 ChatGPT是一個好的因果推理器嗎?
ChatGPT是一個好的因果推理器嗎?
1. 背景和動機
因果推理能力對于許多自然語言處理(NLP)應用至關重要。最近的因果推理系統主要基于經過微調的預訓練語言模型(PLMs),如BERT [1] 和RoBERTa [2]。它們的因果推理能力依賴于使用大量標注數據的監督訓練,然而ChatGPT能夠在不依賴標注數據的前提下在各種NLP任務中取得良好表現。
在本文中,我們進行了全面的評估,以展示ChatGPT的因果推理能力,涉及四個最先進的(SOTA)版本的ChatGPT:text-davinci-002、text-davinci-003、gpt-3.5-turbo和gpt-4。首先,我們利用事件因果關系識別(ECI)任務作為因果推理基準。如圖1所示,ECI任務旨在確定一個句子中的兩個事件之間是否存在因果關系。這要求ChatGPT不僅要掌握常識知識,還要理解由多個實體和事件組成的復雜上下文。最后,ChatGPT必須綜合所有信息來識別因果關系。
其次,我們采用因果發現(CD)任務進行評估,這要求ChatGPT具有更廣泛和更專業的知識,但不需要考慮復雜的上下文。如圖1所示,我們使用了兩種CD任務格式:1)多項選擇,旨在從兩個選項中選擇輸入事件的原因或效果;2)二分類,旨在確定兩個輸入事件之間是否存在因果關系。對于二分類設置,我們將每個多項選擇示例轉換為兩個二分類示例,即將輸入事件與兩個選項中的每一個進行配對。我們的實驗表明,二分類是評估ChatGPT更可靠的方法。
此外,如圖1所示,我們進行因果解釋生成(CEG)任務,以測試ChatGPT是否能為事件間的因果關系生成解釋。這通常用于測試機器是否真正理解因果關系背后的原理,這對于構建可靠的因果推理系統至關重要。

圖1: 三種因果推理任務的形式和我們使用的提示。需要ChatGPT回復的內容用紅色標記。多項選擇CD任務還涉及要求選擇輸入事件可能后果的樣本。對于這些樣本,我們將問題中的“cause”修改為“result”。
關鍵發現如下:
ChatGPT不是一個好的因果推理器,但是一個好的因果解釋器。
ChatGPT存在嚴重的因果幻覺問題,它傾向于假設事件之間存在因果關系,而不管這些關系是否真正存在。
ChatGPT因果幻覺的主要原因可能是自然語言中因果關系和非因果關系之間的報告偏差。ICL和CoT [4]等技術可以進一步加劇ChatGPT的因果幻覺。此外隨著ChatGPT版本提升,這種因果幻覺變得更加明顯。
ChatGPT的因果推理能力對提示中用于表達因果概念的詞匯十分敏感。
隨著句子中事件數量的增加,以及事件之間的詞匯距離變大,ChatGPT的因果推理性能會降低。此外,ChatGPT在識別顯式因果關系方面比識別隱式因果關系做得更好。
