 PyTorch常用代碼段合集資料分享
PyTorch常用代碼段合集資料分享
本文是PyTorch常用代碼段合集,涵蓋基本配置、張量處理、模型定義與操作、數據處理、模型訓練與測試等5個方面,還給出了多個值得注意的Tips,內容非常全面。
PyTorch最好的資料是官方文檔。本文是PyTorch常用代碼段,在參考資料[1](張皓:PyTorch Cookbook)的基礎上做了一些修補,方便使用時查閱。
基本配置
導入包和版本查詢
importtorch importtorch.nnasnn importtorchvision print(torch.__version__) print(torch.version.cuda) print(torch.backends.cudnn.version()) print(torch.cuda.get_device_name(0))
可復現性
在硬件設備(CPU、GPU)不同時,完全的可復現性無法保證,即使隨機種子相同。但是,在同一個設備上,應該保證可復現性。具體做法是,在程序開始的時候固定torch的隨機種子,同時也把numpy的隨機種子固定。
np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) torch.backends.cudnn.deterministic=True torch.backends.cudnn.benchmark=False
顯卡設置
如果只需要一張顯卡
#Deviceconfiguration
device=torch.device('cuda'iftorch.cuda.is_available()else'cpu')
如果需要指定多張顯卡,比如0,1號顯卡。
importosos.environ['CUDA_VISIBLE_DEVICES']='0,1'
也可以在命令行運行代碼時設置顯卡:
CUDA_VISIBLE_DEVICES=0,1pythontrain.py
清除顯存
torch.cuda.empty_cache()
也可以使用在命令行重置GPU的指令
nvidia-smi--gpu-reset-i[gpu_id]
張量(Tensor)處理
張量的數據類型
PyTorch有9種CPU張量類型和9種GPU張量類型。
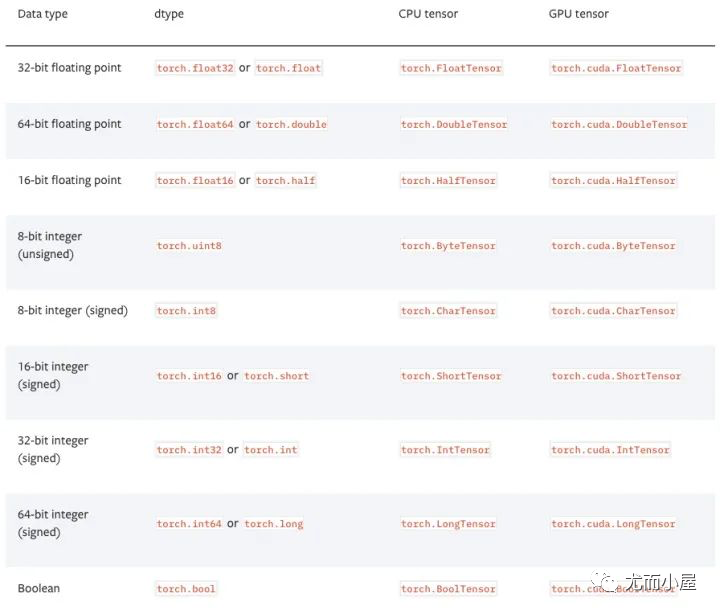
張量基本信息
tensor=torch.randn(3,4,5)print(tensor.type())#數據類型print(tensor.size())#張量的shape,是個元組print(tensor.dim())#維度的數量
命名張量
張量命名是一個非常有用的方法,這樣可以方便地使用維度的名字來做索引或其他操作,大大提高了可讀性、易用性,防止出錯。
#在PyTorch1.3之前,需要使用注釋
#Tensor[N,C,H,W]
images=torch.randn(32,3,56,56)
images.sum(dim=1)
images.select(dim=1,index=0)
#PyTorch1.3之后
NCHW=[‘N’,‘C’,‘H’,‘W’]
images=torch.randn(32,3,56,56,names=NCHW)
images.sum('C')
images.select('C',index=0)
#也可以這么設置
tensor=torch.rand(3,4,1,2,names=('C','N','H','W'))
#使用align_to可以對維度方便地排序
tensor=tensor.align_to('N','C','H','W')
數據類型轉換
#設置默認類型,pytorch中的FloatTensor遠遠快于DoubleTensor torch.set_default_tensor_type(torch.FloatTensor) #類型轉換 tensor=tensor.cuda() tensor=tensor.cpu() tensor=tensor.float() tensor=tensor.long()
torch.Tensor與np.ndarray轉換
除了CharTensor,其他所有CPU上的張量都支持轉換為numpy格式然后再轉換回來。
ndarray=tensor.cpu().numpy() tensor=torch.from_numpy(ndarray).float() tensor=torch.from_numpy(ndarray.copy()).float()#Ifndarrayhasnegativestride.
