 生成式AI,如何從研究里“掘金”?
生成式AI,如何從研究里“掘金”?
導語:在眾多被賦能的行業中,AI+投研,成為了一個炙手可熱的賽道。
準確預測未來,并在關鍵時刻扼住命運的咽喉,做出正確的決定。
這是無數人夢寐以求的情景。
得益于算法的進步,這樣的現實,正離人類正越來越近。
2012年,美國康涅狄格大學生態學和數學教授彼得·圖爾欽(Peter Turchin)在《和平研究雜志》上發表了一篇研究論文,提出一個不祥的預測:美國將在2020年迎來社會動蕩的“高峰”。
結果,美國真在2020年迎來了“大亂”。
疫情、種族沖突、金融危機,將整個社會攪成了一鍋粥。
那這位叫圖爾欽的教授,為何預測得這么準?
原因就在于,他本人是一個“數據史學”的忠誠信徒。
所謂“數據史學”,簡單來說,就是搜集歷史上的各種關鍵數據,如人口、收入水平、暴力事件的頻次等等,之后通過大數據+機器學習的方式,對其進行建模、分析,從中預測出未來的趨勢。
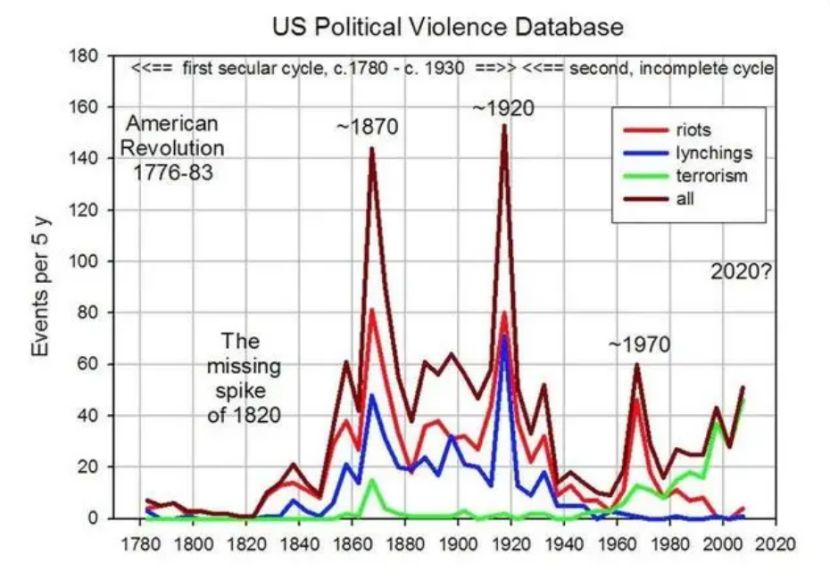
用這樣的分析方式,圖爾欽甚至算出,平均50年,美國就會經歷一次“動亂周期”。
除了用來分析“天下興亡”之外,這樣的技術思路,也擴展了一個需求龐大的賽道——機器(AI)數據分析。
根據MarketsandMarkets的報告,全球機器數據分析市場規模在2020年達到了14.8億美元,預計到2025年將增長至45.4億美元,期間年復合增長率(CAGR)為28.3%。
而在眾多被賦能的行業中,AI+投研,成為了一個炙手可熱的賽道。
數據煉金術
2023年至今,全市場一共開了52,400場投研會議,差不多每天200場。在信息爆炸的年代,信息降噪、提純成為投研人士的新剛需。