開放式生成提示無法提高ChatGPT的因果推理能力。
2 數據集、評估指標及相關設置
2.1 數據集和評估指標
事件因果關系識別
我們在三個廣泛使用的事件因果識別(ECI)數據集上進行實驗:1) EventStoryLine v0.9(ESC)[5],包含22個主題、258份文檔、5,334個事件和1,770對因果事件對;2) Causal-TimeBank(CTB)[6],包含184份文檔、6,813個事件和318對因果事件對;3) MAVEN-ERE [7],包含90個主題、4,480份文檔、103,193個事件和57,992對因果事件對。參照以往的工作 [8, 9],對于ESC我們僅使用其前20個主題進行評估。此外,由于MAVEN-ERE沒有發布測試集,我們在其開發集上評估ChatGPT。我們采用準確度、精確度(P)、召回率(R)和F1-score(F1)作為評估指標。
因果發現
我們在兩個廣泛使用的因果發現(CD)數據集上進行實驗:1) COPA [10],這是一個經典的因果推理數據集,包含1,000個以日常生活場景為主的多項選擇題。2) e-CARE [11],包含21,324個涵蓋廣泛領域的多項選擇題。我們采用準確率作為評估指標。
因果解釋生成
我們在e-CARE上進行實驗,該數據集包含21,324個人工注釋的因果解釋。參照e-CARE的評估設置,我們首先采用BLEU(n=4)[12]和ROUGE-L [13]作為自動評估指標。其次,我們抽取每個版本的ChatGPT在e-CARE上生成的100個解釋進行人工評估。具體來說,我們標記生成的解釋是否能解釋相應的因果事實以人工評估解釋的準確率。
2.2 實驗設置
對于ChatGPT,圖1展示了三個因果推理任務所采用的提示。我們在 zero-shot 設置下評估ChatGPT的性能。其他提示和設置在第四節中討論。
我們使用OpenAI的官方API進行實驗,涵蓋了四個ChatGPT最新版本:text-davinci-002、text-davinci-003、gpt-3.5-turbo和gpt-4。具體來說,text-davinci-002通過RLHF(強化學習與人類反饋)進一步訓練得到text-davinci-003,后者又進一步利用對話數據訓練得到gpt-3.5-turbo。雖然OpenAI未公開gpt-4的具體信息,但gpt-4在各種自然語言處理任務中顯示出了更為卓越的推理能力。對于gpt-4,我們從每個數據集中抽取1000個實例進行評估。我們將temperature參數設置為0,以盡量減少隨機性。
2.3 基線方法
在本文中,所有針對三項因果推理任務的基線方法都基于在完整訓練數據集上微調的預訓練語言模型(PLMs)。
