 無需微調,即插即用的占據預測模型—FlashOcc介紹
無需微調,即插即用的占據預測模型—FlashOcc介紹
1. 本文簡介
占據預測是指在自動駕駛系統中,根據傳感器的輸入,預測三維空間中的每個體素是否被物體占據。占據預測可以有效地解決三維物體檢測中的長尾問題和復雜形狀的缺失問題。然而,占據預測也面臨著一個挑戰,即如何在保證準確性的同時,提高速度和降低內存消耗。現有的占據預測方法通常使用三維卷積來處理體素級別的特征,這會導致大量的計算和存儲開銷,不利于部署到不同的芯片上。為了解決這個問題,文章提出了一種快速和節省內存的占據預測方法,稱為FlashOcc。FlashOcc的核心思想是利用一個通道到高度的變換,將二維的鳥瞰圖特征轉換為三維的占據概率,從而避免了使用三維卷積。FlashOcc的優點是,它可以作為一個插件,直接應用到現有的占據預測方法上,無需額外的訓練或微調。文章在Occ3D-nuScenes數據集上進行了實驗,證明了FlashOcc的有效性和高效性,在保持高精度的同時,顯著提高了速度和降低了內存消耗,展示了其在自動駕駛場景中的潛力。
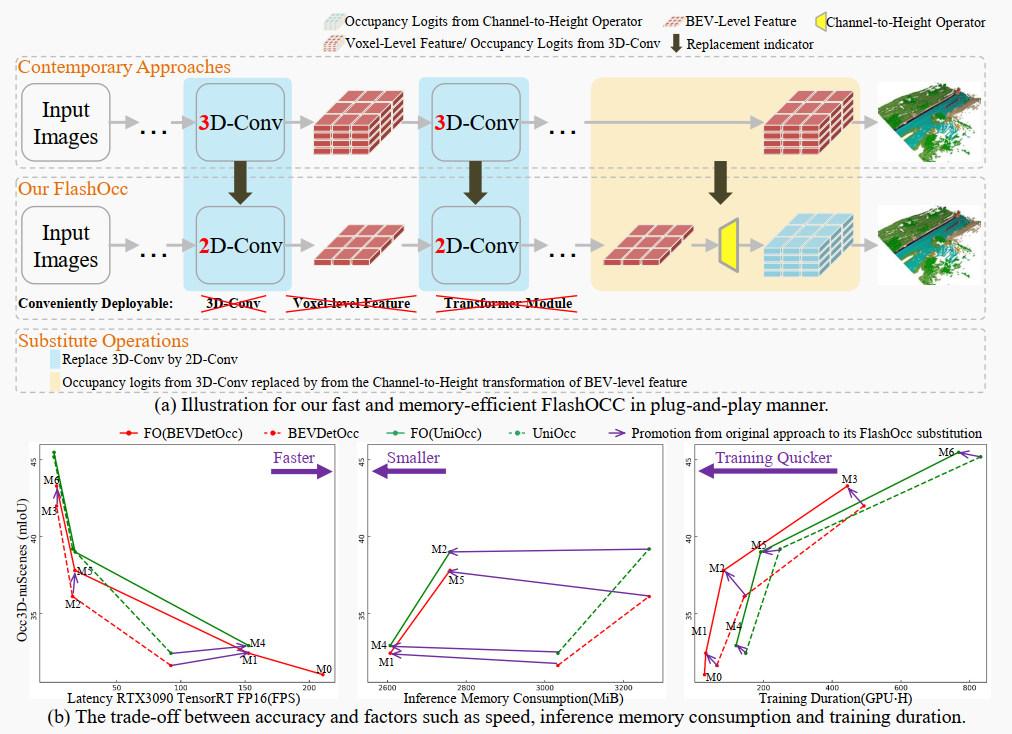
圖1.(a) 說明了我們的FlashOcc如何以插即用的方式實現。當代方法使用由3D卷積處理的體素級特征預測占據情況。與之形成對比,我們的插件模型通過(1)用2D卷積替換3D卷積。(2)用通道與高度變換的BEV級特征替換3D卷積派生的占據logits,實現了快速和內存高效的占據預測。(b) 插件替代與原始方法之間在精度及速度、內存消耗和訓練時間等因素上的權衡。
2. 原文摘要
由于具有減輕數據集長尾效應和復雜形狀缺失的作用,占據預測已經成為自動駕駛系統中的重要組成部分。然而,使用三維體素級表示不可避免地導致了巨大的內存和計算開銷,這限制了占據預測方法的部署。與當前使模型更大更復雜的趨勢相反,我們認為理想的框架應該既能適應各種芯片以便部署,又能保持高精度。為此,我們提出了一個即插即用的范式,即FlashOCC,以實現快速和內存高效的占據預測,同時保持高精度。