 十大排序算法總結
十大排序算法總結
作者:不敗頑童1號
排序算法是最經典的算法知識。因為其實現代碼短,應該廣,在面試中經常會問到排序算法及其相關的問題。一般在面試中最常考的是快速排序和歸并排序等基本的排序算法,并且經常要求現場手寫基本的排序算法。如果這些問題回答不好,估計面試就涼涼了。所以熟練掌握排序算法思想及其特點并能夠熟練地手寫代碼至關重要。
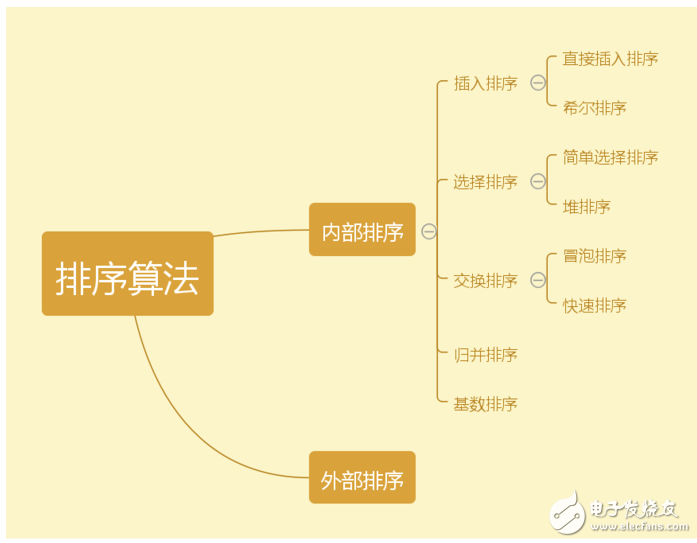
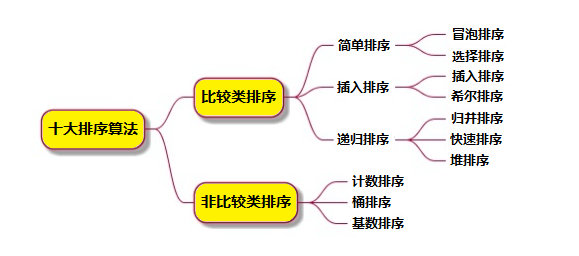
下面介紹幾種常見的排序算法:冒泡排序、選擇排序、插入排序、歸并排序、快速排序、希爾排序、堆排序、計數排序、桶排序、基數排序的思想,其代碼均采用 Java 實現。
1. 冒泡排序
冒泡排序是一種簡單的排序算法。它重復地走訪過要排序的數列,一次比較兩個元素,如果它們的順序錯誤就把它們交換過來。走訪數列的工作是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個算法的名字由來是因為越小的元素會經由交換慢慢 “浮” 到數列的頂端。
算法描述
比較相鄰的元素。如果第一個比第二個大,就交換它們兩個;
對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最后一對,這樣在最后的元素應該會是最大的數;
針對所有的元素重復以上的步驟,除了最后一個;
重復步驟 1~3,直到排序完成。
算法實現
public static void bubbleSort(int[] arr) { int temp = 0; for (int i = arr.length - 1; i > 0; i--) { for (int j = 0; j < i; j++) { if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } } }
穩定性
在相鄰元素相等時,它們并不會交換位置,所以,冒泡排序是穩定排序。
適用場景
冒泡排序思路簡單,代碼也簡單,特別適合小數據的排序。但是,由于算法復雜度較高,在數據量大的時候不適合使用。
代碼優化
在數據完全有序的時候展現出最優時間復雜度,為 O (n)。其他情況下,幾乎總是 O ( n^2 )。因此,算法在數據基本有序的情況下,性能最好。要使算法在最佳情況下有 O (n) 復雜度,需要做一些改進,增加一個swap的標志,當前一輪沒有進行交換時,說明數組已經有序,沒有必要再進行下一輪的循環了,直接退出。
public static void bubbleSort(int[] arr) {
int temp = 0;
boolean swap;
for (int i = arr.length - 1; i > 0; i--) {
swap=false;
for (int j = 0; j < i; j++) {
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swap=true;
}
}
if (swap==false){
break;
}
}
}
2. 選擇排序
選擇排序是一種簡單直觀的排序算法,它也是一種交換排序算法,和冒泡排序有一定的相似度,可以認為選擇排序是冒泡排序的一種改進。
算法描述
在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾。
重復第二步,直到所有元素均排序完畢。
算法實現
public static void selectionSort(int[] arr) { int temp, min = 0; for (int i = 0; i < arr.length - 1; i++) { min = i; for (int j = i + 1; j < arr.length; j++) { if (arr[min] > arr[j]) { min = j; } } if (min != i) { temp = arr[i]; arr[i] = arr[min]; arr[min] = temp; } } }
穩定性
用數組實現的選擇排序是不穩定的,用鏈表實現的選擇排序是穩定的。不過,一般提到排序算法時,大家往往會默認是數組實現,所以選擇排序是不穩定的。
適用場景
選擇排序實現也比較簡單,并且由于在各種情況下復雜度波動小,因此一般是優于冒泡排序的。在所有的完全交換排序中,選擇排序也是比較不錯的一種算法。但是,由于固有的 O (n^2) 復雜度,選擇排序在海量數據面前顯得力不從心。因此,它適用于簡單數據排序。
3. 插入排序
插入排序是一種簡單直觀的排序算法。它的工作原理是通過構建有序序列,對于未排序數據,在已排序序列中從后向前掃描,找到相應位置并插入。
算法描述
把待排序的數組分成已排序和未排序兩部分,初始的時候把第一個元素認為是已排好序的。
