 風靡萬千軟件開發者:揭秘華為研發代碼大模型是如何實現的?
風靡萬千軟件開發者:揭秘華為研發代碼大模型是如何實現的?
作者 | 陳泰紅
秉持“自己的降落傘,自己先跳”的原則,由公司裝備部門牽頭,攜手華為云PaaS作為基礎能力提供方,與公司各產品線共同研發面向產業的代碼大模型。在研發過程中,我們已取得初步成果,為了鞏固各產品線的代碼生成探索經驗,我們將產品線研發成果迅速投入業務應用。在此基礎上,我們總結了前期的方法和經驗,期待更多產業的加入與交流,共同推動產業代碼大模型的演進與推廣落地。
本文深入探討了當前研發大模型在實際產品中代碼生成能力所面臨的挑戰,闡述了探索的總體思路、數據標準與語料層次、演進策略以及模型訓練方案設計。同時,還介紹了RAG方案設計以及某產品線Dopra在真實場景中的應用,并總結了一套可快速復制的方法論。最后,對未來發展趨勢進行了討論:研發大模型是否有可能取代程序員?
一、產業研發大模型面臨的挑戰
華為擁有超過10萬名代碼開發者,每天新增代碼行數達千萬級別。在這種情況下,提高開發過程的效率變得至關重要。研發過程涵蓋了需求理解、系統分析與設計、軟件開發(包括手工編寫代碼、測試用例、代碼檢視)、系統集成與驗證以及研發維護等環節。在整個研發過程中,編寫代碼的部分大約占據20%的比重。在人工智能大模型的時代,為了提升研發效率,利用大模型輔助生成代碼的需求已經迫在眉睫。
在與產品線領域代碼專家進行交流時,我們發現,由于產業數據未納入訓練過程,開源代碼大模型在研發階段基本上無法發揮作用。在產業領域,我們面臨以下挑戰:
首先,信息通信技術(ICT)專業領域知識繁雜且多變,開源模型未系統學習過程領域知識和系統設計等方面,因此難以處理復雜任務。
其次,華為代碼倉庫中存在數十萬自定義的數據類型、函數API和變量引用,這些代碼的語義復雜性較高。由于公司部分產業導向代碼自注釋,結構類型和成員、函數、變量缺少足夠的人工注釋。
此外,代碼具有單一性,不同產品之間的代碼關聯性較小,導致代碼語料數據泛化性不足。同時,文本與代碼關聯的語料數據在質量和數量方面都存在不足。華為嵌入式系統主要基于C/C++開發,C/C++代碼具有固有特征,如頭文件機制使類型和函數邏輯實現分離,狀態空間更為龐大。
