") 人工智能中文本分類(lèi)的基本原理和關(guān)鍵技術(shù)
人工智能中文本分類(lèi)的基本原理和關(guān)鍵技術(shù)
在本文中,我們?nèi)嫣接懥宋谋痉诸?lèi)技術(shù)的發(fā)展歷程、基本原理、關(guān)鍵技術(shù)、深度學(xué)習(xí)的應(yīng)用,以及從RNN到Transformer的技術(shù)演進(jìn)。文章詳細(xì)介紹了各種模型的原理和實(shí)戰(zhàn)應(yīng)用,旨在提供對(duì)文本分類(lèi)技術(shù)深入理解的全面視角。
一、引言
文本分類(lèi)作為人工智能領(lǐng)域的一個(gè)重要分支,其價(jià)值和影響力已經(jīng)深入到我們?nèi)粘I畹母鱾€(gè)角落。在這個(gè)數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,文本分類(lèi)不僅是機(jī)器學(xué)習(xí)和深度學(xué)習(xí)技術(shù)的集中展示,更是智能化應(yīng)用的基礎(chǔ)。
文本分類(lèi)的重要性
文本分類(lèi)的核心是將文本數(shù)據(jù)按照其含義或?qū)傩苑峙涞筋A(yù)定義的類(lèi)別中。這聽(tīng)起來(lái)簡(jiǎn)單,但在實(shí)際操作中卻極具挑戰(zhàn)性。為什么文本分類(lèi)如此重要?其實(shí),無(wú)論是個(gè)人用戶還是大型企業(yè),我們都在日常生活中與海量的文本數(shù)據(jù)打交道。例如,電子郵件自動(dòng)分類(lèi)系統(tǒng)可以幫助我們區(qū)分垃圾郵件和重要郵件,社交媒體平臺(tái)利用文本分類(lèi)來(lái)過(guò)濾不恰當(dāng)?shù)膬?nèi)容,而在商業(yè)智能中,文本分類(lèi)幫助企業(yè)從客戶反饋中提取有價(jià)值的洞察。
技術(shù)發(fā)展歷程
文本分類(lèi)技術(shù)的發(fā)展經(jīng)歷了從簡(jiǎn)單的基于規(guī)則的方法到復(fù)雜的機(jī)器學(xué)習(xí)算法,再到今天的深度學(xué)習(xí)模型的演變。在早期,文本分類(lèi)依賴于專家系統(tǒng)和簡(jiǎn)單的統(tǒng)計(jì)方法,但這些方法往往受限于規(guī)模和靈活性。隨著機(jī)器學(xué)習(xí)的發(fā)展,尤其是支持向量機(jī)(SVM)和隨機(jī)森林等算法的應(yīng)用,文本分類(lèi)的準(zhǔn)確性和適應(yīng)性有了顯著提高。進(jìn)入深度學(xué)習(xí)時(shí)代,卷積神經(jīng)網(wǎng)絡(luò)(CNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)等模型極大地提高了文本分類(lèi)的性能,特別是在處理大規(guī)模和復(fù)雜的數(shù)據(jù)集時(shí)。
現(xiàn)代應(yīng)用實(shí)例
在現(xiàn)代應(yīng)用中,文本分類(lèi)技術(shù)已成為許多行業(yè)不可或缺的部分。例如,在金融領(lǐng)域,文本分類(lèi)被用于分析市場(chǎng)趨勢(shì)和預(yù)測(cè)股市動(dòng)態(tài)。金融分析師依賴于算法從新聞報(bào)道、社交媒體帖子和財(cái)報(bào)中提取關(guān)鍵信息,以做出更明智的投資決策。此外,醫(yī)療保健行業(yè)也在利用文本分類(lèi)技術(shù)來(lái)處理病歷報(bào)告,自動(dòng)識(shí)別疾病模式和病人需求,從而提高診斷的準(zhǔn)確性和效率。
通過(guò)這些例子,我們可以看到,文本分類(lèi)不僅是技術(shù)的展示,更是現(xiàn)代社會(huì)運(yùn)作和發(fā)展的關(guān)鍵部分。隨著技術(shù)的不斷進(jìn)步和應(yīng)用領(lǐng)域的不斷拓展,文本分類(lèi)的重要性和影響力只會(huì)繼續(xù)增長(zhǎng)。
二、文本分類(lèi)基礎(chǔ)
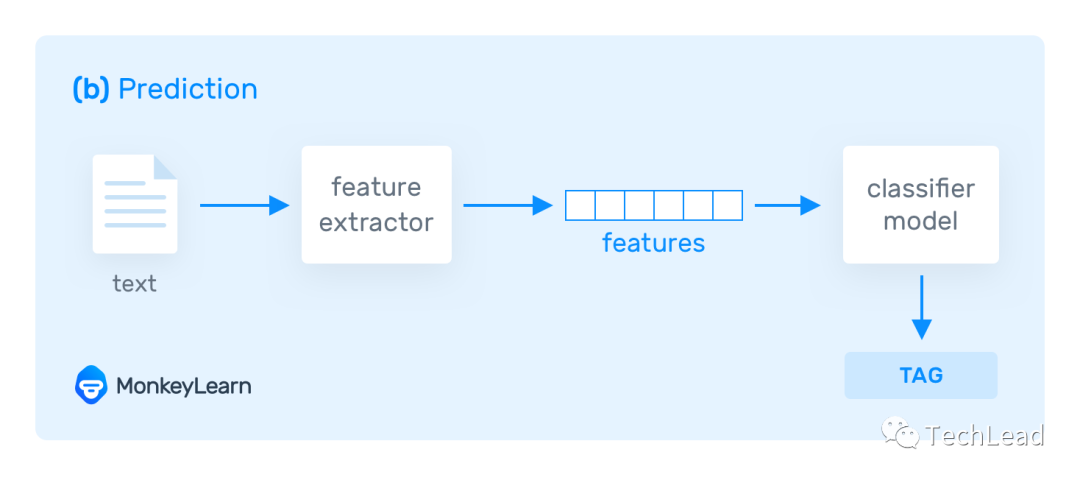
文本分類(lèi)是人工智能和自然語(yǔ)言處理(NLP)領(lǐng)域的一個(gè)核心任務(wù),涉及到理解和處理自然語(yǔ)言文本,將其分類(lèi)到預(yù)定義的類(lèi)別中。這一任務(wù)的基礎(chǔ)是理解文本的含義,并據(jù)此做出決策。
文本分類(lèi)的定義和目的
