 1530億晶體管,AMD發布史上最大、最強芯片!多項指標數倍于H100,打響挑戰英偉達第一槍!
1530億晶體管,AMD發布史上最大、最強芯片!多項指標數倍于H100,打響挑戰英偉達第一槍!
AMD在7日凌晨 2 點舉辦“Advancing AI”活動中,發布了Instinct MI300X人工智能加速器和全球首款數據中心APU--Instinct MI300A,以充分利用蓬勃發展的人工智能和高性能計算市場。 受此消息影響,昨日AMD美股收盤大漲9.89%。
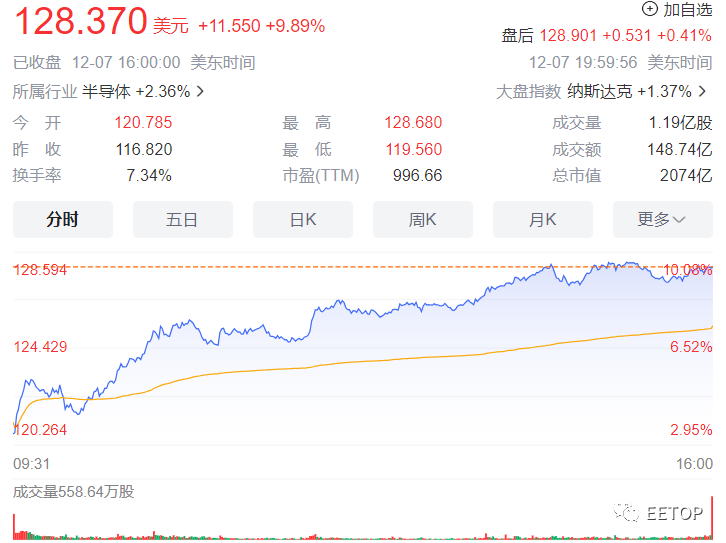
AMD 利用有史以來最先進的量產技術打造了 MI300 系列產品,采用 "3.5D "封裝等新技術生產出兩款多芯片巨型處理器,并稱可在各種 AI 工作負載中提供與 Nvidia 不相上下的性能。其中有多項性能指標評測數倍于競爭對手英偉達的H100。AMD 沒有透露其新的奇特芯片的價格,但這些產品現已向眾多 OEM 合作伙伴發貨。

Instinct MI300 是一種改變游戲規則的設計 - 數據中心 APU 混合了總共 13 個小芯片,其中許多是 3D 堆疊的,以創建一個具有 24 個 Zen 4 CPU 內核并融合了 CDNA 3 圖形引擎和 8 個堆棧的芯片HBM3。總體而言,該芯片擁有 1530 億個晶體管,是 AMD 迄今為止制造的最大芯片。AMD 聲稱該芯片在某些工作負載中的性能比 Nvidia H100 GPU 高出 4 倍,并宣稱其每瓦性能是其兩倍。
AMD 表示,其 Instinct MI300X GPU 在人工智能推理工作負載中的性能比 Nidia H100 高出 1.6 倍,并在訓練工作中提供類似的性能,從而為業界提供了急需的 Nvidia GPU 的高性能替代品。此外,這些加速器的 HBM3 內存容量是 Nvidia GPU的兩倍以上(每個 192 GB 令人難以置信),使其 MI300X 平臺能夠支持每個系統兩倍以上的 LLM 數量,并運行比 Nvidia H100 HGX 更大的模型。
AMD Instinct MI300X
MI300X代表了 AMD 基于小芯片的設計方法的頂峰,將八個 12Hi 堆棧的 HBM3 內存與八個 3D 堆棧的 5nm CDNA 3 GPU 小芯片(稱為 XCD)融合在四個底層 6nm I/O 芯片上,這些芯片使用 AMD 現已成熟的技術進行連接混合鍵合技術。
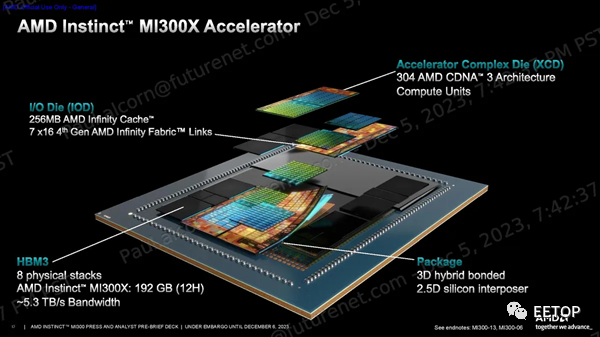






