") 一次k8s升級(jí),滴滴直接故障12小時(shí)?
一次k8s升級(jí),滴滴直接故障12小時(shí)?
前段時(shí)間滴滴的故障相信大家都知道了。
中斷業(yè)務(wù) 12 小時(shí)定級(jí)為 P0 級(jí)故障一點(diǎn)都不冤。

故障回顧
網(wǎng)上有傳言是運(yùn)維人員升級(jí) k8s 時(shí),本來計(jì)劃是從 1.12 版本升級(jí)到 1.20,但是操作失誤選錯(cuò)了版本,操作了集群降級(jí)到低版本。
從下面滴滴技術(shù)的博客中也可以看到滴滴的升級(jí)方案:
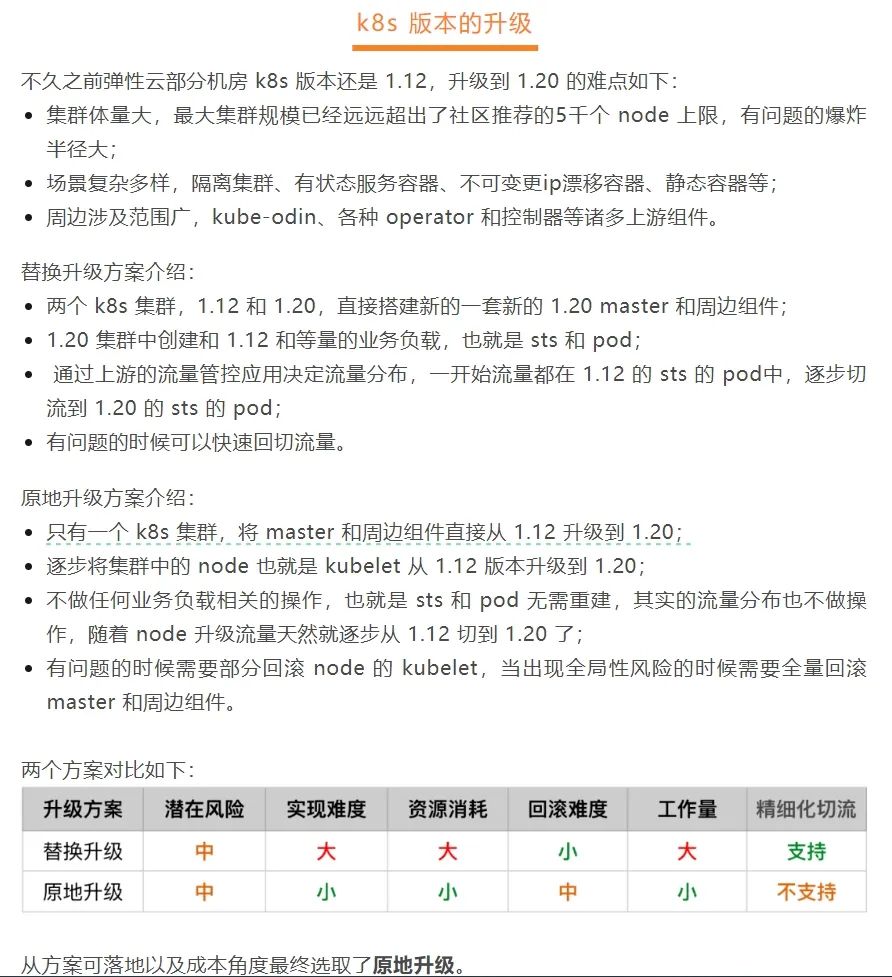
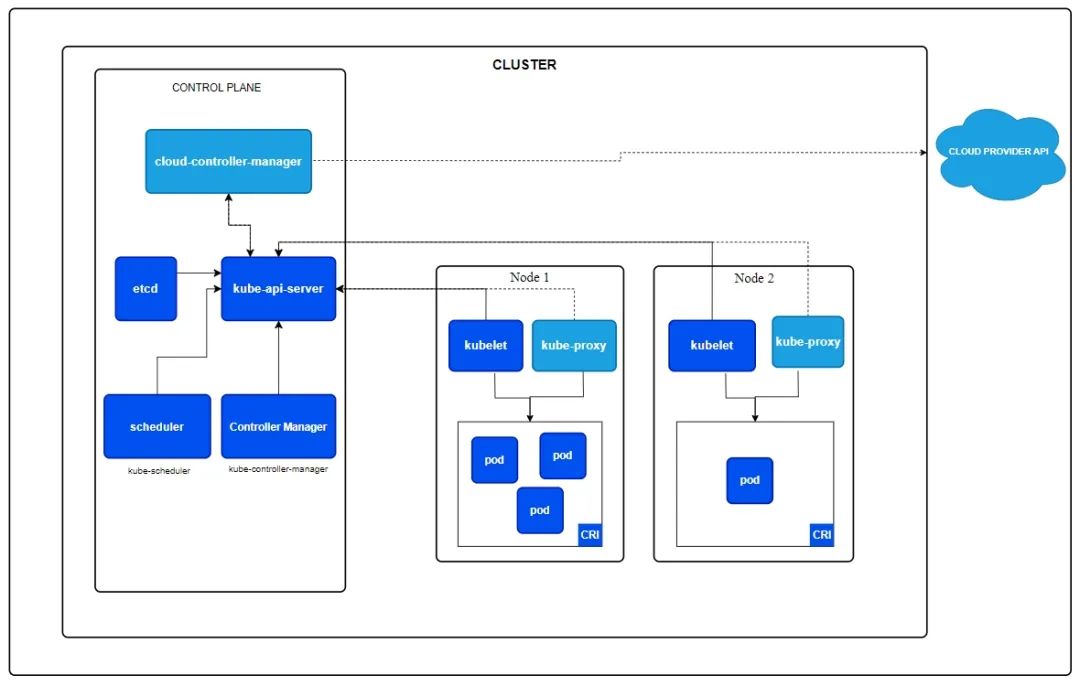
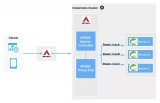
滴滴為了降低升級(jí)成本,選擇了原地升級(jí)的方式。首先升級(jí) master,然后升級(jí) node。我們一起看一下 k8s 官方架構(gòu):
img
master(官網(wǎng)圖中叫 CONTROL PLANE) 節(jié)點(diǎn)由 3 個(gè)重要的組件組成:
cloud-controller-manager:負(fù)責(zé)容器編排;
kube-api-server:為 Node 節(jié)點(diǎn)提供 api 注冊服務(wù);
scheduler:負(fù)責(zé)任務(wù)調(diào)度。
Node 節(jié)點(diǎn)向 kube-api-server 注冊成功后,才可以運(yùn)行 Pod。從滴滴的博客中可以看到,采用原地升級(jí)的方式,升級(jí)了 master 之后,逐步升級(jí) Node,Node 會(huì)有一個(gè)重新注冊的過程,不過既然選擇這個(gè)方案,運(yùn)維人員應(yīng)該反復(fù)演練過,重新注冊耗時(shí)應(yīng)該非常短,用戶無感知。
但是 master 選錯(cuò)版本發(fā)生降級(jí)時(shí),會(huì)把 kube-api-server 污染,Node 節(jié)點(diǎn)注冊 master 失敗,又不能快速回滾,這樣 Node 節(jié)點(diǎn)被集群認(rèn)為是非健康節(jié)點(diǎn),上面的 pod 被 kill 掉,服務(wù)停止。
集群隔離
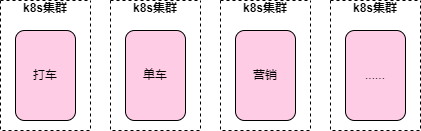
