") 拆解大語言模型RLHF中的PPO算法
拆解大語言模型RLHF中的PPO算法
為什么大多數(shù)介紹大語言模型 RLHF 的文章,一講到 PPO 算法的細(xì)節(jié)就戛然而止了呢?要么直接略過,要么就只扔出一個 PPO 的鏈接。然而 LLM x PPO 跟傳統(tǒng)的 PPO 還是有些不同的呀。
其實(shí)在 ChatGPT 推出后的相當(dāng)一段時間內(nèi),我一直在等一篇能給我講得明明白白的文章,但是一直未能如愿。我想大概是能寫的人都沒時間寫吧。 前幾個月,自己在工作中遇到要用到 PPO 的場景了。我心想,干脆自己啃算了。 于是我找到了 InstructGPT 引用的 OpenAI 自家的大語言模型 RLHF 論文《fine-tuning language models from human preferences》和《learning to summarize from human feedback》的源碼,逐行閱讀。然后用近似但不完全相同的風(fēng)格復(fù)現(xiàn)了一遍。后來又和同事一起把自己的實(shí)現(xiàn)和微軟的 DeepSpeed-Chat 的實(shí)現(xiàn)相互印證,才算是理解了。 既然已經(jīng)有了一些經(jīng)驗(yàn),為何不將它分享出來呢?就當(dāng)是拋磚引玉吧。萬一寫的不對,也歡迎大家一起交流討論。 由于本文以大語言模型 RLHF 的 PPO 算法為主,所以希望你在閱讀前先弄明白大語言模型 RLHF 的前兩步,即 SFT Model 和 Reward Model 的訓(xùn)練過程。另外因?yàn)楸疚牟皇羌冎v強(qiáng)化學(xué)習(xí)的文章,所以我在敘述的時候不會假設(shè)你已經(jīng)非常了解強(qiáng)化學(xué)習(xí)了。只是如果完全沒有了解過,你可能會覺得有些操作看上去沒有那么顯然。但只要你非常了解語言模型和深度學(xué)習(xí),應(yīng)該不會影響你把整個流程給捋順。 接下來,我會把大語言模型 RLHF 中的 PPO 分成三部分逐一介紹。這三部分分別是采樣、反饋和學(xué)習(xí)。 在開始之前,我先用一段偽代碼把三部分的關(guān)系簡要說明一下(先建立一個印象,看不懂也沒關(guān)系,后面自然會看懂):
policy_model=load_model()
forkinrange(20000):
#采樣(生成答案)
prompts=sample_prompt()
data=respond(policy_model,prompts)
#反饋(計算獎勵)
rewards=reward_func(reward_model,data)
#學(xué)習(xí)(更新參數(shù))
forepochinrange(4):
policy_model=train(policy_model,prompts,data,rewards)
對于其中的每部分我都會用計算圖來輔助描述,然后還會根據(jù)我的描述更新這段偽代碼。 好了,讓我們開始這趟旅程吧~
大語言模型的 RLHF,實(shí)際上是模型先試錯再學(xué)習(xí)的過程。 我們扮演著老師的角色,給出有趣的問題,而模型則會像小學(xué)生一樣,不斷嘗試給出答案。模型會對著黑板寫下它的答案,有時候是正確的,有時候會有錯誤。我們會仔細(xì)檢查每一個答案,如果它表現(xiàn)得好,就會給予它高聲贊揚(yáng);如果它表現(xiàn)不佳,我們則會給予它耐心的指導(dǎo)和反饋,幫助它不斷改進(jìn),直到達(dá)到令人滿意的水平。 1
