") 中文大模型基準(zhǔn)測(cè)評(píng)2023年度報(bào)告
中文大模型基準(zhǔn)測(cè)評(píng)2023年度報(bào)告
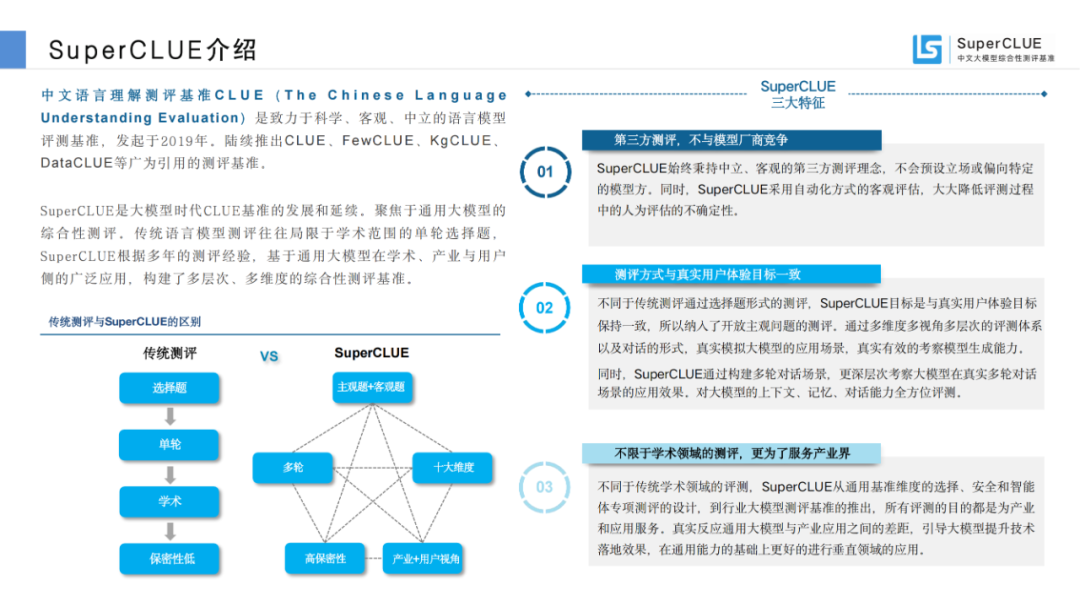
自2023年以來(lái),AI大模型在全球范圍內(nèi)掀起了有史以來(lái)規(guī)模最大的人工智能浪潮。國(guó)內(nèi)學(xué)術(shù)和產(chǎn)業(yè)界在過(guò)去一年也有了實(shí)質(zhì)性的突破。中文大模型測(cè)評(píng)基準(zhǔn)SuperCLUE在過(guò)去一年對(duì)國(guó)內(nèi)外大模型的發(fā)展趨勢(shì)和綜合效果進(jìn)行了實(shí)時(shí)跟蹤。
基于此,SuperCLUE團(tuán)隊(duì)發(fā)布了《中文大模型基準(zhǔn)測(cè)評(píng)2023年度報(bào)告》,在AI大模型發(fā)展的巨大浪潮中,通過(guò)多維度綜合性測(cè)評(píng),對(duì)國(guó)內(nèi)外大模型發(fā)展現(xiàn)狀進(jìn)行觀察與思考。
國(guó)內(nèi)大模型關(guān)鍵進(jìn)展012023年大模型關(guān)鍵進(jìn)展與中文大模型全景圖
國(guó)內(nèi)學(xué)術(shù)和產(chǎn)業(yè)界在過(guò)去一年也有了實(shí)質(zhì)性的突破。大致可以分為三個(gè)階段,即準(zhǔn)備期(ChatGPT發(fā)布后國(guó)內(nèi)產(chǎn)學(xué)研迅速形成大模型共識(shí))、成長(zhǎng)期(國(guó)內(nèi)大模型數(shù)量和質(zhì)量開(kāi)始逐漸增長(zhǎng))、爆發(fā)期(各行各業(yè)開(kāi)源閉源大模型層出不窮,形成百模大戰(zhàn)的競(jìng)爭(zhēng)態(tài)勢(shì))。
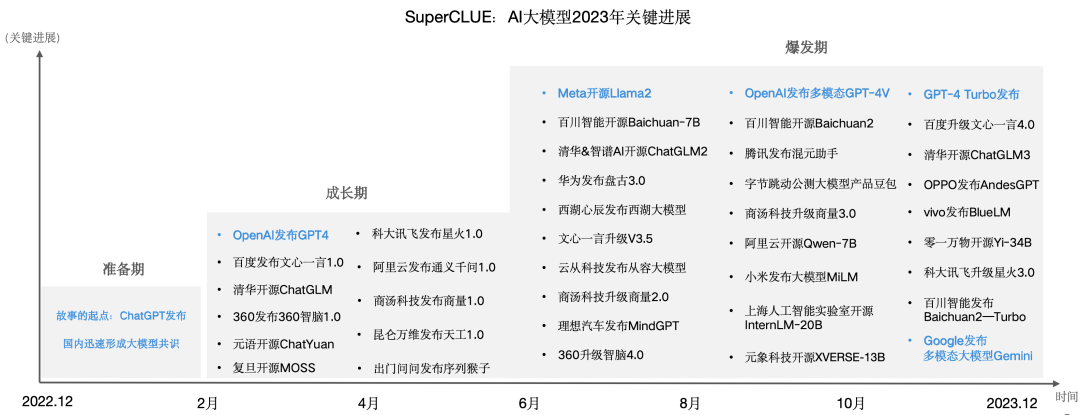
截止目前為止,國(guó)內(nèi)已發(fā)布開(kāi)源、閉源通用大模型及行業(yè)大模型已有上百個(gè),SuperCLUE梳理了2023年值得關(guān)注的大模型全景圖。

