 Lambda數據架構和Kappa數據架構——構建現代數據架構
Lambda數據架構和Kappa數據架構——構建現代數據架構
如何更好地構建我們的數據處理架構,如何對IT系統中的遺留問題進行現代化改造并將其轉變為現代數據架構?該怎么為你的需求匹配最適合的架構設計呢,本文將分析兩種最流行的基于速度的數據架構,為你提供一些思路。
文章速覽:
什么是數據架構?
基于速度的數據架構
Lambda數據架構
Kappa數據架構
探索數據流模型
結語
一、什么是數據架構?
數據架構是企業架構中的一個元素,繼承了企業架構的主要屬性:流程、策略、變更管理和評估權衡。根據Open Group架構框架,數據架構是對“企業主要數據類型、來源、邏輯數據資產、物理數據資產和數據管理資源的結構和交互” 的描述。
根據數據管理知識體系,數據架構是“識別企業的數據需求(無論結構如何)并設計和維護核心藍圖以滿足這些需求”的過程。它使用核心藍圖來指導數據集成、控制數據資產并使數據投資與業務戰略保持一致。
然而,糟糕的數據架構是僵化且過度集中的。它使用了錯誤的工具來完成工作,這阻礙了開發和變更管理。
二、基于速度的數據架構
數據速度是指數據生成的速度、數據移動的速度以及將其處理為可用指導的速度。
根據處理數據的速度,數據架構通常分為兩類:Lambda和Kappa。
Lambda數據架構?
1.什么是Lambda
Lambda數據架構由Apache Storm的創建者Nathan Marz于 2011 年開發,旨在解決大規模實時數據處理的挑戰。術語 Lambda 源自lambda演算 (λ),描述了在多個節點上并行運行分布式計算的函數。Lambda數據架構提供了一個可擴展、容錯且靈活的系統來處理大量數據。它允許以混合方式訪問批處理和流處理方法。
2.Lambda架構的使用場景
1)當您有各種工作負載和速度要求時,Lambda架構是理想的選擇。由于它可以處理大量數據并提供低延遲查詢結果,因此適合儀表板和報告等實時分析應用程序。Lambda架構對于批處理(清理、轉換、數據聚合)、流處理任務(事件處理、開發機器學習模型、異常檢測、欺詐預防)以及構建集中存儲庫(稱為“數據湖”)非常有用。
2)Lambda架構的關鍵區別在于,它使用兩個獨立的處理系統來處理不同類型的數據處理工作負載。第一個是批處理系統,它將結果存儲在集中式數據存儲(例如數據倉庫或數據湖)中。第二個系統是流處理系統,它在數據到達時實時處理數據并將結果存儲在分布式數據存儲中。
3.Lambda架構的組成
Lambda架構由攝取層、批處理層、速度層(或流層)和服務層組成。
·批處理層:批處理層處理大量歷史數據并將結果存儲在集中式數據存儲中,例如數據倉庫或分布式文件系統。該層使用Hadoop或Spark等框架進行高效的數據處理,使其能夠提供所有可用數據的總體視圖。
·速度層:速度層處理高速數據流,并使用Apache Flink或Apache Storm等事件處理引擎提供最新的信息視圖。該層處理傳入的實時數據并將結果存儲在分布式數據存儲中,例如消息隊列或NoSQL數據庫。
·服務層:無論底層處理系統如何,Lambda架構服務層對于為用戶提供一致的數據訪問體驗至關重要。它在支持需要快速訪問當前信息(例如儀表板和分析)的實時應用程序方面發揮著重要作用。
4.Lambda架構的使用場景
Lambda架構解決了計算任意函數的問題,系統必須評估任何給定輸入的數據處理函數(無論是慢動作還是實時)。此外,它還提供容錯功能,確保在一個系統出現故障或不可用時,任一系統的結果都可以用作另一個系統的輸入。在高吞吐量、低延遲和近實時應用程序中,這種架構的效率是很明顯的。

Lambda架構示意圖
5、Lambda架構的缺點
Lambda架構提供了許多優勢,例如可擴展性、容錯性以及處理各種數據處理工作負載(批處理和流)的靈活性。但它也有缺點:
·Lambda架構很復雜,它使用多種技術堆棧來處理和存儲數據。
·設置和維護可能具有挑戰性,尤其是在資源有限的組織中。
·每個階段的批處理和速度層中都會重復底層邏輯。這種重復有一個代價:數據差異。因為盡管具有相同的邏輯,但一層與另一層的實現不同。因此,錯誤/錯誤的概率較高,并且您可能會遇到批處理層和速度層的不同結果。
Kappa數據架構?