對于 ECI 和 CD 任務,我們將 ChatGPT 與基于 BERT-Base [14]和 RoBERTa-Base [15]的普通分類模型進行了比較。它們的框架和訓練過程與之前的工作一致 [16, 17]。
此外,我們將 ChatGPT 與兩種 SOTA ECI 方法進行了比較:基于 BERT-Base 的 KEPT [18],融合了背景和關系信息以進行因果推理;以及基于 RoBERTa-Base 的 DPJL [19],將有關因果線索詞和事件間關系的信息引入到 ECI 模型中。
對于 CEG 任務,我們首先將 ChatGPT 與基于 GRU 的 Seq2Seq 模型 [20]和 GPT2 [21]進行比較。它們的框架和訓練過程與之前的工作一致 [22]。此外,我們在 e-CARE 的訓練集上微調 LLaMA 7B [23]和 FLAN-T5 11B [24],作為基于 LLMs 基線。
3 實驗
3.1 事件因果關系識別
表1顯示了在三個ECI數據集上的結果:ESC、CTB和MAVEN-ERE。
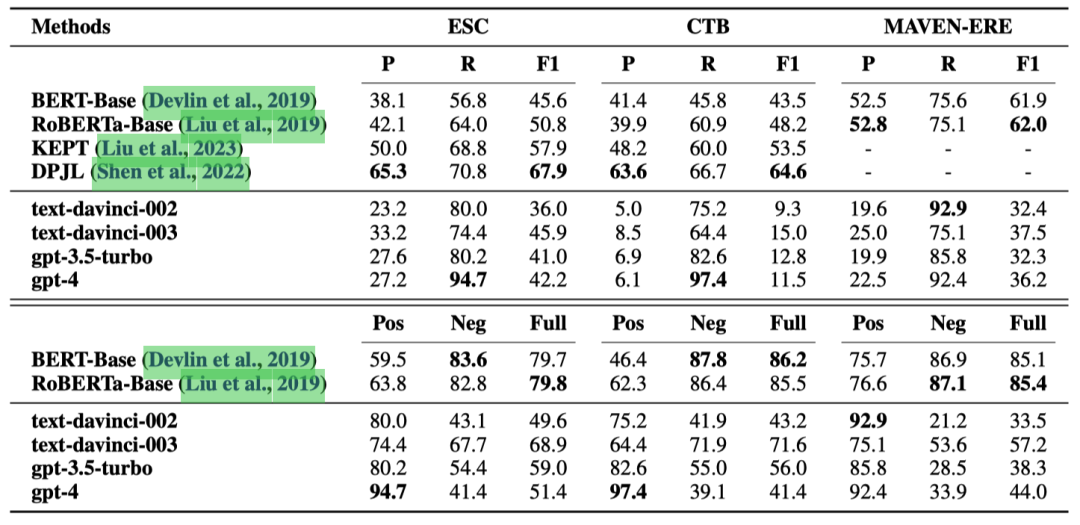
表1: ECI任務上的實驗結果(%)。P、R和F1分別代表準確率、召回率和F1分數。Pos、Neg和Full分別表示因果對、非因果對和所有測試樣例上的準確率。
我們發現:
即使是gpt-4版本的ChatGPT,也被基于微調的小型PLMs的基線方法全面超越。這表明在像ECI這樣復雜的因果推理任務中,ChatGPT并不是一個好的因果推理器。
ChatGPT的召回率很高,但精確度低,這表明大量非因果事件對被錯誤地識別為因果對。這也是ChatGPT在CTB數據集上表現尤其糟糕的原因,因為該數據集包含更多非因果事件對。這可能是因為自然語言包含大量因果關系的描述,主要由諸如“lead to”和“therefore”這樣的因果線索詞指示。然而,自然語言通常不表達哪些事件不是因果相關的。由于ChatGPT的能力來自于對大量自然語言文本的訓練,文本中因果和非因果事件對之間的這種報告偏差使得ChatGPT擅長于識別因果事件對,但不擅長識別非因果事件對。
此外,可以觀察到經過微調的小型PLMs在識別非因果事件對方面表現得更好。這是因為在ECI訓練集中,非因果示例比因果示例多得多,而經過微調的模型學習到了這種數據分布。
3.2 因果關系發現
表2展示了在兩個因果發現(CD)數據集上的結果:COPA和e-CARE。
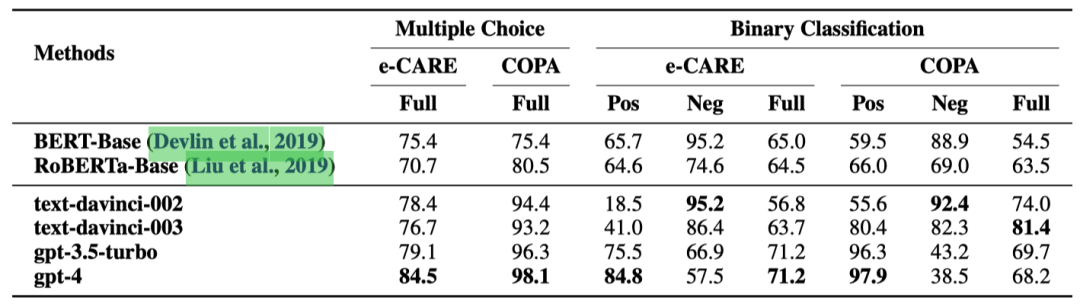
表2: CD任務上的實驗結果(%)。Pos、Neg和Full分別表示因果對、非因果對以及所有測試樣例上的準確率。
我們發現:
盡管ChatGPT在多項選擇設置中表現良好,但在二元分類中的表現卻顯著變差。這主要是因為在多項選擇設置中,ChatGPT只需要考慮與輸入事件呈現更明顯的因果或非因果關系的選項,而可以忽略另一個更難分析的選項。之前的工作 [25, 26]只用多項選擇題來評估ChatGPT的因果推理能力,導致誤認為ChatGPT擅長因果推理。
與ECI任務相比,ChatGPT在CD任務中識別非因果對的準確率更高。這主要是因為e-CARE和COPA數據集中的非因果對是根據輸入事件手動生成的,它們結構簡單,與輸入事件的相關性弱,因此更容易識別。這也是為什么經過微調的小型預訓練語言模型(PLMs)在識別非因果事件對方面比識別因果事件對表現更好。
與COPA相比,ChatGPT在e-CARE數據集中識別因果對的準確率略低。這是因為e-CARE要求ChatGPT掌握更廣泛的知識,這不僅涉及到更多場景中的常識知識,還包括某些領域的專業知識,如生物學。
更重要的是,我們注意到ChatGPT的升級過程(text-davinci-003→gpt-3.5turbo→gpt-4)使得ChatGPT越來越傾向于將事件分類為具有因果關系,而無論因果是否真實存在。這可能是RLHF的對齊稅 [27]所致。這表明,盡管OpenAI [28]提到ChatGPT的升級過程減少了在其他各種任務中的幻覺問題,但也使得ChatGPT更擅長于編造因果關系。
3.3 因果解釋生成
表 3 展示了在 CEG 任務上的實驗結果。
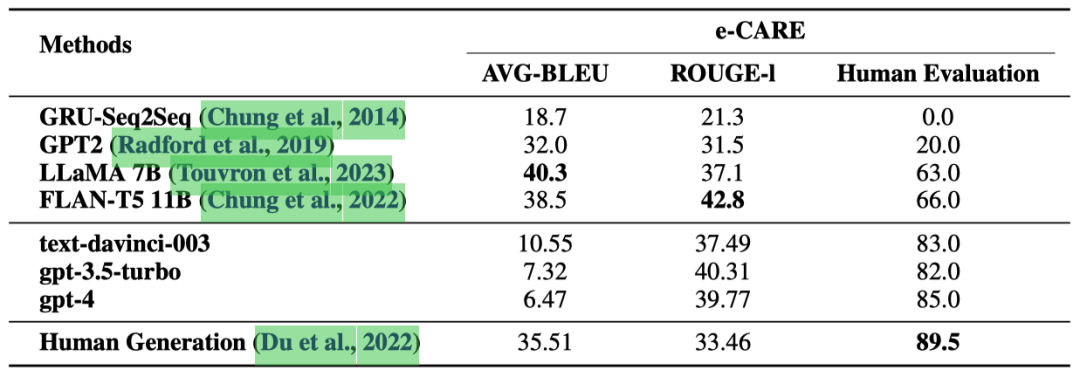
表3: 在CEG任務上的實驗結果(%)。
可以觀察到:
根據人類評估結果,由 ChatGPT 生成的因果解釋的準確性接近人類生成的解釋。這表明 ChatGPT 是一個良好的因果解釋器。
與“Human Generation”相比,ChatGPT 在 ROUGE-l 指標上表現更好,這是一個類似于文本分類中“recall”的文本生成度量。這是因為 ChatGPT 傾向于生成相比人工標注的解釋更完整、更詳細的解釋。這一點在我們的人工評估過程中得到了評估員的一致認可。這也是 ChatGPT 獲得較低的 AVG-BLEU 分數的原因,因為AVG-BLEU是一個類似于文本分類中“precision”的文本生成度量。
通過手動評估,我們發現由 LLaMA 和 FLAN-T5 生成的解釋與輸入事件高度相關。然而,這些解釋可能只是對輸入事件的重復,或者提供相關但無法用于解釋的描述。這也是 LLaMA 和 FLAN-T5 在人類評估中表現不佳的主要原因。
此外,與 ChatGPT 相比,LLaMA 和 FLAN-T5 提供的解釋明顯更短。這是因為 e-CARE 訓練集中標注的解釋非常簡短。然而,ChatGPT 在提供更全面和詳細的解釋方面表現出色。這展示了 ChatGPT 因果解釋相比傳統微調方法的優勢。