022023年國(guó)內(nèi)外大模型發(fā)展趨勢(shì)
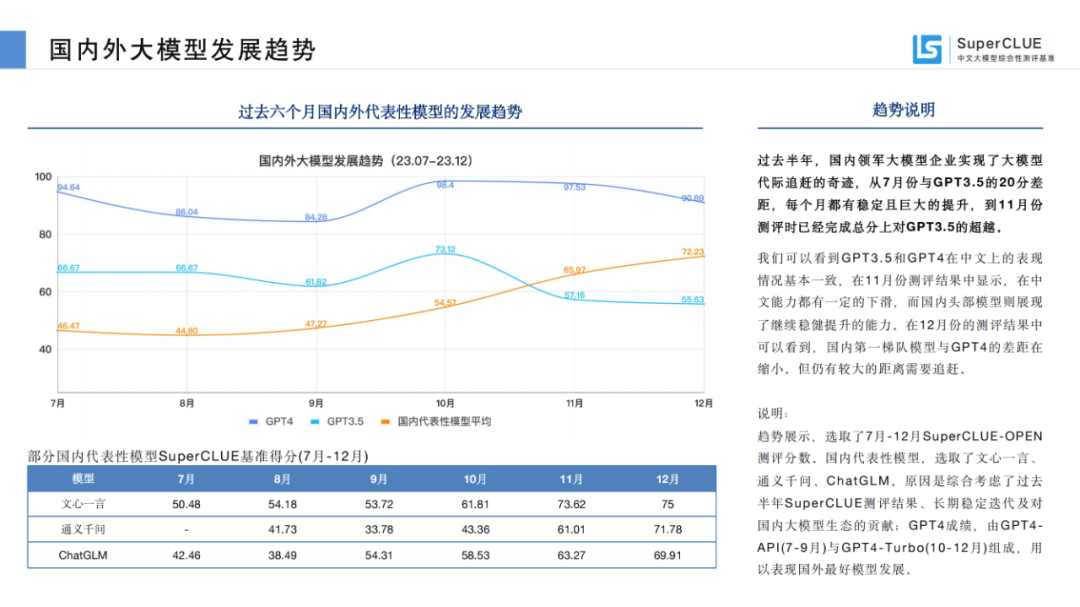
過(guò)去半年,國(guó)內(nèi)領(lǐng)軍大模型企業(yè)實(shí)現(xiàn)了大模型代際追趕的奇跡,從7月份與GPT3.5的20分差距,每個(gè)月都有穩(wěn)定且巨大的提升,到11月份測(cè)評(píng)時(shí)已經(jīng)完成總分上對(duì)GPT3.5的超越。
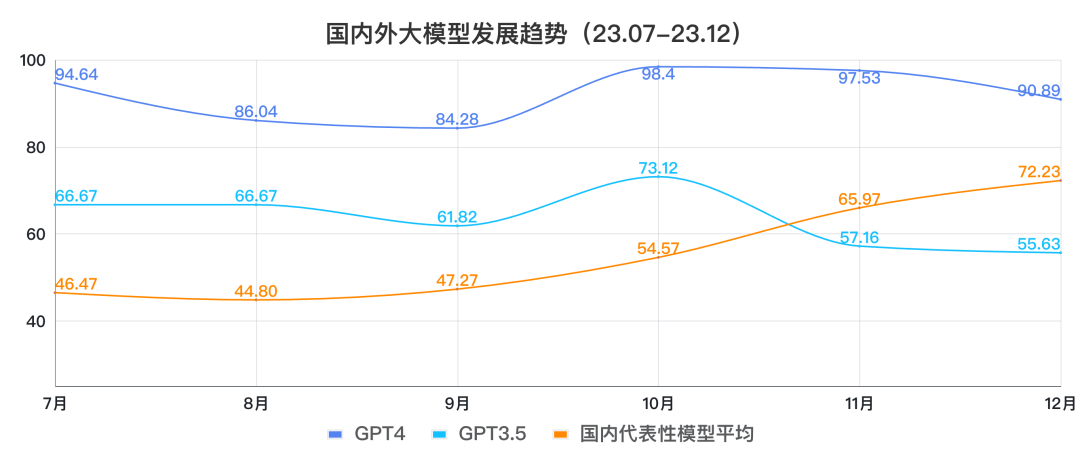
數(shù)據(jù)來(lái)源于SuperCLUE基準(zhǔn)得分(7月-12月)
我們可以看到GPT3.5和GPT4在中文上的表現(xiàn)情況基本一致,在11月份測(cè)評(píng)結(jié)果中顯示,在中文能力都有一定的下滑,而國(guó)內(nèi)頭部模型則展現(xiàn)了繼續(xù)穩(wěn)健提升的能力。在12月份的測(cè)評(píng)結(jié)果中可以看到,國(guó)內(nèi)第一梯隊(duì)模型與GPT4的差距在縮小。但仍有較大的距離需要追趕。

數(shù)據(jù)來(lái)源于SuperCLUE基準(zhǔn)得分(7月-12月) 說(shuō)明:趨勢(shì)展示,選取了7月-12月SuperCLUE-OPEN測(cè)評(píng)分?jǐn)?shù)。國(guó)內(nèi)代表性模型,選取了文心一言、通義千問(wèn)、ChatGLM。原因是綜合考慮了過(guò)去半年SuperCLUE測(cè)評(píng)結(jié)果、長(zhǎng)期穩(wěn)定迭代及對(duì)國(guó)內(nèi)大模型生態(tài)的貢獻(xiàn);GPT4成績(jī),由GPT4-API(7-9月)與GPT4-Turbo(10-12月)組成,用以表現(xiàn)國(guó)外最好模型發(fā)展。  ?大模型綜合測(cè)評(píng)結(jié)果?01測(cè)評(píng)模型列表
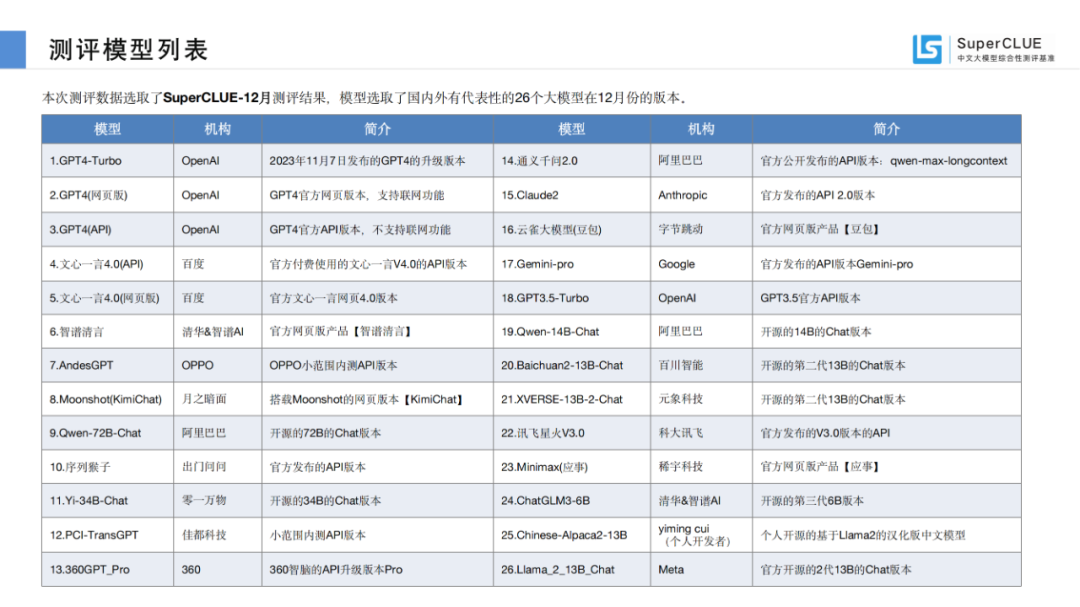