2014年,Jay Kreps指出了Lambda架構的一些缺點。這次討論使大數據社區找到了一種使用更少代碼資源的替代方案——Kappa數據架構。
1、什么是Kappa數據架構
Kappa(以希臘字母 ? 命名,在數學中用于表示循環)背后的主要思想是單個技術堆棧可用于實時和批量數據處理。該名稱反映了該體系結構對連續數據處理或再處理的重視,而不是基于批處理的方法。
Kappa 的核心依賴于流式架構。傳入數據首先存儲在事件流日志中。然后,它由流處理引擎(例如 Kafka)連續實時處理或攝取到另一個分析數據庫或業務應用程序中。這樣做需要使用各種通信范例,例如實時、近實時、批處理、微批處理和請求響應等。
2、Kappa數據架構的組成
數據重新處理是 Kappa的一項關鍵要求,使源端的任何更改對結果的影響可見。因此,Kappa 架構僅由兩層組成:流處理層和服務層。
在Kappa架構中,只有一層處理層:流處理層。該層負責采集、處理和存儲直播數據。這種方法消除了對批處理系統的需要。相反,它使用先進的流處理引擎(例如 Apache Flink、Apache Storm、Apache Kafka 或 Apache Kinesis)來處理大量數據流并提供對查詢結果的快速、可靠的訪問。
流處理層有兩個組件:
·攝取組件:該層從各種來源收集傳入數據,例如日志、數據庫事務、傳感器和 API。數據被實時攝取并存儲在分布式數據存儲中,例如消息隊列或NoSQL數據庫。
·處理組件:該組件處理大量數據流并提供對查詢結果的快速可靠的訪問。它使用事件處理引擎(例如 Apache Flink 或 Apache Storm)來實時處理傳入數據和歷史數據(來自存儲區域),然后將信息存儲到分布式數據存儲中。
對于幾乎所有用例,實時數據都勝過非實時數據。盡管如此,Kappa架構不應該被視為 Lambda 架構的替代品。反之,在不需要批處理層的高性能來滿足標準服務質量的情況下,您應該考慮 Kappa架構。
3、Kappa架構的優勢
Kappa架構旨在提供可擴展、容錯且靈活的系統,用于實時處理大量數據。它使用單一技術堆棧來處理實時和歷史工作負載,并將所有內容視為流。Kappa 架構的主要動機是避免為批處理層和速度層維護兩個獨立的代碼庫(管道)。這使得它能夠提供更加精簡的數據處理管道,同時仍然提供對查詢結果的快速可靠訪問。
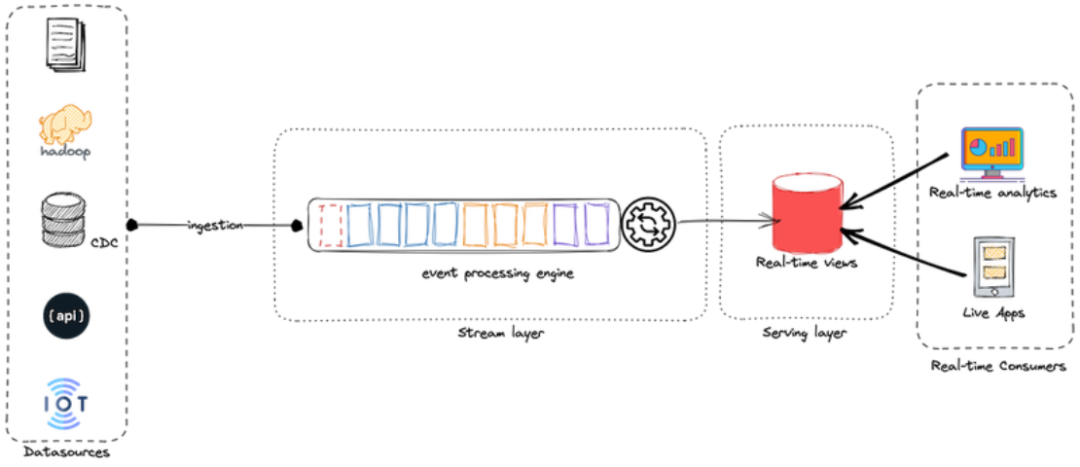
Kappa架構示意圖
4、Kappa架構的缺點
Kappa架構承諾可擴展性、容錯性和簡化的管理。然而,它也有缺點。
· Kappa架構理論上比 Lambda更簡單,但對于不熟悉流處理框架的企業來說,技術上仍然可能很復雜。
· 擴展事件流平臺時的基礎設施成本。在事件流平臺中存儲大量數據可能成本高昂,并會引發其他可擴展性問題,尤其是當數據量達到TB或PB級時。
· 事件時間和處理時間之間的滯后不可避免地會產生數據延遲。因此,Kappa 架構需要一套機制來解決這個問題,例如水印、狀態管理、重新處理或回填。
探索數據流模型?
