


2. 摘要
提出了一種基于RGB-D圖像序列的協(xié)同隱式神經(jīng)同步定位與建圖(SLAM)系統(tǒng),該系統(tǒng)由完整的前端和后端模塊組成,包括里程計(jì)、回環(huán)檢測(cè)、子圖融合和全局優(yōu)化。為了在一個(gè)統(tǒng)一的框架中啟用所有這些模塊,我們提出了一種新的基于神經(jīng)點(diǎn)的3D場(chǎng)景表示,其中每個(gè)點(diǎn)都保持用于場(chǎng)景編碼的可學(xué)習(xí)神經(jīng)特征,并且與某個(gè)關(guān)鍵幀相關(guān)聯(lián)。此外,還提出了一種從分布式到集中式的協(xié)作隱式SLAM學(xué)習(xí)策略,以提高一致性和協(xié)調(diào)性。與傳統(tǒng)的光束法平差一樣,本文還提出了一種新的全局優(yōu)化框架來(lái)提高系統(tǒng)精度。在不同數(shù)據(jù)集上的實(shí)驗(yàn)證明了該方法在相機(jī)跟蹤和建圖方面的優(yōu)越性。
3. 算法解析
重新理一下思路,NeRF SLAM為啥火?
因?yàn)镹eRF和SLAM可以相互輔助,SLAM為NeRF訓(xùn)練提供位姿,NeRF可以重建高清晰度的地圖、做空洞補(bǔ)全、或者用光度損失反過(guò)來(lái)優(yōu)化位姿。
有什么問(wèn)題?
個(gè)人感覺(jué)現(xiàn)在NeRF SLAM有兩個(gè)問(wèn)題,一個(gè)是計(jì)算量大難以落地,一個(gè)是因?yàn)樽霾涣嘶丨h(huán)和全局優(yōu)化導(dǎo)致定位精度低。
CP-SLAM的核心思想是什么?
傳統(tǒng)的NeRF地圖不好做回環(huán)和優(yōu)化,但是改成基于點(diǎn)的NeRF地圖,就可以像傳統(tǒng)SLAM那樣去優(yōu)化了!
具體是如何實(shí)現(xiàn)的?
CP-SLAM本身是一個(gè)多機(jī)協(xié)同SLAM,輸入是RGB-D數(shù)據(jù)流,每個(gè)SLAM系統(tǒng)分別執(zhí)行跟蹤和建圖,最后執(zhí)行子地圖融合。每個(gè)SLAM系統(tǒng)都維護(hù)一個(gè)神經(jīng)點(diǎn)輻射場(chǎng),借助3個(gè)MLP(特征融合、顏色場(chǎng)、占用場(chǎng))來(lái)渲染深度圖和顏色圖。通過(guò)計(jì)算光度和幾何損失來(lái)優(yōu)化輻射場(chǎng)和相機(jī)位姿。同時(shí)每個(gè)單獨(dú)的SLAM不斷地用NetVLAD提取關(guān)鍵幀描述子,并發(fā)送到描述子池(有點(diǎn)像ORB-SLAM的關(guān)鍵幀數(shù)據(jù)庫(kù)),中央服務(wù)器檢測(cè)到回環(huán)以后融合子地圖,并執(zhí)行全局BA。最后再做一個(gè)以關(guān)鍵幀為中心的地圖優(yōu)化。
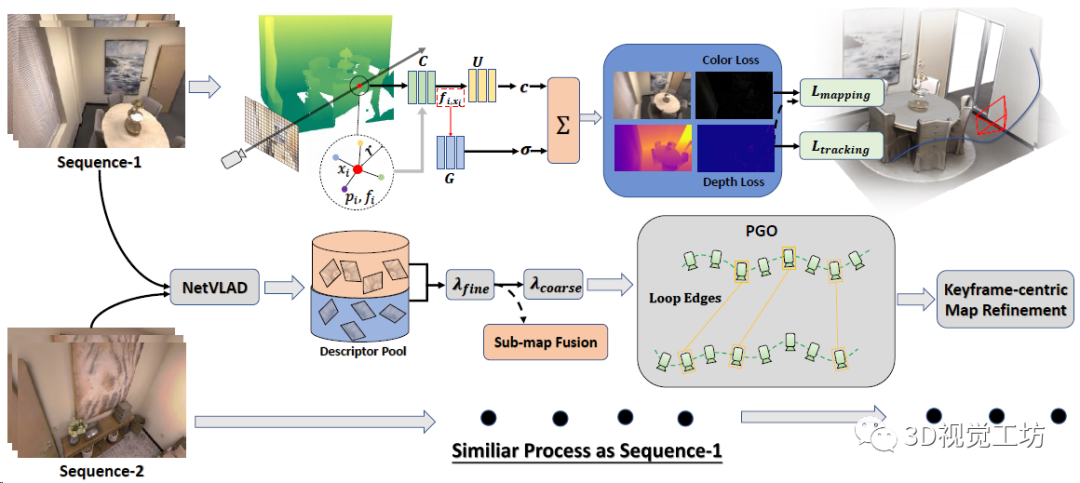
下面來(lái)逐個(gè)聊聊每個(gè)子模塊的具體原理。
這個(gè)神經(jīng)點(diǎn)是啥?
