 如何保證kafka消息不丟失
如何保證kafka消息不丟失
如果在簡歷上寫了使用過kafka消息中間件,面試官大概80%的概率會問你:"如何保證kafka消息不丟失?"反正我是屢試不爽。
如果你的核心業務數據,比如訂單數據,或者其它核心交易業務數據,在使用kafka時,要保證消息不丟失,并讓下游消費系統一定能獲得訂單數據,只靠kafka中間件來保證,是并不可靠的。
kafka已經這么的優秀 了,為什么還會丟消息了?這一定是初學者或者初級使用者心中的疑惑
kafka 已經這么的優秀了,為啥還會丟消息了?----太不省心了
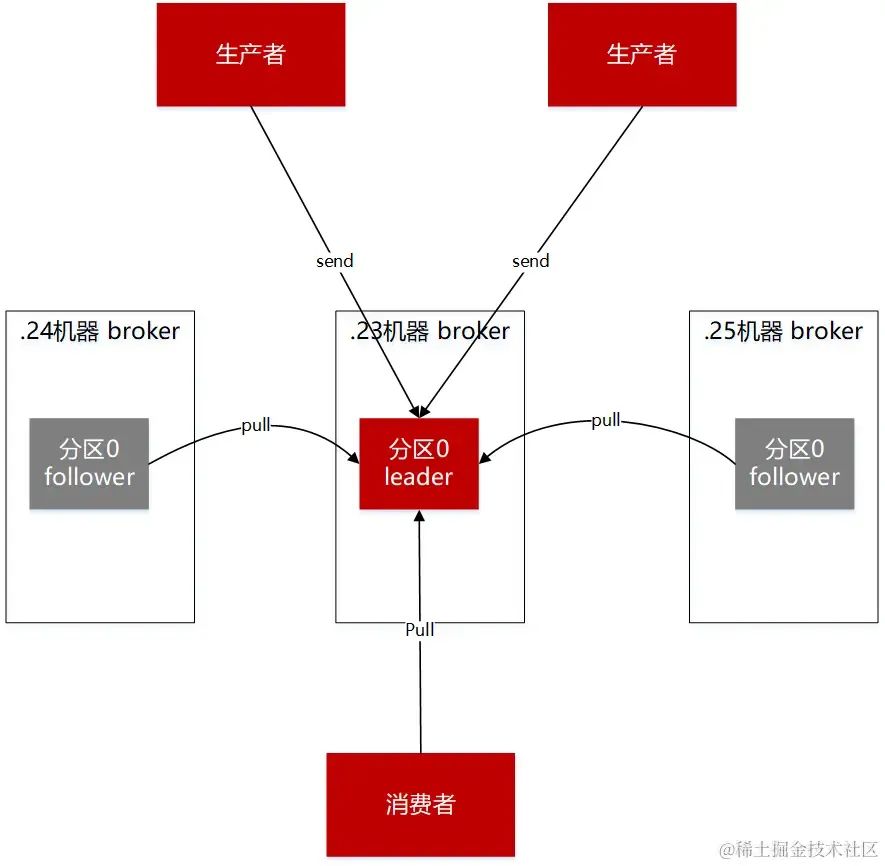
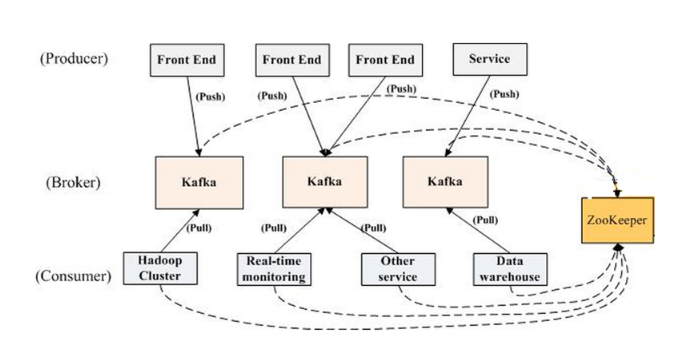
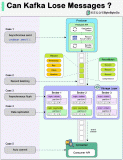
圖一 生產者,broker,消費者
要解決kafka丟失消息的情況,需要從使用kafka涉及的主流程和主要組件進行分析。kafka的核心業務流程很簡單:發送消息,暫存消息,消費消息。而這中間涉及到的主要組件,分別是生產端,broker端,消費端。
生產端丟失消息的情況和解決方法
生產端丟失消息的第一個原因主要來源于kafka的特性:批量發送異步提交。我們知道,kafka在發送消息時,是由底層的IO SEND線程進行消息的批量發送,不是由業務代碼線程執行發送的。即業務代碼線程執行完send方法后,就返回了。消息到底發送給broker側沒有了?通過send方法其實是無法知道的。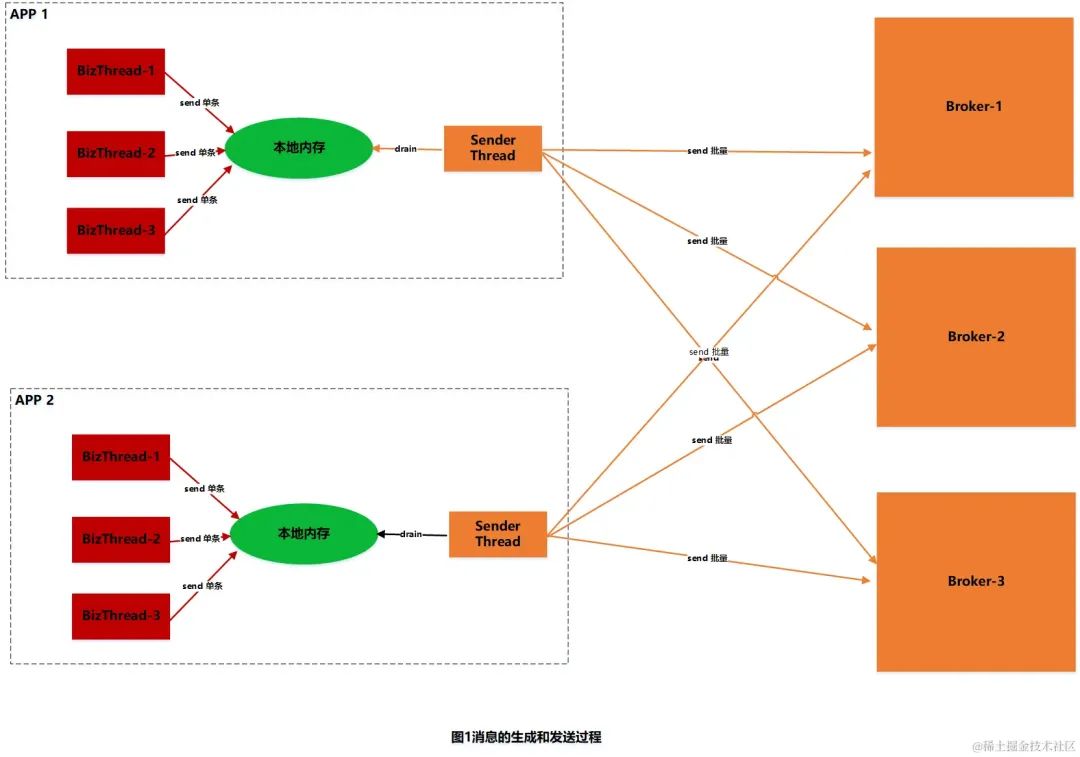