為此,在互聯網時代的早期,就有不少投研機構、平臺開始用數據模型的方式,來分析龐雜的金融數據。
其中,最著名的就是彭博社推出的Bloomberg Terminal(彭博終端),這是一個為金融專業人士提供實時金融數據、新聞和分析的平臺。
通過預構建的金融模型和指標,例如財務比率、估值模型、風險分析模型,以及各種圖表和可視化工具,Bloomberg Terminal可以分析來自300多個交易所和500多個數據提供商的數據,從而幫助投資者實時了解市場動態,制定投資策略。
除此之外,S&P Capital IQ也是基于類似的技術思路研發的分析工具。
在提供了各種預制的財務模型模板,例如貼現現金流(DCF)模型、比較公司分析模型之外,用戶還可以利用插件直接在Excel中調用S&P Capital IQ的數據,利用Excel的公式和功能進行深入的財務分析。
從功能和分析方式上來說,這些平臺大多都是以預設的模型、算法,結合財務報表、歷史交易數據等結構化數據,對金融市場的走向進行分析。
盡管這些終端都在努力整合、處理大量金融數據,但在技術層面上,其仍存在著各種局限,而其中最大的局限之一,就是對非結構化數據(如新聞、研究報告等)相對薄弱的處理能力。
對于金融數據來說,結構性的數據(如財務報表、交易記錄等),只是浮在海面上的一小層冰山。而更多的非結構性文本(新聞、社交網絡信息),才是隱藏在海面之下的,價值更大的冰山。
這是因為,隨著互聯網的不斷普及,大量的文本信息被生成并存儲在網絡空間中。
根據皮尤研究中心(Pew Research Center)的一項研究,從2008年到2018年,全球金融新聞報道的數量增長了約40%。這些報道涵蓋了股票、債券、外匯等各種市場動態。