簡(jiǎn)單來(lái)說(shuō),文本分類(lèi)是將文本數(shù)據(jù)(如文檔、郵件、網(wǎng)頁(yè)內(nèi)容等)自動(dòng)分配到一個(gè)或多個(gè)預(yù)定義類(lèi)別的過(guò)程。這個(gè)過(guò)程的目的在于簡(jiǎn)化信息處理,提高數(shù)據(jù)組織和檢索的效率,以及支持更復(fù)雜的信息處理任務(wù),如情感分析或主題識(shí)別。
文本分類(lèi)的關(guān)鍵要素
1. 預(yù)處理
重要性:預(yù)處理是文本分類(lèi)的首要步驟,涉及清洗和準(zhǔn)備原始文本數(shù)據(jù)。
方法:包括去除噪音(如特殊字符、無(wú)關(guān)信息)、詞干提取、分詞等。
2. 特征提取
概念:將文本轉(zhuǎn)化為機(jī)器可理解的形式,通常是數(shù)值向量。
技術(shù):傳統(tǒng)方法如詞袋模型(Bag of Words)和TF-IDF,以及現(xiàn)代方法如詞嵌入(Word Embeddings)。
3. 分類(lèi)算法
多樣性:文本分類(lèi)可采用多種機(jī)器學(xué)習(xí)算法,包括樸素貝葉斯、決策樹(shù)、支持向量機(jī)等。
發(fā)展:深度學(xué)習(xí)方法如卷積神經(jīng)網(wǎng)絡(luò)(CNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)為文本分類(lèi)帶來(lái)了革命性的改進(jìn)。
文本分類(lèi)的應(yīng)用領(lǐng)域
文本分類(lèi)廣泛應(yīng)用于多個(gè)領(lǐng)域,包括:
垃圾郵件檢測(cè):自動(dòng)識(shí)別并過(guò)濾垃圾郵件。
情感分析:從用戶評(píng)論中提取情感傾向,廣泛應(yīng)用于市場(chǎng)分析和社交媒體監(jiān)控。
主題分類(lèi):自動(dòng)識(shí)別文章或文檔的主題,用于新聞聚合、內(nèi)容推薦等。
挑戰(zhàn)和考量
文本分類(lèi)雖然技術(shù)成熟,但仍面臨一些挑戰(zhàn):
語(yǔ)言多樣性和復(fù)雜性:不同語(yǔ)言和文化背景下的文本處理需要特定的適應(yīng)和處理策略。
數(shù)據(jù)不平衡和偏見(jiàn):訓(xùn)練數(shù)據(jù)的質(zhì)量直接影響分類(lèi)性能,需要注意數(shù)據(jù)偏見(jiàn)和不平衡問(wèn)題。
實(shí)時(shí)性和可擴(kuò)展性:在處理大量實(shí)時(shí)數(shù)據(jù)時(shí),算法的效率和擴(kuò)展性變得尤為重要。
在本章中,我們對(duì)文本分類(lèi)的基礎(chǔ)進(jìn)行了全面的介紹,從定義和目的到關(guān)鍵技術(shù)和挑戰(zhàn),為深入理解文本分類(lèi)的技術(shù)細(xì)節(jié)和實(shí)際應(yīng)用打下了堅(jiān)實(shí)的基礎(chǔ)。
三、關(guān)鍵技術(shù)和模型
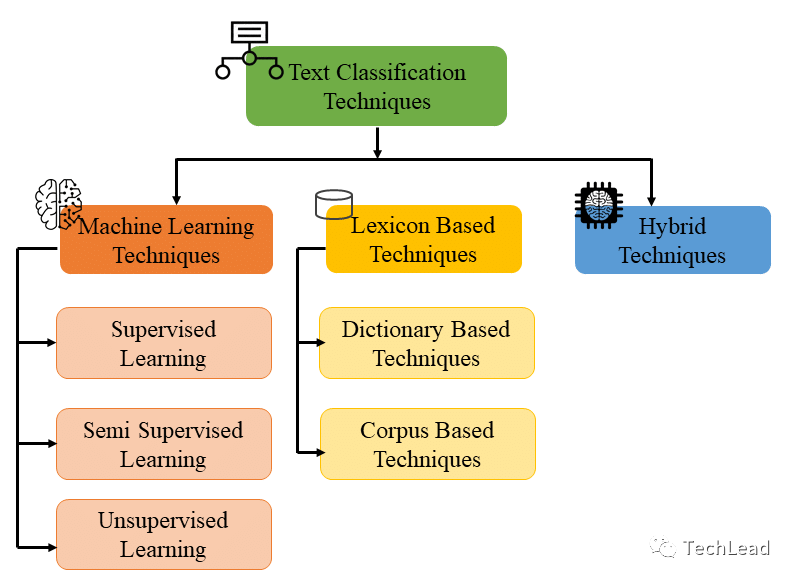
在深入探討文本分類(lèi)的關(guān)鍵技術(shù)和模型時(shí),我們會(huì)涉及從傳統(tǒng)的機(jī)器學(xué)習(xí)方法到現(xiàn)代的深度學(xué)習(xí)技術(shù)。每種技術(shù)都有其獨(dú)特之處,并在特定的應(yīng)用場(chǎng)景下表現(xiàn)出色。在這一部分,我們將通過(guò)一些關(guān)鍵代碼段來(lái)展示這些模型的實(shí)現(xiàn)和應(yīng)用。
傳統(tǒng)機(jī)器學(xué)習(xí)方法
樸素貝葉斯分類(lèi)器
樸素貝葉斯是一種基于概率的簡(jiǎn)單分類(lèi)器,廣泛用于文本分類(lèi)。以下是使用Python和scikit-learn實(shí)現(xiàn)的一個(gè)簡(jiǎn)單例子:
from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.pipeline import Pipeline # 創(chuàng)建一個(gè)文本分類(lèi)管道 text_clf_nb = Pipeline([ ('vect', CountVectorizer()), ('clf', MultinomialNB()), ]) # 示例數(shù)據(jù) train_texts = ["This is a good book", "This is a bad movie"] train_labels = [0, 1] # 0代表正面,1代表負(fù)面 # 訓(xùn)練模型 text_clf_nb.fit(train_texts, train_labels)
