") 更強!Alpha-CLIP:讓CLIP關注你想要的任何地方!
更強!Alpha-CLIP:讓CLIP關注你想要的任何地方!
簡介
本文介紹了一個名為Alpha-CLIP的框架,它在原始的接受RGB三通道輸入的CLIP模型的上額外增加了一個alpha通道。在千萬量級的RGBA-region的圖像文本對上進行訓練后,Alpha-CLIP可以在保證CLIP原始感知能力的前提下,關注到任意指定區(qū)域。通過替換原始CLIP的應用場景,Alpha-CLIP在圖像識別、視覺-語言大模型、2D乃至3D生成領域都展現(xiàn)出強大作用。
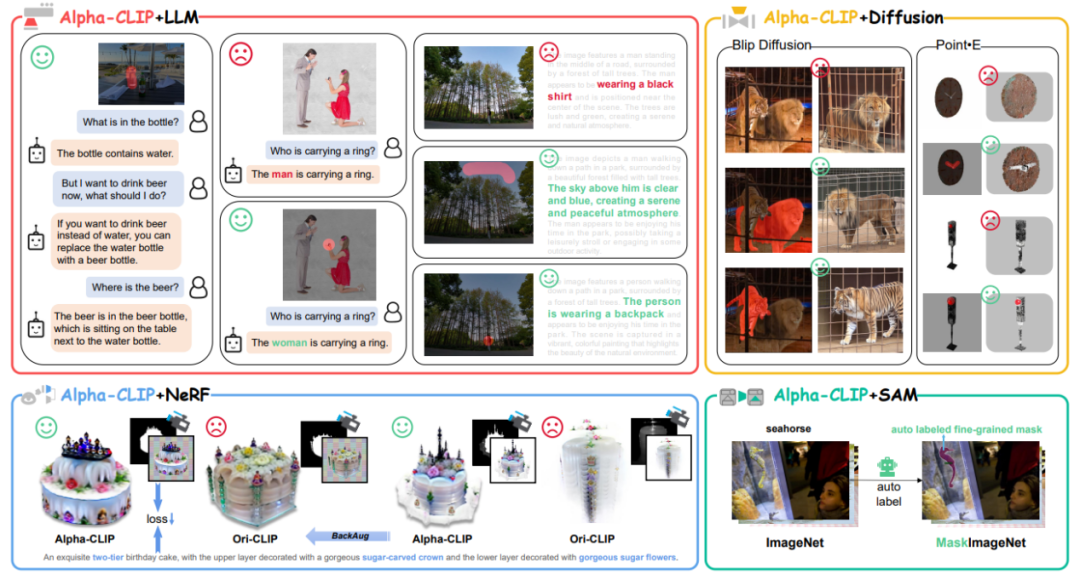
圖1 Alpha-CLIP使用場景總覽
CLIP作為目前最流行的視覺基座模型被廣泛使用。它的應用場景包括但不限于1.與LLM大語言模型結合成為視覺多模態(tài)大模型。2.作為圖像生成(Stable Diffusion)、點云生成(Point-E)的condition model, 實現(xiàn)image-to-3D。3.用于指導NeRF的優(yōu)化方向從而實現(xiàn)text-to-3D。4.本身用于開放類別的識別和檢測。
然而CLIP必須以整張圖片作為輸入并進行特征提取,無法關注到指定的任意區(qū)域。然而,自然的2D圖片中往往包含不同的物體,part和thing。如果能由用戶或檢測模型指定需要關注的區(qū)域,在圖像編碼的過程就確定需要關注的對象,將會提升CLIP模型的可控制性和區(qū)域檢測能力。
為此,上海人工智能實驗室聯(lián)合上海交通大學、復旦大學、香港中文大學、澳門大學的學者們提出了Alpha-CLIP模型,在原始CLIP模型的RGB三個通道的基礎上額外引入了第四個alpha通道來決定需要關注的區(qū)域。通過構造千萬量級的【RGBA四通道圖片-文本對】對Alpha-CLIP進行訓練,Alpha-CLIP不僅在ImageNet上保持了原始的全圖檢測能力,還能對用戶指定的任意區(qū)域進行highlight關注。下面分別介紹Alpha-CLIP的應用場景。