1、為什么會出現數據流模型
Lambda和Kappa試圖通過集成本質上不兼容的復雜工具來克服2010年代Hadoop生態系統的缺點。這兩種方法都難以解決協調批處理和流數據的根本挑戰。然而,Lambda和Kappa 為進一步的改進提供了靈感和基礎。
統一多個代碼路徑是管理批處理和流處理的一項重大挑戰。即使有了Kappa架構的統一隊列和存儲層,開發人員也需要使用不同的工具來收集實時統計數據并運行批量聚合作業。今天,他們正在努力應對這一挑戰。
2、什么是數據流模型
數據流模型的基本前提是將所有數據視為事件并在不同類型的窗口上執行聚合。實時事件流是無界數據,而批量數據是具有自然窗口的有界事件流。
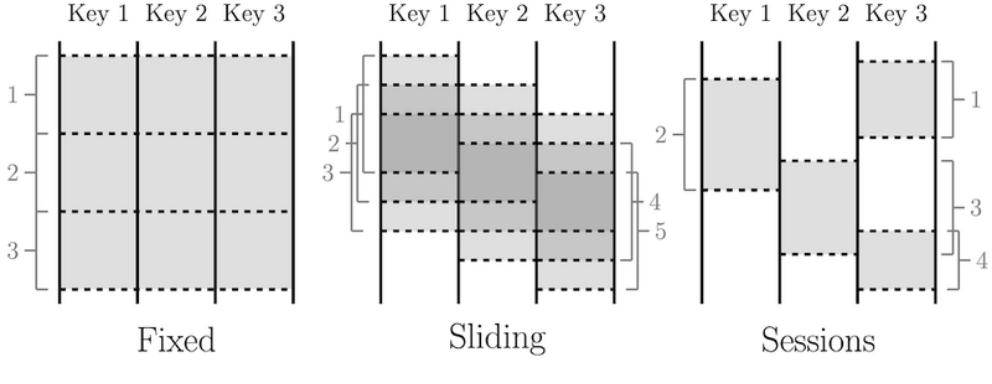
窗口模式示意圖
數據工程師可以選擇不同的窗口,例如滑動窗口或會話窗口,以進行實時聚合。數據流模型允許使用幾乎相同的代碼在同一系統內進行實時和批處理。
“批處理作為流處理的一個特例”的想法已經變得越來越普遍,Flink和Spark等框架也采用了類似的方法。
結語
當然,關于速度模型的數據架構討論還有另一個用處:適合物聯網 (IoT) 的設計選擇,在本篇文章中,我們就不再贅述。如何最好地構建我們處理數據的架構,如何對僵化且緩慢的IT遺留系統,進行現代化改造并將其轉變為現代數據架構,顯然,關于這個問題還尚未有定論。歡迎與我們共同探討。
-
數據
+關注
關注
8文章
7002瀏覽量
88943 -
架構
+關注
關注
1文章
513瀏覽量
25468 -
虹科電子
+關注
關注
0文章
601瀏覽量
14340
發布評論請先 登錄
相關推薦
寶藏級微服務架構工具合集
架構與設計 常見微服務分層架構的區別和落地實踐
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
RISC--V架構的特點
CXL技術:全面升級數據中心架構
超融合架構解決方案
交換芯片架構是什么意思 交換芯片架構怎么工作
AI數據中心架構升級引發800G光模塊需求激增
車載以太網靜態架構介紹
【vsan數據恢復】VSAN超融合基礎架構數據恢復案例
什么是分布式架構?
性能領先|憶聯×新華三,打造超融合架構下的高性能存儲方案






 工商網監
工商網監
評論