 探索AIGC未來:CPU源碼優化、多GPU編程與中國算力瓶頸與發展
探索AIGC未來:CPU源碼優化、多GPU編程與中國算力瓶頸與發展
★人工智能;大數據技術;AIGC;Turbo;DALL·E 3;多模態大模型;MLLM;LLM;Agent;Llama2;國產GPU芯片;GPU;CPU;高性能計算機;邊緣計算;大模型顯存占用;5G;深度學習;A100;H100;A800;H800;L40s;Intel;英偉達;算力
近年來,AIGC的技術取得了長足的進步,其中最為重要的技術之一是基于源代碼的CPU調優,可以有效地提高人工智能模型的訓練速度和效率,從而加快了人工智能的應用進程。同時,多GPU編程技術也在不斷發展,大大提高人工智能模型的計算能力,更好地滿足實際應用的需求。
本文將分析AIGC的最新進展,深入探討以上話題,以及中國算力產業的瓶頸和趨勢。
AIGC發展現狀
AIGC產業在上半年經歷“百模大戰”和“百花齊放”的階段后,現在正站在從“玩具”到“工具”的關鍵時期。大模型市場格局發生深刻變化,行業關注焦點也轉向人工智能發展的“終極命題”——應用與商業化落地。AIGC研發范式的變革從根本上提高數據生產效率,降低使用者和開發者的門檻。
為提升模型的能力和效用,行業共同關注放大模型能力的有效途徑,如微調、提示工程、搜索增強生成、AI Agent等技術手段。同時,開源模型迅速發展,產品向終端延伸,結合更多AI應用技術,推動應用場景多元化。然而,由于政策面向C端設置準入門檻,標準體系覆蓋多個行業,強調數據、算法、模型和安全因素的重要性,因此“百模大戰”回歸理性,行業格局邁入整合階段。
2023 Q3國內AIGC行業發生融資事件35起,涉及公司33家,投資機構51家。融資金額39.61億人民幣,種子輪~天使輪21家(占比63.64%)。通用大模型(6起)和工具平臺(6起)兩個細分賽道相對活躍。在應用層中,元宇宙/數字人(5起)和營銷(5起)是融資事件最頻繁的細分領域。有1家國內AIGC企業完成上市——第四范式(決策類人工智能公司)。2023年Q3國內AIGC行業發生1起并購事件——美團收購光年之外,融資額20.65億元。
一、技術迭代
1、多模態大模型DALL·E 3帶來產業沖擊
多模態大語言模型(MLLM)是一種將文本、圖像、音頻和視頻等多模態信息結合訓練的模型,相比大語言模型(LLM)更符合人類感知世界的方式。通過多模態輸入的支持,用戶可以更靈活的方式與智能助手進行交互,并利用強大的大模型作為大腦來執行多模態任務。
DALL·E 3能夠更好地捕捉語義描述的細微差異,實現提示詞的完美遵循,并高效避免混淆詳細請求中的元素,在畫面呈現方面取得明顯進步。同時,文生圖模型與ChatGPT的結合,極大地減少了提示工程的約束。

2、長文本技術增強產品用戶體驗
LLM中的“上下文長度”是指大語言模型在生成預測時考慮的輸入文本長度。更長的文本建模能力使模型能夠觀察到更長的上下文,避免重要信息的丟失。大模型的應用效果取決于兩個核心指標:模型參數量和上下文長度。其中,上下文長度決定大模型的“內存”能力,長文本可以提供更多上下文和細節信息來輔助模型判斷語義,減少歧義,提高歸納和推理的準確性。
目前,國內外對于文本長度的探索還沒有達到“臨界點”,長文本在未來的Agent和AI原生應用中仍然扮演著重要角色。Agent需要依靠歷史信息進行規劃和決策,而AI原生應用需要依靠上下文來保持連貫、個性化的用戶體驗。這也是為什么像月之暗面、OpenAI等大模型公司關注長文本技術的原因。
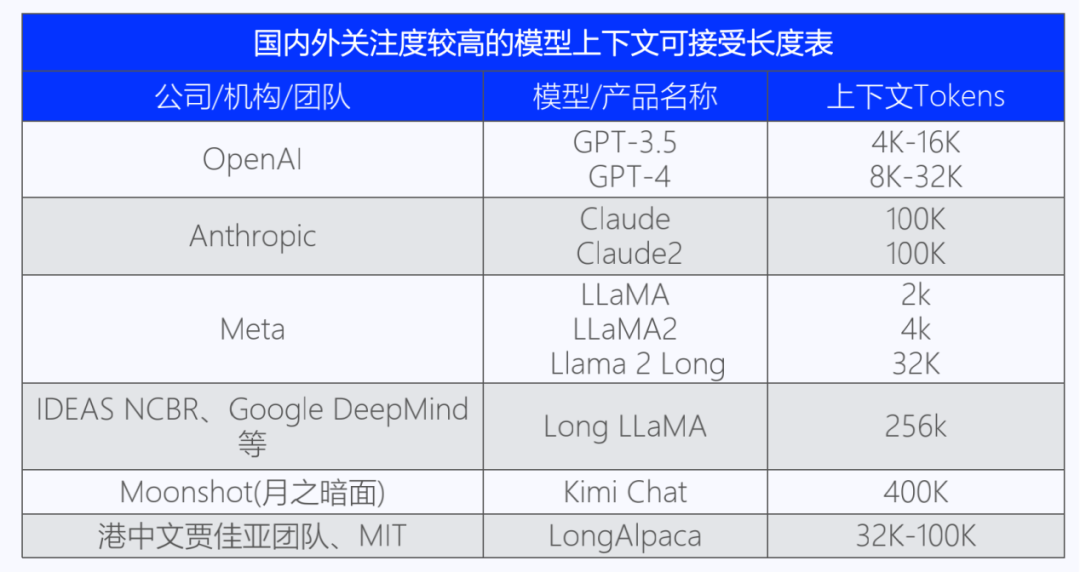
3、Llama2掀起大模型市場新格局
Llama是Meta發布的一款使用公開數據集訓練的大型語言模型,因其與開源協議的兼容性和可復現性而受到AI社區歡迎。但受限于開源協議,LLaMA僅限學術研究使用,不能用于商業用途。
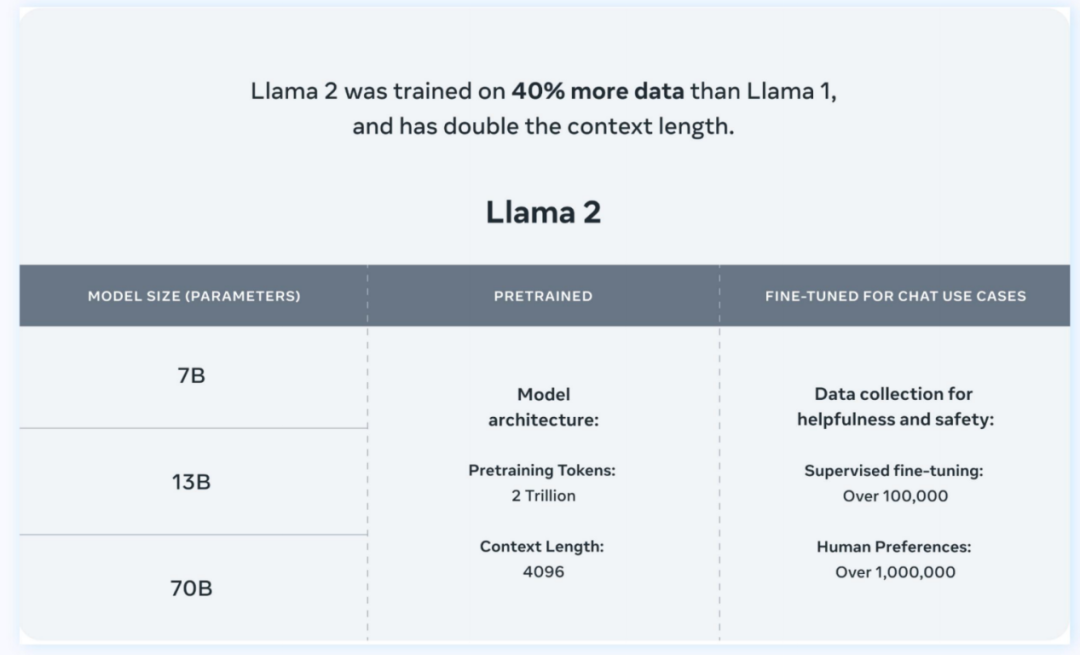
相比Llama 1,Llama 2預訓練語料庫增加40%,達到2萬億Tokens。9月,Llama2的token已達32,768個,并采用分組查詢注意力機制,對文本語義的理解更深入。在MMLU和GSM8K測試中,Llama 2 70B的性能接近GPT-3.5。
4、AI Agent深入挖掘大模型潛力
Agent是指具有自主性、反應性、社會性、預動性、慎思性和認知性等智能特征的軟件或硬件實體,等于大模型+記憶+主動規劃+工具。AI Agent能夠理解、規劃、執行和自我調整,解決更復雜的問題。與LLM相比,AI Agent能夠獨立思考并調用工具逐步完成目標,區別于RPA的是其能夠處理未知環境信息。
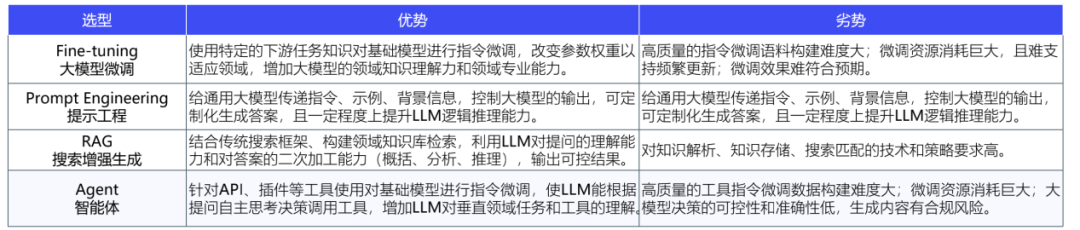
AI Agent與其他技術選型方案發展及優劣勢比較
二、技術趨勢
1、擁抱開源精神,國產模型的崛起已成燎原之勢
在國家的大力支持和頭部廠商的推動下,國產模型已成為大語言模型陣營中的重要力量。盡管起步較晚,且面臨國外高端GPU芯片的圍堵,但國產模型的崛起之勢已成燎原。基礎的互聯網大廠積極推動開源生態體系的構建。
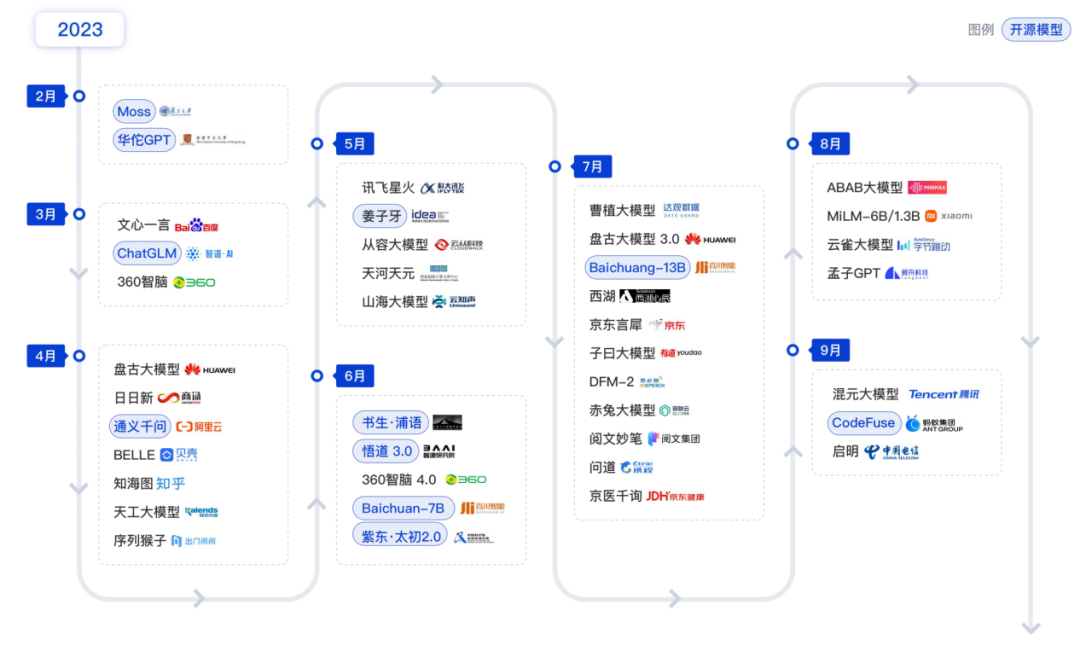
國內AI大模型發展進程 (截至2023年Q3)
2、大模型產品向終端延伸,推動應用場景多元化發展
大模型開源、多模態和Agent等技術將帶來全新、個性化、人性化的交互體驗。未來,大模型將部署在手機、PC、汽車、人形機器人等終端,解決云端AI在成本、能耗、性能、隱私、安全和個性化等方面的問題,并拓寬自動駕駛、智慧教育、智慧家居等場景的多元化應用。然而,如何在端側實現輕量部署和軟硬件深度融合仍是難點問題。

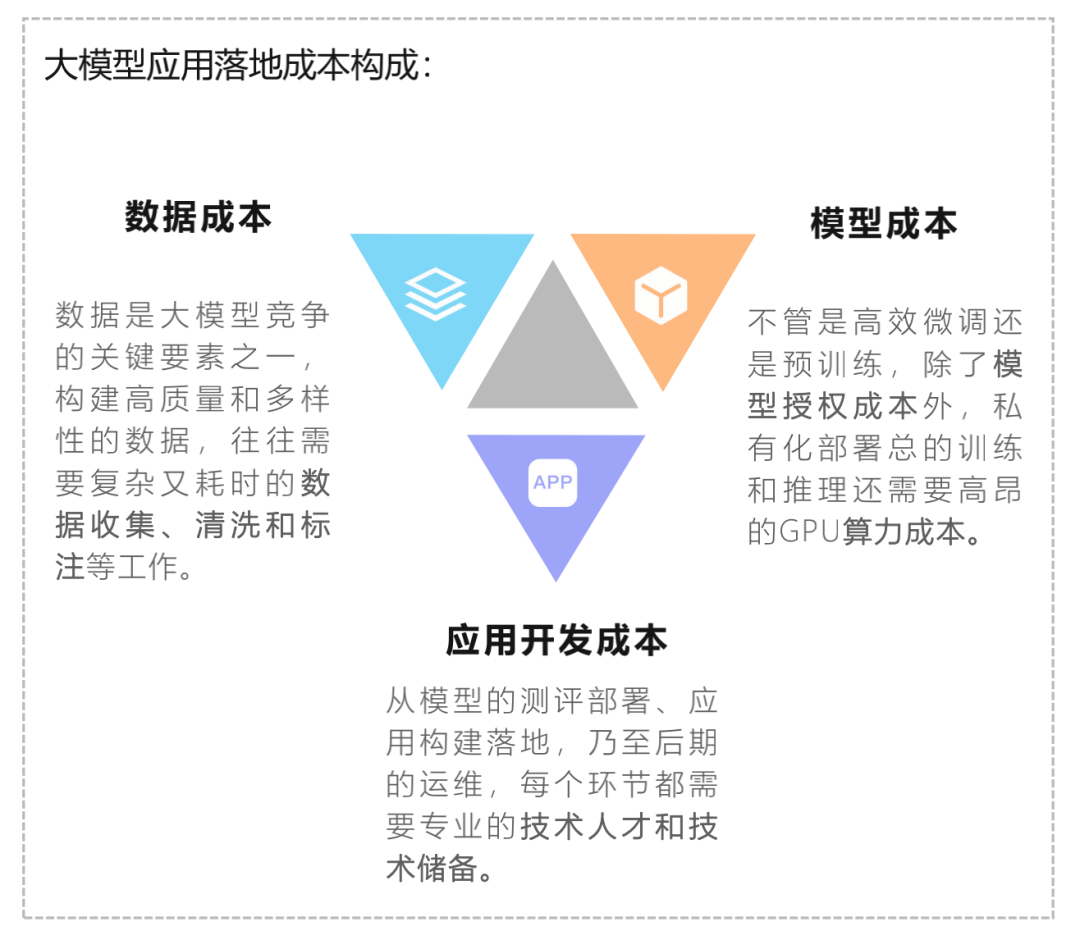
企業私有化部署大模型綜合成本持續降低
大模型應用落地成本包括數據、模型和應用開發成本。模型成本包括授權成本和算力成本。隨著Llama2推動國內模型的商用免費化,MaaS逐漸被市場接受,授權成本過高的壁壘正在消失。通過QLoRA微調和GPTQ量化,中小企業也可以使用千億級模型,算力成本大幅降低。企業私有化部署綜合成本持續降低,有利于大模型對B端市場的滲透。