采樣
采樣就是學(xué)生回答問題的過程,是模型根據(jù)提示(prompt)輸出回答(response)的過程,或者說是模型自行生產(chǎn)訓(xùn)練數(shù)據(jù)的過程。例如:
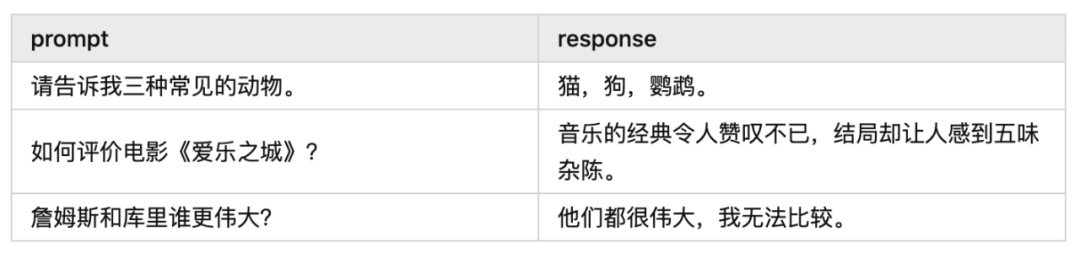
什么是“收益”呢?簡單來說就是從下一個 token 開始,模型能夠獲得的總獎勵(浮點(diǎn)數(shù)標(biāo)量)。這里說的獎勵包括 Reward Model 給出的獎勵。獎勵是怎么給的,以及收益有什么用,這些內(nèi)容我們后面會詳細(xì)介紹。
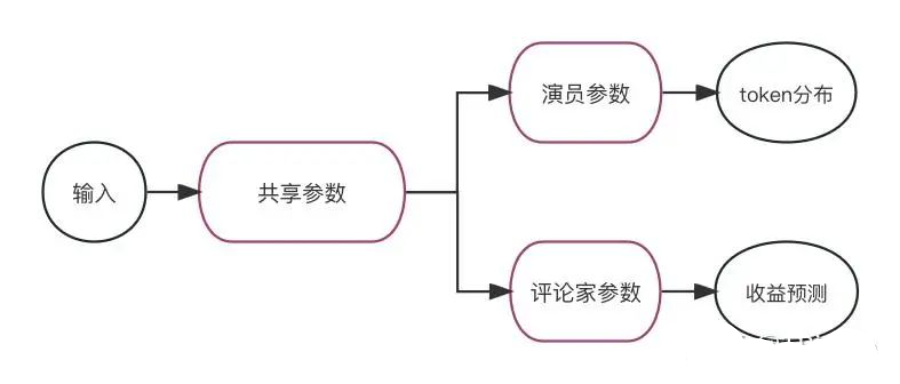
▲policy模型結(jié)構(gòu)
從實(shí)現(xiàn)上說,評論家就是將演員模型的倒數(shù)第二層連接到一個新的全連接層上。除了這個全連接層之外,演員和評論家的參數(shù)都是共享的(如上圖)。
上面提到的模型結(jié)構(gòu)是較早期的版本,后續(xù)不共享參數(shù)的實(shí)現(xiàn)方式也有很多。
現(xiàn)在我們來看看 PPO 的采樣過程中有哪些模型和變量。如下圖,矩形表示模型,橢圓表示變量。
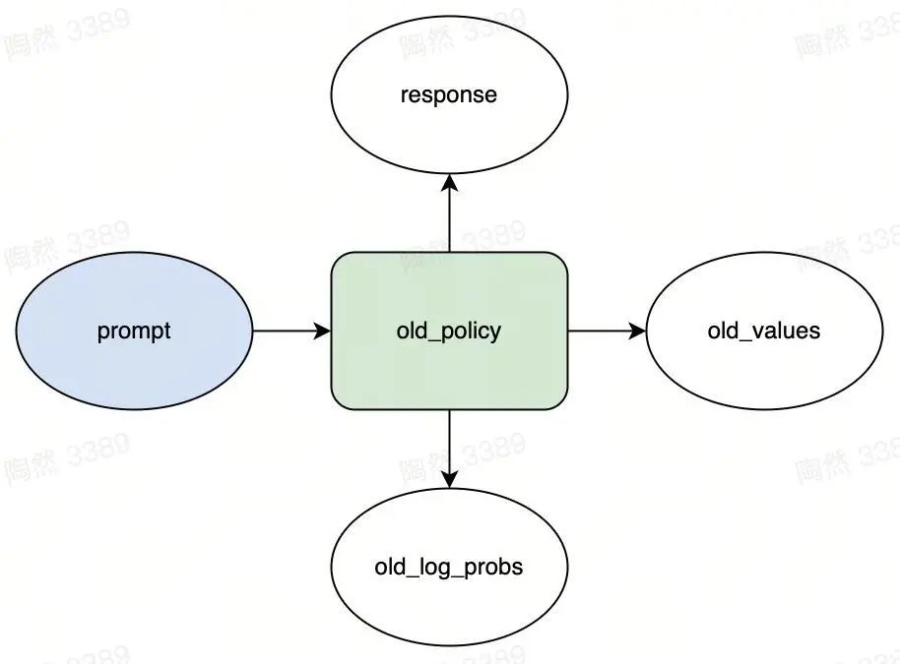
▲采樣流程(轉(zhuǎn)載須引用)
圖中的“old_policy”矩形就是剛剛說的 policy(為啥有個“old”前綴呢?后面我會詳細(xì)解釋)。
采樣指的是 old_policy 從 prompt 池中抽出 M 個 prompt 后,對每個 prompt 進(jìn)行語言模型的 token 采樣:- 計算 response 的第 1 個 token 的概率分布,然后從概率分布中采樣出第 1 個 token
- 根據(jù)第 1 個 token,計算 response 的第2 個 token 的概率分布,然后從概率分布中采樣出第 2 個 token
- ……
- 根據(jù)前 N-1 個 token,計算 response 的第 N 個 token 的概率分布,然后從概率分布中采樣出第 N 個 token
 ▲語言模型的token采樣
▲語言模型的token采樣
然后就得到了三個輸出。假設(shè)對每個 prompt,policy 生成的 token 的個數(shù)為 N,那么這三個輸出分別是:
-
response:M 個字符串,每個字符串包含 N 個 token
-
old_log_probs:演員輸出的 M × N 的張量,包含了 response 中 token 的對數(shù)概率log(p(token|context))
- old_values:評論家輸出的 M ×N的張量,包含了每次生成 token 時評論家預(yù)估的收益
得到這三個輸出后,采樣階段就就結(jié)束了。這三個輸出都是后續(xù)階段重要的輸入數(shù)據(jù)。
我們先將采樣部分的偽代碼更新一下:
#采樣
prompts=sample_prompt()
responses,old_log_probs,old_values=respond(policy_model,prompts)
就像是一場考試,學(xué)生已經(jīng)完成了答題環(huán)節(jié),他們在黑板上留下了答案。但這只是整個學(xué)習(xí)過程的一個環(huán)節(jié),接下來是關(guān)鍵的反饋步驟。
