 開源LLM在各種基準上的代理能力
開源LLM在各種基準上的代理能力
作者:cola
自2022年底ChatGPT發布以來,其已經在人工智能的整個領域帶來了翻天覆地的變化。通過對大型語言模型(LLM)進行指令微調,并從人類反饋中進行監督微調和強化學習,表明模型可以回答人類問題并在廣泛的任務中遵循指令。在這一成功之后,對LLM的研究興趣增強了,新的LLM在學術界和工業界頻繁蓬勃發展。雖然非開源LLM(例如,OpenAI的GPT, Anthropic的Claude)通常優于它們的開源同行,但后者的進展很快。這對研究和商業都有至關重要的影響。在ChatGPT成立一周年之際,本文對這類LLMs進行了詳盡的介紹。

就在一年前,OpenAI發布的ChatGPT席卷了AI社區和廣泛的世界。這是第一次,基于應用程序的人工智能聊天機器人可以為大多數問題提供有用的、安全的和詳細的答案,遵循指示,甚至承認和修復以前的錯誤。值得注意的是,它可以執行傳統上由預訓練然后定制的微調語言模型完成的任務,如摘要或問答(QA)。作為同類應用中的第一個,ChatGPT吸引了普通大眾的關注,它在發布后的兩個月內就達到了1億用戶,比其他流行應用如TikTok或YouTube快得多。它還吸引了巨大的商業投資,因為它具有降低勞動力成本、自動化工作流程甚至為客戶帶來新體驗的潛力。
由于ChatGPT不是開源的,而且它的訪問權限是由一家私人公司控制的,所以它的大部分技術細節仍然未知。盡管聲稱它遵循InstructGPT(也稱為GPT-3.5)中介紹的過程,但其確切的架構、預訓練數據和微調數據是未知的。這種閉源特性產生了幾個關鍵問題。
在不知道預訓練和微調程序等內部細節的情況下,很難正確估計其對社會的潛在風險,特別是知道LLM可以產生有毒、不道德和不真實的內容。
有報道稱,ChatGPT的性能隨著時間的推移而變化,妨礙了可重復性的結果。
ChatGPT經歷了多次宕機,其中最主要的兩次宕機發生在2023年11月,當時對ChatGPT網站及其API的訪問被完全阻斷。
采用ChatGPT的企業可能會擔心API調用的巨大成本、服務中斷、數據所有權和隱私問題,以及其他不可預測的事件,如最近關于董事會解雇CEO Sam Altman以及最終他回歸的戲劇性事件。
而開源LLM提供了一個有希望的方向,因為它們可以潛在地修復或繞過上述大多數問題。因此,研究界一直積極推動在開源中維護高性能的LLM。然而,從今天的情況來看(截至2023年底),人們普遍認為開源LLM,如Llama-2或Falcon,落后于它們的非開源同行,如OpenAI的GPT3.5(ChatGPT)和GPT-4,Anthropic的Claude2或谷歌的Bard3,通常認為GPT-4是它們的冠軍。
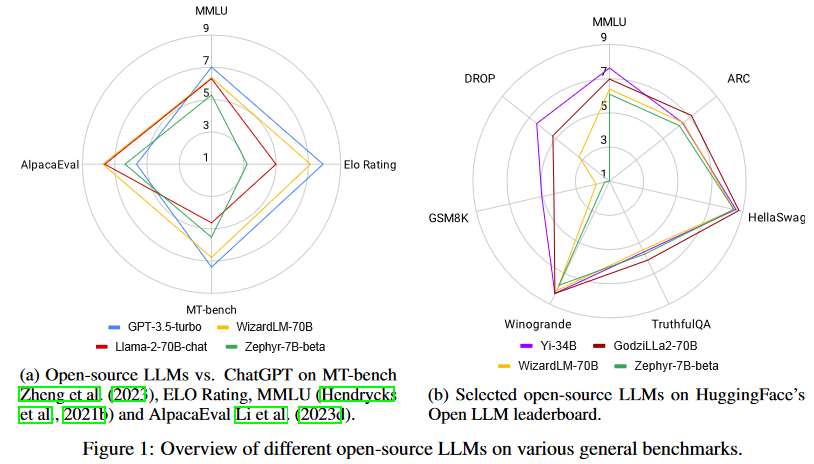
然而,令人鼓舞的是,差距越來越小,開源LLM正在迅速趕上。事實上,正如圖1所示,最好的開源LLM在一些標準基準上的性能已經優于GPT-3.5-turbo。然而,對于開源LLM來說,這并不是一場簡單的艱苦戰斗。情況在不斷發展:非開源LLM通過定期對更新的數據進行再訓練來更新,開源LLM也不斷更新以趕上形勢變化,并且有無數的評估數據集和基準被用于比較LLM,這使得挑選出一個最好的LLM特別具有挑戰性。
背景
訓練方法
預訓練
所有LLM都依賴于在互聯網文本數據上進行大規模的自監督預訓練。僅解碼器的LLM遵循因果語言建模目標,通過該目標,模型學習根據之前的token序列預測下一個token。根據開源LLM分享的預訓練細節,文本數據的來源包括CommonCrawl、C4、GitHub、Wikipedia、書籍和在線討論,如Reddit或StackOverFlow。人們普遍認為,擴展預訓練語料庫的大小可以提高模型的性能,并與擴展模型大小密切相關,這種現象被稱為縮放定律。現代的LLM在數千億到數萬億token的語料庫上進行預訓練。
微調
微調的目的是通過使用可用的監督來更新權重,使預訓練的LLM適應下游任務,這些監督通常時比預訓練使用的數據集小一個量級的數據集。T5是最早將微調框架構建為文本到文本統一框架的之一,用自然語言指令描述每個任務。指令微調后來通過在幾個任務上聯合訓練擴展了微調,每個都用自然語言指令進行描述。指令微調迅速流行起來,因為它能夠大幅提高LLM的零樣本性能,包括在unseen任務上,特別是在更大的模型規模上。使用多任務監督微調(通常稱為SFT)的標準指令微調仍然可以保證模型在安全、道德和無害的同時遵循人類意圖,并可以通過從人類反饋中強化學習(RLHF)進一步改進。
