 深入理解RCU:玩具式實現
深入理解RCU:玩具式實現
1、基于鎖的****RCU
也許最簡單的RCU實現就是用鎖了,如下圖所示。在該實現中,rcu_read_lock()獲取一把全局自旋鎖,rcu_read_unlock()釋放鎖,而synchronize_rcu()獲取自旋鎖,隨后將其釋放。
1 static void rcu_read_lock(void)
2 {
3 spin_lock(&rcu_gp_lock);
4 }
5
6 static void rcu_read_unlock(void)
7 {
8 spin_unlock(&rcu_gp_lock);
9 }
10
11 void synchronize_rcu(void)
12 {
13 spin_lock(&rcu_gp_lock);
14 spin_unlock(&rcu_gp_lock);
15 }
基于鎖的RCU實現
因為synchronize_rcu()只有在獲取鎖(然后釋放)以后才會返回,所以在所有之前發生的RCU讀端臨界區完成前,synchronize_rcu()是不會返回的,因此這符合RCU的語義,特別是存在擔保方面的語義。
但是,在這樣的實現中,一個讀端臨界區同時只能有一個RCU讀者進入,這基本上可以說是和RCU的目的相反。而且,rcu_read_lock()和rcu_read_unlock()中的鎖操作開銷是極大的,讀端的開銷從Power5單核CPU上的100納秒到64核系統上的17微秒不等。更糟的是,使用同一把鎖使得rcu_read_lock(),可能會使得系統形成自旋鎖死鎖。這是因為:RCU的語義允許RCU讀端嵌套。所以,在這樣的實現中,RCU讀端臨界區不能嵌套。最后一點,原則上并發的RCU更新操作可以共享一個公共的優雅周期,但是該實現將優雅周期串行化了,因此無法共享優雅周期。
問題:這樣的死鎖情景會不會出現其他RCU實現中?
問題:為什么不直接用讀寫鎖來實現這個RCU?
很難想象這種實現能用在任何一個產品中,但是這種實現有一點好處:可以用在幾乎所有的用戶態程序上。不僅如此,類似的使用每CPU鎖或者讀寫鎖的實現還曾經用于Linux 2.4內核中。
2、基于每線程鎖的RCU
下圖顯示了一種基于每線程鎖的實現。rcu_read_lock()和rcu_read_unlock()分別獲取和釋放當前線程的鎖。synchronize_rcu()函數按照次序逐一獲取和釋放每個線程的鎖。這樣,所有在synchronize_rcu()開始時就已經執行的RCU讀端臨界區,必須在synchronize_rcu()結束前返回。
1 static void rcu_read_lock(void)
2 {
3 spin_lock(&__get_thread_var(rcu_gp_lock));
4 }
5
6 static void rcu_read_unlock(void)
7 {
8 spin_unlock(&__get_thread_var(rcu_gp_lock));
9 }
10
11 void synchronize_rcu(void)
12 {
13 int t;
14
15 for_each_running_thread(t) {
16 spin_lock(&per_thread(rcu_gp_lock, t));
17 spin_unlock(&per_thread(rcu_gp_lock, t));
18 }
19 }
基于鎖的每線程RCU實現
該實現的優點在于:允許并發的RCU讀者,同時避免了使用單個全局鎖可能造成的死鎖。不僅如此,讀端開銷雖然高達大概140納秒,但是不管CPU數目為多少,始終保持在140納秒。不過,更新端的開銷則在從Power5單核上的600納秒到64核系統上的超過100微秒不等。
問題:如果在第15至18行看,先獲取所有鎖,然后再釋放所有鎖,這樣是不是更清晰一點呢?
問題:該實現能夠避免死鎖嗎?如果能,為什么能?如果不能,為什么不能?
本方法在某些情況下是很有效的,尤其是類似的方法曾在Linux 2.4內核中使用。
下面提到的基于計數的RCU實現,克服了基于鎖實現的某些缺點。
3、基于計數的簡單RCU實現
1 atomic_t rcu_refcnt;
2
3 static void rcu_read_lock(void)
4 {
5 atomic_inc(&rcu_refcnt);
6 smp_mb();
7 }
8
9 static void rcu_read_unlock(void)
10 {
11 smp_mb();
12 atomic_dec(&rcu_refcnt);
13 }
14
15 void synchronize_rcu(void)
16 {
17 smp_mb();
18 while (atomic_read(&rcu_refcnt) != 0) {
19 poll(NULL, 0, 10);
20 }
21 smp_mb();
22 }
使用單個全局引用計數的RCU實現
這是一種稍微復雜一點的RCU實現。本方法在第1行定義了一個全局引用計數rcu_refcnt。rcu_read_lock()原語自動增加計數,然后執行一個內存屏障,確保在原子自增之后才進入RCU讀端臨界區。同樣,rcu_read_unlock()先執行一個內存屏障,劃定RCU讀端臨界區的結束點,然后再原子自減計數。synchronize_rcu()原語不停自旋,等待引用計數的值變為0,語句前后用內存屏障保護正確的順序。第19行的poll()只是純粹的延時,從純RCU語義的角度上看是可以省略的。等synchronize_rcu()返回后,所有之前發生的RCU讀端臨界區都已經完成了。
與基于鎖的實現相比,我們欣喜地發現:這種實現可以讓讀者并發進入RCU讀端臨界區。與基于每線程鎖的實現相比,我們又欣喜地發現:本節的實現可以讓RCU讀端臨界區嵌套。另外,rcu_read_lock()原語不會進入死鎖循環,因為它既不自旋也不阻塞。
問題:但是如果你在調用synchronize_rcu()時持有一把鎖,然后又在RCU讀端臨界區中獲取同一把鎖,會發生什么呢?