從第二個元素開始,在已排好序的子數組中尋找到該元素合適的位置并插入該位置。
重復上述過程直到最后一個元素被插入有序子數組中。
算法實現
public static void insertionSort(int[] arr){
for (int i=1; i0 && arr[position-1]>value){
arr[position] = arr[position-1];
position--;
}
arr[position] = value;
}
}
穩定性
由于只需要找到不大于當前數的位置而并不需要交換,因此,直接插入排序是穩定的排序方法。
適用場景
插入排序由于 O (n^2) 的復雜度,在數組較大的時候不適用。但是,在數據比較少的時候,是一個不錯的選擇,一般做為快速排序的擴充。例如,在 STL 的 sort 算法和 stdlib 的 qsort 算法中,都將插入排序作為快速排序的補充,用于少量元素的排序。又如,在 JDK 7 java.util.Arrays 所用的 sort 方法的實現中,當待排數組長度小于 47 時,會使用插入排序。
4. 歸并排序
歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法的一個非常典型的應用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為 2 - 路歸并。
算法描述
兩種方法
遞歸法(Top-down)
申請空間,使其大小為兩個已經排序序列之和,該空間用來存放合并后的序列
設定兩個指針,最初位置分別為兩個已經排序序列的起始位置
比較兩個指針所指向的元素,選擇相對小的元素放入到合并空間,并移動指針到下一位置
重復步驟 3 直到某一指針到達序列尾
將另一序列剩下的所有元素直接復制到合并序列尾
迭代法(Bottom-up)
原理如下(假設序列共有 n 個元素):
將序列每相鄰兩個數字進行歸并操作,形成 ceil (n/2) 個序列,排序后每個序列包含兩 / 一個元素
若此時序列數不是 1 個則將上述序列再次歸并,形成 ceil (n/4) 個序列,每個序列包含四 / 三個元素
重復步驟 2,直到所有元素排序完畢,即序列數為 1
算法實現
public static void mergeSort(int[] arr){
int[] temp =new int[arr.length];
internalMergeSort(arr, temp, 0, arr.length-1);
}
private static void internalMergeSort(int[] arr, int[] temp, int left, int right){
if (left
穩定性
因為我們在遇到相等的數據的時候必然是按順序 “抄寫” 到輔助數組上的,所以,歸并排序同樣是穩定算法。
適用場景
歸并排序在數據量比較大的時候也有較為出色的表現(效率上),但是,其空間復雜度 O (n) 使得在數據量特別大的時候(例如,1 千萬數據)幾乎不可接受。而且,考慮到有的機器內存本身就比較小,因此,采用歸并排序一定要注意。
5. 快速排序
快速排序是一個知名度極高的排序算法,其對于大數據的優秀排序性能和相同復雜度算法中相對簡單的實現使它注定得到比其他算法更多的寵愛。
算法描述
從數列中挑出一個元素,稱為 "基準"(pivot),
重新排序數列,所有比基準值小的元素擺放在基準前面,所有比基準值大的元素擺在基準后面(相同的數可以到任何一邊)。在這個分區結束之后,該基準就處于數列的中間位置。這個稱為分區(partition)操作。
遞歸地(recursively)把小于基準值元素的子數列和大于基準值元素的子數列排序。
動圖演示
快速排序
算法實現
public static void quickSort(int[] arr){
qsort(arr, 0, arr.length-1);
}
private static void qsort(int[] arr, int low, int high){
if (low >= high)
return;
int pivot = partition(arr, low, high);
qsort(arr, low, pivot-1);
qsort(arr, pivot+1, high);
}
private static int partition(int[] arr, int low, int high){
int pivot = arr[low];
while (low < high){
while (low < high && arr[high] >= pivot) --high;
arr[low]=arr[high];
while (low < high && arr[low] <= pivot) ++low;
arr[high] = arr[low];
}
arr[low] = pivot;
return low;
