 Python軸承故障診斷之經驗模態分解EMD原理介紹
Python軸承故障診斷之經驗模態分解EMD原理介紹
1 經驗模態分解EMD原理介紹
1.1 EMD概述
經驗模態分解(Empirical Mode Decomposition,EMD)方法是一種自適應信號時頻處理方法,特別適用于非線性、非平穩信號的分析處理[1]。其本質是一種對信號進行分解的方法,將信號分解為各個相互獨立的成分的疊加,依據數據自身的時間尺度特征來進行信號分解,具備自適應性。
EMD的優點在于它是一種自適應的、數據驅動的分解方法,不需要預先假設信號的分布或結構。這使得它適用于處理各種類型的信號,包括非線性和非平穩信號。
EMD 認為任何一個復雜序列都是由多個單頻率信號疊加而成,因此可以分解成若干個 本征模態函數(Intrinsic Mode Functions, IMF),IMF 的各個分量即代表了原始信號中的各頻 率分量,并按照從高頻到低頻的順序依次排列,這也是 IMF 的物理含義[2]。
1.2 本征模態函數IMF
本征模態函數(Intrinsic Mode Functions, IMF)就是原始信號被 EMD 分解之后得到的各層信號分量。任何信號都可以拆分成若干個 IMF 之和。IMF 有兩個假設條件:
- 在整個數據段內,極值點的個數和過零點的個數必須相等或相差最多不能超過一 個;
- 在任意時刻,由局部極大值點形成的上包絡線和由局部極小值點形成的下包絡線 的平均值為零,即上、下包絡線相對于時間軸局部對稱。
對于上述的條件理解如下:
第一,圖線要反復跨越 x 軸,比如:
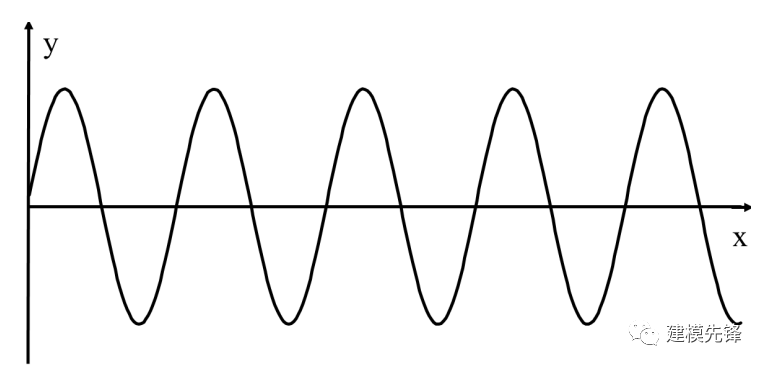
反復跨越 x 軸
而不能像下面這樣某次穿過零點后出現多個極點:
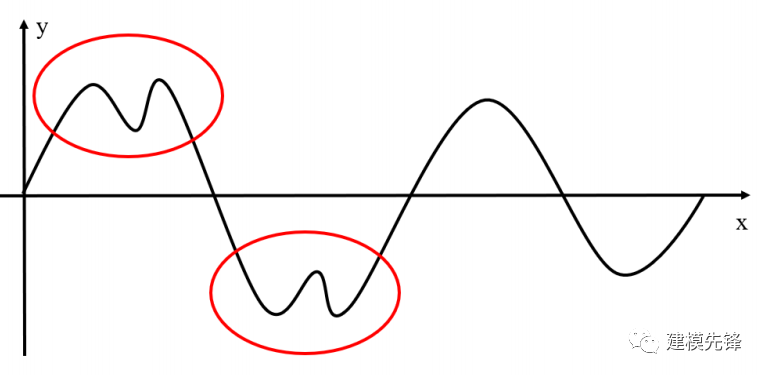
某次穿過零點后出現多個極點
第二,上下包絡線要對稱,比如:
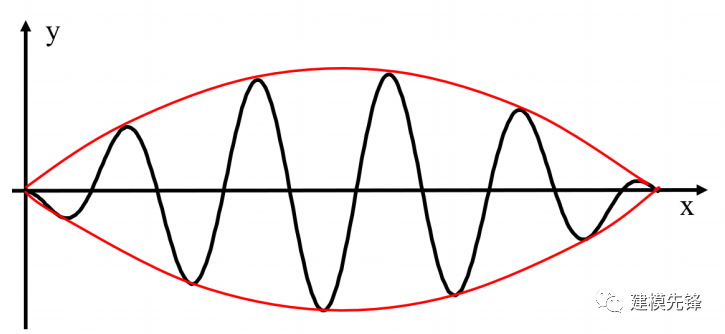
上下包絡線對稱
而不能像如下這樣,上下包絡線不對稱
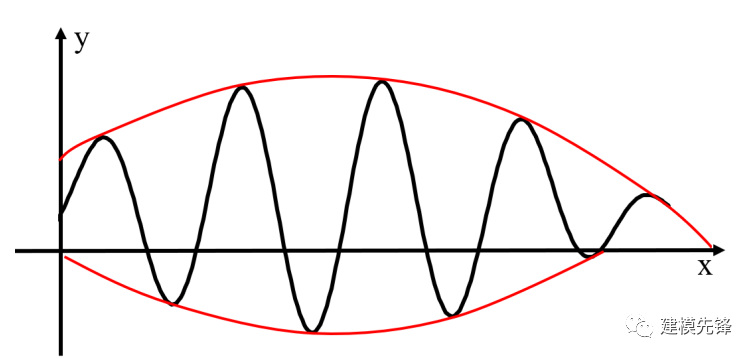
1.3 EMD 分解的基本假設
- 信號至少有兩個極值點:一個極大值點和一個極小值點;
- 特征時間尺度由極值之間的時間間隔定義;
- 如果數據完全沒有極值,但只包含拐點,那么可以一次或多次劃分來揭示極值點,最終的結果可以通過積分得到
2 EMD分解的基本原理和步驟
EMD的分解過程是一個迭代的過程。首先,對原始信號進行極值點的提取,然后通過連接極值點的均值得到第一輪的近似IMF(也叫做“本征模態”)。接下來,將這個近似IMF從原始信號中減去,得到一個新的信號,然后對這個新信號再次進行極值點提取和均值連接,得到第二輪的近似IMF。如此往復,直到得到的近似IMF滿足某種停止準則。
對于原始信號 X(t)
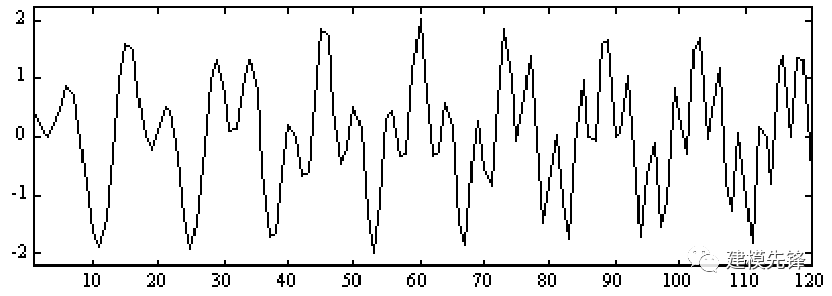
第一步,極值點提取:
從待分解的信號中識別局部極值點,包括局部極大值和局部極小值。極值點是信號中的局部特征,能夠幫助刻畫信號的振蕩特性。
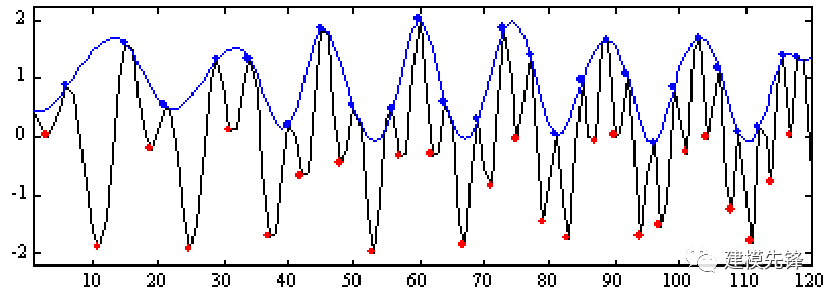
第二步,構建上下包絡線:
通過連接相鄰的局部極大值和局部極小值,構建信號的上包絡線和下包絡線。上包絡線 U(t) 由局部極大值連接而成,下包絡線 L(t) 由局部極小值連接而成。包絡線用于描述信號的振蕩范圍。
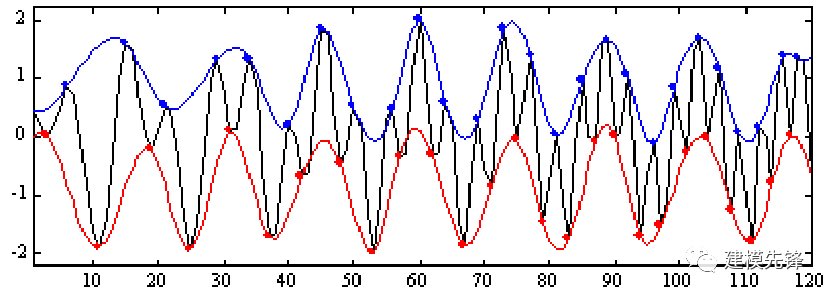
第三步,提取均值函數:
計算上包絡線和下包絡線的平均值,得到均值函數 m1。將原始信號減去均值函數,得到一維信號 h1。
m1 = ( U(t) + L(t) ) / 2
h1 = X(t) - m1