2
反饋
反饋就是老師檢查答案的過程,是獎勵模型(Reward Model)給 response 打分的過程,或者說是獎勵模型給訓(xùn)練數(shù)據(jù) X 標(biāo)上 Y 值的過程。 打出的分?jǐn)?shù)衡量了 response 的正確性,它也可以被視為 prompt 和 response 的匹配程度。 例如:
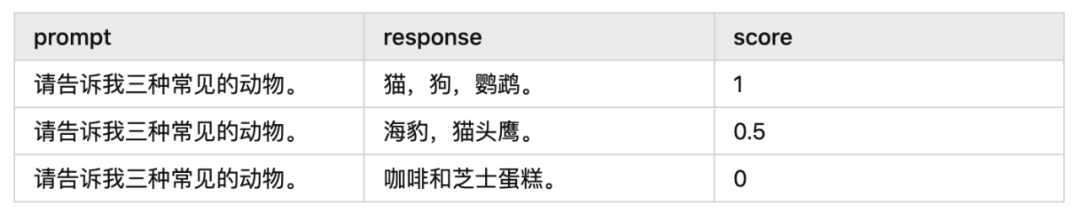 Reward Model 可以被比作班級里成績最好的學(xué)生,他能夠輔助老師批改作業(yè)。就像老師先教會這個學(xué)生如何批改作業(yè),之后這個學(xué)生就能獨(dú)立完成作業(yè)批改一樣,Reward Model 通過學(xué)習(xí)和訓(xùn)練,也能夠獨(dú)立地完成任務(wù)并給出正確的答案。
網(wǎng)上有很多資料介紹 Reward Model 的訓(xùn)練過程,這也不是本文的重點(diǎn),我就不再贅述了。
PPO 拿訓(xùn)練好的 Reward Mode 做了什么呢?我們接著看圖說話:
Reward Model 可以被比作班級里成績最好的學(xué)生,他能夠輔助老師批改作業(yè)。就像老師先教會這個學(xué)生如何批改作業(yè),之后這個學(xué)生就能獨(dú)立完成作業(yè)批改一樣,Reward Model 通過學(xué)習(xí)和訓(xùn)練,也能夠獨(dú)立地完成任務(wù)并給出正確的答案。
網(wǎng)上有很多資料介紹 Reward Model 的訓(xùn)練過程,這也不是本文的重點(diǎn),我就不再贅述了。
PPO 拿訓(xùn)練好的 Reward Mode 做了什么呢?我們接著看圖說話:
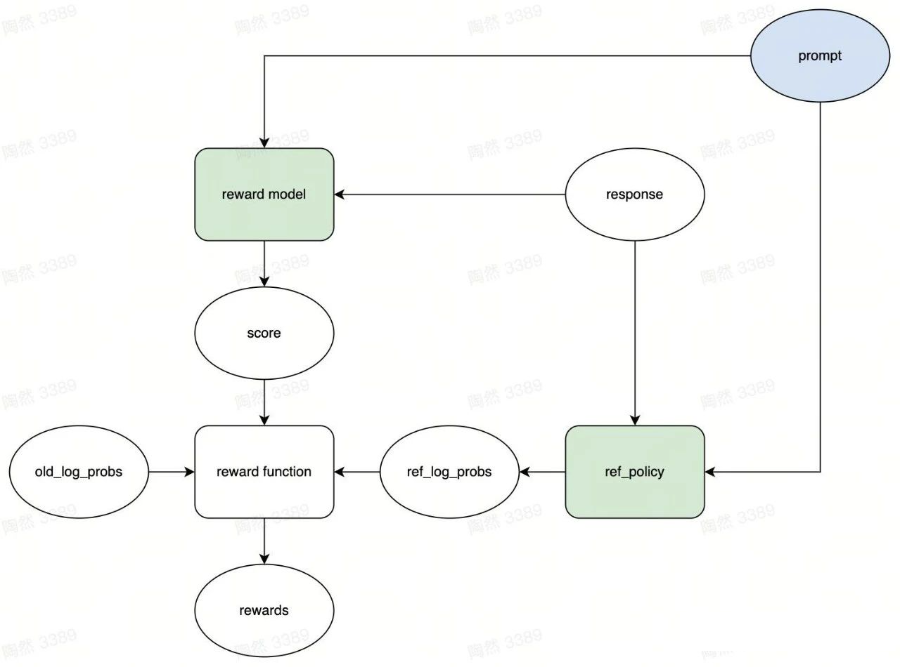 ▲ 獎勵流程(轉(zhuǎn)載須引用)從圖中我們可以看出,左上角的綠色矩形 reward model 拿到 prompt 和 response,然后輸出了分?jǐn)?shù) score。實(shí)際上發(fā)生的事情是,prompt 和 response 被拼接成一個字符串,接著被送入到 reward model 中,最后 reward model 計算出了匹配分?jǐn)?shù)。
你也許發(fā)現(xiàn)了,在圖中,score 并不是最終的獎勵。它和最終的獎勵 rewards 之間還隔著一個 reward function 函數(shù)。
這是因?yàn)?score 只能衡量結(jié)果的對錯,不能衡量過程的合理性。怎么衡量過程的合理性呢?一種簡單粗暴的方法是:循規(guī)蹈矩,即為合理。
當(dāng)年愛因斯坦的相對論理論首次發(fā)表時,遭遇了許多質(zhì)疑。后來,該理論被證明并得到了應(yīng)有的認(rèn)可。大家的目光可能都聚焦于愛因斯坦是如何堅(jiān)定不移地堅(jiān)持自己的理念并獲得成功的。
然而,你有沒有想過,那些反對和質(zhì)疑其實(shí)也是必要的。
在相對論理論出現(xiàn)之前,已經(jīng)有一個相對完整的物理系統(tǒng)。當(dāng)時,一個年輕人突然出現(xiàn)挑戰(zhàn)這個系統(tǒng)。在不知道他的路數(shù)的情況下,有必要基于現(xiàn)有的經(jīng)驗(yàn)給予適當(dāng)?shù)馁|(zhì)疑。因?yàn)椴⒎敲總€人都是偉人啊。如果他的理論真的得到驗(yàn)證,那么就是給予肯定和榮譽(yù)的時候了。