結果是創造出了一個 750W 的加速器,擁有 304 個計算單元、192GB HBM3 容量和 5.3 TB/s 帶寬。該加速器還具有 256MB Infinity Cache,用作共享 L3 緩存層,以促進小芯片之間的通信。AMD 將其將小芯片綁定在一起的封裝技術稱為“3.5D”,表示 3D 堆疊 GPU 和 I/O 芯片通過混合鍵合融合在一起,并與模塊其余部分的標準 2.5D 封裝(水平連接)相結合。。我們將更深入地研究下面的架構組件。 MI300X 加速器設計用于在 AMD 的生成式 AI 平臺中以 8 個為一組工作,GPU 之間通過 Infinity Fabric 互聯實現 896 GB/s 的吞吐量。該系統擁有 1.5TB 的 HBM3 內存,性能高達 10.4 Petaflops(BF16/FP16)。該系統基于開放計算項目(OCP)通用底板(UBB)設計標準構建,從而簡化了采用過程,特別是對于超大規模用戶而言。
與 Nvidia 的 H100 HGX 平臺(BF16/FP16)相比,AMD 的 MI300X 平臺內存容量增加了 2.4 倍,計算能力提高了 1.3 倍,同時還保持了相當的雙向和單節點環帶寬。AMD 為 MI300X 平臺配備了 400GbE 網絡,并支持多種網卡,而 Nvidia 則傾向于使用其收購 Mellanox 后生產的自有網絡產品。
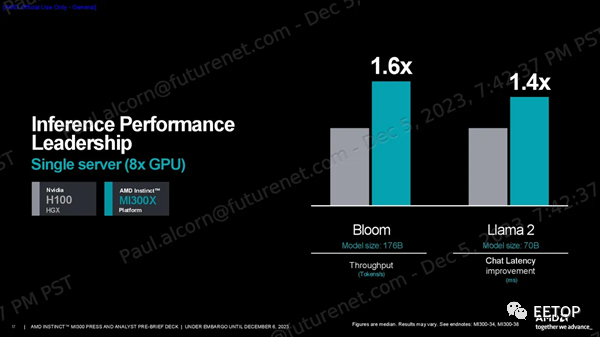
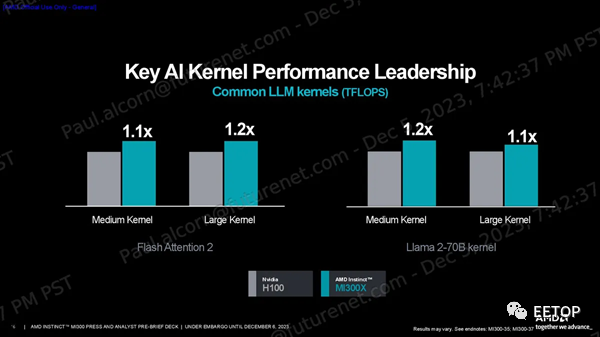


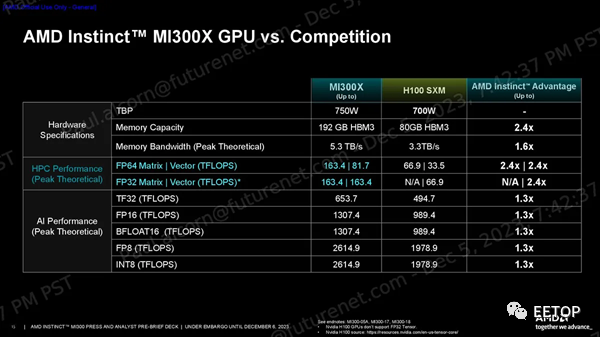
一如既往,我們應該謹慎對待供應商的基準測試。AMD分享了一系列性能指標,顯示其在HPC工作負載方面的FP64和FP32向量矩陣吞吐量峰值理論值是H100的2.4倍,在人工智能工作負載方面的TF32、FP16、BF16、FP8和INT8吞吐量峰值理論值是H100的1.3倍,所有這些都是在沒有稀疏性的情況下預測的(不過MI300X確實支持稀疏性)。 MI300X 的大內存容量和帶寬非常適合推理。AMD 使用 1760 億參數的 Flash Attention 2 模型聲稱在令牌/秒吞吐量方面比 Nvidia H100 具有 1.6 倍的性能優勢,并使用 700 億參數的 Llama 2 模型來強調 1.4 倍的聊天延遲優勢(從2K 序列長度/128 個令牌工作負載的開始到結束)。