神經(jīng)點(diǎn)輻射場(chǎng)來(lái)源于CVPR 2022 oral的文章Point-NeRF,用神經(jīng)點(diǎn)表示三維場(chǎng)景。其實(shí)就是讓空間中的點(diǎn)同時(shí)存儲(chǔ)位置信息(xyz)和局部場(chǎng)景信息(單層CNN提取的神經(jīng)特征向量,CP-SLAM里是32維),原始Point-NeRF的神經(jīng)點(diǎn)里還存儲(chǔ)了[0, 1]范圍的置信度,表示這個(gè)點(diǎn)有多大概率離真實(shí)物體很近。
當(dāng)然,使用神經(jīng)點(diǎn)輻射場(chǎng)也有優(yōu)點(diǎn)有缺點(diǎn):
優(yōu)點(diǎn):執(zhí)行回環(huán)檢測(cè)和BA優(yōu)化時(shí),3D點(diǎn)比原始NeRF場(chǎng)景更好調(diào)整,所以就很容易引入回環(huán)和局部地圖優(yōu)化。
缺點(diǎn):由于神經(jīng)點(diǎn)分布在觀察對(duì)象的表面周?chē)虼宋匆?jiàn)區(qū)域的空洞填補(bǔ)能力弱于特征網(wǎng)格方法。
位姿跟蹤和NeRF建圖如何進(jìn)行?
輻射場(chǎng)采樣上也用到了一個(gè)trick,就是盡量讓采樣點(diǎn)貼近物體表面。對(duì)于深度有效的點(diǎn),分別從[0.95D, 1.05D]和[0.95Dmin, 1.05Dmax]區(qū)間內(nèi)均勻采樣,D表示點(diǎn)的深度值,Dmin和Dmax表示整個(gè)深度圖的最小最大深度。
對(duì)每個(gè)采樣點(diǎn)xi,首先檢索它半徑r范圍內(nèi)的K個(gè)鄰域點(diǎn),用一個(gè)MLP(框圖中的C)分別處理這K個(gè)點(diǎn),使每個(gè)點(diǎn)的特征向量都融合了跟采樣點(diǎn)的距離信息(對(duì)應(yīng)f~k,x~):
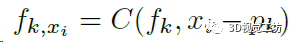
再用一個(gè)MLP(框圖中的U)來(lái)學(xué)習(xí)采樣點(diǎn)xi的RGB信息,這里就需要用到上一步K個(gè)點(diǎn)的特征向量了:
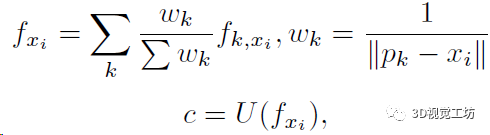
最后還需要用一個(gè)MLP(框圖中的G)來(lái)學(xué)習(xí)采樣點(diǎn)xi的占用概率,這里還是用到上上步計(jì)算的K個(gè)特征向量,當(dāng)然如果沒(méi)有鄰域點(diǎn)那占用肯定就是0了:
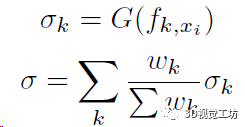
這兩步預(yù)測(cè)的占用和顏色信息實(shí)際上表示了射線中止的概率α,再加上深度值z(mì)就可以渲染得到當(dāng)前視角的深度圖和RGB圖:
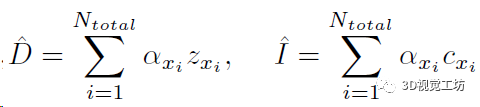
然后就可以使用深度圖和RGB圖計(jì)算幾何損失和光度損失來(lái)優(yōu)化位姿、點(diǎn)特征向量、還有3個(gè)MLP:
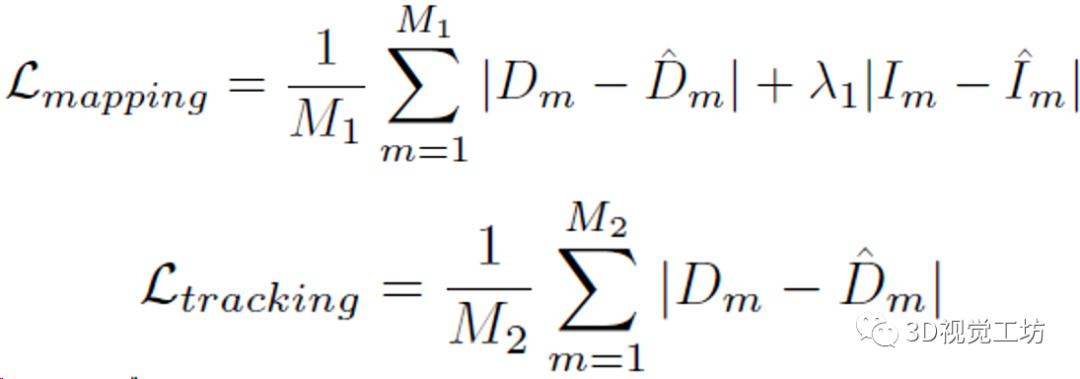
這里還有幾個(gè)需要注意的點(diǎn):
1、整個(gè)序列的第一幀需要采樣很多的點(diǎn)來(lái)初始化,優(yōu)化步驟達(dá)到3000~5000次;
2、位姿表示成四元數(shù)和平移格式,當(dāng)前幀位姿的初始值設(shè)置為上一幀的位姿,優(yōu)化時(shí)要固定神經(jīng)特征向量和3個(gè)MLP權(quán)重;
3、優(yōu)化位姿沒(méi)有用到光度損失,作者認(rèn)為RGB圖是一個(gè)高度非凸問(wèn)題。
基于學(xué)習(xí)的回環(huán)檢測(cè)如何實(shí)現(xiàn)?
這部分主要是用于融合多個(gè)SLAM系統(tǒng)分別建立的子地圖,并減少位姿的累計(jì)漂移。首先對(duì)每個(gè)關(guān)鍵幀用預(yù)訓(xùn)練的NetVLAD提取描述子,并把描述子扔到池子里(類(lèi)似ORB-SLAM的關(guān)鍵幀數(shù)據(jù)庫(kù)),然后用余弦相似性來(lái)檢測(cè)回環(huán)。
局部?jī)?yōu)化很吃初值,如果兩幀運(yùn)動(dòng)太快的話,就很容易陷入局部最優(yōu),所以CP-SLAM采用了一個(gè)由粗到精的回環(huán)檢測(cè)策略。如果相似性超過(guò)λfine的話直接執(zhí)行回環(huán)優(yōu)化和子地圖融合,如果低于λfine但高于λcoarse的話就只做一個(gè)位姿圖優(yōu)化。當(dāng)然子地圖融合之后肯定有大量的冗余點(diǎn),還需要做一步非極大值抑制(網(wǎng)格過(guò)濾)。
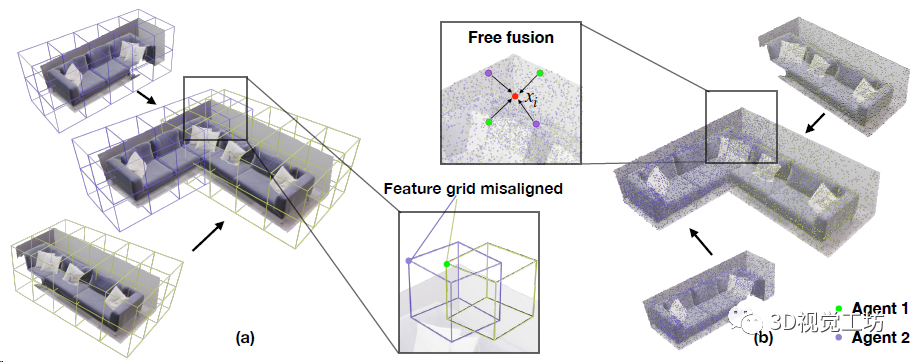
SLAM協(xié)同如何實(shí)現(xiàn)?