RLHF指的是人類標注者對微調模型的輸出進行排序,用于通過強化學習再次微調。最近的工作表明,人類反饋可以被LLM的反饋取代,這一過程稱為從人工智能反饋中強化學習(RLAIF)。直接偏好優化(DPO)繞過了像RLHF那樣將獎勵模型擬合人類偏好的需要,而是用交叉熵目標直接微調策略,實現了LLM與人類偏好的更有效對齊。
在構建不同任務的指令微調數據集時,重點是質量而不是數量:Lima僅在1000個示例上微調Llama-65B,表現優于GPT-3,而Alpagasus通過將其指令微調數據集從52k清理到9k,對Alpaca進行了改進。
再次預訓練
再預訓練包括從預訓練的LLM執行另一輪的預訓練,通常比第一階段的數據量更少。這樣的過程可能有助于快速適應新領域或在LLM中引出新屬性。例如,對Lemur進行再次預訓練,以提高編碼和推理能力,對Llama-2-long進行擴展上下文窗口。
推理
存在幾種使用LLM進行自回歸解碼的序列生成的替代方法,它們的區別在于輸出的隨機性和多樣性程度。在采樣期間增加溫度使輸出更加多樣化,而將其設置為0則會退回到貪婪解碼,這在需要確定性輸出的場景中可能需要。采樣方法top-k和top-p限制了每個解碼步驟要采樣的token池。
注意力復雜度是關于輸入長度的二次型,因此一些技術旨在提高推理速度,特別是在較長的序列長度時。FlashAttention優化了GPU內存級之間的讀寫,加速了訓練和推理。FlashDecoding將注意力機制中的key-value(KV)緩存加載并行化,產生8倍的端到端加速。推測解碼使用一個額外的小型語言模型來近似來自LLM的下一個token分布,這在不損失性能的情況下加速了解碼。vLLM使用PagedAttention加速LLM推理和服務,PagedAttention是一種優化注意力鍵和值的內存使用的算法。
任務域和評估
由于要執行的評估的多樣性和廣度,正確評估LLM的能力仍然是一個活躍的研究領域。Question-answering數據集是非常流行的評估基準,但最近也出現了為LLM評估量身定制的新基準。
開源LLMs vs. ChatGPT
綜合能力
基準
隨著大量LLM的發布,每個LLM都聲稱在某些任務上具有卓越的性能,確定真正的進步和領先的模型變得越來越具有挑戰性。因此,至關重要的是全面評估這些模型在廣泛任務中的性能,以了解它們的一般能力。本節涵蓋使用基于LLM(如GPT-4)評估和傳統(如ROUGE和BLEU)評估指標的基準。
MT-Bench:旨在從八個角度測試多輪對話和指令遵循能力。分別是寫作、角色扮演、信息提取、推理、數學、編碼、知識I (STEM)和知識II(人文/社會科學)。
AlpacaEval:是一個基于AlpacaFarm評估集的自動評估器,它測試了模型遵循一般用戶指令的能力。它利用更強的LLM(如GPT-4和Claude)將候選模型與Davinci-003響應進行基準測試,從而生成候選模型的勝率。
開源LLMs榜單:使用語言模型評估工具在七個關鍵基準上評估LLM,包括AI2 Reasoning Challenge、HellaSwag、MMLU、TruthfulQA、Winogrande、GSM8K和DROP。該框架在零樣本和少樣本設置下,對各種領域的各種推理和一般知識進行評估。
BIG-bench:是一個合作基準,旨在探索LLM并推斷其未來能力。它包括200多個新穎的語言任務,涵蓋了各種各樣的主題和語言,這些是現有模型無法完全解決的。
ChatEval:是一個多智能體辯論框架,它使多智能體裁判團隊能夠自主地討論和評估不同模型在開放式問題和傳統自然語言生成任務上生成的響應的質量。
Fairval-Vicuna:對來自Vicuna基準的80個問題進行了多證據校準和平衡位置校準。其在采用LLM作為評估的范式中提供了一個更公正的評估結果,與人類的判斷密切一致。
LLMs的性能
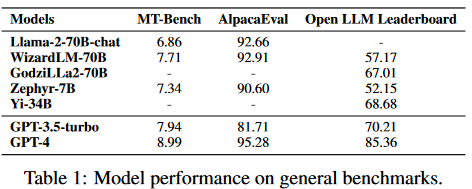
Llama-270B是來自meta的著名開源LLM,已經在2萬億token的大規模數據集上進行了預訓練。它在各種通用基準上展示了顯著的結果。當與指令數據進一步微調時,Llama2-chat-70B變體在一般會話任務中表現出增強的能力。其中,Llama-2-chat-70B在AlpacaEval中取得了92.66%的勝率,將GPT-3.5-turbo的性能提升了10.95%。盡管如此,GPT-4仍然是所有LLM中表現最好的,勝率為95.28%。