AMD 的 MI300X 平臺在 300 億參數 MPT 訓練工作負載中提供的性能與 H100 HGX 系統大致相同,但需要注意的是,此測試并不是加速器的一對一比較。相反,該測試讓八個加速器組相互競爭,因此平臺級功能更像是一個限制因素。無論哪種情況,這種性能都會很快引起受到 Nvidia GPU短缺困擾的行業的興趣。
在平臺功能方面,AMD 還宣稱,MI300X 平臺的內存容量優勢允許托管的 300 億參數訓練模型和 700 億數推理模型數量是 H100 系統的兩倍。此外,MI300X 平臺還可支持多達 70B 的訓練模型和 2900 億參數的推理模型,兩者都是 H100 HGX 所支持模型的兩倍。 當然,Nvidia 即將推出的 H200 GPU在內存容量和帶寬方面將更具競爭力,而計算性能將與現有的 H100 保持相似。Nvidia 要到明年才會開始發貨 H200,因此與 MI300X 的競爭仍然存在。
AMD Instinct MI300A
AMD Instinct MI300A 是全球首款數據中心 APU,這意味著它將 CPU 和 GPU 結合在同一個封裝中。它將直接與Nvidia 的 Grace Hopper Superchips競爭,后者的 CPU 和 GPU 位于單獨的芯片封裝中,可以協同工作。MI300A 已經在El Capitan 超級計算機中取得了顯著的勝利,AMD 已經將該芯片運送給其合作伙伴。



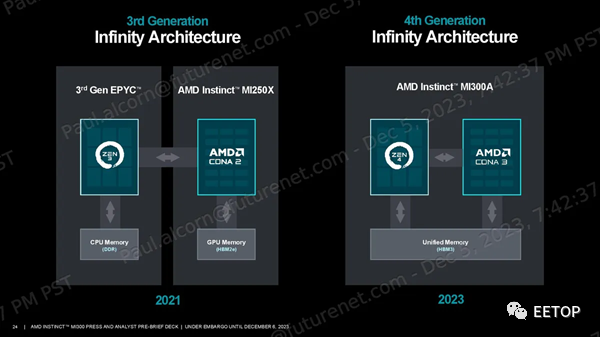

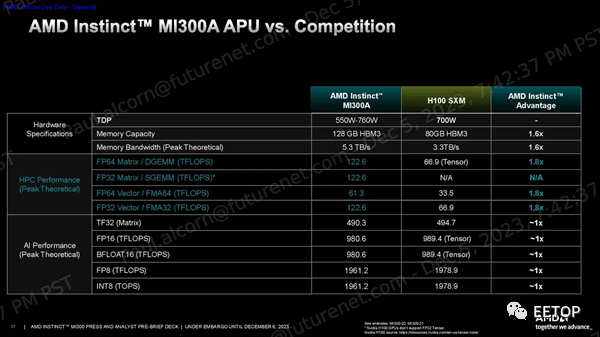
MI300A使用與 MI300X 相同的基本設計和方法,但替換為三個 5nm 核心計算芯片 (CCD),每個核心具有八個 Zen 4 CPU 核心,與 EPYC 和 Ryzen 處理器上的相同,從而取代了兩個 XCD GPU 小芯片。 這使得 MI300A 配備了 24 個線程 CPU 內核和分布在 6 個 XCD GPU 小芯片上的 228 個 CDNA 3 計算單元。與 MI300X 一樣,所有計算小芯片均采用混合鍵合方式與四個底層 I/O 芯片 (IOD) 進行 3D 堆疊,以實現遠超標準芯片封裝技術所能實現的帶寬、延遲和能源效率。 AMD 壓縮了內存容量,使用了 8 個 8Hi HBM3 堆棧,而不是 MI300X 使用的 8 個 12Hi 堆棧,因此容量從 192GB 降至 128GB。不過,內存帶寬仍為 5.3 TB/s。AMD 告訴我們,減少內存容量的決定并不是因為功耗或散熱限制;相反,這是為目標 HPC 和 AI 工作負載量身定制的芯片。無論如何,128GB 的容量和 5.3 TB/s 的吞吐量仍比 Nvidia 的 H100 SXM GPU 高出 1.6 倍。
