") ICLR 2024高分投稿:用于一般時(shí)間序列分析的現(xiàn)代純卷積結(jié)構(gòu)
ICLR 2024高分投稿:用于一般時(shí)間序列分析的現(xiàn)代純卷積結(jié)構(gòu)
這篇是 ICLR 上用 TCN 來(lái)做一般的時(shí)間序列分析的論文,在 Rebuttal 之后的分?jǐn)?shù)為 888,算得上是時(shí)間序列領(lǐng)域相關(guān)的論文中最高分那一檔了。本文提出了一個(gè) ModernTCN 的模型,實(shí)現(xiàn)起來(lái)也很簡(jiǎn)單,所以我后面附上了模型的代碼實(shí)現(xiàn)。

論文標(biāo)題:
ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis
論文鏈接:
https://openreview.net/forum?id=vpJMJerXHU

Key Point
1.1 Motivation
作者發(fā)現(xiàn),在時(shí)間序列領(lǐng)域,最近基于 TCN/CNN 的模型效果沒(méi)有基于Transformer 或 MLP 的模型效果好,而一些現(xiàn)代的 CNN 比如 ConvNeXt、SLaK 的性能都超過(guò)了 Vision Transformer。因此,作者想探究卷積是不是可以在時(shí)間序列分析領(lǐng)域獲得更好的性能。為此,有兩點(diǎn)可以改善 TCN 模型的地方。
首先是要提升感受野。在 CV 領(lǐng)域,現(xiàn)代卷積都有著很大的卷積核。作者發(fā)現(xiàn)在時(shí)間序列領(lǐng)域差不多,可以看下圖:

SCINet 和 MICN 是兩個(gè)基于 TCN 的預(yù)測(cè)模型,它們的感受野都很小。作者發(fā)現(xiàn) ModernTCN 中采用大的卷積核所對(duì)應(yīng)的感受野要大很多。
其次是充分利用卷積可以捕獲跨變量依賴性,也就是多變量時(shí)間序列中變量之間的關(guān)系。在 PatchTST 等最近的時(shí)間序列預(yù)測(cè)文章中,很多方法采用了通道獨(dú)立策略,這種策略直接將多變量序列預(yù)測(cè)中變量之間關(guān)系忽略了,反而取得了更好的效果。作者認(rèn)為,變量之間關(guān)系仍然重要,但是要精心設(shè)計(jì)模型結(jié)構(gòu)來(lái)捕獲。
1.2 從CV中汲取靈感(現(xiàn)代卷積結(jié)構(gòu))
在 CV 中,很多人發(fā)現(xiàn) Transformer 之所以成功,可能是因?yàn)榧軜?gòu)比較好。比如下圖左側(cè),self-attention 負(fù)責(zé) token 之間的混合,F(xiàn)FN 負(fù)責(zé)通道之間的混合,兩者分離開(kāi)。同樣的,把混合 token 的結(jié)構(gòu)替換為深度分離卷積(depth-wise 卷積,DWConv),把 FFN 換為完全等價(jià)的 ConvFFN(由兩個(gè) point-wise Conv 加 GeLU 激活組成)。
不熟悉 depth-wise 卷積的可以去了解一下,它其實(shí)就是對(duì)每個(gè)通道采用獨(dú)立的核,這樣就不會(huì)混合通道,只會(huì)混合 token,大卷積核來(lái)獲取大感受野也是在這里用的。
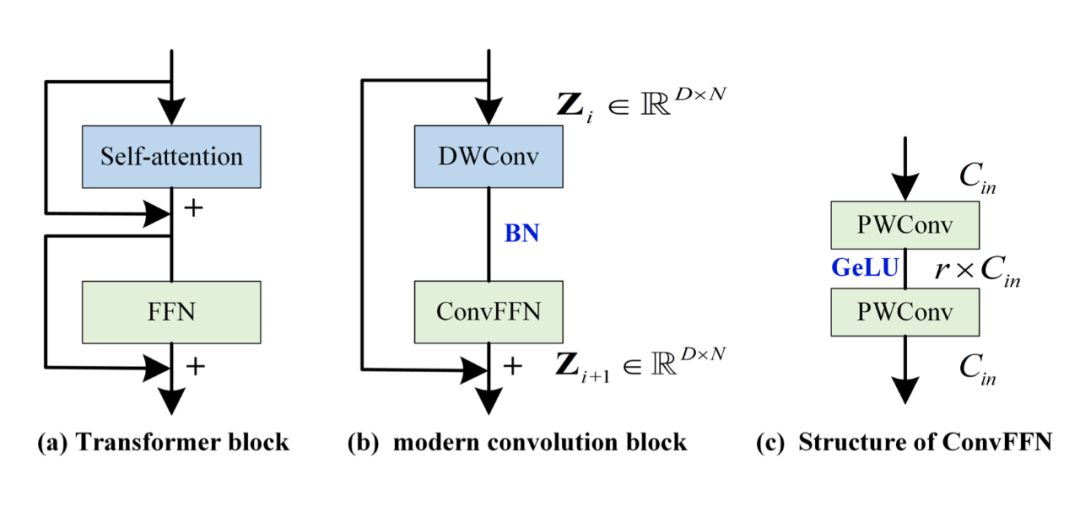