這次故障大家討論的話題還有一個(gè)比較熱門的就是 k8s 集群隔離,因?yàn)槎鄠€(gè)業(yè)務(wù)比如打車業(yè)務(wù)、單車業(yè)務(wù)同時(shí)掛,說明都在一個(gè)集群上,沒有單獨(dú)建集群來做隔離,這可能也是博客中說的“最大集群規(guī)模已經(jīng)遠(yuǎn)遠(yuǎn)超出了社區(qū)推薦的5千個(gè) node 上限”的原因。
當(dāng)然也有可能當(dāng)時(shí)野蠻生長的時(shí)候,為了快速上線開展業(yè)務(wù),就多個(gè)業(yè)務(wù)建在了一個(gè)集群上,后來可能也有過拆分的想法,但發(fā)現(xiàn)業(yè)務(wù)上升空間已經(jīng)很小,現(xiàn)有集群可以維持,所以就擱置了。
拆分成多個(gè)集群好處很明顯,業(yè)務(wù)隔離,故障隔離,可靠性增加,就拿這次升級(jí)來說,先升級(jí)一個(gè)不太關(guān)鍵、業(yè)務(wù)量也比較小的集群做試點(diǎn),升級(jí)成功了再逐個(gè)升級(jí)其他集群。
但缺點(diǎn)也很明顯,運(yùn)維復(fù)雜度增加,成本增加。
升級(jí)方案
工作這些年,也參與過一些大規(guī)模的平臺(tái)重構(gòu),但原地升級(jí)真的是沒有接觸過,主要原因就是架構(gòu)師們不太愿意選擇原地升級(jí)的方案。而他們主要出于下面考慮:
業(yè)務(wù)系統(tǒng)原地重構(gòu)升級(jí),不像推翻重做能夠更徹底地升級(jí)改造;
考慮對業(yè)務(wù)影響最小,一般是要通過灰度發(fā)布漸進(jìn)地把流量切過去;
替換升級(jí)的方案,更能展現(xiàn)團(tuán)隊(duì)的產(chǎn)出。
對于滴滴這樣的大公司,相信運(yùn)維團(tuán)隊(duì)大咖如云,無論采用哪種方案,肯定都是經(jīng)過反復(fù)驗(yàn)證的,或許不要選錯(cuò)版本,原地升級(jí)也沒有問題。
降本增效
看了微博上滴滴道歉的留言區(qū),好多人猜測這次事故的原因是降本增效,裁掉了一線高成本的運(yùn)維,保留了成本低的新人。
從數(shù)據(jù)上來看,出于降本增效的目的,滴滴這兩年確實(shí)少了很多人,但我不相信這是造成事故的直接原因。
在快速增長的階段,確實(shí)需要投入大量的技術(shù)人員來建設(shè)系統(tǒng)。但國內(nèi)互聯(lián)網(wǎng)規(guī)模也基本見頂了,一個(gè)業(yè)務(wù)經(jīng)營這么多年,不會(huì)再有爆發(fā)式地增長,系統(tǒng)也已經(jīng)非常穩(wěn)定。這樣的背景下,公司確實(shí)用不了這么多技術(shù)人員了,留下部分人員來維護(hù)就夠了。