支持向量機(jī)(SVM)
支持向量機(jī)(SVM)是另一種常用的文本分類(lèi)方法,特別適用于高維數(shù)據(jù)。以下是使用SVM的示例代碼:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
# 創(chuàng)建一個(gè)文本分類(lèi)管道
text_clf_svm = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', SVC(kernel='linear')),
])
# 訓(xùn)練模型
text_clf_svm.fit(train_texts, train_labels)
深度學(xué)習(xí)方法
卷積神經(jīng)網(wǎng)絡(luò)(CNN)
卷積神經(jīng)網(wǎng)絡(luò)(CNN)在圖像處理領(lǐng)域表現(xiàn)突出,也被成功應(yīng)用于文本分類(lèi)。以下是使用PyTorch實(shí)現(xiàn)文本分類(lèi)的CNN模型的簡(jiǎn)單例子:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.conv = nn.Conv2d(1, 100, (3, embed_dim))
self.fc = nn.Linear(100, num_classes)
def forward(self, x):
x = self.embedding(x) # Embedding layer
x = x.unsqueeze(1) # Add channel dimension
x = F.relu(self.conv(x)).squeeze(3) # Convolution layer
x = F.max_pool1d(x, x.size(2)).squeeze(2) # Max pooling
x = self.fc(x) # Fully connected layer
return x
# 示例網(wǎng)絡(luò)創(chuàng)建
vocab_size = 1000 # 詞匯表大小
embed_dim = 100 # 嵌入層維度
num_classes = 2 # 類(lèi)別數(shù)
model = TextCNN(vocab_size, embed_dim, num_classes)
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和LSTM
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)及其變體LSTM(長(zhǎng)短期記憶網(wǎng)絡(luò))在處理序列數(shù)據(jù),如文本,方面非常有效。以下是使用PyTorch實(shí)現(xiàn)RNN的示例:
class TextRNN(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):
super(TextRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.RNN(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
x = self.embedding(x)
x, _ = self.rnn(x) # RNN layer
x = x[:, -1, :] # 獲取序列的最后一個(gè)時(shí)間步的輸出
x = self.fc(x)
return x
# 示例網(wǎng)絡(luò)
創(chuàng)建
hidden_dim = 128 # 隱藏層維度
model = TextRNN(vocab_size, embed_dim, hidden_dim, num_classes)
這些代碼段展示了不同文本分類(lèi)技術(shù)的實(shí)現(xiàn),從簡(jiǎn)單的機(jī)器學(xué)習(xí)模型到復(fù)雜的深度學(xué)習(xí)網(wǎng)絡(luò)。在接下來(lái)的章節(jié)中,我們將進(jìn)一步探討這些模型的應(yīng)用案例和性能評(píng)估。
四、深度學(xué)習(xí)在文本分類(lèi)中的應(yīng)用
深度學(xué)習(xí)技術(shù)已成為文本分類(lèi)領(lǐng)域的重要推動(dòng)力,為處理自然語(yǔ)言帶來(lái)了前所未有的效果。在這一部分,我們將探討深度學(xué)習(xí)在文本分類(lèi)中的幾種關(guān)鍵應(yīng)用,并通過(guò)示例代碼展示這些模型的實(shí)現(xiàn)。
卷積神經(jīng)網(wǎng)絡(luò)(CNN)的應(yīng)用
