 機器學習與PAWS相結合的性能感知系統簡介
機器學習與PAWS相結合的性能感知系統簡介
[概述]
在數據中心,資源利用率指標,尤其是 CPU 利用率常用于量化集群的有效利用程度。在實際環境中,系統給負載分配的資源以及工作負載的調度決策都會影響利用率。
如果工作負載資源分配不準確,集群可能會因空閑而未充分利用。另一方面,如果調度決策不合理,即便是利用率有提升,負載間的資源沖突也會導致性能出現下降。
為了提高資源利用率,同時盡量減少由于干擾導致的性能下降,以保證 QoS,性能感知系統 PAWS(Performance Aware System)應運而生。
PAWS 的愿景是提供一套能夠基于負載特征歷史特征進行資源推薦,同時盡可能避免互相干擾的調度算法。
[特性介紹]
PAWS 主要解決資源精準推薦以及資源干擾的問題,因此其主要圍繞著這兩方面來構建自己的能力。當前 PAWS 主要主要以下兩個特性:
特性一、VPA 資源推薦
算法思想
VPA (Vertical Pod Autoscaler) 是一種自動伸縮技術,通過對分配給微服務的物理資源(CPU、內存等)進行調整,來滿足微服務不斷變化的需求。不同的服務有不同的資源需求,這取決于多個因素,例如一天中的時間、用戶需求等。為這些服務進行固定的資源分配可能會導致集群的資源利用率非常低。
PAWS 提出了一種將經典的數值優化解決方案與當代的機器學習方法相結合的 VPA 推薦算法,通過對負載歷史特征的分析,為工作負載推薦適當的資源,從而釋放多余申請的資源,從而提高集群利用率。
PAWS-VPA 的整體架構如下:
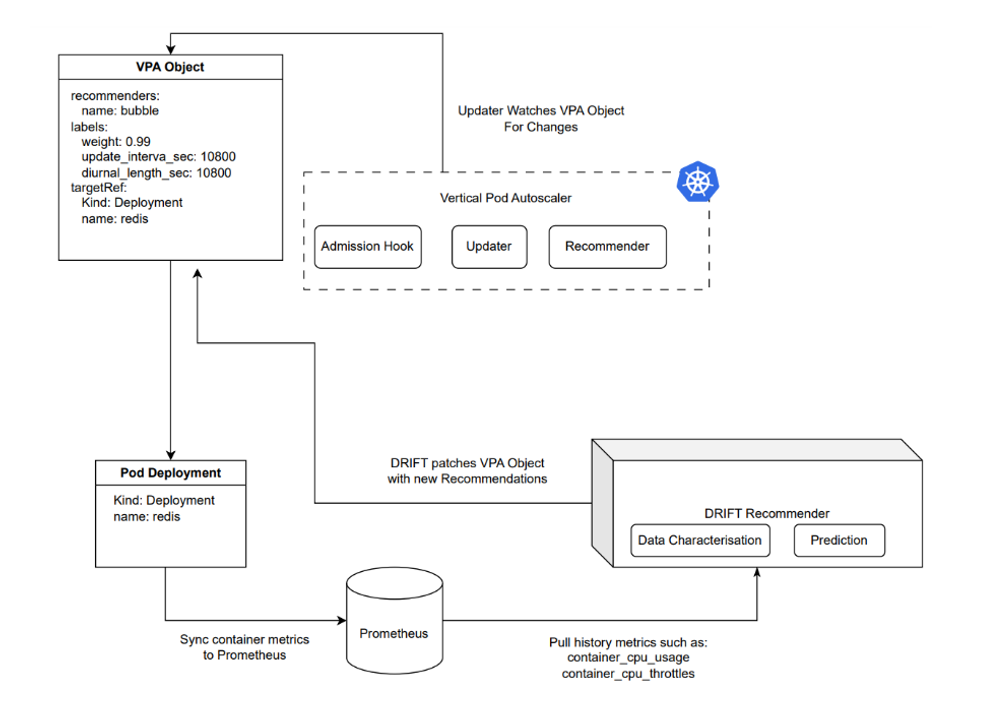
其中 DRIFT Recommender 從 Prometheus 中獲取所需數據,并通過 VPA 推薦算法,給出對應的數據值。其整體算法包括了主動預測,負載感知以及預測反饋三部分:
[ ] 主動預測:預測負載資源,在變化之前給出建議;
[ ] 負載感知:基于歷史數據庫感知負載特征模式,并給出建議;
[ ] 反饋機制:通過運行時的反饋系統,快速糾正不當建議;
整個算法的整體思想為,以過去 N 個時間窗口的 CPU 利用率以及資源執行情況為輸入,每隔一段時間*(k)*進行一次調用,對未來一個或者多個時刻之內,每個容器的 CPU 資源推薦最佳值。
在推薦時,會考慮過往的資源推薦情況,基于過往的 overestimation(過高估計)和 underestimation(過低估計)進行加權,給出最優建議。
在算法中,我們的目標函數(OBJ)是資源高估和低估事件的加權(w)平均值。在這里,
[ ] 高估(overestimation)是指 CPU 的建議高于實際 CPU 利用率,導致整體利用率偏低;
[ ] 低估(underestimation)指的是 CPU 建議低于 CPU 利用率導致 throttle 事件,會導致負載性能下降;
數學上,OBJ=w x UE+(1-w)x OE,其中 w 是分配給低估相對于高估的重要性或權重。
模塊組成
整個 PAWS-VPA 推薦算法共包含三個模塊:負載表征,數值優化以及機器學習預測。
負載表征(Workload Characterization):分析過去的 CPU 利用率特征,以給出合理的 OBJ 權重 w
數值優化(Numerical Optimization):使用經典的數值優化來計算過去 M 個時間段內的最優推薦。具體來說,我們最小化 OBJ 以獲得過去樣本的最優目標推薦,并將這個最小化問題描述為混合整數線性規劃(Mixed Integer Linear Program,MILP).