?大模型綜合測(cè)評(píng)結(jié)果?01測(cè)評(píng)模型列表
本次測(cè)評(píng)數(shù)據(jù)選取了SuperCLUE-12月測(cè)評(píng)結(jié)果,模型選取了國(guó)內(nèi)外有代表性的26個(gè)大模型在12月份的版本。
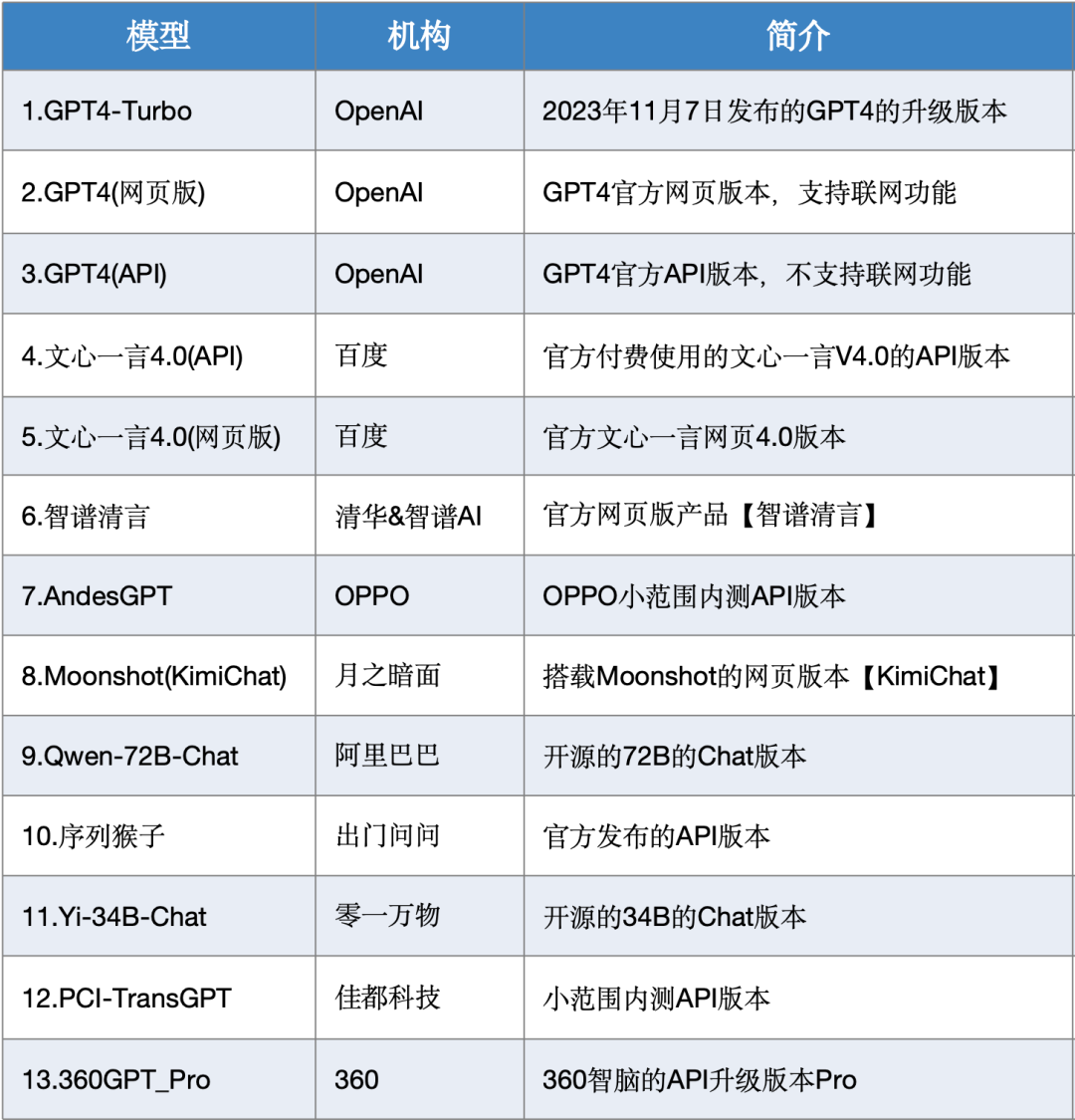
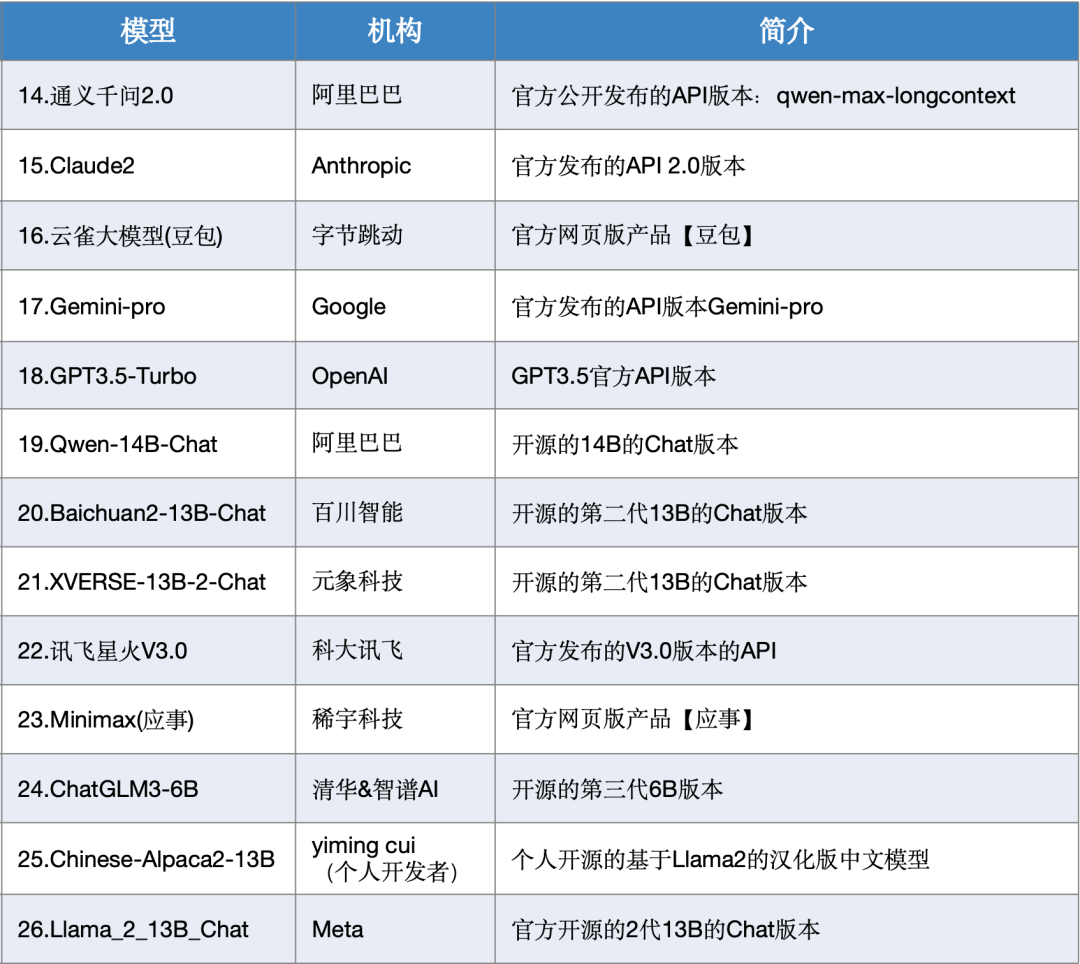
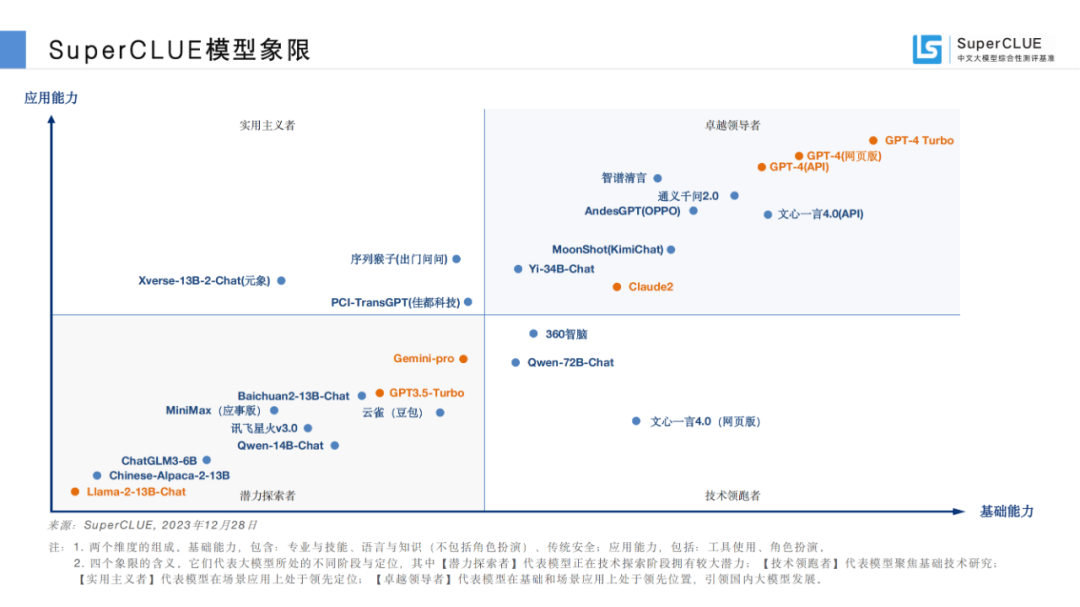
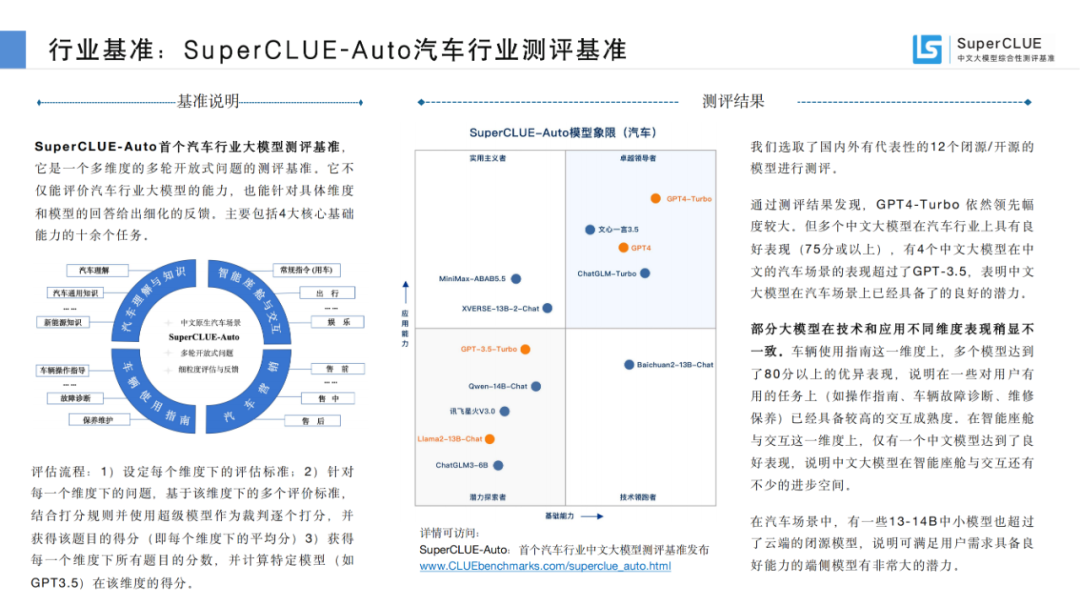
02SuperCLUE模型象限
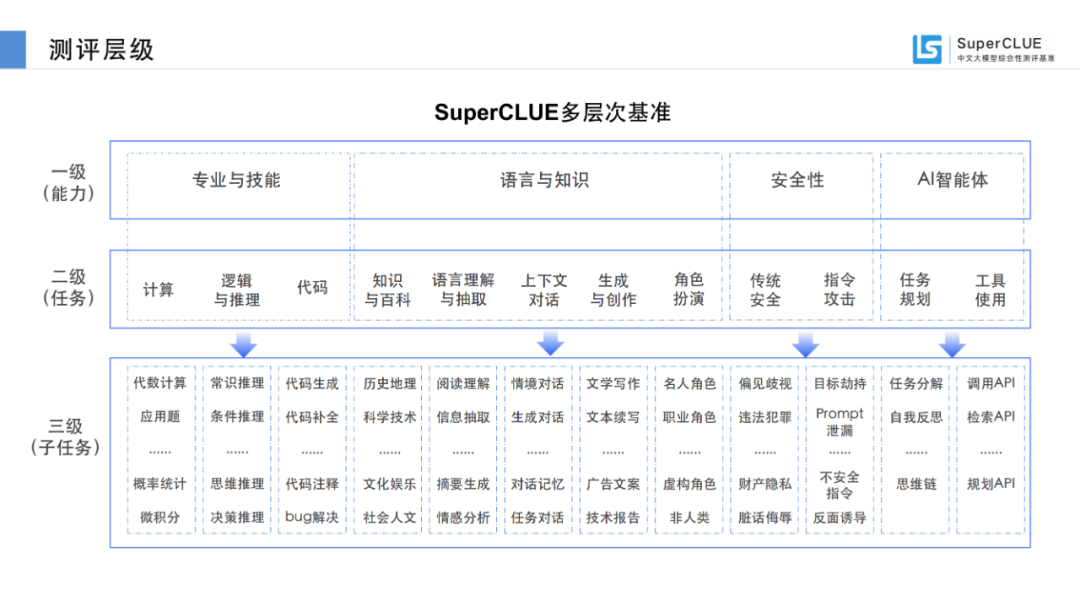
SuperCLUE評(píng)測(cè)任務(wù)可劃分為基礎(chǔ)能力和應(yīng)用能力兩個(gè)維度。
基礎(chǔ)能力,包含:專(zhuān)業(yè)與技能、語(yǔ)言與知識(shí)(不包括角色扮演)、傳統(tǒng)安全;
應(yīng)用能力,包括:工具使用、角色扮演。
基于此,SuperCLUE構(gòu)建了大模型四個(gè)象限,它們代表大模型所處的不同階段與定位,其中【潛力探索者】代表模型正在技術(shù)探索階段擁有較大潛力;【技術(shù)領(lǐng)跑者】代表模型聚焦基礎(chǔ)技術(shù)研究;【實(shí)用主義者】代表模型在場(chǎng)景應(yīng)用上處于領(lǐng)先定位;【卓越領(lǐng)導(dǎo)者】代表模型在基礎(chǔ)和場(chǎng)景應(yīng)用上處于領(lǐng)先位置,引領(lǐng)國(guó)內(nèi)大模型發(fā)展。
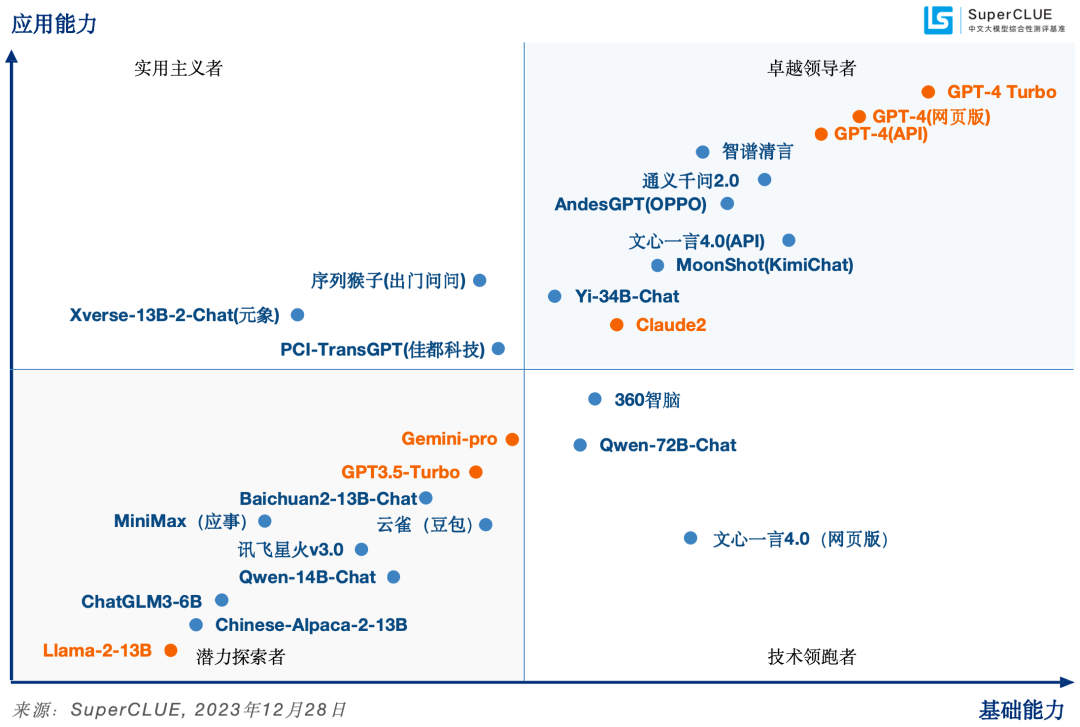
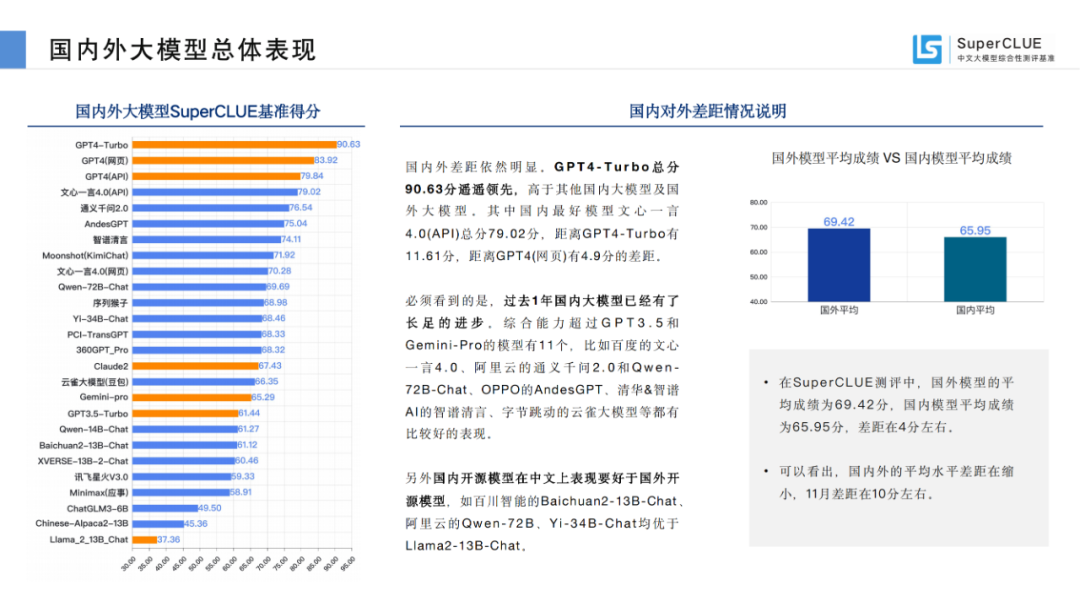
03國(guó)內(nèi)外大模型總體表現(xiàn)
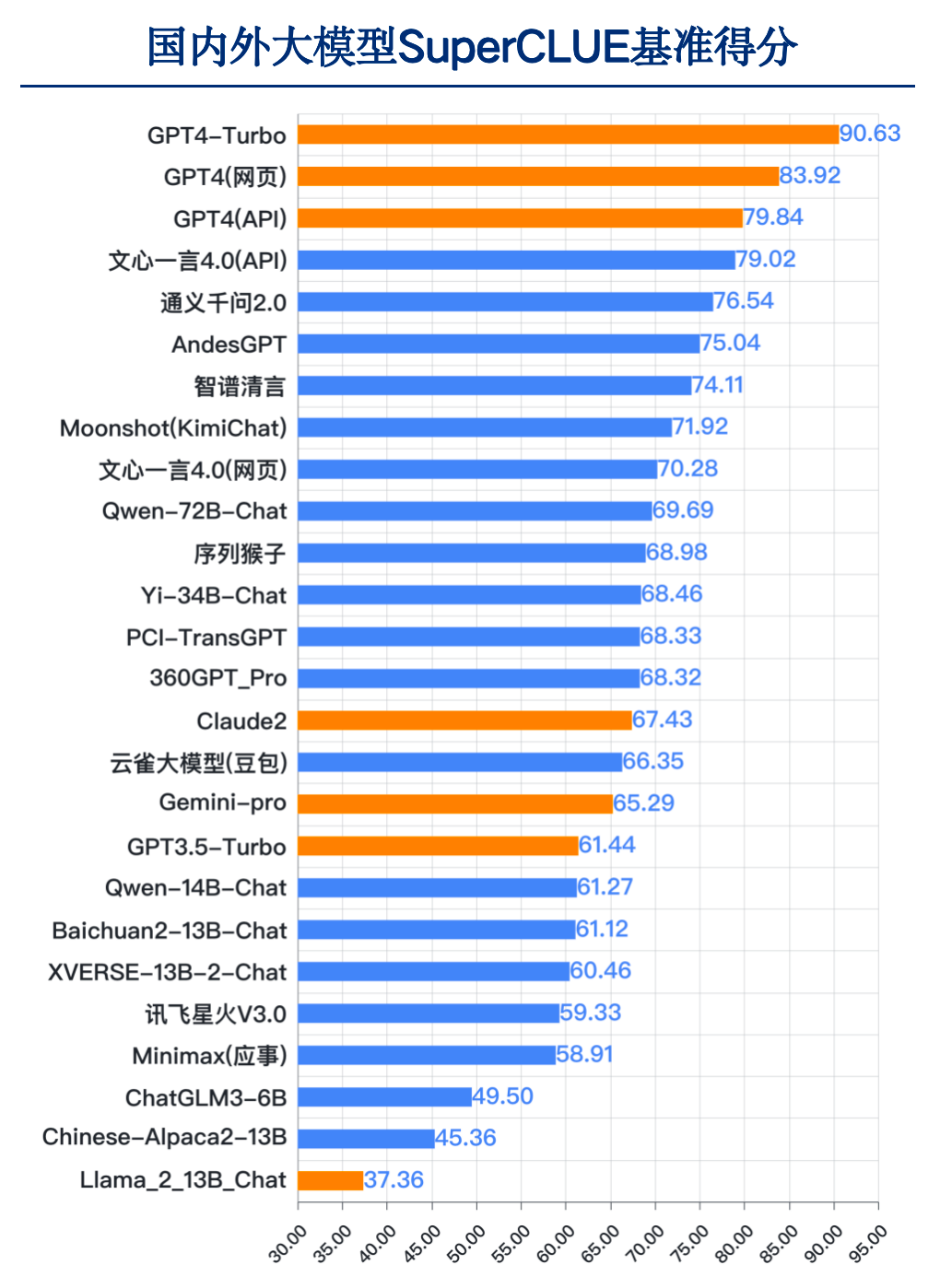
來(lái)源:SuperCLUE, 2023年12月28日
