") 超分畫質(zhì)大模型!華為和清華聯(lián)合提出CoSeR:基于認(rèn)知的萬物超分大模型
超分畫質(zhì)大模型!華為和清華聯(lián)合提出CoSeR:基于認(rèn)知的萬物超分大模型

項(xiàng)目主頁:https://coser-main.github.io/ 論文:https://arxiv.org/abs/2311.16512 代碼:https://github.com/VINHYU/CoSeR

圖1. LR,GR和SR分別為低清圖像、基于對(duì)低清圖像的認(rèn)知生成的參考圖像和超分圖像。
圖像超分辨率技術(shù)旨在將低分辨率圖像轉(zhuǎn)換為高分辨率圖像,從而提高圖像的清晰度和細(xì)節(jié)真實(shí)性。這項(xiàng)技術(shù)在手機(jī)拍照等領(lǐng)域有著廣泛的應(yīng)用和需求。隨著超分技術(shù)的發(fā)展和手機(jī)硬件性能的提升,人們期望拍攝出更加清晰的照片。然而,現(xiàn)有的超分方法存在一些局限性,如圖2所示,主要有以下兩個(gè)方面:
一是缺乏泛化能力。為了實(shí)現(xiàn)更好的超分效果,通常需要針對(duì)特定場(chǎng)景使用特定傳感器采集到的數(shù)據(jù)來進(jìn)行模型訓(xùn)練,這種學(xué)習(xí)方式擬合了某種低清圖像和高清圖像間的映射,但在其他場(chǎng)景下表現(xiàn)不佳。此外,逐場(chǎng)景訓(xùn)練的方式計(jì)算成本較高,不利于模型的部署和更新。
二是缺乏理解能力。現(xiàn)有的超分方法主要依賴于從大量數(shù)據(jù)中學(xué)習(xí)圖像的退化分布,忽視了對(duì)圖像內(nèi)容的理解,無法利用常識(shí)來準(zhǔn)確恢復(fù)物體的結(jié)構(gòu)和紋理。

圖2. 真實(shí)場(chǎng)景超分SOTA方法的局限性:(行一)難以處理訓(xùn)練集外的退化分布;(行二)難以利用常識(shí)恢復(fù)物體結(jié)構(gòu)。