機器學習預測(Machine Learning Forecast):在 MILP 計算出過去 M 個時間間隔的目標值后,本模塊將這 M 個最佳歷史推薦作為輸入,并根據機器學習算法中定義的預測水平 F 預測下一個(一個或多個)更新間隔的最佳未來推薦。
特性二、時序沖突檢測調度
算法思想
PAWS 開發了一套調度插件,通過利用負載歷史數據中提取的資源利用率并進行時序分析統計,并讓調度器基于該統計對負載進行錯峰填谷,避免資源沖突的同時實現更高的資源分配。其使用了中的機制,對于系統中標記的進行資源的采集。通過收集作業容器的歷史資源使用情況,分析時間序列周期(如每小時),輸出每個周期周期的預估資源利用率,從而避免作業資源沖突,最終實現錯峰補谷的調度,提升集群資源利用率。
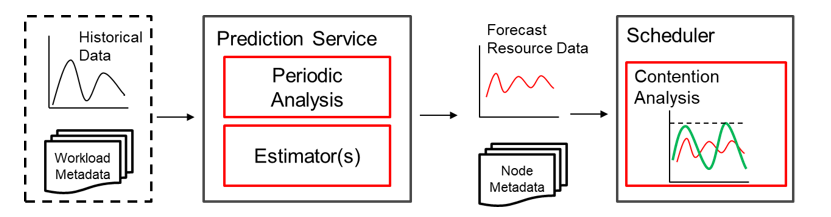
算法流程
整個算法分為預測和調度兩個部分,其中預測主要基于每種負載的歷史數據,統計其時序變化情況,以供調度器使用;調度則基于上述信息,結合新任務的特征情況,給出合理的調度決策。
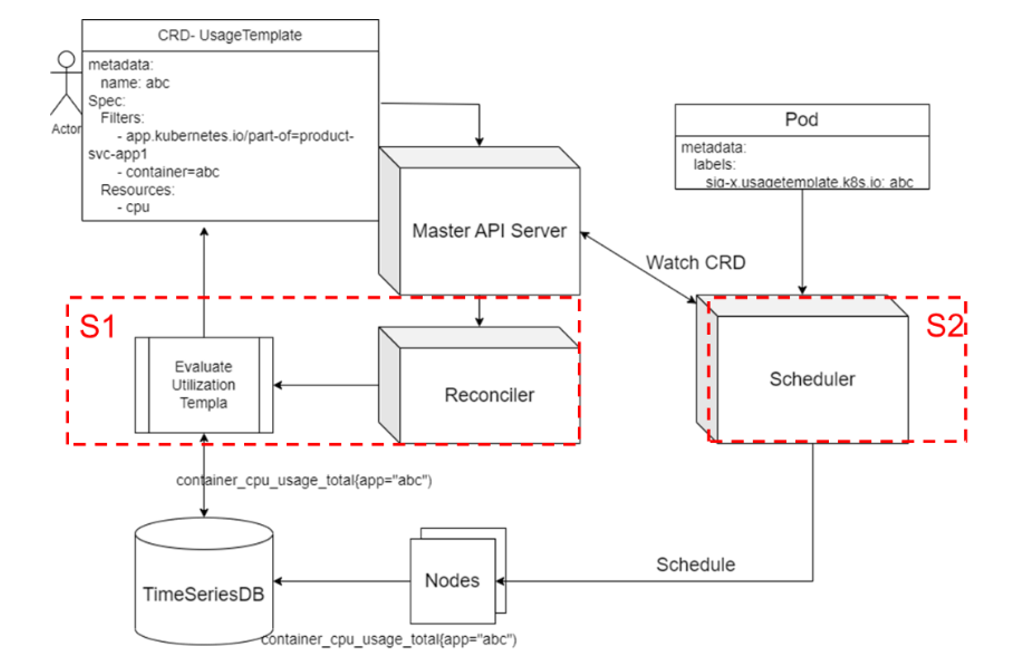
預測流程:通過 Prometheus 等時序數據庫,讀取每個已知負載的資源利用率歷史數據點,分析出小時維度的變化情況,并保存為歷史數據,以供調度器參考。
調度流程:對于新來的任務,基于任務標簽來判斷具體策略。對于已知任務,從調度器中選取歷史模板,與每個節點歷史數據進行疊加求和;對于未知任務,則基于任務資源 request 與節點數據進行疊加求和。在 Scoring 階段,當存在任務運行周期階段超過閾值的可能性,進行不同的打分并歸一。于此同時,系統對于未知任務會實時統計其資源利用率,確保后續該任何再次被拉起時可能進行更精確的打分。
[結果評估]
文中所述的 Performance Aware System 通過機器學習與數理分析手段,對負載資源的分配與調度進行優化。我們在實驗室場景下模擬了包括 Redis,Nginx 和 Torchserve 等在內的一些典型應用,并通過搭建 10 臺服務器的小型集群進行驗證。通過測試發現,集群整體利用率在部署前后出現明顯的提升。下圖為其中某一個節點的利用率變化情況,該節點的峰值利用率從 30%提升到了 40%以上。
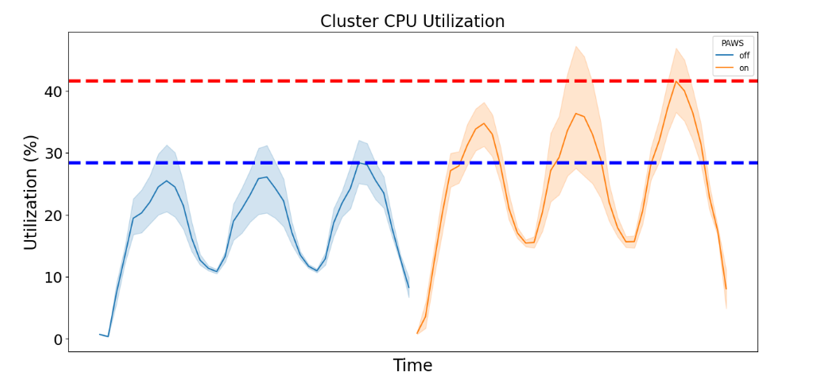