具體來說,我們的FlashOCC在現有的體素級占據預測方法的基礎上做了兩點改進。第一,特征保留在俯視圖中,以利用高效的2D卷積層進行特征提取。第二,引入了一種通道與高度的變換,以將輸出結果從俯視圖映射到三維空間。我們在具有挑戰性的Occ3D-nuScenes基準測試上將FlashOCC應用于不同的占據預測基線,并進行了廣泛的實驗來驗證其有效性。結果表明,我們的即插即用范式在精度、運行時效率和內存成本方面都優于之前的最先進的方法,顯示了其部署的潛力。代碼將會開源。
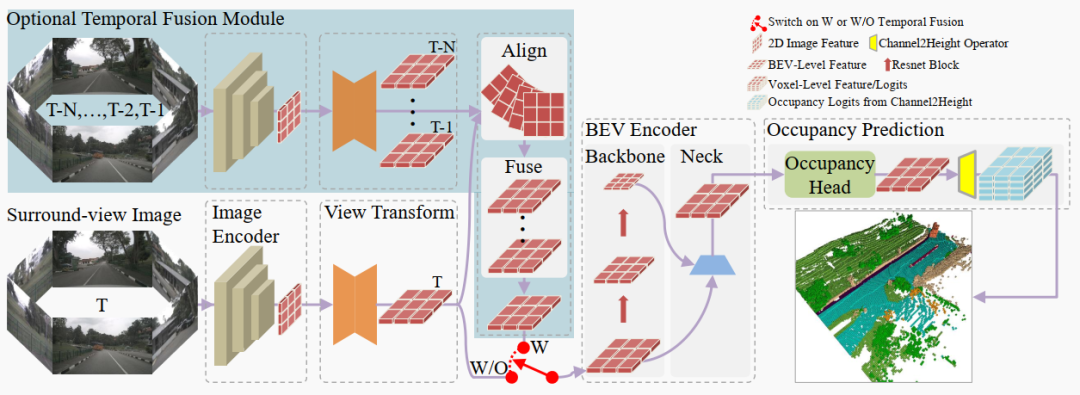
圖2. 我們的FlashOcc的總體架構。虛線框標識的區域表示可替換模塊。每個可替換模塊的特征形狀按圖1和圖2中的說明表示。淺藍色區域對應可選的時序融合模塊,其使用取決于紅色開關的激活。
3. 方法詳解
FlashOcc系統框架如圖2所示。輸入數據為環視圖像,輸出為密集的占據預測結果。它包括五個基本模塊:(1)二維圖像編碼器;(2)視角變換模塊;(3)BEV編碼器;(4)占據預測模塊;(5)時序融合模塊(可選)。
3.1 圖像編碼器
圖像編碼器使用backbone網絡提取輸入圖像的高層語義特征,然后饋入neck模塊進行融合,從而充分利用不同粒度的語義信息。常用的backbone網絡有經典的ResNet和強大的Swin Transformer。neck模塊選擇簡潔的FPN-LSS,它將細粒度特征與直接上采樣的粗粒度特征集成。
3.2 視角變換
視角變換模塊的作用是將二維感知視角特征映射到BEV表示中。Lift-splat-shot (LSS)和Lidar Structure (LS)被廣泛使用。LSS利用像素級密集深度預測和相機內在外參將圖像特征投影到預定義的三維網格體素上。然后沿垂直維度(高度)應用匯聚操作以獲得扁平的BEV表示。然而,LS依賴均勻分布的深度進行特征轉換,這會導致沿相機光線方向的特征錯配和后續的錯誤檢測,盡管計算復雜度有所降低。
3.3 BEV編碼器