Torch.tensor與PIL.Image轉換
#pytorch中的張量默認采用[N,C,H,W]的順序,并且數據范圍在[0,1],需要進行轉置和規范化 #torch.Tensor->PIL.Image image=PIL.Image.fromarray(torch.clamp(tensor*255,min=0,max=255).byte().permute(1,2,0).cpu().numpy()) image=torchvision.transforms.functional.to_pil_image(tensor)#Equivalentlyway #PIL.Image->torch.Tensor path=r'./figure.jpg' tensor=torch.from_numpy(np.asarray(PIL.Image.open(path))).permute(2,0,1).float()/255 tensor=torchvision.transforms.functional.to_tensor(PIL.Image.open(path))#Equivalentlyway
np.ndarray與PIL.Image的轉換
image=PIL.Image.fromarray(ndarray.astype(np.uint8)) ndarray=np.asarray(PIL.Image.open(path))
從只包含一個元素的張量中提取值
value=torch.rand(1).item()
張量形變
#在將卷積層輸入全連接層的情況下通常需要對張量做形變處理, #相比torch.view,torch.reshape可以自動處理輸入張量不連續的情況 tensor=torch.rand(2,3,4) shape=(6,4) tensor=torch.reshape(tensor,shape)
打亂順序
tensor=tensor[torch.randperm(tensor.size(0))]#打亂第一個維度
水平翻轉
#pytorch不支持tensor[::-1]這樣的負步長操作,水平翻轉可以通過張量索引實現 #假設張量的維度為[N,D,H,W]. tensor=tensor[:,:,:,torch.arange(tensor.size(3)-1,-1,-1).long()]
復制張量
#Operation|New/Sharedmemory|Stillincomputationgraph| tensor.clone()#|New|Yes| tensor.detach()#|Shared|No| tensor.detach.clone()()#|New|No|
張量拼接
''' 注意torch.cat和torch.stack的區別在于torch.cat沿著給定的維度拼接, 而torch.stack會新增一維。例如當參數是3個10x5的張量,torch.cat的結果是30x5的張量, 而torch.stack的結果是3x10x5的張量。 ''' tensor=torch.cat(list_of_tensors,dim=0) tensor=torch.stack(list_of_tensors,dim=0)
將整數標簽轉為one-hot編碼
#pytorch的標記默認從0開始 tensor=torch.tensor([0,2,1,3]) N=tensor.size(0) num_classes=4 one_hot=torch.zeros(N,num_classes).long() one_hot.scatter_(dim=1,index=torch.unsqueeze(tensor,dim=1),src=torch.ones(N,num_classes).long())
得到非零元素
torch.nonzero(tensor)#indexofnon-zeroelements torch.nonzero(tensor==0)#indexofzeroelements torch.nonzero(tensor).size(0)#numberofnon-zeroelements torch.nonzero(tensor==0).size(0)#numberofzeroelements
判斷兩個張量相等
torch.allclose(tensor1,tensor2)#floattensor torch.equal(tensor1,tensor2)#inttensor
張量擴展
#Expandtensorofshape64*512toshape64*512*7*7. tensor=torch.rand(64,512) torch.reshape(tensor,(64,512,1,1)).expand(64,512,7,7)
矩陣乘法
#Matrixmultiplcation:(m*n)*(n*p)*->(m*p). result=torch.mm(tensor1,tensor2) #Batchmatrixmultiplication:(b*m*n)*(b*n*p)->(b*m*p) result=torch.bmm(tensor1,tensor2) #Element-wisemultiplication. result=tensor1*tensor2