語言模型也是一樣,在我們給予最終獎勵之前,最好也對它的“標(biāo)新立異”給予少量的懲罰(即剛剛說的質(zhì)疑)。
怎么做呢?我們給它立一個規(guī)矩,只要它按照這個規(guī)矩來,就能獲得少量獎勵。而這個規(guī)矩就是我們在 SFT 階段已經(jīng)訓(xùn)練好的語言模型 ref_policy(圖中右下角的綠色矩形),或者說是完全還沒經(jīng)過強(qiáng)化學(xué)習(xí)訓(xùn)練的語言模型。
過程合理性獎勵的計算方式是這樣的。ref_policy 拿到 prompt,然后給 old_policy 生成的 response 的每個 token 計算對數(shù)概率,得到一個張量 ref_log_prob。現(xiàn)在假設(shè) old_policy 的演員模型生成了第 i 個 token,此時它應(yīng)該獲得的獎勵為:
▲ 獎勵流程(轉(zhuǎn)載須引用)從圖中我們可以看出,左上角的綠色矩形 reward model 拿到 prompt 和 response,然后輸出了分?jǐn)?shù) score。實(shí)際上發(fā)生的事情是,prompt 和 response 被拼接成一個字符串,接著被送入到 reward model 中,最后 reward model 計算出了匹配分?jǐn)?shù)。
你也許發(fā)現(xiàn)了,在圖中,score 并不是最終的獎勵。它和最終的獎勵 rewards 之間還隔著一個 reward function 函數(shù)。
這是因?yàn)?score 只能衡量結(jié)果的對錯,不能衡量過程的合理性。怎么衡量過程的合理性呢?一種簡單粗暴的方法是:循規(guī)蹈矩,即為合理。
當(dāng)年愛因斯坦的相對論理論首次發(fā)表時,遭遇了許多質(zhì)疑。后來,該理論被證明并得到了應(yīng)有的認(rèn)可。大家的目光可能都聚焦于愛因斯坦是如何堅(jiān)定不移地堅(jiān)持自己的理念并獲得成功的。
然而,你有沒有想過,那些反對和質(zhì)疑其實(shí)也是必要的。
在相對論理論出現(xiàn)之前,已經(jīng)有一個相對完整的物理系統(tǒng)。當(dāng)時,一個年輕人突然出現(xiàn)挑戰(zhàn)這個系統(tǒng)。在不知道他的路數(shù)的情況下,有必要基于現(xiàn)有的經(jīng)驗(yàn)給予適當(dāng)?shù)馁|(zhì)疑。因?yàn)椴⒎敲總€人都是偉人啊。如果他的理論真的得到驗(yàn)證,那么就是給予肯定和榮譽(yù)的時候了。
語言模型也是一樣,在我們給予最終獎勵之前,最好也對它的“標(biāo)新立異”給予少量的懲罰(即剛剛說的質(zhì)疑)。
怎么做呢?我們給它立一個規(guī)矩,只要它按照這個規(guī)矩來,就能獲得少量獎勵。而這個規(guī)矩就是我們在 SFT 階段已經(jīng)訓(xùn)練好的語言模型 ref_policy(圖中右下角的綠色矩形),或者說是完全還沒經(jīng)過強(qiáng)化學(xué)習(xí)訓(xùn)練的語言模型。
過程合理性獎勵的計算方式是這樣的。ref_policy 拿到 prompt,然后給 old_policy 生成的 response 的每個 token 計算對數(shù)概率,得到一個張量 ref_log_prob。現(xiàn)在假設(shè) old_policy 的演員模型生成了第 i 個 token,此時它應(yīng)該獲得的獎勵為:
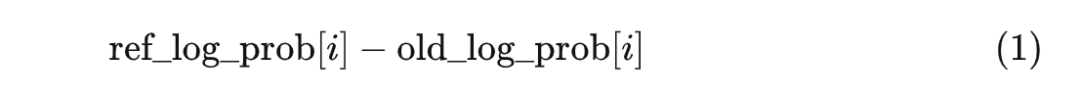
來理解一下這個式子:
-
ref_log_prob[i] 越高,ref_policy 越認(rèn)可 old_policy 的輸出,說明 old_policy 更守規(guī)矩,因此應(yīng)該獲得更高的獎勵;
- old_log_prob[i] 越高,old_policy 獲得的獎勵反而更低。old_log_prob[i] 作為正則項(xiàng),可以保證概率分布的多樣性。
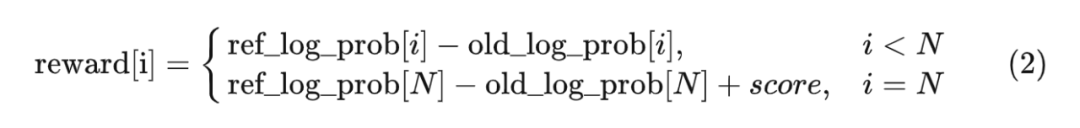 式 (2) 就是圖中“reward function”的計算內(nèi)容。
通俗來說,整個 reward function 的計算邏輯是典型的霸總邏輯:除非你能拿到好的結(jié)果,否則你就得給我守規(guī)矩。注意,我們只對 response 計算獎勵。另外在整個反饋階段,reward_model 和 ref_policy 是不更新參數(shù)的。一旦給出 reward,就完成了反饋階段。現(xiàn)在我們將反饋部分的偽代碼更新一下:
式 (2) 就是圖中“reward function”的計算內(nèi)容。
通俗來說,整個 reward function 的計算邏輯是典型的霸總邏輯:除非你能拿到好的結(jié)果,否則你就得給我守規(guī)矩。注意,我們只對 response 計算獎勵。另外在整個反饋階段,reward_model 和 ref_policy 是不更新參數(shù)的。一旦給出 reward,就完成了反饋階段。現(xiàn)在我們將反饋部分的偽代碼更新一下:
#采樣
prompts=sample_prompt()
responses,old_log_probs,old_values=respond(policy_model,prompts)
#policy_model的副本,不更新參數(shù)
ref_policy_model=policy_model.copy()
#反饋
scores=reward_model(prompts,responses)
ref_log_probs=analyze_responses(ref_policy_model,prompts,responses)
rewards=reward_func(reward_model,scores,old_log_probs,ref_log_probs)
這就像是老師在檢查學(xué)生的答案并給出評價后,學(xué)生們就可以了解他們的表現(xiàn)如何,并從中學(xué)習(xí)和進(jìn)步。然而,獲得反饋并不是結(jié)束,而是新的開始。正如學(xué)生需要用這些反饋來進(jìn)行復(fù)習(xí)和改進(jìn)一樣,模型也需要通過學(xué)習(xí)階段來優(yōu)化其性能和預(yù)測能力。
3
學(xué)習(xí)
“學(xué)習(xí)”就是學(xué)生根據(jù)反饋總結(jié)得失并自我改進(jìn)的過程,或者說是強(qiáng)化優(yōu)勢動作的過程。
如果說前兩步分別是在收集數(shù)據(jù) X,以及給數(shù)據(jù)打上標(biāo)簽 Y。那么這一步就是在利用數(shù)據(jù) (X, Y) 訓(xùn)練模型。