BEV編碼器通過視角變換獲得的粗糙BEV特征,輸出更詳細的三維表示。其結構與圖像編碼器類似,包括backbone和neck。正如第3.1節所概述的,我們采用相同的設置。經過若干層后,特征擴散用于改善中心特征丟失的問題。如圖2所示,兩個不同尺度的特征被集成以增強表示質量。
3.4 占據預測頭部

3.5 時序融合組件
時序融合組件通過整合歷史信息來增強動態物體或屬性的感知。它包含兩個主要組件:空間-時序對齊模塊和特征融合模塊。對齊模塊使用自身信息將歷史BEV特征與當前激光雷達系統對齊。這種對齊過程確保歷史特征得以正確插值和與當前感知系統同步。一旦完成對齊,對齊的BEV特征被傳遞到特征融合模塊。該模塊考慮它們的時序上下文,集成對齊特征以生成動態物體或屬性的全面表示。融合過程組合相關的歷史特征和當前感知輸入的信息,以提高整體感知精度和可靠性。
4. 實驗結果
我們對Talk2BEV在Talk2BEV-Bench上的問題進行了定量評估。我們報告了不同LVLM在不同任務子集和不同類型問題上的性能,以及它們的平均性能。MiniGPT-4在所有類型問題上都取得了最佳的平均性能。BEV中的誤差對性能的影響較小,這表明隨著更高性能的LVLM的出現,Talk2BEV的性能有望進一步提高。表II展示了Talk2BEV使用不同LVLM構建的語言增強地圖(BLIP-2、InstructBLIP-2、MiniGPT-4)和BEV變體(LSS和GT)在多項選擇問題(MCQs)上的性能。表III評估了空間操作符對系統性能的影響,顯示了集成空間操作符帶來的顯著改進。此外,表IV報告了不同對象類別的性能,突出了車輛類別之間的性能差異。
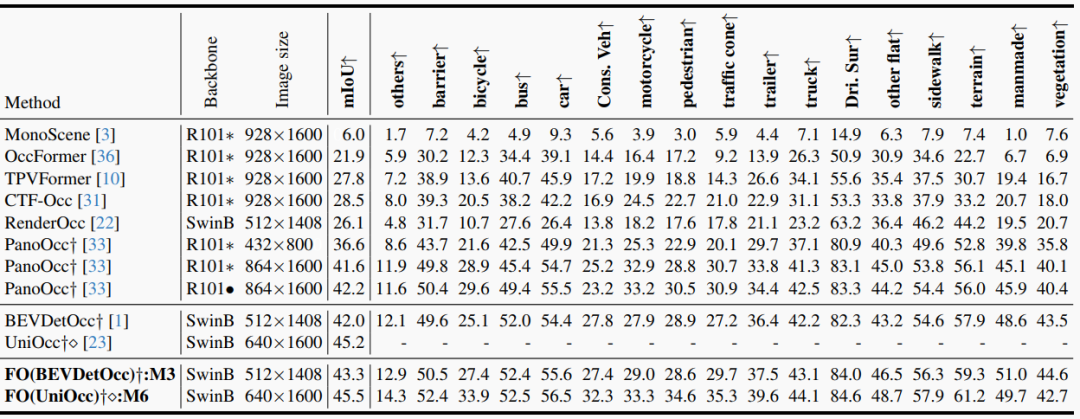
表1. Occ3D-nuScenes驗證集上的三維占據預測性能。
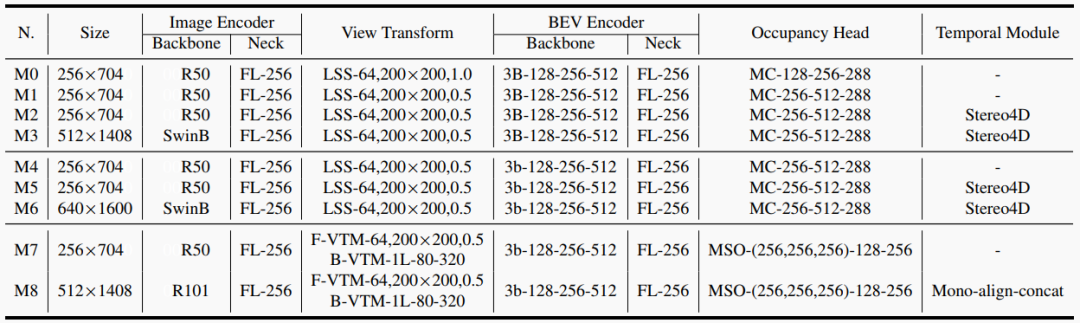
表2. 各種方法的詳細設置。
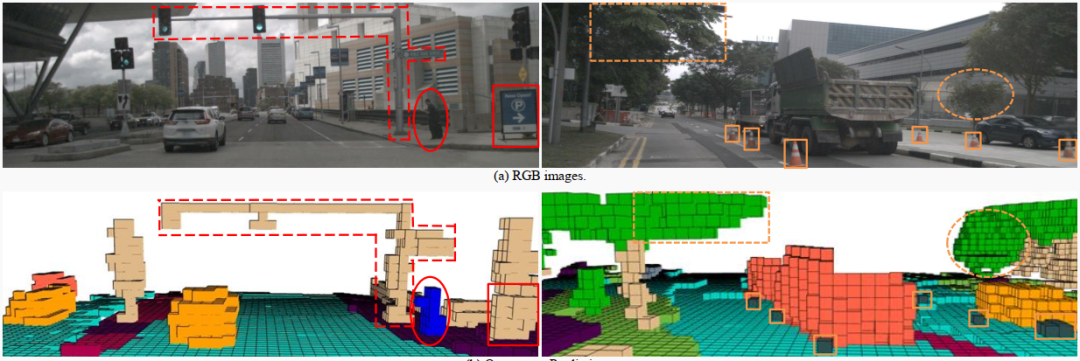
圖3. Occ3D-nuScenes上的定性結果。

