") AWS成為第一個(gè)提供NVIDIA GH200 Grace Hopper超級(jí)芯片的提供商
AWS成為第一個(gè)提供NVIDIA GH200 Grace Hopper超級(jí)芯片的提供商
2023年的AWS re:Invent大會(huì)上,AWS和NVIDIA宣布AWS將成為第一個(gè)提供NVIDIA GH200 Grace Hopper超級(jí)芯片的云服務(wù)提供商。這一超級(jí)芯片通過NVIDIA DGX Cloud與NVIDIA NVLink技術(shù)相連,將在Amazon Elastic Compute Cloud(Amazon EC2)上運(yùn)行,為云計(jì)算帶來了一場技術(shù)革命。
一)大殺器NVIDIA GH200 NVL32
NVIDIA GH200 NVL32 是針對 NVIDIA GH200 Grace Hopper 超級(jí)芯片的機(jī)架級(jí)參考設(shè)計(jì),通過 NVLink 連接,面向超大規(guī)模數(shù)據(jù)中心。支持 16 個(gè)與 NVIDIA MGX 機(jī)箱設(shè)計(jì)兼容的雙 NVIDIA Grace Hopper 服務(wù)器節(jié)點(diǎn),并且可以采用液體冷卻,以最大限度地提高計(jì)算密度和效率。
NVIDIA GH200 NVL32 的主要特點(diǎn)如下:
●擁有 32 個(gè) GPU NVLink 域,每個(gè) GPU NVLink 域包含一個(gè) GH200 Grace Hopper 超級(jí)芯片,可以訪問網(wǎng)絡(luò)中任何其他 Grace Hopper 超級(jí)芯片的內(nèi)存,從而提供 19.5 TB 的 NVLink 可尋址內(nèi)存。這意味著它可以突破單個(gè)系統(tǒng)的內(nèi)存限制,實(shí)現(xiàn)更大的并行性和可擴(kuò)展性。
●使用 9 個(gè) NVLink 交換機(jī),每個(gè)交換機(jī)包含一個(gè)第三代 NVSwitch 芯片,將 32 個(gè) GH200 GPU 連接在一起,形成一個(gè)完全連接的胖樹網(wǎng)絡(luò)。這意味著它可以實(shí)現(xiàn)高速的通信和低延遲的同步,提高人工智能的性能和效率。
●由 NVIDIA HPC SDK 以及全套 CUDA、NVIDIA CUDA-X 和 NVIDIA Magnum IO 庫支持,可加速超過 3,000個(gè) GPU 應(yīng)用程序。這意味著它可以提供豐富的軟件生態(tài)系統(tǒng),讓開發(fā)者和研究者可以輕松地開發(fā)和部署人工智能應(yīng)用程序。
二)NVIDIAGH200 NVL32的應(yīng)用場景
NVIDIA GH200 NVL32 非常適合以下幾種人工智能應(yīng)用場景:
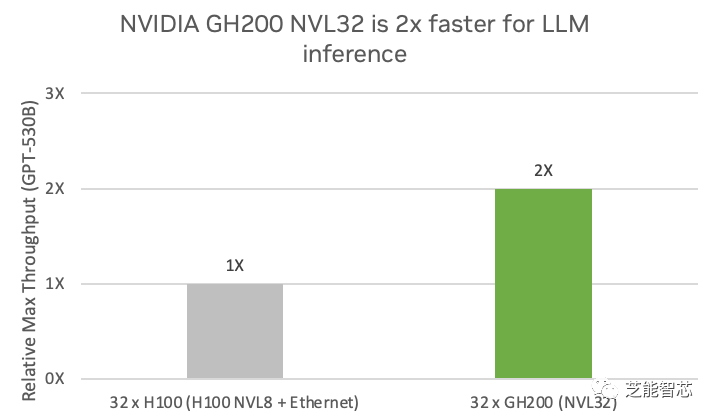