}
穩定性
快速排序并不是穩定的。這是因為我們無法保證相等的數據按順序被掃描到和按順序存放。
適用場景
快速排序在大多數情況下都是適用的,尤其在數據量大的時候性能優越性更加明顯。但是在必要的時候,需要考慮下優化以提高其在最壞情況下的性能。
6. 堆排序
堆排序 (Heapsort) 是指利用堆積樹(堆)這種數據結構所設計的一種排序算法,它是選擇排序的一種。可以利用數組的特點快速定位指定索引的元素。堆排序就是把最大堆堆頂的最大數取出,將剩余的堆繼續調整為最大堆,再次將堆頂的最大數取出,這個過程持續到剩余數只有一個時結束。
堆的概念
堆是一種特殊的完全二叉樹(complete binary tree)。完全二叉樹的一個 “優秀” 的性質是,除了最底層之外,每一層都是滿的,這使得堆可以利用數組來表示(普通的一般的二叉樹通常用鏈表作為基本容器表示),每一個結點對應數組中的一個元素。如下圖,是一個堆和數組的相互關系:
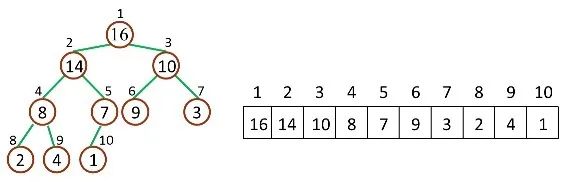
image 對于給定的某個結點的下標 i,可以很容易的計算出這個結點的父結點、孩子結點的下標:
Parent (i) = floor (i/2),i 的父節點下標
Left (i) = 2i,i 的左子節點下標
Right (i) = 2i + 1,i 的右子節點下標
二叉堆一般分為兩種:最大堆和最小堆。最大堆:最大堆中的最大元素值出現在根結點(堆頂) 堆中每個父節點的元素值都大于等于其孩子結點(如果存在)
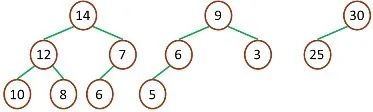
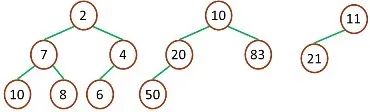
image 最小堆:最小堆中的最小元素值出現在根結點(堆頂) 堆中每個父節點的元素值都小于等于其孩子結點(如果存在)
image
堆排序原理
堆排序就是把最大堆堆頂的最大數取出,將剩余的堆繼續調整為最大堆,再次將堆頂的最大數取出,這個過程持續到剩余數只有一個時結束。在堆中定義以下幾種操作:
最大堆調整(Max-Heapify):將堆的末端子節點作調整,使得子節點永遠小于父節點
創建最大堆(Build-Max-Heap):將堆所有數據重新排序,使其成為最大堆
堆排序(Heap-Sort):移除位在第一個數據的根節點,并做最大堆調整的遞歸運算 繼續進行下面的討論前,需要注意的一個問題是:數組都是 Zero-Based,這就意味著我們的堆數據結構模型要發生改變
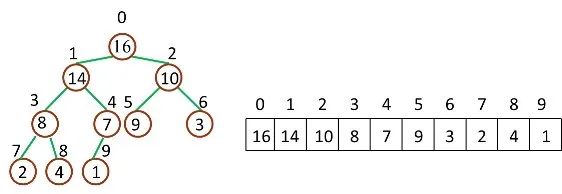
image 相應的,幾個計算公式也要作出相應調整:
Parent (i) = floor ((i-1)/2),i 的父節點下標
Left (i) = 2i + 1,i 的左子節點下標
Right (i) = 2 (i + 1),i 的右子節點下標
堆的建立和維護
堆可以支持多種操作,但現在我們關心的只有兩個問題:
給定一個無序數組,如何建立為堆?
刪除堆頂元素后,如何調整數組成為新堆?
先看第二個問題。假定我們已經有一個現成的大根堆。現在我們刪除了根元素,但并沒有移動別的元素。想想發生了什么:根元素空了,但其它元素還保持著堆的性質。我們可以把最后一個元素(代號 A)移動到根元素的位置。如果不是特殊情況,則堆的性質被破壞。但這僅僅是由于 A 小于其某個子元素。于是,我們可以把 A 和這個子元素調換位置。如果 A 大于其所有子元素,則堆調整好了;否則,重復上述過程,A 元素在樹形結構中不斷 “下沉”,直到合適的位置,數組重新恢復堆的性質。上述過程一般稱為 “篩選”,方向顯然是自上而下。
刪除后的調整,是把最后一個元素放到堆頂,自上而下比較
刪除一個元素是如此,插入一個新元素也是如此。不同的是,我們把新元素放在末尾,然后和其父節點做比較,即自下而上篩選。
插入是把新元素放在末尾,自下而上比較
那么,第一個問題怎么解決呢? 常規方法是從第一個非葉子結點向下篩選,直到根元素篩選完畢。這個方法叫 “篩選法”,需要循環篩選 n/2 個元素。 但我們還可以借鑒 “插入排序” 的思路。我們可以視第一個元素為一個堆,然后不斷向其中添加新元素。這個方法叫做 “插入法”,需要循環插入 (n-1) 個元素。 由于篩選法和插入法的方式不同,所以,相同的數據,它們建立的堆一般不同。大致了解堆之后,堆排序就是水到渠成的事情了。
動圖演示
image
算法描述
我們需要一個升序的序列,怎么辦呢?我們可以建立一個最小堆,然后每次輸出根元素。但是,這個方法需要額外的空間(否則將造成大量的元素移動,其復雜度會飆升到 O (n^2) )。如果我們需要就地排序(即不允許有 O (n) 空間復雜度),怎么辦? 有辦法。我們可以建立最大堆,然后我們倒著輸出,在最后一個位置輸出最大值,次末位置輸出次大值…… 由于每次輸出的最大元素會騰出第一個空間,因此,我們恰好可以放置這樣的元素而不需要額外空間。很漂亮的想法,是不是?
