") 一種新的分割模型Stable-SAM
一種新的分割模型Stable-SAM
0. 筆者個人體會
分割一切模型(SAM)這幾年在CV領域應用很多,很多文章都在努力提高SAM的分割精度,但SAM分割的前提是高質量的提示(點、框)。但是實踐中的SAM經(jīng)常遇到不準確的提示,尤其是眾包標注平臺,這種不準確的提示會導致分割錯誤。
這也就是Stable Segment Anything Model這篇文章想要解決的問題,提出了一種新的分割模型Stable-SAM,希望遇到錯誤提示時也能實現(xiàn)穩(wěn)定分割!
1. 效果展示
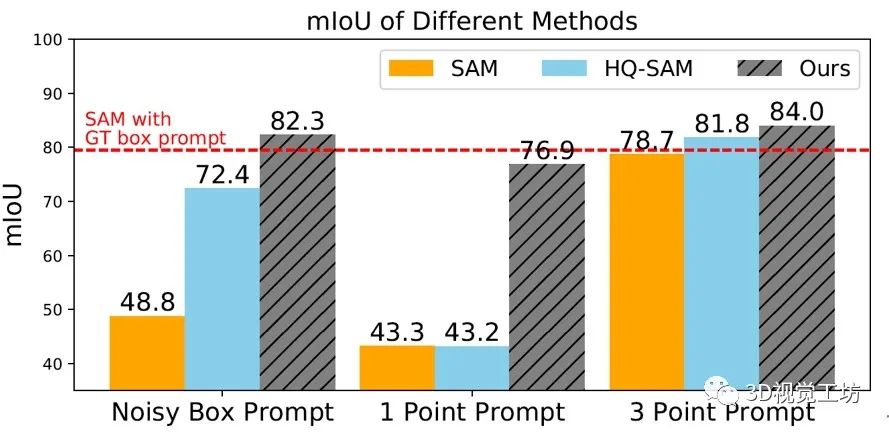
SAM、HQ-SAM、Stable-SAM在提供次優(yōu)提示時的性能比較,Stable-SAM明顯優(yōu)于其他算法。
SAM和Stable-SAM的預測Mask和圖像特征的權重對比,橙色圓圈表示注意力權重,半徑越大表示得分越高。(a) 當提供高質量提示時,SAM分割結果很好。(b) 微小的提示修改會導致不穩(wěn)定的分割輸出,SAM錯誤分割了背景。(c) Stable-SAM通過將更多的特征采樣注意力轉移到目標對象上來準確地分割目標對象。
2. 具體原理是什么?
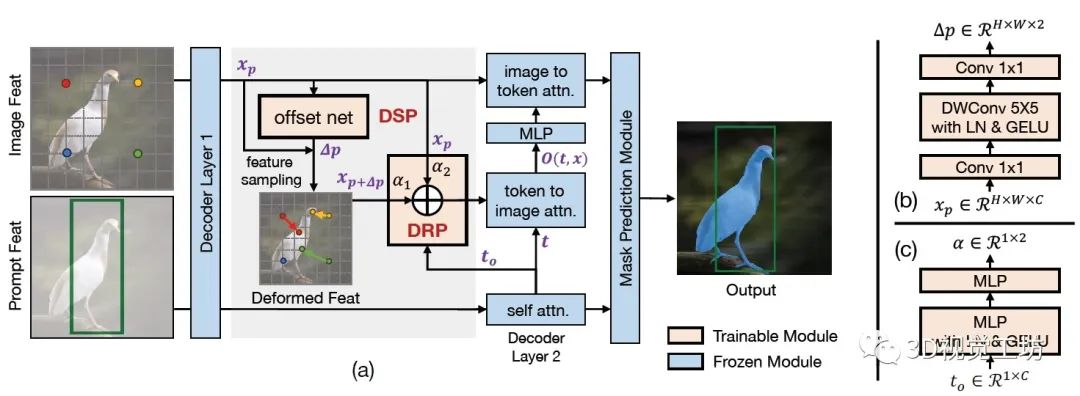
Stable-SAM的具體pipeline由三部分組成:
(a)是SAM的Mask解碼器中的可變形采樣插件(DSP)和可變形路由插件(DRP)。DSP采用小偏移網(wǎng)絡(b)來預測特征采樣偏移。隨后DSP在更新的采樣位置對可變形圖像特征進行重新采樣,并將它們饋送到SAM的標記到圖像注意力。DRP采用一個小型MLP網(wǎng)絡(c)來根據(jù)輸入提示質量調節(jié)DSP激活的程度。注意,DSP自適應地單獨調整圖像特征采樣位置,不會改變原始SAM模型。
3. 和其他SOTA方法對比如何?