然而,想要挖掘這些文本數據組成的“金山”,就需要運用如自然語言處理、大數據分析等先進的技術,才能從非結構性的文本中,提取有價值的信息。
為此,不少以自然語言處理技術(NLP)為核心的投研AI紛紛涌現,由此開啟了金融數據分析的一個新階段。
化簡為繁
當下的大模型+金融賽道,入局者甚多。
然而,在NLP技術沒有絕對性差距的情況下,要想在以自然語言處理技術為核心的投研AI中脫穎而出,高質量、多樣化且實時更新的金融數據源,就成了競爭中的關鍵。
因為數據的質量和多樣性,將直接影響到分析結果的準確性和可靠性。
而在這方面,熵簡科技,試圖站到行業的前列。
“熵”是熱力學中描述系統混亂、無序的程度。
“熵簡” 寓意以技術手段簡化業務數據的復雜度,用“化繁為簡”的方式,幫助用戶在數據中獲得洞察。
而其研發的新一代智能引擎AlphaEngine,就是這種理念的最佳體現。
AlphaEngine不僅聚合了海量優質商業情報數據源,內涵三大商業數據庫,并且深度融合AI能力,能夠幫助用戶在海量數據中快速獲取洞察。
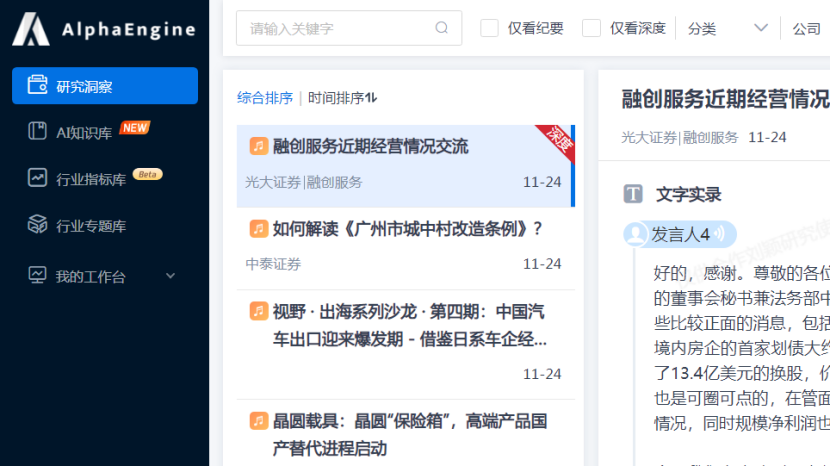
具體來說,AlphaEngine內涵的三大商業數據庫,分別是會議紀要數據庫、研究報告數據庫、行業經濟數據庫。
其中的會議紀要數據庫,不僅會提供全面的會議紀要數據庫,包括主流券商電話會議、調研會議紀要、專家訪談紀要等一手研究資料。
而研究報告數據庫,則了涵蓋主流券商研報、產業咨詢報告、外資券商研究報告等專業投研資料。具有多種篩選器,方便用戶定位所需資料。
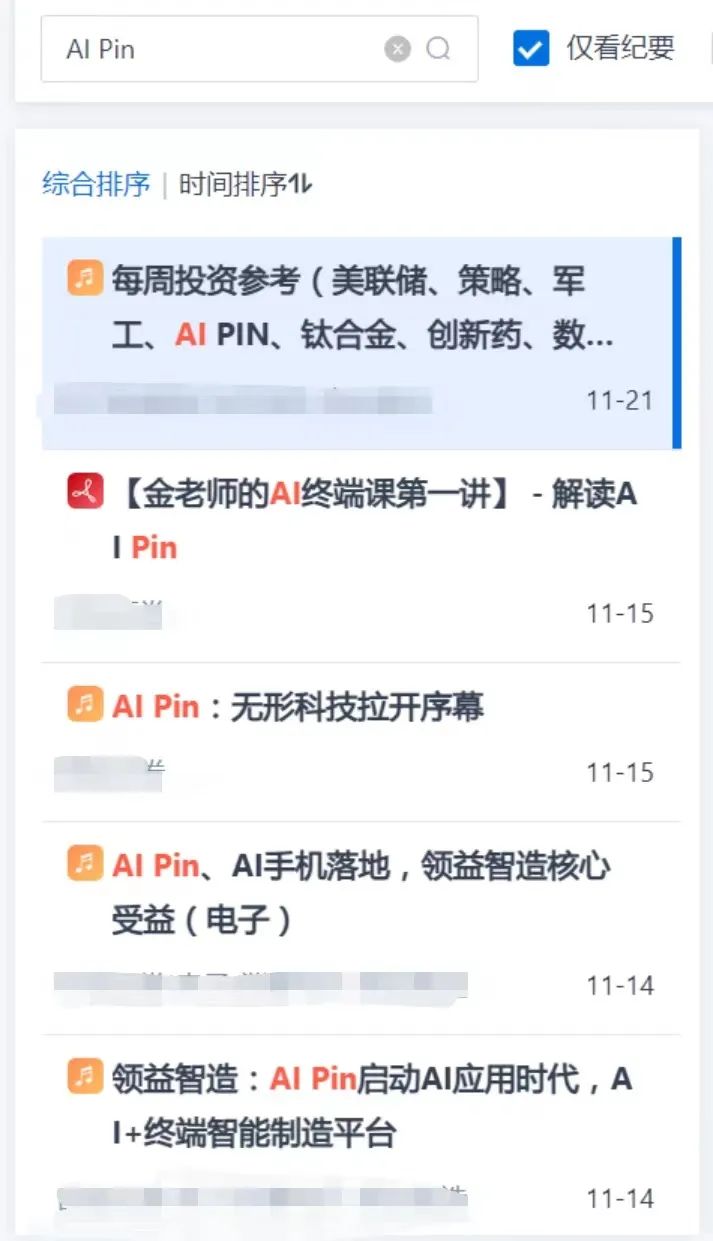