計算兩組數據之間的兩兩歐式距離
利用廣播機制
dist=torch.sqrt(torch.sum((X1[:,None,:]-X2)**2,dim=2))
模型定義和操作
一個簡單兩層卷積網絡的示例
#convolutionalneuralnetwork(2convolutionallayers)
classConvNet(nn.Module): def__init__(self,num_classes=10): super(ConvNet,self).__init__() self.layer1=nn.Sequential( nn.Conv2d(1,16,kernel_size=5,stride=1,padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2,stride=2)) self.layer2=nn.Sequential( nn.Conv2d(16,32,kernel_size=5,stride=1,padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2,stride=2)) self.fc=nn.Linear(7*7*32,num_classes) defforward(self,x): out=self.layer1(x) out=self.layer2(out) out=out.reshape(out.size(0),-1) out=self.fc(out) returnout model=ConvNet(num_classes).to(device)
卷積層的計算和展示可以用這個網站輔助。
雙線性匯合(bilinear pooling)
X=torch.reshape(N,D,H*W)#AssumeXhasshapeN*D*H*W X=torch.bmm(X,torch.transpose(X,1,2))/(H*W)#Bilinearpooling assertX.size()==(N,D,D) X=torch.reshape(X,(N,D*D)) X=torch.sign(X)*torch.sqrt(torch.abs(X)+1e-5)#Signed-sqrtnormalization X=torch.nn.functional.normalize(X)#L2normalization
多卡同步 BN(Batch normalization)
當使用 torch.nn.DataParallel 將代碼運行在多張 GPU 卡上時,PyTorch 的 BN 層默認操作是各卡上數據獨立地計算均值和標準差,同步 BN 使用所有卡上的數據一起計算 BN 層的均值和標準差,緩解了當批量大小(batch size)比較小時對均值和標準差估計不準的情況,是在目標檢測等任務中一個有效的提升性能的技巧。
sync_bn=torch.nn.SyncBatchNorm(num_features,
eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
將已有網絡的所有BN層改為同步BN層
defconvertBNtoSyncBN(module,process_group=None):
'''RecursivelyreplaceallBNlayerstoSyncBNlayer. Args: module[torch.nn.Module].Network ''' ifisinstance(module,torch.nn.modules.batchnorm._BatchNorm): sync_bn=torch.nn.SyncBatchNorm(module.num_features,module.eps,module.momentum, module.affine,module.track_running_stats,process_group) sync_bn.running_mean=module.running_mean sync_bn.running_var=module.running_var ifmodule.affine: sync_bn.weight=module.weight.clone().detach() sync_bn.bias=module.bias.clone().detach() returnsync_bn else: forname,child_moduleinmodule.named_children(): setattr(module,name)=convert_syncbn_model(child_module,process_group=process_group)) returnmodule
類似 BN 滑動平均
如果要實現類似 BN 滑動平均的操作,在 forward 函數中要使用原地(inplace)操作給滑動平均賦值。
classBN(torch.nn.Module)
def__init__(self):
...
self.register_buffer('running_mean',torch.zeros(num_features))
defforward(self,X):
...