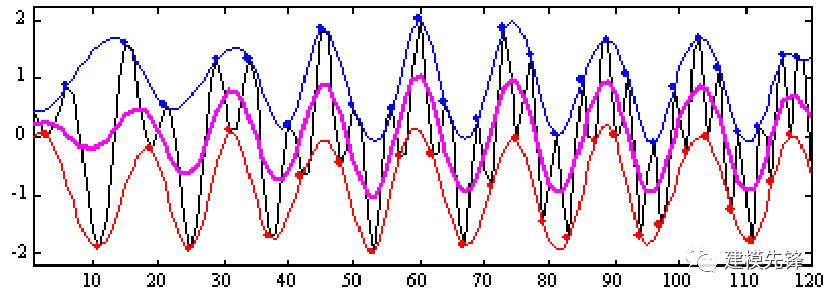
第四步,迭代分解:
對減去均值函數后的一維信號 h1,重復步驟1-3的過程,直到得到的剩余信號為“單調信號”,或者滿足IMF的兩個假設條件。迭代k次的IMF為
hk = h(k-1) - mk
第五步,確定本征模態函數(IMF):
在每一次迭代中,通過極值點提取、構建包絡線等步驟,得到的剩余信號被稱為一個本征模態函數(IMF)。IMF具有局部特征,并且代表了信號在不同尺度上的振蕩模式。使用上述方法得到的第一個IMF記為c1, 然后將c1從原始信號中分離,得到
r1 = X(t) - c1
由于r1仍然包含大量信息,因此將r1作為新的原始信號,再通過步驟1-4的分析,可以得到IMF2,以此類推,得到
r1 - c2 = r2,... ..., r(n-1) -cn = rn
當cn或rn小于某一設定值,或者得到的剩余信號為“單調信號”,無法提取更多的IMF時,迭代終止,得到最終的分解結果為:
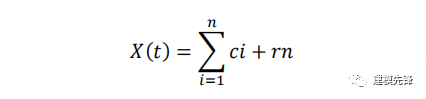
第六步,重構信號:
將得到的IMF函數進行逐個提取,直到無法再得到新的IMF為止。最終得到的IMF函數可以被看作是信號在不同時間尺度上的振蕩模式,它們的組合可以重構原始信號。
這些基本步驟構成了EMD方法的核心流程,通過這些步驟,EMD可以將復雜的信號分解成不同尺度和頻率的本征模態函數,從而揭示信號的局部特征和振蕩模式。
3 基于Python的EMD實現
在 Python 中,使用 PyEMD 庫來實現經驗模態分解(EMD)
2.1 代碼示例
import numpy as np
import matplotlib.pyplot as plt
from PyEMD import EMD
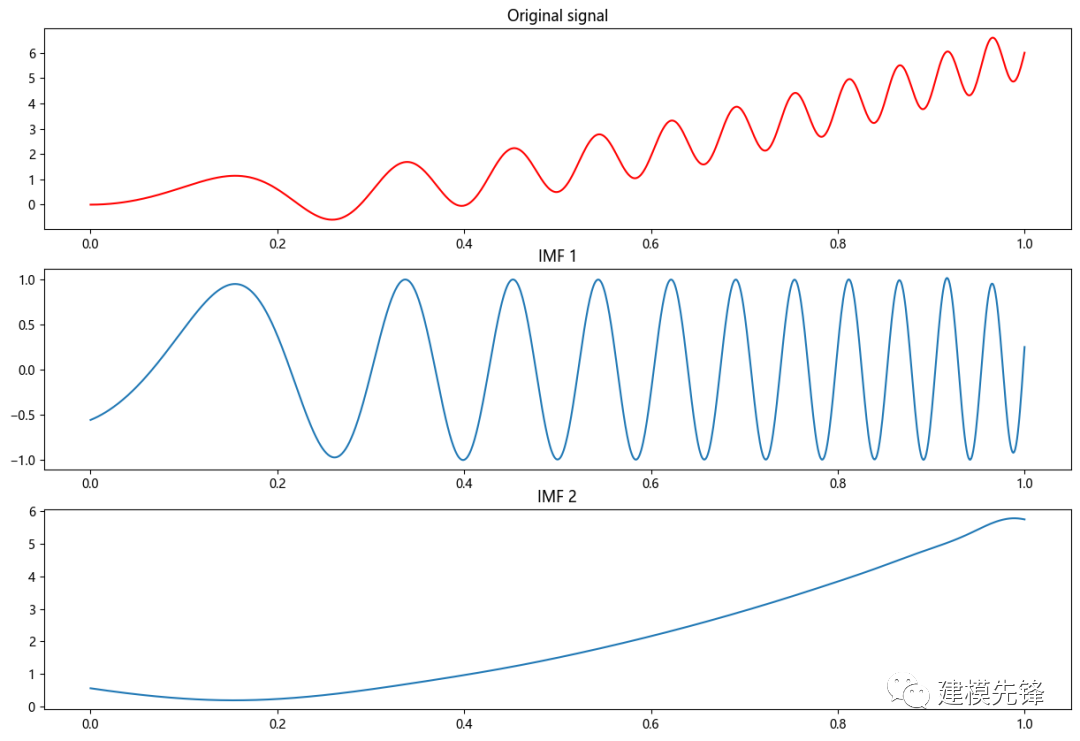