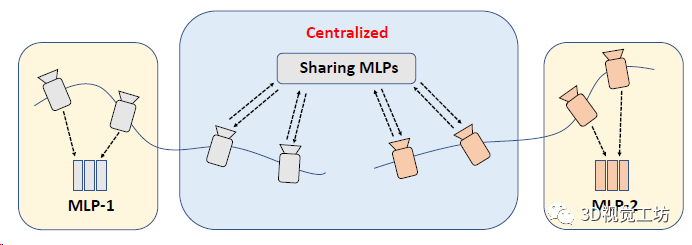
CP-SLAM本身就是一個(gè)協(xié)同SLAM,協(xié)同部分是設(shè)計(jì)了一個(gè)兩階段(從分布式到集中式)的MLP訓(xùn)練策略,來(lái)提高協(xié)作一致性。分布式階段就是每個(gè)SLAM單獨(dú)做跟蹤和優(yōu)化,執(zhí)行回環(huán)和子地圖融合以后就進(jìn)入集中式階段,注意集中式階段需要一個(gè)中心服務(wù)器來(lái)做子圖和優(yōu)化的全局管理。
這個(gè)階段用的是聯(lián)合學(xué)習(xí),也就是以共享的方式訓(xùn)練單個(gè)網(wǎng)絡(luò)。在子地圖融合的同時(shí),對(duì)每組MLP進(jìn)行平均處理,并對(duì)所有關(guān)鍵幀上的平均MLP進(jìn)行微調(diào),隨后將共享MLP轉(zhuǎn)移到每個(gè)SLAM做訓(xùn)練,并且平均每個(gè)SLAM權(quán)重作為共享MLP的最終優(yōu)化結(jié)果。
最后簡(jiǎn)單說(shuō)一下位姿圖優(yōu)化
這個(gè)模塊分為兩部分,一部分是維護(hù)子地圖的共視圖,一部分是是基于幀的地圖優(yōu)化。在執(zhí)行子地圖融合后做全局優(yōu)化,位姿圖中每幀的位姿是頂點(diǎn),序列相對(duì)位姿和回環(huán)相對(duì)位姿是邊,優(yōu)化還是用的L-M算法。
為了方便優(yōu)化3D點(diǎn)云位置,作者還做了一個(gè)trick:每個(gè)3D點(diǎn)都與一個(gè)關(guān)鍵幀相關(guān)聯(lián)。
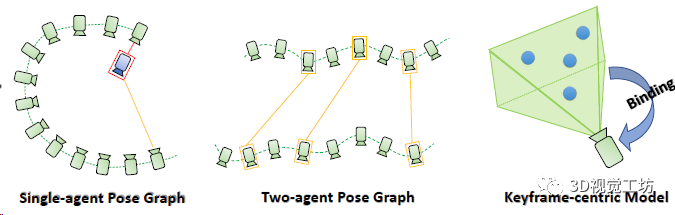