最后值得注意的是,盡管經過微調的 LLaMA、FLAN-T5 和 ChatGPT 在 ROUGE-l 分數上表現相近,但兩個微調的 LLMs 在我們的人類評估中表現明顯更差。這是因為 ChatGPT 生成的解釋相比測試集中標注的解釋更加全面、詳細,導致了偏低的ROUGE-l數值。事實上ChatGPT生成的解釋質量相當可靠。
4 分析
4.1 上下文學習
如表4和表5所示,我們分析了ChatGPT在不同上下文學習設置下的表現:1)“x pos + y neg”:我們隨機選擇x個因果訓練樣例和y個非因果訓練樣例作為上下文學習的示例,所有測試樣例共享相同的示例;2)“top k similar”:對于每個測試樣例,我們檢索與其最相似的k個訓練樣例作為其上下文示例。論文中還額外分析了ICL示例的順序和標簽分布對因果推理性能的影響。
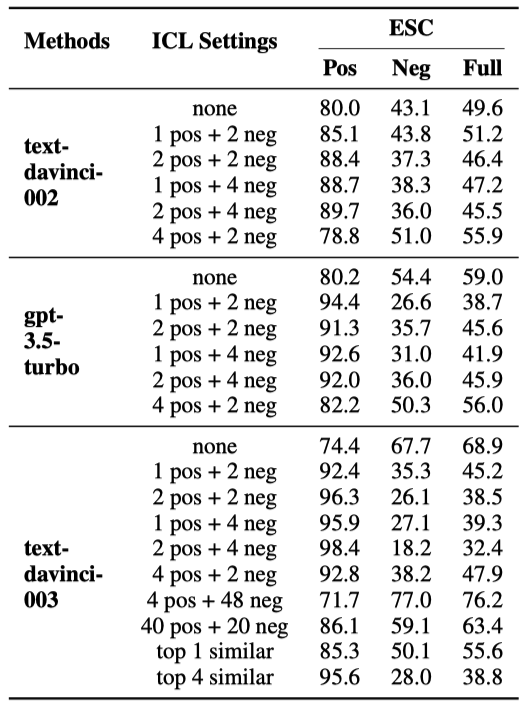
表4: ChatGPT在ECI任務中使用上下文學習的表現。其中“none”表示未使用上下文學習的ChatGPT。
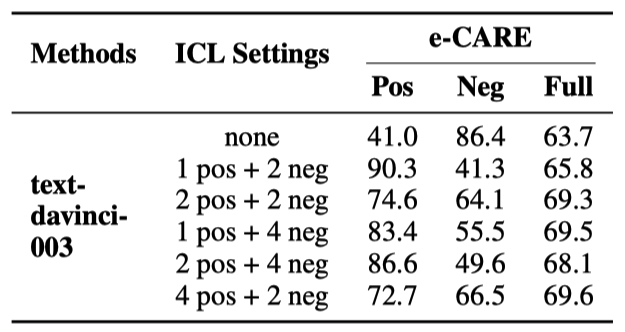
表5: ChatGPT 在 binary-classification CD任務中使用上下文學習的性能。“none” 表示沒有使用上下文學習的 ChatGPT。
我們觀察到:
當x和y不大于4時,ICL主要提高了ChatGPT在因果對中的準確率,但降低了非因果對的準確率。這可能是因為雖然ICL可以激發ChatGPT的能力,但ChatGPT更擅長識別因果事件對。因此,ICL進一步加劇了ChatGPT識別因果和非因果對的性能的不均衡。
“4 pos + 48 neg”實現了更高的Full Acc。然而它是以犧牲Pos Acc為代價提高了Neg Acc。又因為ESC數據集包含更多的非因果對,造成表面看起來Full Acc有所提升。但整體性能的有效提升不應該是以拆東墻補西墻的形式實現,而應該是同時提高Pos Acc和Neg Acc。
4.2 思維鏈提示
如表6所示,我們分析了ChatGPT在不同思維鏈設置下的表現:1)“-w/ CoT zero-shot”:我們通過在提示后添加“Let’s think step by step” 來實現zero-shot CoT [29];2)“-w/ CoT x pos + y neg”:我們為x個因果訓練樣例和y個非因果訓練樣例手動注釋推理鏈。它們被選為上下文學習的示例,所有測試樣例共享相同的上下文示例。論文中還額外展示了ChatGPT的錯誤類型、推理鏈條的樣例等。
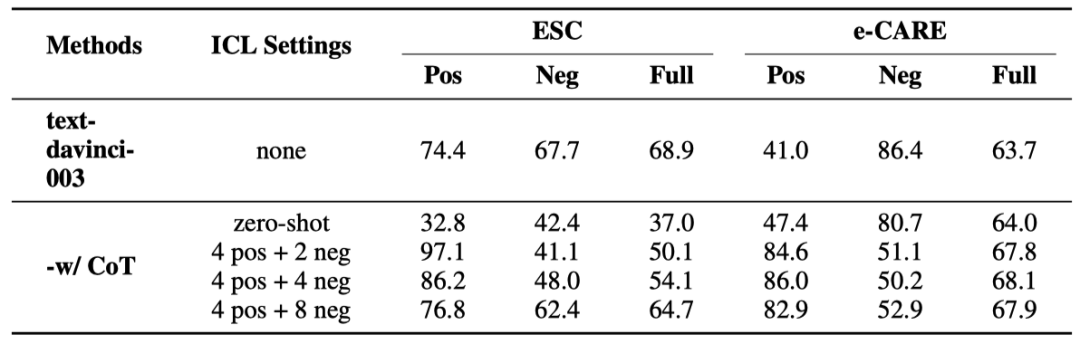
表6: ChatGPT在ECI和binary-classification CD任務上的使用CoT的表現。“none” 表示沒有使用上下文學習的 ChatGPT。