我們同時對部署前后的業務性能變化進行了對比,發現 P99 時延劣化在 10%以內,證明了算法在提升集群利用率的同時也能有效避免性能出現下降。
| 任務名稱 | 負載類型 | P99 時延(前) | P99 時延(后) | 性能劣化 |
|---|---|---|---|---|
| Ngix | CPU / Net 密集型 | 437.7 | 447.6 | 2% |
| Redis | Memory 密集型 | 0.019 | 0.021 | 10% |
| Torchserve | CPU 密集型 | 316.2 | 302.2 | 0% |
目前本特性代碼已在 openEuler Cloud Native SIG 進行開源,地址為:https://gitee.com/openeuler/paws
于此同時,本方案仍然存在一些不夠完美的地方,比如當前本方案主重點瞄準 CPU 計算密集型場景,但是在實際場景中,內存以及 IO 可能都成為影響業務的瓶頸點,同時資源競爭導致的性能下降也很難 100%從利用率的角度進行監控。因此也希望對該技術方向有興趣的伙伴能加入該 SIG,對 PAWS 進行持續優化。
審核編輯:黃飛
-
cpu
+關注
關注
68文章
10854瀏覽量
211587 -
算法
+關注
關注
23文章
4607瀏覽量
92840 -
數據中心
+關注
關注
16文章
4761瀏覽量
72034 -
數據庫
+關注
關注
7文章
3794瀏覽量
64362 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565
原文標題:openEuler 資源利用率提升之道 07:PAWS 性能感知系統簡介
文章出處:【微信號:openEulercommunity,微信公眾號:openEuler】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人工智能感知技術是安防機器人應用支撐技術之一
安森美智能感知技術對三大應用領域發展有什么影響?
智能感知怎么助力機器視覺發展?
基于虛擬儀器的智能感知專家系統的設計
基于虛擬儀器的智能感知專家系統的設計
智能感知的發展現狀_智能感知的未來
最新機器學習工具對材料進行計算建模相結合
LSTM和注意力機制相結合的機器學習模型

NVIDIA發布高性能感知技術的最新項目






 工商網監
工商網監
評論