MI300A 的默認 TDP 為 350W,但可配置為最高 760W。AMD 根據使用情況在芯片的 CPU 和 GPU 部分之間動態分配功率,從而優化性能和效率。AMD 盡可能巧妙地重復利用:MI300A 插入 AMD 的標準 LGA6096 插槽,就像 EPYC Genoa 處理器一樣,但該插槽的 SH5 版本與使用 SP5 的 AMD EPYC 處理器在電氣上不兼容。 內存空間在 CPU 和 GPU 之間共享,從而消除了數據傳輸。該技術通過消除單元之間的數據傳輸來提高性能和能源效率,同時還減少編碼負擔。與 MI300X 一樣,該芯片具有中央 256MB Infinity Cache,有助于確保流經芯片的數據的帶寬和延遲。 AMD 聲稱 FP64 Matrix/DGEMM 和 FP64/FP32 Vector TFLOPS 比 H100 高出 1.8 倍。該公司還聲稱 TF32、FP16、BF16、FP8 和 INT8 與 H100 相同。
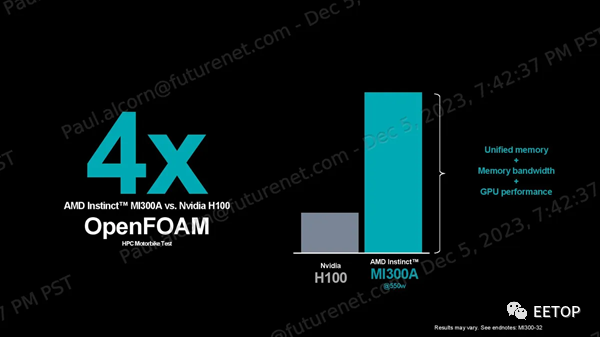
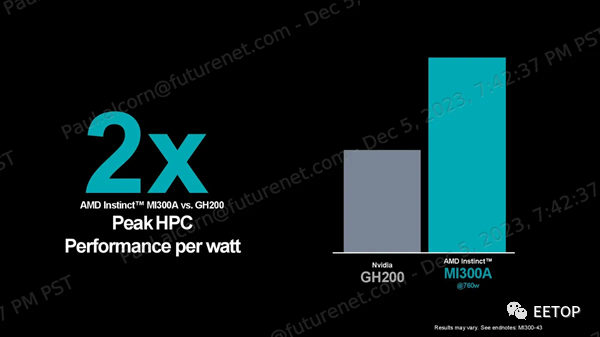
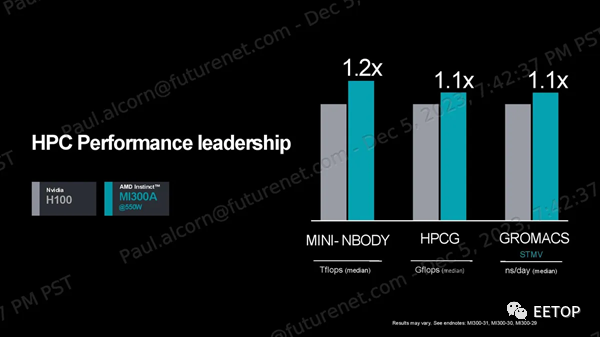
AMD聲稱,在OpenFOAM HPCmotorbike測試中,其MI300A比Nvidia的H100快4倍,但這種比較并不理想:H100是GPU,而MI300A的CPU和GPU混合計算通過共享內存尋址空間,在這種內存密集型、有時是串行的工作負載中提供了固有優勢。如果與Nvidia Grace Hopper GH200超級芯片進行比較,效果會更好,該芯片也是將CPU和GPU緊密耦合在一起實現的,但AMD表示無法找到Nvidia GH200的任何公開OpenFOAM結果。 AMD 確實提供了與 Nvidia GH200 的每瓦性能比較數據,以強調 2 倍的優勢,這些結果基于有關 H200 的公開信息。AMD 還強調了與 H100 在 Mini-Nbody、HPCG 和 Gromacs 基準測試中的比較,聲稱分別領先 1.2 倍、1.1 倍和 1.1 倍。同樣,對于這組基準測試,與 GH200 進行比較會更理想。
AMD Instinct MI300X 和 MI300A 架構
我們介紹了上面設計的基礎知識,這些細節為理解下面的部分提供了重要的視角。



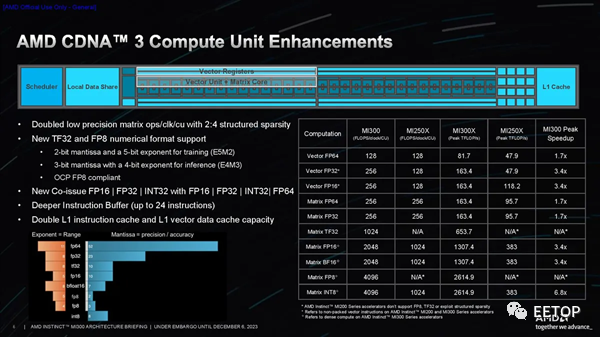