人類在處理信息時(shí),有兩種不同的認(rèn)知反饋系統(tǒng)。諾貝爾獎(jiǎng)經(jīng)濟(jì)學(xué)得主丹尼爾·卡爾曼在《思考,快與慢》中將它們稱為系統(tǒng)一和系統(tǒng)二,如圖3所示。系統(tǒng)一是快速的、直覺的、基于記憶的反饋,比如,我們可以脫口而出十以內(nèi)的加減運(yùn)算。系統(tǒng)二是緩慢的、多步的反饋,比如,28x39往往需要逐步運(yùn)算。現(xiàn)有的超分方法更貼近系統(tǒng)一,它們主要依賴于從大量數(shù)據(jù)中學(xué)習(xí)圖像的退化分布,忽視了對(duì)圖像內(nèi)容的理解,無法按照常識(shí)來準(zhǔn)確恢復(fù)物體的結(jié)構(gòu)和紋理,也無法處理域外的退化情況。本文認(rèn)為,真正能有效應(yīng)用于真實(shí)場(chǎng)景的畫質(zhì)大模型應(yīng)該具備類似系統(tǒng)二的多步修復(fù)能力,即基于對(duì)圖像內(nèi)容的認(rèn)知,結(jié)合先驗(yàn)知識(shí)來實(shí)現(xiàn)圖像超分(Cognitive Super-Resolution,CoSeR)。
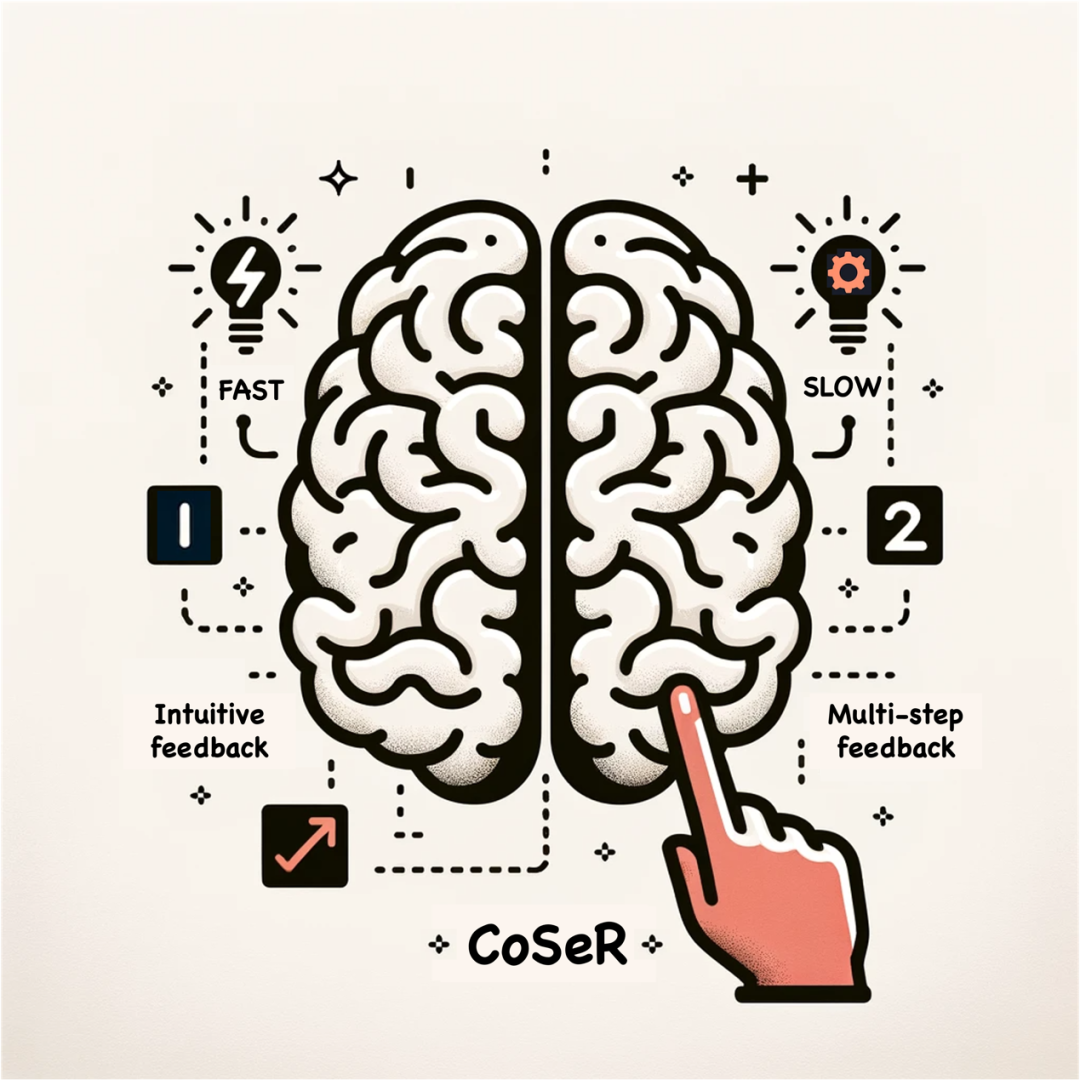
圖3. CoSeR采用類似于人腦中系統(tǒng)二的修復(fù)方式
CoSeR模仿了人類專家修復(fù)低質(zhì)量圖像自上而下的思維方式,首先建立對(duì)圖像內(nèi)容的全面認(rèn)知,包括識(shí)別場(chǎng)景和主要物體的特征,隨后將重點(diǎn)轉(zhuǎn)移到對(duì)圖像細(xì)節(jié)的檢查和還原。本文的主要貢獻(xiàn)如下:
提出了一種通用的萬物超分畫質(zhì)大模型CoSeR,它能夠從低清圖像中提取認(rèn)知特征,包括場(chǎng)景內(nèi)容理解和紋理細(xì)節(jié)信息,從而提高模型的泛化能力和理解能力。
提出了一種基于認(rèn)知特征的參考圖像生成方法,它能夠生成與低清圖像內(nèi)容一致的高質(zhì)量參考圖像,用于指導(dǎo)圖像的恢復(fù)過程,增強(qiáng)圖像的保真度和美感度。
提出了一種“All-in-Attention”模塊,它能夠?qū)⒌颓鍒D像、認(rèn)知特征、參考圖像三個(gè)條件注入到模型當(dāng)中,實(shí)現(xiàn)多源信息的融合和增強(qiáng)。
在多個(gè)測(cè)試集和評(píng)價(jià)指標(biāo)上,相較于現(xiàn)有方法,CoSeR均取得了更好的效果。同時(shí),CoSeR在真實(shí)場(chǎng)景下也展現(xiàn)頗佳。
方法介紹
圖4展示了CoSeR的整體架構(gòu)。CoSeR首先使用認(rèn)知編碼器來對(duì)低清圖像進(jìn)行解析,將提取到的認(rèn)知特征傳遞給Stable Diffusion模型,用以激活擴(kuò)散模型中的圖像先驗(yàn),從而恢復(fù)更精細(xì)的細(xì)節(jié)。此外,CoSeR利用認(rèn)知特征來生成與低清圖像內(nèi)容一致的高質(zhì)量參考圖像。這些參考圖像作為輔助信息,有助于提升超分辨率效果。最終,CoSeR使用提出的“All-in-Attention”模塊,將低清圖像、認(rèn)知特征、參考圖像三個(gè)條件注入到模型當(dāng)中,進(jìn)一步提升結(jié)果的保真度。
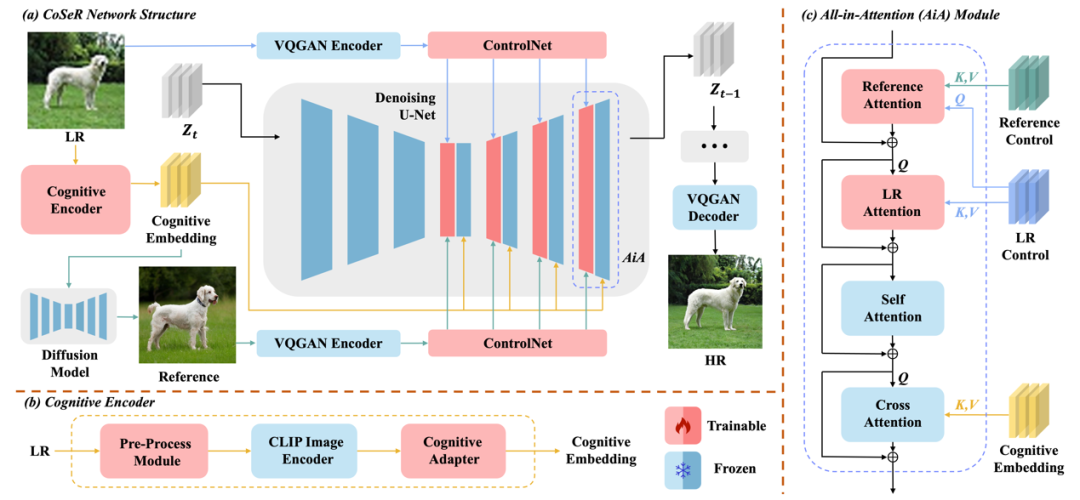
圖4. 本文提出的萬物超分畫質(zhì)大模型CoSeR