* 論文鏈接:https://arxiv.org/abs/2312.03818 * 項目主頁:https://aleafy.github.io/alpha-clip * 代碼鏈接:https://github.com/SunzeY/AlphaCLIP1. 圖像分類
如圖所示,對于ImagNet的一張圖片,我們可以通過alpha-map控制CLIP去關注魚或漁夫。
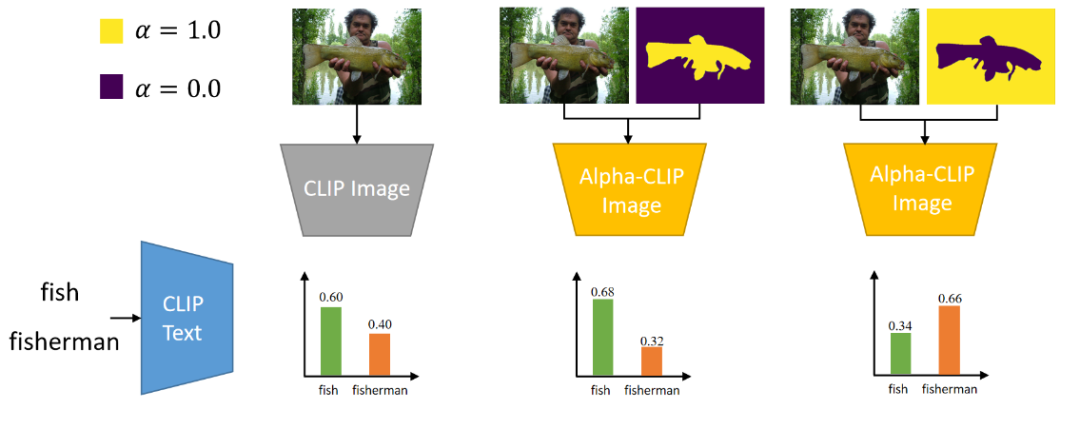

以ImageNet的Zero-Shot Classification作為評價指標,我們驗證了在對全圖進行識別時,Alpha-CLIP可以保持原本CLIP的分類準確率。進一步地,在給出了需要關注區(qū)域的長方形box或者mask時,Alpha-CLIP可以進一步提升分類準確率。
2. 與LLM大語言模型的結合
將主流的LLaVA-1.5中的CLIP基座模型替換為Alpha-CLIP,用戶可以通過簡單地用畫筆標記處需要關注的區(qū)域,從而進行指定區(qū)域的對話交互。
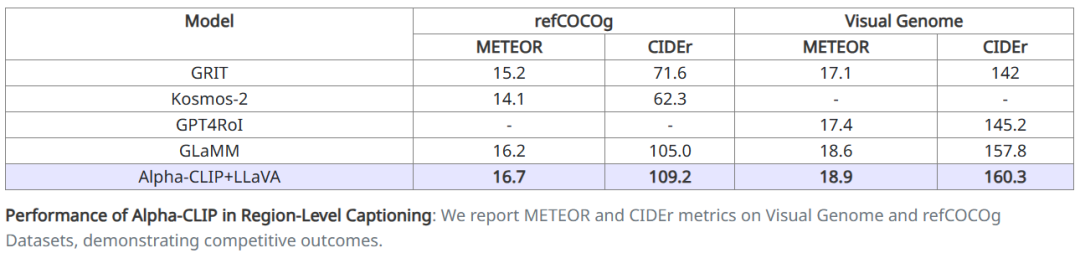
在定量實驗方面,我們通過LLaVA測試了MLLM的region caption能力。通過在RefCOCO和VG上分別進行finetune,取得了SOTA的region caption分數(shù)。
3. 與Stable Diffusion的結合
Stable-Diffusion是目前主流的2D圖片生成模型,其Image Variation版本可以實現(xiàn)“圖生圖”,其中圖片的編碼器也是CLIP模型。通過將該模型替換為Alpha-CLIP,可以實現(xiàn)更復雜圖片中指定物體的生成(同時較好地保留背景)。如上圖所示,使用原始的CLIP會生成同時具有獅子和老虎特征的“獅虎獸”,而Alpha-CLIP能夠很好地區(qū)分兩個物體,從而指導Stable Diffusion模型生成更專一的圖片。更多結果見下圖