然而,作者發(fā)現(xiàn)采用上圖(b)的結(jié)構(gòu)構(gòu)建的模型效果也不是特別好,這是因?yàn)檫@個(gè)現(xiàn)代卷積結(jié)構(gòu)中并沒(méi)有專(zhuān)門(mén)為時(shí)間序列設(shè)計(jì)的一些特殊的東西,一個(gè)重要的就是如何建模跨變量依賴性。注意,在這里要區(qū)分通道和變量之間的關(guān)系。變量是指多變量序列中每個(gè)變量,通道是指每個(gè)變量映射到的隱空間維度(而 PatchTST 中提到的通道獨(dú)立則是變量之間獨(dú)立,這個(gè)不要混淆)。ConvFFN 可以建模通道間關(guān)系,但無(wú)法建模變量間關(guān)系。
1.3 適用于時(shí)間序列的改動(dòng)(變量間建模)
首先,在 embedding 的過(guò)程中,cv 一般是直接混合 RGB 變量。而在時(shí)間序列中,這種方式不適用,因?yàn)橐粋€(gè)簡(jiǎn)單的 embedding 顯然無(wú)法充分建模變量間關(guān)系。如果在 embedding 時(shí)就已經(jīng)把變量混合了起來(lái),那后續(xù)對(duì)變量間的建模則是混亂的。
因此,作者提出了變量無(wú)關(guān) embedding,也是用了分 patch 的方法,對(duì)每個(gè)變量獨(dú)立分 patch 進(jìn)行 embedding。具體在代碼實(shí)現(xiàn)上,作者是采用有 stride 的卷積,在這里我給出了代碼實(shí)現(xiàn),先介紹下代碼相關(guān)的注釋?zhuān)?/span>
# B:batch size
# M:多變量序列的變量數(shù)
# L:過(guò)去序列的長(zhǎng)度
#T:預(yù)測(cè)序列的長(zhǎng)度
#N:分Patch后Patch的個(gè)數(shù)
# D:每個(gè)變量的通道數(shù)
# P:kernel size of embedding layer
# S:stride of embedding layer
classEmbedding(nn.Module):
def__init__(self,P=8,S=4,D=2048):
super(Embedding,self).__init__()
self.P=P
self.S=S
self.conv=nn.Conv1d(
in_channels=1,
out_channels=D,
kernel_size=P,
stride=S
)
defforward(self,x):
#x:[B,M,L]
B=x.shape[0]
x=x.unsqueeze(2)#[B,M,L]->[B,M,1,L]
x=rearrange(x,'bmrl->(bm)rl')#[B,M,1,L]->[B*M,1,L]
x_pad=F.pad(
x,
pad=(0,self.P-self.S),
mode='replicate'
)#[B*M,1,L]->[B*M,1,L+P-S]
x_emb=self.conv(x_pad)#[B*M,1,L+P-S]->[B*M,D,N]
x_emb=rearrange(x_emb,'(bm)dn->bmdn',b=B)#[B*M,D,N]->[B,M,D,N]
returnx_emb#x_emb:[B,M,D,N]
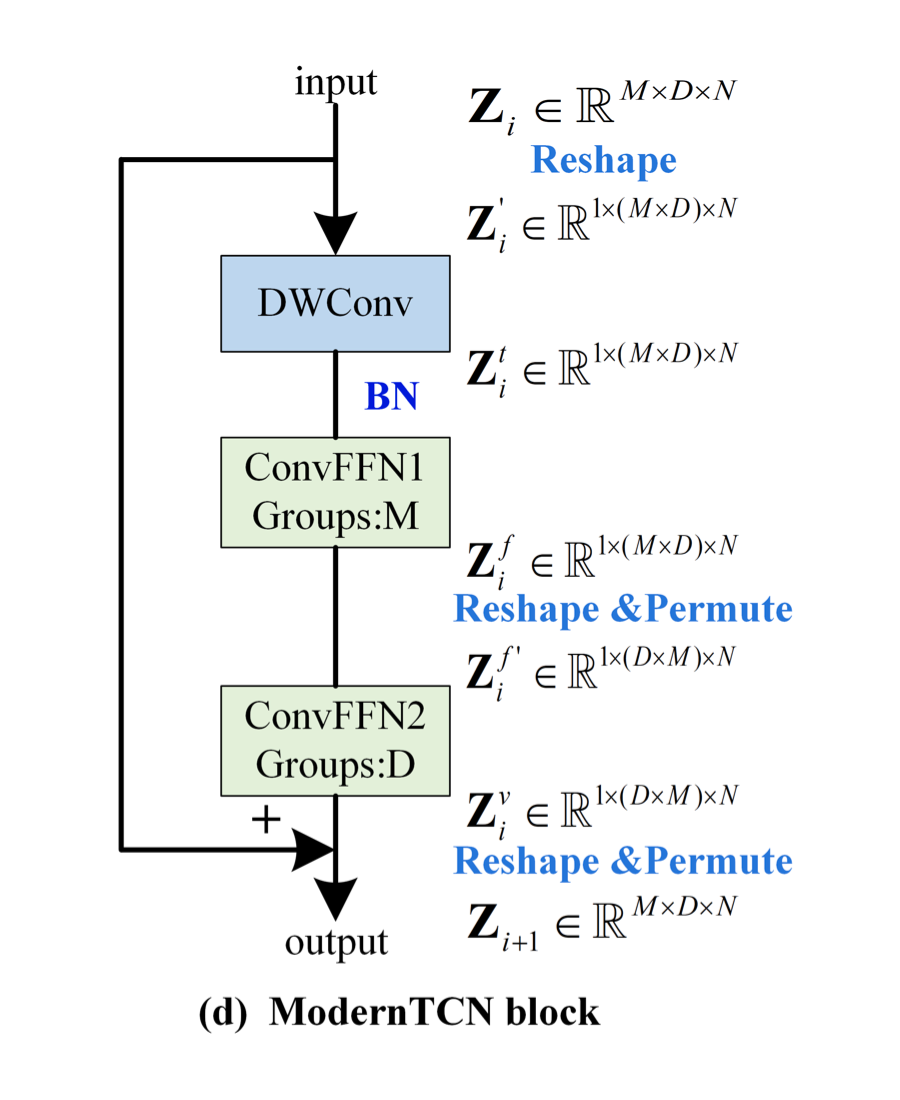
上圖中 DWconv 用來(lái)建模時(shí)間關(guān)系,第一個(gè) ConvFFN 用來(lái)建模通道關(guān)系,第二個(gè) ConvFFN 用來(lái)建模變量關(guān)系。下面介紹具體的實(shí)現(xiàn),注意看上圖中 shape 在每一個(gè)模塊的前后變化。
首先,希望用 DWConv 來(lái)建模時(shí)間上的關(guān)系,但又不希望它參與到通道間和變量間的建模上。因此,作者將 M 和 D 這兩個(gè)表示變量和通道的維度 reshape 在一起,再進(jìn)行深度可分離卷積。