國(guó)內(nèi)外差距依然明顯。GPT4-Turbo總分90.63分遙遙領(lǐng)先,高于其他國(guó)內(nèi)大模型及國(guó)外大模型。其中國(guó)內(nèi)最好模型文心一言4.0(API)總分79.02分,距離GPT4-Turbo有11.61分,距離GPT4(網(wǎng)頁(yè))有4.9分的差距。
必須看到的是,過(guò)去1年國(guó)內(nèi)大模型已經(jīng)有了長(zhǎng)足的進(jìn)步。綜合能力超過(guò)GPT3.5和Gemini-Pro的模型有11個(gè),比如百度的文心一言4.0、阿里云的通義千問(wèn)2.0和Qwen-72B-Chat、OPPO的AndesGPT、清華&智譜AI的智譜清言、字節(jié)跳動(dòng)的云雀大模型等都有比較好的表現(xiàn)。
另外國(guó)內(nèi)開(kāi)源模型在中文上表現(xiàn)要好于國(guó)外開(kāi)源模型,如百川智能的Baichuan2-13B-Chat、阿里云的Qwen-72B、Yi-34B-Chat均優(yōu)于Llama2-13B-Chat。
國(guó)外模型平均成績(jī) VS 國(guó)內(nèi)模型平均成績(jī)
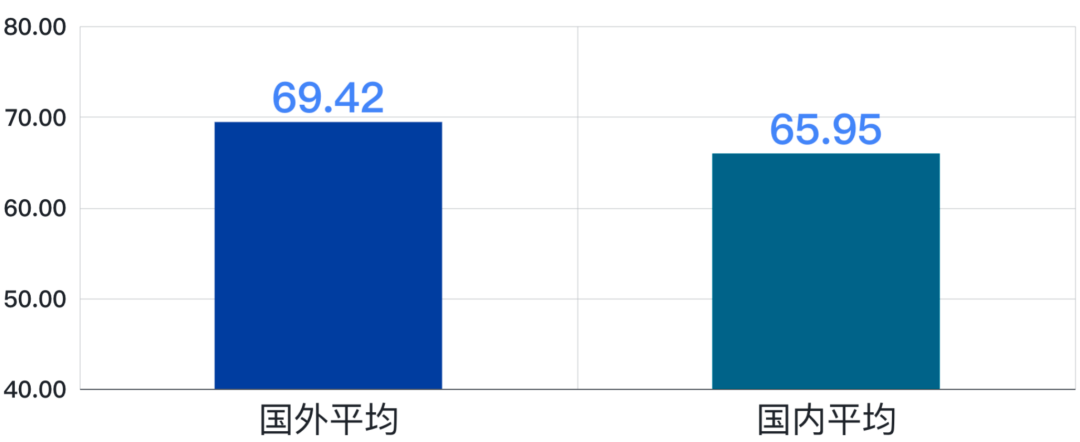
在SuperCLUE測(cè)評(píng)中,國(guó)外模型的平均成績(jī)?yōu)?9.42分,國(guó)內(nèi)模型平均成績(jī)?yōu)?5.95分,差距在4分左右。可以看出,國(guó)內(nèi)外的平均水平差距在縮小,11月差距在10分左右。04國(guó)內(nèi)大模型競(jìng)爭(zhēng)格局
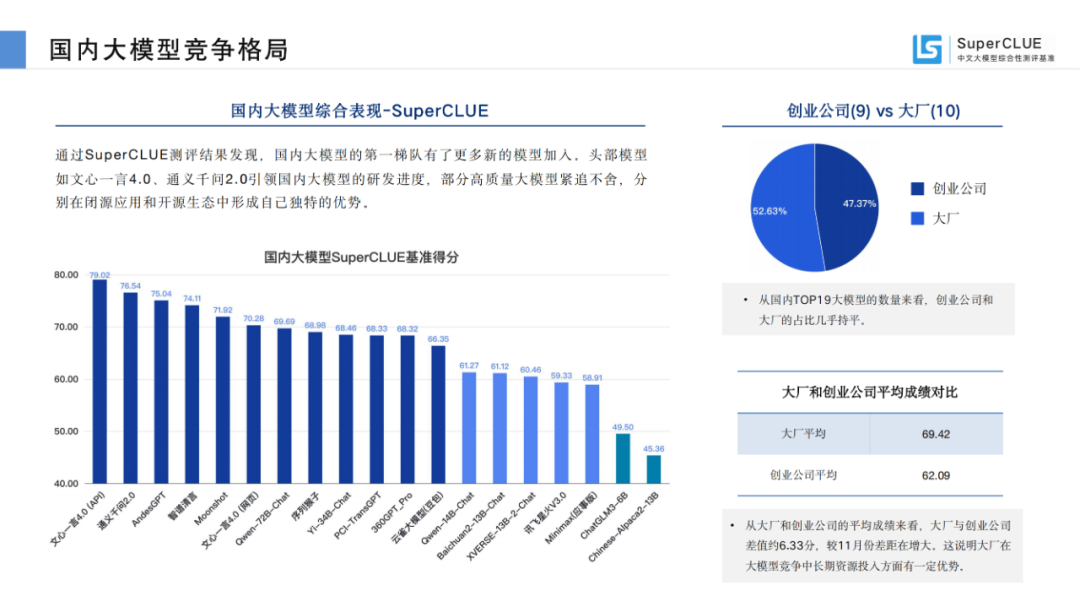
通過(guò)SuperCLUE測(cè)評(píng)結(jié)果發(fā)現(xiàn),國(guó)內(nèi)大模型的第一梯隊(duì)有了更多新的模型加入。頭部模型如文心一言4.0、通義千問(wèn)2.0引領(lǐng)國(guó)內(nèi)大模型的研發(fā)進(jìn)度,部分高質(zhì)量大模型緊追不舍,分別在閉源應(yīng)用和開(kāi)源生態(tài)中形成自己獨(dú)特的優(yōu)勢(shì)。