算法實現
public class ArrayHeap {
private int[] arr;
public ArrayHeap(int[] arr) {
this.arr = arr;
}
private int getParentIndex(int child) {
return (child - 1) / 2;
}
private int getLeftChildIndex(int parent) {
return 2 * parent + 1;
}
private void swap(int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
private void adjustHeap(int i, int len) {
int left, right, j;
left = getLeftChildIndex(i);
while (left <= len) {
right = left + 1;
j = left;
if (j < len && arr[left] < arr[right]) {
j++;
}
if (arr[i] < arr[j]) {
swap(array, i, j);
i = j;
left = getLeftChildIndex(i);
} else {
break;
}
}
}
public void sort() {
int last = arr.length - 1;
for (int i = getParentIndex(last); i >= 0; --i) {
adjustHeap(i, last);
}
while (last >= 0) {
swap(0, last--);
adjustHeap(0, last);
}
}
}
穩定性
堆排序存在大量的篩選和移動過程,屬于不穩定的排序算法。
適用場景
堆排序在建立堆和調整堆的過程中會產生比較大的開銷,在元素少的時候并不適用。但是,在元素比較多的情況下,還是不錯的一個選擇。尤其是在解決諸如 “前 n 大的數” 一類問題時,幾乎是首選算法。
7. 希爾排序(插入排序的改良版)
在希爾排序出現之前,計算機界普遍存在 “排序算法不可能突破 O (n2)” 的觀點。希爾排序是第一個突破 O (n2) 的排序算法,它是簡單插入排序的改進版。希爾排序的提出,主要基于以下兩點:
插入排序算法在數組基本有序的情況下,可以近似達到 O (n) 復雜度,效率極高。
但插入排序每次只能將數據移動一位,在數組較大且基本無序的情況下性能會迅速惡化。
算法描述
先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,具體算法描述:
選擇一個增量序列 t1,t2,…,tk,其中 ti>tj,tk=1;
按增量序列個數 k,對序列進行 k 趟排序;
每趟排序,根據對應的增量 ti,將待排序列分割成若干長度為 m 的子序列,分別對各子表進行直接插入排序。僅增量因子為 1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
