 AI從GPU席卷至MCU,內存的重要性與算力等同
AI從GPU席卷至MCU,內存的重要性與算力等同
電子發燒友網報道(文/周凱揚)在市場對AI的不懈追求中,似乎絕大多數人都把重心放在了算力上。然而決定真正AI計算表現的,還有內存這一重要組成部分。為此,除了傳統的標準內存選項外,市面上也出現了專門針對AI進行優化的內存。
高性能AI芯片需要超高帶寬內存
無論是英偉達最新的服務器GPU,還是一眾初創公司推出的AI加速器,我們都可以看到HBM出現的越來越頻繁,比如英偉達H100、谷歌TPU等等。美光、SK海力士和三星等廠商都在布局這類超高帶寬內存,用于解決 AI計算中時常出現的內存墻問題。
以LLM模型的訓練負載為例,HBM3內存與處理器可以與處理器以最高6.4Gb/s的接口速率相連,并實現3.2TB/s的超大帶寬。而且在3D堆疊技術的支撐下,SoC芯片的面積依然控制在一個合理的范圍內。超大的帶寬顯著減少了模型訓練時間,所以我們才能看到如此快的LLM模型更迭速度。
當把模型推向終端應用時,效率就和效能一樣重要了。推理帶來的計算成本異常龐大,所以我們需要更低的系統功耗。而HBM內存恰好可以在維持“較低”速率的同時,實現與處理器的“近距離接觸”和大帶寬,從而進一步降低整體系統功耗。
當然了,HBM也并非那么完美,不然我們也不會只在服務器級別的產品上看到它們。隨著HBM而來的是設計復雜度和更高的成本,比如需要額外設計硅中介層等等。但還是由于吃到了AI紅利,HBM的成本也在慢慢降低,甚至有的初創公司在首個AI芯片上就直接采用HBM3內存,為的就是充分釋放AI芯片的計算性能。
小芯片的AI夢
隨著AI熱潮的襲來,我們也看到了邊緣端不少AIoT產品開始追逐這一風口,尤其是智能音箱等具備交互能力的設備。然而以這類設備主用的MCU芯片而言,本身計算性能就難以與GPU這樣的高性能AI加速器媲美,更別說內存帶寬了。
為此,英飛凌推出了HyperRAM這一高速內存,相較傳統的pSRAM,HyperRAM成了更高效簡潔的解決方案。HyperRAM基于HyperBus這一接口開發,相較于其他DRAM內存方案,HyperRAM并不見得有壓倒性的帶寬優勢,比如最新的HyperRAM 3.0版本,其帶寬最高可達800MB/s。
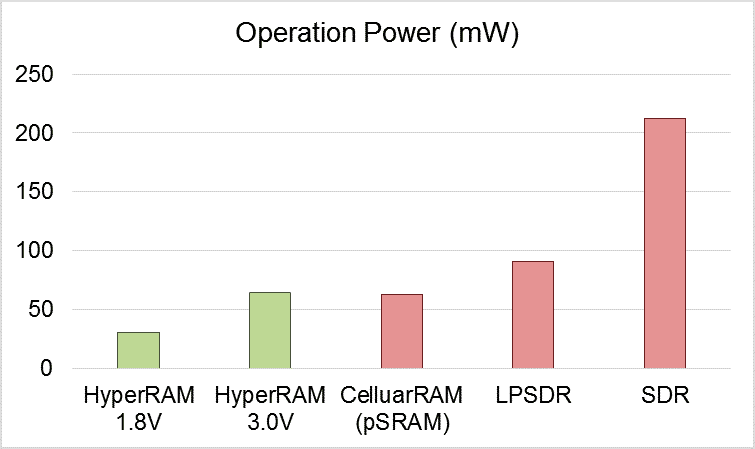
不同內存的工作功耗對比 / 華邦電子
但在同等帶寬下工作時,HyperRAM可以提供更少的引腳數和更低的功耗,對于不少可穿戴應用來說,采用HyperRAM不僅降低所需的PCB面積,也進一步降低了功耗,提高了這類設備的續航能力。根據華邦電子提供的數據,同樣64MB的內存,HyperRAM可以實現比SDRAM低數十倍的待機功耗。
時至今日,我們已經看到不少頂尖MCU廠商,諸如NXP、瑞薩和TI等,都已經提供了支持HyperBus接口的MCU。新思、Cadence等廠商也開始提供HyperBus控制IP,華邦電子也加入HyperRAM的供應生態鏈中來,HyperRAM已然成了AIoT應用中MCU乃至MPU外部RAM的理想選擇。
寫在最后
無論是HBM還是HyperRAM,都是AI時代下開始發光發熱的內存選擇。他們的出現不僅為市場提供了更靈活的設計選擇,也進一步推動了內存技術在設計、工藝和封裝上的進步。未來隨著內存技術邁入下一個階段,或許不只有AI應用能從中受益。
-
mcu
+關注
關注
146文章
17123瀏覽量
350995 -
AI
+關注
關注
87文章
30731瀏覽量
268893
發布評論請先 登錄
相關推薦

《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
存力與算力并重:數據時代的雙刃劍
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
論RISC-V的MCU中UART接口的重要性
Sora算力需求引發業界對集結國內AI企業算力的探討
夯實算力底座,順網科技算力業務全面升級






 工商網監
工商網監
評論