另一個較小的模型Zephyr-7B使用蒸餾進行優化,在AlpacaEval上取得了與70B LLMs相當的結果,勝率為90.6%。它甚至超過了Llama-2-chat-70B。此外,WizardLM-70B已經使用大量具有不同復雜度的指令數據進行了指令微調。它以7.71的分數脫穎而出,成為MT-Bench上得分最高的開源LLM。然而,這仍然略低于GPT-3.5turbo(7.94)和GPT-4(8.99)。盡管Zephyr-7B在MT-Bench中表現最好,但它在Open LLM排行榜中不出色,得分僅為52.15%。另一方面,GodziLLa2-70B,將Maya Philippines 6和Guanaco Llama 2 1K數據集中的各種專有LoRAs與Llama-2-70b相結合,在Open LLM排行榜上取得了更有競爭力的67.01%的分數。Yi-34B從一開始就由開發人員進行了預訓練。AI 7,以68.68%的顯著分數在所有開源LLM中脫穎而出。該性能與GPT-3.5-turbo的70.21%相當。然而,兩者仍然明顯落后于GPT-4,后者以85.36%的高分領先。UltraLlama利用了增強多樣性和質量的微調數據。它在其建議的基準中與GPT-3.5-turbo的性能相匹配,同時在世界和專業知識領域超過了它。
代理能力
基準
隨著模型規模的不斷擴大,基于LLM的智能體(也稱為語言智能體)引起了NLP社區的廣泛關注。鑒于此,本文研究了開源LLM在各種基準上的代理能力。根據所需的技能,現有的基準主要可以分為四類。
使用工具:已經提出了一些基準來評估LLM的工具使用能力。
API-Bank是專門為工具增強的LLM設計的。
ToolBench 是一個工具操作基準,包括用于現實世界任務的各種軟件工具。
APIBench由HuggingFace、TorchHub和TensorHub的API組成。
ToolAlpaca通過多智能體仿真環境開發了多樣化和全面的工具使用數據集。
MINT可以評估使用工具解決需要多輪交互的任務的熟練程度。
自調試(self-debugging):有幾個數據集可用于評估LLM的自調試能力。
InterCode-Bash
InterCode-SQL
MINT-MBPP
MINT-HumanEval
RoboCodeGen。
遵循自然語言反饋:
MINT通過使用GPT-4來模擬人類用戶,也可用于測量LLM利用自然語言反饋的能力。
探索環境:評估基于LLMs的智能體是否能夠從環境中收集信息并做出決策。
ALFWorld
InterCode-CTF
WebArena。
LLMs的性能
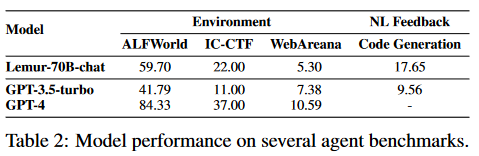
通過使用包含90B標記的代碼密集型語料庫對Llama-2進行預訓練,并對包括文本和代碼在內的300K示例進行指令微調,Lemur-70B-chat在探索環境或遵循編碼任務的自然語言反饋時超過了GPT-3.5-turbo的性能。AgentTuning使用Llama-2對其構建的AgentInstruct數據集和通用域指令進行指令調整,產生AgentLlama。值得注意的是,AgentLlama-70B在未見過的代理任務上實現了與GPT-3.5-turbo相當的性能。通過在ToolBench上對Llama-2-7B進行微調,ToolLLaMA在工具使用評估中展示了與GPT3.5-turbo相當的性能。FireAct,它可以對Llama-2-13B進行微調,以在HotpotQA上超越提示GPT-3.5-turbo。此外,從Llama-7B進行微調的Gorilla在編寫API調用方面優于GPT-4。
邏輯推理能力
基準
邏輯推理是高級技能的基本能力,如程序設計、定理證明、算術推理等。我們將介紹以下基準:
GSM8K:由人類問題作者創造的8.5K個高質量的小學數學問題組成。解決這些問題需要2到8步,解決這些問題主要涉及使用基本算術運算以得到最終答案。
MATH:是一個包含12,500個具有挑戰性的數學競賽問題的數據集。數學中的每個問題都有一個完整的分步解決方案,可用于教模型生成答案的推導和解釋。
TheoremQA:是一個定理驅動的問答數據集,旨在評估人工智能模型應用定理解決挑戰性科學問題的能力。TheoremQA由領域專家策劃,包含800個高質量的問題,涵蓋了數學、物理、EE&CS和金融的350個定理。