當然,這個實現還是存在一些嚴重的缺點。首先,rcu_read_lock()和rcu_read_unlock()中的原子操作開銷是非常大的,讀端開銷從Power5單核CPU上的100納秒到64核系統上的40微秒不等。這意味著RCU讀端臨界區必須非常長,才能夠滿足現實世界中的讀端并發請求。但是從另一方面來說,當沒有讀者時,優雅周期只有差不多40納秒,這比Linux內核中的產品級實現要快上很多個數量級。
其次,如果存在多個并發的rcu_read_lock()和rcu_read_unlock()操作,因為出現大量高速緩沖未命中,對rcu_refcnt的內存訪問競爭將會十分激烈。
以上這兩個缺點極大地影響RCU的目標,即提供一種讀端低開銷的同步原語。
最后,在很長的讀端臨界區中的大量RCU讀者甚至會讓synchronize_rcu()無法完成,因為全局計數可能永遠不為0。這會導致RCU更新端的饑餓,這一點在產品級應用里肯定是不可接受的。
問題:當synchronize_rcu()等待時間過長了以后,為什么不能簡單地讓rcu_read_lock()暫停一會兒呢?這種做法不能防止synchronize_rcu()饑餓嗎?
通過上述內容,很難想象本節的實現可以在產品級應用中使用,雖然它比基于鎖的實現更有這方面的潛力,比如,作為一種高負荷調試環境中的RCU實現。下面我們將介紹一種對寫者更有利的引用計數RCU變體。
4、不會讓更新者饑餓的引用計數RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 atomic_t rcu_refcnt[2];
3 atomic_t rcu_idx;
4 DEFINE_PER_THREAD(int, rcu_nesting);
5 DEFINE_PER_THREAD(int, rcu_read_idx);
RCU全局引用計數對的數據定義
下圖展示了一種RCU實現的讀端原語,使用一對引用計數(rcu_refcnt[]),通過一個全局索引(rcu_idx)從這對計數中選出一個計數,一個每線程的嵌套計數rcu_nesting,一個每線程的全局索引快照(rcu_read_idx),以及一個全局鎖(rcu_gp_lock),上圖給出了上述定義。
1 static void rcu_read_lock(void)
2 {
3 int i;
4 int n;
5
6 n = __get_thread_var(rcu_nesting);
7 if (n == 0) {
8 i = atomic_read(&rcu_idx);
9 __get_thread_var(rcu_read_idx) = i;
10 atomic_inc(&rcu_refcnt[i]);
11 }
12 __get_thread_var(rcu_nesting) = n + 1;
13 smp_mb();
14 }
15
16 static void rcu_read_unlock(void)
17 {
18 int i;
19 int n;
20
21 smp_mb();
22 n = __get_thread_var(rcu_nesting);
23 if (n == 1) {
24 i = __get_thread_var(rcu_read_idx);
25 atomic_dec(&rcu_refcnt[i]);
26 }
27 __get_thread_var(rcu_nesting) = n - 1;
28 }
使用全局引用計數對的RCU讀端原語
擁有兩個元素的rcu_refcnt[]數組讓更新者免于饑餓。這里的關鍵點是synchronize_rcu()只需要等待已存在的讀者。如果在給定實例的synchronize_rcu()正在執行時,出現一個新的讀者,那么synchronize_rcu()不需要等待那個新的讀者。在任意時刻,當給定的讀者通過通過rcu_read_lock()進入其RCU讀端臨界區時,它增加rcu_refcnt[]數組中由rcu_idx變量所代表下標的元素。當同一個讀者通過rcu_read_unlock()退出其RCU讀端臨界區,它減去其增加的元素,忽略對rcu_idx值任何可能的后續更改。
這種安排意味著synchronize_rcu()可以通過修改rcu_idx的值來避免饑餓。假設rcu_idx的舊值為零,因此修改后的新值為1。在修改操作之后到達的新讀者將增加rcu_idx[1],而舊的讀者先前遞增的rcu_idx [0]將在它們退出RCU讀端臨界區時遞減。這意味著rcu_idx[0]的值將不再增加,而是單調遞減。這意味著所有synchronize_rcu()需要做的是等待rcu_refcnt[0]的值達到零。
有了背景,我們來好好看看實際的實現原語。
實現rcu_read_lock()原語自動增加由rcu_idx標出的rcu_refcnt[]成員的值,然后將索引保存在每線程變量rcu_read_idx中。rcu_read_unlock()原語自動減少對應的rcu_read_lock()增加的那個計數的值。不過,因為rcu_idx每個線程只能設置為rcu_idx設置一個值,所以還需要一些手段才能允許嵌套。方法是用每線程的rcu_nesting變量跟蹤嵌套。
為了讓這種方法能夠工作,rcu_read_lock()函數的第6行獲取了當前線程的rcu_nesting,如果第7行的檢查發現當前處于最外層的rcu_read_lock(),那么第8至10行獲取變量rcu_idx的當前值,將其存到當前線程的rcu_read_idx中,然后增加被rcu_idx選中的rcu_refcnt元素的值。第12行不管現在的rcu_nesting值是多少,直接對其加1。第13行執行一個內存屏障,確保RCU讀端臨界區不會在rcu_read_lock()之前開始。
同樣,rcu_read_unlock()函數在第21行也執行一個內存屏障,確保RCU讀端臨界區不會在rcu_read_unlock()代碼之后還未完成。第22行獲取當前線程的rcu_nesting,如果第23行的檢查發現當前處于最外層的rcu_read_unlock(),那么第24至25行獲取當前線程的rcu_read_idx(由最外層的rcu_read_lock()保存)并且原子減少被rcu_read_idx選擇的rcu_refcnt元素。無論當前嵌套了多少層,第27行都直接減少本線程的rcu_nesting值。
