 什么是LlamaIndex?LlamaIndex數據框架的特點和功能
什么是LlamaIndex?LlamaIndex數據框架的特點和功能
來源:Coggle數據科學
什么是LlamaIndex ?
LlamaIndex是一個數據框架,用于讓基于LLM的應用程序攝取、結構化和訪問私有或領域特定的數據。它提供Python和Typescript版本。
LLMs提供了人類和數據之間的自然語言接口。廣泛可用的模型預先訓練了大量公開可用的數據,如維基百科、郵件列表、教科書、源代碼等。然而,雖然LLMs在大量數據上進行了訓練,但它們沒有接觸您的數據,這可能是私有的或與您要解決的問題特定相關的數據。它可能存在于APIs、SQL數據庫中,或者被困在PDF和幻燈片中。
LlamaIndex特點
LlamaIndex采用了一種稱為檢索增強生成(RAG)的不同方法。與要求LLMs立即生成答案不同,LlamaIndex:
先從您的數據源中檢索信息,
將其添加到您的問題作為上下文,
要求LLMs基于豐富的提示進行回答。
RAG克服了微調方法的所有三個缺點:
由于不涉及訓練,因此它是便宜的。
僅在您要求時才檢索數據,因此它始終保持最新。
LlamaIndex可以向您展示檢索到的文檔,因此它更可信。
LlamaIndex對您如何使用LLMs沒有限制。您仍然可以將LLMs用作自動完成、聊天機器人、半自主代理等(請參見左側的用例)。它只是使LLMs對您更有相關性。
LlamaIndex功能
LlamaIndex提供以下工具:
數據連接器從其原生來源和格式攝取您的現有數據。這可以是APIs、PDF、SQL等等。
數據索引將您的數據結構化為中間表示,LLMs可以輕松高效地使用。
引擎為您的數據提供自然語言訪問。例如:
查詢引擎是用于知識增強輸出的強大檢索接口。
聊天引擎是用于與數據進行多消息、“來回”交互的對話接口。
數據代理是由工具增強的LLM驅動的知識工作者,從簡單的輔助功能到API集成等等。
應用集成將LlamaIndex與您的生態系統的其余部分相連接。這可以是LangChain、Flask、Docker、ChatGPT或… 其他任何東西!
LlamaIndex安裝
pipinstallllama-index
安裝通常所需的可選依賴項的方法。目前,這些依賴項分為三組:
pip install llama-index[local_models]安裝對私有LLMs、本地推理和HuggingFace模型有用的工具
pip install llama-index[postgres]如果您正在使用Postgres、PGVector或Supabase,則此選項很有用
pip install llama-index[query_tools]為您提供混合搜索、結構化輸出和節點后處理的工具
檢索增強生成(RAG)
LLMs在龐大的數據集上進行訓練,但它們并沒有接觸您的數據。檢索增強生成(RAG)通過將您的數據添加到LLMs已經可以訪問的數據中來解決這個問題。在本文檔中,您將經常看到對RAG的引用。
在RAG中,您的數據被加載并準備進行查詢或“索引”。用戶的查詢作用于索引,將您的數據篩選到最相關的上下文。然后,此上下文和您的查詢與LLM一起傳遞給一個提示,LLM將提供響應。
即使您正在構建的是一個聊天機器人或代理,您也會想要了解RAG技術,以將數據引入您的應用程序。
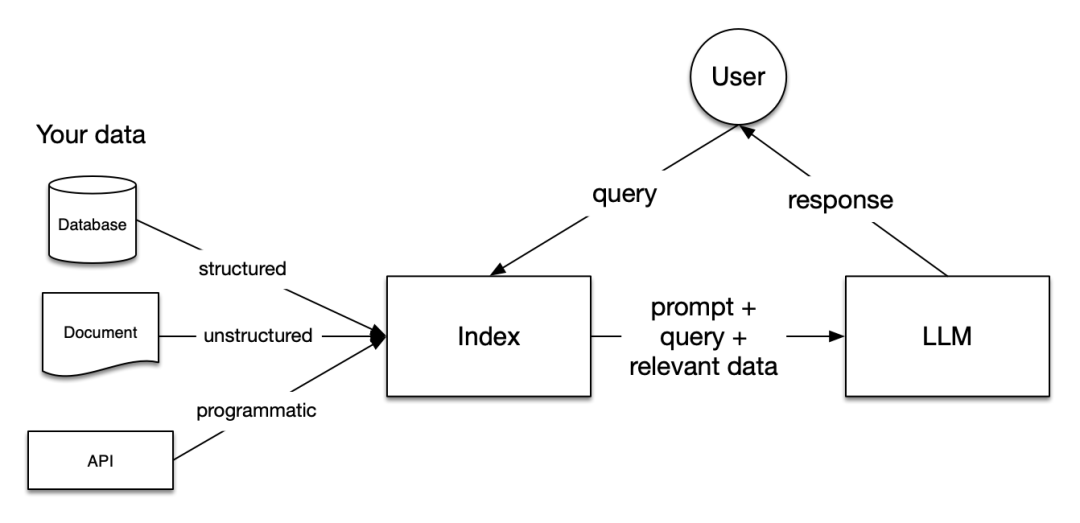
RAG中的階段
RAG中有五個關鍵階段,這些階段將成為您構建的任何更大應用程序的一部分。這些階段是:
加載:這指的是從數據所在的地方(無論是文本文件、PDF、另一個網站、數據庫還是API)獲取您的數據,將其引入您的管道。LlamaHub 提供了數百個可供選擇的連接器。
索引:這意味著創建一個允許查詢數據的數據結構。對于LLMs,這幾乎總是意味著生成矢量嵌入,這是您的數據意義的數字表示,以及許多其他元數據策略,使其易于準確找到上下文相關的數據。
存儲:一旦您的數據被索引,您幾乎總是希望存儲您的索引,以及其他元數據,以避免必須重新索引它。
查詢:對于任何給定的索引策略,您可以使用LLMs和LlamaIndex數據結構以多種方式進行查詢,包括子查詢、多步查詢和混合策略。
評估:在任何管道中,檢查其相對于其他策略或在進行更改時的有效性是一個關鍵步驟。評估提供了有關您對查詢的響應的準確性、忠實度和速度的客觀度量。