那么如何解決了?kafka提供了一個帶有callback回調函數的方法,如果消息成功/(失敗的)發送給broker端了,底層的IO線程是可以知道的,所以此時IO線程可以回調callback函數,通知上層業務應用。我們也一般在callback函數里,根據回調函數的參數,就能知道消息是否發送成功了,如果發送失敗了,那么我們還可以在callback函數里重試。一般業務場景下 通過重試的方法保證消息再次發送出去。
90%的面試者都能給出上面的標準回答。
但在一些嚴格的交易場景:僅僅依靠回調函數的通知和重試,是不能保證消息一定能發送到broker端的
理由如下:
1、callback函數是在jvm層面由IO SEND線程執行的,如果剛好遇到在執行回調函數時,jvm宕機了,或者恰好長時間的GC,最終導致OOM,或者jvm假死的情況;那么回調函數是不能被執行的。恰好你的消息數據,是一個帶有交易屬性核心業務數據,必須要通知給下游。比如下單或者支付后,需要通知傭金系統,或者積分系統,去計算訂單傭金。此時一個JVM宕機或者OOM,給下游的數據就丟了,那么計算聯盟客的訂單傭金數據也就丟了,造成聯盟客資損了。
2、IO SEND線程和broker之間是通過網絡進行通信的,而網絡通信并不一定都能保證一直都是順暢的,比如網絡丟包,網絡中的交換機壞了,由底層網絡硬件的故障,導致上層IO線程發送消息失敗;此時發送端配置的重試參數 retries 也不好使了。
如何解決生產端在極端嚴格的交易場景下,消息丟失了?