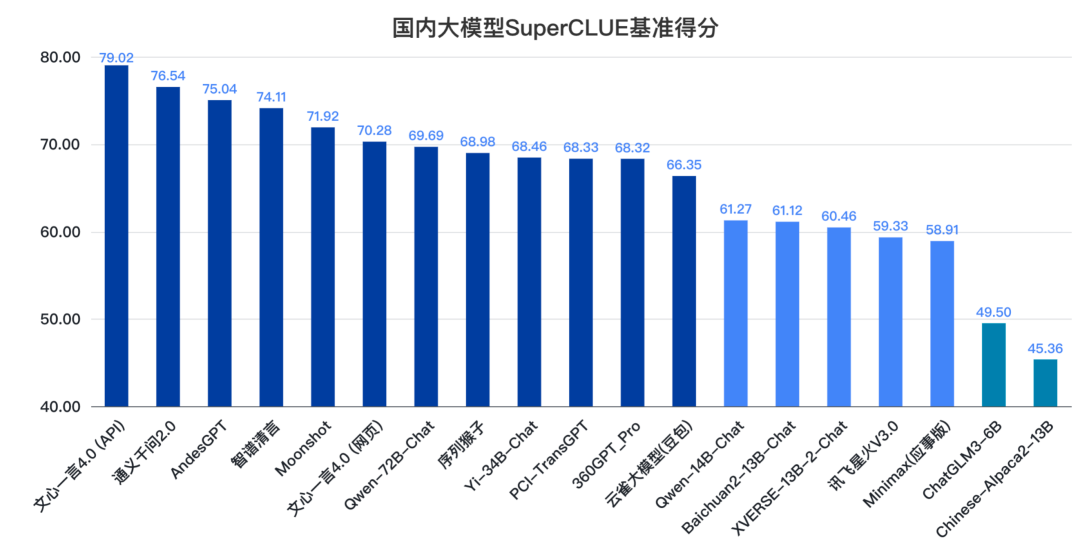
來(lái)源:SuperCLUE, 2023年12月28日
從國(guó)內(nèi)TOP19大模型的數(shù)量來(lái)看,創(chuàng)業(yè)公司有9個(gè),大廠有10個(gè),占比幾乎持平。
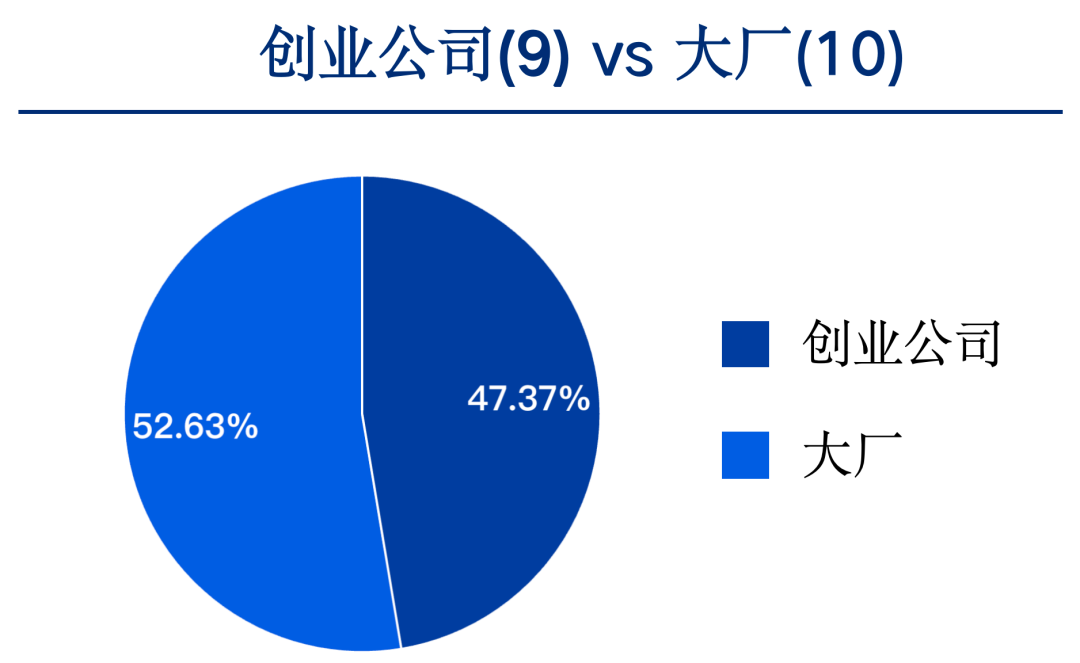
從大廠和創(chuàng)業(yè)公司的平均成績(jī)來(lái)看,大廠研發(fā)的大模型平均成績(jī)?yōu)?9.42分,創(chuàng)業(yè)公司研發(fā)的大模型平均成績(jī)?yōu)?2.09分,差值約6.33分,較11月份差距在略有增大。這說(shuō)明大廠在大模型競(jìng)爭(zhēng)中長(zhǎng)期資源投入方面有一定優(yōu)勢(shì)。

05國(guó)內(nèi)大模型歷月前三甲
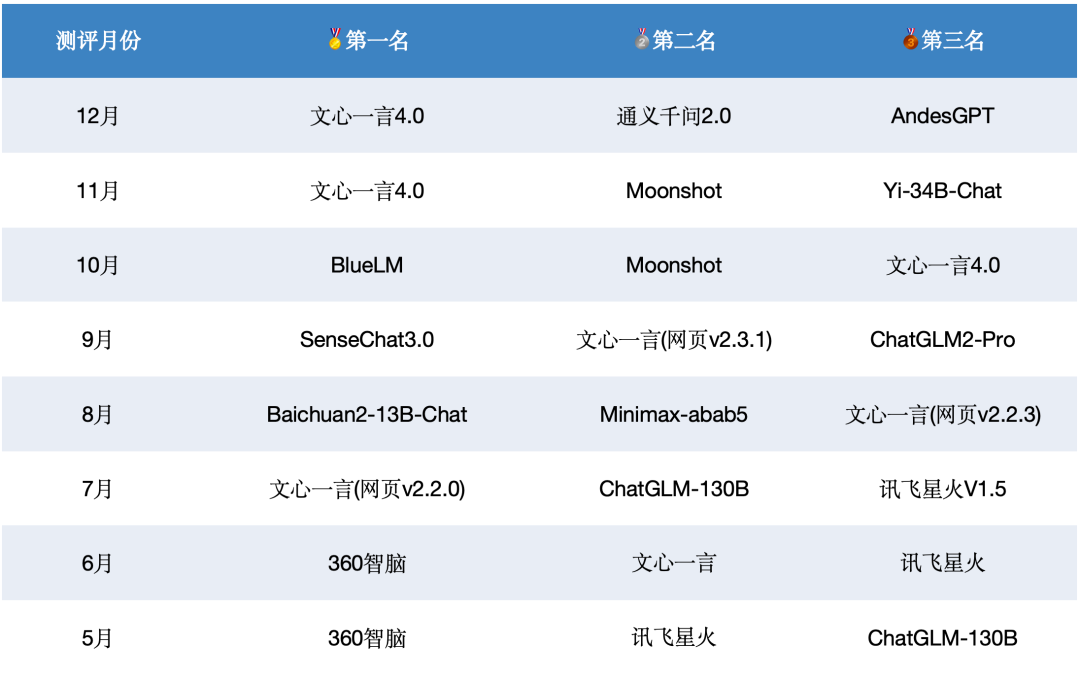
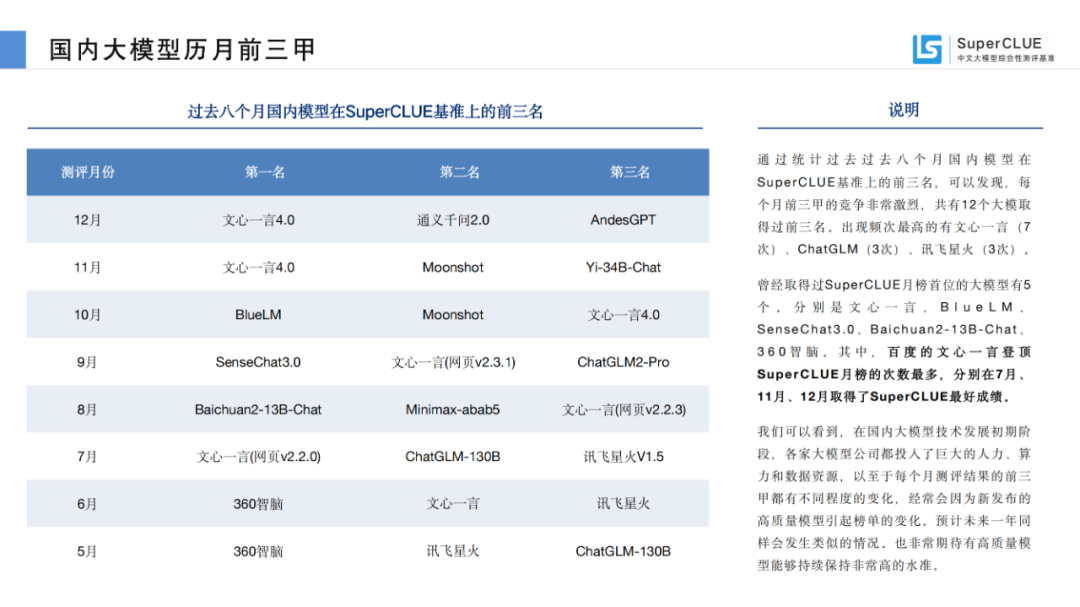
過(guò)去八個(gè)月國(guó)內(nèi)模型在SuperCLUE基準(zhǔn)上的前三名。
來(lái)源:SuperCLUE
曾經(jīng)取得過(guò)SuperCLUE月榜首位的大模型有6個(gè)。分別是文心一言、BlueLM、SenseChat3.0、Baichuan2-13B-Chat、360智腦。其中,百度的文心一言登頂SuperCLUE月榜的次數(shù)最多,分別在7月、11月、12月取得了SuperCLUE最好成績(jī)。
我們可以看到,在國(guó)內(nèi)大模型技術(shù)發(fā)展初期階段,各家大模型公司都投入了巨大的人力、算力和數(shù)據(jù)資源,以至于每個(gè)月測(cè)評(píng)結(jié)果的前三甲都不同程度的變化,經(jīng)常會(huì)因?yàn)樾掳l(fā)布的高質(zhì)量模型引起榜單的變化。預(yù)計(jì)未來(lái)一年同樣會(huì)發(fā)生類(lèi)似的情況。也非常期待有高質(zhì)量模型能夠持續(xù)保持非常高的水準(zhǔn)。
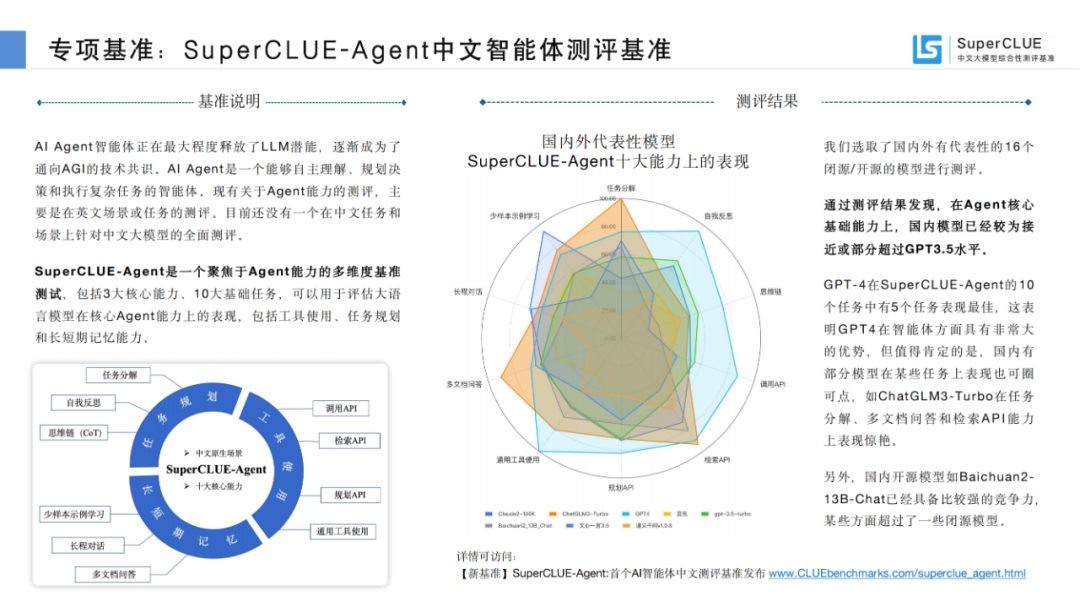