AMD利用臺積電的 3D 混合鍵合 SoIC(集成電路上硅)技術,在四個底層 I/O 芯片之上對各種計算元件進行 3D 堆疊,無論是 CPU CCD(核心計算芯片)還是 GPU XCD。每個 I/O 芯片可以容納兩個 XCD 或三個 CCD。每個 CCD 與現有 EPYC 芯片中使用的 CCD 相同,每個 CCD 擁有八個超線程 Zen 4 核心。MI300A 使用了其中的三個 CCD 和六個 XCD,而 MI300X 使用了八個 XCD。 HBM 堆棧使用采用 2.5D 封裝技術的標準中介層進行連接。AMD 將 2.5D 和 3D 封裝技術相結合,使該公司創造了“3.5D”封裝的綽號。每個 I/O 芯片都包含一個 32 通道 HBM3 內存控制器,用于托管 8 個 HBM 堆棧中的兩個,從而為該設備提供了總共 128 個 16 位內存通道。MI300X 采用 12Hi HBM3 堆棧,容量為 192GB,而 MI300A 使用 8Hi 堆棧,容量為 128GB。 AMD 還增加了 256MB 的無限緩存總容量,分布在所有四個 I/O 芯片上,通過預取器緩存數據流量,從而提高命中率和電源效率,同時減少總線爭用和延遲。這為 CPU 增加了新級別的緩存(概念上是共享 L4),同時為 GPU 提供共享 L3 緩存。Infinity Fabric NoC(片上網絡)被稱為 AMD Infinity Fabric AP(高級封裝)互連,用于連接 HBM、I/O 子系統和計算。 該芯片總共具有 128 個 PCIe 5.0 連接通道,分布在四個 I/O 芯片上。它們被分為兩組:一組是四個 x16 PCIe 5.0 + 第四代 Infinity Fabric 鏈路的組合,而另一組則有四個專門用于 Infinity Fabric 的 x16 鏈路。后者僅用于將 MI300 相互連接(跨套接字流量)。 MI300X 純粹用作端點設備 - 它連接到外部 CPU - 因此其 PCIe 根節點需要充當端點設備。相比之下,MI300A 由于其本機 CPU 內核而采用自托管,因此 PCIe 根聯合體必須充當主機。為了適應這兩種場景,AMD 定制的 MI300 I/O 裸片支持來自同一 PCIe 5.0 根節點的兩種模式,該根節點是該公司 IP 產品組合的新成員。 AMD 的 CPU CCD 通過 3D 混合鍵合到底層 I/O 芯片,需要新的接口。雖然這與 EPYC 服務器處理器中的 CCD 相同,但這些芯片通過利用標準 2.5D 封裝的GMI3 (Global Memory Interconnect 3) 接口進行通信。對于 MI300,AMD 添加了一個新的焊盤通孔接口,可繞過 GMI3 鏈路,從而提供垂直堆疊芯片所需的 TSV(通過硅通孔)。該接口在雙鏈路寬模式下運行。
