 AXI通道讀寫DDR的阻塞問題?
AXI通道讀寫DDR的阻塞問題?
Q1
基于vivado2020.1和zcu102開發板(rev1.1)開發項目,工程涉及DDR4(MIG)和PL端多個讀寫接口交互的問題,通過AXI interconnect進行互聯和仲裁(采用默認配置)。一個完整控制周期內(約100ms),各端口讀寫情況如下(AWSIZE均為4):
AXI1:只寫入,AWLEN=119,每次寫請求共計4320次突發寫,完整控制周期內1次讀請求
AXI2:讀寫,ARLEN=35,AWLEN=3,每次讀請求共計56-232次突發讀,寫請求共計192-384次突發寫,完整控制周期內讀寫請求各176次
AXI3:讀寫,ARLEN=5-6,AWLEN=3,每次讀請求共計56-232次突發讀,寫請求共計192-384次突發寫,完整控制周期內讀寫請求各60次
AXI4:讀寫,ARLEN=7,AWLEN=127,每次讀請求共計320-1152次突發讀,寫請求共計62-128次突發寫,完整控制周期內1次寫請求,48次讀請求
AXI5:只讀,ARLEN=127,每次讀請求共計3240次突發讀,該模塊是HDMI顯示模塊(1920*1080*3)的輸入,頻率為60Hz,它的讀操作是獨立于控制周期的
AXI3與AXI4的讀會同時請求相同內存區域的數據,AXI4的寫與AXI5的讀會訪問相同內存區域的數據。
AXI2-AXI4是計算模塊的輸入輸出接口,設計之初默認DDR讀寫速度遠高于計算速度,DDR讀寫會先于計算完成。因此在設計計算模塊控制邏輯的時候,沒有考慮ddr讀寫相關的握手信號。但在實際驗證過程中,各通道會隨機出現阻塞,因此會導致DDR讀寫地址乃至控制邏輯的錯亂。
經過估算DDR帶寬是遠高于讀寫數據帶寬的,為了解決這一問題,包括但不限于改變突發長度、調整AXI interconnect仲裁優先級等操作中的哪些會起到作用?
以及,一般涉及DDR讀寫仲裁的控制邏輯需要注意哪些方面?
注:控制邏輯產生的問題是,以AXI2為例,它的176次讀寫是分為176個子階段完成的,階段1首先讀取第1批讀數據后,開始對第1批數據進行計算,同時開始讀取第2批數據。之前默認讀一定快于計算,所以以計算完成作為狀態轉移的標志,在計算完成后發出第1批數據的寫請求后,進入第2階段的邏輯。在該階段計算第2批數據的同時,讀入第3批數據,并完成第1批數據的寫入。同樣默認讀寫一定快于計算,在計算完成后,發出第2批數據的寫請求,并進入第3階段。阻塞會導致讀數據晚于計算完成,在此情況下,所有的控制邏輯都會發生錯亂,DDR的讀寫地址將不受預期的控制。