其次,希望獨(dú)立建模通道和變量。因此,作者采用了兩個(gè)組卷積,其中一個(gè)組卷積的 Group 數(shù)為 M(表示每 D 個(gè)通道構(gòu)成一個(gè)組,因此用來(lái)建模通道間關(guān)系),另一個(gè)組卷積的 Group 數(shù)為 D(表示每 M 個(gè)變量構(gòu)成一個(gè)組,因此用來(lái)建模變量間關(guān)系)。注意,兩個(gè)組卷積之間存在著 reshape 和 permute 操作,這是為了正確的分組,最后會(huì)再 reshape 和 permute 回去。
最后,整體再用一個(gè)殘差連接,即可得到最終的 ModernTCN block。ModernTCN block 的代碼實(shí)現(xiàn)在最后,堆疊多個(gè) block 即可得到 ModernTCN 模型。
綜上所述,作者將時(shí)間上、通道上、變量上的三種關(guān)系解耦建模,用三種組卷積來(lái)巧妙地進(jìn)行實(shí)現(xiàn)(深度可分離卷積其實(shí)也是組數(shù)等于深度數(shù)的組卷積),既簡(jiǎn)單又有效。

實(shí)驗(yàn)
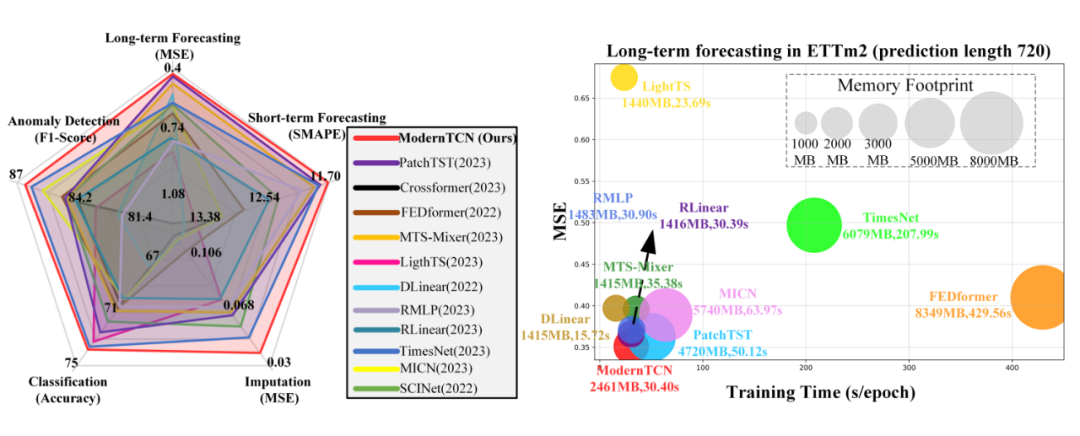
作者也是在各種時(shí)間序列任務(wù)上進(jìn)行了實(shí)驗(yàn),如下圖,又快又好的五邊形戰(zhàn)士:

代碼實(shí)現(xiàn)
注意,我這里實(shí)現(xiàn)的模型是用于時(shí)間序列預(yù)測(cè)任務(wù)的,在 backbone 的基礎(chǔ)上加了個(gè)預(yù)測(cè)頭,具體的結(jié)構(gòu)在論文附錄圖 5。
importtorch
importtorch.nnasnn
importtorch.nn.functionalasF
fromeinopsimportrearrange
# B:batch size
# M:多變量序列的變量數(shù)
# L:過(guò)去序列的長(zhǎng)度
#T:預(yù)測(cè)序列的長(zhǎng)度
#N:分Patch后Patch的個(gè)數(shù)
# D:每個(gè)變量的通道數(shù)
# P:kernel size of embedding layer
# S:stride of embedding layer
classEmbedding(nn.Module):
def__init__(self,P=8,S=4,D=2048):
super(Embedding,self).__init__()
self.P=P
self.S=S
self.conv=nn.Conv1d(
in_channels=1,
out_channels=D,
kernel_size=P,
stride=S
)
defforward(self,x):
#x:[B,M,L]
B=x.shape[0]
x=x.unsqueeze(2)#[B,M,L]->[B,M,1,L]
x=rearrange(x,'bmrl->(bm)rl')#[B,M,1,L]->[B*M,1,L]
x_pad=F.pad(
x,
pad=(0,self.P-self.S),
mode='replicate'
)#[B*M,1,L]->[B*M,1,L+P-S]
x_emb=self.conv(x_pad)#[B*M,1,L+P-S]->[B*M,D,N]
x_emb=rearrange(x_emb,'(bm)dn->bmdn',b=B)#[B*M,D,N]->[B,M,D,N]
returnx_emb#x_emb:[B,M,D,N]
classConvFFN(nn.Module):
def__init__(self,M,D,r,one=True):#oneisTrue:ConvFFN1,oneisFalse:ConvFFN2
