 一文詳解超標量處理器
一文詳解超標量處理器
一、引言
處理器(central process unit,簡稱CPU)是手機的核心部件,其主要功能是取指令并譯碼執行。CPU主要包括控制器和運算器兩個部件,它對在手機中的所有硬件資源(如存儲器,輸入輸出單元)進行控制調配,執行運算。在系統中所有軟件層的操作,最終都將通過指令集映射為CPU的操作,因此,它的性能高低直接影響著用戶的體驗。
得益于半導體工藝的進步,架構的演進,CPU的性能不斷地提升。然而,應用程序(APP)的不斷發展對處理器性能有了更高的要求,要使得APP運行的穩定、流暢,軟件工作者要深入理解處理器的微架構,理解指令的執行過程,做出一些更精細化的改善和優化。
二、超標量處理器簡介
目前,手機處理器大部分是超標量處理器(superscalar processor)。想要理解超標量處理器,得先明白流水線技術。流水線技術是將一條指令分解為多個步驟(周期),并且每一個周期時間相同。

超標量處理器的流水線中,允許多條指令同時存在。這樣一條指令不用等待它前面的指令執行完畢,就有可能可以進入處理器的后面得到執行,這種方式提升了處指令并行性(ILP: instruction level parallelism),進而提升性能。如上圖所示,當處理器沒有使用流水線的時候,它的時間周期是D,在使用了n級流水線之后,一條指令的平均執行周期變成了D/n+S,其中s表示為流水線中間的延遲。
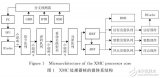
如今,處理器的微架構已經趨于成熟,指令所經過的部件和被處理的過程相似。一個典型的超標量亂序處理器的組織結構如下圖所示:

該處理器它包含了取指令(fetch),譯碼(decode),寄存器重命名(rename),發射(issue),執行(execute),寫回(write back),和提交階段(commit)。
三、處理器流水線介紹
前一小節介紹了超標量處理器的組織結構,本小節將跟蹤指令的具體執行過程,介紹處理器在每一個階段的行為。
1.分支預測/取指令
在取指令階段,除了需要從I-Cache中取出指令之外,同時還要決定下個周期指令的地址。而分支指令的結果只有在執行階段才可以得出,因此,有必要對分支指令的行為進行預測,需要預測的內容包含了跳轉方向和跳轉地址。
a.跳轉方向
分支指令可能是發生跳轉和不發生跳轉,有些分支指令是無條件執行的,它的方向總是發生跳轉,其余分支指令則需要進行預測。
對于分支指令方向的預測,主要有以下4種方式:
首先,本文給大家介紹一個簡單的分支預測

該方法直接使用上次分支的結果,相比于靜態分支預測在一些情況下可以獲得比較好的結果。如下圖,在10000次的for循環語句中,只有兩次預測失敗了,預測失敗率僅有2/10000=0.002%。

但是在一些情況下,預測的結果是不準確的,如指令的方向不停的發生跳轉,那么分支預測的預測失敗率可能接近100%.
i. 基于兩位飽和數的分支預測

兩位飽和數的預測方式在特定情況下有較好的預測結果,但其有一個極限值,因次后來處理器都放棄了這一做法。
ii. 基于局部歷史的分支預測

通過將它的每次跳轉或者不跳轉的結果記錄于BHR寄存器中作為歷史狀態,然后通過PC值索引該表作為參考。如果一條分支指令的執行結果很有規律,那么可以較好地預測正確率。
iii. 基于全局歷史的分支預測

與BHR相似,GHR寄存器記錄了最近所有的分支指令的執行結果并作為預測。
i.競爭的分支預測
基于BHR和GHR,在不同場景的應用中,各有優缺點。競爭的分支預設計了一種自適應的算法根據不同的場景自動的選擇其中一種預測正確率較高的方法。

