 什么是加速計算?加速計算的應用場景和解決方案
什么是加速計算?加速計算的應用場景和解決方案
隨著科技的發展,處理大量數據和進行復雜計算的需求越來越高,人工智能、大數據和物聯網等領域更是如此,傳統的計算方式已經無法滿足這些需求。因此,加速計算作為一種現代計算方式,成了必要的手段。加速計算具有前所未有的處理能力,在云基礎設施中發揮著核心作用,因為它有助于更高效、更有效地管理數據中心的海量信息。此外,加速計算還能提供必要的計算能力和內存,以便更高效地訓練和實施 GPT-4 等高級生成式人工智能模型。這種能力可加快訓練時間、處理大型數據集和開發日益復雜的模型。
加速計算利用 GPU、ASIC、TPU 和 FPGA 等專用硬件來執行比 CPU 更高效的計算,從而提高速度和性能。它尤其適用于可并行化的任務,如高性能計算、深度學習、機器學習和人工智能。
加速計算發展迅速,各種硬件和軟件解決方案如 GPU、ASIC、TPU、FPGA、CUDA、OpenCL 和網絡技術層出不窮。下面我們來深入了解一下加速計算,就能明白為何它會成為 AI 時代的計算力“新寵”。
什么是加速計算
加速計算是指使用專用硬件來執行某些類型的計算,其效率要比僅使用通用中央處理器(CPU)高。利用圖形處理單元(GPU)、專用集成電路(ASIC)(包括張量處理單元(TPU))和現場可編程邏輯門陣列(FPGA)等設備的強大功能,以更高的速度執行計算,從而加速計算過程,一般我們也將這些設備稱之為加速器。
這些加速器尤其適用于可被分解為較小并行任務的項目,如高性能計算 (HPC)、深度學習、機器學習、人工智能和大數據分析。通過將指定類型的工作分派到這些專用加速計算硬件上,大大提高了系統的性能和效率。
加速計算因其高效處理海量數據的能力,從而推動了機器學習、AI、實時分析和科學研究的進步。加速計算在圖形、游戲、邊緣計算和云計算領域的影響力與日俱增,是數據中心等數字基礎設施的骨干力量。隨著對更強大應用和系統的需求日益增長,傳統的 CPU 方法難以與加速計算競爭,而加速計算可提供更快、更具成本效益的性能升級。
加速計算解決方案
加速計算解決方案涉及硬件、軟件和網絡的結合。這些解決方案專門用于提高復雜計算任務的速度和效率。
硬件
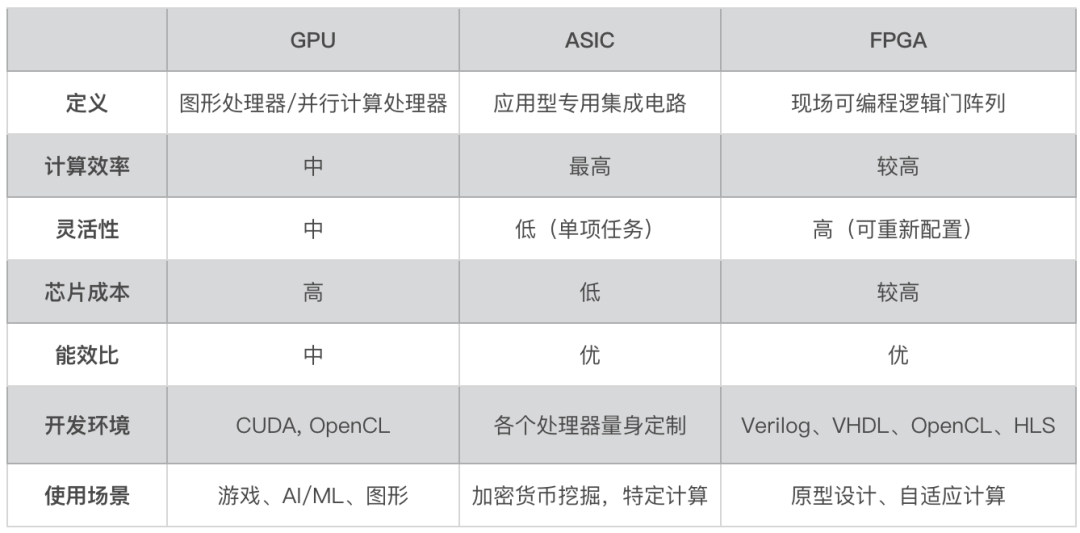
硬件加速器是加速計算的基礎,這些加速器包括圖形處理器 (GPU)、專用集成電路 (ASIC) 和現場可編程門陣列 (FPGA)。
GPU
圖形處理器(GPU)廣泛用于各種計算密集型任務,其優勢在于可以同時執行許多復雜的計算,因此非常適合高性能計算(HPC)和機器學習中的神經網絡訓練等任務。
英偉達公司數據中心和計算密集型任務(機器學習、人工智能)的 GPU 市場上處于領先地位。該公司用于數據中心的主要 GPU 架構包括 Hopper (H100) 和 Ampere (A100)。值得一提的是,H100 GPU 非常適合加速涉及大型語言模型 (LLM)、深度推薦系統、基因學和復雜數字孿生的應用。
應用型專用集成電路 ASIC
應用型專用集成電路(ASIC)是為執行特定任務而設計的定制芯片,與 CPU 不同, CPU 可處理各種應用。由于專用集成電路是為特定功能定制的,因此執行任務的效率比 CPU 更高,在速度、功耗和整體性能方面都具有優勢。