1 void synchronize_rcu(void)
2 {
3 int i;
4
5 smp_mb();
6 spin_lock(&rcu_gp_lock);
7 i = atomic_read(&rcu_idx);
8 atomic_set(&rcu_idx, !i);
9 smp_mb();
10 while (atomic_read(&rcu_refcnt[i]) != 0) {
11 poll(NULL, 0, 10);
12 }
13 smp_mb();
14 atomic_set(&rcu_idx, i);
15 smp_mb();
16 while (atomic_read(&rcu_refcnt[!i]) != 0) {
17 poll(NULL, 0, 10);
18 }
19 spin_unlock(&rcu_gp_lock);
20 smp_mb();
21 }
使用全局引用計數對的RCU更新端原語
上圖實現了對應的synchronize_rcu()。第6行和第19行獲取并釋放rcu_gp_lock,因為這樣可以防止多于一個的并發synchronize_rcu()實例。第7至8行分別獲取rcu_idx的值,并對其取反,這樣后續的rcu_read_lock()實例將使用與之前的實例不同的rcu_idx值。然后第10至12行等待之前的由rcu_idx選出的元素變成0,第9行的內存屏障是為了保證對rcu_idx的檢查不會被優化到對rcu_idx取反操作之前。第13至18行重復這一過程,第20行的內存屏障是為了保證所有后續的回收操作不會被優化到對rcu_refcnt的檢查之前執行。
問題:為什么上圖中,在獲得自旋鎖之前,synchronize_rcu()第5行還有一個內存屏障?
問題:為什么上圖的計數要檢查兩次?難道檢查一次還不夠嗎?
本節的實現避免了簡單計數實現可能發生的更新端饑餓問題。
討論不過這種實現仍然存在一些嚴重問題。首先,rcu_read_lock()和rcu_read_unlock()中的原子操作開銷很大。事實上,它們比上一個實現中的單個計數要復雜很多,讀端原語的開銷從Power5單核處理器上的150納秒到64核處理器上的40微秒不等。更新端synchronize_rcu()原語的開銷也變大了,從Power5單核CPU中的200納秒到64核處理器中的40微秒不等。這意味著RCU讀端臨界區必須非常長,才能夠滿足現實世界的讀端并發請求。
其次,如果存在很多并發的rcu_read_lock()和rcu_read_unlock()操作,那么對rcu_refcnt的內存訪問競爭將會十分激烈,這將導致耗費巨大的高速緩存未命中。這一點進一步延長了提供并發讀端訪問所需要的RCU讀端臨界區持續時間。這兩個缺點在很多情況下都影響了RCU的目標。
第三,需要檢查rcu_idx兩次這一點為更新操作增加了開銷,尤其是線程數目很多時。
最后,盡管原則上并發的RCU更新可以共用一個公共優雅周期,但是本節的實現串行化了優雅周期,使得這種共享無法進行。
問題:既然原子自增和原子自減的開銷巨大,為什么不第10行使用非原子自增,在第25行使用非原子自減呢?
盡管有這樣那樣的缺點,這種RCU的變體還是可以運用在小型的多核系統上,也許可以作為一種節省內存實現,用于維護與更復雜實現之間的API兼容性。但是,這種方法在CPU增多時可擴展性不佳。
另一種基于引用計數機制的RCU變體極大地改善了讀端性能和可擴展性。
5、可擴展的基于計數RCU實現
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 DEFINE_PER_THREAD(int [2], rcu_refcnt);
3 atomic_t rcu_idx;
4 DEFINE_PER_THREAD(int, rcu_nesting);
5 DEFINE_PER_THREAD(int, rcu_read_idx);
RCU每線程引用計數對的數據定義
下圖是一種RCU實現的讀端原語,其中使用了每線程引用計數。本實現與前一個實現十分類似,唯一的區別在于rcu_refcnt成了一個每線程變量。使用這個兩元素數組是為了防止讀者導致寫者饑餓。使用每線程rcu_refcnt[]數組的另一個好處是,rcu_read_lock()和rcu_read_unlock()原語不用再執行原子操作。
1 static void rcu_read_lock(void)
2 {
3 int i;
4 int n;
5
6 n = __get_thread_var(rcu_nesting);
7 if (n == 0) {
8 i = atomic_read(&rcu_idx);
9 __get_thread_var(rcu_read_idx) = i;
10 __get_thread_var(rcu_refcnt)[i]++;
11 }
12 __get_thread_var(rcu_nesting) = n + 1;
13 smp_mb();
14 }
15
16 static void rcu_read_unlock(void)
17 {
18 int i;
19 int n;
20
21 smp_mb();
22 n = __get_thread_var(rcu_nesting);
23 if (n == 1) {
24 i = __get_thread_var(rcu_read_idx);
25 __get_thread_var(rcu_refcnt)[i]--;
26 }
27 __get_thread_var(rcu_nesting) = n - 1;
28 }
使用每線程引用計數對的RCU讀端原語
問題:別忽悠了!我在rcu_read_lock()里看見atomic_read()原語了!為什么你想假裝rcu_read_lock()里沒有原子操作?