當處理器預測了分支指令會跳轉之后,需要對目標地址進行預測:
b. 目標地址
i. 直接跳轉:在指令中直接以立即數的形式給出了一個相對PC的偏移值。目標地址是固定的,分支預測器可以準確的找到地址;
ii. 間接跳轉:分支指令的目標地址在通用寄存器中,處理器通過獲取寄存器中的值,然后根據該值進行跳轉。對于一些跳轉地址有規律情形,如call指令調用固定地址的函數,return函數返回至函數調用的下一條指令,預測的結果比較準確。其余一些不規律情形,預測它的跳轉地址則比較困難。
- 譯碼
指令解碼階段的任務是將指令中攜帶的信息提取出來,這時候指令就變成了微操作(uop),處理器的后續階段將使用這些信息繼續執行。對于CICS指令集,指令的長度是不固定的,尋址方式也比較復雜,這增加了譯碼的難度。目前,在手機處理器中主要用的ARM系列處理器,其指令的長度格式是格式固定的,如在32位處理器中:

- 寄存器重命名
接下來,在超標量亂序處理器中,指令將進入寄存器重命名階段。首先,本文介紹關于相關性的概念。在處理器執行過程中,指令之間存在一定的相關性,所謂的相關性是指一條指令的執行依賴于另一條指令的執行結果,指令之間的執行順序不能夠改變,這制約了指令發射階段的選擇范圍。具體的依賴關系有如下三種:
先寫后寫(write after write):表示兩條指令都將結果寫到同一個寄存器;
先讀后寫(write after read):一條指令的目的寄存器和它前面某一條指令的源寄存器一樣;
先寫后讀(read after write):一條指令的源寄存器來自于它前面某條指令的計算結果;
在采用亂序執行的處理器中,寄存器重命名通過映射表將邏輯寄存器(指令中表示的寄存器)映射到物理寄存器(處理器中參與運算的寄存器)解決了WAR 和WAW依賴關系,不存在依賴關系的指令可以同時執行,提高了ILP(instruction level parallesim)。如下圖:

只有第二條指令的源寄存器r0依賴于第一條指令計算的結果,寄存器重命名之后,其余指令之間并無依賴關系。
- 發射
將符合一定條件的指令從發射隊列中選出來,并送到FU(function unit)中去執行。滿足發射條件是指指令的操作數準備好了,FU數量充足。然而,對于訪存(load/store)指令,只有在執行階段指令的地址被計算得出,它們之間的依賴關系才可以知道。處理器有一定的做法,來加速這種執行方式。對于存儲指令加速的如下的三種方式,當出現違例(memory vialotion)時,在流水線的后續階段會進行消歧處理。
- 完全的順序處理
- 部分的亂序指行,如下圖

- 完全的亂序指令
- 執行
指令在執行單元獲得執行,典型的執行單元有ALU,AGU,BPU。
- 寫回
將FU計算的結果寫到物理寄存器堆,并通過旁路網絡將這個計算結果送到需要的地方,喚醒依賴于這條指令計算結果的指令。如:
add r0, r1, r2 (1)
add r4, r0, r3 (2)
當第一條指令的結果r0計算完成,它會通知第二條指令r0的值已近準備好,那么這條指令才有可能變成準備好的狀態并獲得發射執行。
- 提交
程序的指令流順序進入處理器,亂序執行,并按照指令進入ROB(Reorder Buffer,重排序緩存)的順序進行提交這保證了程序執行正確性。保留提交信息的關鍵部件是ROB,它的結構如下圖:

當一條指令到達流水線的這個階段時,ROB會將這條指令標記為complete狀態,但是并不意味著可以提交了,比如異常,分支預測失敗等,一條已經完成狀態的指令可能從流水線中抹掉。所以,在一條指令沒有退休(retire)之前,他的狀態都是推測的(speculative),
ROB本質上是一個FIFO器件,存儲了一條指令的相關信息。如這條指令的類型、結果、目的寄存器、和異常的類型等。ROB的容量決定了流水線中最多可以同時執行的指令的個數。每一個ROB的表項可以包括的內容如下:
(1)complete, 表示一條指令是否已經執行完畢;
(2)Areg: 在原始程序中指定的目的寄存器,它以邏輯寄存器的形式給出;
(3)Preg:指令的Areg經過寄存器重命名之后,對應的物理寄存器編號;
(4)Opreg: 指令的Areg被重命名為新的Preg之前,對應的舊的Preg, 當指令發生異常(exception), 而進行狀態恢復的時候,會使用這個值;
(5)PC:指令對應的PC值,當一條指令發生中斷或者異常的時,需要重新保存這個值;
(6)Exception,如果指令發生了異常,會將這個異常的類型記錄,當指令要退休的時候,會對這個異常進行處理;
(7)Type:指令的類型會被記錄到這里,當指令退休的時候,不同類型的指令會有不同的動作,例如store指令要寫入D-cache。
處理器的執行過程中,錯誤的分支預測也需要處理,這個執行過程如下:
(1) 回滾:將在錯誤路徑上的后續指令從流水線中“沖刷”;
(2) 重新取指:"正確的路徑上取出合適的指令執行;