三、如何確定大模型顯存占用?
在部署大模型時,顯存占用是個關鍵問題。大模型因其巨大規模,要么因顯存溢出而無法運行,要么因模型過大導致推理速度慢。優化大模型的推理與優化小模型CNN的推理有所不同。下面將主要探討如何計算大模型的顯存占用。
以流行的LLama2大模型為例,主要有7B、13B、70B三個版本。B(Billion)是十億,M(Million)是百萬,所以LLama2這類大模型可稱為十億、百億級大模型。
對于深度學習模型,精度通常有float32、float16、int8、int4等。后面的int8、int4等低精度主要用于推理加速。比如,一個float32會占用4個字節32個比特,往后就減半,如int8是1字節占用8比特,int4的占用空間會更加小。參數量和模型精度可以用來計算模型的顯存占用。以LLama2-13B為例:
對于float32精度:13 * 10^9 * 4 / 1024^3 約等于 48.42G
對于float16精度:13 * 10^9 * 2 / 1024^3 約等于 24.21G
以此類推,計算LLama2-7B的顯存占用。
對于float32精度:7 * 10^9 * 4 / 1024^3 約等于 26.08G;
對于float16精度顯存減半:約等于 13G;
對于int8精度再減半:約等于6.5G;
對于int4精度再減半:約等于3.2G。
可見低比特量化在大模型部署顯存管理中的重要性。上述推理顯存占用只適用于模型前向推理,不適用于模型訓練。訓練過程中還會受梯度、優化器參數、bs等因素影響。一般經驗來說,訓練時的顯存占用會是推理時的好多倍,甚至十幾倍。上述推理顯存占用是理論值,實際肯定會更多一些,因此需要預留一些余量。例如,實測LLama2-13B時,理論值約為48.21G,但實際需要大約52G的顯存。當然,這種方法也適用于CNN模型的前向推理顯存占用計算。
基于源代碼的CPU調優
對于高性能應用,如云服務、科學計算和3A游戲等,硬件基礎至關重要。忽視硬件因素可能導致性能瓶頸。標準算法和數據結構在某些場景下可能無法提供最佳性能。
一、CPU前端優化
隨著“扁平化”數據結構的普及,鏈表逐漸被淘汰。傳統鏈表每個節點動態分配內存,導致內存訪問延遲和碎片化。這使得遍歷鏈表比遍歷數組更耗時。有些數據結構(如二叉樹)有類似鏈表的天然結構,使用指針追蹤實現可能更高效。另外,更高效的數據結構版本如boost::flat_map 和 boost::flat_set也存在。
特定問題的最優算法在特定場景中可能不是最好的選擇。例如,二分搜索在排序數組中查找元素很高效,但分支預測錯誤可能導致其在大規模數據中表現不佳。因此,在處理小規模整型數組時,線性搜索可能更有效。總之,針對高性能應用,需要深入理解硬件和算法性能,并靈活選擇和優化合適的算法和數據結構以適應不同場景。
“數據驅動”優化是一種重要的調優技術,基于對程序處理數據的深入理解。專注于數據的分布和在程序中的轉化方式。其中一個典型的例子是將數組結構體(SOA)轉換為結構體數組(AOS)。選擇哪種布局取決于代碼訪問數據的方式。如果程序遍歷數據結構并僅訪問字段b,則SOA更有效,這主要是由于所有內存訪問都是按順序執行;如果程序遍歷數據結構并對對象的所有字段(即a、b和c)進行大量操作,則AOS更佳,因為所有成員都可能保存在相同的緩存行中,減少緩存行讀取,提高內存帶寬利用率。要進行此類優化,需要了解程序將處理哪些數據和數據的分布情況,并相應地修改程序。

另一個重要的數據驅動優化方法是“小尺寸優化”,旨在為容器預先分配固定量的內存,以避免動態內存分配。該方法在LLVM基礎設施中廣泛應用,并可顯著提升性能(如對于SmallVector,boost::static_vector也是基于相同概念實現)。現代CPU是非常復雜的設備,幾乎不可能預測某段代碼的運行方式。CPU指令的執行受制于眾多因素,包括許多變化的組件。
1、機器碼布局
機器碼布局指編譯器將源代碼轉化為串行的字節列。由于編譯器會影響到二進制文件的性能,因此在將源代碼翻譯為機器碼時,會考慮到指令在內存中的放置偏移位置。
2、基本塊
基本塊是指具有單個入口和出口的指令序列,可以有多個前驅和后繼,但在基本塊中間沒有任何指令可以跳出基本塊。這種結構確保了基本塊中的每條代碼只會被執行一次,從而大大減少控制流圖分析和轉換的問題。
3、基本塊布局
// hot path
if (cond)
coldFunc();
// hot path again
如果條件cond通常為真,那么選擇默認布局,因為另一個布局會導致兩次而不是一次跳轉。coldFunc是錯誤處理函數,不太可能經常執行,因此選擇保持熱點代碼間的直通,并將選取分支轉化為未被選取分支。選擇這種布局的原因如下:
1)CPU每個時鐘可以執行2個未被選擇的分支,但每2個時鐘周期才能執行一個被選取的分支,因此未被選取的分支比被選取時耗時更少。
2)所有熱點代碼都是連續的,沒有緩存行碎片化問題,因此可以更充分利用指令和微操作緩存。
3)每個被選取的跳轉指令都意味著跳轉之后的字節都是無效的,因此被選取的分支對于讀取單元來說也更耗時。
4、基本塊對齊
性能因指令在內存中的偏移而變化。若循環跨越多條緩存行,CPU前端可能會出現性能問題。因此,可以使用nop指令將循環提前,使其整個循環位于一條緩存行中。
LLVM使用-mllvm-align-all-blocks對齊基本塊,但可能造成性能劣化。插入nop指令會增加程序開銷,尤其在關鍵路徑上。盡管nop指令不需要執行,但仍需從內存中讀取、解碼和執行,消耗前端數據結構和記賬緩沖區空間。
為精確控制對齊,可使用ALIGN匯編指令。開發人員先生成匯編列表,然后插入ALIGN指令以滿足特定實驗場景的需求。
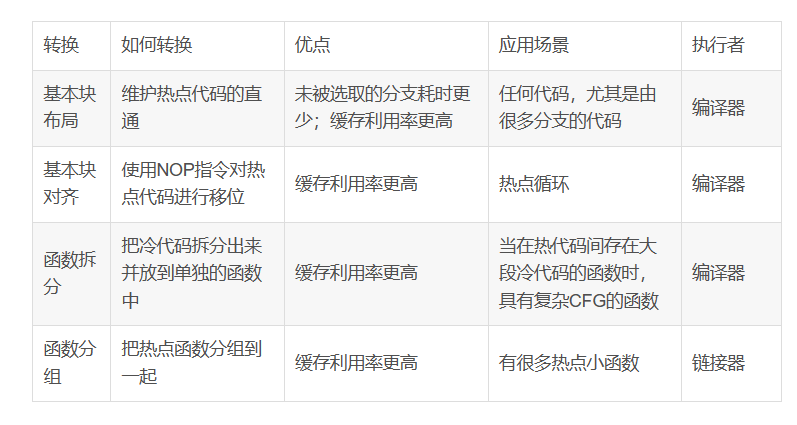
5、函數拆分