最后,代碼依賴鏈路較長,涉及Void *、指針、結構體、宏定義、頭文件等多種元素。項目級的跨文件和多層嵌套導致上下文依賴鏈路較長,從而降低了代碼生成的準確性。
根據實地考察的業務需求以及公司研發戰略目標,我們將重點關注具有業務價值的場景。目前,研發大模型項目組正致力于攻克代碼輔助生成(C/C++/Java/Python)的難題,以構建軟件領域的代碼大模型,從而推動軟件開發領域的新范式。
二、研發大模型構建探索總體思路
為了提高研發迭代的反饋效率,華為云PaaS大模型團隊制定了5項數據標注與清洗規范、以及5個腳本工程項目。
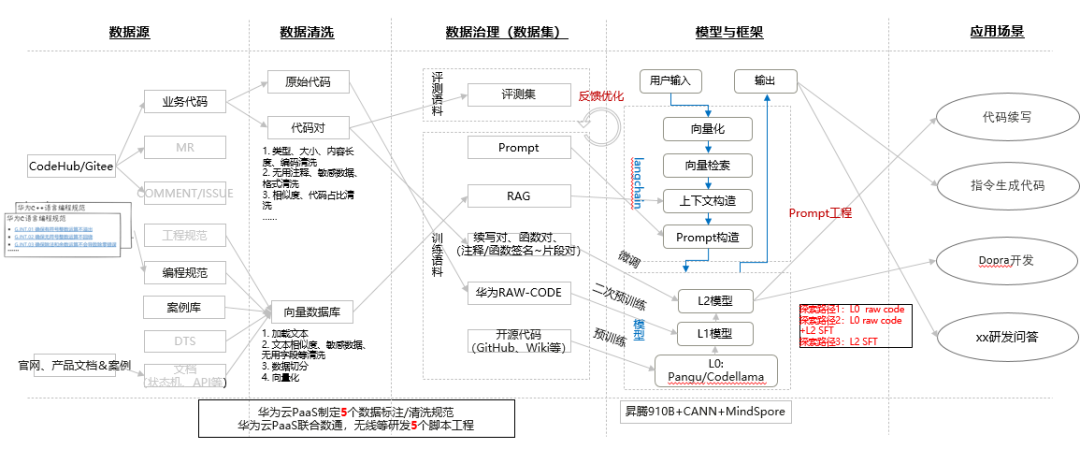
圖1 研發大模型探索的總體思路
在整個流程中,從原始訓練語料的準備與清洗、SFT語料的提取,到訓練、評估和部署的全自動化操作,華為云PaaS團隊已經制定了5個數據標注和清洗規范。在訓練流水線過程中,涉及到的5個腳本工具(包括清洗工具、SFT提取工具、訓練腳本工程、部署腳本工程和IDE插件)也已經得到了產品線業務專家的認可和落實。這些措施顯著提高了大模型研發的效率。
三、那些數據應該參與研發大模型的訓練?
數據是大模型研發的基石,其質量直接影響到模型的最高性能。若大模型未經過專業領域數據的訓練,就如同“文科生學理科”。針對產業特有的數據特征和挑戰,我們首先對產業數據的訓練配方表進行了梳理。明確了訓練語料的范圍、目標、場景、數據標準、處理規則、處理工具、試點產業以及質量評價等相關信息。

圖2 研發大模型語料層次表
L0 開源階段
對 GitHub、Stack Overflow 等高質量數據進行清洗。
L1 RawCode 階段
清洗華為語料庫中的 30 億 tokens,涉及公司 10 余個產品線,以增強華為業務代碼的基礎能力。
L2 領域數據-SFT 階段
包括代碼地圖、項目級的跨文件信息以及工程規范。通過 SFT 指令微調,利用跨文件上下文信息和領域專業知識,解決生成代碼中的幻覺問題。