5nm XCD GPU 芯片標志著 AMD GPU 設計的全面小芯片化。與 MI200 中使用的小芯片表現為兩個獨立的設備不同,MI300 小芯片則是表現為一個單片 GPU。
每個 XCD 有 40 個物理 CDNA3 計算單元,但只有 38 個被激活(這有助于解決良率問題)。每個 38-CU 小芯片都有 4MB 共享 L2 (16x 256KB)。XCD 和 IOD 具有硬件輔助機制,可將作業分解為更小的部分、分派它們并保持它們同步,從而減少主機系統開銷。這些單元還具有硬件輔助的緩存一致性。 上圖中的最后一張PPT展示了 CDNA 3 計算單元的增強功能和性能。


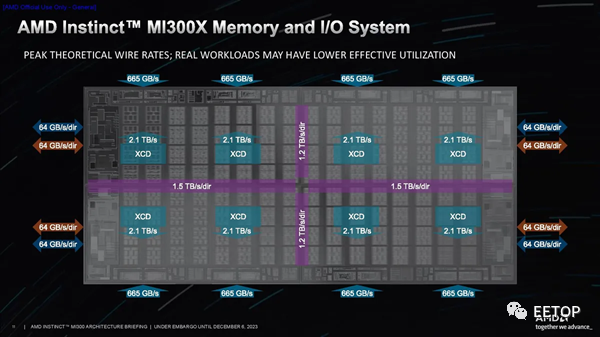
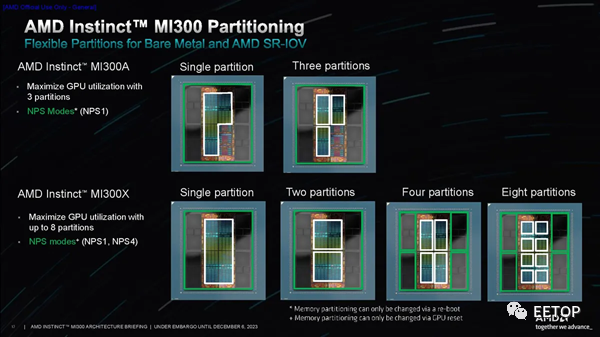
每個I/O裸片上連接有兩個XCD,然后連接到兩個HBM3堆棧。這樣,GPU就能與兩個連接的堆棧進行私密通信,以緩解帶寬、延遲和一致性問題。不過,每個XCD都可以與任何內存堆棧通信(I/O裸片之間的Infinity Fabric連接在PPT的前兩張圖片中以彩色條形直觀顯示)。 當然,尋址遠程堆棧會帶來延遲損失。內存事務傳輸得越遠,就會產生越長的延遲。AMD 指出,直接連接到 IOD 和 XCD 的 HBM 是零跳事務(zero-hop),而訪問 IOD 上的不同內存堆棧則需要兩跳。最后,訪問相鄰 IOD 上的內存堆棧是三跳跳轉。兩跳跳轉的延遲大約增加 30%,而三跳跳轉的延遲則增加 60%。
第三張PPT顯示了 NoC 提供的帶寬,在整個封裝的垂直部分,I/O Dies 之間的帶寬為 1.2 TB/s/dir,而水平數據路徑提供的帶寬略高,為 1.5 TB/s/dir,以幫助容納來自 I/O 設備的額外流量,從而允許 I/O 流量與內存流量分開處理。封裝右側和左側的 PCIe可從每個 I/O 芯片提供 64 GB/s/dir 的吞吐量。在封裝的頂部和底部,可以看到每個 HBM 堆棧提供 665 GB/s 的吞吐量。
AMD 有多種分區方案,可將計算單元劃分為不同的邏輯域,就像 EPYC 處理器的 NPS 設置一樣。這允許將不同的 XCD 分成不同的組以優化帶寬,從而最大限度地提高性能并限制“NUMAness”的影響。多種配置范圍從將單元尋址為一個邏輯設備到將它們尋址為八個不同的設備,以及多種中間選項,為各種工作負載提供了足夠的靈活性。