super(ConvFFN,self).__init__()
groups_num=MifoneelseD
self.pw_con1=nn.Conv1d(
in_channels=M*D,
out_channels=r*M*D,
kernel_size=1,
groups=groups_num
)
self.pw_con2=nn.Conv1d(
in_channels=r*M*D,
out_channels=M*D,
kernel_size=1,
groups=groups_num
)
defforward(self,x):
#x:[B,M*D,N]
x=self.pw_con2(F.gelu(self.pw_con1(x)))
returnx#x:[B,M*D,N]
classModernTCNBlock(nn.Module):
def__init__(self,M,D,kernel_size,r):
super(ModernTCNBlock,self).__init__()
#深度分離卷積負(fù)責(zé)捕獲時(shí)域關(guān)系
self.dw_conv=nn.Conv1d(
in_channels=M*D,
out_channels=M*D,
kernel_size=kernel_size,
groups=M*D,
padding='same'
)
self.bn=nn.BatchNorm1d(M*D)
self.conv_ffn1=ConvFFN(M,D,r,one=True)
self.conv_ffn2=ConvFFN(M,D,r,one=False)
defforward(self,x_emb):
#x_emb:[B,M,D,N]
D=x_emb.shape[-2]
x=rearrange(x_emb,'bmdn->b(md)n')#[B,M,D,N]->[B,M*D,N]
x=self.dw_conv(x)#[B,M*D,N]->[B,M*D,N]
x=self.bn(x)#[B,M*D,N]->[B,M*D,N]
x=self.conv_ffn1(x)#[B,M*D,N]->[B,M*D,N]
x=rearrange(x,'b(md)n->bmdn',d=D)#[B,M*D,N]->[B,M,D,N]
x=x.permute(0,2,1,3)#[B,M,D,N]->[B,D,M,N]
x=rearrange(x,'bdmn->b(dm)n')#[B,D,M,N]->[B,D*M,N]
x=self.conv_ffn2(x)#[B,D*M,N]->[B,D*M,N]
x=rearrange(x,'b(dm)n->bdmn',d=D)#[B,D*M,N]->[B,D,M,N]
x=x.permute(0,2,1,3)#[B,D,M,N]->[B,M,D,N]
out=x+x_emb
returnout#out:[B,M,D,N]
classModernTCN(nn.Module):
def__init__(self,M,L,T,D=2048,P=8,S=4,kernel_size=51,r=1,num_layers=2):
super(ModernTCN,self).__init__()
#深度分離卷積負(fù)責(zé)捕獲時(shí)域關(guān)系
self.num_layers=num_layers
N=L//S
self.embed_layer=Embedding(P,S,D)
self.backbone=nn.ModuleList([ModernTCNBlock(M,D,kernel_size,r)for_inrange(num_layers)])
self.head=nn.Linear(D*N,T)
defforward(self,x):
#x:[B,M,L]
x_emb=self.embed_layer(x)#[B,M,L]->[B,M,D,N]