HumanEval:是一組164個手寫編程問題。每個問題包括一個函數簽名、文檔字符串、函數體和幾個單元測試,平均每個問題7.7個測試。
MBPP:(主要基礎編程問題)數據集包含974個短Python程序,這些程序是通過具有基本Python知識的內部眾包人員構建而成。每個問題都分配了一個獨立的Python函數來解決指定的問題,以及三個測試用例來檢查函數的語義正確性。
APPs:是代碼生成的基準,衡量模型采用任意自然語言規范并生成令人滿意的Python代碼的能力。該基準包括10,000個問題,從簡單的單行解決方案到巨大的算法挑戰。
增強指令微調
與傳統的基于知識蒸餾的指令微調不同,通過構建特定于任務的高質量指令微調數據集,其中種子指令已經進化到在知識邊界或任務復雜度深度上擴展的指令。此外,研究人員還納入了PPO算法,以進一步提高生成的指令和答案的質量。在獲得擴展的指令池之后,通過收集另一個LLM(如GPT-3.5-turbo)的響應來生成新的指令微調數據集。得益于改進的查詢深度和寬度,微調后的模型取得了比GPT-3.5-turbo更好的性能。例如,WizardCoder在HumanEval上的性能優于GPT3.5-turbo,有19.1%的改進。與GPT-3.5-turbo相比,WizardMath在GSM8K上也獲得了42.9%的改進。
在具有更高質量的數據上進行預訓練
Lemur驗證了自然語言數據和代碼能更好的融合,并證實在函數調用、自動編程和代理能力方面具有更強能力。Lemur-70B-chat在HumanEval和GSM8K上都比GPT-3.5-turbo取得了顯著的改進,而無需特定任務的微調。Phi-1和Phi-1.5走了一條不同的道路,將教科書作為預訓練的主要語料庫,這使得在更小的語言模型上可以觀察到強大的能力。
上下文建模能力
基準
處理長序列仍然是LLM的關鍵技術瓶頸之一,因為所有模型都受到有限的最大上下文窗口的限制,通常從2k到8k token長度。對LLM的上下文能力進行基準測試涉及對幾個自然具有長上下文的任務進行評估,如抽象摘要或多文檔QA。以下基準已被提出用于LLMs的長上下文評估:
SCROLLS:是一個流行的評估基準,由7個具有自然長輸入的數據集組成。任務涵蓋摘要、問答和自然語言推理。
ZeroSCROLLS:建立在SCROLLS上(丟棄ContractNLI,重用6個其他數據集,并添加4個數據集),并且只考慮零樣本設置。
LongBench:在6個任務中設置了21個數據集的英漢雙語長上下文基準。
L-Eval:重用了16個現有的數據集,并從頭創建了4個數據集,以創建一個多樣化的長上下文基準,每個任務的平均長度超過4k token。作者主張使用LLM進行評估(特別是GPT-4),而不是N-gram進行長上下文評估。
BAMBOO:創建了一個長上下文LLM評估基準,通過僅收集評估數據集中的最新數據,專注于消除預訓練數據污染。
M4LE:引入了一個廣泛的基準,將36個數據集劃分為5種理解能力:顯式single-span、語義single-span、顯式multiple-span、語義multiple-span和全局理解。
模型
在LongBench、L-Eval、BAMBOO和M4LE基準上,GPT-3.5-turbo或其16k版本的性能基本上超過了所有開源LLM,這表明提高開源LLM在長輸入任務上的性能并非易事。Llama-2-long使用16k上下文窗口(從Llama-2的4k增加到400B token)繼續對Llama-2進行預訓練。由此產生的Llama-2-long-chat-70B在ZeroSCROLLS上的性能比GPT-3.5-turbo-16k高出37.7到36.7。解決長上下文任務的方法包括使用位置插值的上下文窗口擴展,這涉及另一輪微調與較長的上下文窗口,以及檢索增強。研究人員結合了這兩種看似相反的技術,在7個長上下文任務(包括來自ZeroSCROLLS的4個數據集)中,平均推動Llama-2-70B超過GPT-3.5-turbo-16k。
特定應用能力
面向查詢摘要
基準:聚焦查詢或基于方面的摘要需要生成關于細粒度問題或方面類別的摘要。面向查詢的數據集包括AQualMuse、QMSum和SQuALITY,而基于方面的數據集包括CovidET、NEWTS、WikiAsp等。
模型:與ChatGPT相比,訓練數據上的標準微調在性能上仍然更好,比CovidET、NEWTS、QMSum和SQuALITY平均提高了2點ROUGE-1。
開放式QA