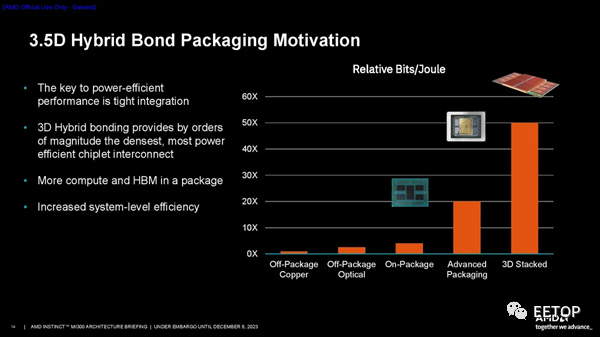
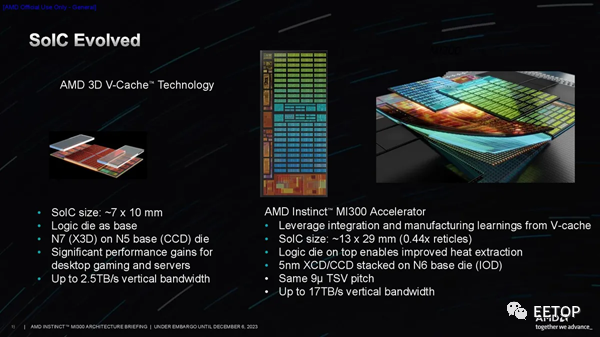
AMD確定 3D 混合鍵合 (SoIC) 是在計算單元和 I/O 芯片之間提供足夠帶寬的唯一現實途徑。公司在該技術方面擁有豐富的經驗;它已經應用于數百萬個配備 3D V-Cache的 PC 處理器中。 該公司在這種現已成熟的混合鍵合技術方面積累的長期經驗使其有信心在 MI300 處理器中繼續采用該技術。與由 3D V-Cache和標準型號組成的 AMD 消費類 PC 芯片系列相比,MI300 處理器代表該公司首次在整個產品堆棧中完全依賴該技術。
總體而言,SoC 連接可在各種 3D 堆疊單元中提供高達 17 TB/s 的垂直帶寬。SoIC 尺寸為 13x29mm。
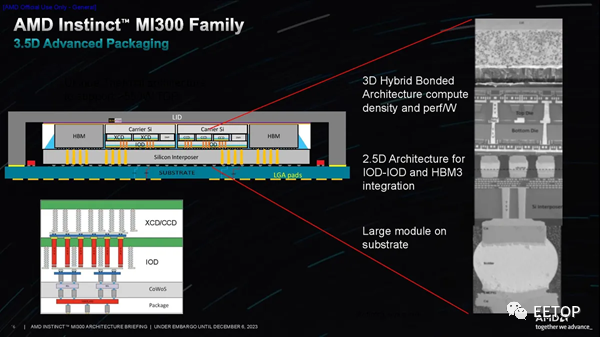
專輯最后一張PPT中的剖面圖展示了 3.5D 封裝方法的復雜性和美妙之處。。它說明了如何從底部使用有機基板、上方具有金屬布線和 TSV 的 CoWos 無源硅中介層,以及采用混合鍵合(9 微米間距)的 3D 堆疊 IOD 和 XCD 來構建封裝。將有機基板與硅中介層(底部)配合的巨大銅凸塊突出了 3D 堆疊部分的頂部和底部芯片(靠近頂部)之間幾乎不可見的混合鍵合連接是多么小和密集。芯片)。
混合鍵合技術需要減薄芯片以暴露 TSV,以便它們可以配對。因此,AMD 必須在封裝頂部采用硅墊片以保持結構完整性,就像其他配備 3D V-Cache 的處理器一樣。
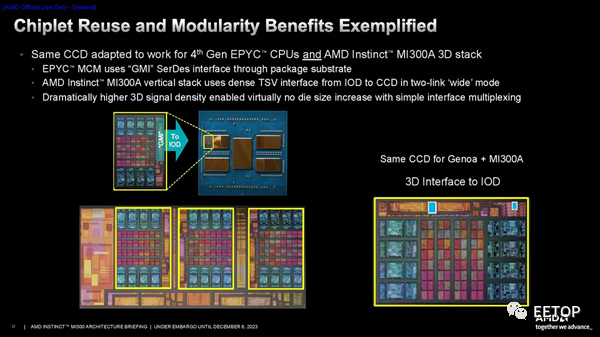


AMD高級副總裁、AMD公司院士兼產品技術架構師Sam Naffziger介紹了團隊在設計階段遇到的一些挑戰。 巧妙的IP重用一直是AMD小芯片戰略的基石,MI300也不例外。MI300 團隊沒有資源為 MI300 構建全新的 CPU CCD,因此他們要求該公司的 CCD 團隊在設計階段的早期將 3D 接口 (TSV) 添加到 EPYC CCD。令人驚訝的是,工程團隊找到了一種將連接塞入現有 GMI 接口之間的方法。
在第一張幻燈片中,您可以看到兩個小藍點代表 TSV 的總面積,而點兩側的大橙色矩形塊是用于 2.5D 封裝的標準 GMI3 接口。這說明了 SoIC 技術的密度和面積效率是多么令人難以置信。AMD 還添加了一些門、開關和多路復用器,以允許信號從 GMI3 接口重新路由到 3D 接口。