4. 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)這一塊分別對(duì)比了單機(jī)SLAM和協(xié)作SLAM模式,單機(jī)SLAM對(duì)比在Replica數(shù)據(jù)集進(jìn)行,對(duì)比傳統(tǒng)SLAM(ORB-SLAM3)和NeRF SLAM(NICE-SLAM和Vox-Fusion),協(xié)同SLAM對(duì)比的傳統(tǒng)SLAM方案(CCM-SLAM、Swarm-SLAM、ORB-SLAM3)。CP-SLAM的運(yùn)行環(huán)境是一塊3090,如果需要做協(xié)同的話,就再需要一塊3090做為中心服務(wù)器。
雙機(jī)協(xié)作精度的定量對(duì)比,注意ORB-SLAM3本身不是協(xié)作SLAM,所以作者的實(shí)驗(yàn)方法是融合數(shù)據(jù)集,然后用ORB-SLAM3的多地圖系統(tǒng)來(lái)執(zhí)行地圖融合。
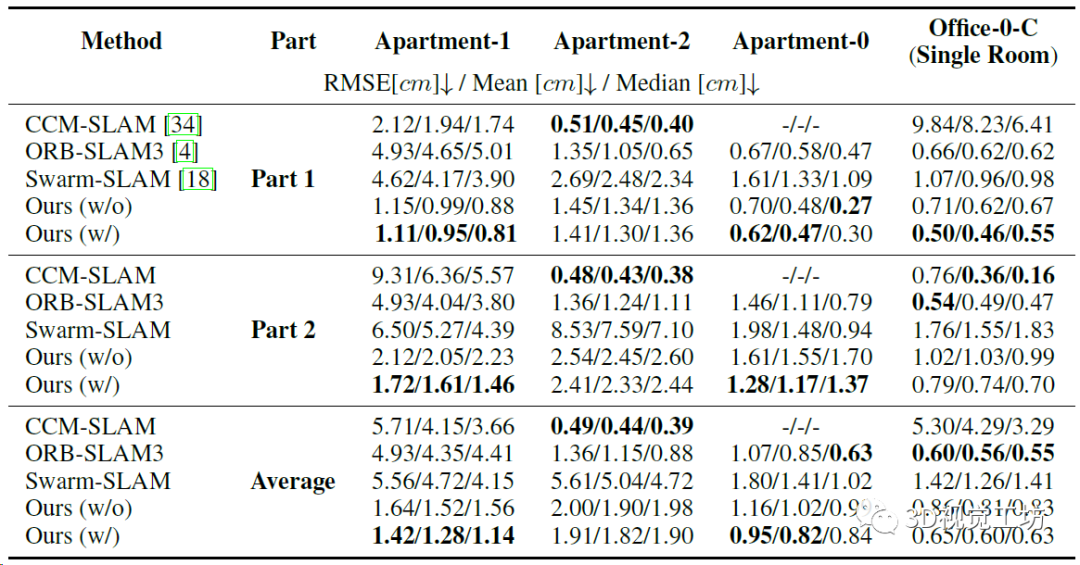
4個(gè)場(chǎng)景上CP-SLAM和CCM-SLAM的協(xié)作實(shí)驗(yàn)軌跡對(duì)比,可以發(fā)現(xiàn)CP-SLAM的地圖融合效果還是比較好的。
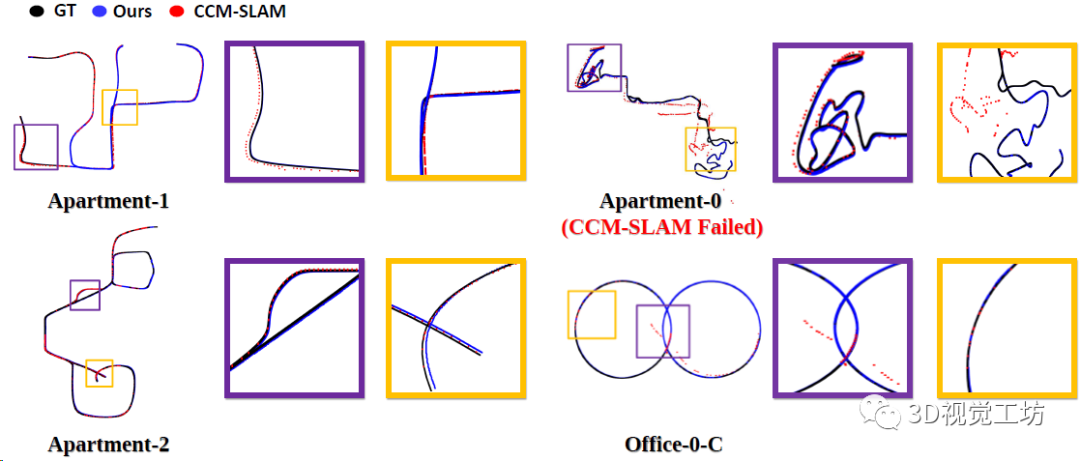
單機(jī)SLAM的精度對(duì)比,這個(gè)就說(shuō)明CP-SLAM的精度超越ORB-SLAM3了。當(dāng)然如果不加入回環(huán)的話,CP-SLAM精度還是不夠,這一點(diǎn)上說(shuō)明限制NeRF SLAM精度提升的關(guān)鍵就在局部地圖優(yōu)化和回環(huán)優(yōu)化。
單機(jī)SLAM軌跡的定性對(duì)比,對(duì)比的NICE-SLAM和Vox-Fusion這兩個(gè)NeRF SLAM方案,沒(méi)有對(duì)比ORB-SLAM3。
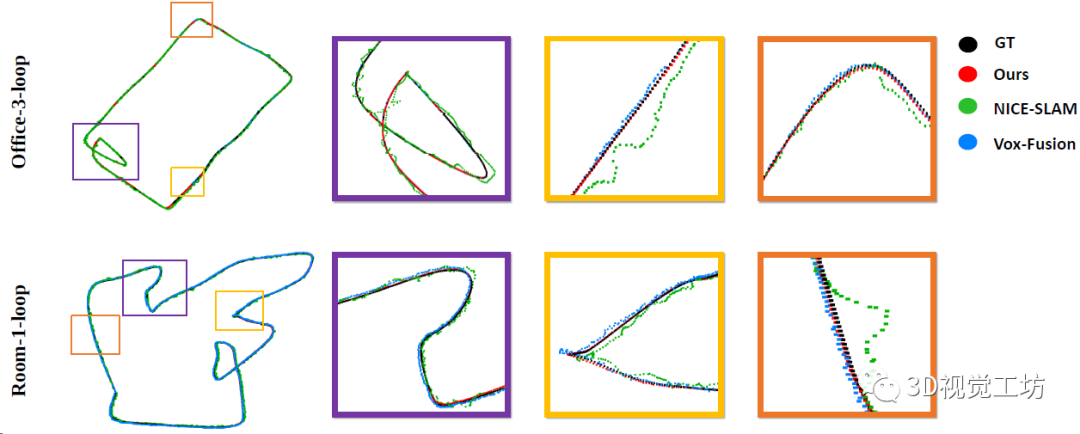
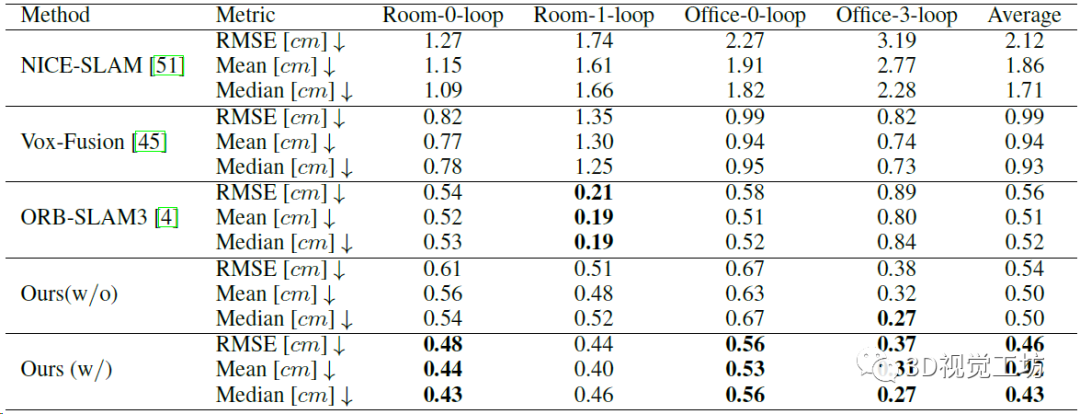