RAG階段
RAG(Retrieval Augmented Generation)階段,在 IDE 項目文件中檢索跨文件信息;在向量數據庫中檢索 API 接口說明、工程規范信息。根據 prompt 模板,將用戶的需求描述與上述檢索信息拼接成完整的 prompt,輸入給大模型。
由于 L1/L2 模型訓練需要一定周期,業務實踐中項目組先使用 RAG 語料驗證效果,逐步探索 L2 SFT/L1 Raw Code 匹配任務,以提升模型的理解能力和研發效率。
單一的 Prompt 工程/RAG 在一定程度上可以讓模型接觸到專業領域知識,增強專業表達。然而,更為關鍵的是讓專業領域知識參與到模型訓練過程中。
四、研發大模型整體演進策略與方案設計
為了提高大模型研發的效率,我們將整個研發過程分為兩個階段進行迭代和優化:
數據準備階段
首先,我們對各產品線的代碼倉庫進行評估,挑選出高質量的代碼倉庫。接著,根據華為云PaaS研發項目組制定的五項數據標注和清洗規范對代碼進行清洗。在《訓練&推理語料層次表》的基礎上,構建代碼地圖,并通過人工抽查與腳本校驗自動化執行。最后,對訓練數據進行格式統一,生成訓練集、客觀評測集和主觀評測集。
訓練和評估階段
在該階段中,我們針對第一階段所準備的訓練數據,在ModelArts平臺上啟動訓練任務。通過每隔x個epoch生成的檢查點(checkpoint)來進行訓練迭代。在此基礎上,我們進行批量模型評估,并將模型部署在Alpha環境中,以便用戶進行評估和使用。
在Alpha環境中,IDE插件的上下文提取和RAG檢索兩個過程被巧妙地隱藏起來。IDE需要在項目層面跨文件進行上下文分析,從而提取當前編輯區域用戶關注的跨文件上下文信息,并在prompt工程中進行組裝。同時,RAG會根據用戶的輸入和意圖,檢索業務知識向量庫。在prompt工程中,上下文信息和業務知識將按照重要性進行排序,然后送入代碼大模型進行推理。生成的代碼經過后處理后,最終呈現在IDE用戶界面上。