基準:開放式QA有兩個子類:答案要么是短形式,要么是長形式。短格式數據集包括SQuAD 1.1、NewsQA、TriviaQA、SQuAD 2.0、NarrativeQA、Natural Question (NQ)、Quoref和DROP。長格式數據集包括ELI5和doc2dial。對于短文和長篇數據集,評估指標都是答案中單詞的精確匹配(EM)和F1。回答開放式QA要求模型理解提供的上下文,或者在沒有提供上下文的情況下檢索相關知識。
模型:InstructRetro在NQ、TriviaQA、SQuAD 2.0和DROP上比GPT-3有很大的改進,同時在一系列長短開放式QA數據集上,與類似大小的專有GPTinstruct模型相比,有7-10%的改進。InstructRetro從預訓練的GPT模型初始化,通過檢索繼續預訓練,然后進行指令微調。
醫學領域
基準:對于心理健康,IMHI基準使用10個現有的心理健康分析數據集構建,包括心理健康檢測:DR、CLP、Dreaddit、loneliness、SWMH和T-SID;心理健康原因檢測:SAD、CAMS;心理風險因素檢測:MultiWD、IRF。對于放射學,OpenI數據集和MIMIC-CXR數據集都包含有發現和印象文本的放射學報告。
模型:為了心理健康,MentalLlama-chat-13B在IMHI訓練集上對Llama-chat-13B模型進行了微調。零樣本提示的MentalLlama-chat-13B模型在IMHI的10個任務中有9個表現優于少樣本提示或零樣本提示的ChatGPT。還有研究人員對Llama檢查點進行微調,以根據放射學報告發現生成印象文本。由此產生的Radiology-Llama-2模型在MIMIC-CXR和OpenI數據集上都以很大的優勢優于ChatGPT和GPT-4。
生成結構化響應
基準:Rotowire包含NBA比賽摘要和相應的得分表。Struc-Bench介紹了兩個數據集:Struc-Bench-Latex,其中輸出為Latex格式的表格,Struc-Bench-HTML輸出為HTML格式的表格。
模型:Struc-Bench在結構化生成數據上微調Llama-7B模型。微調后的7B模型在上述所有基準上的表現都優于ChatGPT。
生成評論
基準:LLM的一個有趣的能力是對問題的回答提供反饋或批評。為了對這種能力進行基準測試,人們可以使用人工標注者或GPT-4作為評估者,直接對評論進行評分。原始問題可以來自上述任何具有其他功能的數據集。
模型:Shepherd是一個從Llama-7B初始化的7B模型,并在社區收集的批判數據和1,317個高質量人工標注數據示例上進行訓練。Shepherd在一系列不同的NLP數據集上生成評論:AlpacaFarm、FairEval、CosmosQA、OBQA、PIQA、TruthfulQA和CritiqueEval。使用GPT-4作為評估器,Shepherd在60%以上的情況下會贏或等于ChatGPT。在人工評估方面,Shepherd幾乎可以與ChatGPT相提并論。
走向值得信賴的AI
為了確保LLM在現實世界的應用中可以被人類信任,一個重要的考慮因素是它們的可靠性。例如,幻覺和安全性可能會惡化用戶對LLM的信任,并在高影響的應用中導致風險。
幻覺
基準:為了更好地評估LLM中的幻覺,人們提出了各種基準。具體來說,它們由大規模數據集、自動化指標和評估模型組成。
TruthfulQA:是一個基準問答(QA)數據集,由跨越38個類別的問題組成。這些問題被精心設計,以至于一些人類也會由于誤解而錯誤地回答它們。
FactualityPrompts:是一個為開放式一代測量幻覺的數據集。它由事實提示和非事實提示組成,以研究提示對LLM的持續影響。
HaluEval:是一個由生成的和人工標注的幻覺樣本組成的大型數據集。它跨越了三個任務:問答、以知識為基礎的對話和文本摘要。
FACTOR:提出了一種可擴展的語言模型真實性評估方法,它自動將事實語料庫轉換為忠實度評估基準。該框架用于創建Wiki-FACTOR和News-FACTOR基準。
KoLA:構建了一個面向知識的LLM評估基準(KoLA),具有三個關鍵因素分別是,模仿人類認知進行能力建模,使用維基百科進行數據收集,以及設計用于自動幻覺評估的對比指標。
FActScore:提出了一種新的評估方法,首先將LLM的生成分解為一系列原子事實,然后計算可靠知識源支持的原子事實的百分比。