TUM數(shù)據(jù)集上精度和魯棒性的定量對(duì)比,但對(duì)比的還是只有Co-SLAM和ESLAM這兩個(gè)NeRF SLAM方案,沒(méi)對(duì)比ORB-SLAM3。這里也推薦工坊推出的新課程《徹底剖析激光-視覺(jué)-IMU-GPS融合SLAM算法:理論推導(dǎo)、代碼講解和實(shí)戰(zhàn)》。

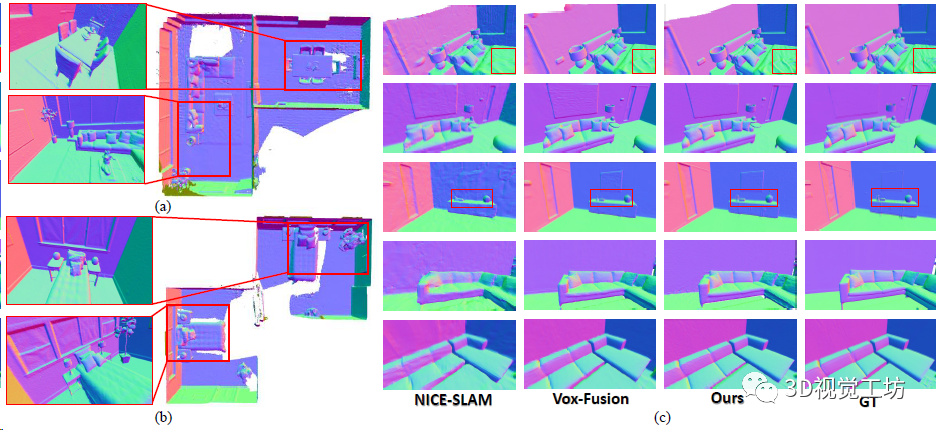
NeRF建圖的定量對(duì)比,證明三維重建的精度超越了之前的NeRF SLAM方案。

NeRF建圖的定性對(duì)比。
神經(jīng)點(diǎn)密度的消融實(shí)驗(yàn),證明神經(jīng)點(diǎn)不是越多越好,也不是越少越好。

Office-0-loop場(chǎng)景上運(yùn)行時(shí)間和內(nèi)存消耗的定量對(duì)比,包括單幀跟蹤時(shí)間、建圖時(shí)間、MLP大小、整個(gè)神經(jīng)場(chǎng)的內(nèi)存大小。NICE-SLAM神經(jīng)場(chǎng)的尺寸超級(jí)大,這是因?yàn)樗鼮榱私鉀Q遺忘問(wèn)題設(shè)計(jì)的多層特征網(wǎng)格。

地圖優(yōu)化和采樣點(diǎn)融合的消融實(shí)驗(yàn),還是驗(yàn)證它們的策略是對(duì)的。

5. 總結(jié)
本文介紹了浙大最新的工作CP-SLAM,號(hào)稱是第一個(gè)基于NeRF的協(xié)作SLAM,跟傳統(tǒng)SLAM一樣具備前后端,定位精度和建圖質(zhì)量都有了很大提升。可惜沒(méi)有開(kāi)源。
審核編輯:劉清
-
RGB
+關(guān)注
關(guān)注
4文章
808瀏覽量
60008 -
CCM
+關(guān)注
關(guān)注
0文章
165瀏覽量
24808 -
SLAM
+關(guān)注
關(guān)注
24文章
444瀏覽量
32530 -
MLP
+關(guān)注
關(guān)注
0文章
57瀏覽量
4640