self.running_mean+=momentum*(current-self.running_mean)
計算模型整體參數量
num_parameters=sum(torch.numel(parameter)forparameterinmodel.parameters())
查看網絡中的參數
可以通過model.state_dict()或者model.named_parameters()函數查看現在的全部可訓練參數(包括通過繼承得到的父類中的參數)
params=list(model.named_parameters())
(name,param)=params[28]
print(name)
print(param.grad)
print('-------------------------------------------------')
(name2,param2)=params[29]
print(name2)
print(param2.grad)
print('----------------------------------------------------')
(name1,param1)=params[30]
print(name1)
print(param1.grad)
模型可視化(使用pytorchviz)
szagoruyko/pytorchvizgithub.com
類似 Keras 的 model.summary() 輸出模型信息,使用pytorch-summary
sksq96/pytorch-summarygithub.com
模型權重初始化
注意 model.modules() 和 model.children() 的區別:model.modules() 會迭代地遍歷模型的所有子層,而 model.children() 只會遍歷模型下的一層。
#Commonpractiseforinitialization. forlayerinmodel.modules(): ifisinstance(layer,torch.nn.Conv2d): torch.nn.init.kaiming_normal_(layer.weight,mode='fan_out', nonlinearity='relu') iflayer.biasisnotNone: torch.nn.init.constant_(layer.bias,val=0.0) elifisinstance(layer,torch.nn.BatchNorm2d): torch.nn.init.constant_(layer.weight,val=1.0) torch.nn.init.constant_(layer.bias,val=0.0) elifisinstance(layer,torch.nn.Linear): torch.nn.init.xavier_normal_(layer.weight) iflayer.biasisnotNone: torch.nn.init.constant_(layer.bias,val=0.0) #Initializationwithgiventensor. layer.weight=torch.nn.Parameter(tensor)
提取模型中的某一層
modules()會返回模型中所有模塊的迭代器,它能夠訪問到最內層,比如self.layer1.conv1這個模塊,還有一個與它們相對應的是name_children()屬性以及named_modules(),這兩個不僅會返回模塊的迭代器,還會返回網絡層的名字。
#取模型中的前兩層 new_model=nn.Sequential(*list(model.children())[:2] #如果希望提取出模型中的所有卷積層,可以像下面這樣操作: forlayerinmodel.named_modules(): ifisinstance(layer[1],nn.Conv2d): conv_model.add_module(layer[0],layer[1])
部分層使用預訓練模型
注意如果保存的模型是 torch.nn.DataParallel,則當前的模型也需要是
model.load_state_dict(torch.load('model.pth'),strict=False)
將在 GPU 保存的模型加載到 CPU
model.load_state_dict(torch.load('model.pth',map_location='cpu'))
導入另一個模型的相同部分到新的模型
模型導入參數時,如果兩個模型結構不一致,則直接導入參數會報錯。用下面方法可以把另一個模型的相同的部分導入到新的模型中。
#model_new代表新的模型
#model_saved代表其他模型,比如用torch.load導入的已保存的模型
model_new_dict=model_new.state_dict()
model_common_dict={k:vfork,vinmodel_saved.items()ifkinmodel_new_dict.keys()}
model_new_dict.update(model_common_dict)
model_new.load_state_dict(model_new_dict)
數據處理
計算數據集的均值和標準差
importos importcv2 importnumpyasnp fromtorch.utils.dataimportDataset fromPILimportImage defcompute_mean_and_std(dataset): #輸入PyTorch的dataset,輸出均值和標準差 mean_r=0 mean_g=0 mean_b=0 forimg,_indataset: img=np.asarray(img)#changePILImagetonumpyarray mean_b+=np.mean(img[:,:,0]) mean_g+=np.mean(img[:,:,1]) mean_r+=np.mean(img[:,:,2]) mean_b/=len(dataset) mean_g/=len(dataset) mean_r/=len(dataset) diff_r=0 diff_g=0 diff_b=0 N=0 forimg,_indataset: img=np.asarray(img) diff_b+=np.sum(np.power(img[:,:,0]-mean_b,2)) diff_g+=np.sum(np.power(img[:,:,1]-mean_g,2)) diff_r+=np.sum(np.power(img[:,:,2]-mean_r,2)) N+=np.prod(img[:,:,0].shape) std_b=np.sqrt(diff_b/N) std_g=np.sqrt(diff_g/N) std_r=np.sqrt(diff_r/N) mean=(mean_b.item()/255.0,mean_g.item()/255.0,mean_r.item()/255.0) std=(std_b.item()/255.0,std_g.item()/255.0,std_r.item()/255.0) returnmean,std
得到視頻數據基本信息
importcv2 video=cv2.VideoCapture(mp4_path) height=int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)) width=int(video.get(cv2.CAP_PROP_FRAME_WIDTH)) num_frames=int(video.get(cv2.CAP_PROP_FRAME_COUNT)) fps=int(video.get(cv2.CAP_PROP_FPS)) video.release()
