 時間復雜度為O (nlogn)的排序算法簡述
時間復雜度為O (nlogn)的排序算法簡述
歸并排序
歸并排序遵循分治的思想:將原問題分解為幾個規模較小但類似于原問題的子問題,遞歸地求解這些子問題,然后合并這些子問題的解來建立原問題的解,歸并排序的步驟如下:
劃分:分解待排序的 n 個元素的序列成各具 n/2 個元素的兩個子序列,將長數組的排序問題轉換為短數組的排序問題,當待排序的序列長度為 1 時,遞歸劃分結束
合并:合并兩個已排序的子序列得出已排序的最終結果
歸并排序的代碼實現如下:
private void sort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
// 劃分
int mid = left + right >> 1;
sort(nums, left, mid);
sort(nums, mid + 1, right);
// 合并
merge(nums, left, mid, right);
}
private void merge(int[] nums, int left, int mid, int right) {
// 輔助數組
int[] temp = Arrays.copyOfRange(nums, left, right + 1);
int leftBegin = 0, leftEnd = mid - left;
int rightBegin = leftEnd + 1, rightEnd = right - left;
for (int i = left; i <= right; i++) {
if (leftBegin > leftEnd) {
nums[i] = temp[rightBegin++];
} else if (rightBegin > rightEnd || temp[leftBegin] < temp[rightBegin]) {
nums[i] = temp[leftBegin++];
} else {
nums[i] = temp[rightBegin++];
}
}
}
歸并排序最吸引人的性質是它能保證將長度為 n 的數組排序所需的時間和 nlogn 成正比;它的主要缺點是所需的額外空間和 n 成正比。 算法特性:
空間復雜度:借助輔助數組實現合并,使用 O (n) 的額外空間;遞歸深度為 logn,使用 O (logn) 大小的棧幀空間。忽略低階部分,所以空間復雜度為 O (n)
非原地排序
穩定排序
非自適應排序
以上代碼是歸并排序常見的實現,下面我們來一起看看歸并排序的優化策略:
將多次創建小數組的開銷轉換為只創建一次大數組
在上文實現中,我們在每次合并兩個有序數組時,即使是很小的數組,我們都會創建一個新的 temp [] 數組,這部分耗時是歸并排序運行時間的主要部分。更好的解決方案是將 temp [] 數組定義成 sort () 方法的局部變量,并將它作為參數傳遞給 merge () 方法,實現如下:
private void sort(int[] nums, int left, int right, int[] temp) {
if (left >= right) {
return;
}
// 劃分
int mid = left + right >> 1;
sort(nums, left, mid, temp);
sort(nums, mid + 1, right, temp);
// 合并
merge(nums, left, mid, right, temp);
}
private void merge(int[] nums, int left, int mid, int right, int[] temp) {
System.arraycopy(nums, left, temp, left, right - left + 1);
int l = left, r = mid + 1;
for (int i = left; i <= right; i++) {
if (l > mid) {
nums[i] = temp[r++];
} else if (r > right || temp[l] < temp[r]) {
nums[i] = temp[l++];
} else {
nums[i] = temp[r++];
}
}
}
當數組有序時,跳過 merge () 方法 我們可以在執行合并前添加判斷條件:如果nums[mid] <= nums[mid + 1]?時我們認為數組已經是有序的了,那么我們就跳過 merge () 方法。它不影響排序的遞歸調用,但是對任意有序的子數組算法的運行時間就變成線性的了,代碼實現如下:
private void sort(int[] nums, int left, int right, int[] temp) {
if (left >= right) {
return;
}
// 劃分
int mid = left + right >> 1;
sort(nums, left, mid, temp);
sort(nums, mid + 1, right, temp);
// 合并
if (nums[mid] > nums[mid + 1]) {
merge(nums, left, mid, right, temp);
}
}
private void merge(int[] nums, int left, int mid, int right, int[] temp) {
System.arraycopy(nums, left, temp, left, right - left + 1);
int l = left, r = mid + 1;
for (int i = left; i <= right; i++) {
if (l > mid) {
nums[i] = temp[r++];
} else if (r > right || temp[l] < temp[r]) {
nums[i] = temp[l++];
} else {
nums[i] = temp[r++];
}
}
}
對小規模子數組使用插入排序 對小規模數組進行排序會使遞歸調用過于頻繁,而使用插入排序處理小規模子數組一般可以將歸并排序的運行時間縮短 10% ~ 15%,代碼實現如下:
/**
* M 取值在 5 ~ 15 之間大多數情況下都能令人滿意
*/
private final int M = 9;
private void sort(int[] nums, int left, int right) {
if (left + M >= right) {
// 插入排序
insertSort(nums);
return;
}
// 劃分
int mid = left + right >> 1;
sort(nums, left, mid);
sort(nums, mid + 1, right);
// 合并
merge(nums, left, mid, right);
}
/**
* 插入排序
*/
private void insertSort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int base = nums[i];
int j = i - 1;
while (j >= 0 && nums[j] > base) {
nums[j + 1] = nums[j--];
}
nums[j + 1] = base;
}
}
private void merge(int[] nums, int left, int mid, int right) {
// 輔助數組
int[] temp = Arrays.copyOfRange(nums, left, right + 1);
int leftBegin = 0, leftEnd = mid - left;
int rightBegin = leftEnd + 1, rightEnd = right - left;
for (int i = left; i <= right; i++) {
if (leftBegin > leftEnd) {
nums[i] = temp[rightBegin++];
} else if (rightBegin > rightEnd || temp[leftBegin] < temp[rightBegin]) {
nums[i] = temp[leftBegin++];
} else {
nums[i] = temp[rightBegin++];
}
}
}
快速排序 快速排序也遵循分治的思想,它與歸并排序不同的是,快速排序是原地排序,而且快速排序會先排序當前數組,再對子數組進行排序,它的算法步驟如下:
哨兵劃分:選取數組中最左端元素為基準數,將小于基準數的元素放在基準數左邊,將大于基準數的元素放在基準數右邊
排序子數組:將哨兵劃分的索引作為劃分左右子數組的分界,分別對左右子數組進行哨兵劃分和排序
快速排序的代碼實現如下:
private void sort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
// 哨兵劃分
int partition = partition(nums, left, right);
// 分別排序兩個子數組
sort(nums, left, partition - 1);
sort(nums, partition + 1, right);
}
/**
* 哨兵劃分
*/
private int partition(int[] nums, int left, int right) {
// 以 nums[left] 作為基準數,并記錄基準數索引
int originIndex = left;
int base = nums[left];
while (left < right) {
// 從右向左找小于基準數的元素
while (left < right && nums[right] >= base) {
right--;
}
// 從左向右找大于基準數的元素
while (left < right && nums[left] <= base) {
left++;
}
swap(nums, left, right);
}
// 將基準數交換到兩子數組的分界線
swap(nums, originIndex, left);
return left;
}
private void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}算法特性:
時間復雜度:平均時間復雜度為 O (nlogn),最差時間復雜度為 O (n2)
空間復雜度:最差情況下,遞歸深度為 n,所以空間復雜度為 O (n)
原地排序
非穩定排序
自適應排序
歸并排序的時間復雜度一直是 O (nlogn),而快速排序在最壞的情況下時間復雜度為 O (n2),為什么歸并排序沒有快速排序應用廣泛呢? 答:因為歸并排序是非原地排序,在合并階段需要借助非常量級的額外空間
快速排序有很多優點,但是在哨兵劃分不平衡的情況下,算法的效率會比較低效。下面是對快速排序排序優化的一些方法:
切換到插入排序
對于小數組,快速排序比插入排序慢,快速排序的 sort () 方法在長度為 1 的子數組中也會調用一次,所以,在排序小數組時切換到插入排序排序的效率會更高,如下:
/**
* M 取值在 5 ~ 15 之間大多數情況下都能令人滿意
*/
private final int M = 9;
public void sort(int[] nums, int left, int right) {
// 小數組采用插入排序
if (left + M >= right) {
insertSort(nums);
return;
}
int partition = partition(nums, left, right);
sort(nums, left, partition - 1);
sort(nums, partition + 1, right);
}
/**
* 插入排序
*/
private void insertSort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int base = nums[i];
int j = i - 1;
while (j >= 0 && nums[j] > base) {
nums[j + 1] = nums[j--];