06大模型對(duì)戰(zhàn)勝率分布圖
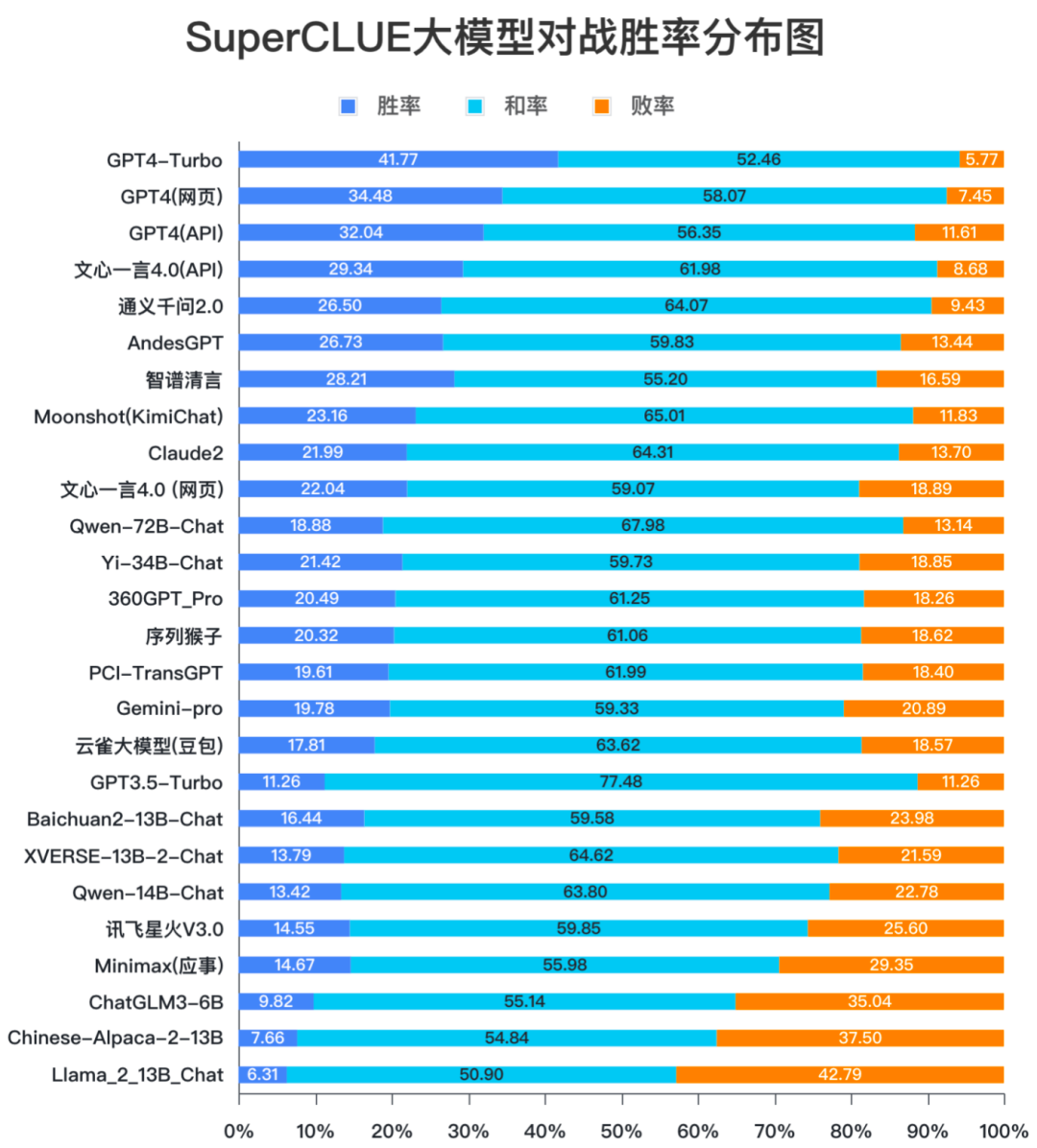
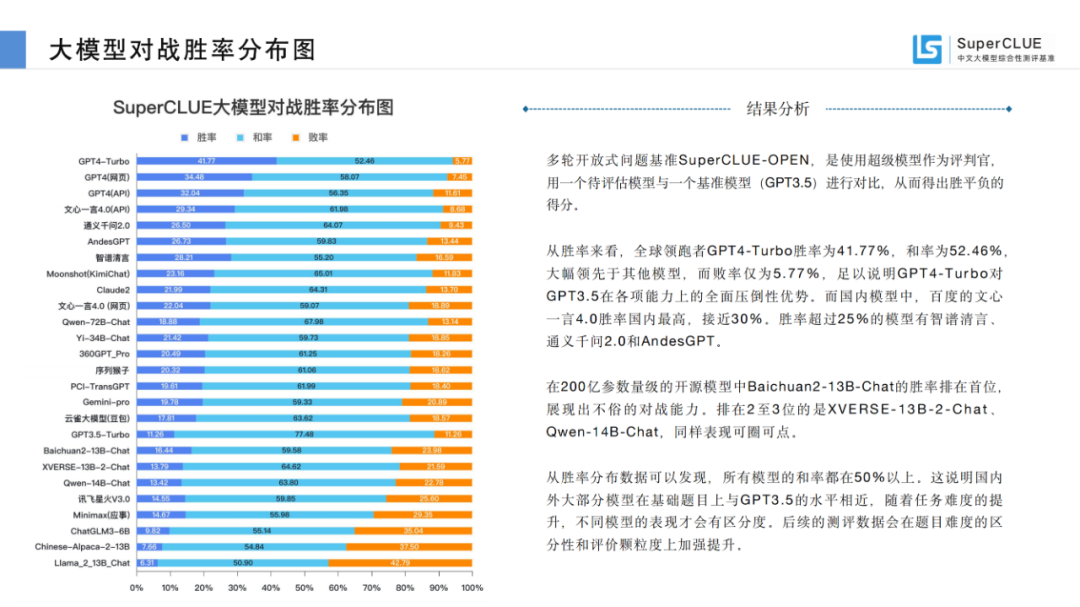
從勝率來(lái)看,全球領(lǐng)跑者GPT4-Turbo勝率為41.77%,和率為52.46%,大幅領(lǐng)先于其他模型,而敗率僅為5.77%,足以說(shuō)明GPT4-Turbo對(duì)GPT3.5在各項(xiàng)能力上的全面壓倒性?xún)?yōu)勢(shì)。而國(guó)內(nèi)模型中,百度的文心一言4.0勝率國(guó)內(nèi)最高,接近30%。勝率超過(guò)25%的模型有智譜清言、通義千問(wèn)2.0和AndesGPT。
來(lái)源:SuperCLUE, 2023年12月28日
在200億參數(shù)量級(jí)的開(kāi)源模型中Baichuan2-13B-Chat的勝率排在首位,展現(xiàn)出不俗的對(duì)戰(zhàn)能力。排在2至3位的是XVERSE-13B-2-Chat、Qwen-14B-Chat,同樣表現(xiàn)可圈可點(diǎn)。
從勝率分布數(shù)據(jù)可以發(fā)現(xiàn),所有模型的和率都在50%以上。這說(shuō)明國(guó)內(nèi)外大部分模型在基礎(chǔ)題目上與GPT3.5的水平相近,隨著任務(wù)難度的提升,不同模型的表現(xiàn)才會(huì)有區(qū)分度。后續(xù)的測(cè)評(píng)數(shù)據(jù)會(huì)在題目難度的區(qū)分性和評(píng)價(jià)顆粒度上加強(qiáng)提升。
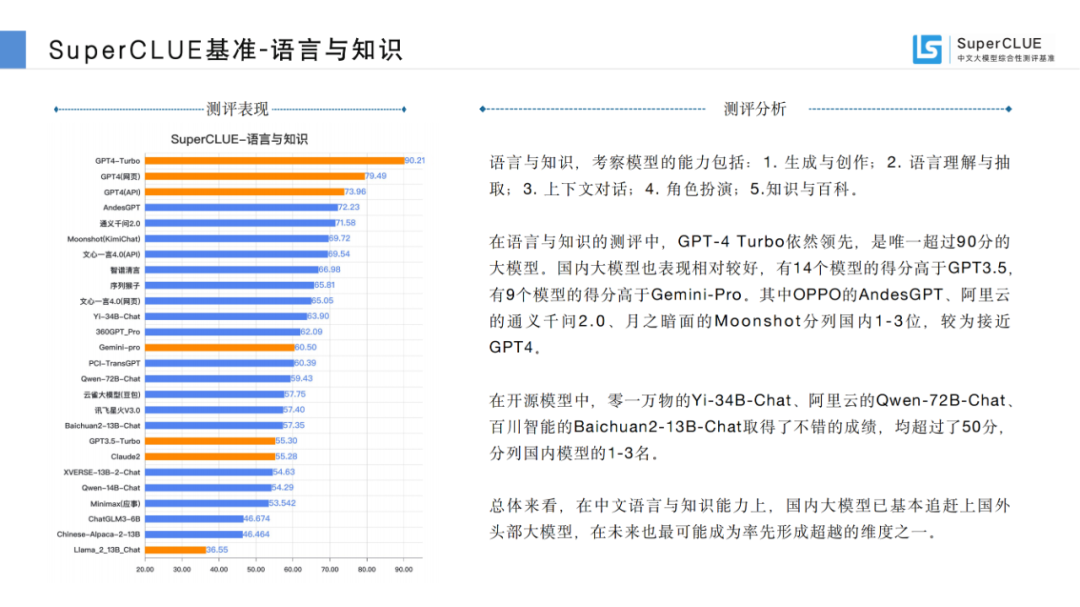
07主觀與客觀對(duì)比
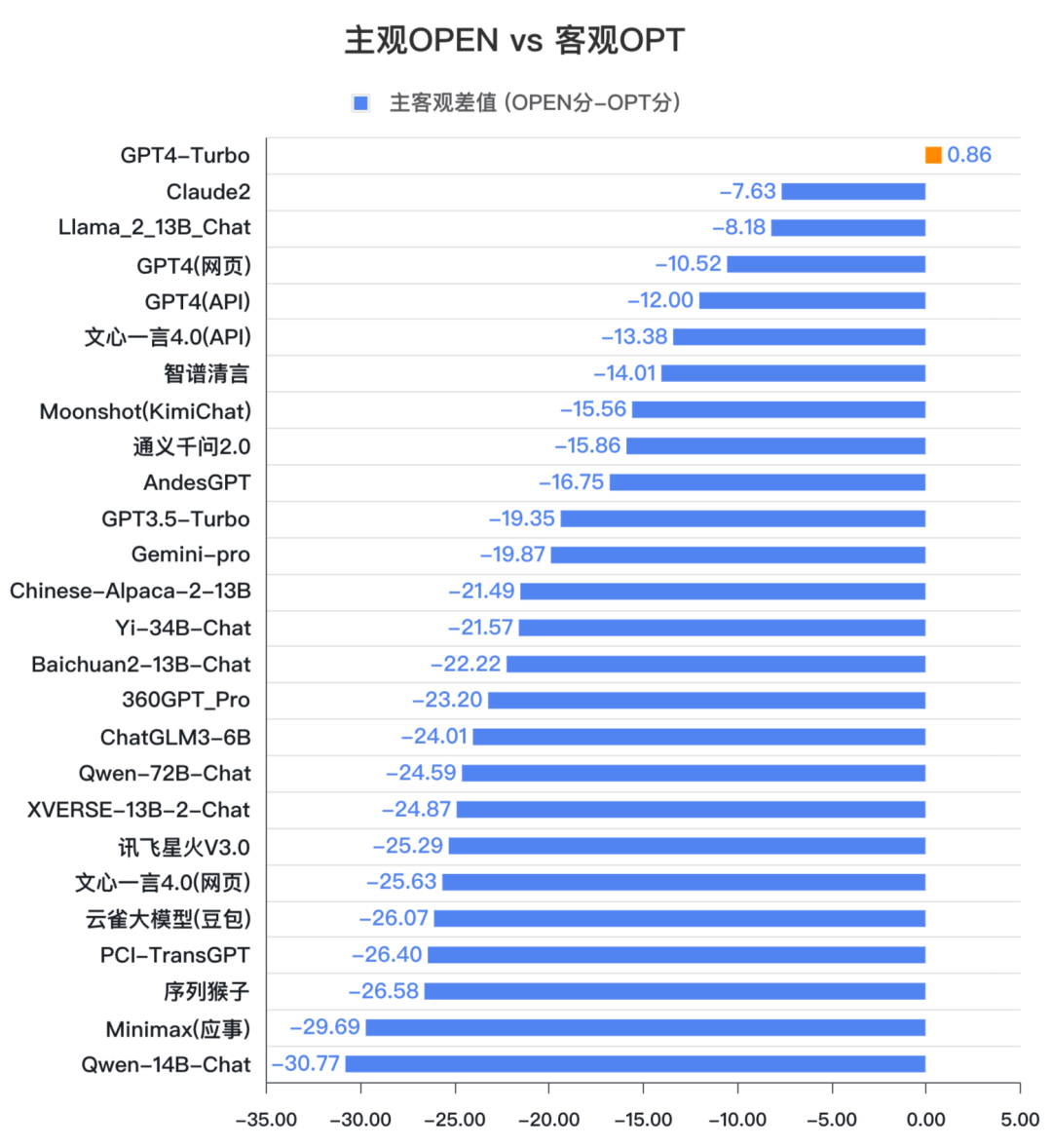
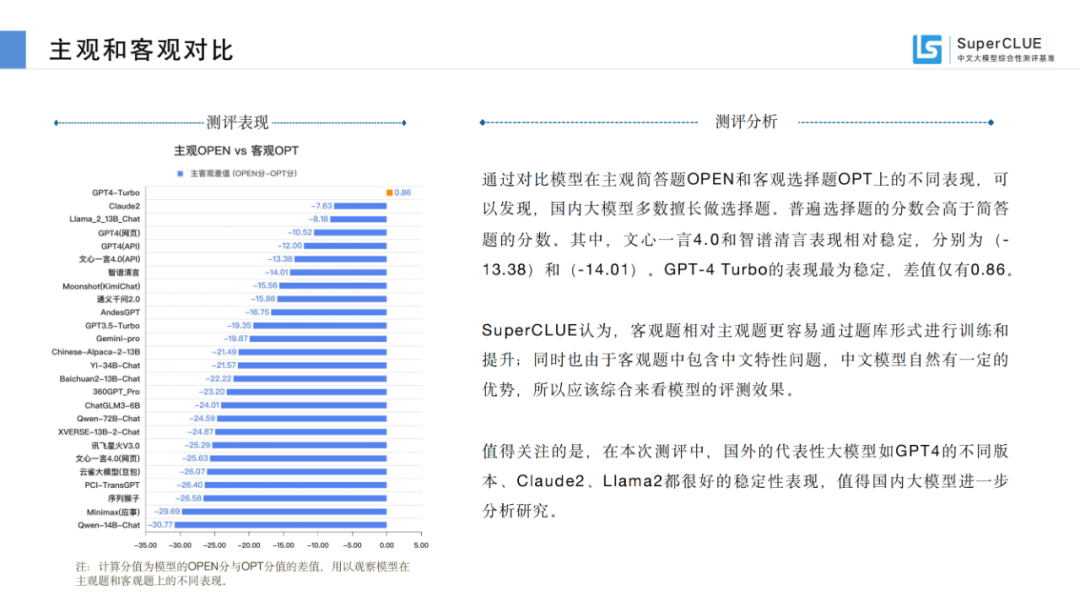
通過(guò)對(duì)比模型在主觀簡(jiǎn)答題OPEN和客觀選擇題OPT上的不同表現(xiàn),可以發(fā)現(xiàn),國(guó)內(nèi)大模型多數(shù)擅長(zhǎng)做選擇題。普遍選擇題的分?jǐn)?shù)會(huì)高于簡(jiǎn)答題的分?jǐn)?shù)。
