 AHB與DMA詳細解讀
AHB與DMA詳細解讀
AHB(先進高性能總線)
隨著深亞微米工藝技術日益成熟,集成電路芯片的規模越來越大。數字IC從基于時序驅動的設計方法,發展到基于IP核復用的設計方法,并在SOC設計中得到了廣泛應用。在基于IP核復用的SoC(System on Chip的縮寫,稱為系統級芯片,也有稱片上系統)設計中,片上總線設計是最關鍵的問題。為此,業界出現了很多片上總線標準。其中,由ARM公司推出的AMBA片上總線受到了廣大IP開發商和SoC系統集成者的青睞,已成為一種流行的工業標準片上結構。AMBA規范主要包括了AHB(Advanced High performance Bus)系統總線和APB(Advanced Peripheral Bus)外圍總線。
AHB
AHB=Advanced High Performance Bus,高級高性能總線。如同USB(Universal Serial Bus)一樣,也是一種總線接口。
AHB主要用于高性能模塊(如CPU、DMA和DSP等)之間的連接,作為SoC的片上系統總線,它包括以下一些特性:單個時鐘邊沿操作;非三態的實現方式;支持突發傳輸;支持分段傳輸;支持多個主控制器;可配置32位~128位總線寬度;支持字節、半字和字的傳輸。AHB 系統由主模塊、從模塊和基礎結構(Infrastructure)3部分組成,整個AHB總線上的傳輸都由主模塊發出,由從模塊負責回應。基礎結構則由仲裁器(arbiter)、主模塊到從模塊的多路器、從模塊到主模塊的多路器、譯碼器(decoder)、虛擬從模塊(dummy Slave)、虛擬主模塊(dummy Master)所組成。針對Soc設計中IP復用問題提出了一種新的解決辦法。傳統的方法是將特定功能模塊的非標準接口標準化為AHB主/從設備接口。本文提出了一種新的基于ARM的Soc通用平臺設計寄存器總線標準接口,這種設計使整個系統的結構清晰,增強系統的通用性與系統中功能模塊的可移植性。
AMBA
AMBA 2.0規范包括四個部分:AHB、ASB、APB和Test Methodology。AHB的相互連接采用了傳統的帶有主模塊和從模塊的共享總線,接口與互連功能分離,這對芯片上模塊之間的互連具有重要意義。AMBA已不僅是一種總線,更是一種帶有接口模塊的互連體系。
APB
APB主要用于低帶寬的周邊外設之間的連接,例如UART、1284等,它的總線架構不像AHB支持多個主模塊,在APB里面唯一的主模塊就是APB 橋。其特性包括:兩個時鐘周期傳輸;無需等待周期和回應信號;控制邏輯簡單,只有四個控制信號。
1)系統初始化為IDLE狀態,此時沒有傳輸操作,也沒有選中任何從模塊。2)當有傳輸要進行時,PSELx=1,PENABLE=0,系統進入SETUP狀態,并只會在SETUP 狀態停留一個周期。當PCLK的下一個上升沿時到來時,系統進入ENABLE 狀態。
3)系統進入ENABLE狀態時,維持之前在SETUP 狀態的PADDR、PSEL、PWRITE不變,并將PENABLE置為1。傳輸也只會在ENABLE狀態維持一個周期,在經過SETUP與ENABLE狀態之后就已完成。之后如果沒有傳輸要進行,就進入IDLE狀態等待;如果有連續的傳輸,則進入SETUP狀態。
轉換
大多數掛在總線上的模塊(包括處理器)只是單一屬性的功能模塊:主模塊或者從模塊。主模塊是向從模塊發出讀寫操作的模塊,如CPU,DSP等;從模塊是接受命令并做出反應的模塊,如片上的RAM,AHB/APB 橋等。另外,還有一些模塊同時具有兩種屬性,例如直接存儲器存取(DMA)在被編程時是從模塊,但在系統讀傳輸數據時必須是主模塊。如果總線上存在多個主模塊,就需要仲裁器來決定如何控制各種主模塊對總線的訪問。雖然仲裁規范是AMBA總線規范中的一部分,但具體使用的算法由RTL設計工程師決定,其中兩個最常用的算法是固定優先級算法和循環制算法。AHB總線上最多可以有16個主模塊和任意多個從模塊,如果主模塊數目大于16,則需再加一層結構(具體參閱ARM公司推出的Multi-layer AHB規范)。APB 橋既是APB總線上唯一的主模塊,也是AHB系統總線上的從模塊。其主要功能是鎖存來自AHB系統總線的地址、數據和控制信號,并提供二級譯碼以產生APB外圍設備的選擇信號,從而實現AHB協議到APB協議的轉換。