動圖演示
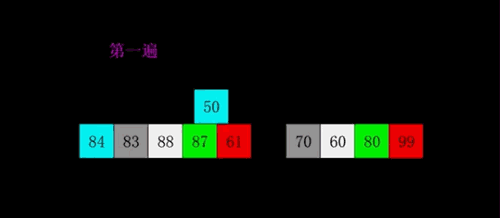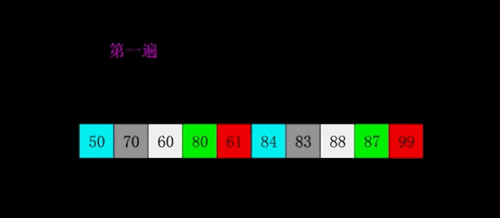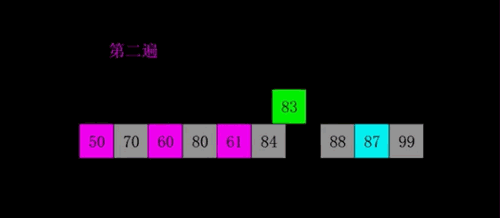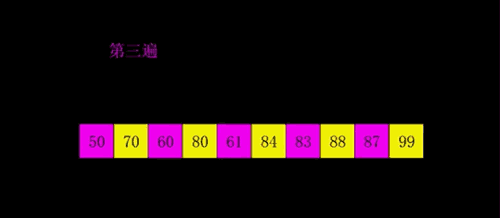
image
算法實現
Donald Shell 增量
public static void shellSort(int[] arr){
int temp;
for (int delta = arr.length/2; delta>=1; delta/=2){
for (int i=delta; i=delta && arr[j]
O(n^(3/2)) by Knuth
public static void shellSort2(int[] arr){
int delta = 1;
while (delta < arr.length/3){
delta=delta*3+1;
}
int temp;
for (; delta>=1; delta/=3){
for (int i=delta; i=delta && arr[j]
希爾排序的增量
希爾排序的增量數列可以任取,需要的唯一條件是最后一個一定為 1(因為要保證按 1 有序)。但是,不同的數列選取會對算法的性能造成極大的影響。上面的代碼演示了兩種增量。切記:增量序列中每兩個元素最好不要出現 1 以外的公因子!(很顯然,按 4 有序的數列再去按 2 排序意義并不大)。下面是一些常見的增量序列。
第一種增量是最初 Donald Shell 提出的增量,即折半降低直到 1。據研究,使用希爾增量,其時間復雜度還是 O (n2)。
第二種增量 Hibbard:{1, 3, ..., 2k-1}。該增量序列的時間復雜度大約是 O (n1.5)。 第三種增量 Sedgewick 增量:(1, 5, 19, 41, 109,...),其生成序列或者是 94^i - 92^i + 1 或者是 4^i - 3*2^i + 1。
穩定性
我們都知道插入排序是穩定算法。但是,Shell 排序是一個多次插入的過程。在一次插入中我們能確保不移動相同元素的順序,但在多次的插入中,相同元素完全有可能在不同的插入輪次被移動,最后穩定性被破壞,因此,Shell 排序不是一個穩定的算法。
適用場景
Shell 排序雖然快,但是畢竟是插入排序,其數量級并沒有后起之秀 -- 快速排序 O (n㏒n) 快。在大量數據面前,Shell 排序不是一個好的算法。但是,中小型規模的數據完全可以使用它。
8、計數排序
計數排序不是基于比較的排序算法,其核心在于將輸入的數據值轉化為鍵存儲在額外開辟的數組空間中。作為一種線性時間復雜度的排序,計數排序要求輸入的數據必須是有確定范圍的整數。
算法描述
找出待排序的數組中最大和最小的元素;
統計數組中每個值為 i 的元素出現的次數,存入數組 C 的第 i 項;
