 重塑翻譯與識別技術:開源語音識別模型Whisper的編譯優化與部署
重塑翻譯與識別技術:開源語音識別模型Whisper的編譯優化與部署
模型介紹
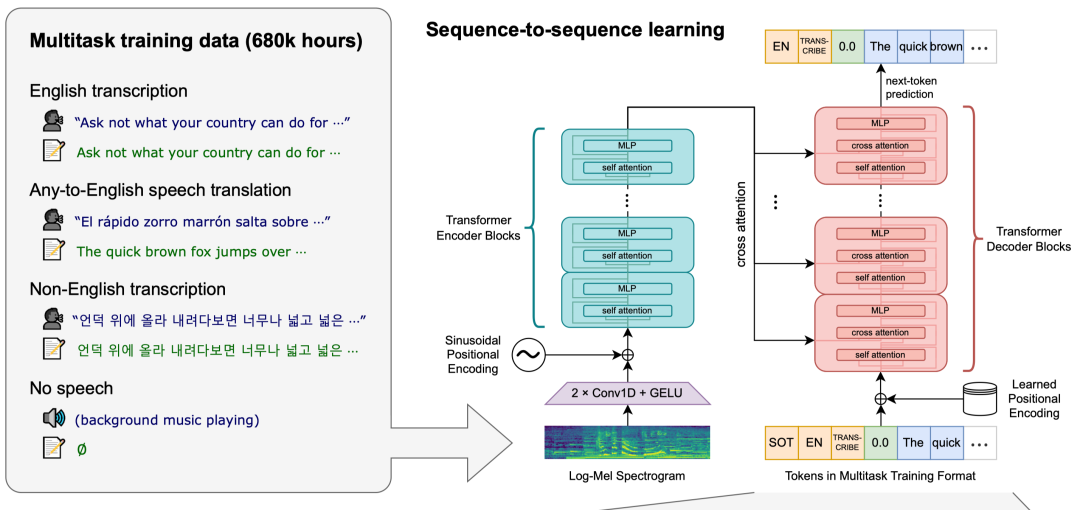
Whisper模型是一個由OpenAI團隊開發的通用語音識別模型。它的訓練基于大量不同的音頻數據集,是一個多任務模型,可以執行語音識別、語言翻譯、語言識別。下面是模型的整體架構:
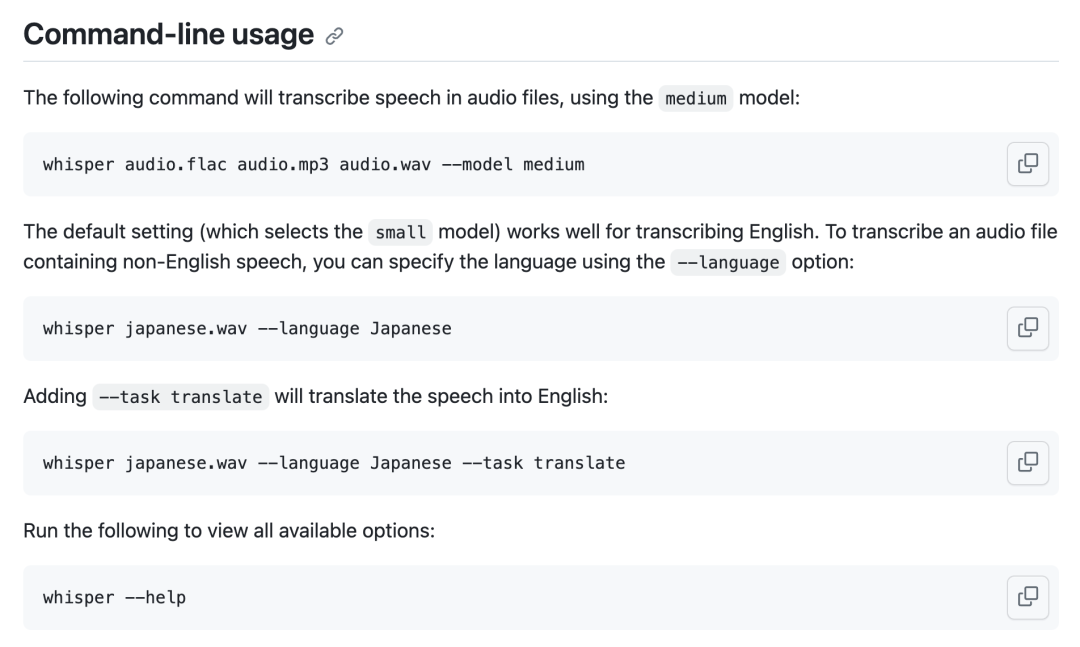
使用方法如下:
通過修改TPU-MLIR編譯器代碼,可以對Whisper模型性能進行深度優化,使得模型在SOPHON BM1684X處理器上運行時間減少到原來的一半,本篇文章將帶領大家對Whisper模型進行編譯與優化,并完成實際應用的部署。