"強(qiáng)化優(yōu)勢動作"是 PPO 學(xué)習(xí)階段的焦點(diǎn)。在深入探討之前,我們首先要明確一個關(guān)鍵概念——優(yōu)勢。
此處,我們將優(yōu)勢定義為“實(shí)際獲得的收益超出預(yù)期的程度”。
為了解釋這個概念,請?jiān)试S我舉一個例子。假設(shè)一個高中生小明,他在高一時數(shù)學(xué)考試的平均分為 100 分,在此之后,大家對他的數(shù)學(xué)成績的預(yù)期就是 100 分了。到了高二,他的數(shù)學(xué)平均分提升到了 130 分。在這個學(xué)期,小明的數(shù)學(xué)成績顯然是超出大家的預(yù)期的。
表現(xiàn)是可用分?jǐn)?shù)量化的,故表現(xiàn)超出預(yù)期的程度也是可以用分?jǐn)?shù)差來量化的。我們可以認(rèn)為,在高二階段,小明超出預(yù)期的程度為 30 分(130 - 100)。根據(jù)優(yōu)勢的定義我們可以說,在高二階段,小明相對于預(yù)期獲得了 30 分的優(yōu)勢。
在這個例子中,實(shí)際已經(jīng)給出了 PPO 計算優(yōu)勢的方法:優(yōu)勢 = 實(shí)際收益 - 預(yù)期收益。
對于語言模型而言,生成第 i 個 token 的實(shí)際收益就是:從生成第 i 個 token 開始到生成第 N 個 token 為止,所能獲得的所有獎勵的總和。我們用 return 來表示實(shí)際收益,它的計算方式如下:
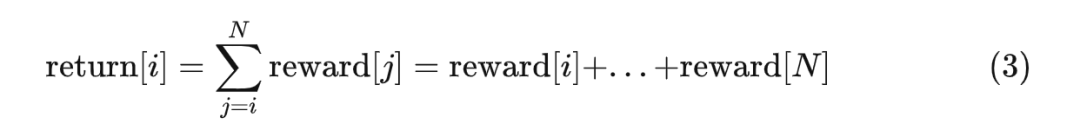
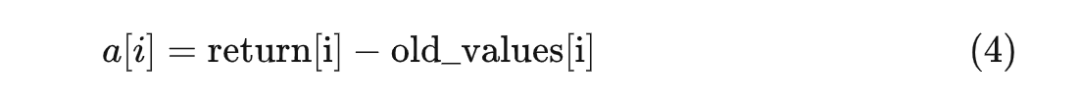
好的,我們已經(jīng)理解了優(yōu)勢的含義了。現(xiàn)在終于可以揭開這個關(guān)鍵主題的面紗——在 PPO 學(xué)習(xí)階段,究竟什么是"強(qiáng)化優(yōu)勢動作"。
所謂“強(qiáng)化優(yōu)勢動作”,即強(qiáng)化那些展現(xiàn)出顯著優(yōu)勢的動作。
在上面的小明的例子中,這意味著在高三階段,小明應(yīng)該持續(xù)使用高二的學(xué)習(xí)方法,因?yàn)樵诟叨A段,他的學(xué)習(xí)策略展示出了顯著的優(yōu)勢。
在語言模型中,根據(jù)上下文生成一個 token 就是所謂的“動作”。"強(qiáng)化優(yōu)勢動作"表示:如果在上下文(context)中生成了某個 token,并且這個動作的優(yōu)勢很高,那么我們應(yīng)該增加生成該 token 的概率,即增加 p(token|context) 的值。
由于 policy 中的演員模型建模了 p(token|context),所以我們可以給演員模型設(shè)計一個損失函數(shù),通過優(yōu)化損失函數(shù)來實(shí)現(xiàn)“強(qiáng)化優(yōu)勢動作”:
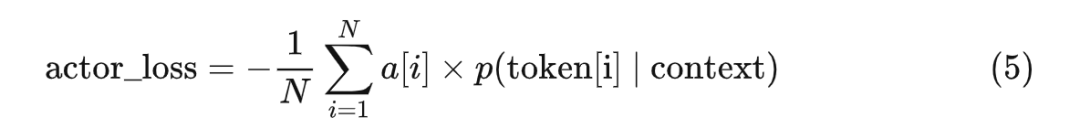
其中:
- 當(dāng)優(yōu)勢大于 0 時,概率越大,loss 越小;因此優(yōu)化器會通過增大概率(即強(qiáng)化優(yōu)勢動作)來減小 loss
-
當(dāng)優(yōu)勢小于 0 時,概率越小,loss 越小;因此優(yōu)化器會通過減小概率(即弱化劣勢動作)來減小 loss
這很像巴浦洛夫的狗不是嗎?