在研發過程中,數據準備以及模型的訓練和評估并非一蹴而就,而是需要經過多次迭代和驗證。訓練和評估過程中出現的現象和問題可以為數據迭代過程提供反饋。兩個階段緊密銜接,共同推進以實現最終的優化目標。
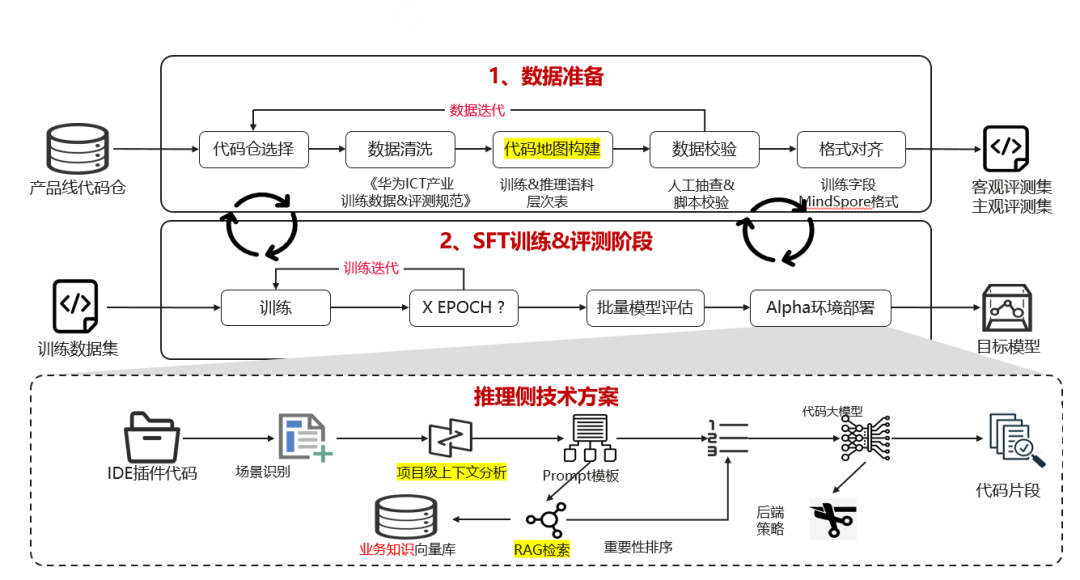
圖3 研發大模型整體演進策略與方案設計
五、RAG:研發大模型的最后“一公里”
模型訓練在一定程度上緩解了領域知識匱乏的問題(例如,避免使用不存在的數據對象和API,從而減少編譯錯誤和運行錯誤)。然而,由于模型更新迭代周期較長且領域范圍廣泛,在實際產業應用中,仍需結合領域相關的《xx使用手冊》、《xx白皮書》和《xx使用指南》等資料,以進一步減輕代碼生成中的幻覺問題,提高知識的可追溯性和解釋性。
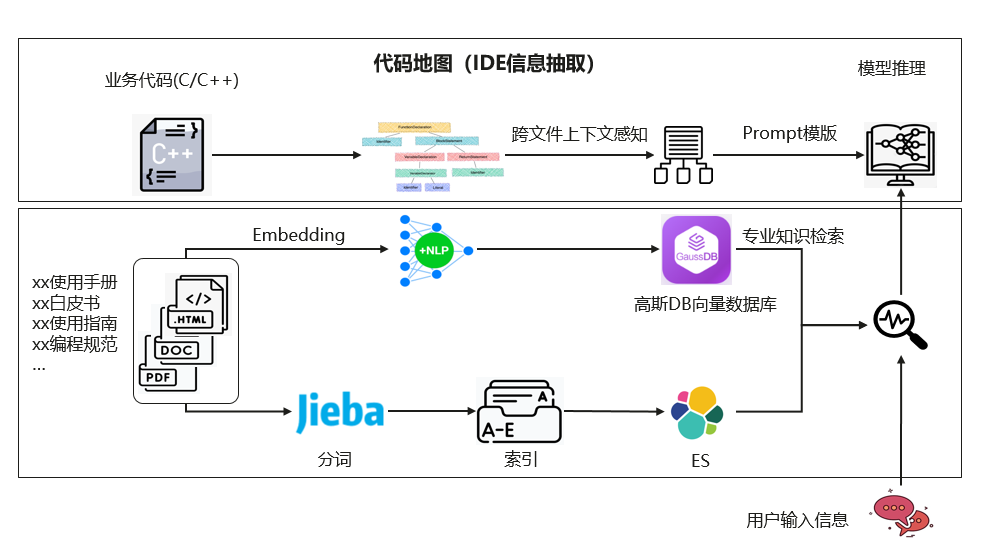
圖4 RAG整體框架圖
RAG的設計方案和實現形式多樣,我們的RAG方案主要關注自動化信息抽取和項目級上下文感知能力。
業務知識廣泛分布于HTML、PDF、DOC、Word等多種形式,且范圍廣泛且接口不統一。為解決這一問題,項目組結合知識圖譜和大模型技術,實現結構化、半結構化和非結構化信息的抽取,無需人工干預,即可生成低成本且高質量的知識。
自動化信息抽取同時解決了知識增量刷新機制的問題:通過工程化方法,克服了LLM知識更新的難題。將業務領域知識、華為編程框架、工程規范等模型所不具備的能力與模型相協同。在項目級上下文感知方面,基于項目靜態結構、倉庫演化歷史以及開發者實時行為,精確檢索與代碼生成任務最相關的項目上下文。
以某產品線Dopra開發場景為例,我們整理了開發手冊、線下文檔、社區平臺以及開發者經驗等數據,匯總成Dopra開發的領域知識,并將這些知識向量化,存儲到向量數據庫中。當用戶輸入需求任務后,通過RAG能力,我們可以獲取與該任務相關的開發經驗信息。將這些信息通過“領域經驗”提示模板輸入給大模型,從而顯著提高大模型輸出代碼的正確性。
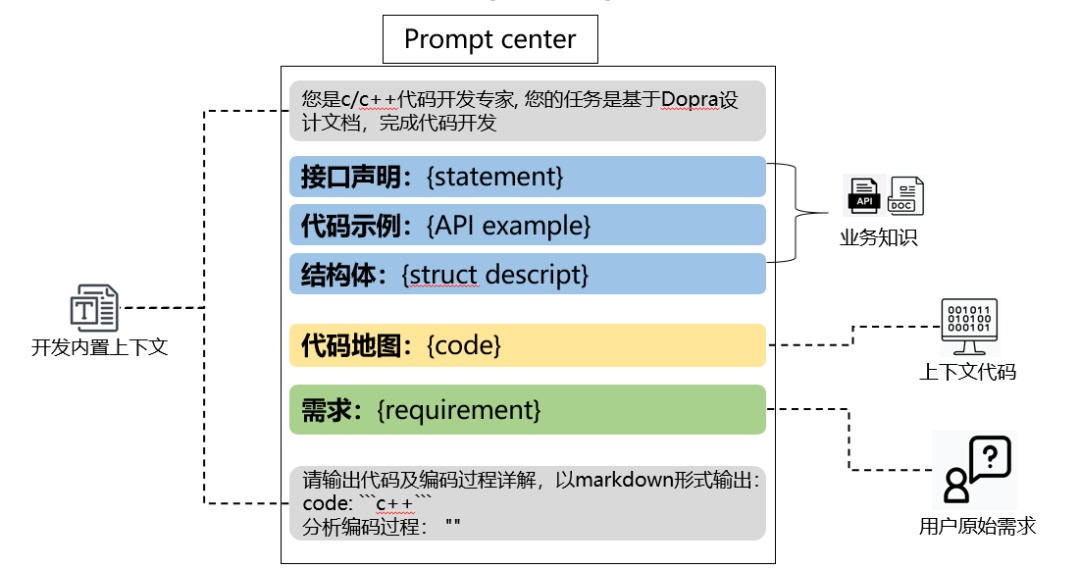
圖5 RAG方案中使用的Prompt版本示例
六、研發大模型:是否會取代程序員?