# 生成一個示例信號
t = np.linspace(0, 1, 1000)
s = np.sin(11*2*np.pi*t*t) + 6*t*t
# 創建 EMD 對象
emd = EMD()
# 對信號進行經驗模態分解
IMFs = emd(s)
# 繪制原始信號和每個本征模態函數(IMF)
plt.figure(figsize=(15,10))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(t, s, 'r')
plt.title("Original signal")
for num, imf in enumerate(IMFs):
plt.subplot(len(IMFs)+1, 1, num+2)
plt.plot(t, imf)
plt.title("IMF "+str(num+1))
plt.show()
2.2 軸承故障數據的分解
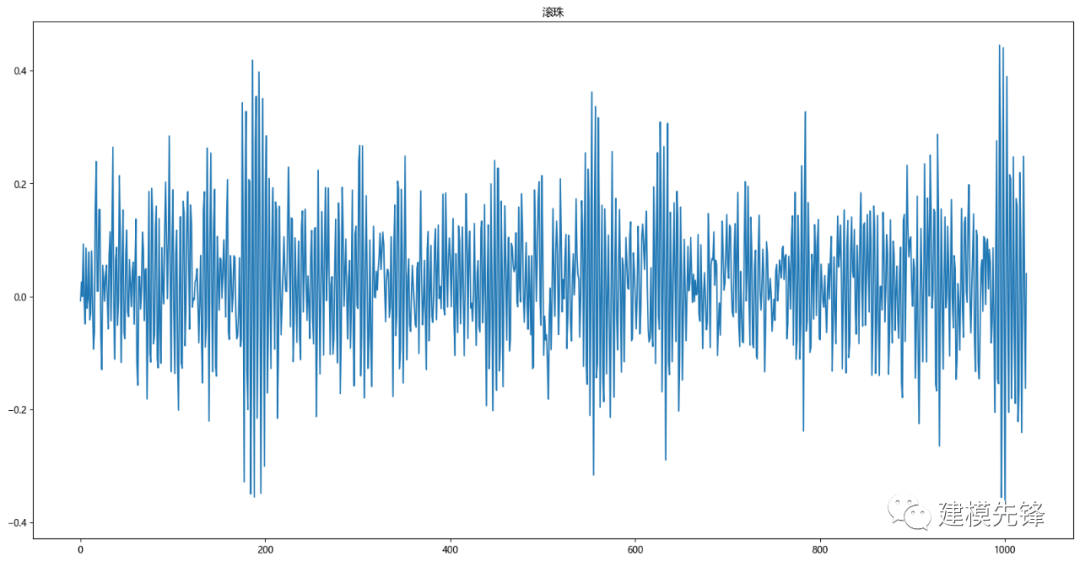
選擇 0.021英寸滾珠故障信號數據來做EMD分解
2.2.1 凱斯西儲大學軸承數據的加載
第一步,導入包,讀取數據
import numpy as np
from scipy.io import loadmat
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 讀取MAT文件
data = loadmat('21_2.mat') # 0.021英寸 滾珠
# 注意,讀取出來的data是字典格式,可以通過函數type(data)查看。
第二步,數據集中讀取 驅動端加速度數據,取一個長度為1024的信號進行后續觀察和實驗
# DE - drive end accelerometer data 驅動端加速度數據
data_list = data['X222_DE_time'].reshape(-1)