如果要解決jvm宕機,或者JVM假死;又或者底層網絡問題,帶來的消息丟失;是需要上層應用額外的機制來保證消息數據發送的完整性。大概流程如下圖
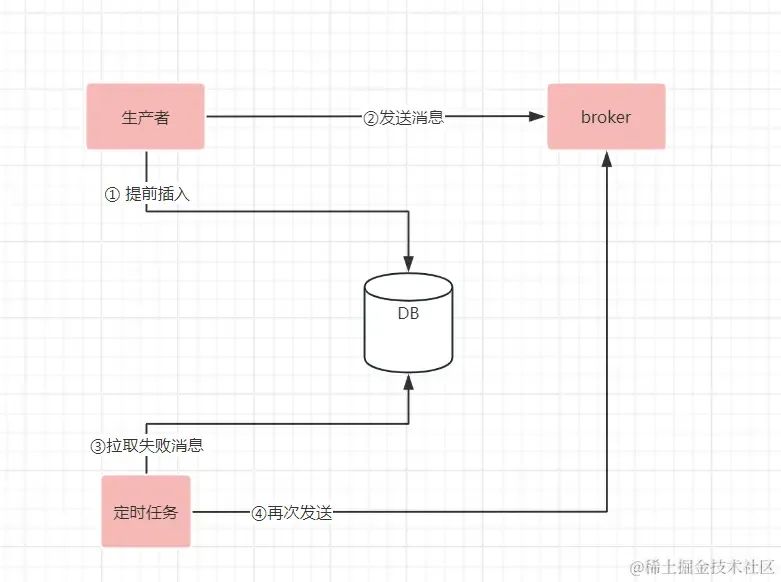
1、在發送消息之前,加一個發送記錄,并且初始化為待發送;并且把發送記錄進行存儲(可以存儲在DB里,或者其它存儲引擎里);2、利用帶有回調函數的callback通知,在業務代碼里感知到消息是否發送成功;如果消息發送成功,則把存儲引擎里對應的消息標記為已發送 3、利用延遲的定時任務,每隔5分鐘(可根據實際情況調整掃描頻率)定時掃描5分鐘前未發送或者發送失敗的消息,再次進行發送。
這樣即使應用的jvm宕機,或者底層網絡出現故障,消息是否發送的記錄,都進行了保存。通過持續的定時任務掃描和重試,能最終保證消息一定能發送出去。
broker端丟失消息的情況和解決方法
broker端接收到生產端的消息后,并成功應答生產端后,消息會丟嗎?如果broker能像mysql服務器一樣,在成功應答給客戶端前,能把消息寫入到了磁盤進行持久化,并且在宕機斷電后,有恢復機制,那么我們能說broker端不會丟消息。
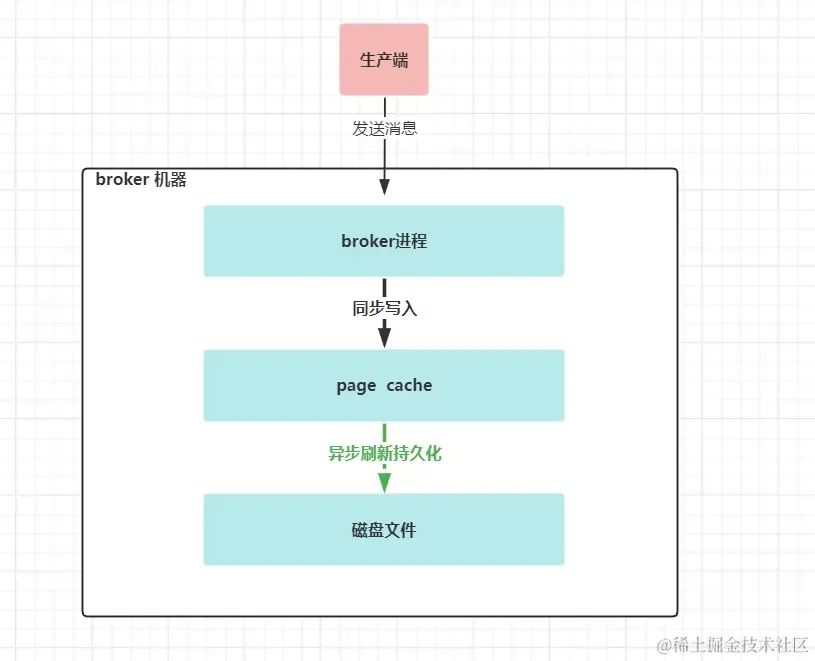
但broker端提供數據不丟的保障和mysql是不一樣的。broker端在接受了一批消息數據后,是不會馬上寫入磁盤的,而是先寫入到page cache里,這個page cache是操作系統的頁緩存(也就是另外一個內存,只是由操作系統管理,不屬于JVM管理的內存),通過定時或者定量的的方式( log.flush.interval.messages和log.flush.interval.ms)會把page cache里的數據寫入到磁盤里。
如果page cache在持久化到磁盤前,broker進程宕機了,這個時候不會丟失消息,重啟broker即可;如果此時操作系統宕機或者物理機宕機了,page cache里的數據還沒有持久化到磁盤里,此種情況數據就丟了。
kafka應對此種情況,建議是通過多副本機制來解決的,核心思想也挺簡單的:如果數據保存在一臺機器上你覺得可靠性不夠,那么我就把相同的數據保存到多臺機器上,某臺機器宕機了可以由其它機器提供相同的服務和數據。
要想達到上面效果,有三個關鍵參數需要配置
第一:生產端參數ack 設置為all
代表消息需要寫入到“大多數”的副本分區后,leader broker才給生產端應答消息寫入成功。(即寫入了“大多數”機器的page cache里)
第二:在broker端 配置min.insync.replicas參數設置至少為2
此參數代表了 上面的“大多數”副本。為2表示除了寫入leader分區外,還需要寫入到一個follower 分區副本里,broker端才會應答給生產端消息寫入成功。此參數設置需要搭配第一個參數使用。
第三:在broker端配置replicator.factor參數至少3
此參數表示:topic每個分區的副本數。如果配置為2,表示每個分區只有2個副本,在加上第二個參數消息寫入時至少寫入2個分區副本,則整個寫入邏輯就表示集群中topic的分區副本不能有一個宕機。如果配置為3,則topic的每個分區副本數為3,再加上第二個參數min.insync.replicas為2,即每次,只需要寫入2個分區副本即可,另外一個宕機也不影響,在保證了消息不丟的情況下,也能提高分區的可用性;只是有點費空間,畢竟多保存了一份相同的數據到另外一臺機器上。