DMA
直接內存訪問(DMA,Direct Memory Access)是一些計算機總線架構提供的功能,它能使數據從附加設備(如磁盤驅動器)直接發送到計算機主板的內存上。
通常會指定一個內存部分用于直接內存訪問。在ISA總線標準中,高達16兆字節的內存可用于DMA。EISA和微通道架構標準允許訪問全套內存地址(假設他們可以用32位尋址)。外圍設備互連通過使用一個總線主控器來完成直接內存訪問。直接內存訪問的另一個選擇是程控輸入輸出(PIO)接口。在程控輸入輸出接口中,設備之間所有的數據傳輸都要通過處理器。ATA/IDE接口的新協議是Ultra DMA,它提供的突發數據傳輸速率可達33兆字節每秒。具有Ultra DMA/33的硬盤驅動器也支持PIO模式1、3、4和多字DMA模式2(每秒16.6兆字節)。
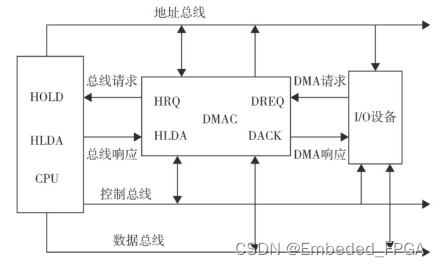
外設與存儲器之間以及存儲器與存儲器之間的數據傳輸,通常采用程序中斷方式、程序查詢方式和DMA控制方式。程序中斷方式和程序查詢方式都需要CPU發出輸入/輸出(In/Out,I/O)的指令,然后等待I/O設備完成操作之后返回,期間CPU需要等待I/O設備完成操作。DMA在傳輸存儲器和I/O設備的數據時,無須CPU來控制數據的傳輸,直接通過DMA控制器(direct memory access controller,DMAC)完成外設與存儲器之間以及存儲器與存儲器之間的數據高速傳輸。 [3]DMA傳輸原理一個完整的DMA傳輸包括DMA請求、DMA響應、DMA傳輸和DMA結束4個步驟。DMA傳輸原理如圖1所示,圖中I/O設備為源端設備,由I/O設備向目的端設備(存儲器)傳輸數據,其DMA的基本傳輸過程如下:①CPU對總線控制器進行初始化,制定工作內存空間,讀取DMAC中的寄存器信息,了解DMAC的傳輸狀態[1];②I/O設備向DMAC發送DMA請求(DMA request,DREQ),DMAC收到此信號后,向CPU發出總線保持信號(HOLD); ③CPU當前總線周期執行結束后發出總線響應信號保持確認(hold acknowledgment,HLDA); ④DMAC收到總線授權后,向I/O設備發送DMA響應信號DMA確認(DMA acknowledgment,DACK),表示允許I/O設備進行DMA傳送;⑤開始傳輸時,DMAC首先從源地址讀取數據并存入內部緩存中,再寫入目的地址,完成總線數據從源地址到目的地址的傳輸[1];⑥DMA傳輸完成后,DMAC向CPU發出結束信號,釋放總線,使CPU重新獲得總線控制權。一次DMA傳輸只需要執行一個DMA周期,相當于一個總線讀/寫周期,因而能夠滿足外設數據高速傳輸的需要。
DMA是所有現代電腦的重要特色,它允許不同速度的硬件設備來溝通,而不需要依于中央處理器的大量中斷負載。否則,中央處理器需要從來源把每一片段的數據復制到寄存器,然后把它們再次寫回到新的地方。在這個時間中,中央處理器對于其他的工作來說就無法使用。DMA傳輸常使用在將一個內存區從一個設備復制到另外一個。當中央處理器初始化這個傳輸動作,傳輸動作本身是由DMA控制器來實行和完成。典型的例子就是移動一個外部內存的區塊到芯片內部更快的內存去。像是這樣的操作并沒有讓處理器工作拖延,使其可以被重新調度去處理其他的工作。DMA傳輸對于高性能嵌入式系統算法和網絡是很重要的。 舉個例子,個人電腦的ISADMA控制器擁有8個DMA通道,其中的7個通道是可以讓計算機的中央處理器所利用。