1 static void flip_counter_and_wait(int i)
2 {
3 int t;
4
5 atomic_set(&rcu_idx, !i);
6 smp_mb();
7 for_each_thread(t) {
8 while (per_thread(rcu_refcnt, t)[i] != 0) {
9 poll(NULL, 0, 10);
10 }
11 }
12 smp_mb();
13 }
14
15 void synchronize_rcu(void)
16 {
17 int i;
18
19 smp_mb();
20 spin_lock(&rcu_gp_lock);
21 i = atomic_read(&rcu_idx);
22 flip_counter_and_wait(i);
23 flip_counter_and_wait(!i);
24 spin_unlock(&rcu_gp_lock);
25 smp_mb();
26 }
使用每線程引用計數對的RCU更新端原語
下圖是synchronize_rcu()的實現,還有一個輔助函數flip_counter_ and_wait()。synchronize_rcu()函數和前一個實現基本一樣,除了原來的重復檢查計數過程被替換成了第22至23行的輔助函數。
新的flip_counter_and_wait()函數在第5行更新rcu_idx變量,第6行執行內存屏障,然后第7至11行循環檢查每個線程對應的rcu_refcnt元素,等待該值變為0。一旦所有元素都變為0,第12行執行另一個內存屏障,然后返回。
本RCU實現對軟件環境有所要求,(1)能夠聲明每線程變量,(2)每個線程都可以訪問其他線程的每線程變量,(3)能夠遍歷所有線程。絕大多數軟件環境都滿足上述要求,但是通常對線程數的上限有所限制。更復雜的實現可以避開這種限制,比如,使用可擴展的哈希表。這種實現能夠動態地跟蹤線程,比如,在線程第一次調用rcu_read_lock()時將線程加入哈希表。
問題:好極了,如果我有N個線程,那么我要等待2N*10毫秒(每個flip_counter_and_wait()調用消耗的時間,假設我們每個線程只等待一次)。我們難道不能讓優雅周期再快一點完成嗎?
不過本實現還有一些缺點。首先,需要檢查rcu_idx兩次,這為更新端帶來一些開銷,特別是線程數很多時。
其次,synchronize_rcu()必須檢查的變量數隨著線程增多而線性增長,這給線程數很多的應用程序帶來一定的開銷。
第三,和之前一樣,雖然原則上并發的RCU更新可以共用一個公共優雅周期,但是本節的實現串行化了優雅周期,使得這種共享無法進行。
最后,本節曾經提到的軟件環境需求,在某些環境下每線程變量和遍歷線程可能存在問題。
讀端原語的擴展性非常好,不管是在單核系統還是64核系統都只需要115納秒左右。Synchronize_rcu()原語的擴展性不佳,開銷在單核Power5系統上的1微秒到64核系統上的200微秒不等。總體來說,本節的方法可以算是一種初級的產品級用戶態RCU實現了。
下面介紹一種能夠讓并發的RCU更新更有效的算法。
6、可擴展的基于計數RCU實現,可以共享優雅周期
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 DEFINE_PER_THREAD(int [2], rcu_refcnt);
3 long rcu_idx;
4 DEFINE_PER_THREAD(int, rcu_nesting);
5 DEFINE_PER_THREAD(int, rcu_read_idx);
使用每線程引用計數對和共享更新數據的數據定義
下圖是一種使用每線程引用計數RCU實現的讀端原語,但是該實現允許更新端共享優雅周期。本節的實現和前面的實現唯一的區別是,rcu_idx現在是一個long型整數,可以自由增長,所以第8行用了一個掩碼屏蔽了最低位。我們還將atomic_read()和atomic_set()改成了ACCESS_ONCE()。上圖中的數據定義和前例也很相似,只是rcu_idx現在是long類型而非之前的atomic_t類型。
1 static void rcu_read_lock(void)
2 {
3 int i;
4 int n;
5
6 n = __get_thread_var(rcu_nesting);
7 if (n == 0) {
8 i = ACCESS_ONCE(rcu_idx) & 0x1;
9 __get_thread_var(rcu_read_idx) = i;
10 __get_thread_var(rcu_refcnt)[i]++;
11 }
12 __get_thread_var(rcu_nesting) = n + 1;
13 smp_mb();
14 }
15
16 static void rcu_read_unlock(void)
17 {
18 int i;
19 int n;
20
21 smp_mb();
22 n = __get_thread_var(rcu_nesting);
23 if (n == 1) {
24 i = __get_thread_var(rcu_read_idx);
25 __get_thread_var(rcu_refcnt)[i]--;
26 }
27 __get_thread_var(rcu_nesting) = n - 1;
28 }
使用每線程引用計數對和共享更新數據的RCU讀端原語
1 static void flip_counter_and_wait(int ctr)
2 {
3 int i;
4 int t;
5
6 ACCESS_ONCE(rcu_idx) = ctr + 1;
7 i = ctr & 0x1;
8 smp_mb();
9 for_each_thread(t) {
10 while (per_thread(rcu_refcnt, t)[i] != 0)
{
11 poll(NULL, 0, 10);
12 }
13 }
14 smp_mb();
15 }
16
17 void synchronize_rcu(void)
18 {
19 int ctr;