函數拆分是為了優化在熱點路徑具有復雜CFG和大量冷代碼的函數。通過將冷代碼移動到單獨的函數中,可以避免在運行時加載不必要的代碼,從而改善內存占用情況。
在優化后的代碼中,將原來的函數拆分為兩個函數,一個包含熱點代碼,另一個包含冷代碼。通過將冷代碼移動到單獨的函數中,可以避免在運行時加載不必要的代碼,從而改善內存占用情況。同時,使用__attribute__((noinline))禁止內聯冷函數,以避免冷函數被內聯到熱點代碼中,從而影響性能。
通過將熱點代碼和冷代碼分離,可以更好地利用CPU前端數據結構(指令緩存和DSB),提高CPU的利用率。同時,將新函數放在.text段之外,可以避免在運行時加載不必要的代碼,從而改善內存占用情況。
6、函數分組
熱點函數可以聚集在一起,以提高CPU前端緩存的利用率,降低緩存行的讀取需求。鏈接器負責規劃程序中所有函數的排列布局,LLD鏈接器通過--symbol-ordering-file優化函數布局。HFSort工具能根據剖析數據自動生成分區排序文件。
7、基于剖析文件的編譯優化
大多數編譯器具備一組轉換功能,可根據剖析數據來調整算法,這被稱為PGO(Profile-Directed Optimization)。剖析數據生成有兩種方式:代碼插樁和基于采樣的剖析。
1)利用LLVM編譯器通過-fprofile-instr-generate參數生成插樁代碼,再使用-fprofile-inst-use參數利用剖析數據重新編譯程序,生成PGO調優的二進制文件。
2)基于采樣生成編譯器所需的剖析數據,然后通過AutoFDO工具將linux perf生成的采樣數據轉換為GCC和LLVM編譯器可理解的形式。但編譯器會假設所有負載表現相同。
8、對ITLB的優化
內存中的虛地址到物理地址轉換是前端優化的關鍵領域之一。通過將性能關鍵代碼映射到大頁上,可以減輕ITLB(指令翻譯緩沖)的壓力。這需要重新鏈接二進制文件,確保代碼段在適當的頁邊界對齊。除使用大頁,還可以采用其他技術來優化指令緩存性能,如重新排列函數以使熱點函數更集中,使用LTO(鏈接時間優化)/IPO(內聯函數優化)來減小熱點區域的大小,使用PGO(基于剖析的編譯優化)并避免過度內聯。
二、CPU后端優化
在計算機處理過程中,前端完成取指和譯碼后,如果后端資源不足無法處理新的微操作,會導致前端無法繼續交付微操作。例如,當數據緩存未命中或除法單元過載時,后端無法高效處理指令,從而造成前端停滯。
1、存儲bound
當應用程序進行大量內存訪問并花費較長時間等待內存訪問完成時,被視為存儲bound。這意味著需要優化存儲訪問情況,減少存儲訪問次數或升級存儲子系統。
在TMA中,存儲bound會統計CPU流水線由于按需加載或存儲指令而阻塞的部分槽位。解決此類性能問題的第一步是定位導致高“存儲bound”指標的訪存操作,并識別具體的訪存操作。然后開始進行調優。
1)緩存友好的數據類型
關于緩存友好算法和數據結構是性能關鍵要素之一,重點在于時間和空間局部性原則,目標是從緩存中高效地讀取所需的數據。
按順序訪問數據
利用緩存空間局部性的最佳方法是順序訪問內存。標準實現二分搜索不會利用空間局部性,而解決這個問題的方法之一是Eytzinger布局存儲數組元素。其思想是維護一個隱式二叉搜索樹,并使用類似廣度優先搜索的布局將二叉搜索樹打包到一個數組中。
使用適當容器
幾乎所有語言都提供各種現成的容器,理解它們底層存儲機制和性能影響至關重要。在處理數據時,需要根據代碼的具體情況來選擇合適的數據存儲方式。
打包數據
提高內存層次利用率的一種方式是使數據更加緊湊。打包數據的一個經典例子就是使用位存儲,可以極大地減少來回傳輸的內存數量,同時節省緩存空間。然而,由于b和a與c共享一個機器字,編譯器需要執行移位操作。在額外計算的開銷比低效內存轉移開銷低的情況下,打包數據是值得的。
對于結構體或類中的字段布局,程序員可以通過重新排列來減少內存的使用,同時避免由編譯器添加結構體填充。例如,如果有一個結構體包含一個布爾值和一個整數,最好將整數放在前面,因為這樣可以使用整數的位來存儲布爾值,從而節省內存。
對齊與填充
當變量存儲在能被其大小整除的內存地址時,訪問效率最高。對齊可能導致未使用的字節形成空位,降低內存帶寬利用率。為避免邊緣情況如緩存爭用和偽共享,需要填充數據結構成員。例如,兩個線程訪問同一結構體的不同字段時,緩存一致性問題可能導致程序運行速度明顯降低。通過填充方法,可確保結構體的不同字段位于不同的緩存行。當使用malloc進行動態分配時,要確保返回的內存地址滿足平臺目標的最小對齊要求。最重要的是,對于SIMD代碼,當使用編譯器向量化內建函數時,地址通常要被16、32或64整除。
動態內存分配
malloc的替代方案往往更快、更可擴展,更能有效地處理內存碎片問題。動態內存分配的一個挑戰在于,多個線程可能同時嘗試申請內存,導致效率降低。
為解決此問題,可以使用自定義分配器加速內存分配。這類分配器的優勢在于開銷較低,因為避免了每次內存分配都進行系統調用。同時,也具有高度靈活性,允許開發者根據操作系統的內存區域來實現自己的分配策略。一種策略是維護兩個不同的分配器,各自負責熱數據和冷數據的分配。將熱數據放在一起可以共享高速緩存行,從而提高內存帶寬利用率和空間局部性。同時,這種策略還可以提高TLB利用率,因為熱數據占用的內存頁更少。此外,自定義內存分配器還可以利用線程本地存儲來實現每個線程的獨立分配,從而消除線程間的同步問題。
針對存儲器層次調優代碼
某些應用程序的性能取決于特定層緩存的大小,最著名的例子是使用循環分塊來改進矩陣乘法。
2)顯式內存預取
當arr數組規模較大時,硬件預取可能無法識別訪存模式并提前獲取所需數據。為在計算j與arrp[j]請求之間的時間窗口內手動添加預取指令,可使用__builtin_prefetch,如下所示:
for (int i = 0; i < N; ++i) {
int j = calNextIndex();
__builtin_prefetch(arr + j, 0, 1);
// ...
doSomeExtensiveComputation();
// ...