Vectara’s Hallucination Evaluation Model:是一個小型的語言模型,它被微調為二進制分類器,以將摘要分類為與源文檔事實一致(或不一致)。然后,用它來評估和基準各種LLM生成摘要的幻覺。
FacTool:是一個任務和領域無關的框架,用于檢測LLM生成的文本的事實錯誤。
除了新引入的幻覺基準,之前基于現實世界知識的QA數據集也被廣泛用于測量忠實度,如HotpotQA、OpenBookQA、MedMC-QA 和TriviaQA。除了數據集和自動化指標,人工評估也被廣泛采用作為忠實度的可靠度量。
模型:超越當前GPT-3.5-turbo性能的方法可以在微調期間納入,也可以只在推理時納入。所選性能指標如表3所示。在微調過程中,提高數據質量的正確性和相關性,可以減少模型的幻覺。研究人員策劃了一個內容過濾、指令微調的數據集,重點關注STEM領域的高質量數據。一個LLM族在這個過濾后的數據集上進行微調并合并,由此產生的家族,名為Platypus,與GPT-3.5-turbo相比,在TruthfulQA上有了實質性的改進(約20%)。
在推理過程中,現有技術包括特定的解碼策略、外部知識增強和多智能體對話。對于解碼有Chain-of-Verification(CoVe),其中LLM起草驗證問題并自驗證響應。CoVe使FactScore比GPT-3.5-turbo有了實質性的改進。
對于外部知識擴充,各種框架結合了不同的搜索和提示技術,以提高當前GPT-3.5-turbo的性能。Chain-ofKnowledge(CoK)在回答問題之前從異構的知識源中檢索。LLM-AUGMENTER用一組即插即用模塊增強LLM,并迭代修訂LLM提示,以使用效用函數生成的反饋改善模型響應。Knowledge Solver (KSL)試圖通過利用自身強大的通用性,教會LLM從外部知識庫中搜索基本知識。CRITIC允許LLM以類似于人類與工具交互的方式驗證和逐步修正自己的輸出。Parametric Knowledge Guiding(PKG)框架為LLM配備了一個知識指導模塊,以在不改變參數的情況下訪問相關知識。與使用GPT-3.5-turbo的樸素提示策略相比,這些推理技術提高了答案的準確性。目前,GPT-3.5-turbo還包含了一個檢索插件,可以訪問外部知識以減少幻覺。
對于多智能體對話,研究人員促進了生成聲明的考生LLM和引入問題以發現不一致的另一個考官LLM之間的多輪交互。通過交叉檢查過程,各種QA任務的性能得到了提高。另外的方法要求多個語言模型實例在多輪中提出并辯論各自的響應和推理過程,以得出共同的最終答案,這在多個基準上都有所提高。

安全性
基準:LLM中的安全問題主要可以分為三個方面:社會偏見、模型魯棒性和中毒問題。為了收集更好地評估上述方面的數據集,人們提出了幾個基準:
SafetyBench:是一個由11435個不同的選擇題組成的數據集,涵蓋7個不同的安全問題類別。
Latent Jailbreak:引入了一個評估LLM安全性和魯棒性的基準,強調了平衡方法的必要性。
XSTEST:是一個測試套件,系統地識別夸張的安全行為,例如拒絕安全提示。
RED-EVAL:是一個基準,用于執行red-teaming以使用基于Chain of Utterances(CoU)的提示對LLM進行安全評估。
除了自動化基準之外,安全性的一個重要衡量標準是人工評估。一些研究也試圖從GPT-4中收集此類標簽。
模型:基于當前評估,GPT-3.5-turbo和GPT-4模型在安全性評估方面仍然處于領先地位。這在很大程度上歸因于人類反饋強化學習(RLHF)。RLHF首先收集人類對響應的偏好數據集,然后訓練一個獎勵模型來模仿人類的偏好,最后使用RL訓練LLM來對齊人類的偏好。在這個過程中,LLM學習展示所需的行為,并排除有害的反應,如不禮貌或有偏見的答案。然而,RLHF過程需要收集大量昂貴的人工注釋,這阻礙了它用于開源LLM。為推動LLM安全對齊的努力,研究人員收集了一個人類偏好數據集,以從人類偏好得分中分離出無害和有用性,從而為兩個指標提供了單獨的排名數據。另有研究人員試圖通過人工智能反饋(RLAIF)來提高RL的安全性,其中使用LLM生成的自我批評和修正來訓練偏好模型。直接偏好優化減少了學習獎勵模型的需要,并通過簡單的交叉熵損失直接從偏好中學習,這可以在很大程度上降低RLHF的成本。結合和改進這些方法可能會導致開源LLM安全性的潛在改進。
討論
LLMs的發展趨勢