每個步驟中的重要概念
在每個階段中,您還會遇到一些涉及到這些階段的術語。
加載階段
節點和文檔:一個文檔是圍繞任何數據源的容器,例如PDF、API輸出或從數據庫檢索的數據。節點是LlamaIndex中數據的原子單位,表示源文檔的“塊”。節點具有將其與所在文檔和其他節點相關聯的元數據。
連接器:數據連接器(通常稱為讀取器)從不同的數據源和數據格式中攝取數據到文檔和節點中。
索引階段
索引:一旦攝取了您的數據,LlamaIndex將幫助您將數據索引到易于檢索的結構中。這通常涉及生成矢量嵌入,這些嵌入存儲在一個稱為矢量存儲的專用數據庫中。索引還可以存儲有關您的數據的各種元數據。
嵌入:LLMs生成稱為嵌入的數據的數字表示。在為相關性過濾數據時,LlamaIndex將查詢轉換為嵌入,并且您的矢量存儲將找到數值上與查詢嵌入相似的數據。
查詢階段
檢索器:檢索器定義了在給定查詢時如何有效地從索引中檢索相關上下文。您的檢索策略對于檢索的數據的相關性以及執行此操作的效率至關重要。
路由器:路由器確定將使用哪個檢索器從知識庫中檢索相關上下文。更具體地說,RouterRetriever類負責選擇一個或多個候選檢索器來執行查詢。它們使用選擇器根據每個候選的元數據和查詢選擇最佳選項。
節點后處理器:節點后處理器接收一組檢索到的節點并對其應用變換、過濾或重新排序邏輯。
響應合成器:響應合成器使用用戶查詢和一組檢索到的文本塊從LLM生成響應。
將所有內容整合在一起
有無數數據支持的LLM應用程序的用例,但它們大致可以分為三類:
查詢引擎:查詢引擎是一個端到端的管道,允許您在數據上提問。它接收自然語言查詢,并返回一個響應,以及檢索到的并傳遞給LLM的參考上下文。
聊天引擎:聊天引擎是一個端到端的管道,用于與您的數據進行對話(而不是單一的問答)。
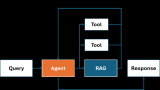
代理:代理是由LLM驅動的自動決策者,通過一組工具與世界互動。代理可以采取任意數量的步驟來完成給定任務,動態決定最佳行動方案,而不是按照預先確定的步驟進行。這使得它具有處理更復雜任務的額外靈活性。
審核編輯:湯梓紅
-
接口
+關注
關注
33文章
8575瀏覽量
151015 -
SQL
+關注
關注
1文章
762瀏覽量
44117 -
數據庫
+關注
關注
7文章
3794瀏覽量
64360 -
自然語言
+關注
關注
1文章
287瀏覽量
13346 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:小白學大模型:LlamaIndex數據框架
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多功能程序框架
主流web前端技術框架
power_supply框架包括哪些功能?
OpenHarmony 3.1 Beta版本關鍵特性解析——HiStreamer框架大揭秘
WCDB移動數據框架的功能
基于功能體驗ios新增了SiriKit框架
什么是Hibernate?Hibernate框架架構與框架原理分析
大數據具有哪些特點優勢和應用功能
DB4494_無線工業節點上的多傳感器AI數據監控框架,STM32Cube的功能包

LlamaIndex:面向QA系統的全新文檔摘要索引
fastapi框架原理及應用
谷歌模型框架是什么?有哪些功能和應用?
使用OpenVINO和LlamaIndex構建Agentic-RAG系統





 工商網監
工商網監
評論