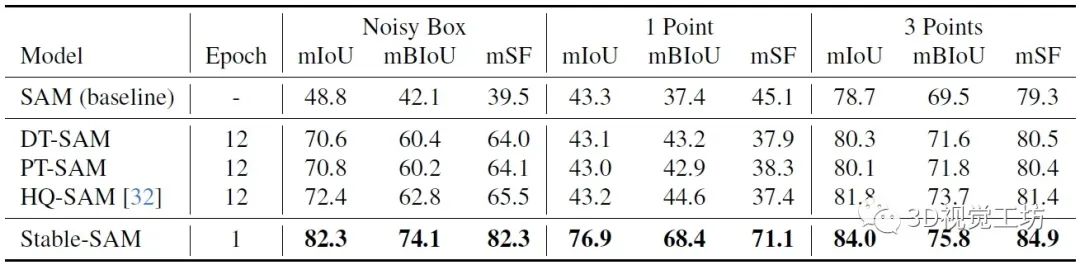
在不同質量的提示下,SAM、DT-SAM(微調SAM的Mask解碼器)、PT-SAM(微調SAM的提示token及其對應的輸出MLP層)、HQ-SAM和Stable-SAM在HQ數(shù)據(jù)集上的對比。這里也推薦工坊推出的新課程《如何將深度學習模型部署到實際工程中?(分類+檢測+分割)》。
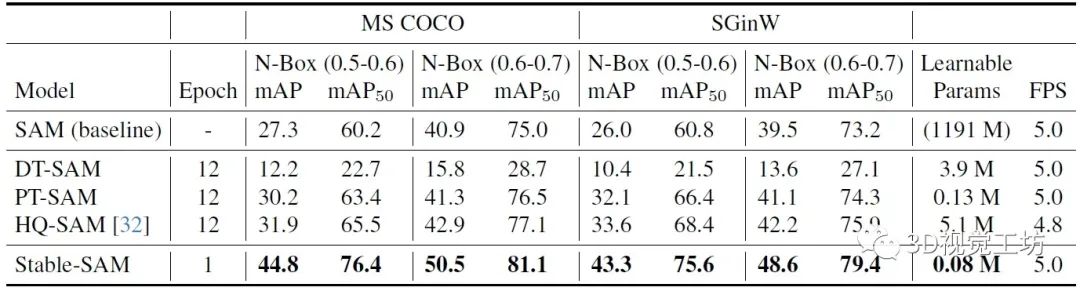
MS COCO和SGinW數(shù)據(jù)集上的對比,Stable-SAM最優(yōu)。
審核編輯:黃飛
-
dsp
+關注
關注
553文章
7987瀏覽量
348757 -
解碼器
+關注
關注
9文章
1143瀏覽量
40718 -
圖像分割
+關注
關注
4文章
182瀏覽量
17995 -
SAM
+關注
關注
0文章
112瀏覽量
33519
原文標題:SAM終結者:穩(wěn)定分割一切!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一種帶驗證的自適應鏡頭分割算法
一種目標飛機分割提取方法
一種新的彩色圖像分割算法
一種牙齒半自動精確分割算法

一種高精度的肝臟圖像自動分割算法
SAM-Adapter:首次讓SAM在下游任務適應調優(yōu)!
近期分割大模型發(fā)展情況

第一篇綜述!分割一切模型(SAM)的全面調研

基于一種移動端高性能 Stable Diffusion 模型

YOLOv8最新版本支持SAM分割一切

基于SAM設計的自動化遙感圖像實例分割方法

介紹一種自動駕駛汽車中可行駛區(qū)域和車道分割的高效輕量級模型

ICCV 2023 | 超越SAM!EntitySeg:更少的數(shù)據(jù),更高的分割質量






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論