同時,為了使用戶在大量數據中,高效找到需要的信息,AlphaEngine提供了多種篩選器,通過使用高效的信息檢索技術和數據挖掘方法,使用戶能夠輕松地在大量數據中找到所需資料。
在AlphaEngine中,以NLP技術為核心的生成式AI,被用于文本預處理、查詢處理、語義理解等環節。通過使用NLP技術,AlphaEngine能夠更好地理解用戶查詢和文檔內容,從而提高信息檢索的準確性和效率。
而在文本摘要、總結方面,熵簡科技通過FinGPT大模型,實現了自動化生成AI摘要,從而讓用戶能方便、快速地獲取會議中的關鍵信息。
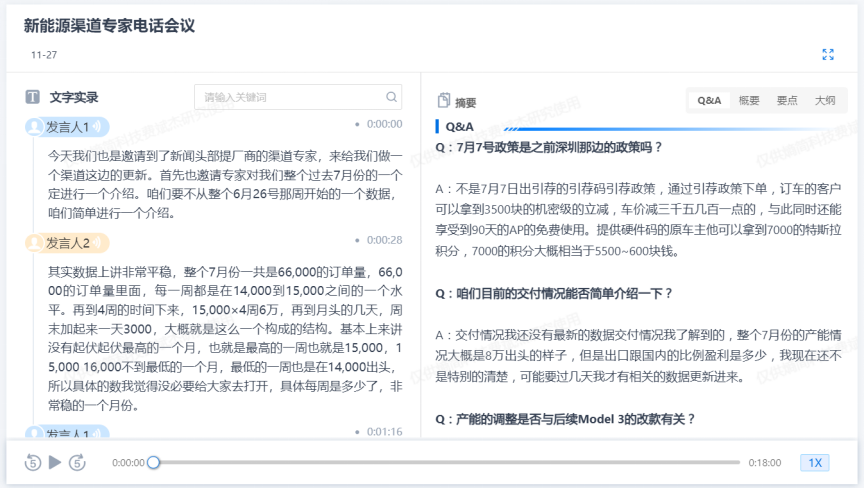
在瀏覽行業報告時,AlphaEngine內嵌的生成式AI,會自動將報告中的要點、關鍵信息進行總結、提煉,在節約了用戶視角的同時,從而讓用戶在整體上對報告的核心內容有了清晰的認知。
除此之外,針對一些較為重要的會議、演講,AlphaEngine也能將會議錄音轉錄成文本,并且形成會議摘要,并支持定位播放及摘要溯源功能,方便用戶快速獲取會議關鍵信息。

AlphaEngine除了提供三方海量會議紀要外,也可以用于構建屬于自己的AI知識庫。
在【知識庫】模塊中,可以整理任何類型的研究資料,大模型會自動進行音頻轉寫及全文摘要,包括但不限于PDF、Office文檔、音頻、視頻等格式的文件。
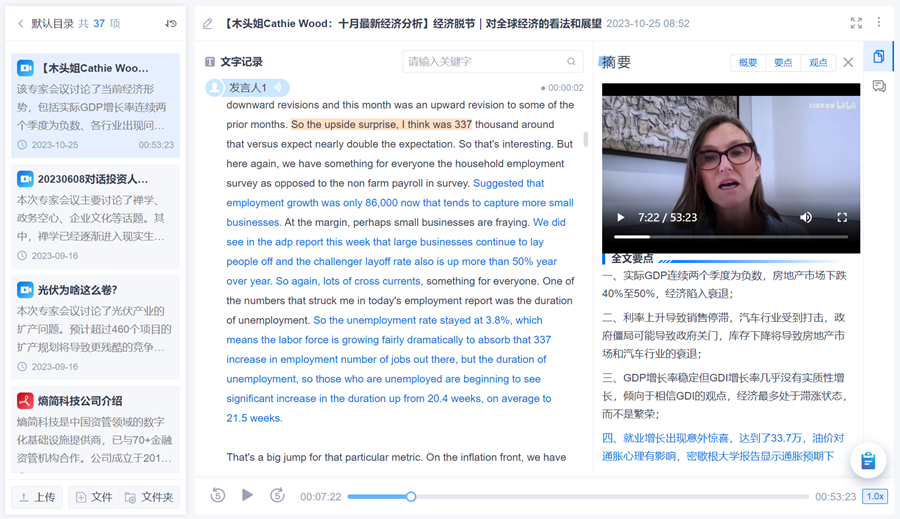
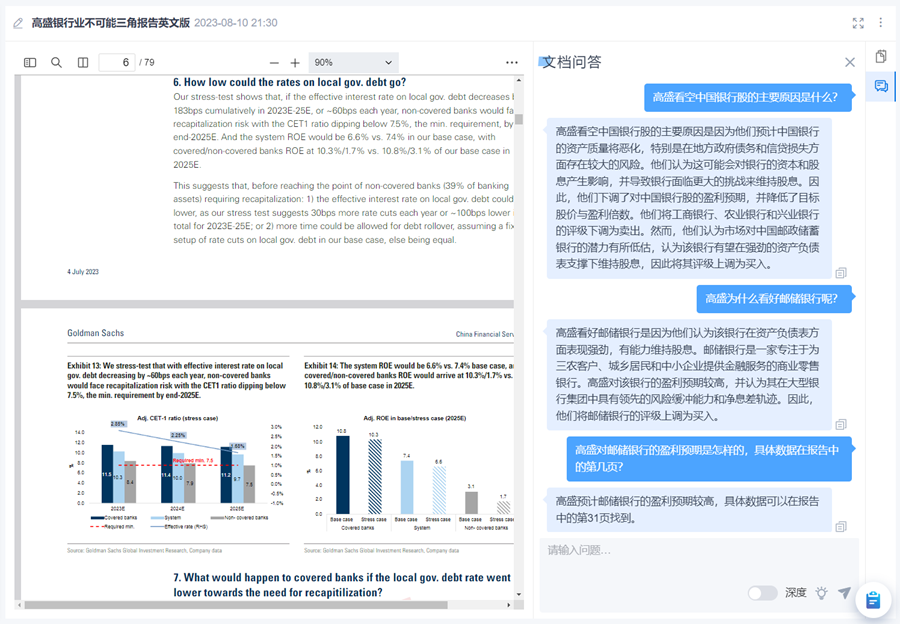
也可以對任意資料進行提問,讓大模型根據資料中的信息做出專業解答。