我們常常在科技文章中看到的神經處理單元(NPU)和深度學習處理器(DLP)就是 ASIC 中的一員,還有谷歌的張量處理單元(TPU)也是 ASIC 下的一員猛將。TPU 專為加速機器學習工作荷載而設計,它們被廣泛應用于語言翻譯、谷歌助手中的語音識別和智能化廣告排名等項目中。
現場可編程邏輯門陣列 FPGA
現場可編程邏輯門陣列(FPGA)是一種半導體集成電路,與 CPU 相比,FPGA 可重新編程以便能更高效地執行特定任務。與 ASIC、GPU 和 CPU 的固定架構不同,FPGA 硬件包括可配置邏輯塊和可編程互連。這樣,即使在芯片出廠和部署后,也可以進行功能更新。
FPGA 憑借其靈活性和并行計算能力,在數據中心的高性能計算、AI、機器學習中越來越受歡迎。不過,與 GPU 和定制 ASIC 解決方案相比,FPGA 的開發速度較慢,其軟件生態系統目前也不夠健全,由于其編程復雜,專業工程師的數量也很有限。
軟件
加速計算利用應用編程接口(API)和編程模型(如 CUDA 和 OpenCL)來連接軟件和硬件。這樣可以優化數據流,從而提高性能、能效、成本效益和準確性。開發人員通過 API 和編程模型,就能夠編寫在 GPU 上運行的代碼,并利用軟件程序庫實現高效算法。
CUDA
CUDA(全稱為 Compute Unified Device Architecture,統一計算架構)是英偉達公司開發的專有并行計算平臺和 API 模型,通過這個技術,開發者可利用英偉達的 GPU 進行圖像處理之外的運算,顯著加速計算任務。該平臺包括 cuDNN、TensorRT 和 DeepStream 等深度學習庫,可增強人工智能訓練和推理任務。
自 2006 年推出以來,CUDA 已被下載 4000 萬次,在全球擁有 400 萬開發者用戶群,已形成了一個龐大的開發者社區,因此英偉達公司在數據中心硬件和軟件市場上占據了顯著優勢。
OpenCL
OpenCL(Open Computing Language,開放計算語言)是一個為異構平臺編寫程序的框架。OpenCL 的一個特別顯著的特點是它在不同硬件類型之間的可移植性,平臺可由 CPU、GPU、FPGA 或其他類型的處理器與硬件加速器所組成。其廣泛的兼容性使開發人員能夠利用這些不同硬件的強大功能,來進行加速計算。
網絡
網絡在加速計算中發揮著至關重要的作用,因為它有助于成千上萬個處理單元和內存以及存儲設備之間的通信。各種網絡技術被用來實現這些計算設備與系統其他設備之間的通信,并在網絡內的多個設備之間共享數據。常見的技術有:
PCI Express(PCIe):PCIe 是計算機總線的一個重要分支,它沿用既有的 PCI 編程概念及信號標準,并且構建了更加高速的串行通信系統標準。這一標準提供了計算設備與 CPU、內存之間的直接連接。在加速計算中,PCIe 通常用于將 GPU 或其他加速器連接到主機系統。
NVLink:英偉達公司專有的高帶寬、高能效互連技術,可提供比 PCIe 高得多的帶寬。該技術旨在促進 GPU 之間以及 GPU 與 CPU 之間更高效的數據共享。