所以,無論哪家公司,降本增效是業(yè)務(wù)穩(wěn)定后必定會(huì)經(jīng)歷的階段。想想滴滴這次 12 小時(shí)故障的損失,能比養(yǎng) 1000 個(gè)技術(shù)人員的成本高嗎?
對于我們研發(fā)人員,如果有機(jī)會(huì)進(jìn)入快速增長的公司,那就抓住機(jī)會(huì)多掙錢,被裁員的時(shí)候平常心看待就可以了,想在一家公司干到退休太難了。同時(shí)也要看到自己給公司帶來的價(jià)值,千萬不要認(rèn)為我們技術(shù)厲害就比那個(gè) PPT 工程師更有價(jià)值。
總結(jié)
本文根據(jù)網(wǎng)上流傳的滴滴故障的原因,分析了升級(jí)方案和降本增效。
最后,又快年末了,希望大家都能維護(hù)好自己的系統(tǒng),不要發(fā)生嚴(yán)重故障影響自己的年底考核。
-
節(jié)點(diǎn)
+關(guān)注
關(guān)注
0文章
220瀏覽量
24604 -
MASTER
+關(guān)注
關(guān)注
0文章
104瀏覽量
11435 -
滴滴
+關(guān)注
關(guān)注
1文章
193瀏覽量
13098
原文標(biāo)題:一次 k8s 升級(jí),滴滴直接故障 12 小時(shí)?
文章出處:【微信號(hào):小林coding,微信公眾號(hào):小林coding】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
全面提升,阿里云Docker/Kubernetes(K8S) 日志解決方案與選型對比
OpenStack與K8s結(jié)合的兩種方案的詳細(xì)介紹和比較
如何使用kubernetes client-go實(shí)踐一個(gè)簡單的與K8s交互過程
Docker不香嗎為什么還要用K8s
簡單說明k8s和Docker之間的關(guān)系
K8S集群服務(wù)訪問失敗怎么辦 K8S故障處理集錦

mysql部署在k8s上的實(shí)現(xiàn)方案
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres
什么是K3s和K8s?K3s和K8s有什么區(qū)別?
k8s生態(tài)鏈包含哪些技術(shù)
K8S落地實(shí)踐經(jīng)驗(yàn)分享
k8s云原生開發(fā)要求






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論