每一個DMA通道有一個16位地址寄存器和一個16位計數寄存器。要初始化數據傳輸時,設備驅動程序一起設置DMA通道的地址和計數寄存器,以及數據傳輸的方向,讀取或寫入。然后指示DMA硬件開始這個傳輸動作。當傳輸結束的時候,設備就會以中斷的方式通知中央處理器。“分散-收集”(Scatter-gather)DMA允許在一次單一的DMA處理中傳輸數據到多個內存區域。相當于把多個簡單的DMA要求串在一起。同樣,這樣做的目的是要減輕中央處理器的多次輸出輸入中斷和數據復制任務。 DRQ意為DMA要求;DACK意為DMA確認。這些符號一般在有DMA功能的電腦系統硬件概要上可以看到。它們表示了介于中央處理器和DMA控制器之間的電子信號傳輸線路。
DMA會導致緩存一致性問題。想像中央處理器帶有緩存與外部內存的情況,DMA的運作則是去訪問外部內存,當中央處理器訪問外部內存某個地址的時候,暫時先將新的值寫入緩存中,但并未將外部內存的數據更新,若在緩存中的數據尚未更新到外部內存前發生了DMA,則DMA過程將會讀取到未更新的數據。相同的,如果外部設備寫入新的值到外部內存內,則中央處理器若訪問緩存時則會訪問到尚未更新的數據。這些問題可以用兩種方法來解決:
1.緩存同調系統(Cache-coherent system):以硬件方法來完成,當外部設備寫入內存時以一個信號來通知緩存控制器某內存地址的值已經過期或是應該更新數據。
2.非同調系統(Non-coherent system):以軟件方法來完成,操作系統必須確認緩存讀取時,DMA程序已經開始或是禁止DMA發生。第二種的方法會造成DMA的系統負擔。
除了與硬件交互相關外,DMA也可為昂貴的內存耗費減負。比如大型的拷貝行為或scatter-gather操作,從中央處理器到專用的DMA引擎。Intel的高端服務器包含這種引擎,它被稱為I/O加速技術。
在電腦運算領域,遠程直接內存訪問(英語:remote direct memory access,RDMA)是一種直接存儲器訪問技術,它將數據直接從一臺計算機的內存傳輸到另一臺計算機,無需雙方操作系統的介入。這允許高通量、低延遲的網絡通信,尤其適合在大規模并行計算機集群中使用。
RDMA支持零復制網絡傳輸,通過使網絡適配器直接在應用程序內存間傳輸數據,不再需要在應用程序內存與操作系統緩沖區之間復制數據。這種傳輸不需要中央處理器、CPU緩存或上下文交換參與,并且傳輸可與其他系統操作并行。當應用程序執行RDMA讀取或寫入請求時,應用程序數據直接傳輸到網絡,從而減少延遲并實現快速的消息傳輸。
但是,這種策略也表現出目標節點不會收到請求完成的通知(單向通信)等相關的若干問題。
-
mcu
+關注
關注
146文章
17185瀏覽量
351727 -
dma
+關注
關注
3文章
565瀏覽量
100680 -
AHB
+關注
關注
0文章
21瀏覽量
9799 -
AHB總線
+關注
關注
0文章
18瀏覽量
9508
發布評論請先 登錄
相關推薦
ZYNQ基礎---AXI DMA使用
DMA是什么?詳細介紹
在rtt studio使用qspi dma就是進不了中斷,為什么?

經驗分享 | DMA助力實時控制

stm32f4 I2S DMA中斷進不去的原因?
STM32F205使定時器8的TIM_DMA_Update事件循環觸發DMA2,dma不起作用是為什么?
stm32F429串口采用DMA方式發送,數據流使能失敗的原因?
stm32H750VB LL庫串口DMA空閑中斷接收不到數據的原因?怎么解決?
STM32G070CB TIM1使用DMA 方式來產生PWM不同duty的波形,無法進入中斷的原因?
Xilinx高性能PCIe DMA控制器IP,8個DMA通道
什么是DMA?DMA究竟有多快!
雅特力AT32F423 DMA使用指南






 工商網監
工商網監
評論