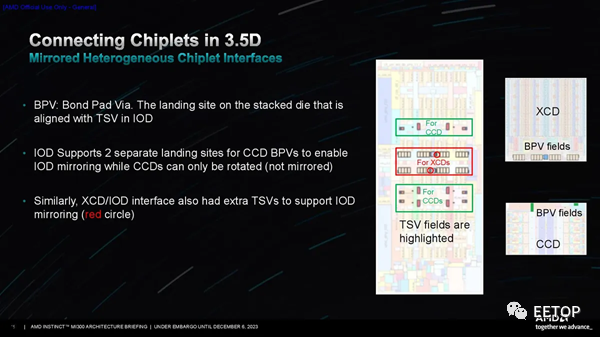
AMD創建了 I/O Die的鏡像版本,以確保它們可以旋轉到正確的位置,同時確保 XCD 中的內存控制器和其他接口仍然正確對齊。工程團隊對稱地設計了接口/信號和電源連接,從而允許小芯片旋轉,如第二張圖所示。
然而,雖然 AMD 專門為 MI300 從頭開始設計了 I/O Die,但該團隊必須采用 EPYC 的現有 CCD 設計。他們不想為 CCD 創建鏡面掩模組,這在此類設計中通常是必需的,以確保正確的接口對齊,因為這會增加設計的成本和復雜性。然而,其中兩個 CCD 需要旋轉 180 度才能確保正確對齊。然而,CCD的外部接口設計不對稱,因此帶來了挑戰。
如第三張幻燈片所示,AMD 通過在 I/O Die上的鍵合焊盤通孔 (BPV) 連接點添加一些冗余來克服這一挑戰,從而允許 CCD 僅旋轉而不是鏡像。
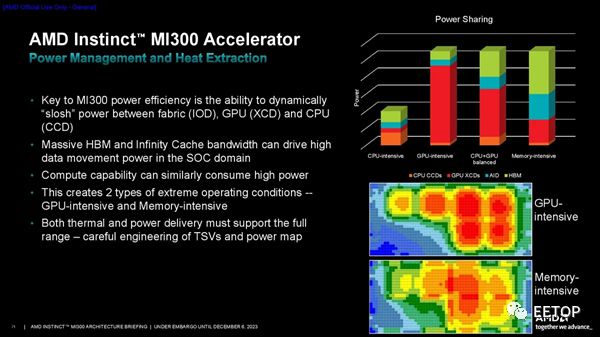
不過,供電輸送仍然是一個挑戰。TSV 是非常小的銅插頭,AMD 需要為位于 I/O Die頂部的計算芯片提供數百安培的電源。細小的 TSV 不太適合這項工作,因此它們需要大量的連接來供電。AMD 設計了一種新的電網來克服這個問題,它滿足了 IR 壓降目標,并且沒有超過電流密度限制。
最后,由于 3D 堆疊設計,該設計提出了一些新的熱挑戰。通過熱建模,AMD 確定了兩種類型的極端操作條件 - 內存密集型和 GPU 密集型 - 然后利用其基于使用模式在單元之間動態轉移功率的行之有效的策略來幫助緩解這些問題。
因此,一個令人難以置信的處理器誕生了。AMD的MI300在相當長的一段時間內對Nvidia在AI和HPC工作負載方面的性能主導地位提出了第一次真正的挑戰,AMD堅稱自己有能力滿足需求。在 GPU 短缺的時代,這是一種競爭優勢,并且肯定會刺激行業的快速發展。AMD 現在正在向其合作伙伴運送 MI300 處理器。
-
amd
+關注
關注
25文章
5476瀏覽量
134289 -
晶體管
+關注
關注
77文章
9706瀏覽量
138481 -
數據中心
+關注
關注
16文章
4810瀏覽量
72212 -
人工智能
+關注
關注
1792文章
47425瀏覽量
238955
原文標題:1530億晶體管,AMD發布史上最大、最強芯片!多項指標數倍于H100,打響挑戰英偉達第一槍!
文章出處:【微信號:semiwebs,微信公眾號:芯通社】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論