1)AI推理和訓(xùn)練:生成式人工智能模型可以根據(jù)給定的文本或上下文生成自然語言,廣泛應(yīng)用于聊天機(jī)器人、文本摘要、文本生成、機(jī)器翻譯等領(lǐng)域,為用戶提供智能的交互和服務(wù)。法學(xué)碩士需要大規(guī)模、多 GPU 訓(xùn)練,參數(shù)數(shù)量非常龐大,例如 GPT-3 有 1750 億個(gè)參數(shù),GPT-4 有 1.5 萬億個(gè)參數(shù)。NVIDIA GH200 NVL32 專為推理和訓(xùn)練下一代法學(xué)碩士而構(gòu)建。該系統(tǒng)利用 32 個(gè) NVLink 連接的 GH200 Grace Hopper 超級(jí)芯片突破了內(nèi)存、通信和計(jì)算瓶頸,訓(xùn)練萬億參數(shù)模型的速度比 NVIDIA HGX H100 快 1.7 倍 以上。在 GPT-530B 推理模型上,NVIDIA GH200 NVL32 系統(tǒng)的性能比四個(gè) H100 NVL8 系統(tǒng)高出 2 倍。
2)推薦系統(tǒng):人工智能模型可以根據(jù)用戶的偏好和行為,向用戶推薦最相關(guān)和最感興趣的內(nèi)容或產(chǎn)品。它們廣泛用于電子商務(wù)和零售、媒體和社交媒體、數(shù)字廣告等領(lǐng)域,以實(shí)現(xiàn)內(nèi)容個(gè)性化。
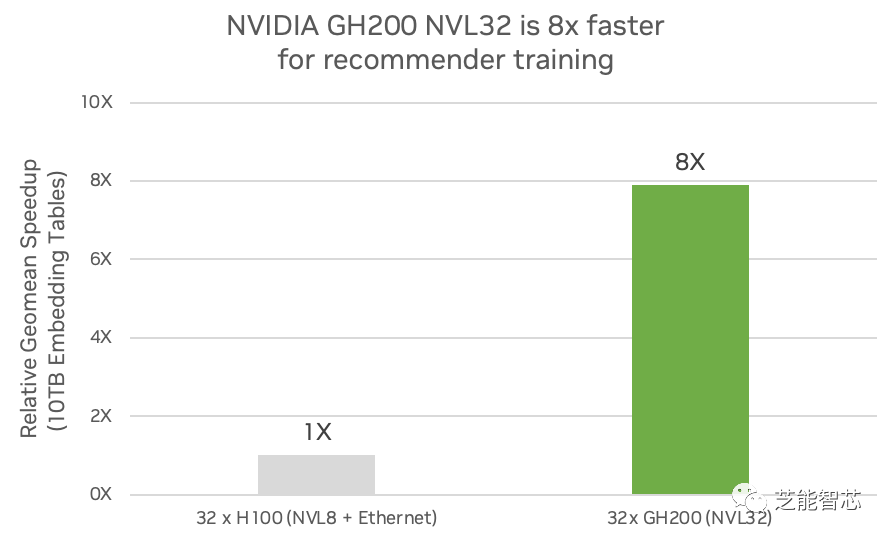
這推動(dòng)了收入和商業(yè)價(jià)值。推薦器使用代表用戶、產(chǎn)品、類別和上下文的嵌入,大小可達(dá)數(shù)十 TB。高度準(zhǔn)確的推薦器將提供更具吸引力的用戶體驗(yàn),但也需要更大的嵌入和更精確的推薦器。嵌入對于人工智能模型具有獨(dú)特的特征,需要大量內(nèi)存、高帶寬和閃電般快速的網(wǎng)絡(luò)。NVIDIA GH200 NVL32 可提供 7 倍 的快速訪問內(nèi)存,并且與基于 x86 的傳統(tǒng)設(shè)計(jì)中與 GPU 的 PCIe Gen5 連接相比,可提供 7 倍 的帶寬。與采用 x86 的 H100 相比,它可以實(shí)現(xiàn) 7 倍 詳細(xì)的嵌入。NVIDIA GH200 NVL32 還可以為具有大量嵌入表的模型提供高達(dá) 7.9 倍 的訓(xùn)練性能。
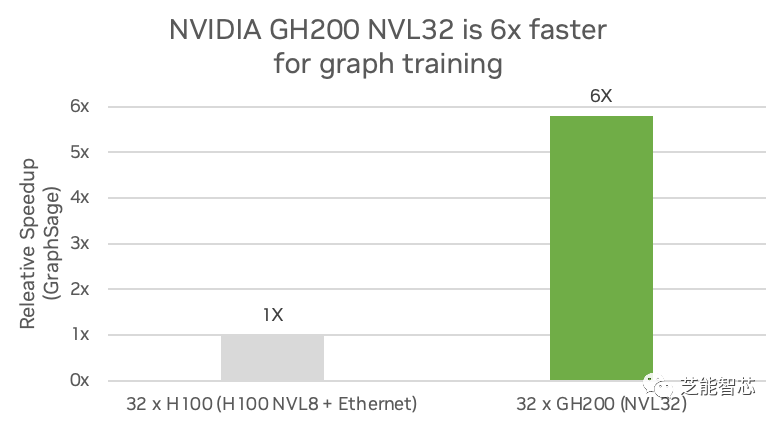
3)圖神經(jīng)網(wǎng)絡(luò):圖神經(jīng)網(wǎng)絡(luò)是一種人工智能模型,可以將深度學(xué)習(xí)的預(yù)測能力應(yīng)用于豐富的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)將對象及其關(guān)系描述為圖中由線連接的點(diǎn)。科學(xué)和工業(yè)的許多分支已經(jīng)將有價(jià)值的數(shù)據(jù)存儲(chǔ)在圖數(shù)據(jù)庫中。深度學(xué)習(xí)用于訓(xùn)練預(yù)測模型,從圖表中挖掘新的見解。
總結(jié):