foriinrange(self.num_layers):
x_emb=self.backbone[i](x_emb)#[B,M,D,N]->[B,M,D,N]
#Flatten
z=rearrange(x_emb,'bmdn->bm(dn)')#[B,M,D,N]->[B,M,D*N]
pred=self.head(z)#[B,M,D*N]->[B,M,T]
returnpred#out:[B,M,T]
past_series=torch.rand(2,4,96)
model=ModernTCN(4,96,192)
pred_series=model(past_series)
print(pred_series.shape)
#torch.Size([2,4,192])

Comments
附錄很長(zhǎng),里面的消融實(shí)驗(yàn)很充分,效果也很好,想法很合理,實(shí)現(xiàn)起來(lái)也很簡(jiǎn)單,估計(jì)能中 oral。不過(guò)感覺(jué)在那幾個(gè)時(shí)間序列預(yù)測(cè)任務(wù)上的數(shù)據(jù)集都快刷爆了,性能快到瓶頸了,感覺(jué)之后很難再有大的效果提升了。
原文標(biāo)題:ICLR 2024高分投稿:用于一般時(shí)間序列分析的現(xiàn)代純卷積結(jié)構(gòu)
文章出處:【微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2909文章
44578瀏覽量
372863
原文標(biāo)題:ICLR 2024高分投稿:用于一般時(shí)間序列分析的現(xiàn)代純卷積結(jié)構(gòu)
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何使用RNN進(jìn)行時(shí)間序列預(yù)測(cè)
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】時(shí)間序列的信息提取
【《時(shí)間序列與機(jī)器學(xué)習(xí)》閱讀體驗(yàn)】+ 時(shí)間序列的信息提取
【《時(shí)間序列與機(jī)器學(xué)習(xí)》閱讀體驗(yàn)】+ 了解時(shí)間序列
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】全書(shū)概覽與時(shí)間序列概述
循環(huán)神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)的區(qū)別
卷積神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)原理
卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)和工作原理
卷積神經(jīng)網(wǎng)絡(luò)的一般步驟是什么
卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)及其功能
卷積神經(jīng)網(wǎng)絡(luò)的基本原理、結(jié)構(gòu)及訓(xùn)練過(guò)程
名單公布!【書(shū)籍評(píng)測(cè)活動(dòng)NO.35】如何用「時(shí)間序列與機(jī)器學(xué)習(xí)」解鎖未來(lái)?
數(shù)控加工工藝分析的一般步驟與方法
時(shí)間序列分析的異常檢測(cè)綜述
深度學(xué)習(xí)在時(shí)間序列預(yù)測(cè)的總結(jié)和未來(lái)方向分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論