4. 與Point-E的結合
Point-E是Open-AI開源的一個支持Image-to-3D和text-to-3D的點云diffusion模型,通過將它的Image編碼器從原始的CLIP替換為Alpha-CLIP。可以支持用戶對任意區(qū)域進行關注,從而恢復丟失的“表針”和“盾牌的十字架”。更多結果見下圖

5. Attention Map可視化
本工作對Alpha-CLIP的注意力進行可視化,以檢查Alpha-CLIP是否更加關注用戶定義alpha-map。通過檢查視覺編碼器中最后一個Transformer塊中[CLS] token的注意力圖。可視化采用了具有16個注意頭的ViT-L/14模型。為了進行公正比較,使用第5和第16個注意頭的注意力圖進行可視化,因為我們發(fā)現(xiàn)在這16個頭中,這兩個特征圖最為明顯。結果如下圖所示。這種可視化驗證了Alpha-CLIP更加關注要聚焦的區(qū)域,更重要的是,它在保留原始CLIP特征位置的二維位置信息時沒有造成損害。

結論
本文介紹的這項工作提出了Alpha-CLIP模型,該模型引入了一個額外的alpha通道,用于指定感興趣的區(qū)域。通過對數(shù)百萬個RGBA區(qū)域-文本對進行訓練,Alpha-CLIP不僅表現(xiàn)出卓越的區(qū)域關注能力,而且確保其輸出空間與原始的CLIP模型保持一致。這種一致性使得Alpha-CLIP在CLIP的各種下游應用中能夠輕松替代,無縫銜接。我們證明了當提供特定關注的區(qū)域時,Alpha-CLIP展現(xiàn)出了更強大的Zero-Shot識別能力,并驗證了它在許多下游任務中的有用性。CLIP的應用遠遠超出了本文的范圍。我們希望在前景區(qū)域或mask較容易獲得時,Alpha-CLIP將能夠在更多場景中得到應用。
雖然Alpha-CLIP在需要關注區(qū)域的各種場景中表現(xiàn)出有效的性能,但目前的結構和訓練過程限制了其專注于多個對象或建模不同對象之間關系的能力。此外,當前的訓練方法限制了alpha通道在中間值之外的泛化(只能接受0,1兩個值)。因此,用戶無法指定注意力的幅度。另一個限制同時存在于我們的Alpha-CLIP和原始CLIP中,即純Transformer結構的編碼器分辨率較低,這阻礙了Alpha-CLIP識別小物體并進行關注。我們計劃在未來的工作中解決這些限制并擴展CLIP的輸入分辨率。我們相信這些未來的方向是增強Alpha-CLIP能力并在各種下游任務中擴展其實用性的途徑。
-
人工智能
+關注
關注
1791文章
47203瀏覽量
238272 -
Clip
+關注
關注
0文章
31瀏覽量
6664 -
大模型
+關注
關注
2文章
2425瀏覽量
2646
原文標題:更強!Alpha-CLIP:讓CLIP關注你想要的任何地方!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
新品 | 可拼接燈板矩陣 Puzzle Unit & 創(chuàng)意固定套件CLIP-A/CLIP-B

使用TPA6112A后,藍牙1KHz信號有失真現(xiàn)象,怎么解決?
設計的tas5613a板子BTL模式正常工作1,2分鐘后clip告警,輸出端電壓為0是哪里的問題?怎么解決?
TPA3251不小心把GVDD_CD腳和CLIP管腳碰到一起,然后CILP和FAULT指示燈一直亮,管腳一直輸出低電平,什么問題?
為什么我的TPA3251上電后,F(xiàn)AULT和CLIP_OTW輸出電壓是1.4V左右?
請問TPA3244,RESET FAULT CLIP_OTW怎么跟MCU連接?
TPA3220功放的OTW_CLIP管腳會異常拉低,為什么?
TAS5630電路PBTL接法,CLIP燈無法滅是怎么回事?

如何停止引導加載程序輸出消息?
求分享esp8266和esp32的匯編指令集?
CapSENSE在CSX模式下同時跟蹤的觸點數(shù)量是否有限制?
愛芯元智推出邊端側智能SoCAX650N,讓視覺更智能
TPAK SiC優(yōu)選解決方案:有壓燒結銀+銅夾Clip無壓燒結銀





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論