A:
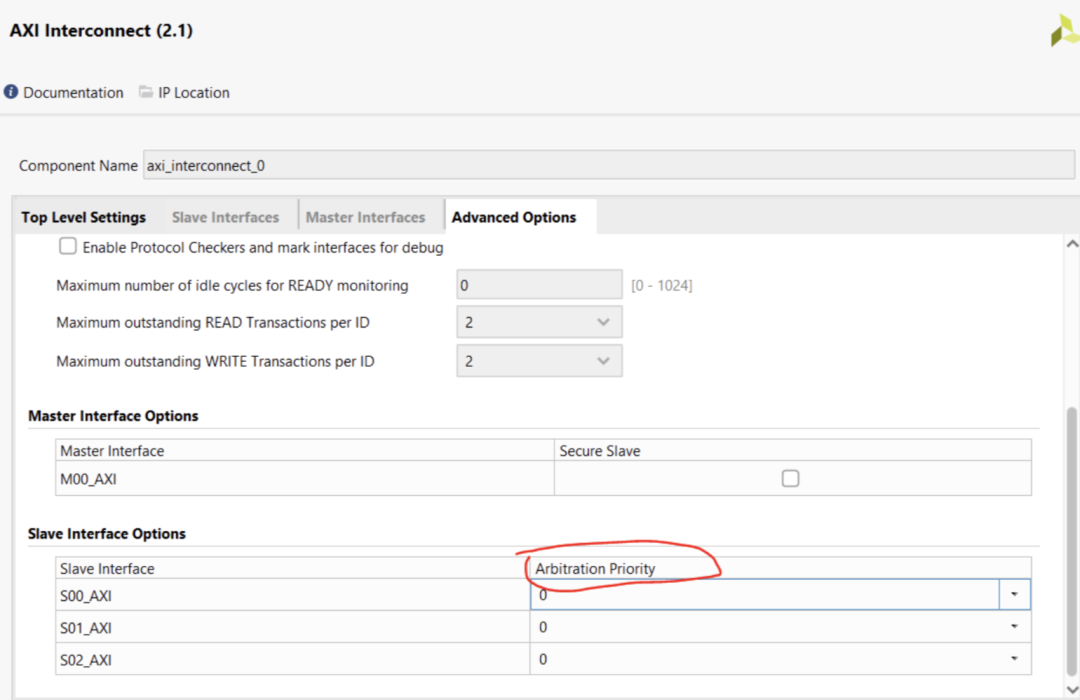
通常如果你多個端口同時訪問DDR,就會發生阻塞,你可以通過設置priority的方式(如下圖),設置優先的通道。
并且建議你的optimization strategic設置成 Maximum Performance,提高interconnect本身的時鐘頻率。
關于 DDR(MIG),如果你都是地址隨機讀寫的話,并且長度一致的話,DDR效率可以變得很低,這是你的系統設計需要注意的。
有關DDR的效率問題,可以到IP應用的板塊進一步咨詢。
審核編輯:劉清
-
HDMI
+關注
關注
32文章
1694瀏覽量
151864 -
DDR
+關注
關注
11文章
712瀏覽量
65318 -
AXI總線
+關注
關注
0文章
66瀏覽量
14261
原文標題:《Vivado那些事兒》多AXI通道讀寫DDR的阻塞問題?
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用AXI-Full接口的IP進行DDR的讀寫測試
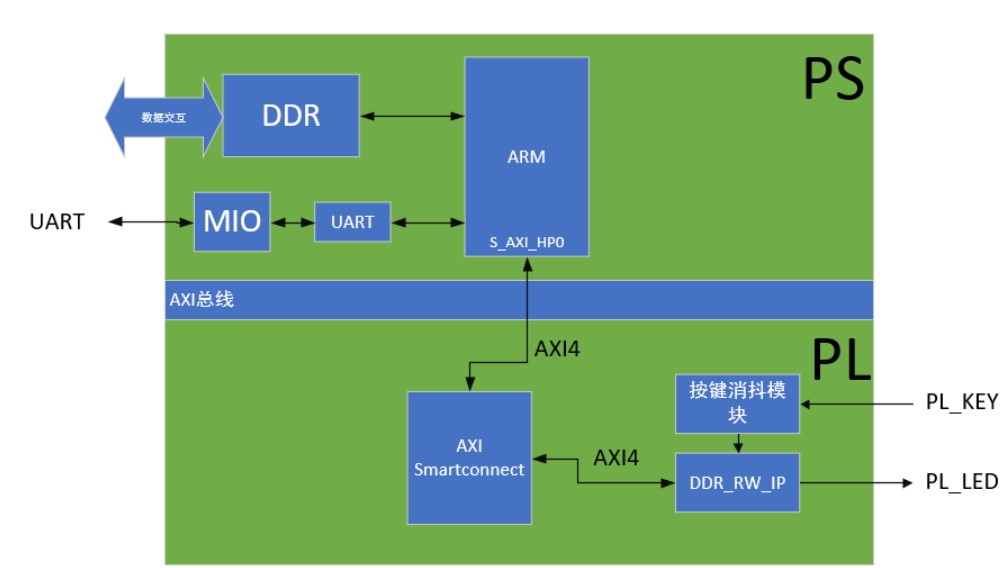
有關PL端利用AXI總線控制PS端DDR進行讀寫(從機wready信號一直不拉高)
基于FPGA的DDR3六通道讀寫防沖突設計
玩轉Zynq連載37——[ex56] 基于Zynq的AXI HP總線讀寫實例
【正點原子FPGA連載】第九章AXI4接口之DDR讀寫實驗--摘自【正點原子】達芬奇之Microblaze 開發指南
DMA內部寄存器的讀寫方式和應用場合
AXI4協議的讀寫通道結構
關于期貨行情數據加速處理中基于FPGA的DDR3六通道讀寫防沖突設計詳解
使用AXI performance monitors(APM)測試MPSoC DDR訪問帶寬
握手機制、通道依賴性及AXI-Lite握手實例






 工商網監
工商網監
評論