x = arr[j];
}
為使預取有效,需提前插入預取指示,確保用于計算的值在計算時已加載到緩存中,同時避免過早插入預取提示以避免污染緩存。
顯式內存預取不可移植,一個平臺上的性能提升無法保證在另一個平臺上也有相同效果。此外,顯式預取指令會增加代碼大小并增加CPU前端的壓力。
3)針對DTLB優化
TLB分為ITLB和DTLB在L1,統一TLB在L2。L1 ITLB未命中時延很小,通常被亂序執行隱藏。統一TLB未命中會調用頁遍歷器,可能導致性能損失。
Linux默認頁面大小為4KB,增大頁大小可減少TLB條目和未命中次數。Intel 64和AMD 64支持2MB和1GB巨型頁。使用大頁的TLB更緊湊,遍歷內核頁表的代價減少。
在Linux系統中,應用程序使用大頁的方法有顯式大頁和透明大頁。使用libhugetlbfs庫可動態分配大頁內存。開發者可以通過以下方式控制對大頁的訪問:帶MAP_HUGETLB參數使用mmap;掛載hugetlbfs文件系統中的文件使用mmap;對SHM_HUGETLB參數使用shmget。
2、計算bound
主要有兩種性能瓶頸:硬件計算資源短缺和軟件指令依賴關系。前者指執行單元過載或執行端口爭用,發生在負載頻繁執行大量繁重指令時;后者指程序數據流或指令流中的依賴關系限制了性能。下面討論函數內聯、向量化和循環優化等常見優化手段,旨在減少執行指令總量,提高性能。
1)函數內聯
內聯函數不僅可以消除函數調用的開銷,還可以擴展編譯器分析的范圍,進行更多優化。但內聯也可能增加編譯后文件的大小和編譯時間。編譯器通常基于成本模型來決定是否內聯函數,例如LLVM會考慮計算成本和調用次數。一般而言,小函數、單一調用點的函數更可能被內聯,而大型函數和遞歸函數通常不會被內聯。通過指針調用的函數可以用內聯來代替直接調用。開發者可以使用特殊提示(如C++ 11的gnu::always_inline)來強制內聯函數。另一種方法是剖析數據來識別潛在的內聯對象,特別是分析函數的參數傳遞和返回頻率。
2)循環優化
循環是程序中執行最頻繁的代碼段,因此大部分執行時間都在循環中消耗。循環的性能受到內存延遲、內存帶寬或計算能力的限制。屋頂線模型是一個很好的基于硬件理論最大值的評估不同循環的方法,TMA分析是另一種處理這種瓶頸的方法。
低層優化
通過將循環中永遠不會改變的表達式移到循環外,進行循環不變量外提,有助于提高算術強度性能。循環展開可以增加指令級并行,同時減少循環開銷,但不建議開發者手動展開任何循環,因為編譯器非常擅長并以最佳方式展開循環。借助亂序執行,處理器具有“內嵌的展開器”。循環強度折疊使用開銷更小的指令代替開銷高的指令,應用于所有循環變量的表達式和數組索引,編譯器通過分析變量的值在循環迭代中的演變方式來實現。此外,如果循環內部有不變的判斷條件,將其移到循環外,即進行循環判斷外提,也有助于提高性能。
高層優化
此類優化策略會深度改變循環結構,并可能影響多個嵌套循環的整體性能。其根本目的是提升內存訪問效率,解決內存帶寬和時延的瓶頸問題。為實現這個目標,可以采用以下幾種策略:通過交換嵌套循環的順序,使得對多維數組元素的內存訪問更加有序,從而消除帶寬和時延的限制;將多維循環的執行范圍合理拆分為多個循環塊,使得每塊數據的訪問能夠與CPU緩存的大小相適配,從而優化跨步幅訪存的內存帶寬和時延;對于可以合并的情況,將多個獨立的循環合并在一起,以減少循環開銷,同時改善內存訪問的時間局部性。
但需要注意的是,循環合并并不總是能提高性能,有時候將循環拆分為多條路徑、預過濾數據、對數據進行排序和重組等可能更有效。拆分循環有助于解決在大循環中發生的緩存高度爭用問題,還可以減少寄存器壓力,并且可以借助編譯器對小循環進行進一步的單獨優化。
3)發現循環優化的機會
編譯優化報告顯示轉換失敗,需要查看由應用程序剖析文件生成的匯編代碼的熱點部分。優化的策略應從簡單的方案開始嘗試,然后開發者需明確循環中的瓶頸,并基于硬件理論最大值評估性能。可以使用屋頂線模型來確定需要分析的瓶頸點,然后嘗試各種變換。
4)使用循環優化框架
多面體框架可用于檢查循環轉換的合法性并自動轉換循環。Polly是基于LLVM的高層循環和數據局部性優化器及優化基礎設施,采用基于整數多面體的抽象數學表示來分析和優化程序的內存訪問模式。要啟用Polly,需要用戶通過顯式的編譯器選項(-mllvm -polly)來啟用,因為LLVM基礎設施的標準流水線并未默認啟用Polly。
3、向量化
使用SIMD指令可以顯著提高未向量化代碼的運行速度。性能分析的重點之一是確保關鍵代碼能夠被編譯器正確向量化。如果編譯器無法生成所需的匯編指令,可以使用編譯器內建函數重寫代碼片段。使用編譯器內建函數的代碼與內聯后的匯編代碼類似,可讀性較差。通常可以通過使用編譯注解等方式來指導編譯器進行自動向量化。編譯器可以進行三種向量化操作:內循環自動向量化、外循環向量化和超字向量化。
1)編譯器自動向量化
編譯器自動向量化受到多種因素阻礙,包括編程語言的固有語義和處理器向量操作的限制。這些因素導致編譯器難以有效地將循環轉換為向量化的代碼。然而,通過合法性檢查、收益檢查和轉換三個階段,可以逐步優化代碼并提高程序的運行速度。在合法性檢查階段,評估循環向量化是否滿足一系列條件,以確保生成的代碼正確且有效。在收益檢查階段,比較不同的向量化因子并選擇最優的方案,同時考慮代碼的執行成本和效率。最后,在轉換階段,將通過插入向量化的保護代碼來啟用向量化執行,并優化代碼以提高運行速度。
2)探索向量化的機會
分析程序中的熱點循環,檢查編譯器已進行哪些優化,最簡單方法是查看編譯器向量化標記。當循環無法向量化時,編譯器會給出失敗原因。另一種方法是檢查程序的匯編輸出,分析剖析工具的輸出更好。雖然查看匯編費時,但該技能回報高,因為可從匯編代碼中發現次優代碼、缺乏向量化、次優向量化因子、執行不必要計算等。
向量化標記能清晰解釋問題及編譯器不能向量化代碼的原因。gcc 10.2可輸出優化報告(使用參數-fopt-info啟用)。開發者應意識到向量化代碼的隱藏成本,尤其是AVX512可能導致大幅降頻。對于循環次數小的循環,強制向量化程序使用小向量化因子或計數展開以減少循環處理的元素數量。
多GPU編程
CUDA提供多GPU編程的功能,包括在一個或多個進程中管理多設備,使用統一的虛擬尋址直接訪問其他設備內存,GPUDirect,以及使用流和異步函數實現的多設備計算通信重疊。
一、從一個GPU到多GPU
在處理大規模數據集時,使用多GPU是提高計算效率和吞吐量的有效方式。多GPU系統通過不同的連接方式,如通過PCIe總線或在集群中的網絡交換機連接,來實現高效的GPU間通信。在多GPU應用程序中,工作負載的分配和數據交換模式是關鍵因素。最基本的模式是各問題分區在獨立GPU上運行,而更復雜的模式則需要考慮數據如何在設備間進行最優移動以避免數據復制到主機再復制到另一GPU。
1、在多GPU上執行
CUDA的cudaGetDeviceCount函數可確定系統內可用的CUDA設備數量。在利用CUDA與多GPU協作的應用程序中,必須顯式指定目標GPU。使用cudaSetDevice(int id)函數可設置當前設備,該函數將具有特定ID的設備設置為當前設備,與其他設備無同步,因此開銷較低。
如果在首個CUDA API調用前未顯示調用cudaSetDevice函數,則當前設備將自動設置為設備0。選定當前設備后,所有CUDA運算將應用于此設備,包括:從主線程分配的設備內存、由CUDA運行時函數分配的主機內存、由主機線程創建的流或事件以及由主機線程啟動的內核。
多GPU適用于以下場景:單節點的單線程、單節點的多線程、單節點的多進程以及多節點的多進程。以下代碼展示如何在主機線程中執行內核和內存拷貝:
for (int i = 0; i < ngpus; i++) { ?