20 int oldctr;
21
22 smp_mb();
23 oldctr = ACCESS_ONCE(rcu_idx);
24 smp_mb();
25 spin_lock(&rcu_gp_lock);
26 ctr = ACCESS_ONCE(rcu_idx);
27 if (ctr - oldctr >= 3) {
28 spin_unlock(&rcu_gp_lock);
29 smp_mb();
30 return;
31 }
32 flip_counter_and_wait(ctr);
33 if (ctr - oldctr < 2)
34 flip_counter_and_wait(ctr + 1);
35 spin_unlock(&rcu_gp_lock);
36 smp_mb();
37 }
使用每線程引用計數對的RCU共享更新端原語
上圖是synchronize_rcu()及其輔助函數flip_counter_and_wait()的實現。flip_counter_and_wait()的變化在于:
1.第6行使用ACCESS_ONCE()代替了atomic_set(),用自增替代取反。
2.新增了第7行,將計數的最低位掩去。
synchronize_rcu()的區別要多一些:
1.新增了一個局部變量oldctr,存儲第23行的獲取每線程鎖之前的rcu_idx值。
2.第26行用ACCESS_ONCE()代替atomic_read()。
3.第27至30行檢查在鎖已獲取時,其他線程此時是否在循環檢查3個以上的計數,如果是,釋放鎖,執行一個內存屏障然后返回。在本例中,有兩個線程在等待計數變為0,所以其他的線程已經做了所有必做的工作。
4.在第33至34行,在鎖已被獲取時,如果當前檢查計數是否為0的線程不足2個,那么flip_counter_and_wait()會被調用兩次。另一方面,如果有兩個線程,另一個線程已經完成了對計數的檢查,那么只需再有一個就可以。
在本方法中,如果有任意多個線程并發調用synchronize_rcu(),一個線程對應一個CPU,那么最多只有3個線程在等待計數變為0。
盡管有這些改進,本節的RCU實現仍然存在一些缺點。首先,和上一節一樣,需要檢查rcu_idx兩次為更新端帶來開銷,尤其是線程很多時。
其次,本實現需要每CPU變量和遍歷所有線程的能力,這在某些軟件環境可能是有問題的。
最后,在32位機器上,由于rcu_idx溢出而導致需要做一些額外的檢查。
本實現的讀端原語擴展性極佳,不管CPU數為多少,開銷大概為115納秒。synchronize_rcu()原語的開銷仍然昂貴,從1微秒到15微秒不等。然而這比前面的200微秒的開銷已經好多了。所以,盡管存在這些缺點,本節的RCU實現已經可以在真實世界中的產品中使用了。
問題:所有這些玩具式的RCU實現都要么在rcu_read_lock()和rcu_read_ unlock()中使用了原子操作,要么讓synchronize_rcu()的開銷與線程數線性增長。那么究竟在哪種環境下,RCU的實現既可以讓上述三個原語的實現簡單,又能擁有O(1)的開銷和延遲呢?
重新審視代碼,我們看到了對一個全局變量的訪問和對不超過4個每線程變量的訪問。考慮到在POSIX線程中訪問每線程變量的開銷相對較高,我們可以將三個每線程變量放進單個結構體中,讓rcu_read_lock()和rcu_read_unlock()用單個每線程變量存儲類來訪問各自的每線程變量。
但是,下面將會介紹一種更好的辦法,可以減少訪問每線程變量的次數到一次。
7、基于自由增長計數的RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 long rcu_gp_ctr = 0;
3 DEFINE_PER_THREAD(long, rcu_reader_gp);
4 DEFINE_PER_THREAD(long, rcu_reader_gp_snap);
使用自由增長計數的數據定義
下圖是一種基于單個全局free-running計數的RCU實現,該計數只對偶數值進行計數,相關的數據定義見上圖。rcu_read_lock()的實現極其簡單。第3行向全局free-running變量rcu_gp_ctr加1,將相加后的奇數值存儲在每線程變量rcu_reader_gp中。第4行執行一個內存屏障,防止后續的RCU讀端臨界區內容“泄漏”。
1 static void rcu_read_lock(void)
2 {
3 __get_thread_var(rcu_reader_gp) = rcu_gp_ctr + 1;
4 smp_mb();
5 }
6
7 static void rcu_read_unlock(void)
8 {
9 smp_mb();
10 __get_thread_var(rcu_reader_gp) = rcu_gp_ctr;
11 }
12
13 void synchronize_rcu(void)
14 {
15 int t;
16
17 smp_mb();
18 spin_lock(&rcu_gp_lock);
19 rcu_gp_ctr += 2;
20 smp_mb();
21 for_each_thread(t) {
22 while ((per_thread(rcu_reader_gp, t) & 0x1) &&
23 ((per_thread(rcu_reader_gp, t) -
24 rcu_gp_ctr) < 0)) {
25 poll(NULL, 0, 10);
26 }
27 }
28 spin_unlock(&rcu_gp_lock);
29 smp_mb();
30 }
使用自由增長計數的RCU實現
rcu_read_unlock()實現也很類似。第9行執行一個內存屏障,防止前一個RCU讀端臨界區“泄漏”。第10行將全局變量rcu_gp_ctr的值復制給每線程變量rcu_reader_gp,將此每線程變量的值變為偶數值,這樣當前并發的synchronize_rcu()實例就知道忽略該每線程變量了。
問題:如果任何偶數值都可以讓synchronize_rcu()忽略對應的任務,那么第10行為什么不直接給rcu_reader_gp賦值為0?