Amazon和NVIDIA推動(dòng)NVIDIA DGX Cloud即將在AWS上推出,將成為首家在DGX云中提供NVIDIA GH200 NVL32,并將其作為EC2實(shí)例的云服務(wù)提供商。NVIDIA GH200 NVL32解決方案包含32個(gè)GPU NVLink域和19.5 TB的大容量統(tǒng)一內(nèi)存。在GPT-3的訓(xùn)練和LLM推理方面明顯優(yōu)于先前的模型。NVIDIA GH200 NVL32的CPU-GPU內(nèi)存互連速度非常快,提高了應(yīng)用程序的內(nèi)存可用性。該技術(shù)是超大規(guī)模數(shù)據(jù)中心可擴(kuò)展設(shè)計(jì)的一部分,由NVIDIA軟件和庫提供支持,可加速數(shù)千個(gè)GPU應(yīng)用程序。NVIDIA GH200 NVL32特別適用于LLM訓(xùn)練和推理、推薦系統(tǒng)、GNN等任務(wù),為人工智能和計(jì)算應(yīng)用程序帶來顯著的性能改進(jìn)。
審核編輯:劉清
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4978瀏覽量
102990 -
GPT
+關(guān)注
關(guān)注
0文章
352瀏覽量
15343 -
超級(jí)芯片
+關(guān)注
關(guān)注
0文章
34瀏覽量
8876 -
AWS
+關(guān)注
關(guān)注
0文章
431瀏覽量
24355 -
GPU芯片
+關(guān)注
關(guān)注
1文章
303瀏覽量
5804
原文標(biāo)題:NVIDIA GH200 NVL32在AWS里落地
文章出處:【微信號(hào):QCDZSJ,微信公眾號(hào):汽車電子設(shè)計(jì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
NVIDIA GB200超級(jí)芯片引領(lǐng)液冷散熱新紀(jì)元
NVIDIA AI Enterprise榮獲金獎(jiǎng)

亞馬遜AWS暫緩采購英偉達(dá)GH200芯片,期待Blackwell更強(qiáng)
亞馬遜未中斷英偉達(dá)訂單,等待Grace Blackwell更強(qiáng)性能
SiPearl更新Rhea1處理器規(guī)格,聚焦HPC與AI推理應(yīng)用
NVIDIA Grace Hopper點(diǎn)亮AI超級(jí)計(jì)算新時(shí)代
NVIDIA通過CUDA-Q平臺(tái)為全球各地的量子計(jì)算中心提供加速
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
美國首個(gè)Grace Hopper架構(gòu)超算Venado落地:達(dá)10 exaFLOPS
NVIDIA推出搭載GB200 Grace Blackwell超級(jí)芯片的NVIDIA DGX SuperPOD?
NVIDIA 推出 Blackwell 架構(gòu) DGX SuperPOD,適用于萬億參數(shù)級(jí)的生成式 AI 超級(jí)計(jì)算






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論