cudaSetDevice(i);
kernel<<>>(...);
cudaMemcpyAsync();
}
由于循環中的內核啟動和數據傳輸是異步的,因此在每次操作后,控制將快速返回至主機線程。
2、點對點通信
在計算能力2.0或以上的設備上,64位應用程序執行的內核可以直接訪問連接到同一PCIe根節點的GPU全局內存,但需使用CUDA點對點API進行設備間直接通信,該功能需要CUDA4.0或更高版本。點對點訪問和傳輸是CUDA P2P API支持的兩種模式,但當GPU連接到不同PCIe根節點時,將不允許直接點對點訪問,此時可使用CUDA P2P API進行點對點傳輸,但數據傳輸會通過主機內存進行。
1)啟用點對點訪問
點對點訪問允許GPU直接引用連接到同一PCIe根節點的其他GPU設備內存上的數據。使用cudaDeviceCanAccessPeer檢查設備是否支持P2P,設備能直接訪問對等設備全局內存則返回1,否則返回0。在兩個設備間,必須使用cudaDeviceEnablePeerAccess顯式啟用點對點內存訪問,該函數允許當前設備到peerDevice的點對點訪問,授權的訪問是單向的。點對點訪問保持啟用狀態,直到被cudaDeviceDisablePeerAccess顯式禁用。32位應用程序不支持點對點訪問。
2)點對點內存復制
在兩個設備之間啟用對等訪問后,可以使用cudaMemcpyPeerAsync函數異步復制設備上的數據。該函數將數據從源設備srcDev傳輸到目標設備dstDev。如果srcDev和dstDev連接在同一PCIe根節點上,數據傳輸將沿著PCIe的最短路徑執行,無需通過主機內存中轉。
3、多GPU間同步
多GPU應用程序中,流和事件與單一設備關聯,典型工作流程包括:選擇GPU集、為每個設備創建流和事件、分配設備資源、通過流啟動任務、查詢和等待任務完成并清空資源。只有與流關聯的設備才能啟動內核和記錄事件。內存拷貝可在任何流中進行,與設備和當前狀態無關。即使流或事件與當前設備不相關,也可以查詢或同步它們。
二、多GPU間細分計算
1、在多設備上分配內存
在分配多個設備任務之前,首先需要確定系統中的可用GPU數量。通過cudaGetDeviceCount獲取GPU數量并打印。
接下來,為每個設備聲明所需的內存和流。使用cudaSetDevice為每個設備分配內存和流。
對于每個設備,分配一定大小的主機內存和設備內存,并創建流。為了在設備和主機之間進行異步數據傳輸,還需要分配鎖頁內存。
最后,使用循環為每個設備執行以下操作:
1)設置當前設備
2)分配設備內存:cudaMalloc
3)分配主機內存:cudaMallocHost
4)創建流:cudaStreamCreate
這樣,就為每個設備分配了內存和流,準備好進行任務分配和數據傳輸。
2、單主機線程分配工作
// 在設備間分配操作之前,為每個設備初始化主機數組的狀態
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i);
initial(h_A[i], iSize);
initial(h_B[i], iSize);
}
// 在多個設備間分配數據和計算
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i);
cudaMemcpyAsync(d_A[i], h_A[i], iBytes, cudaMemcpyHostToDevice, streams[i]);
cudaMemcpyAsync(d_B[i], h_B[i], iBytes, cudaMemcpyHostToDevice, streams[i]);
iKernel<<>>(d_A[i], d_B[i], d_C[i], iSize);
cudaMemcpyAsync(gpuRef[i], d_C[i], iBytes, cudaMemcpyDeviceToHost, stream[i]);
}
cudaDeviceSynchronize();
這個循環遍歷多個GPU,為設備異步地復制輸入數組。然后在想要的流中操作iSize個數據元素以便啟動內核。最后,設備發出異步拷貝命令,把結果從內核返回到主機。因為所有的元素都是異步的,所以控制會立即返回到主機線程。
三、多個GPU上的點對點通信
下面將測試兩個GPU之間的單向內存復制;兩個GPU之間的雙向內存和內核中對等設備內存的訪問3種情況;
1、實現點對點訪問
首先,必須對所有設備啟用雙向點對點訪問,代碼如下;
// 啟動雙向點對點訪問權限
inline void enableP2P(int ngpus)
{
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i)
for (int j = 0; j < ngpus; j++)
{
if (i == j)
continue;
int peer_access_available = 0;
cudaDeviceCanAccessPeer(&peer_access_available, i, j);
if (peer_access_avilable)
{
cudaDeviceEnablePeerAccess(j, i);
printf(" > GP%d enbled direct access to GPU%dn", i, j);
}
else
printf("(%d, %d)n", i, j);
}
}
}
函數enbleP2P遍歷所有設備對(i,j),如果支持點對點訪問,則使用cudaDeviceEnablePeerAccess函數啟用雙向點對點訪問。
2、點對點內存復制
不能啟用點對點訪問的最有可能的原因是它們沒有連接到同一個PCIe根節點上。如果兩個GPU之間不支持點對點訪問,那么這兩個設備之間的點對點內存復制將通過主機內存中轉,從而降低了性能。
啟用點對點訪問后,下面的代碼在兩個設備間執行ping-pong同步內存復制,次數為100次。
// ping-pong undirectional gmem copy