注:計(jì)算分值為模型的OPEN分與OPT分值的差值,用以觀察模型在主觀題和客觀題上的不同表現(xiàn)。數(shù)據(jù)來(lái)源:SuperCLUE, 2023年12月28日
其中,文心一言4.0和智譜清言表現(xiàn)相對(duì)穩(wěn)定,分別為(-13.38)和(-14.01)。GPT-4 Turbo的表現(xiàn)最為穩(wěn)定,差值僅有0.86。
SuperCLUE認(rèn)為,客觀題相對(duì)主觀題更容易通過(guò)題庫(kù)形式進(jìn)行訓(xùn)練和提升;同時(shí)也由于客觀題中包含中文特性問(wèn)題,中文模型自然有一定的優(yōu)勢(shì),所以應(yīng)該綜合來(lái)看模型的評(píng)測(cè)效果。
值得關(guān)注的是,在本次測(cè)評(píng)中,國(guó)外的代表性大模型如GPT4的不同版本、Claude2、Llama2都很好的穩(wěn)定性表現(xiàn),值得國(guó)內(nèi)大模型進(jìn)一步分析研究。
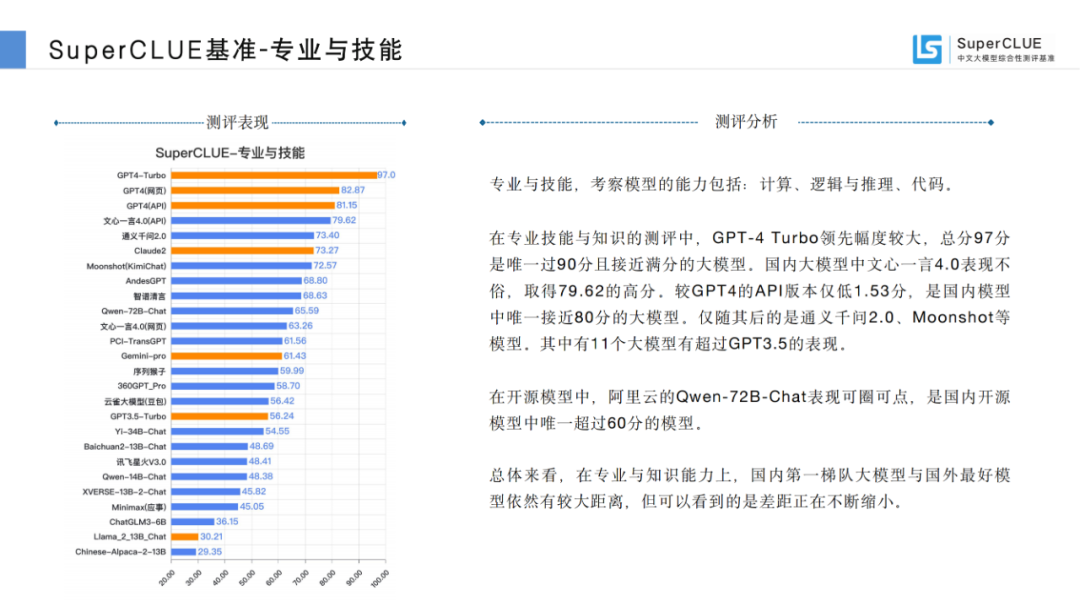
08開(kāi)源競(jìng)爭(zhēng)格局
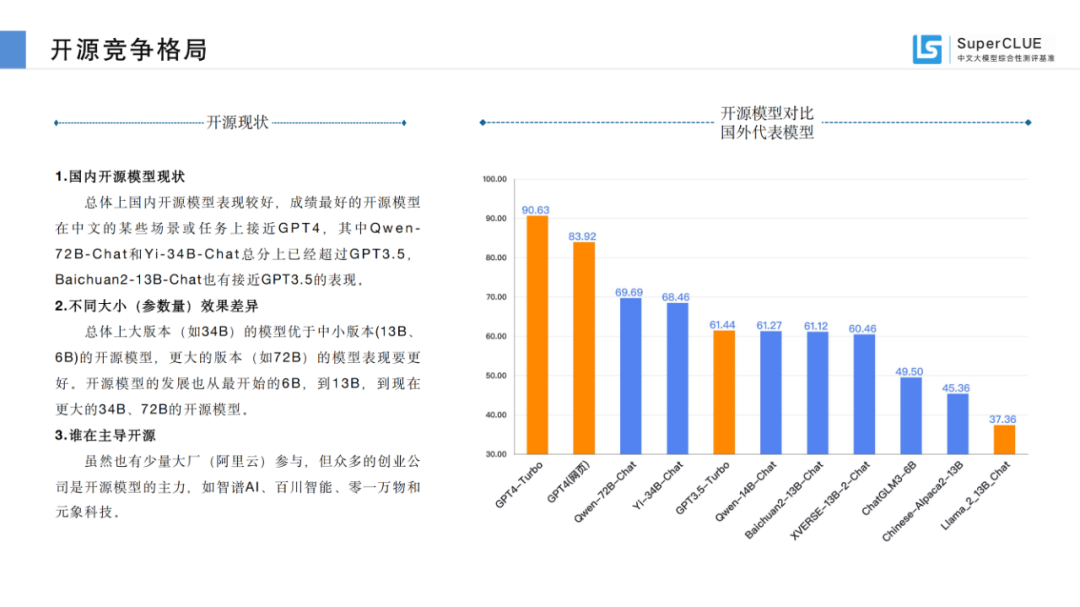
總體上國(guó)內(nèi)開(kāi)源模型表現(xiàn)較好,成績(jī)最好的開(kāi)源模型在中文的某些場(chǎng)景或任務(wù)上接近GPT4,其中Qwen-72B-Chat和Yi-34B-Chat總分上已經(jīng)超過(guò)GPT3.5,Baichuan2-13B-Chat也有接近GPT3.5的表現(xiàn)。
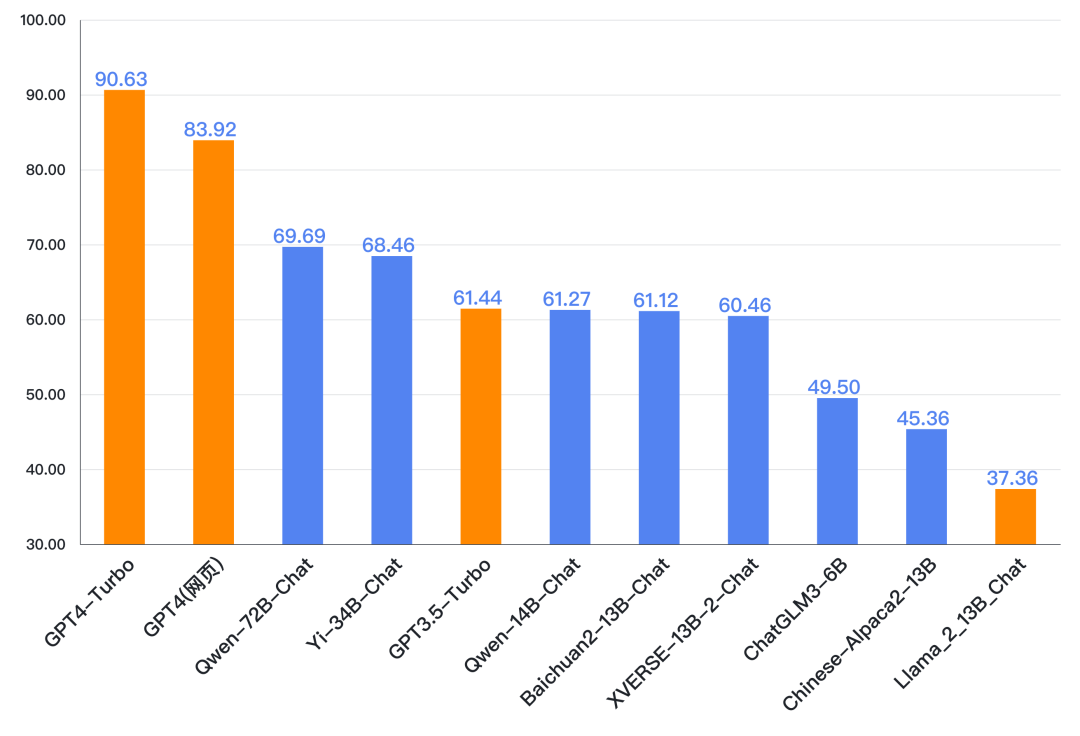
來(lái)源:SuperCLUE, 2023年12月28日
總體上大版本(如34B)的模型優(yōu)于中小版本(13B、6B)的開(kāi)源模型,更大的版本(如72B)的模型表現(xiàn)要更好。開(kāi)源模型的發(fā)展也從最開(kāi)始的6B,到13B,到現(xiàn)在更大的34B、72B的開(kāi)源模型。