}
nums[j + 1] = base;
}
}
private int partition(int[] nums, int left, int right) {
int originIndex = left;
int base = nums[left];
while (left < right) {
while (left < right && nums[right] >= base) {
right--;
}
while (left < right && nums[left] <= base) {
left++;
}
swap(nums, left, right);
}
swap(nums, left, originIndex);
return left;
}
private void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
基準數優化 如果數組為倒序的情況下,選擇最左端元素為基準數,那么每次哨兵劃分會導致右數組長度為 0,進而使快速排序的時間復雜度為 O (n2),為了盡可能避免這種情況,我們可以對基準數的選擇進行優化,采用三取樣切分的方法:選取數組最左端、中間和最右端這三個值的中位數為基準數,這樣選擇的基準數大概率不是區間的極值,時間復雜度為 O (n2) 的概率大大降低,代碼實現如下:
public void sort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
// 基準數優化
betterBase(nums, left, right);
int partition = partition(nums, left, right);
sort(nums, left, partition - 1);
sort(nums, partition + 1, right);
}
/**
* 基準數優化,將 left, mid, right 這幾個值中的中位數換到 left 的位置
* 注意其中使用了異或運算進行條件判斷
*/
private void betterBase(int[] nums, int left, int right) {
int mid = left + right >> 1;
if ((nums[mid] < nums[right]) ^ (nums[mid] < nums[left])) {
swap(nums, left, mid);
} else if ((nums[right] < nums[left]) ^ (nums[right] < nums[mid])) {
swap(nums, left, right);
}
}
private int partition(int[] nums, int left, int right) {
int originIndex = left;
int base = nums[left];
while (left < right) {
while (left < right && nums[right] >= base) {
right--;
}
while (left < right && nums[left] <= base) {
left++;
}
swap(nums, left, right);
}
swap(nums, originIndex, left);
return left;
}
private void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
三向切分 在數組有大量重復元素的情況下,快速排序的遞歸性會使元素全部重復的子數組經常出現,而對這些數組進行快速排序是沒有必要的,我們可以對它進行優化。 一個簡單的想法是將數組切分為三部分,分別對應小于、等于和大于基準數的數組,每次將其中 “小于” 和 “大于” 的數組進行排序,那么最終也能得到排序的結果,這種策略下我們不會對等于基準數的子數組進行排序,提高了排序算法的效率,它的算法流程如下: 從左到右遍歷數組,維護指針 l 使得 [left, l - 1] 中的元素都小于基準數,維護指針 r 使得 [r + 1, right] 中的元素都大于基準數,維護指針 mid 使得 [l, mid - 1] 中的元素都等于基準數,其中 [mid, r] 區間中的元素還未確定大小關系,圖示如下:
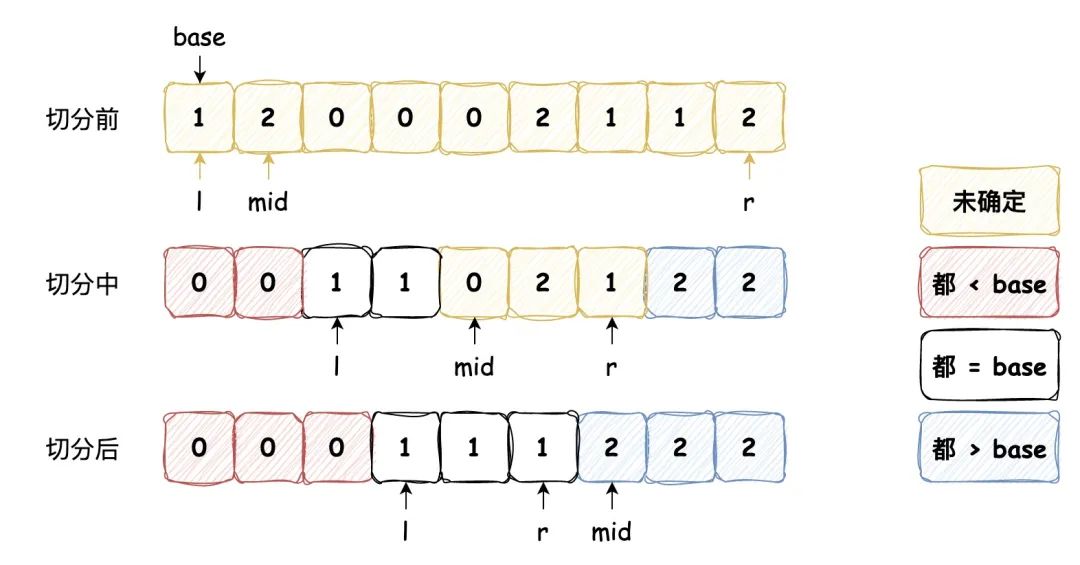
public void sort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
// 三向切分
int l = left, mid = left + 1, r = right;
int base = nums[l];
while (mid <= r) {
if (nums[mid] < base) {
swap(nums, l++, mid++);
} else if (nums[mid] > base) {
swap(nums, mid, r--);
} else {
mid++;
}
}
sort(nums, left, l - 1);
sort(nums, r + 1, right);
}
private void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
這也是經典的荷蘭國旗問題,因為這就好像用三種可能的主鍵值將數組排序一樣,這三種主鍵值對應著荷蘭國旗上的三種顏色
審核編輯:黃飛
-
算法
+關注
關注
23文章
4607瀏覽量
92840 -
數組
+關注
關注
1文章
417瀏覽量
25939
原文標題:時間復雜度為O (nlogn)的排序算法
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

常用的非比較排序算法:計數排序,基數排序,桶排序的詳細資料概述
如何求遞歸算法的時間復雜度
算法時空復雜度分析實用指南2
算法時空復雜度分析實用指南(上)
算法時空復雜度分析實用指南(下)
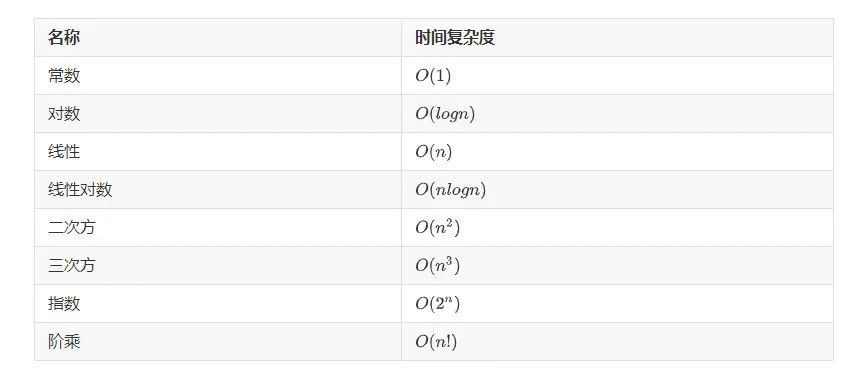
如何計算時間復雜度





 工商網監
工商網監
評論