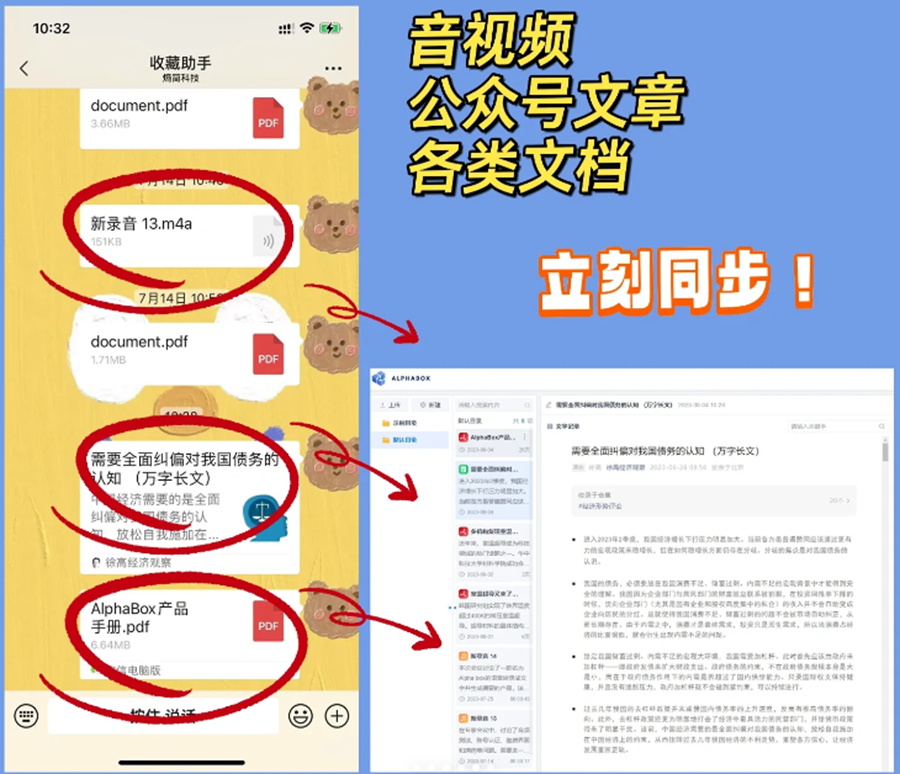
對于手機上發現的優質研究資料,只需把這篇文章轉發到微信助手,AlphaEngine會將文章自動同步至知識庫中存檔,可以在【個人中心】-【微信助手】中進行設置。
上述的技術特點,展現了熵簡在處理非結構性金融數據時的巨大優勢。
隨著生成式AI的重大進展和衍生應用帶來的領域拓寬,可以想見,未來熵簡也將在AI+數據分析的賽道上,研發出更多有價值的技術或產品。
而這種基于AI的數據分析技術,也是當下處于飛速變化中的社會所期待和需要的。
畢竟,在劃時代的機遇來臨時,唯有敏銳地捕捉變化,洞察先機,才能找到在新時代的生存發展之道。
-
AI
+關注
關注
87文章
30985瀏覽量
269271 -
數據模型
+關注
關注
0文章
49瀏覽量
10032 -
生成式AI
+關注
關注
0文章
504瀏覽量
481
原文標題:生成式AI,如何從研究里“掘金”?
文章出處:【微信號:alpworks,微信公眾號:阿爾法工場研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
STAR AI進軍美股科技星智能領跑生成式AI賽道

亞馬遜云科技助力Shulex打造生成式AI應用
2024學習生成式AI的最佳路線圖

如何用C++創建簡單的生成式AI模型
生成式AI的基本原理和應用領域


生成式 AI 進入模型驅動時代

Bria利用NVIDIA NeMo和Picasso為企業打造負責任的生成式AI
NVIDIA生成式AI研究實現在1秒內生成3D形狀

生成式 AI (3/4):如何緩解人才短缺,促進芯片設計多元化?





 工商網監
工商網監
評論