許多程序員都關心一個問題:研發大模型是否會最終取代程序員?經過調查,我們發現了一些有趣的觀點。
1. 程序員的需求各異。在對產品線專家進行調研時,我們發現他們對業務非常熟悉,主要關注行級續寫或代碼塊續寫,目的是減少敲擊鍵盤的時間。他們期望模型能順應開發思路給出提示,輔助編碼,而非完全替代開發。
2. AI編程具有很高的特殊性。
精確敏感性:一個字符的錯誤可能導致代碼不可用,需要人工干預。 遠程敏感性:全局變量、父類信息、項目級跨文件信息等大量遠程(非IDE插件打開的當前文件信息)對語義影響很大。庫敏感性:調用API庫的語句對函數的語義影響非常大。
3. AI目前的定位是助手,即開發人員的智能助手。AI助手并不會替代程序員的思考;它們擅長處理重復性高、機械性的任務,幫助程序員聚焦高價值點,提升專業方向的能力。然而,程序員仍需要掌握輔助駕駛的方向盤。
大模型的使用對程序員提出了更高的要求。簡單重復的工作可以交給大模型,但更高維度的工作,如代碼調試、通信鏈路聯調、項目級別的功能實現等,可能需要經驗豐富的架構師和資深程序員來把控。
總而言之,研發大模型將有效提升研發效率,使程序員能夠更加專注于深入思考,從而減少重復性和高頻率的工作負擔。
文章來自 PaaS技術創新Lab,PaaS技術創新Lab隸屬于華為云,致力于綜合利用軟件分析、數據挖掘、機器學習等技術,為軟件研發人員提供下一代智能研發工具服務的核心引擎和智慧大腦。我們將聚焦軟件工程領域硬核能力,不斷構筑研發利器,持續交付高價值商業特性!加入我們,一起開創研發新“境界”!
詳情歡迎聯系:
mayuchi1@huawei.com;bianpan@huawei.com
原文標題:風靡萬千軟件開發者:揭秘華為研發代碼大模型是如何實現的?
文章出處:【微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
-
華為
+關注
關注
216文章
34417瀏覽量
251526
原文標題:風靡萬千軟件開發者:揭秘華為研發代碼大模型是如何實現的?
文章出處:【微信號:華為DevCloud,微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
我國軟件開發者數量超過940萬
華為云軟件開發生產線(CodeArts)11 月新功能特性
云端AI開發者工具怎么用
華為云軟件開發生產線(CodeArts)10 月新功能特性
HarmonyOS NEXT應用元服務開發Intents Kit(意圖框架服務)事件推薦開發者測試
華為云軟件開發生產線(CodeArts)9 月新功能特性

中軟國際亮相華為開發者大會2024
【《軟件開發珠璣》閱讀體驗】+ 心得
華為云開發者桌面全新發布 CodeArts IDE for Python,極致優雅云原生開發體驗
華為云 CodeArts Snap,揭開智能研發新篇章
華為宣布HarmonyOS NEXT鴻蒙星河版開發者預覽面向開發者開放申請





 工商網監
工商網監
評論