CNN在文本分類(lèi)中的應(yīng)用,主要是利用其在提取局部特征方面的優(yōu)勢(shì)。以下是用PyTorch實(shí)現(xiàn)的一個(gè)簡(jiǎn)單的文本分類(lèi)CNN模型:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.conv1 = nn.Conv2d(1, 100, (3, embed_dim))
self.conv2 = nn.Conv2d(1, 100, (4, embed_dim))
self.conv3 = nn.Conv2d(1, 100, (5, embed_dim))
self.fc = nn.Linear(300, num_classes)
def forward(self, x):
x = self.embedding(x).unsqueeze(1) # 增加一個(gè)維度表示通道
x1 = F.relu(self.conv1(x)).squeeze(3)
x1 = F.max_pool1d(x1, x1.size(2)).squeeze(2)
x2 = F.relu(self.conv2(x)).squeeze(3)
x2 = F.max_pool1d(x2, x2.size(2)).squeeze(2)
x3 = F.relu(self.conv3(x)).squeeze(3)
x3 = F.max_pool1d(x3, x3.size(2)).squeeze(2)
x = torch.cat((x1, x2, x3), 1) # 合并特征
x = self.fc(x)
return x
# 示例網(wǎng)絡(luò)創(chuàng)建
vocab_size = 1000
embed_dim = 100
num_classes = 2
model = TextCNN(vocab_size, embed_dim, num_classes)
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和LSTM
RNN和LSTM在處理文本序列時(shí)表現(xiàn)出色,特別是在理解長(zhǎng)文本和上下文信息方面。以下是使用PyTorch實(shí)現(xiàn)的LSTM模型:
class TextLSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):
super(TextLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x) # LSTM layer
x = x[:, -1, :] # 獲取序列最后一個(gè)時(shí)間步的輸出
x = self.fc(x)
return x
# 示例網(wǎng)絡(luò)創(chuàng)建
hidden_dim = 128
model = TextLSTM(vocab_size, embed_dim, hidden_dim, num_classes)
Transformer和BERT
Transformer模型,特別是BERT(Bidirectional Encoder Representations from Transformers),已經(jīng)成為NLP領(lǐng)域的一個(gè)重要里程碑。BERT通過(guò)預(yù)訓(xùn)練和微調(diào)的方式,在多種文本分類(lèi)任務(wù)上取得了革命性的進(jìn)展。以下是使用Hugging Face的Transformers庫(kù)來(lái)加載預(yù)訓(xùn)練的BERT模型并進(jìn)行微調(diào)的代碼:
from transformers import BertTokenizer, BertForSequenceClassification import torch # 加載預(yù)訓(xùn)練模型和分詞器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=num_classes) # 示例文本 texts = ["This is a good book", "This is a bad movie"] inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt") # 微調(diào)模型 outputs = model(**inputs)
在這一章節(jié)中,我們展示了深度學(xué)習(xí)在文本分類(lèi)中的幾種關(guān)鍵應(yīng)用,包括CNN、RNN、LSTM和Transformer模型。這些模型的代碼實(shí)現(xiàn)為我們提供了一個(gè)實(shí)際操作的視角,幫助我們理解它們?cè)谖谋痉诸?lèi)任務(wù)中的作用和效果。