TSN 每段(segment)采樣一幀視頻
K=self._num_segments ifis_train: ifnum_frames>K: #Randomindexforeachsegment. frame_indices=torch.randint( high=num_frames//K,size=(K,),dtype=torch.long) frame_indices+=num_frames//K*torch.arange(K) else: frame_indices=torch.randint( high=num_frames,size=(K-num_frames,),dtype=torch.long) frame_indices=torch.sort(torch.cat(( torch.arange(num_frames),frame_indices)))[0] else: ifnum_frames>K: #Middleindexforeachsegment. frame_indices=num_frames/K//2 frame_indices+=num_frames//K*torch.arange(K) else: frame_indices=torch.sort(torch.cat(( torch.arange(num_frames),torch.arange(K-num_frames))))[0] assertframe_indices.size()==(K,) return[frame_indices[i]foriinrange(K)]
常用訓練和驗證數據預處理
其中 ToTensor 操作會將 PIL.Image 或形狀為 H×W×D,數值范圍為 [0, 255] 的 np.ndarray 轉換為形狀為 D×H×W,數值范圍為 [0.0, 1.0] 的 torch.Tensor。
train_transform=torchvision.transforms.Compose([ torchvision.transforms.RandomResizedCrop(size=224, scale=(0.08,1.0)), torchvision.transforms.RandomHorizontalFlip(), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=(0.485,0.456,0.406), std=(0.229,0.224,0.225)), ]) val_transform=torchvision.transforms.Compose([ torchvision.transforms.Resize(256), torchvision.transforms.CenterCrop(224), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=(0.485,0.456,0.406), std=(0.229,0.224,0.225)), ])
模型訓練和測試
分類模型訓練代碼
#Lossandoptimizer
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)
#Trainthemodel
total_step=len(train_loader)
forepochinrange(num_epochs):
fori,(images,labels)inenumerate(train_loader):
images=images.to(device)
labels=labels.to(device)
#Forwardpass
outputs=model(images)
loss=criterion(outputs,labels)
#Backwardandoptimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
if(i+1)%100==0:
print('Epoch:[{}/{}],Step:[{}/{}],Loss:{}'
.format(epoch+1,num_epochs,i+1,total_step,loss.item()))
分類模型測試代碼
#Testthemodel
model.eval()#evalmode(batchnormusesmovingmean/variance
#insteadofmini-batchmean/variance)
withtorch.no_grad():
correct=0
total=0
forimages,labelsintest_loader:
images=images.to(device)
labels=labels.to(device)
outputs=model(images)
_,predicted=torch.max(outputs.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()
print('Testaccuracyofthemodelonthe10000testimages:{}%'
.format(100*correct/total))
自定義loss
繼承torch.nn.Module類寫自己的loss。
classMyLoss(torch.nn.Moudle): def__init__(self): super(MyLoss,self).__init__() defforward(self,x,y): loss=torch.mean((x-y)**2) returnloss
標簽平滑(label smoothing)
寫一個label_smoothing.py的文件,然后在訓練代碼里引用,用LSR代替交叉熵損失即可。label_smoothing.py內容如下:
importtorch importtorch.nnasnn classLSR(nn.Module): def__init__(self,e=0.1,reduction='mean'): super().__init__() self.log_softmax=nn.LogSoftmax(dim=1) self.e=e self.reduction=reduction def_one_hot(self,labels,classes,value=1): """ Convertlabelstoonehotvectors Args: labels:torchtensorinformat[label1,label2,label3,...] classes:int,numberofclasses value:labelvalueinonehotvector,defaultto1 Returns: returnonehotformatlabelsinshape[batchsize,classes] """ one_hot=torch.zeros(labels.size(0),classes) #labelsandvalue_addedsizemustmatch