另外還有兩個點(diǎn)值得注意:
- 優(yōu)勢的絕對值越大,loss 的絕對值也就越大
-
優(yōu)勢是不接收梯度回傳的
實(shí)際上,式 5 只是一個雛形。PPO 真正使用的演員的損失函數(shù)是這樣的:
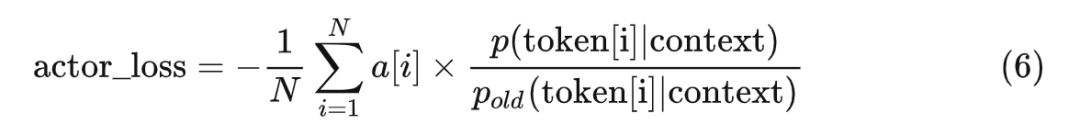
* 寫給熟悉 RL 的人:簡單起見,在這里我們既不考慮損失的截斷,也不考慮優(yōu)勢的白化。
式子 6 相比式 5 子多了一個分母 。在式子 6 里, 表示 的一個較老的版本。因?yàn)樗唤邮仗荻然貍鳎晕覀兛梢詫?當(dāng)作常量,或者說,把它當(dāng)成 的學(xué)習(xí)率的一部分。我們來分析一下它的作用。以優(yōu)勢大于 0 的情況為例,對任意 ,當(dāng) 有較大的值的時候, 的參數(shù)的學(xué)習(xí)率更小。直觀來說,當(dāng)生成某個 token 的概率已經(jīng)很大了的時候,即便這個動作的優(yōu)勢很大,也不要再使勁增大概率了。或者更通俗地說,就是步子不要邁得太大。現(xiàn)在的問題就是,我們應(yīng)該使用 p 的哪個老版本。還記得我們在本文開頭時給出的偽代碼嗎(后來在介紹“采樣”和“反饋”階段時又各更新了一次),我們對著代碼來解釋:
policy_model=load_model()
ref_policy_model=policy_model.copy()
forkinrange(20000):
#采樣(已更新)
prompts=sample_prompt()
responses,old_log_probs,old_values=respond(policy_model,prompts)
#反饋(已更新)
scores=reward_model(prompts,responses)
ref_log_probs=analyze_responses(ref_policy_model,prompts,responses)
rewards=reward_func(reward_model,scores,old_log_probs,ref_log_probs)
#學(xué)習(xí)
forepochinrange(4):
policy_model=train(policy_model,prompts,responses,old_log_probs,old_values,rewards)
簡單來說,這段代碼做的事情是:迭代 2 萬次。在每次迭代中,通過采樣和反饋得到一份數(shù)據(jù),然后在學(xué)習(xí)階段使用數(shù)據(jù)微調(diào)語言模型。每份數(shù)據(jù)我們都拿來訓(xùn)練 4 個 epoch。
那 使用 2 萬次迭代開始之前的演員模型的參數(shù)可以嗎?不行,那個版本過于老了(實(shí)際上就是 SFT,我們已經(jīng)在獎勵階段中的 ref_policy 中用過了)。不妨使用同一次迭代的還未進(jìn)入學(xué)習(xí)階段的演員模型吧。如果是這樣的話,仔細(xì)一看, 不就是采樣階段得到的 old_log_probs 嗎?只是少了一個對數(shù)而已。這就是為什么我們在采樣階段,對所有的模型和參數(shù)都使用“old”前綴,就是為了區(qū)分模型和變量的版本。(補(bǔ)充:前面提到的 old_policy 指的是上面?zhèn)未a中采樣出 old_log_probs 的那個時刻的 policy_model)而對于 我們可以使用實(shí)時的演員模型的參數(shù)計算出來,然后用 log_prob 來表示它。于是,我們可以將式子 6 改寫成以下形式: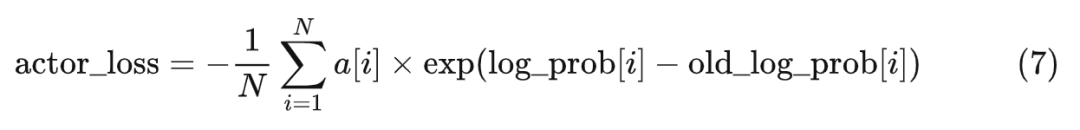
至此,我們完整地描述了 PPO 的學(xué)習(xí)階段中“強(qiáng)化優(yōu)勢動作”的方法。就像下面的計算圖展示的那樣(policy 與前面的圖中的 old_policy 不一樣,是實(shí)時版本的模型)。
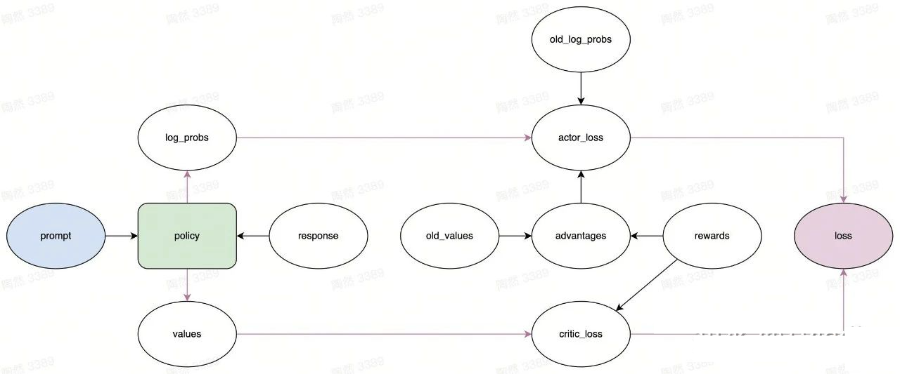
▲學(xué)習(xí)流程(轉(zhuǎn)載須引用)
等等,似乎還沒完。圖中還有一個叫 critic_loss 的沒提到過的東西。
當(dāng)然了,負(fù)責(zé)決策的演員需要學(xué)習(xí),難道總結(jié)得失的評論家就不需要學(xué)習(xí)了?評論家也是需要與時俱進(jìn)的嘛,否則畫評家難道不怕再次錯過梵高那樣的天才?