可以發現:
“-w/ CoT zero-shot”不能有效地提高ChatGPT在ECI任務中的表現。這可能是因為 zero-shot CoT生成的推理鏈質量不足以有效地指導模型。
“-w/ CoT x pos + y neg”提高了ChatGPT在因果對上的準確率,但降低了其在非因果對上的準確率。觀察ChatGPT生成的推理鏈,我們發現ChatGPT為非因果對生成的鏈條質量低于因果對。這種差異會加劇ChatGPT在識別因果和非因果事件對方面的不平衡。
4.3 表達因果關系的方式
如圖2所示,我們分析了在提示中使用不同方式表達因果概念時ChatGPT的性能變化:
1)“counterfactual”,基于 [30]的反事實因果觀點的提示;
2)“one-step”,我們添加了“one-step”這樣的限制性詞語來減輕將非因果事件對識別為因果的傾向;
3)“trigger()”,我們使用不同的因果提示詞(例如,“lead to”)來構建提示。
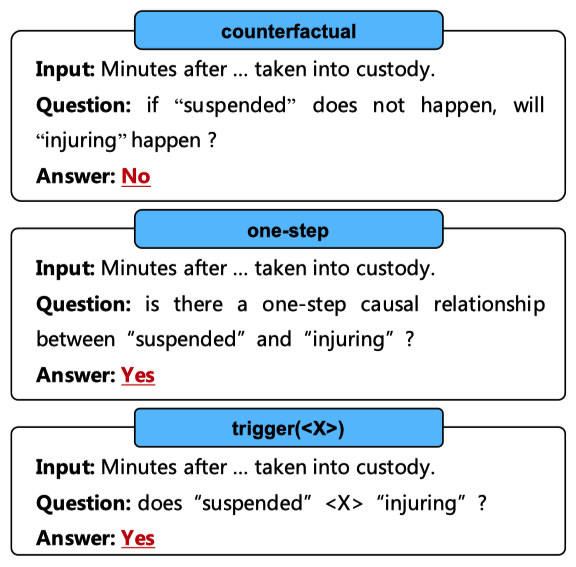
圖2: 以各種方式表達因果概念的提示。需要ChatGPT回復的內容用紅色標記。
實驗結果顯示在表7中。
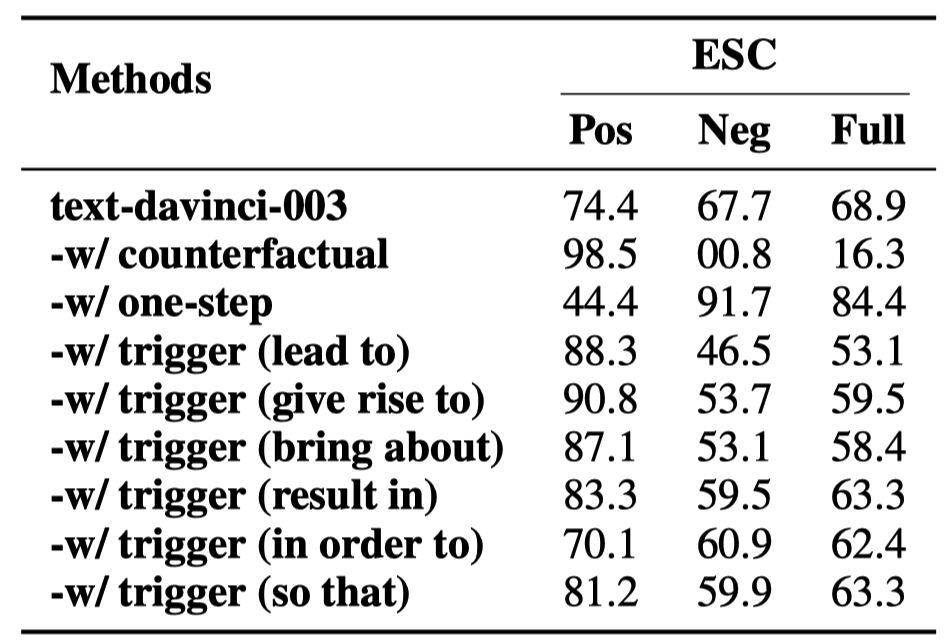
表7: 以不同方式表達因果概念的提示在ECI任務上的性能。
我們發現:
“counterfactual” 提示使得幾乎所有非因果對被識別為因果。人工檢查發現這主要是因為ChatGPT的反事實推理結果不夠準確。
“one-step”提高了ChatGPT在非因果對上的準確性,但降低了其在因果對上的準確性。這是意味著盡管像“one-step”這樣的限制性詞語可以使模型更傾向于預測事件對為非因果,但它并沒有真正增強ChatGPT的因果推理能力。
“trigger()” 在不同因果提示詞下的表現有顯著差異。這可能是因為在預訓練期間,ChatGPT主要通過因果提示詞學習因果知識,但每個提示詞觸發的因果關系分布都有所不同。因此,對于人類來說意義相同的因果提示詞對ChatGPT來說代表不同的因果概念。這進一步表明,通過提示準確地向ChatGPT傳達因果含義是一個具有挑戰性的任務。
4.4 事件之間的詞匯距離
如圖3所示,我們分析了ChatGPT處理不同詞匯距離事件對的表現。“詞匯距離”指的是一個句子中兩個事件之間間隔的單詞數。
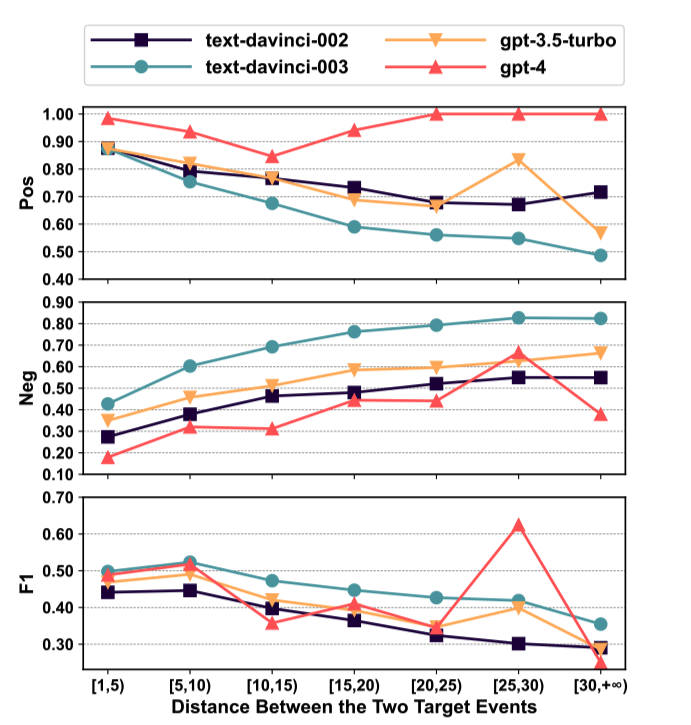
圖3: ChatGPT在ESC數據集中處理具有不同詞匯距離的事件對的表現。
我們發現:
隨著間距的增加,ChatGPT更傾向于將事件對預測為非因果。這可能是因為在自然語言中,事件之間的距離越大,存在因果關系的可能性越小,而ChatGPT學到了這種模式。