Infinity Fabric:AMD 公司專有的互連技術,用于連接其芯片中的各種組件,包括 CPU、GPU 和內存。
Compute Express Link (CXL):CXL 是一種開放式互連標準,有助于減少 CPU 和加速器之間的延遲同時增加帶寬。它將多個接口合并為一個 PCIe 接口,連接到 CPU。
InfiniBand:一種高速、低延遲的互連技術,通常用于高性能計算(HPC)設置。它實現了服務器集群和存儲設備之間的高速互連。
以太網:應用最廣泛最成熟的網絡技術,主要用于在數據中心的服務器之間傳輸大量數據。但是,它無法提供與 NVLink 或 InfiniBand 相同的性能水平。
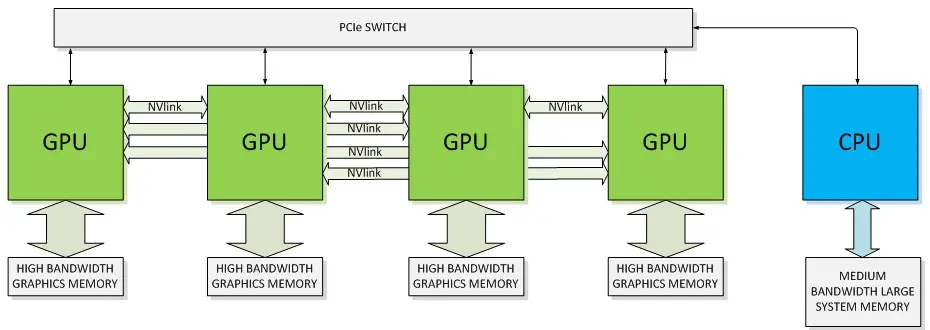
△ NVLink 和 PCIe 與 CPU 連接的 GPU 架構
加速計算應用場景
生成式AI
加速計算是開發和實施先進的生成式 AI 模型的關鍵因素。生成式 AI 涉及使用算法來統計特征上與訓練集相似的數據,在圖像、文本和語音領域都有廣泛應用。
在生成式 AI 領域,會用到生成對抗網絡(GANs)、變異自動編碼器(VAEs)和變換器(Transformers)等模型,還有包括 OpenAI 的 ChatGPT 的大型語言模型(LLMs)。這些模型所涉及到的復雜數學運算,需要在大型數據集上進行訓練,并需要大量的計算能力和內存。更具體地說,模型大小、每層復雜度、序列長度和多樣化是計算需求日益增加的最主要因素。
加速計算在解決生成式 AI 的計算能力和內存需求方面發揮著至關重要的作用,其主要作用在加快訓練時間、處理大型數據集、支持復雜模型、促進實時生成并保障高效梯度計算。
加快訓練時間
加速計算在生成式 AI 中最重要的作用是縮短 GAN、VAE 和 Transformer 模型的訓練時間。在基于 CPU 的傳統架構上,這些模型的訓練通常需要數天、數周甚至數月的時間,但 GPU 和 TPU 等加速計算平臺是專為并行處理而設計的加速硬件,它們能夠同時并行處理多個計算,從而大大縮短了訓練時間。
處理大型數據集
生成式 AI 模型通常在海量數據集上進行訓練,與傳統 CPU 相比,加速計算硬件可以更高效地處理這些大型數據集。此外,使用先進的內存架構(如某些 GPU 中的高帶寬內存)可以在訓練過程中高效處理這些大型數據集。
創建復雜模型
加速計算所帶來的計算能力的提升,可以創建更復雜、更大型的模型,從而獲得更好的結果。例如,像 GPT-4 這樣擁有 170 萬億個參數的生成型預訓練變換模型,只有通過加速計算才能實現。
實時功能
在某些應用中,人工智能模型需要實時(或接近實時)生成輸出。這對于交互式應用(如視頻游戲中的人工智能和實時翻譯)尤為重要。加速計算可確保快速執行這些操作,從而實現實時功能。
高效的計算梯度
深度學習模型通過使用基于梯度的優化技術(如反向傳播)進行學習。這些計算方法以誤差或損失函數最小化的方向來迭代調整模型參數。由于計算是基于矩陣的,因此具有很高的并行性,非常適合選用加速計算方案來處理。
AI數據中心
加速計算平臺的目的是加速各類數據中心的計算密集型工作,包括人工智能、數據分析、圖形和科學計算。這些數據中心包括企業、主機托管、超大規模/云、邊緣和模塊化設施,其主要目標是提高工作負載性能,同時降低功耗和每次查詢的成本。