# 劃窗取值(大多數窗口大小為1024)
data_list = data_list3[0:1024]
# 進行數據可視化
plt.figure(figsize=(20,10))
plt.plot(data_list)
plt.title("滾珠")
plt.show()
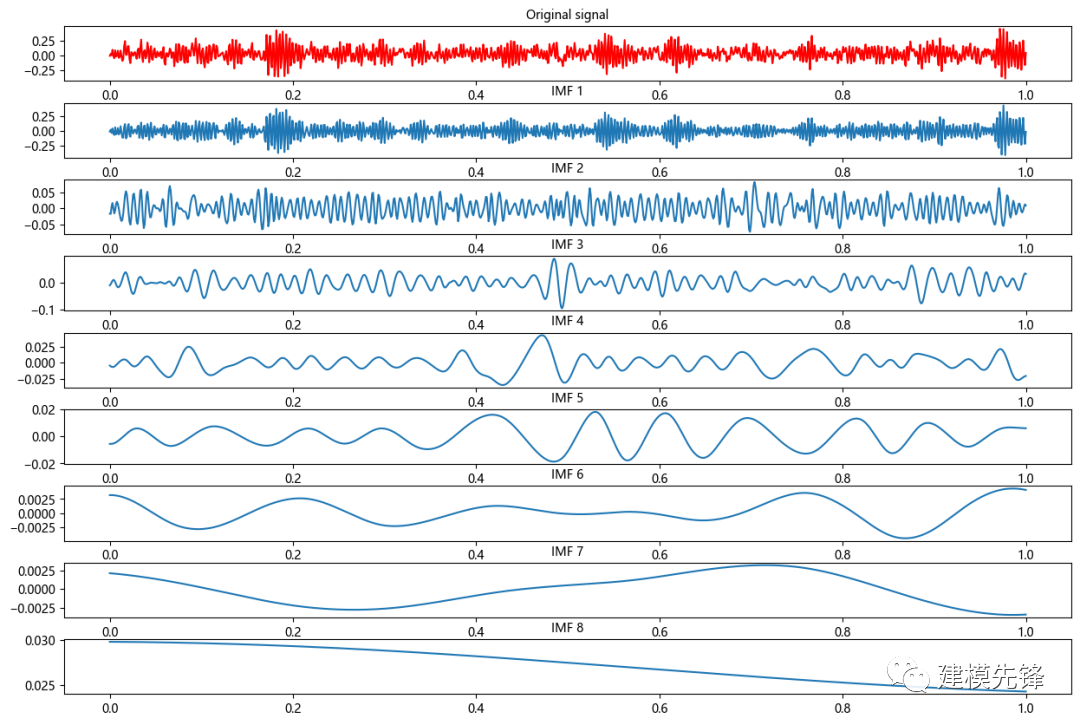
2.2.2 滾珠故障信號EMD分解
import numpy as np
import matplotlib.pyplot as plt
from PyEMD import EMD
t = np.linspace(0, 1, 1024)
data = np.array(data_list)
# 創建 EMD 對象
emd = EMD()
# 對信號進行經驗模態分解
IMFs = emd(data)
# 繪制原始信號和每個本征模態函數(IMF)
plt.figure(figsize=(15,10))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(t, data, 'r')
plt.title("Original signal", fontsize=10)
for num, imf in enumerate(IMFs):
plt.subplot(len(IMFs)+1, 1, num+2)
plt.plot(t, imf)
plt.title("IMF "+str(num+1), fontsize=10)
# 增加第一排圖和第二排圖之間的垂直間距
plt.subplots_adjust(hspace=0.4, wspace=0.2)
plt.show()
2.3 信號分量的處理
通過經驗模態分解(EMD)得到了信號的分量,可以進行許多不同的分析和處理操作,以下是一些常見的對分量的利用方向:
(1)信號重構:將分解得到的各個本征模態函數(IMF)相加,可以重構原始信號。這可以用于驗證分解的效果,或者用于信號的重建和恢復。
(2)去噪:對于復雜的信號,可能存在噪聲或干擾成分。通過分析各個IMF的頻率和振幅,可以識別和去除信號中的噪聲成分。
(3)頻率分析:分析每個IMF的頻率成分,可以幫助理解信號在不同頻率上的振蕩特性,從而揭示信號的頻域特征。
(4)特征提取:每個IMF代表了信號的局部特征和振蕩模式,可以用于提取信號的特征,并進一步應用于機器學習或模式識別任務中。
(5)信號預測:通過對分解得到的各個IMF進行分析,可以探索信號的未來趨勢和發展模式,從而用于信號的預測和預測建模。
(6)模式識別:分析每個IMF的時域和頻域特征,可以幫助對信號進行模式識別和分類,用于識別信號中的不同模式和特征。
(7)異常檢測:通過分析每個IMF的振幅和頻率特征,可以用于探測信號中的異常或突發事件,從而用于異常檢測和故障診斷。
在得到了信號的分量之后,可以根據具體的應用需求選擇合適的分析和處理方法,以實現對信號的深入理解、特征提取和應用。對于后續的研究,主要利用IMF分類來對故障信號做模式識別,即故障分類。
-
信號處理
+關注
關注
48文章
1046瀏覽量
103527 -
EMD
+關注
關注
1文章
43瀏覽量
20140 -
機器學習
+關注
關注
66文章
8459瀏覽量
133373 -
python
+關注
關注
56文章
4812瀏覽量
85273 -
頻率分析
+關注
關注
0文章
4瀏覽量
4984
發布評論請先 登錄
相關推薦
Python軸承故障診斷—基于EMD-CNN的故障分類

基于labview的軸承故障診斷與健康監測
電機軸承故障診斷與分析
葉片的故障診斷和模態分析
基于EMD和SVM的柴油機氣閥故障診斷

基于CUDA加速的高速振動信號故障診斷方法

軸承故障診斷方法





 工商網監
工商網監
評論