對所有的計數累加(從 C 中的第一個元素開始,每一項和前一項相加);
反向填充目標數組:將每個元素 i 放在新數組的第 C (i) 項,每放一個元素就將 C (i) 減去 1。
動圖演示
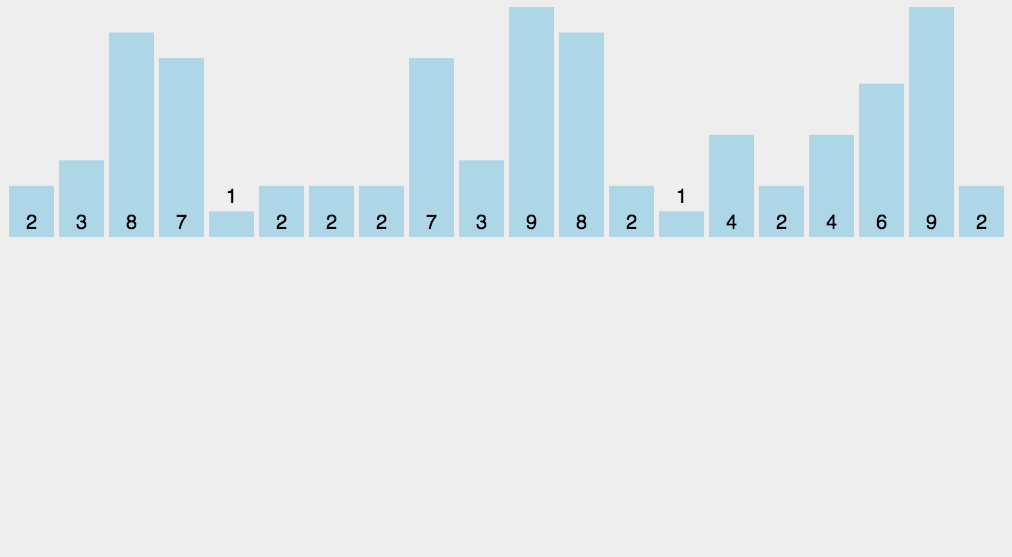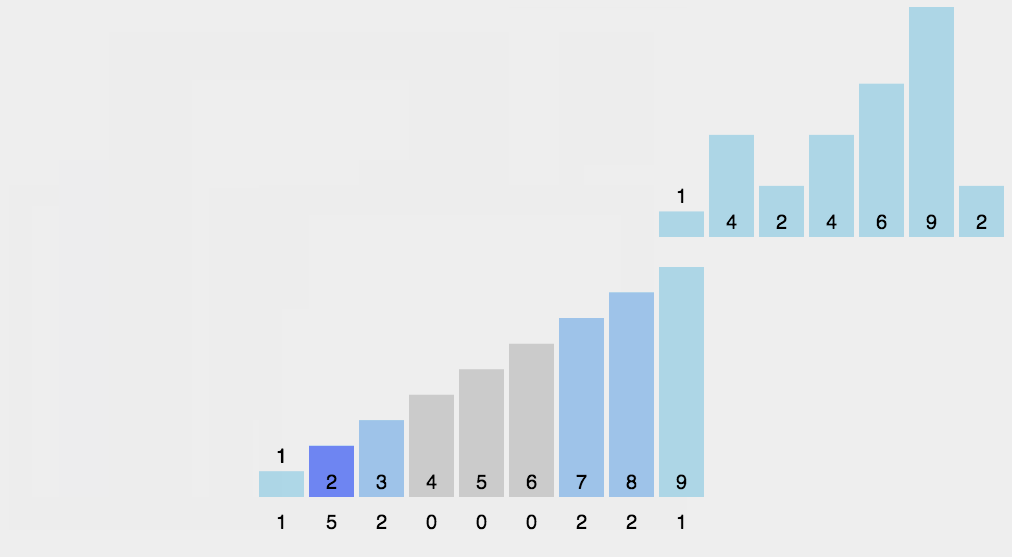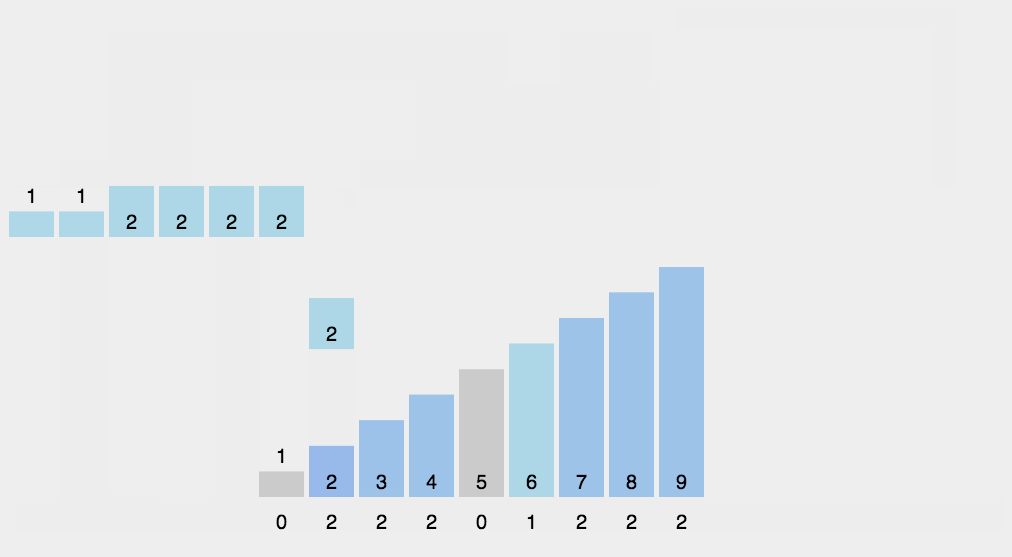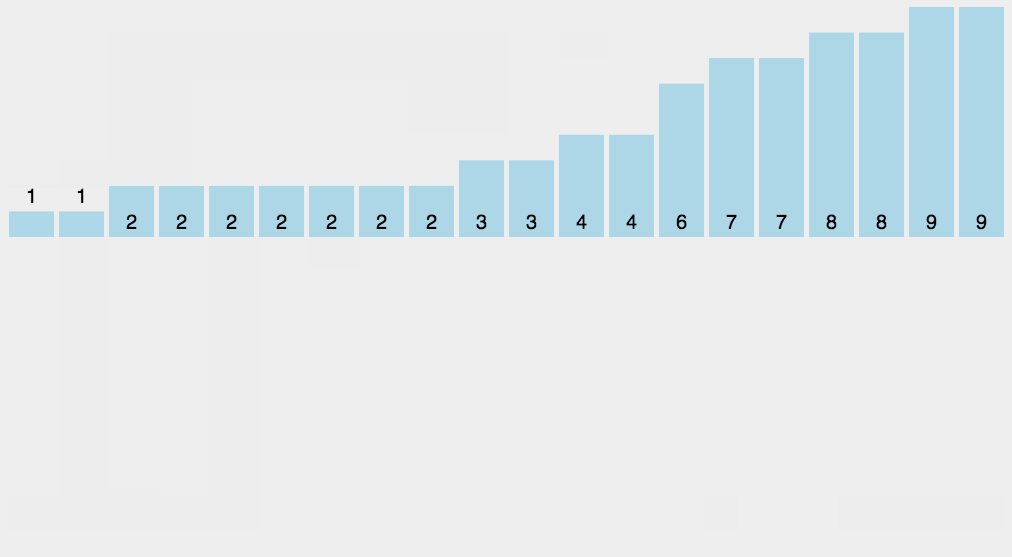
image
算法實現
public static void countSort(int[] a, int max, int min) {
int[] b = new int[a.length];
int[] count = new int[max - min + 1];
for (int num = min; num <= max; num++) {
count[num - min] = 0;
}
for (int i = 0; i < a.length; i++) {
int num = a[i];
count[num - min]++;
}
for (int num = min + 1; num <= max; num++) {
count[num - min] += sum[num - min - 1]
}
for (int i = 0; i < a.length; i++) {
int num = a[i];
int index = count[num - min] - 1;
b[index] = num;
count[num - min]--;
}
for(int i=0;i
穩定性
最后給 b 數組賦值是倒著遍歷的,而且放進去一個就將 C 數組對應的值(表示前面有多少元素小于或等于 A [i])減去一。如果有相同的數 x1,x2,那么相對位置后面那個元素 x2 放在(比如下標為 4 的位置),相對位置前面那個元素 x1 下次進循環就會被放在 x2 前面的位置 3。從而保證了穩定性。
適用場景
排序目標要能夠映射到整數域,其最大值最小值應當容易辨別。例如高中生考試的總分數,顯然用 0-750 就 OK 啦;又比如一群人的年齡,用個 0-150 應該就可以了,再不濟就用 0-200 嘍。另外,計數排序需要占用大量空間,它比較適用于數據比較集中的情況。
9、桶排序
桶排序又叫箱排序,是計數排序的升級版,它的工作原理是將數組分到有限數量的桶子里,然后對每個桶子再分別排序(有可能再使用別的排序算法或是以遞歸方式繼續使用桶排序進行排序),最后將各個桶中的數據有序的合并起來。
計數排序是桶排序的一種特殊情況,可以把計數排序當成每個桶里只有一個元素的情況。網絡中很多博文寫的桶排序實際上都是計數排序,并非標準的桶排序,要注意辨別。
算法描述
找出待排序數組中的最大值 max、最小值 min