隨著事件間距的增加,ChatGPT的F1得分降低。這表明ChatGPT不擅長識別長距離的因果關系。一個異常值是在[25,30)區間內gpt-4的F1得分。這是因為在gpt-4的1000個測試樣例中,只有35個例子在[25,30)區間內,導致表現更加隨機。然而,所有其他結果都表明,隨著事件距離的增加,ChatGPT的表現會下降。
4.5 事件密度
如圖4所示,我們分析了ChatGPT在ECI任務中處理具有不同數量事件的句子的表現。
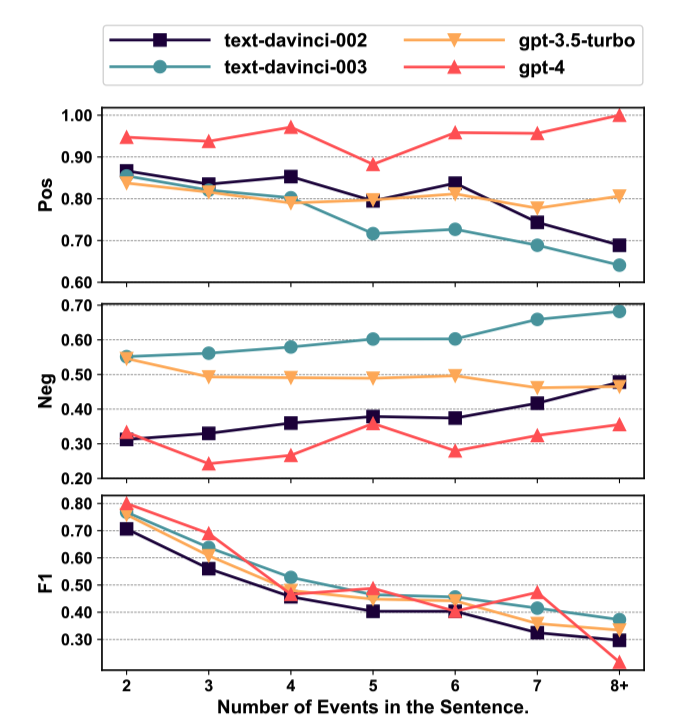
圖4: ChatGPT在ESC數據集中處理具有不同事件數量的句子的表現。
我們發現:
隨著事件密度的增加,大多數版本的ChatGPT更傾向于預測事件對為非因果關系。這主要是因為隨著事件密度的增加,事件的上下文變得更加復雜,使得捕捉事件之間的關聯變得更加困難。
隨著事件密度的增加,ChatGPT的F1分數下降。這表明ChatGPT不擅長處理涉及多個事件的復雜情況。
4.6 因果關系類型
如圖5所示,我們分析了ChatGPT在ECI任務中處理具有不同類型因果關系的事件對的準確性:1)顯式因果,指的是句子中由因果提示詞(例如,“lead to”)明確觸發的因果關系;2)隱式因果,指的是未使用因果提示詞表達的因果關系。
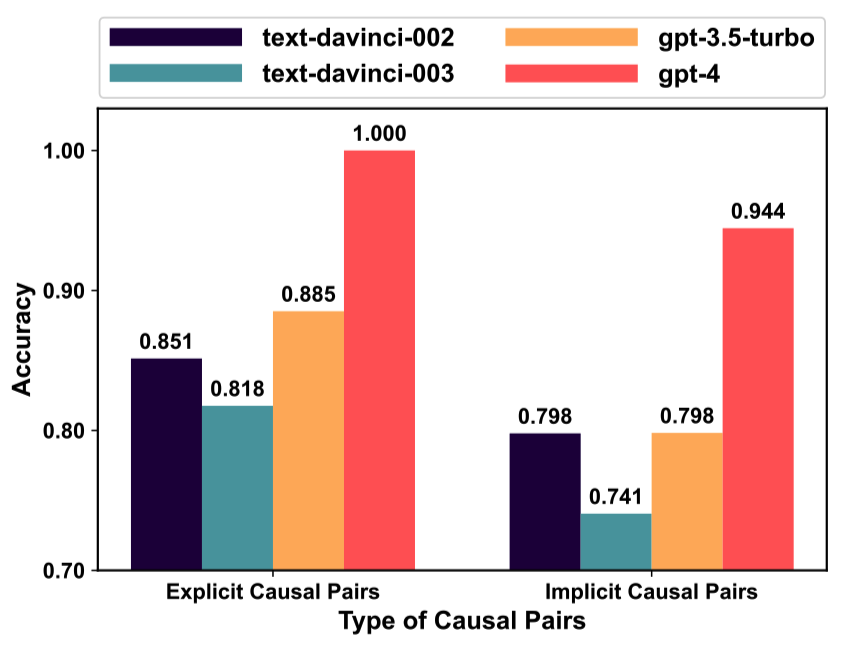
圖5: 在ESC數據集中,ChatGPT在不同類型因果關系的事件對上的表現。
可以觀察到:
與隱性因果性相比,ChatGPT在捕捉顯性因果性方面表現更好。這主要是因為識別顯性因果性只需識別因果提示詞,而識別隱性因果性則需要利用上下文信息和常識知識進行推理。
4.7 開放式提示
最近,阿羅拉等人 [31]發現,開放式提示(例如“誰去了公園?”)對于ChatGPT來說,往往比限制性的提示(例如“約翰去了公園。對還是錯?”)產生更好的結果。如表8所示,我們分析了ChatGPT使用開放式提示的因果推理性能:
1)“open-ended A.1/2/3”,要求ChatGPT生成輸入句子中的所有因果事件對。我們設計了三種不同的提示,以全面評估ChatGPT的表現。
2)“open-ended B”,給出輸入句子中的目標事件,并要求ChatGPT生成輸入句子中與目標事件具有因果關系的事件。
這些提示的格式在圖6中展示。

圖6: 開放式提示。標記為紅色的內容需要ChatGPT回復。
我們對開放式提示采用了邊界寬松的P、R和F1計算方法。具體來說,當預測的結果事件與標注的結果事件共享至少一個單詞,同時預測的原因事件與標注的原因事件也共享至少一個單詞,則認為預測的因果事件對是正確的。
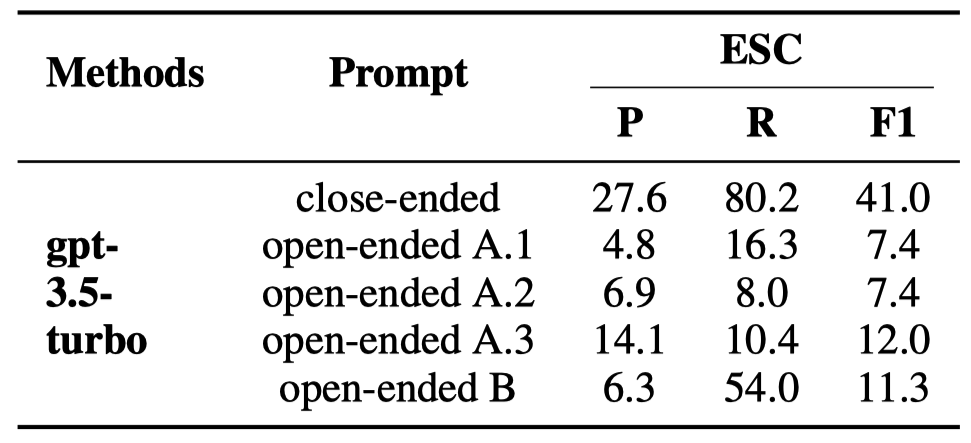