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpy(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpy(d_src[0], drc[1], iBytes, cudaMemcpyDeviceToHost);
}
請注意,在內存復制之前沒有指定設備,因為跨設備的內存復制不需要顯式地設定當前設備。如果在內存復制前指定了設備,也不會影響它的行為。
如需衡量設備之間數據傳輸的性能,需要把啟動和停止事件記錄在同一設備上,并將ping-pong內存復制包含在內。然后,用cudaEventElapsedTime計算兩個事件之間消耗的時間。
// ping-pong undirectional gmem copy
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpy(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpy(d_src[0], drc[1], iBytes, cudaMemcpyDeviceToHost);
}
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
...
}
cudaSetDevice(0);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsed_time_ms;
cudaEventElapsedTime(&elapsed_time_ms, start, stop);
elapsed_time_ms /= 100;
printf("Ping-pong unidirectional cudaMemcpy: tt %8.2f ms", elapsed_time_ms);
printf("performance: %8.2f GB/sn", (float)iBytes / (elapsed_time_ms * 1e6f));
因為PCIe總線支持任何兩個端點之間的全雙工通道,所以也可以使用異步復制函數來進行雙向的且點對點的內存復制。
// bidirectional asynchronous gmem copy
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpyAsync(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpyAsync(d_rcv[0], drcv[1], iBytes, cudaMemcpyDeviceToHost);
}
注意,由于PCIe總線是一次兩個方向上使用的,所以獲得的帶寬增加了一倍。
中國算力產業發展及瓶頸
一、市場規模:服務器作為算力載體,受益云計算需求提升
1、產業鏈:下游各領域算力需求帶動服務器產業發展
服務器產業鏈上游主要是電子材料及零部件/配套。中游為各類服務器產品,包括云服務器、智能服務器、邊緣服務器、儲存服務器。下游需求主體為數據中心服務商、互聯網企業、政府部門、金融機構、電信運營商等。
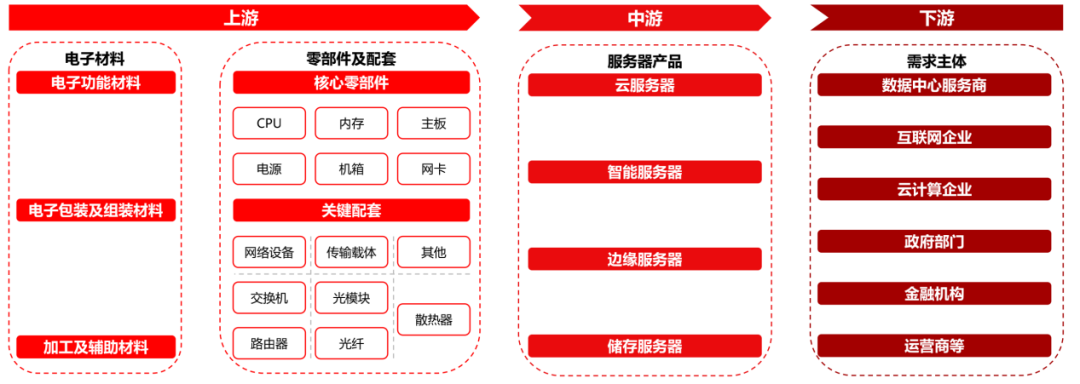
服務器產業鏈全景圖
2、云計算:算力應用互聯網需求最大,其次為政府、服務等
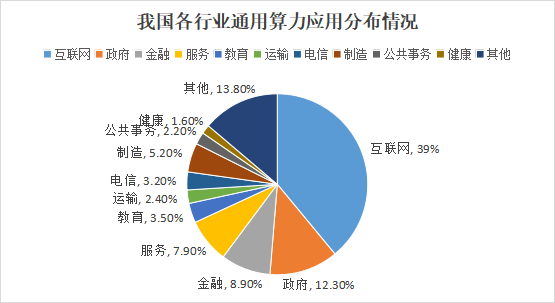
在通用算力領域,互聯網行業依然是算力需求最大的行業,占據了通用算力的39%。電信行業加大了對算力基礎設施的投入,算力份額首次超過政府行業,位列第二。而政府、服務、金融、制造、教育、運輸等行業位列三到八位。
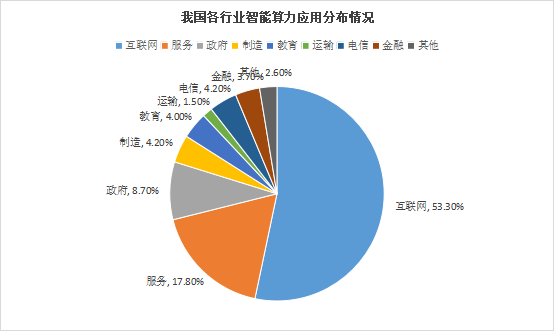
在智能算力領域,互聯網行業對數據處理和模型訓練的需求持續增長,成為智能算力需求最大的行業,占據了智能算力的53%。服務行業正在快速從傳統模式轉向新興智慧模式,其算力份額占比位列第二。而政府、電信、制造、教育、金融、運輸等行業分列第三到八位。
2、云計算:中國市場增速快于全球,預計2025年突破萬億元
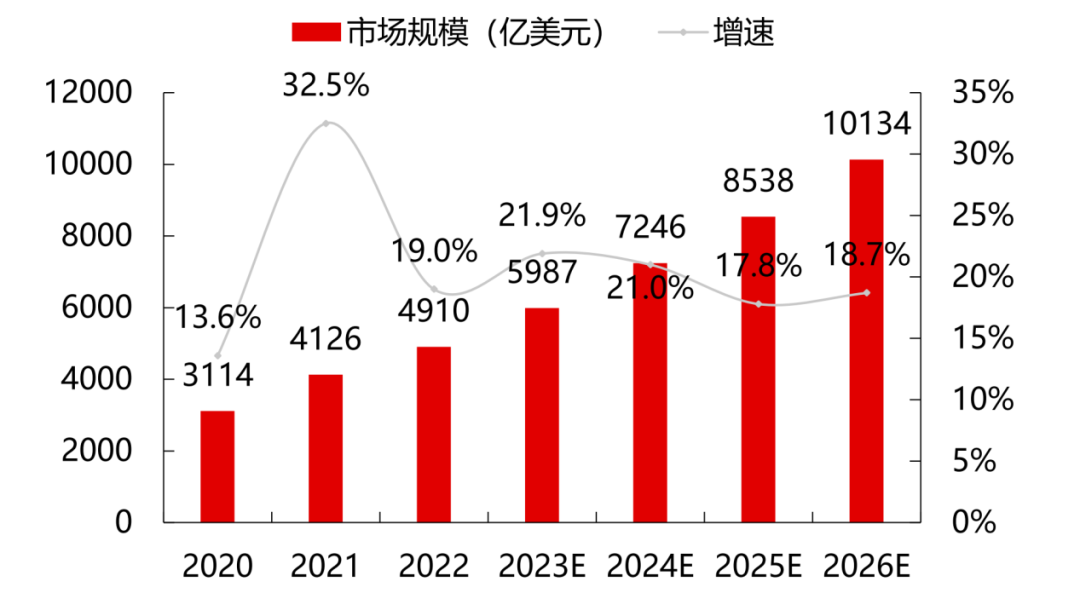
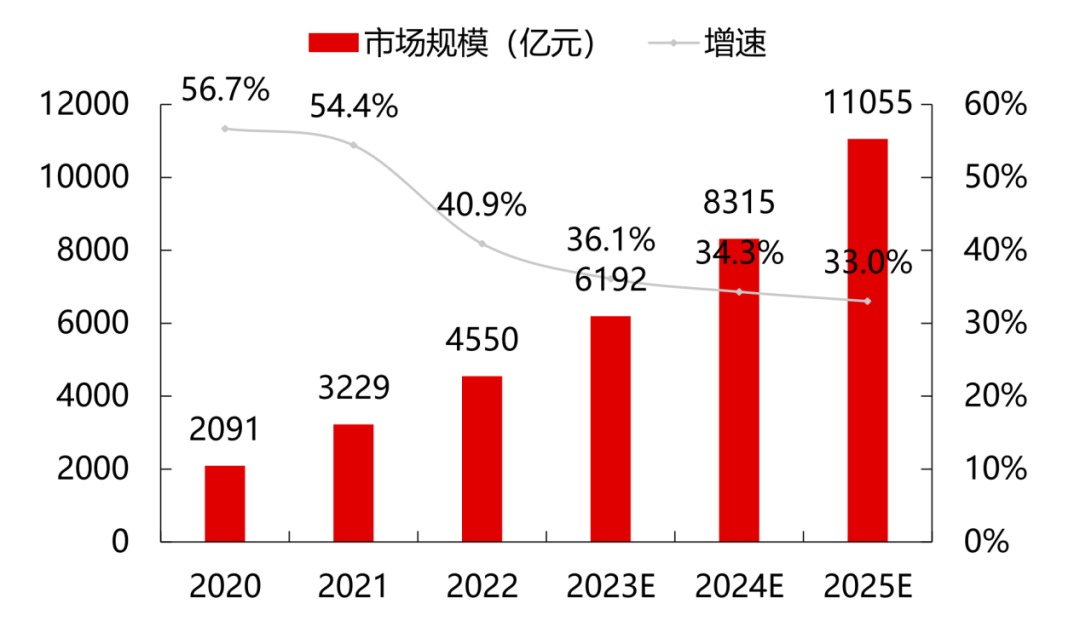
根據Gartner數據,2022年全球云計算市場規模達到4910億美元,同比增長19%,但較2021年同比下降13.5%。而根據中國信息通信研究院的統計,2022年中國云計算市場規模達到4550億元,同比增長40.91%。
全球云計算市場規模及增速
云計算仍然是新技術融合和業態發展的重要推動力。預計在大模型和算力需求的刺激下,市場將繼續保持穩定增長,到2026年全球云計算市場將突破萬億美元。相比全球19%的增速,中國云計算市場仍處于快速發展階段,在大經濟頹勢下仍保持較高的抗風險能力,預計到2025年我國云計算整體市場規模將突破萬億元。
中國云計算市場規模及增速
3、服務器:銷售端頭部集中,采購端以科技巨頭為主
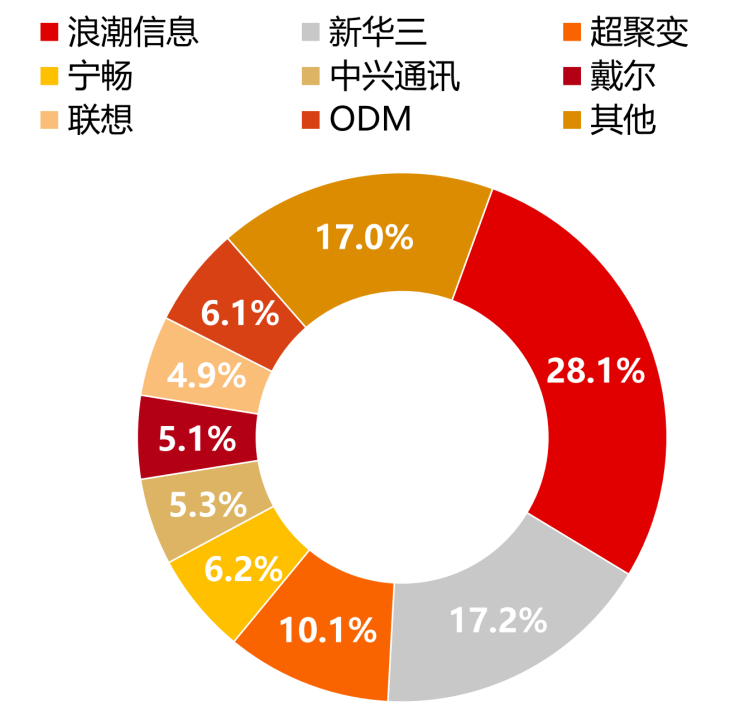
根據IDC之前公布的數據,2022年中國服務器市場的主要供應商包括浪潮信息、新華三、超聚變、寧暢和中興通訊。
2022年中國服務器市份額情況
國內AI服務器行業采用CPU+加速芯片的架構形式,在進行模型訓練和推斷時具有效率優勢。浪潮信息在國內市場份額較高,其次為新華三、寧暢、安擎等。
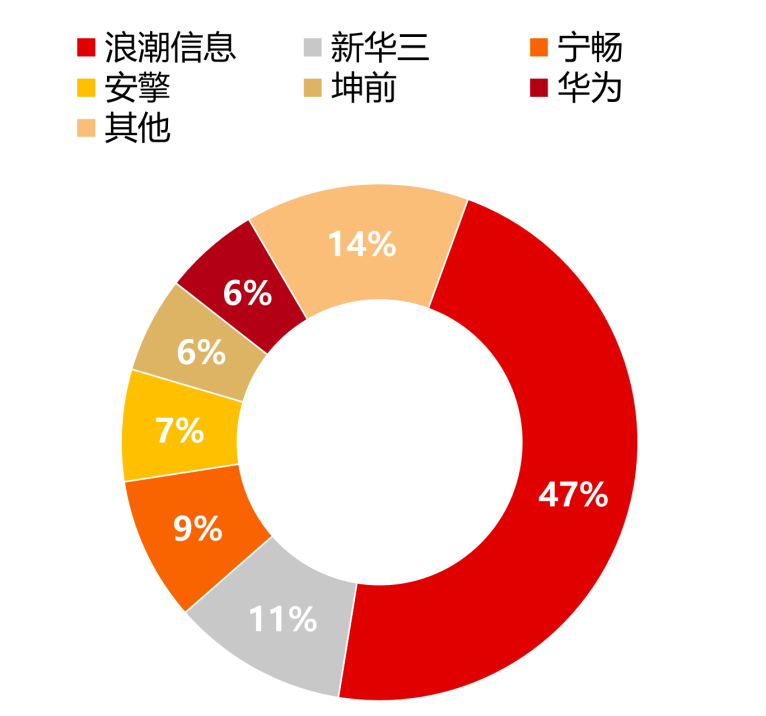
2022年中國AI服務器市份額情況
隨著云計算、移動互聯網、物聯網、大數據、人工智能等技術的興起,互聯網巨頭逐漸取代政府和銀行等部門成為服務器的主要采購方。在2012年之前,服務器的下游客戶主要是政府、銀行等金融機構、電信和其他大型企業。然而,現在服務器的下游客戶主要以科技巨頭為主,如海外亞馬遜、微軟、谷歌以及國內阿里、騰訊等為代表的云計算巨頭逐步成為服務器市場的主要采購客戶。
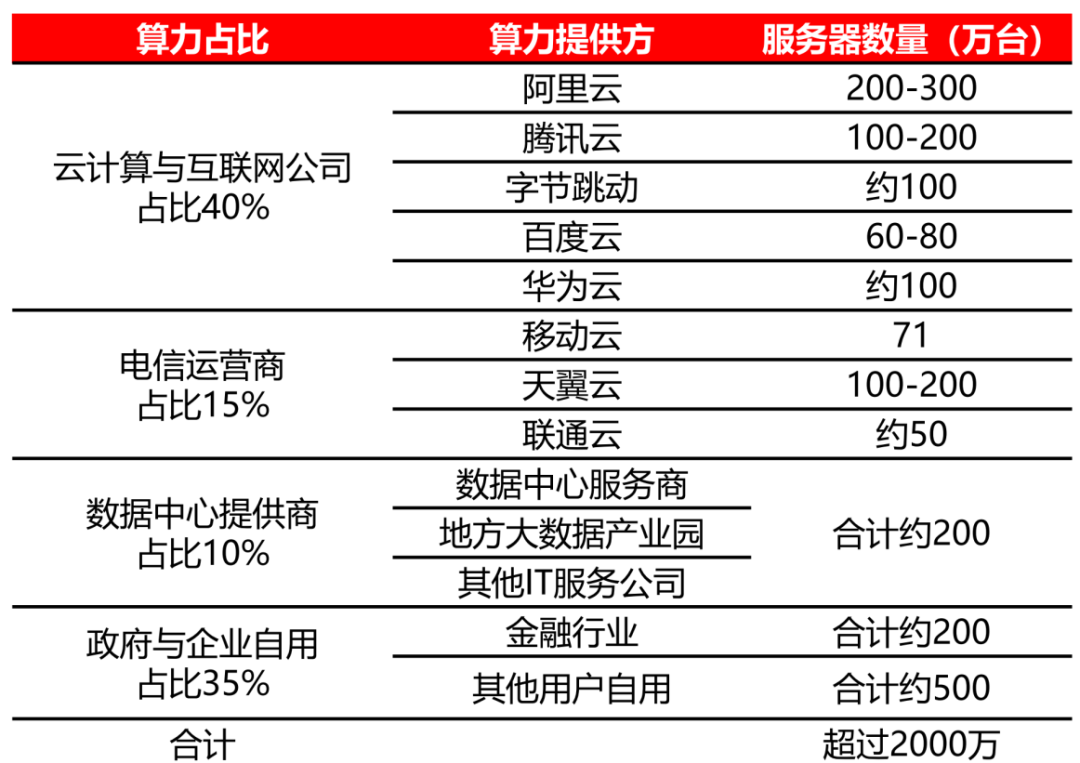
2022年中國主要云廠商服務器規模