我們使用 動態數組 ArrayList 作為桶,桶里放的元素也用 ArrayList 存儲。桶的數量為 (max-min)/arr.length+1
遍歷數組 arr,計算每個元素 arr [i] 放的桶
每個桶各自排序
遍歷桶數組,把排序好的元素放進輸出數組
圖片演示
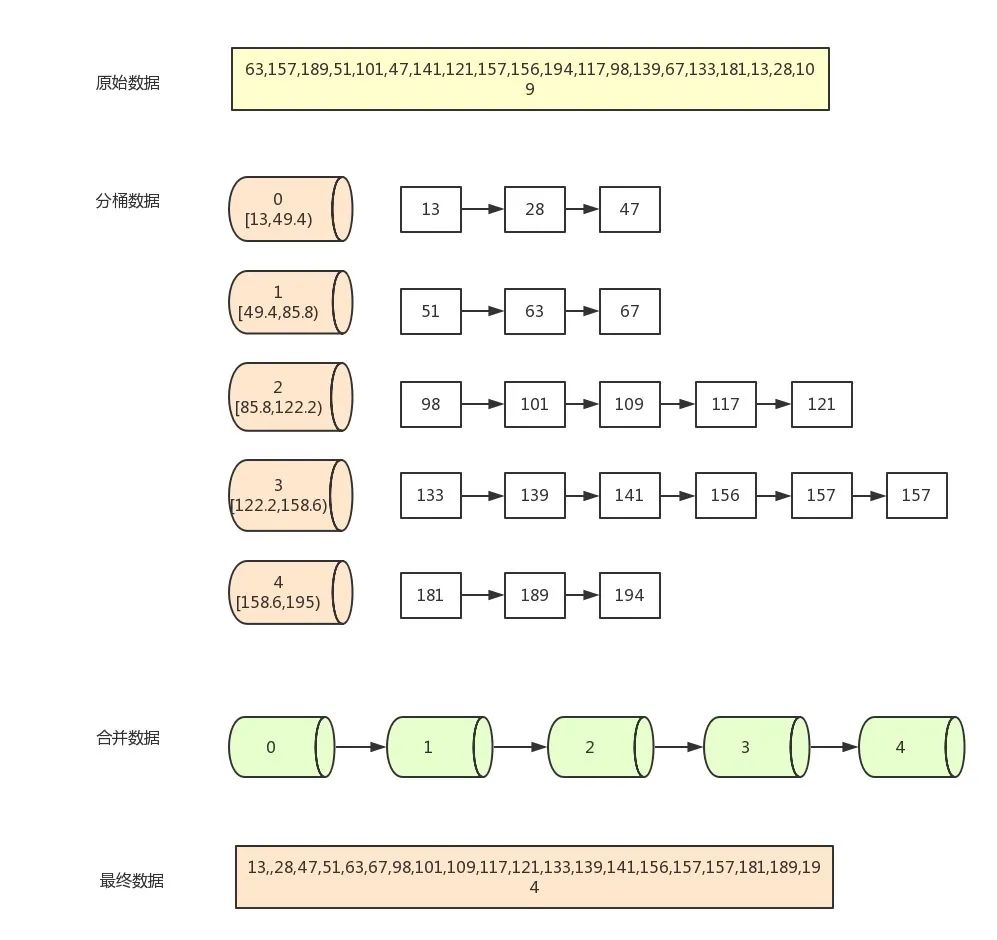
image
算法實現
public static void bucketSort(int[] arr){
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
int bucketNum = (max - min) / arr.length + 1;
ArrayList> bucketArr = new ArrayList<>(bucketNum);
for(int i = 0; i < bucketNum; i++){
bucketArr.add(new ArrayList());
}
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
}
System.out.println(bucketArr.toString());
}
穩定性
可以看出,在分桶和從桶依次輸出的過程是穩定的。但是,由于我們在對每個桶進行排序時使用了其他算法,所以,桶排序的穩定性依賴于這一步。如果我們使用了快排,顯然,算法是不穩定的。
適用場景
桶排序可用于最大最小值相差較大的數據情況,但桶排序要求數據的分布必須均勻,否則可能導致數據都集中到一個桶中。比如 [104,150,123,132,20000], 這種數據會導致前 4 個數都集中到同一個桶中。導致桶排序失效。
10、基數排序
基數排序 (Radix Sort) 是桶排序的擴展,它的基本思想是:將整數按位數切割成不同的數字,然后按每個位數分別比較。排序過程:將所有待比較數值(正整數)統一為同樣的數位長度,數位較短的數前面補零。然后,從最低位開始,依次進行一次排序。這樣從最低位排序一直到最高位排序完成以后,數列就變成一個有序序列。
算法描述
取得數組中的最大數,并取得位數;
arr 為原始數組,從最低位開始取每個位組成 radix 數組;
對 radix 進行計數排序(利用計數排序適用于小范圍數的特點);
動圖

image
算法實現
public abstract class Sorter {
public abstract void sort(int[] array);
}
public class RadixSorter extends Sorter {
private int radix;
public RadixSorter() {
radix = 10;
}
@Override
public void sort(int[] array) {
int[][] bucket = new int[radix][array.length];
int distance = getDistance(array);
int temp = 1;