labels=labels.view(labels.size(0),-1) value_added=torch.Tensor(labels.size(0),1).fill_(value) value_added=value_added.to(labels.device) one_hot=one_hot.to(labels.device) one_hot.scatter_add_(1,labels,value_added) returnone_hot def_smooth_label(self,target,length,smooth_factor): """converttargetstoone-hotformat,andsmooth them. Args: target:targetinformwith[label1,label2,label_batchsize] length:lengthofone-hotformat(numberofclasses) smooth_factor:smoothfactorforlabelsmooth Returns: smoothedlabelsinonehotformat """ one_hot=self._one_hot(target,length,value=1-smooth_factor) one_hot+=smooth_factor/(length-1) returnone_hot.to(target.device) defforward(self,x,target): ifx.size(0)!=target.size(0): raiseValueError('Expectedinputbatchsize({})tomatchtargetbatch_size({})' .format(x.size(0),target.size(0))) ifx.dim()
或者直接在訓練文件里做label smoothing
forimages,labelsintrain_loader: images,labels=images.cuda(),labels.cuda() N=labels.size(0) #Cisthenumberofclasses. smoothed_labels=torch.full(size=(N,C),fill_value=0.1/(C-1)).cuda() smoothed_labels.scatter_(dim=1,index=torch.unsqueeze(labels,dim=1),value=0.9) score=model(images) log_prob=torch.nn.functional.log_softmax(score,dim=1) loss=-torch.sum(log_prob*smoothed_labels)/N optimizer.zero_grad() loss.backward() optimizer.step()
Mixup訓練
beta_distribution=torch.distributions.beta.Beta(alpha,alpha) forimages,labelsintrain_loader: images,labels=images.cuda(),labels.cuda() #Mixupimagesandlabels. lambda_=beta_distribution.sample([]).item() index=torch.randperm(images.size(0)).cuda() mixed_images=lambda_*images+(1-lambda_)*images[index,:] label_a,label_b=labels,labels[index] #Mixuploss. scores=model(mixed_images) loss=(lambda_*loss_function(scores,label_a) +(1-lambda_)*loss_function(scores,label_b)) optimizer.zero_grad() loss.backward() optimizer.step()
L1 正則化
l1_regularization=torch.nn.L1Loss(reduction='sum') loss=...#Standardcross-entropyloss forparaminmodel.parameters(): loss+=torch.sum(torch.abs(param)) loss.backward()
不對偏置項進行權重衰減(weight decay)
pytorch里的weight decay相當于l2正則
bias_list=(paramforname,paraminmodel.named_parameters()ifname[-4:]=='bias') others_list=(paramforname,paraminmodel.named_parameters()ifname[-4:]!='bias') parameters=[{'parameters':bias_list,'weight_decay':0}, {'parameters':others_list}] optimizer=torch.optim.SGD(parameters,lr=1e-2,momentum=0.9,weight_decay=1e-4)
梯度裁剪(gradient clipping)
torch.nn.utils.clip_grad_norm_(model.parameters(),max_norm=20)
得到當前學習率
#Ifthereisonegloballearningrate(whichisthecommoncase). lr=next(iter(optimizer.param_groups))['lr'] #Iftherearemultiplelearningratesfordifferentlayers. all_lr=[] forparam_groupinoptimizer.param_groups: all_lr.append(param_group['lr'])
另一種方法,在一個batch訓練代碼里,當前的lr是optimizer.param_groups[0]['lr']
學習率衰減
#Reducelearningratewhenvalidationaccuarcyplateau. scheduler=torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='max',patience=5,verbose=True) fortinrange(0,80): train(...) val(...) scheduler.step(val_acc) #Cosineannealinglearningrate. scheduler=torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=80) #Reducelearningrateby10atgivenepochs. scheduler=torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[50,70],gamma=0.1) fortinrange(0,80): scheduler.step() train(...) val(...) #Learningratewarmupby10epochs. scheduler=torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda=lambdat:t/10) fortinrange(0,10): scheduler.step() train(...) val(...)