表3. 在各種流行的基于體素的占據方法論上普適性demonstration的FlashOcc。
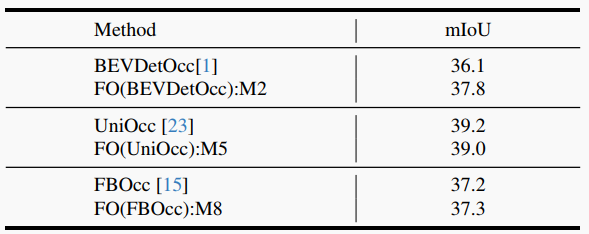
表4. 時序融合中的持續改進demonstration。
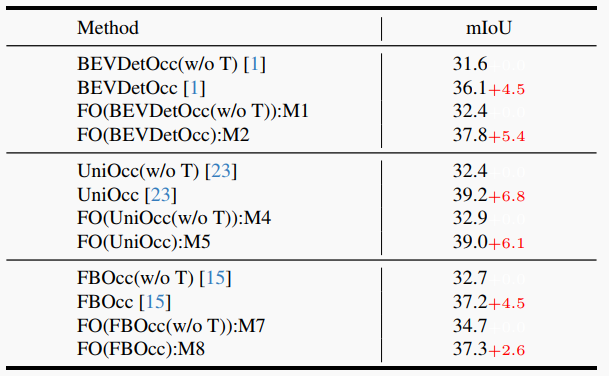
表5. 訓練和部署期間的資源消耗分析。
5. 總結
在本文中,我們介紹了一種即插即用的方法,稱為FlashOCC,它旨在實現快速和節省內存的占據預測。它直接用二維卷積替換了基于體素的占據方法中的三維卷積,并引入了通道到高度的變換,將扁平化的BEV特征重塑為占據logits。FlashOCC的有效性和泛化性已經在多種體素級占據預測方法上得到了驗證。廣泛的實驗表明,該方法在精度、時間消耗、內存效率和部署友好性方面優于以前的最先進的方法。據我們所知,我們是第一個將子像素范式(通道到高度)應用于占據任務的工作,它僅利用BEV級特征,完全避免了使用計算復雜的三維(可變形)卷積或變換器模塊。并且,可視化結果令人信服地證明了FlashOcc成功地保留了高度信息。在我們的未來工作中,我們將探索將我們的FlashOcc集成到自動駕駛的感知流程中,旨在實現高效的片上部署。
審核編輯:劉清
-
傳感器
+關注
關注
2557文章
51729瀏覽量
758804 -
編碼器
+關注
關注
45文章
3706瀏覽量
135755 -
變換器
+關注
關注
17文章
2112瀏覽量
109826 -
自動駕駛系統
+關注
關注
0文章
66瀏覽量
6933 -
LSS
+關注
關注
0文章
8瀏覽量
1995
原文標題:FlashOcc:無需微調,即插即用的占據預測模型!
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
即插即用和熱插拔的區別
————即插即用無需組網協議wifi模塊————
多片段時序數據建模預測實踐資料分享
PCI與即插即用
基于通用即插即用協議服務系統模型






 工商網監
工商網監
評論