根據IDC的預測數據,2023年全球服務器市場規模同比幾乎持平,而2024年及以后服務器市場將保持8-11%的增速,預計到2027年市場規模將達到1780億美元。
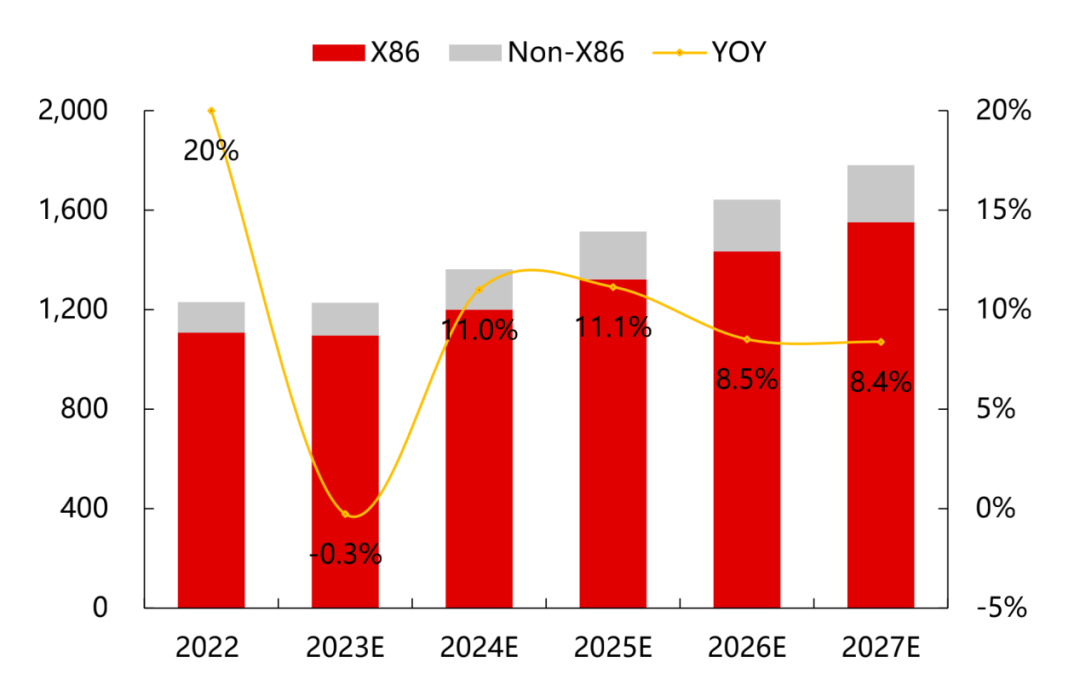
2022-2027E全球服務器市場規模(億美元)
2022年中國服務器市場規模約為273.4億美元,同比增長9%,增速有所放緩。根據華經產業研究院的數據,2023年市場規模將達到308億美元,增速為13%。隨著東數西算項目的推進、海量數據運算和存儲需求的快速增長等因素的影響,中國服務器整體的采購需求將進一步增加。IDC預測,到2027年中國AI服務器市場規模將達到164億美元。
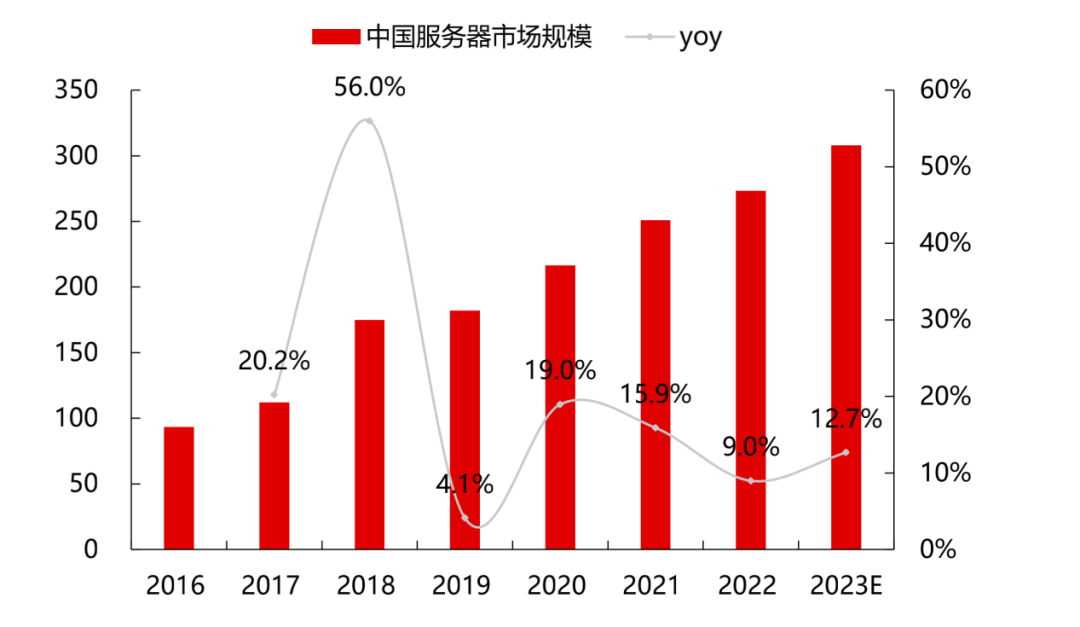
2016-2023E中國服務器市場規模(億美元)
二、底層關鍵: CPU是服務器的大腦,國產替代空間廣闊
1、作用關鍵:CPU是服務器的大腦,GPU并行計算能力很強
CPU是服務器的控制中心,負責完成布局謀略、發號施令、控制行動等任務,其結構包括運算器、控制單元、寄存器、高速緩存器和通訊的總線。GPU由于圖形渲染、數值分析、AI推理等底層邏輯需要將繁重的數學任務拆解,利用GPU多流處理器機制,將大量運算拆解為小運算,并行處理。CPU和GPU是兩種不同的處理器,CPU是程序控制、順序執行的通用處理器,而GPU是用于特定領域分析的專用處理器,受CPU控制。在許多終端設備中,CPU和GPU通常集成在一個芯片中,同時具備CPU或GPU處理能力。
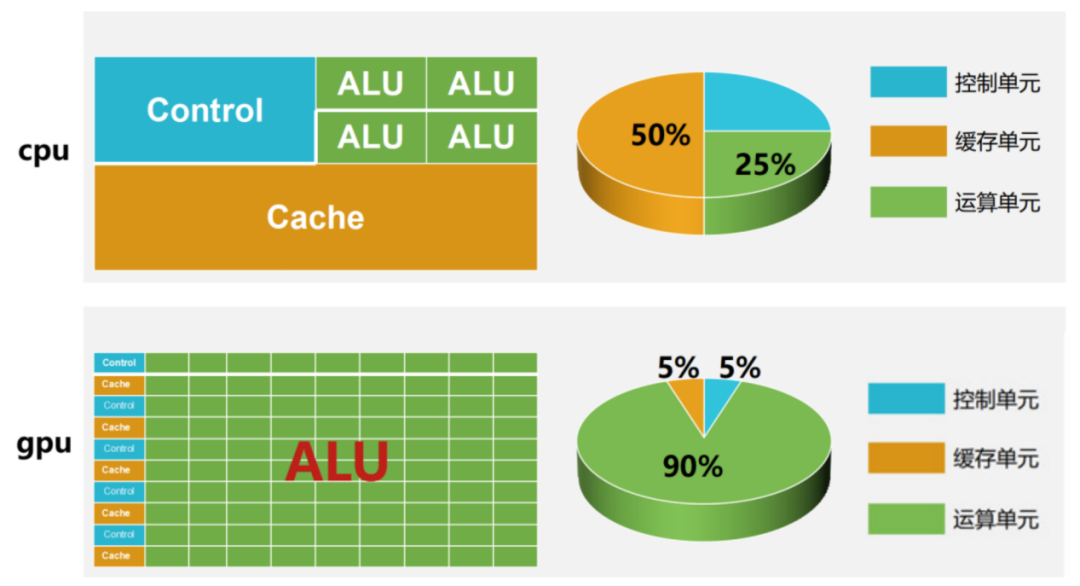
GPU投入更多晶體管進行數據處理,并行運算能力強
2、價值關鍵:CPU、GPU占據各類服務器的硬件成本高
服務器的硬件成本構成上,CPU及芯片組、內存和外部存儲是主要部分:在普通服務器中,CPU及芯片組約占32%,內存約占27%,外部存儲約占18%,其他硬件約占23%。而在AI服務器上,GPU的成本占比則遠高于其他部分,可能接近整體成本的70%。從普通服務器升級到AI訓練服務器時,其他單臺服務器價值量增量較大的部件包括內存、SSD、PCB、電源等,都有數倍的提升。
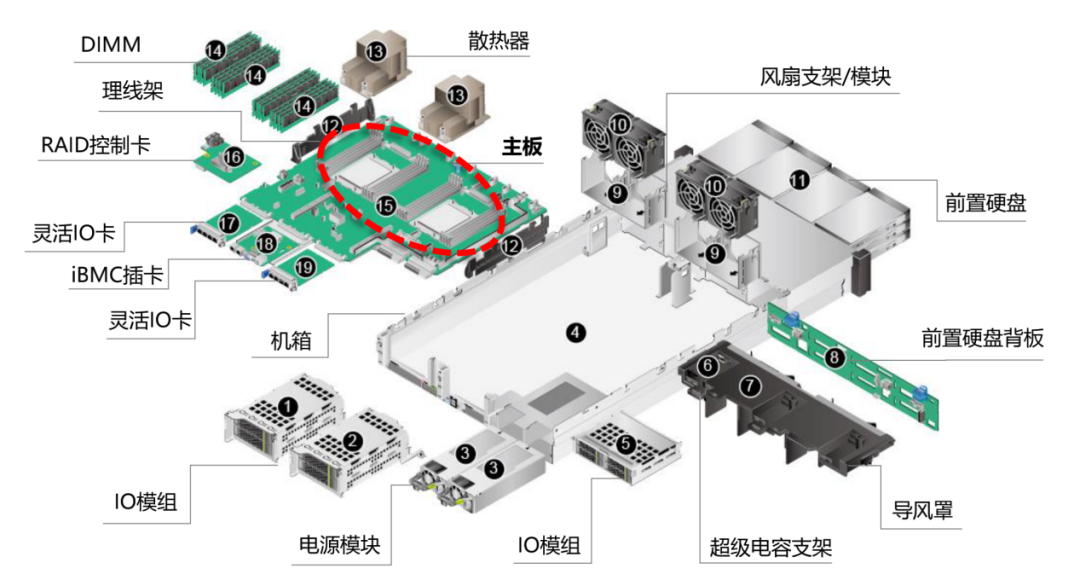
服務器內部拆解示意圖
3、處理器:CPU主導地位,GPU增長迅猛
根據Yole Intelligence的報告,預計到2028年處理器市場的收入將達到2420億美元,復合年增長率為8%。CPU市場的主導地位將得到鞏固,2028年市場規模將達到970億美元,復合年增長率為6.9%。GPU市場也將實現顯著增長,2028年市場規模將達到550億美元,復合年增長率為16.5%。在處理器市場上,英特爾、AMD、英偉達等巨頭以及紫光展銳主導著市場。在國內外服務器所使用的處理器方面,英特爾、AMD、英偉達、龍芯、兆芯、鯤鵬、海光、飛騰、申威、昇騰等占主導地位。
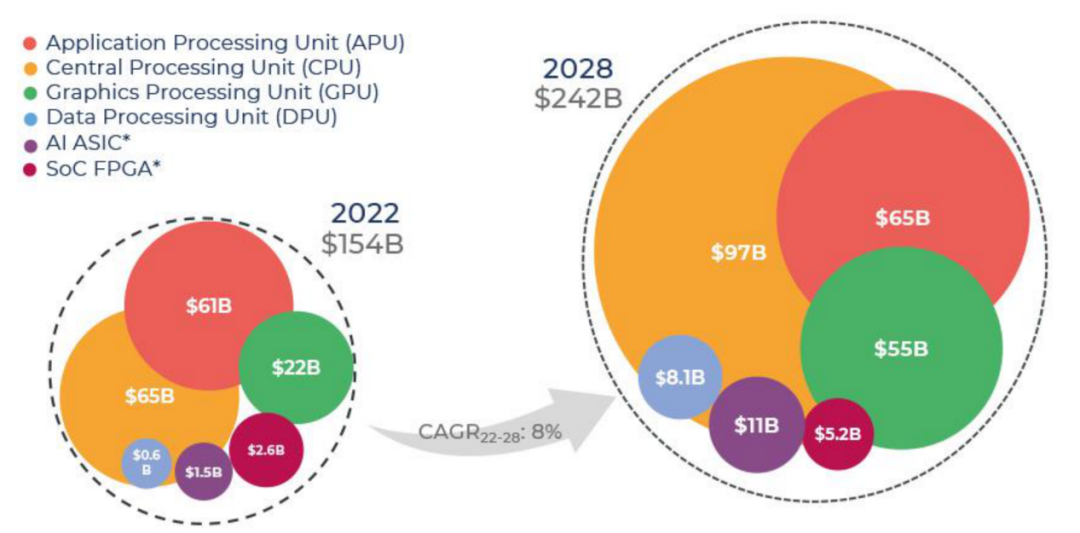
2022-2028年按處理器類型劃分的處理器收入預測
4、我國在美國多輪制裁下不斷進行科技攻堅
自2019年5月至2020年9月,美國政府對華為實施多輪制裁,導致華為5G手機芯片供應被切斷,華為手機銷量大幅下滑。此后,美國針對我國半導體領域的限制不斷升級。然而,華為最新旗艦機型采用了7nm工藝的麒麟9000s芯片,標志著中國在芯片設計和制造領域的里程碑。
2023年10月17日,美國商務部工業和安全局公布了新的尖端芯片出口管制規則,共計近500頁,全面限制美國芯片巨頭如英偉達、英特爾等生產的“特供版”芯片出口到中國及40余個國家。此外,還更新了半導體設備和技術相關的“長臂管轄”,擴大荷蘭***企業ASML不可對華出口機型范圍,并限制波及中國之外20余個國家。同時,將壁仞科技、摩爾線程等13個中國實體加入美國管制清單,限制中國企業通過代工廠生產先進芯片。

10月17日美國商務部工業和安全局公布管制新規
三、算力的瓶頸在哪里,機會就會在哪里
算力是現代計算機技術的核心,其瓶頸主要存在于數據傳輸和存儲方面。目前,計算機普遍采用馮諾依曼架構,數據存儲和數據計算分開,算力容易被卡在數據傳輸,而非真正的計算。算力分為四層,每一層都需要解決如何讓數據連接更快的問題。
1、GPU內部
GPU內部的計算單元與顯存之間的數據傳輸是性能提升的瓶頸,同時多個GPU間的協同計算也受到數據傳輸速度的限制。傳統GPU通常采用GDDR內存,這種內存是平面封裝,導致數據傳輸速度跟不上GPU的計算速度。為解決這一問題,升級后的方案采用HBM內存技術。HBM內存是垂直封裝,能夠提供更大的帶寬,從而將數據更快地傳輸到GPU的計算單元中。例如,HBM2的帶寬高達256GB/s,比傳統的GDDR內存快十倍以上。
2、AI服務器
每臺AI服務器都由多個GPU組成(4個、8個甚至更多),GPU需要進行協同計算。然而,它們之間的數據傳輸速度成為性能的瓶頸。在這方面,英偉達GPU連接技術最為先進,使用的是其NVLink協議,每秒傳輸速度高達50GB。華為也擁有自己的HCCS協議,帶寬表現不錯,每秒30GB,與英偉達沒有量級的差異。然而,其他傳統的服務器只采用PCIe 5標準接口,每通道傳輸速度只有4GB,不到英偉達的十分之一。因此,為提高數據傳輸速度并解決該瓶頸問題,需要采用更先進的技術和協議。
3、數據中心
數據中心由上百甚至上千臺AI服務器組成計算集群,服務器之間需要快速的數據連接。英偉達采用專用的InfiniBand網絡,而其他廠商則使用ROC高速以太網網絡。盡管這兩種網絡在物理層都使用光纖連接,但都離不開光模塊。無論是數據發送還是接收,無論是服務器端還是交換機端,都需要光模塊。今年,光模塊的技術從400G升級到800G,因為國內廠商在光模塊制造領域的占比很高,因此這一塊的業績能夠真正實現,導致光模塊技術在算力領域被炒作得最多。
4、數據網絡