另外在broker端,還有個參數unclean.leader.election.enable
此參數表示:沒有和leader分區保持數據同步的副本分區是否也能參與leader分區的選舉,建議設置為false,不允許。如果允許,這這些落后的副本分區競選為leader分區后,則之前leader分區已保存的最新數據就有丟失的風險。注意在0.11版本之前默認為TRUE。
消費端側丟失消息的情況和解決方法
消費端丟失消息的情況:消費端丟失消息的情況,主要是設置了 autoCommit為true,即消費者消費消息的位移,由消費者自動提交。
自動提交,表面上看起來挺高大上的,但這是消費端丟失消息的主要原因。實例代碼如下
while(true){
consumer.poll(); #①拉取消息
XXX #②進行業務處理;
}
如果在第一步拉取消息后,即提交了消息位移;而在第二步處理消息的時候發生了業務異常,或者jvm宕機了。則第二次在從消費端poll消息時,會從最新的位移拉取后面的消息,這樣就造成了消息的丟失。
消費端解決消息丟失也不復雜,設置autoCommit為false;然后在消費完消息后手工提交位移即可 實例代碼如下:
while(true){
consumer.poll(); #①拉取消息
XXX #②處理消息;
consumer.commit();
}
在第二步進行了業務處理后,在提交消費的消息位移;這樣即使第二步或者第三步提交位移失敗了又或者宕機了,第二次再從poll拉取消息時,則會以第一次拉取消息的位移處獲取后面的消息,以此保證了消息的不丟失。
總結
在生產端所在的jvm運行正常,底層網絡通順的情況下,通過kafka 生產端自身的retries機制和call back回調能減少一部分消息丟失情況;但并不能保證在應用層,網絡層有問題時,也能100%確保消息不丟失;如果要解決此問題,可以試試 記錄消息發送狀態+定時任務掃描+重試的機制。
在broker端,要保證消息數據不丟失;kafka提供了多副本機制來進行保證。關鍵核心參數三個,一個生產端ack=all,兩個broker端參數min.insync.replicas 寫入數據到分區最小副本數為2,并且每個分區的副本集最小為3
在消費端,要保證消息不丟失,需要設置消費端參數 autoCommit為false,并且在消息消費完后,再手工提交消息位置
審核編輯:湯梓紅
-
代碼
+關注
關注
30文章
4779瀏覽量
68524 -
線程
+關注
關注
0文章
504瀏覽量
19675 -
kafka
+關注
關注
0文章
51瀏覽量
5214
原文標題:kafka 消息“零丟失”的配方
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
kafka設計原理的深度探討
kafka數據可靠性深度解讀
流水線設計提高數據處理有沒有辦法保證數據不丟失?
sja1000跟51外部中斷只能保證8幀不丟失
Kafka集群環境的搭建
基于臭氧的Kafka自適應調優方法ENLHS
Kafka的概念及Kafka的宕機
Kafka 的簡介
物通博聯5G-kafka工業網關實現kafka協議對接到云平臺
Kafka架構技術:Kafka的架構和客戶端API設計
面試官:Kafka會丟消息嗎?





 工商網監
工商網監
評論