五、PyTorch實(shí)戰(zhàn):文本分類(lèi)
在這一章節(jié)中,我們將通過(guò)一個(gè)具體的例子,展示如何使用PyTorch框架實(shí)現(xiàn)文本分類(lèi)任務(wù)。我們將構(gòu)建一個(gè)簡(jiǎn)單的深度學(xué)習(xí)模型,用于區(qū)分文本的情感傾向,即將文本分類(lèi)為正面或負(fù)面。
場(chǎng)景描述
我們的目標(biāo)是創(chuàng)建一個(gè)文本分類(lèi)模型,能夠根據(jù)用戶評(píng)論的內(nèi)容,自動(dòng)判斷其為正面或負(fù)面評(píng)價(jià)。這種類(lèi)型的模型在各種在線平臺(tái),如電子商務(wù)網(wǎng)站、電影評(píng)價(jià)網(wǎng)站中都有廣泛應(yīng)用。
輸入和輸出
輸入:用戶的文本評(píng)論。
輸出:二元分類(lèi)結(jié)果,即正面(positive)或負(fù)面(negative)。
處理過(guò)程
1. 數(shù)據(jù)預(yù)處理
首先,我們需要對(duì)文本數(shù)據(jù)進(jìn)行預(yù)處理,包括分詞、去除停用詞、轉(zhuǎn)換為小寫(xiě)等,然后將文本轉(zhuǎn)換為數(shù)字表示(詞嵌入)。
2. 構(gòu)建模型
我們將使用一個(gè)基于LSTM的神經(jīng)網(wǎng)絡(luò)模型,它能有效地處理文本數(shù)據(jù)的序列特性。
3. 訓(xùn)練模型
使用標(biāo)記好的數(shù)據(jù)集來(lái)訓(xùn)練我們的模型,通過(guò)調(diào)整參數(shù)優(yōu)化模型性能。
4. 評(píng)估模型
在獨(dú)立的測(cè)試集上評(píng)估模型性能,確保其準(zhǔn)確性和泛化能力。
完整的PyTorch實(shí)現(xiàn)代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F
# 示例數(shù)據(jù)集
class TextDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
return self.texts[idx], self.labels[idx]
# 文本分類(lèi)模型
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):
super(TextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x)
x = x[:, -1, :]
x = self.fc(x)
return x
# 參數(shù)設(shè)置
vocab_size = 10000 # 詞匯表大小
embed_dim = 100 # 嵌入維度
hidden_dim = 128 # LSTM隱藏層維度
num_classes = 2 # 類(lèi)別數(shù)(正面/負(fù)面)
batch_size = 64 # 批處理大小
learning_rate = 0.001 # 學(xué)習(xí)率
# 數(shù)據(jù)準(zhǔn)備
train_dataset = TextDataset([...], [...]) # 訓(xùn)練數(shù)據(jù)集
test_dataset = TextDataset([...], [...]) # 測(cè)試數(shù)據(jù)集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 初始化模型
model = TextClassifier(vocab_size, embed_dim, hidden_dim, num_classes)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 訓(xùn)練過(guò)程
for epoch in range(num_epochs):
for texts, labels in train_loader:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 測(cè)試過(guò)程
correct = 0
total = 0
with torch.no_grad():
for texts, labels in test_loader:
outputs = model(texts)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the model on the test texts: {100 * correct / total}%')