生成式 AI 和大型語言模型(LLM)在消費者、互聯網公司、企業和初創公司中的興起,使人工智能的應用進入了一個快速發展時刻,加速了數據中心和云平臺中的 AI 推理部署。目前,大多數 AI 推理工作都部署在 CPU 和網絡接口卡(NIC)上運行。然而,由于性能、能效、成本效益和功耗限制的日益增加,業界正在轉向利用 GPU 和 ASIC 等專用硬件進行加速計算。
現代數據中心的發展方向之一,就是建立一個可持續運行的 " AI 工廠"。通過 LLM、推薦系統以及最終的推理模型等人工智能模型,配備推理機群,以便支持各種各樣的工作任務,例如視頻處理、文本生成、圖像生成以及虛擬世界和虛擬 3D 圖形。
使用GPU進行加速計算
使用 GPU 進行加速計算方法主要有三大類:
使用商業套裝軟件
使用開源或官方函式庫
自行編程 CUDA
第一項種類繁多,其中又以有限元素分析領域最多,此領域相關計算包含流體力學分析、熱傳導分析、電磁場分析或應力分析等等應用。由于范圍涵蓋 IC 設計、建筑設計、甚至許多交通工具或化工廠也需要通過這類軟件進行模擬分析,所以開發這類軟件有很大的商業價值。
第二項則比較個性化,由開發者自行編寫程序,GPU 的計算組件則可以引用他人已經準備好的函數庫,或者參考英偉達官方提供的函數庫,也可以從 GitHub 上進行搜索。
第三項就必須通過編程語言進行 CUDA 編寫,不同的編程語言能夠操縱的自由度也各不相同,其中 C/C++ 或 Fortran屬于開發自由度最高的編程語言,可從底層控制 GPU 計算,甚至可以針對本機內存與 GPU 內存數據的傳輸進行優化。其次則為 Python,Python 也是目前市面上最主流的 AI 應用開發語言,實現的方式包括 PyCuda 或者使用Numba 函數庫。另外,Java、R、C# 等也都可以支持 CUDA。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19259瀏覽量
229653 -
FPGA
+關注
關注
1629文章
21729瀏覽量
603009 -
AI
+關注
關注
87文章
30728瀏覽量
268891 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113 -
算力
+關注
關注
1文章
964瀏覽量
14794
原文標題:加速計算,為何會成為AI時代的計算力“新寵”
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
加速云發布新品,異構計算加速平臺有效滿足AI及高性能計算業務需求
FPGA與MCU的應用場景
云計算十大應用場景
【解決方案】加速海嘯模擬
加速度傳感器的7大不同應用場景
請問怎么通過MPU6050的x,,y,z軸加速度,計算出合加速度
機器學習實戰:GNN加速器的FPGA解決方案
GNN(圖神經網絡)硬件加速的FPGA實戰解決方案
異構計算是未來趨勢,看加速云玩轉FPGA
業內最強的FPGA圖像加速解決方案
FPGA與GPU計算存儲加速對比
加速場景智能化:華為行業感知出席2023計算產業生態大會






 工商網監
工商網監
評論