synchronize_rcu()會等待所有線程的rcu_reader_gp變量變為偶數值。但是,因為synchronize_rcu()只需要等待“在調用synchronize_rcu()之前就已存在的”RCU讀端臨界區,所以完全可以有更好的方法。第17行執行一個內存屏障,防止之前操縱的受RCU保護的數據結構被亂序(由編譯器或者是CPU)放到第17行之后執行。為了防止多個synchronize_rcu()實例并發執行,第18行獲取rcu_gp_lock鎖(第28釋放鎖)。然后第19行給全局變量rcu_gp_ctr加2。回憶一下,rcu_reader_gp的值為偶數的線程不在RCU讀端臨界區里,所以第21至27行掃描rcu_reader_gp的值,直到所有值要么是偶數(第22行),要么比全局變量rcu_gp_ctr的值大(第23至24行)。第25行阻塞一小段時間,等待一個之前已經存在的RCU讀端臨界區退出,如果對優雅周期的延遲很敏感的話,也可以用自旋鎖來代替。最后,第29行的內存屏障保證所有后續的銷毀工作不會被亂序到循環之前進行。
問題:為什么需要第17和第29行的內存屏障?難道第18行和第28行的鎖原語自帶的內存屏障還不夠嗎?
本節方法的讀端性能非常好,不管CPU數目多少,帶來的開銷大概是63納秒。更新端的開銷稍大,從Power5單核的500納秒到64核的超過100微秒不等。
這個實現除了剛才提到的更新端的開銷較大以外,還有一些嚴重缺點。首先,該實現不允許RCU讀端臨界區嵌套。其次如果讀者在第3行獲取rcu_gp_ctr之后,存儲到rcu_reader_gp之前被搶占,并且如果rcu_gp_ctr計數的值增長到最大值的一半以上,但沒有達到最大值時,那么synchronize_rcu()將會忽略后續的RCU讀端臨界區。第三也是最后一點,本實現需要軟件環境支持每線程變量和對所有線程遍歷。
問題:第3行的讀者被搶占問題是一個真實問題嗎?換句話說,這種導致問題的事件序列可能發生嗎?如果不能,為什么不能?如果能,事件序列是什么樣的,我們該怎樣處理這個問題?
8、基于自由增長計數的可嵌套RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 #define RCU_GP_CTR_SHIFT 7
3 #define RCU_GP_CTR_BOTTOM_BIT (1 <<
RCU_GP_CTR_SHIFT)
4 #define RCU_GP_CTR_NEST_MASK
(RCU_GP_CTR_BOTTOM_BIT - 1)
5 long rcu_gp_ctr = 0;
6 DEFINE_PER_THREAD(long, rcu_reader_gp);
基于自由增長計數的可嵌套RCU的數據定義
下圖是一種基于單個全局free-running計數的RCU實現,但是允許RCU讀端臨界區的嵌套。這種嵌套能力是通過讓全局變量rcu_gp_ctr的低位記錄嵌套次數實現的,定義在上圖中。該方法保留低位來記錄嵌套深度。為了做到這一點,定義了兩個宏,RCU_GP_CTR_NEST_MASK和RCU_GP_CTR_BOTTOM_BIT。兩個宏之間的關系是:RCU_GP_CTR_NEST_MASK=RCU_GP_ CTR_BOTTOM_BIT - 1。RCU_GP_CTR_BOTTOM_BIT宏是用于記錄嵌套那一位之前的一位,RCU_GP_CTR_NEST_MASK宏則包含rcu_gp_ctr中所有用于記錄嵌套的位。顯然,這兩個宏必須保留足夠多的位來記錄允許的最大RCU讀端臨界區嵌套深度,在本實現中保留了7位,這樣,允許最大RCU讀端臨界區嵌套深度為127,這足夠絕大多數應用使用。
1 static void rcu_read_lock(void)
2 {
3 long tmp;
4 long *rrgp;
5
6 rrgp = &__get_thread_var(rcu_reader_gp);
7 tmp = *rrgp;
8 if ((tmp & RCU_GP_CTR_NEST_MASK) == 0)
9 tmp = rcu_gp_ctr;
10 tmp++;
11 *rrgp = tmp;
12 smp_mb();
13 }
14
15 static void rcu_read_unlock(void)
16 {
17 long tmp;
18
19 smp_mb();
20 __get_thread_var(rcu_reader_gp)--;
21 }
22
23 void synchronize_rcu(void)
24 {
25 int t;
26
27 smp_mb();
28 spin_lock(&rcu_gp_lock);
29 rcu_gp_ctr += RCU_GP_CTR_BOTTOM_BIT;
30 smp_mb();
31 for_each_thread(t) {
32 while (rcu_gp_ongoing(t) &&
33 ((per_thread(rcu_reader_gp, t) -
34 rcu_gp_ctr) < 0)) {
35 poll(NULL, 0, 10);
36 }
37 }
38 spin_unlock(&rcu_gp_lock);
39 smp_mb();
40 }
使用自由增長計數的可嵌套RCU實現
rcu_read_lock()的實現仍然十分簡單。第6行將指向本線程rcu_reader_gp實例的指針放入局部變量rrgp中,將代價昂貴的訪問phtread每線程變量API的數目降到最低。第7行記錄rcu_reader_gp的值放入另一個局部變量tmp中,第8行檢查低位字節是否為0,表明當前的rcu_read_lock()是最外層的。如果是,第9行將全局變量rcu_gp_ctr的值存入tmp,因為第7行之前存入的值可能已經過期了。如果不是,第10行增加嵌套深度,如果你能記得,它存放在計數的最低7位。第11行將更新后的計數值重新放入當前線程的rcu_reader_gp實例中,然后,也是最后,第12行執行一個內存屏障,防止RCU讀端臨界區泄漏到rcu_read_lock()之前的代碼里。