六、總結(jié)
在本文中,我們對(duì)文本分類(lèi)技術(shù)進(jìn)行了全面的探討,從其基本原理到高級(jí)應(yīng)用,從傳統(tǒng)機(jī)器學(xué)習(xí)方法到最新的深度學(xué)習(xí)技術(shù)。我們的目的是為讀者提供一個(gè)從基礎(chǔ)到前沿的知識(shí)架構(gòu),幫助他們深入理解文本分類(lèi)在人工智能領(lǐng)域的重要地位和發(fā)展趨勢(shì)。
技術(shù)融合的重要性:文本分類(lèi)的進(jìn)步不僅僅源于單一技術(shù)的突破,而是多種技術(shù)的融合與創(chuàng)新。例如,深度學(xué)習(xí)的興起給傳統(tǒng)的文本分類(lèi)方法帶來(lái)了新的生命力,而最新的模型如Transformer則是自然語(yǔ)言處理領(lǐng)域的一個(gè)重大革命。
數(shù)據(jù)的核心作用:無(wú)論技術(shù)多么先進(jìn),高質(zhì)量的數(shù)據(jù)始終是文本分類(lèi)成功的關(guān)鍵。數(shù)據(jù)的準(zhǔn)備、預(yù)處理和增強(qiáng)對(duì)于構(gòu)建高效、準(zhǔn)確的模型至關(guān)重要。
模型的可解釋性與道德責(zé)任:隨著文本分類(lèi)技術(shù)的廣泛應(yīng)用,模型的可解釋性和道德責(zé)任成為了不可忽視的話題。如何確保模型的決策公平、透明,并考慮到潛在的倫理影響,是我們未來(lái)需要深入探討的問(wèn)題。
持續(xù)的技術(shù)革新:文本分類(lèi)領(lǐng)域持續(xù)經(jīng)歷著快速的技術(shù)革新。從最初的基于規(guī)則的系統(tǒng),到現(xiàn)在的基于深度學(xué)習(xí)的模型,技術(shù)的進(jìn)步推動(dòng)了文本分類(lèi)應(yīng)用的邊界不斷擴(kuò)展。
實(shí)踐與理論的結(jié)合:理論知識(shí)和實(shí)際應(yīng)用的結(jié)合是理解和掌握文本分類(lèi)技術(shù)的關(guān)鍵。通過(guò)實(shí)戰(zhàn)案例,我們能更深刻地理解理論,并在實(shí)際問(wèn)題中找到合適的解決方案。
在文本分類(lèi)的未來(lái)發(fā)展中,我們預(yù)計(jì)將看到更多的技術(shù)創(chuàng)新和應(yīng)用探索。這不僅會(huì)推動(dòng)人工智能領(lǐng)域的進(jìn)步,也將在更廣泛的領(lǐng)域產(chǎn)生深遠(yuǎn)的影響。我們期待看到這些技術(shù)如何在不同的行業(yè)中發(fā)揮作用,同時(shí)也關(guān)注它們?nèi)绾胃玫胤?wù)于社會(huì)和個(gè)人。
審核編輯:湯梓紅
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238254 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48807 -
文本分類(lèi)
+關(guān)注
關(guān)注
0文章
18瀏覽量
7296 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132562 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121111
原文標(biāo)題:六、總結(jié)
文章出處:【微信號(hào):OSC開(kāi)源社區(qū),微信公眾號(hào):OSC開(kāi)源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NLPIR平臺(tái)在文本分類(lèi)方面的技術(shù)解析
【HarmonyOS HiSpark IPC DIY Camera試用 】基于視頻的農(nóng)村公路巡查事件人工智能檢測(cè)系統(tǒng)關(guān)鍵技術(shù)研究
明白VPP關(guān)鍵技術(shù)有哪些
《移動(dòng)終端人工智能技術(shù)與應(yīng)用開(kāi)發(fā)》人工智能的發(fā)展與AI技術(shù)的進(jìn)步
WCDMA的關(guān)鍵技術(shù)及基本原理(PPT資料)
EVDO基本原理和關(guān)鍵技術(shù)
基于AdaBoost_Bayes算法的中文文本分類(lèi)系統(tǒng)
基于apiori算法改進(jìn)的knn文本分類(lèi)方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論