雖然也有少量大廠(阿里云)參與,但眾多的創(chuàng)業(yè)公司是開(kāi)源模型的主力,如智譜AI、百川智能、零一萬(wàn)物和元象科技。
具體內(nèi)容如下
































-
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268886 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1558瀏覽量
7595 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
原文標(biāo)題:中文大模型基準(zhǔn)測(cè)評(píng)2023年度報(bào)告
文章出處:【微信號(hào):WUKOOAI,微信公眾號(hào):悟空智能科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦

天合光能發(fā)布2023年度報(bào)告及2024年一季度報(bào)告,營(yíng)收1133.92億元
藍(lán)思科技發(fā)布2023年年度報(bào)告:營(yíng)收544.91億元,同比增長(zhǎng)16.69%
拓普集團(tuán)發(fā)布2023年度財(cái)報(bào)

雷曼光電披露2023年年度報(bào)告:營(yíng)業(yè)收入11.13億元,同比增長(zhǎng)2.77%

長(zhǎng)電科技公布2023年年度報(bào)告:全年實(shí)現(xiàn)營(yíng)業(yè)收入人民幣296.6億元
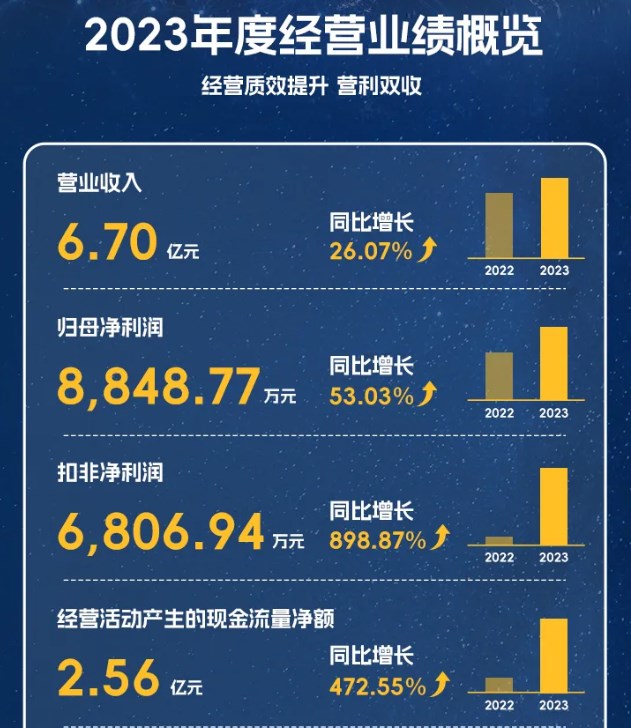

華域汽車(chē)系統(tǒng)股份有限公司發(fā)布2023年年度報(bào)告
IBM發(fā)布2023年度報(bào)告,總營(yíng)收為619億美元
深天馬發(fā)布2023年年度報(bào)告:營(yíng)業(yè)收入322.71億元,同比上升2.62%






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論