換句話說,除非當前調用的rcu_read_lock()的代碼位于RCU讀端臨界區中,否則本節實現的rcu_read_lock()原語會獲取全局變量rcu_gp_ctr的一個副本,而在嵌套環境中,rcu_read_lock()則去獲取rcu_reader_gp在當前線程中的實例。在兩種情況下,rcu_read_lock()都會增加獲取到的值,表明嵌套深度又增加了一層,然后將結果儲存到當前線程的rcu_reader_gp實例中。
有趣的是,rcu_read_unlock()的實現和前面的實現一模一樣。第19行執行一個內存屏障,防止RCU讀端臨界區泄漏到rcu_read_unlock()之后的代碼中去,然后第20行減少當前線程的rcu_reader_gp實例,這將減少rcu_reader_gp最低幾位包含的嵌套深度。rcu_read_unlock()原語的調試版本將會在減少嵌套深度之前檢查rcu_reader_gp的最低幾位是否為0。
synchronize_rcu()的實現與前面十分類似。不過存在兩點不同。第一,第29行將RCU_GP_CTR_BOTTOM_BIT增加到全局變量rcu_gp_ctr,而不是直接加常數2。第二,第32行的比較被剝離成一個函數,檢查RCU_GP_CTR_BOTTOM_BIT指示的位,而非無條件地檢查最低位。
本節方法的讀端性能與前面的實現幾乎一樣,不管CPU數目多少,開銷大概為65納秒。更新端的開銷仍然較大,從Power5單核的600納秒到64核的超過100微秒。
問題:為什么不像上一節那樣,直接用一個單獨的每線程變量來表示嵌套深度,反而用復雜的位運算來表示?
除了解決了RCU讀端臨界區嵌套問題以外,本節的實現有著和前面實現一樣的缺點。另外,在32位系統上,本方法會減少全局變量rcu_gp_ctr變量溢出所需的時間。隨后將介紹一種能大大延長溢出所需時間,同時又極大地降低了讀端開銷的方法。
問題:怎樣才能將全局變量rcu_gp_ctr溢出的時間延長一倍?
問題:溢出是致命的嗎?為什么?為什么不是?如果是致命的,有什么辦法可以解決它?
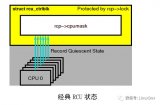
9、基于靜止狀態的RCU
1 DEFINE_SPINLOCK(rcu_gp_lock);
2 long rcu_gp_ctr = 0;
3 DEFINE_PER_THREAD(long, rcu_reader_qs_gp);
基于quiescent-state的RCU的數據定義
下圖是一種基于靜止狀態的用戶態級RCU實現的讀端原語。數據定義在上圖。從圖中第1至7行可以看出,rcu_read_lock()和rcu_read_unlock()原語不做任何事情,就和Linux內核一樣,這種空函數會成為內聯函數,然后被編譯器優化掉。之所以是空函數,是因為基于靜止狀態的RCU實現用之前提到的靜止狀態來大致的作為RCU讀端臨界區的長度,這種狀態包括第9至15行的rcu_quiescent_state()調用。進入擴展的靜止狀態(比如當發生阻塞時)的線程可以分別用thread_offline()和thread_online() API,來標記擴展的靜止狀態的開始和結尾。這樣,thread_online()就成了對rcu_read_lock()的模仿,thread_offline()就成了對rcu_read_unlock()的模仿。此外,rcu_quiescent_state()可以被認為是一個rcu_thread_online()緊跟一個rcu_thread_offline()。從RCU讀端臨界區中調用rcu_quiescent_state()、rcu_thread_offline()或rcu_thread_online()是非法的。
1 static void rcu_read_lock(void)
2 {
3 }
4
5 static void rcu_read_unlock(void)
6 {
7 }
8
9 rcu_quiescent_state(void)
10 {
11 smp_mb();
12 __get_thread_var(rcu_reader_qs_gp) =
13 ACCESS_ONCE(rcu_gp_ctr) + 1;
14 smp_mb();
15 }
16
17 static void rcu_thread_offline(void)
18 {
19 smp_mb();
20 __get_thread_var(rcu_reader_qs_gp) =
21 ACCESS_ONCE(rcu_gp_ctr);
22 smp_mb();
23 }
24
25 static void rcu_thread_online(void)
26 {
27 rcu_quiescent_state();
28 }
基于靜止狀態的RCU讀端原語
在rcu_quiescent_state()中,第11行執行一個內存屏障,防止在靜止狀態之前的代碼亂序到靜止狀態之后執行。第12至13行獲取全局變量rcu_gp_ctr的副本,使用ACCESS_ONCE()來保證編譯器不會啟用任何優化措施讓rcu_gp_ctr被讀取超過一次。然后對取來的值加1,儲存到每線程變量rcu_reader_qs_gp中,這樣任何并發的synchronize_rcu()實例都只會看見奇數值,因此就知道新的RCU讀端臨界區開始了。正在等待老的讀端臨界區的synchronize_rcu()實例因此也知道忽略新產生的讀端臨界區。最后,第14行執行一個內存屏障,這會阻止后續代碼(包括可能的RCU讀端臨界區)對第12至13行的重新排序。
問題:第14行多余的內存屏障會不會顯著增加rcu_quiescent_state()的開銷?