int round = 1;
while (round <= distance) {
int[] counter = new int[radix];
for (int i = 0; i < array.length; i++) {
int which = (array[i] / temp) % radix;
bucket[which][counter[which]] = array[i];
counter[which]++;
}
int index = 0;
for (int i = 0; i < radix; i++) {
if (counter[i] != 0)
for (int j = 0; j < counter[i]; j++) {
array[index] = bucket[i][j];
index++;
}
counter[i] = 0;
}
temp *= radix;
round++;
}
}
private int getDistance(int[] array) {
int max = computeMax(array);
int digits = 0;
int temp = max / radix;
while(temp != 0) {
digits++;
temp = temp / radix;
}
return digits + 1;
}
private int computeMax(int[] array) {
int max = array[0];
for(int i=1; imax) {
max = array[i];
}
}
return max;
}
}
穩定性
通過上面的排序過程,我們可以看到,每一輪映射和收集操作,都保持從左到右的順序進行,如果出現相同的元素,則保持他們在原始數組中的順序。可見,基數排序是一種穩定的排序。
適用場景
基數排序要求較高,元素必須是整數,整數時長度 10W 以上,最大值 100W 以下效率較好,但是基數排序比其他排序好在可以適用字符串,或者其他需要根據多個條件進行排序的場景,例如日期,先排序日,再排序月,最后排序年 ,其它排序算法可是做不了的。
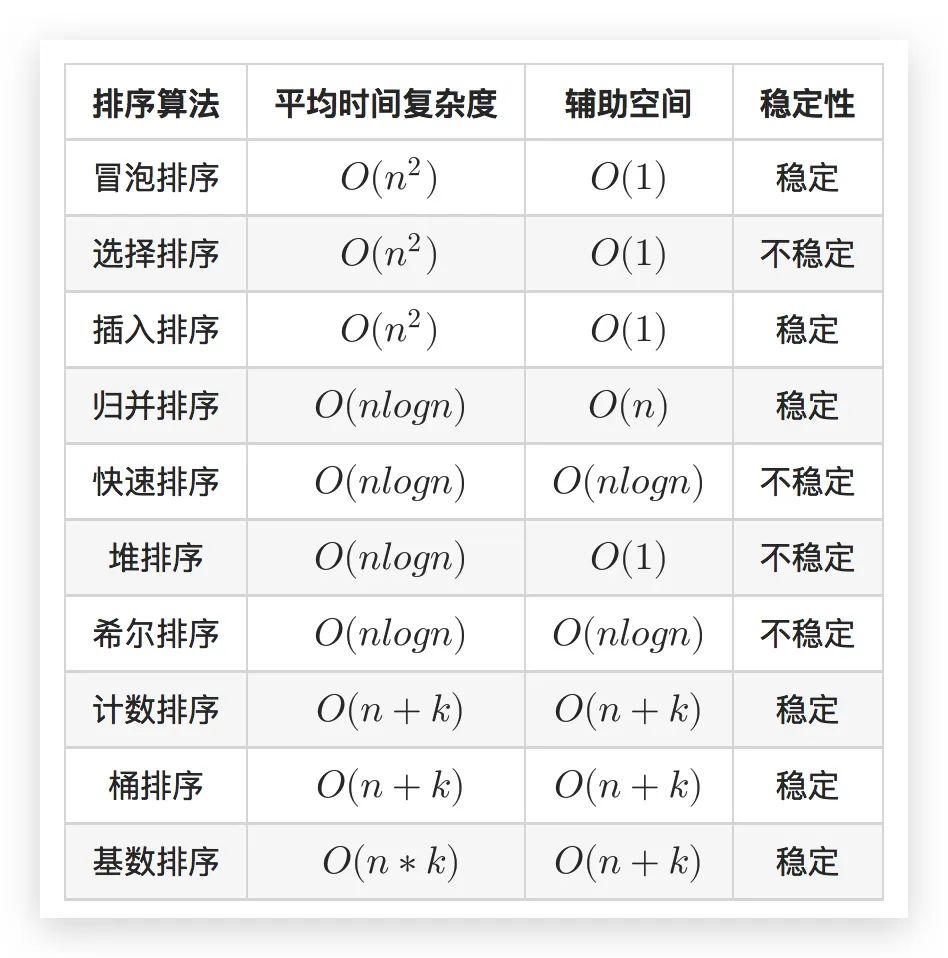
總結
審核編輯:湯梓紅
-
JAVA
+關注
關注
19文章
2966瀏覽量
104702 -
代碼
+關注
關注
30文章
4779瀏覽量
68524 -
排序算法
+關注
關注
0文章
52瀏覽量
10056
原文標題:【算法總結]】十大排序算法
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《Visual C# 2008程序設計經典案例設計與實現》---利用冒泡算法實現從小到大排序
汽車led大燈十大排名
行車記錄儀十大排名
程序員的內功:C語言八大排序算法
C++中十大排序算法前五個詳解
C++基礎語法十大排序算法后五個分享

空氣凈化器十大排名,口碑最好的空氣凈化器排名推薦






 工商網監
工商網監
評論