優化器鏈式更新
從1.4版本開始,torch.optim.lr_scheduler 支持鏈式更新(chaining),即用戶可以定義兩個 schedulers,并交替在訓練中使用。
importtorch fromtorch.optimimportSGD fromtorch.optim.lr_schedulerimportExponentialLR,StepLR model=[torch.nn.Parameter(torch.randn(2,2,requires_grad=True))] optimizer=SGD(model,0.1) scheduler1=ExponentialLR(optimizer,gamma=0.9) scheduler2=StepLR(optimizer,step_size=3,gamma=0.1) forepochinrange(4): print(epoch,scheduler2.get_last_lr()[0]) optimizer.step() scheduler1.step() scheduler2.step()
模型訓練可視化
PyTorch可以使用tensorboard來可視化訓練過程。
安裝和運行TensorBoard。
pipinstalltensorboard tensorboard--logdir=runs
使用SummaryWriter類來收集和可視化相應的數據,放了方便查看,可以使用不同的文件夾,比如'Loss/train'和'Loss/test'。
fromtorch.utils.tensorboardimportSummaryWriter importnumpyasnp writer=SummaryWriter() forn_iterinrange(100): writer.add_scalar('Loss/train',np.random.random(),n_iter) writer.add_scalar('Loss/test',np.random.random(),n_iter) writer.add_scalar('Accuracy/train',np.random.random(),n_iter) writer.add_scalar('Accuracy/test',np.random.random(),n_iter)
保存與加載斷點
注意為了能夠恢復訓練,我們需要同時保存模型和優化器的狀態,以及當前的訓練輪數。
start_epoch=0 #Loadcheckpoint. ifresume:#resume為參數,第一次訓練時設為0,中斷再訓練時設為1 model_path=os.path.join('model','best_checkpoint.pth.tar') assertos.path.isfile(model_path) checkpoint=torch.load(model_path) best_acc=checkpoint['best_acc'] start_epoch=checkpoint['epoch'] model.load_state_dict(checkpoint['model']) optimizer.load_state_dict(checkpoint['optimizer']) print('Loadcheckpointatepoch{}.'.format(start_epoch)) print('Bestaccuracysofar{}.'.format(best_acc)) #Trainthemodel forepochinrange(start_epoch,num_epochs): ... #Testthemodel ... #savecheckpoint is_best=current_acc>best_acc best_acc=max(current_acc,best_acc) checkpoint={ 'best_acc':best_acc, 'epoch':epoch+1, 'model':model.state_dict(), 'optimizer':optimizer.state_dict(), } model_path=os.path.join('model','checkpoint.pth.tar') best_model_path=os.path.join('model','best_checkpoint.pth.tar') torch.save(checkpoint,model_path) ifis_best: shutil.copy(model_path,best_model_path)
提取 ImageNet 預訓練模型某層的卷積特征
#VGG-16relu5-3feature. model=torchvision.models.vgg16(pretrained=True).features[:-1] #VGG-16pool5feature. model=torchvision.models.vgg16(pretrained=True).features #VGG-16fc7feature. model=torchvision.models.vgg16(pretrained=True) model.classifier=torch.nn.Sequential(*list(model.classifier.children())[:-3]) #ResNetGAPfeature. model=torchvision.models.resnet18(pretrained=True) model=torch.nn.Sequential(collections.OrderedDict( list(model.named_children())[:-1])) withtorch.no_grad(): model.eval() conv_representation=model(image)
提取 ImageNet 預訓練模型多層的卷積特征
classFeatureExtractor(torch.nn.Module): """Helperclasstoextractseveralconvolutionfeaturesfromthegiven pre-trainedmodel. Attributes: _model,torch.nn.Module. _layers_to_extract,listorset Example: >>>model=torchvision.models.resnet152(pretrained=True) >>>model=torch.nn.Sequential(collections.OrderedDict( list(model.named_children())[:-1])) >>>conv_representation=FeatureExtractor( pretrained_model=model, layers_to_extract={'layer1','layer2','layer3','layer4'})(image) """ def__init__(self,pretrained_model,layers_to_extract): torch.nn.Module.__init__(self) self._model=pretrained_model self._model.eval() self._layers_to_extract=set(layers_to_extract) defforward(self,x): withtorch.no_grad(): conv_representation=[] forname,layerinself._model.named_children(): x=layer(x) ifnameinself._layers_to_extract: conv_representation.append(x) returnconv_representation 微調全連接層
model=torchvision.models.resnet18(pretrained=True) forparaminmodel.parameters(): param.requires_grad=False model.fc=nn.Linear(512,100)#Replacethelastfclayer optimizer=torch.optim.SGD(model.fc.parameters(),lr=1e-2,momentum=0.9,weight_decay=1e-4)
以較大學習率微調全連接層,較小學習率微調卷積層
model=torchvision.models.resnet18(pretrained=True) finetuned_parameters=list(map(id,model.fc.parameters())) conv_parameters=(pforpinmodel.parameters()ifid(p)notinfinetuned_parameters) parameters=[{'params':conv_parameters,'lr':1e-3}, {'params':model.fc.parameters()}] optimizer=torch.optim.SGD(parameters,lr=1e-2,momentum=0.9,weight_decay=1e-4)
其他注意事項
不要使用太大的線性層。因為nn.Linear(m,n)使用的是的內存,線性層太大很容易超出現有顯存。
不要在太長的序列上使用RNN。因為RNN反向傳播使用的是BPTT算法,其需要的內存和輸入序列的長度呈線性關系。
model(x) 前用 model.train() 和 model.eval() 切換網絡狀態。
不需要計算梯度的代碼塊用 with torch.no_grad() 包含起來。
model.eval() 和 torch.no_grad() 的區別在于,model.eval() 是將網絡切換為測試狀態,例如 BN 和dropout在訓練和測試階段使用不同的計算方法。torch.no_grad() 是關閉 PyTorch 張量的自動求導機制,以減少存儲使用和加速計算,得到的結果無法進行 loss.backward()。
model.zero_grad()會把整個模型的參數的梯度都歸零, 而optimizer.zero_grad()只會把傳入其中的參數的梯度歸零.