有些應用程序可能只是偶爾需要用RCU,但是一旦它們開始用,那一定是到處都在用。這種應用程序可以在開始用RCU時調用rcu_thread_online(),在不再使用RCU時調用rcu_thread_offline()。在調用rcu_thread_offline()和下一個調用rcu_thread_ online()之間的時間成為擴展的靜止狀態,在這段時間RCU不會顯式地注冊靜止狀態。
rcu_thread_offline()函數直接將每線程變量rcu_reader_qs_gp賦值為rcu_gp_ctr的當前值,該值是一個偶數。這樣所有并發的synchronize_rcu()實例就知道忽略這個線程。
問題:為什么需要第19行和第22行的內存屏障?
rcu_thread_online()函數直接調用rcu_quiescent_state(),這也表示延長靜止狀態的結束。
1 void synchronize_rcu(void)
2 {
3 int t;
4
5 smp_mb();
6 spin_lock(&rcu_gp_lock);
7 rcu_gp_ctr += 2;
8 smp_mb();
9 for_each_thread(t) {
10 while (rcu_gp_ongoing(t) &&
11 ((per_thread(rcu_reader_qs_gp, t) -
12 rcu_gp_ctr) < 0)) {
13 poll(NULL, 0, 10);
14 }
15 }
16 spin_unlock(&rcu_gp_lock);
17 smp_mb();
18 }
基于靜止狀態的RCU更新端原語
下圖是synchronize_rcu()的實現,和前一個實現很相像。
本節實現的讀端原語快得驚人,調用rcu_read_lock()和rcu_read_unlock()的開銷一共大概50皮秒(10的負12次方秒)。synchronize_rcu()的開銷從Power5單核上的600納秒到64核上的超過100微秒不等。
問題:可以確定的是,ca-2008Power系統的時鐘頻率相當高,可是即使是5GHz的時鐘頻率,也不足以讓讀端原語在50皮秒執行完畢。這里究竟發生了什么?
不過,本節的實現要求每個線程要么周期性地調用rcu_quiescent_state(),要么為擴展的靜止狀態調用rcu_thread_offline()。周期性調用這些函數的要求在某些情況下會讓實現變得困難,比如某種類型的庫函數。
另外,本節的實現不允許并發的synchronize_rcu()調用來共享同一個優雅周期。不過,完全可以基于這個RCU版本寫一個產品級的RCU實現。
10、關于玩具式RCU實現的總結
如果你看到這里,恭喜!你現在不僅對RCU本身有了更清晰的了解,而且對其所需要的軟件和應用環境也更熟悉了。想要更進一步了解RCU的讀者,請自行閱讀在各種產品中大量采用的RCU實現。
之前的章節列出了各種RCU原語的理想特性。下面我們將整理一個列表,供有意實現自己的RCU實現的讀者做參考。
1.必須有讀端原語(比如rcu_read_lock()和rcu_read_unlock())和優雅周期原語(比如synchronize_rcu()和call_rcu()),任何在優雅周期開始前就存在的RCU讀端臨界區必須在優雅周期結束前執行完畢。
2.RCU讀端原語應該有最小的開銷。特別是應該避免如高速緩存未命中、原子操作、內存屏障和條件分支之類的操作。
3.RCU讀端原語應該有O(1)的時間復雜度,可以用于實時用途。(這意味著讀者可以與更新者并發運行。)
4.RCU讀端原語應該在所有上下文中都可以使用(在Linux內核中,只有空的死循環時不能使用RCU讀端原語)。一個重要的特例是RCU讀端原語必須可以在RCU讀端臨界區中使用,換句話說,必須允許RCU讀端臨界區嵌套。
5.RCU讀端原語不應該有條件判斷,不會返回失敗。這個特性十分重要,因為錯誤檢查會增加復雜度,讓測試和驗證變得更復雜。
6.除了靜止狀態以外的任何操作都能在RCU讀端原語里執行。比如像I/O這樣的操作也該允許。
7.應該允許在RCU讀端臨界區中執行的同時更新一個受RCU保護的數據結構。
8.RCU讀端和更新端的原語應該在內存分配器的設計和實現上獨立。
9.RCU優雅周期不應該被在RCU讀端臨界區之外阻塞的線程而阻塞。
所有這些目標,都被Linux內核RCU實現所滿足。后續將分析Linux內核中RCU實現代碼。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19259瀏覽量
229655 -
LINUX內核
+關注
關注
1文章
316瀏覽量
21644 -
Posix
+關注
關注
0文章
36瀏覽量
9496 -
rcu
+關注
關注
0文章
21瀏覽量
5446
原文標題:謝寶友: 深入理解RCU之五:玩具式實現
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深入理解Linux RCU:經典RCU實現概要





 工商網監
工商網監
評論