前面我們提到過,評論家會為 response 中的每個 token 計算一個預(yù)期收益,第 個預(yù)期收益記為 values[i],它預(yù)估的是 。既然如此,就設(shè)計一個損失函數(shù)來衡量評論家預(yù)期收益和真實(shí)收益之間的差距。
PPO 用的是均方差損失(MSE):
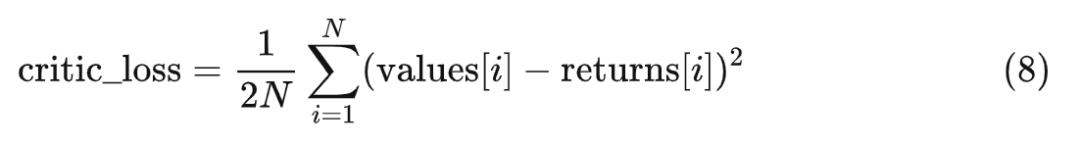
* 寫給熟悉 RL 的人:由于我們不考慮 GAE,所以 returns 的計算也做了相應(yīng)的簡化。
最終優(yōu)化 policy 時用的 loss 是演員和評論家的 loss 的加權(quán)和:

這才算是真正完事兒了。現(xiàn)在我們將整個 PPO 的偽代碼都更新一下:
policy_model=load_model()
ref_policy_model=policy_model.copy()
forkinrange(20000):
#采樣
prompts=sample_prompt()
responses,old_log_probs,old_values=respond(policy_model,prompts)
#反饋
scores=reward_model(prompts,responses)
ref_log_probs,_=analyze_responses(ref_policy_model,prompts,responses)
rewards=reward_func(reward_model,scores,old_log_probs,ref_log_probs)
#學(xué)習(xí)
forepochinrange(4):
log_probs,values=analyze_responses(policy_model,prompts,responses)
advantages=advantage_func(rewards,old_values)
actor_loss=actor_loss_func(advantages,old_log_probs,log_probs)
critic_loss=critic_loss_func(rewards,values)
loss=actor_loss+0.1*critic_loss
train(loss,policy_model.parameters())
4
總結(jié)
到這里,大語言模型 RLHF 中 PPO 算法的完整細(xì)節(jié)就算介紹完了。掌握這些細(xì)節(jié)之后,我們可以做的有趣的事情就變多了。例如:
-
你可以照著偽代碼從頭到尾自己實(shí)現(xiàn)一遍,以加深理解。相信我,這是非常有趣且快樂的過程
-
你可以以此為契機(jī),把強(qiáng)化學(xué)習(xí)知識系統(tǒng)性地學(xué)一遍。你會發(fā)現(xiàn)很多強(qiáng)化學(xué)習(xí)的概念一下變得具象化了
-
你可以在你的產(chǎn)品或者研究方向中思考 PPO 是否可以落地
-
你也許會發(fā)現(xiàn) PPO 算法的不合理之處,那么就深入研究下去,直到做出自己的改進(jìn)
-
你可以跟周圍不熟悉 PPO 的小伙伴吹牛,順便嘲諷對方(大誤)
總之,希望我們都因?yàn)檎莆樟酥R變得更加充實(shí)和快樂~
-
算法
+關(guān)注
關(guān)注
23文章
4607瀏覽量
92842 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1560瀏覽量
7598 -
大模型
+關(guān)注
關(guān)注
2文章
2425瀏覽量
2646 -
LLM
+關(guān)注
關(guān)注
0文章
286瀏覽量
327
原文標(biāo)題:拆解大語言模型RLHF中的PPO算法
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
大語言模型開發(fā)框架是什么
大語言模型開發(fā)語言是什么
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識學(xué)習(xí)
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實(shí)踐】大語言模型的評測
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】核心技術(shù)綜述
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》
圖解大模型RLHF系列之:人人都能看懂的PPO原理與源碼解讀

大語言模型推斷中的批處理效應(yīng)

一種基于表征工程的生成式語言大模型人類偏好對齊策略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論