torch.nn.CrossEntropyLoss 的輸入不需要經過 Softmax。torch.nn.CrossEntropyLoss 等價于 torch.nn.functional.log_softmax + torch.nn.NLLLoss。
loss.backward() 前用 optimizer.zero_grad() 清除累積梯度。
torch.utils.data.DataLoader 中盡量設置 pin_memory=True,對特別小的數據集如 MNIST 設置 pin_memory=False 反而更快一些。num_workers 的設置需要在實驗中找到最快的取值。
用 del 及時刪除不用的中間變量,節約 GPU 存儲。使用 inplace 操作可節約 GPU 存儲,如:
x=torch.nn.functional.relu(x,inplace=True)
減少 CPU 和 GPU 之間的數據傳輸。例如如果你想知道一個 epoch 中每個 mini-batch 的 loss 和準確率,先將它們累積在 GPU 中等一個 epoch 結束之后一起傳輸回 CPU 會比每個 mini-batch 都進行一次 GPU 到 CPU 的傳輸更快。
使用半精度浮點數 half() 會有一定的速度提升,具體效率依賴于 GPU 型號。需要小心數值精度過低帶來的穩定性問題。
時常使用 assert tensor.size() == (N, D, H, W) 作為調試手段,確保張量維度和你設想中一致。
除了標記 y 外,盡量少使用一維張量,使用 n*1 的二維張量代替,可以避免一些意想不到的一維張量計算結果。
統計代碼各部分耗時:
withtorch.autograd.profiler.profile(enabled=True,use_cuda=False)asprofile:
...print(profile)#或者在命令行運行python-mtorch.utils.bottleneckmain.py使用TorchSnooper來調試PyTorch代碼,程序在執行的時候,就會自動 print 出來每一行的執行結果的 tensor 的形狀、數據類型、設備、是否需要梯度的信息。
#pipinstalltorchsnooper importtorchsnooper#對于函數,使用修飾器@torchsnooper.snoop() #如果不是函數,使用 with 語句來激活 TorchSnooper,把訓練的那個循環裝進 with 語句中去。 withtorchsnooper.snoop(): 原本的代碼https://github.com/zasdfgbnm/TorchSnoopergithub.com
模型可解釋性,使用captum庫:https://captum.ai/captum.ai
審核編輯:黃飛
-
cpu
+關注
關注
68文章
10855瀏覽量
211603 -
gpu
+關注
關注
28文章
4729瀏覽量
128897 -
函數
+關注
關注
3文章
4328瀏覽量
62575 -
pytorch
+關注
關注
2文章
808瀏覽量
13202
原文標題:PyTorch高頻代碼段集錦!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Verilog HDL詳細資料合集!
智能家居合集資料
工程測試技術的詳細中文合集資料(免費下載)
電路分析基礎教程合集資料免費下載
使用51單片機設計的智能小車程序代碼合集資料免費下載

VB.NET的常用命名空間和類介紹和VB的完美代碼庫資料合集免費


如何進行編程可以減少程序的bug?單片機技巧合集資料下載






 工商網監
工商網監
評論