圖5展示了CoSeR參考圖像生成的效果。與直接從低清圖像中獲取描述的方法相比,CoSeR的認(rèn)知特征保留了細(xì)粒度的圖像特征,在生成具有高度相似內(nèi)容的參考圖像時(shí)具有優(yōu)勢(shì)。在圖5的第一行,使用BLIP2從低清圖像生成的描述無法準(zhǔn)確識(shí)別動(dòng)物的類別、顏色和紋理。此外,CoSeR的認(rèn)知特征對(duì)于低清圖像更加魯棒。例如,在圖5的第二行,由于輸入分布的差異,BLIP2會(huì)生成錯(cuò)誤的圖像描述,而CoSeR生成了內(nèi)容一致的高質(zhì)量參考圖像。最后,相比于BLIP2大模型接近7B的參數(shù)量,CoSeR的認(rèn)知編碼器只有其3%的參數(shù)量,極大提升了推理速度。
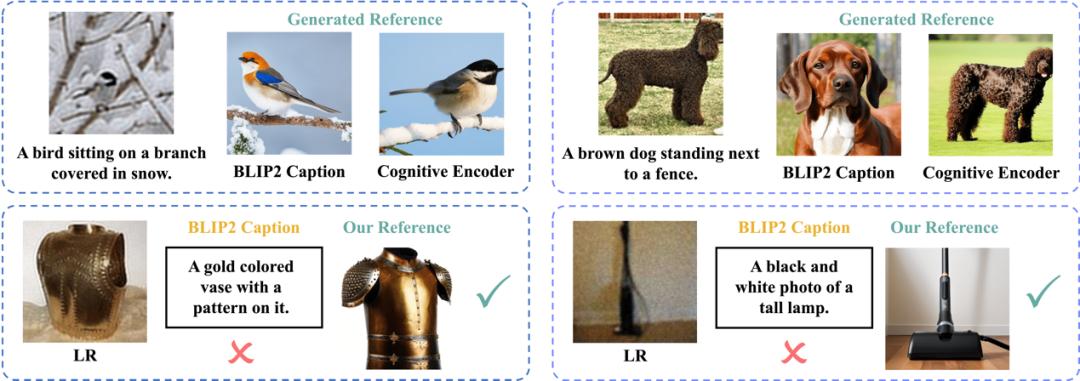
圖5.(行一)使用BLIP2描述生成的參考圖和CoSeR生成的參考圖;(行二)CoSeR的高魯棒性
結(jié)果展示
表1和圖6展示了CoSeR與其他方法的定量和定性結(jié)果對(duì)比。CoSeR在含有豐富類別的ImageNet數(shù)據(jù)集及真實(shí)超分?jǐn)?shù)據(jù)集RealSR和DRealSR上,都取得了不錯(cuò)的結(jié)果。CoSeR能夠恢復(fù)出更加清晰和自然的圖像細(xì)節(jié),同時(shí)保持了圖像的內(nèi)容一致性和結(jié)構(gòu)完整性。
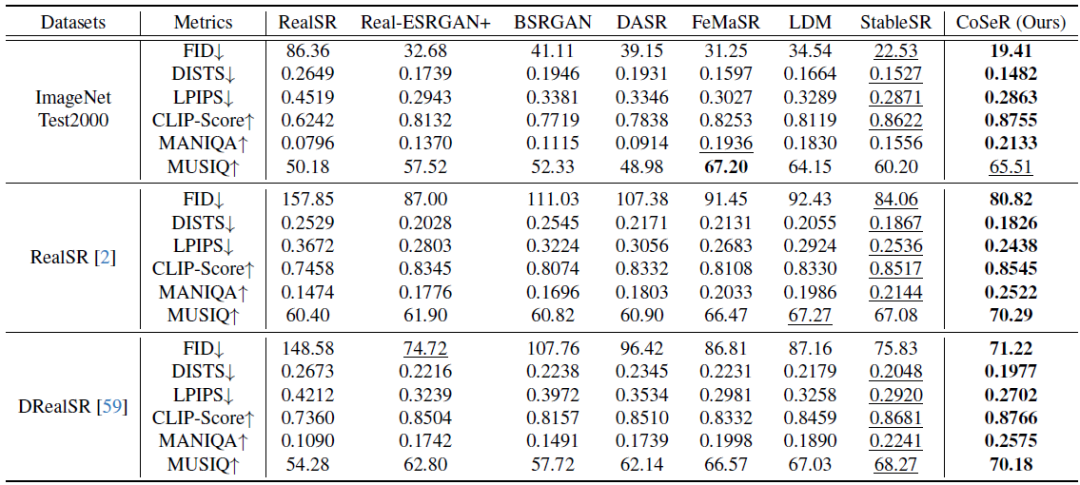
表1. 定量結(jié)果對(duì)比
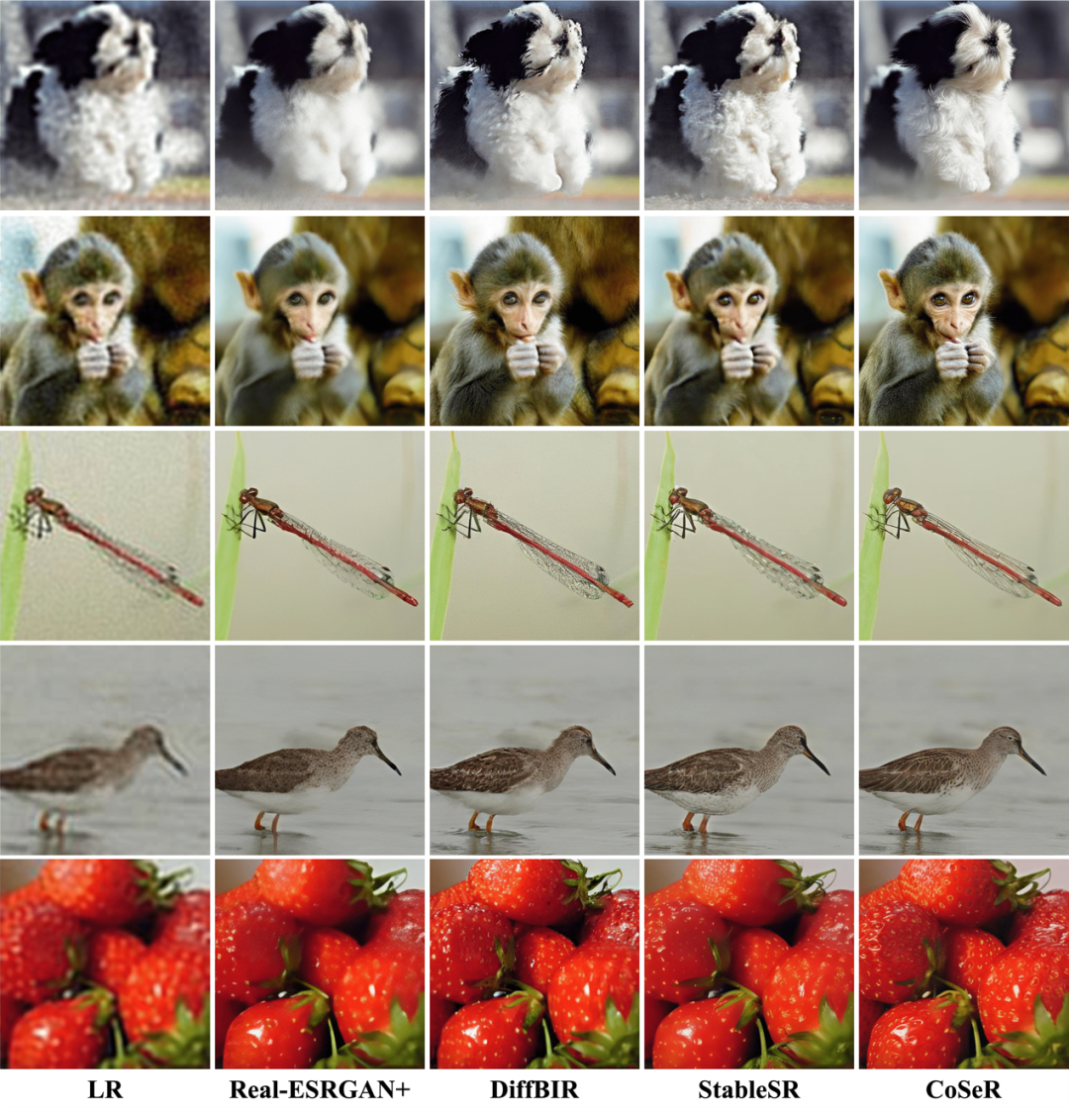
圖6. 定性結(jié)果對(duì)比
本文提出的CoSeR模型為圖像超分辨率技術(shù)提供了一種新的思路和方法,它能夠從低清圖像中提取認(rèn)知特征,用于激活圖像先驗(yàn)、生成參考圖像,從而實(shí)現(xiàn)高質(zhì)量的萬物超分效果。我們未來的研究重點(diǎn)是如何在不影響超分性能的情況下加速采樣,以獲得更高的視覺質(zhì)量。此外,我們還將探索統(tǒng)一模型在更多樣化的圖像修復(fù)任務(wù)中的表現(xiàn)。