自從研究人員證明了凍結的GPT-3模型可以在各種任務上實現令人印象深刻的零樣本和少樣本性能以來,人們為推進LLM的發展做出了許多努力。研究重點是擴大模型參數,包括Gopher、GLaM、LaMDA、MT-NLG和PaLM,最終達到540B參數。盡管這些模型表現出了非凡的能力,但閉源的性質限制了它們廣泛應用,從而導致人們對開發開源LLM的興趣日益濃厚。
另一項研究沒有擴大模型大小,而是探索了預訓練較小模型的更好策略或目標,如Chinchilla和UL2。除了預訓練之外,還將相當大的精力用于研究語言模型的指令微調,例如FLAN、T0和FLAN-T5。
一年前OpenAI的ChatGPT的出現極大地改變了NLP社區的研究重點。為了趕上OpenAI,谷歌和Anthropic分別引入了Bard和Claude。雖然它們在許多任務上表現出與ChatGPT相當的性能,但與最新的OpenAI模型GPT-4之間仍然存在性能差距。由于這些模型的成功主要歸功于從人工反饋中強化學習(RLHF),研究人員探索了各種改進RLHF的方法。
為了促進開源LLM的研究,Meta發布了Llama系列模型。從那時起,基于Llama的開源模型開始爆炸式地出現。一個有代表性的研究方向是利用指令數據對Llama進行微調,包括Alpaca、Vicuna、Lima和WizardLM。正在進行的研究還探索了改進代理、邏輯推理和長上下文建模等能力。此外,許多工作都致力于從頭開始訓練強大的LLM,而不是基于Llama開發,例如MPT、Falcon、XGen、Phi、Baichuan、Mistral、Grok和Yi。我們相信,開發更強大、更高效的開源LLM,使閉源LLM的能力民主化,應該是一個非常有前途的未來方向。
結果總結
對于一般功能,Llama-2-chat-70B在一些基準中顯示了比GPT3.5-turbo的改進,但仍然落后于大多數其他測試。Zephir-7B 通過蒸餾直接偏好優化接近70B LLMs。WizardLM70B和GodziLLa-70B可以實現與GPT-3.5-turbo相當的性能,這表明了一條有前途的道路。
開源的LLM能夠通過更廣泛和特定任務的預訓練和微調超越GPT-3.5-turbo。例如,Lemur-70B-chat在探索環境和跟蹤編碼任務的反饋方面表現更好。AgentTuning改進了未見過的代理任務。ToolLLama可以更好地掌握工具的使用。Gorilla在編寫API調用方面優于GPT-4。對于邏輯推理,WizardCoder和WizardMath通過增強的指令微調來提高推理能力。Lemur和Phi通過對更高質量的數據進行預訓練,實現了更強的能力。對于長上下文建模,Llama-2-long可以通過使用更長的token和更大的上下文窗口進行預訓練來提高選定的基準。對于特定應用的能力,InstructRetro通過檢索和指令微調的預訓練,改進了開放式QA。通過特定任務的微調,MentaLlama-chat13B在心理健康分析數據集上的表現優于GPT-3.5-turbo。RadiologyLlama2可以提高放射學報告的性能。只有7B參數的Shepherd在生成模型反饋和批評方面可以實現與GPT-3.5-turbo相當或更好的性能。對于可信的人工智能,可以通過對更高質量的數據進行微調、上下文感知解碼技術、外部知識增強來減少幻覺。
還有一些領域GPT-3.5-turbo和GPT-4仍然是不可戰勝的,例如人工智能安全。由于GPT模型涉及大規模的RLHF,它們被認為表現出更安全、更符合道德的行為,這可能是商業LLM比開源LLM更重要的考慮因素。然而,隨著最近對RLHF進程民主化的努力,我期待看到開源LLM在安全性方面的更多性能改進。
最佳的開源LLMs配方
訓練LLM涉及復雜和資源密集的實踐,包括數據收集和預處理,模型設計和訓練過程。雖然定期發布開源LLM的趨勢越來越大,但遺憾的是,主要模型的詳細實現細節往往保密。下面我們列出了一些社區廣泛認可的最佳實現要點。
數據
預訓練涉及使用數萬億的數據tokens,這些tokens通常是公開。從倫理上講,至關重要的是排除任何包括私人信息的數據。與預訓練數據不同,微調數據的數量更少,但質量更高。具有高質量數據的微調LLM表現出了更好的性能,特別是在特定領域。
模型結構
雖然大多數LLM利用只有解碼器的Transformer架構,但模型中采用了不同的技術來優化效率。Llama-2實現了Ghost注意力以改進多輪對話控制。Mistral利用滑動窗口注意力來處理擴展的上下文長度。
訓練