四、處理器性能建模

處理器的執行過程中,理想狀況下,處理器運行在穩定的狀態,沒有停頓和“汽泡”。然而總會有各種缺失(miss)事件導致性能的下降。根據區間模型理論,處理器的CPI(cycles per instruction)可以根據硬件PMU參數的值和參考硬件手冊中缺失事件的代價,并通過公式進行擬合。這些擬合的結果可以作為應用負載的特性給處理器的調度作為參考。
五、影響處理器發展的三堵墻
- 功耗墻
功耗是影響處理器性能發揮的重要因素,尤其在是嵌入式設備如手機領域,手機通過電池供電,電池容量有限,所以處理器功耗不能過高。

Post-Dennardian(處理器供電電壓不變),系統增加S倍,但是因為供電電壓不變,電容減少了S倍,所以總功耗增大了S^2倍。為了保持總功耗不變,chip利用率將減小為以前的1/S^2。
- 訪存墻
處理器的性能在發展過程中有大量的提升,然而內存受限于工藝,價格,帶寬和延遲等發展緩慢。處理器運算速度和內存訪問速度不匹配。

- 編譯墻
不同處理器有不同的指令集,需要通過二進制翻譯技術將一種處理器上的二進制程序翻譯到另一種處理器上的可執行程序,這可以擴大了硬件、軟件的適用范圍,提高了兼容性。

六、總結
超標量處理器是手機平臺的核心,處理器的微架構在不斷地變化和演進中,軟件工程師如何利用硬件特性,寫出高質量、高性能的代碼成為了一個難點和痛點。
本文詳細介紹了超標量處理器的微架構,跟蹤了一條指令在處理器每一階段的具體執行過程,讓讀者深刻理解了硬件行為。同時,結合性能采樣分析工具如perf, vtune, simpleperf,讀者可以獲取程序的熱點(hotspot)或者性能瓶頸。然后,軟件工作人員可以通過讀取硬件數據PMU(Performance Monitor Unit),深刻理解處理器的性能瓶頸,對代碼做出針對性的調整、優化。這可以充分發揮具體處理器的性能,進而提升整個手機應用的體驗。此外,深刻理解處理器執行方式,通過建模的方式,可以獲悉軟件應用的負載大小,這為操作系統的調度提供了進一步的思考。
處理器,特別是在手機平臺上的處理器,它的性能發揮受限于存儲墻,功耗墻,如何克服這些不利因素,提高未來手機的整體體驗,讀者可以進一步思考。
-
處理器
+關注
關注
68文章
19265瀏覽量
229690 -
寄存器
+關注
關注
31文章
5336瀏覽量
120262 -
CICS
+關注
關注
0文章
3瀏覽量
5478 -
cache技術
+關注
關注
0文章
41瀏覽量
1062 -
for循環
+關注
關注
0文章
61瀏覽量
2502
發布評論請先 登錄
相關推薦
一文詳解高效能x86處理器
一文詳解CP15協處理器

什么是超標量處理器的流水線?超標量處理器的特點有哪些?
Arm Cortex-R52處理器技術參考手冊
ARM Cortex-R52處理器技術參考手冊
Arm Cortex-M7處理器產品介紹
ARM Cortex-R52+處理器技術參考手冊
什么是超標量技術/FADD?
PowerPC芯片特點及超標量體系CPU優化技術
亂序超標量處理器核的功耗優化





 工商網監
工商網監
評論