-
傳感器
+關(guān)注
關(guān)注
2550文章
51035瀏覽量
753085 -
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40449 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2645
原文標(biāo)題:超分畫質(zhì)大模型!華為和清華聯(lián)合提出CoSeR:基于認(rèn)知的萬物超分大模型
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
IoT物聯(lián)網(wǎng)課程清單
萬物互聯(lián)時(shí)代引領(lǐng)者—微物聯(lián)網(wǎng)云服務(wù)平臺(tái)
鴻蒙是什么?他是兼容萬物的斗戰(zhàn)勝佛
HarmonyOS IoT首著,走進(jìn)萬物互聯(lián)的世界!
HarmonyOS IoT首著,走進(jìn)萬物互聯(lián)的世界!
鴻蒙座艙子品牌來了,華為發(fā)布 HarmonySpace:萬物互聯(lián)的智能出行空間
ARM用以解決圖像超分模型過參數(shù)問題
介紹一種MobileAI2021的圖像超分競(jìng)賽的最佳方案
介紹一種Any-time super-Resolution Method用以解決圖像超分模型過參數(shù)問題
基于混合先驗(yàn)模型的超分辨率重建
基于信譽(yù)模型的認(rèn)知物聯(lián)網(wǎng)非均勻分簇路由算法
如何使用TensorFlow Hub的ESRGAN模型來在安卓app中生成超分圖片
OpenHarmony分論壇-圖庫應(yīng)用數(shù)據(jù)加載顯示模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論