原文標(biāo)題:NeurlPS'23 | 第一個(gè)協(xié)作神經(jīng)隱式SLAM!(浙大NICE-SLAM團(tuán)隊(duì)最新力作)
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一種適用于動(dòng)態(tài)環(huán)境的實(shí)時(shí)RGB-D SLAM系統(tǒng)

一種適用于動(dòng)態(tài)環(huán)境的3DGS-SLAM系統(tǒng)

【「# ROS 2智能機(jī)器人開(kāi)發(fā)實(shí)踐」閱讀體驗(yàn)】視覺(jué)實(shí)現(xiàn)的基礎(chǔ)算法的應(yīng)用
一種基于點(diǎn)、線和消失點(diǎn)特征的單目SLAM系統(tǒng)設(shè)計(jì)

使用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行時(shí)間序列預(yù)測(cè)
一種基于MASt3R的實(shí)時(shí)稠密SLAM系統(tǒng)
一種降低VIO/VSLAM系統(tǒng)漂移的新方法
利用VLM和MLLMs實(shí)現(xiàn)SLAM語(yǔ)義增強(qiáng)

LSTM神經(jīng)網(wǎng)絡(luò)在圖像處理中的應(yīng)用
LSTM神經(jīng)網(wǎng)絡(luò)在時(shí)間序列預(yù)測(cè)中的應(yīng)用
最新圖優(yōu)化框架,全面提升SLAM定位精度

MG-SLAM:融合結(jié)構(gòu)化線特征優(yōu)化高斯SLAM算法

一種完全分布式的點(diǎn)線協(xié)同視覺(jué)慣性導(dǎo)航系統(tǒng)
一種半動(dòng)態(tài)環(huán)境中的定位方法
一種適用于動(dòng)態(tài)環(huán)境的實(shí)時(shí)視覺(jué)SLAM系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論