表8: ChatGPT 使用開放式提示在 ECI 任務上的表現。“close-ended”表示圖 1 中顯示的原始 ECI 提示。值得注意的是,“close-ended”提示并不明確要求 ChatGPT 輸出“yes”或“no”,但其句法形式引導 ChatGPT 幾乎總是輸出“yes”或“no”。
可以觀察到:
開放式提示降低了ChatGPT的性能。這是因為開放式提示要求ChatGPT同時執行事件提取和ECI任務。然而,之前的研究 [32, 33]表明,ChatGPT不擅長提取事件。
5 結論
在本文中,我們對ChatGPT的因果推理能力進行了全面評估。實驗表明:
ChatGPT不是一個好的因果推理器,但擅長因果解釋生成;
ChatGPT存在嚴重的因果幻覺,這可能是由于因果的報告偏見;
隨著ChatGPT版本的提升,以及ICL和CoT技術的應用,這種因果幻覺進一步加劇;
ChatGPT對于提示中表達因果概念的方式敏感,且開放式提示不適合ChatGPT;
對于句子中的事件,ChatGPT擅長捕捉明確的因果關系,在事件密度較低和事件距離較小的句子中表現更好。
開放式生成提示無法提高ChatGPT的因果推理能力。
盡管可能存在更細致的提示,可以進一步超越我們報告的結果,但我們認為,僅依靠提示無法從根本上解決 ChatGPT 在因果推理中面臨的問題。我們希望這項研究能激發未來的工作,例如解決ChatGPT的因果幻覺問題或在多因素和多模態因果推理的場景中進一步評估ChatGPT。
審核編輯:劉清
-
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595
原文標題:ChatGPT 是一個好的因果推理器嗎? 一份綜合評估
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
科技大廠競逐AIGC,中國的ChatGPT在哪?
不到1分鐘開發一個GPT應用!各路大神瘋狂整活,網友:ChatGPT就是新iPhone
基于加性噪聲的缺失數據因果推斷
醫學AI的行業研究人員演示了一種“因果推理”算法
超詳細EMNLP2020 因果推斷

基于e-CARE的因果推理相關任務
問了一個讓ChatGPT尷尬的問題……
ChatGPT了的七個開源項目

ChatGPT的潛力和局限
基準數據集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力
ChatGPT plus多少錢一個月 ChatGPT Plus國內代充教程
如何使用Rust創建一個基于ChatGPT的RAG助手
AMD助力HyperAccel開發全新AI推理服務器






 工商網監
工商網監
評論