 大模型學習筆記
大模型學習筆記
Apple最近發表了一篇文章,可以在iphone, MAC 上運行大模型:【LLM in a flash: Efficient Large Language Model Inference with Limited Memory】。
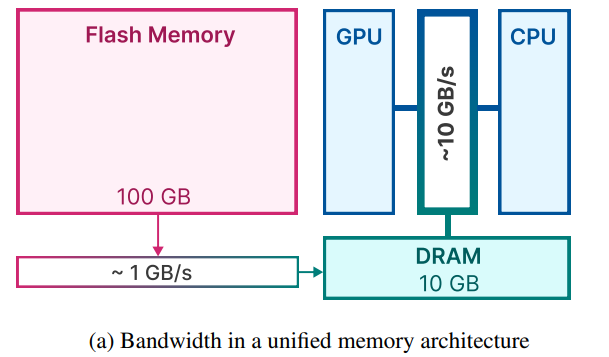
主要解決的問題是在DRAM中無法存放完整的模型和計算,但是Flash Memory可以存放完整的模型。但是Flash帶寬較低,LLM in Flash通過盡量減少從Flash中加載參數的數量,優化在DRAM中的內存管理,實現在Flash帶寬有限的條件下提高計算速度的目的。
這篇文章很多都是工程上的細節,很少理論。下面是這篇論文的總結,如有不對的地方,歡迎私信。
利用FeedForward 層的稀疏度,只加載FeedForward層輸入非0和預測輸出非0的參數
通過Window Sliding 只加載增量的參數,復用之前的計算,減少需要加載的參數。
將up-projection的row和down-projection的column放在一起存放,這樣在flash中可以一次讀取比較大的chunk,提高flash的帶寬利用效率。
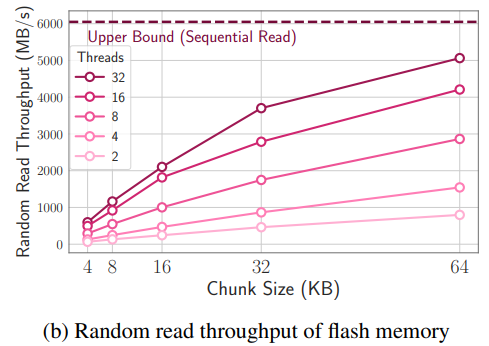
如下圖所示,chunk越大,帶寬也就越大,初始加載chunk的latency可以被平攤。
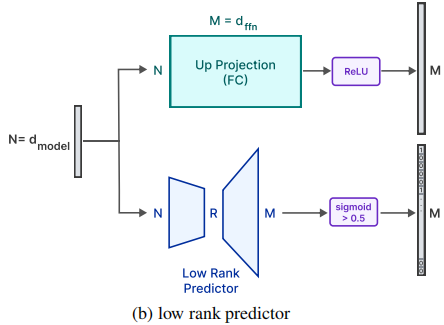
1. 大模型在FeedForward layer有超過90%的稀疏度。將embedding和attention 矩陣一直保存在DRAM中。Attention 的權重占據了model總量的1/3。對于FeedForward Layer,只有非稀疏的部分被動態的加載進去DRAM。
2. 預測Relu層的稀疏性。在attention層的輸出后面增加low-rank predictor,預測在relu層之后可能是0的元素。
經過優化后,最終只需要加載2%的FeedForward層的參數到DRAM中。
3. Sliding Window
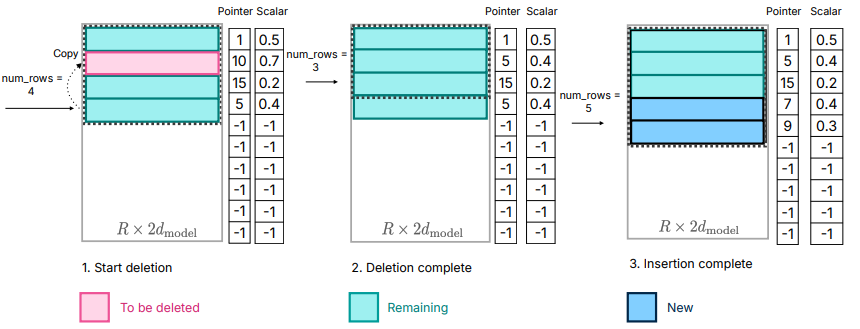
每次滑動窗口,在生成新的token后,刪掉不在window內的neuron,增加新的neuron。
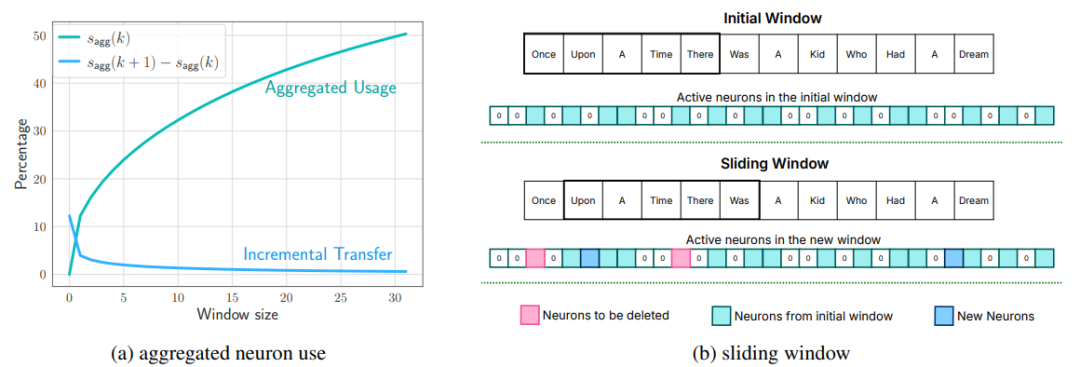
上圖右側為一個window size為5的示意圖,粉色的是要刪除的元素,藍色的是新加入的元素。
上圖左側是如何在aggregated usage和incremental transfer中保持平衡,window設置的越大,每次新需要加載neruon也就越少,但是需要在memory中累計保存的空間占用的也就越大。
上圖左側的目標就是如何讓aggregated usage和incremental transfer都比較小。
譯者疑問:這個window就是Longformer: The Long-Document Transformer中的sliding window嗎?歡迎私信。
4.內存管理
內存管理也是因為sliding window引入的。
譯者注:
就像c++中vector的維護一樣,如果每次刪除vector中間的一個元素,都需要導致該元素后面所有元素的移動。
下圖描述的就是刪除和加入新neuron的內容。
最后文章還提出了比較有意思的一點,他們主要進行了稀疏化的優化,在計算和加載參數方面。他們也嘗試了通過和當前neuron關系緊密的 “closest friend”綁定,每次加載neuron時,也都加載他的closest friend。
作者說但是這樣帶來了負面作用,因為存在一些closest friend是很多neuron的closest friend (譯者注:類似于大眾之友),這些neuron被頻繁的加載到DRAM中,反而降低了性能。
審核編輯:湯梓紅
-
DRAM
+關注
關注
40文章
2311瀏覽量
183446 -
Mac
+關注
關注
0文章
1104瀏覽量
51458 -
大模型
+關注
關注
2文章
2423瀏覽量
2643 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:大模型筆記【2】 LLM in Flash
文章出處:【微信號:處理器與AI芯片,微信公眾號:處理器與AI芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
記錄一下Linux設備模型學習歷程


Altera FPGA CPLD學習筆記

Linux設備模型學習筆記(1)
RT-Thread 內核學習筆記 - 設備模型rt_device的理解





 工商網監
工商網監
評論