使用指令微調數據進行監督式微調(SFT)的過程至關重要。對于高質量的結果,數萬個SFT注釋就足夠了,Llama-2使用的27540個注釋就證明了這一點。在RLHF階段,近端策略優化(PPO)通常是首選的算法,以更好地使模型的行為與人類偏好和指令遵循相一致,在增強LLM安全性方面發揮著關鍵作用。PPO的另一種選擇是直接偏好優化(DPO)。例如,Zephyr-7B采用了蒸餾的DPO,并在各種通用基準上顯示了與70B-LLMs相當的結果,甚至超過了AlpacaEval上的GPT-3.5-turbo。
潛在問題
預訓練期間的數據污染
隨著基礎模型的發布,數據污染的問題變得越來越明顯,這些模型模糊了其預訓練語料庫的來源。這種透明度的缺乏可能會導致人們對LLM的真正泛化能力的偏見。忽略基準數據通過人類專家的注釋或更大的模型手動集成到訓練集的情況,數據污染問題的根源在于基準數據的收集來源已經包含在預訓練語料庫中。雖然這些模型不是故意使用監督數據進行預訓練,但它們仍然可以獲得準確的知識。因此,解決檢測LLM的預訓練語料的挑戰至關重要,需要探索現有基準和廣泛使用的預訓練語料之間的重疊,以及評估對基準的過擬合。這些努力對于提高LLM的忠實度和可靠性至關重要。
對齊
基于RLHF在利用一般偏好數據進行對齊方面的應用受到了越來越多的關注。然而,只有有限數量的開源LLM使用RLHF進行對齊,這主要是由于高質量的、公開可用的偏好數據集和預訓練獎勵模型的稀缺。一些研究人員試圖為開源社區做出貢獻。然而,在復雜的推理、編程和安全場景中,仍然面臨缺乏多樣化、高質量和可擴展的偏好數據的挑戰。
難以持續提高基本能力
回顧本文概述的基本能力的突破,揭示了一些具有挑戰性的場景:
在預訓練期間,在探索改進的數據混合方面投入了大量努力,以增強構建更有效的基礎模型的平衡性和魯棒性。然而,相關的勘探成本往往使這種方法不切實際。
超越GPT-3.5-turbo或GPT-4的模型主要是基于從閉源模型中提取的知識和額外的專家注釋。雖然效率很高,但在擴展到教師模型時,對知識蒸餾的嚴重依賴可能會掩蓋所提出方法的有效性的潛在問題。LLM被期望充當代理并提供合理的解釋以支持決策,而注釋代理風格的數據以使LLM適用于現實世界的場景也是昂貴和耗時的。本質上,僅通過知識蒸餾或專家注釋的優化無法實現持續改進,可能會接近一個上限。未來的研究方向可能涉及探索新的方法,如無監督或自監督學習范式,以實現基本LLM能力的持續進步,同時減輕相關的挑戰和成本。
總結
主要貢獻:
整合了對開源LLM的各種評估基準,提供開源LLM與ChatGPT的公正和全面的看法。
系統地回顧了在各種任務中性能與ChatGPT相當或超過ChatGPT的開源LLM并進行分析。我們還維護了一個實時網頁來跟蹤最新的更新:https://github.com/ntunlp/OpenSource-LLMs-better-than-OpenAI/tree/main
介紹了對開源LLM發展趨勢的見解,訓練開源LLM的最佳方法和開源LLM的潛在問題。
審核編輯:黃飛
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238265 -
OpenAI
+關注
關注
9文章
1079瀏覽量
6482 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7596 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:ChatGPT一周歲啦!開源LLMs正在緊緊追趕嗎?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
對比解碼在LLM上的應用
使用開源的麥克風陣列的喚醒識別能力和拾音能力,是否能夠在硬件和軟件上對當前開源的代碼進行分離?
邱錫鵬團隊提出具有內生跨模態能力的SpeechGPT,為多模態LLM指明方向

LLM在各種情感分析任務中的表現如何

Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態語言建模
基準數據集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力
適用于各種NLP任務的開源LLM的finetune教程~

Nvidia 通過開源庫提升 LLM 推理性能
深度解讀各種人工智能加速器和GPU上的LLM性能特征

Ambarella展示了在其CV3-AD芯片上運行LLM的能力
100%在樹莓派上執行的LLM項目






 工商網監
工商網監
評論