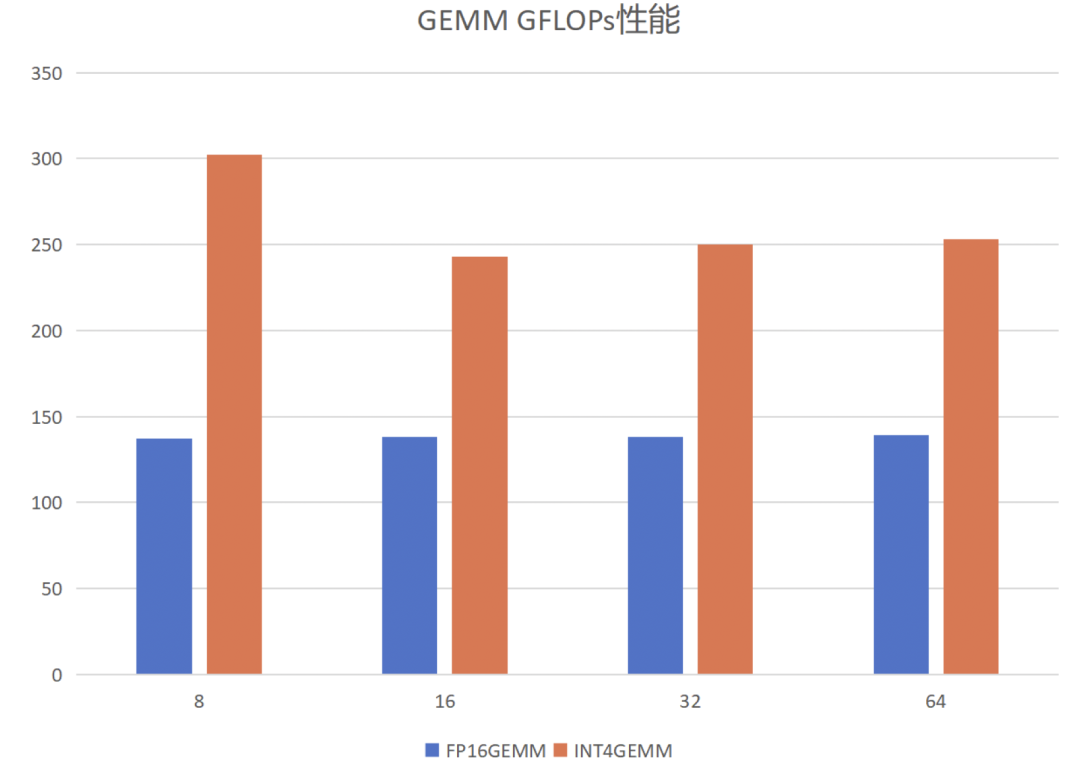
2)針對(duì)GEMV算子。需要說明的是,GEMV可以視作GEMM的一種變體,當(dāng)B矩陣的n等于1時(shí),則GEMM轉(zhuǎn)換為GEMV算子。GEMV是一個(gè)典型的訪存密集型算子,其優(yōu)化核心在于如何提高訪存效率,并掩蓋計(jì)算所需要的開銷。PerfXLLM通過向量化訪存來提高訪存效率,通過循環(huán)展開來避免流水線阻塞提高指令并行度。并且針對(duì)int4類型的GEMV,通過共享內(nèi)存來存儲(chǔ)zero和scale來減少對(duì)全局內(nèi)存的數(shù)據(jù)訪問。此外,對(duì)A矩陣的兩個(gè)維度進(jìn)行分塊來提高并行性。使用Image類型來提高對(duì)于B向量的訪存性能。
以上一些披露的信息,表明了PerfXLLM已經(jīng)完成了整個(gè)計(jì)算系統(tǒng)架構(gòu)的設(shè)計(jì),并將緊密跟隨大模型算法的更迭速度,這彌補(bǔ)了計(jì)算芯片迭代慢的弊端(>2年)。
四、未來規(guī)劃
4.1.更多的模型支持
4.2.支持更多的硬件
4.3.性能優(yōu)化
4.4.框架優(yōu)化
歡迎聯(lián)系我們wangjh@perfxlab.com。一起探索大模型的軟件基礎(chǔ)建設(shè)。
原文標(biāo)題:澎峰科技發(fā)布大模型推理引擎PerfXLLM
文章出處:【微信公眾號(hào):澎峰科技PerfXLab】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
RISC-V
+關(guān)注
關(guān)注
45文章
2270瀏覽量
46125 -
澎峰科技
+關(guān)注
關(guān)注
0文章
55瀏覽量
3168
原文標(biāo)題:澎峰科技發(fā)布大模型推理引擎PerfXLLM
文章出處:【微信號(hào):perfxlab,微信公眾號(hào):perfxlab】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
澎峰科技校園行走進(jìn)湖南開放大學(xué)
澎峰科技攜手湖南第一師范,開啟大模型AI學(xué)習(xí)新模式

澎峰科技PerfXCloud平臺(tái)獲海光DCU生態(tài)兼容性認(rèn)證
澎峰科技助力中國移動(dòng) 重磅發(fā)布智算“芯合”算力原生基礎(chǔ)軟件棧2.0

喜報(bào) 祝賀澎峰科技榮獲“2024中國算力卓越企業(yè)獎(jiǎng)”

第一屆“澎峰云?大模型AI校園應(yīng)用創(chuàng)新賽完美結(jié)束
澎峰科技受邀出席人工智能技術(shù)專題講座
“澎峰云”校園行:湖南科技職業(yè)學(xué)院站,共啟校園創(chuàng)新之旅!

澎峰科技“澎峰云”校園行活動(dòng)回顧
澎峰科技高性能大模型推理引擎PerfXLM解析

OpenAI即將發(fā)布“草莓”推理大模型
澎峰科技受邀參加全球AI芯片峰會(huì),探討大模型推理引擎PerfXLM面向RISC-V的移植和優(yōu)化

澎峰科技受聘為“主權(quán)級(jí)大模型”創(chuàng)新聯(lián)合體學(xué)術(shù)委員會(huì)委員
澎峰科技CA100智能計(jì)算一體機(jī)核心優(yōu)勢解讀
澎峰科技與并行科技共拓AI大模型技術(shù)創(chuàng)新應(yīng)用服務(wù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論