不同地點和城市的數據中心可以組成一個龐大的算力網絡,通過調度和統籌,終端用戶輕松地使用最快且最便宜的算力資源。目前,算力網絡的發展趨勢是采用云-邊-端的架構,旨在解決數據傳輸的問題。其中,邊緣計算是最為熱門的技術之一。邊緣計算并不僅僅是指手機和智能車輛,而是指在傳統的云計算中心之外,更靠近終端地方增加一層直接計算能力,以節省數據傳輸的成本和時間。因此,未來的大趨勢是云的AI算力、邊緣的AI算力和用戶端的AI算力相互結合,共同推動人工智能技術的發展。
藍海大腦深度學習大數據平臺
藍海大腦深度學習大數據平臺是面向多源空間數據的處理平臺,集成存儲、計算和數據處理軟件,具有高效、易操作、低成本、多層次擴展和快速部署等顯著優勢,在測繪、農業、林業、水利、環保等領域大大提升圖像處理能力,保護投資,高效應對大數據挑戰,加速業務突破和轉型。
一、主要技術指標
可 靠 性:平均故障間隔時間MTBF≥15000 h
工作溫度:5~40 ℃
工作濕度:35 %~80 %
存儲溫度:-40~55 ℃
存儲濕度:20 %~90 %
聲 噪:≤35dB

二、特點及優勢:
基于統一的整體架構,采用先進成熟可靠的技術與軟硬件平臺,保證基礎數據平臺易擴展、易升級、易操作、易維護等特性。基于業界熱門,且領先的 Spark 技術,極速提高平臺的整體計算性能。
支持基礎數據模型、應用分析模型、前端應用的擴展性;支持在統一系統架構中服務器、存儲、I/O 設備等的可擴展性。
制定并實施基礎數據平臺高可用性方案、運行管理監控制度、運行維護制度、故障處理預案等,保證系統在多用戶、多節點等復雜環境下的可靠性。
高效性:在規定時間內完成數據寫入操作,并將數據寫入對數據分析的影響降到最低;提升實現規劃要求的數據查詢和統計分析速度。
數據質量貫穿基礎數據平臺系統建設的每個環節,基礎數據平臺系統通過合理的數據質量管理解決方案保證數據質量。
按國家標準、行業標準、安全規范等實現數據安全管理。
統一的管理平臺,對系統進行相應的性能管理和日志監控。
人機接口靈活多樣的展現方式,最終用戶只需進行適當的培訓就可以方便地使用新的分析工具,減少 IT 人員的工作量,加強集群監管的時效性。
具有超強影像處理能力,每天(24小時)可處理多達500景對(全色和多光譜)高分一號影像數據。
廣泛適用于基礎測繪、農業、林業、水利、環保等領域,適合常規模式下產品生產和應急模式下快速影像圖生成。
針對大數據原始技術存在的問題,藍海大腦大數據平臺從企業應用角度出發,對 Apache Hadoop 進行了系列技術開發,形成了適應企業級應用的一站式大數據平臺,從而滿足各類企業的要求:
超大數據的分布式存儲、流數據實時計算要求
滿足大數據的高并發、低延遲查詢請求
分布式應用系統異常故障時,業務切換
系統線性擴展時,無需增加開發工作,實現無成本擴展
三、常用配置推薦
1、CPU:
- Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
- Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
- AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
- AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
- Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Gold 6240R 24C/48T,2.4GHz,35.75MB,DDR4 2933,Turbo,HT,165W.1TB
- Intel Xeon Gold 6258R 28C/56T,2.7GHz,38.55MB,DDR4 2933,Turbo,HT,205W.1TB
- Intel Xeon W-3265 24C/48T 2.7GHz 33MB 205W DDR4 2933 1TB
- Intel Xeon Platinum 8280 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W 1TB
- Intel Xeon Platinum 9242 48C/96T 3.8GHz 71.5MB L2,DDR4 3200,HT 350W 1TB
- Intel Xeon Platinum 9282 56C/112T 3.8GHz 71.5MB L2,DDR4 3200,HT 400W 1TB
2、GPU:
- NVIDIA A100, NVIDIA GV100
- NVIDIA L40S GPU 48GB
- NVIDIA NVLink-A100-SXM640GB
- NVIDIA HGX A800 80GB
- NVIDIA Tesla H800 80GB HBM2
- NVIDIA A800-80GB-400Wx8-NvlinkSW
- NVIDIA RTX 3090, NVIDIA RTX 3090TI
- NVIDIA RTX 8000, NVIDIA RTX A6000
- NVIDIA Quadro P2000,NVIDIA Quadro P2200
審核編輯 黃宇
-
cpu
+關注
關注
68文章
10872瀏覽量
211999 -
gpu
+關注
關注
28文章
4743瀏覽量
128992 -
源碼
+關注
關注
8文章
643瀏覽量
29241 -
大數據
+關注
關注
64文章
8894瀏覽量
137480 -
AIGC
+關注
關注
1文章
362瀏覽量
1554
發布評論請先 登錄
相關推薦
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
【一文看懂】大白話解釋“GPU與GPU算力”

《算力芯片 高性能 CPU/GPU/NPU 微架構分析》第1-4章閱讀心得——算力之巔:從基準測試到CPU微架構的深度探索
GPU算力租用平臺是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
中國算力大會召開,業界首個算力高質量評估體系發布

弘信電子集團:破解中國算力瓶頸的燧弘模式
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
算力服務器為什么選擇GPU






 工商網監
工商網監
評論