優化方法
本次模型優化很具有典型性,不僅適用當前模型,對其他模型也有幫助,下面對相關的優化方法進行介紹
Tile算子轉廣播
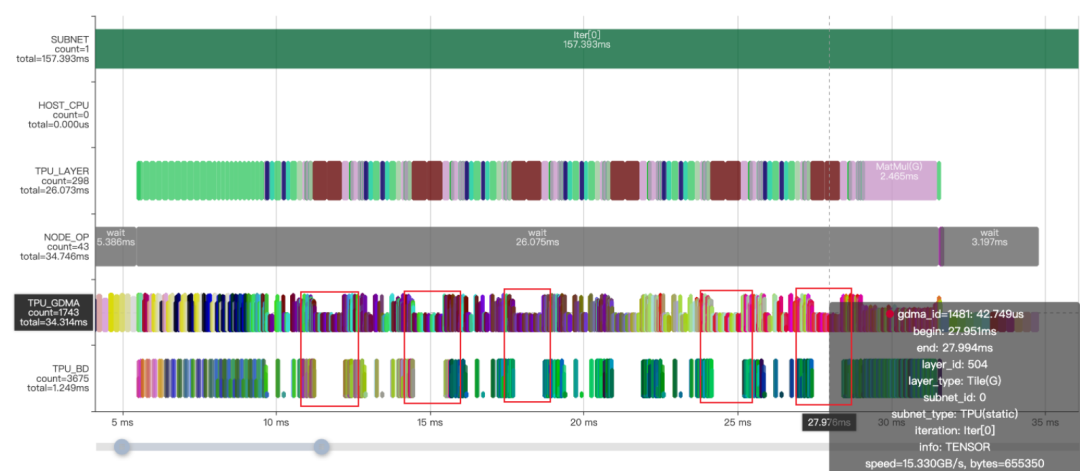
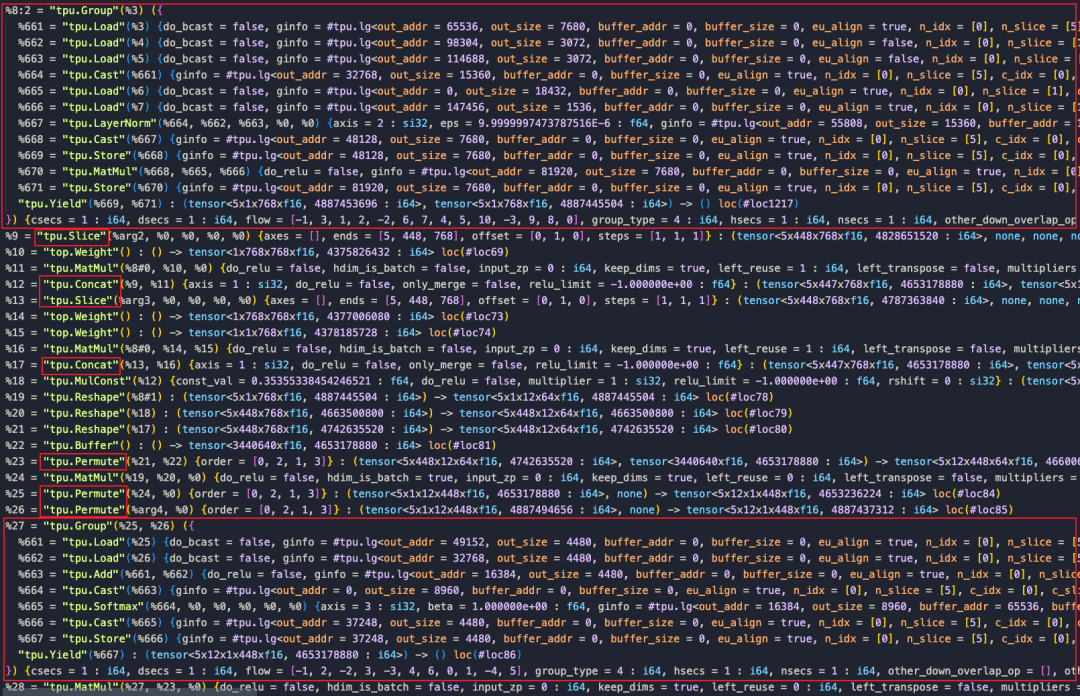
模型轉換完成后,觀察Profile時序圖和對應的MLIR文件,可以看到MatMulOp前面有兩個Tile操作,通過復制數據來使數據shape對齊,并且耗時占用十分明顯(如紅框所示),實際上完全可以利用算子的廣播功能實現,解決方法是使MatMulOp在hdim_is_batch的情況下支持n維度的廣播 (形如:5x1x8x64@1x1500x8x64 )。

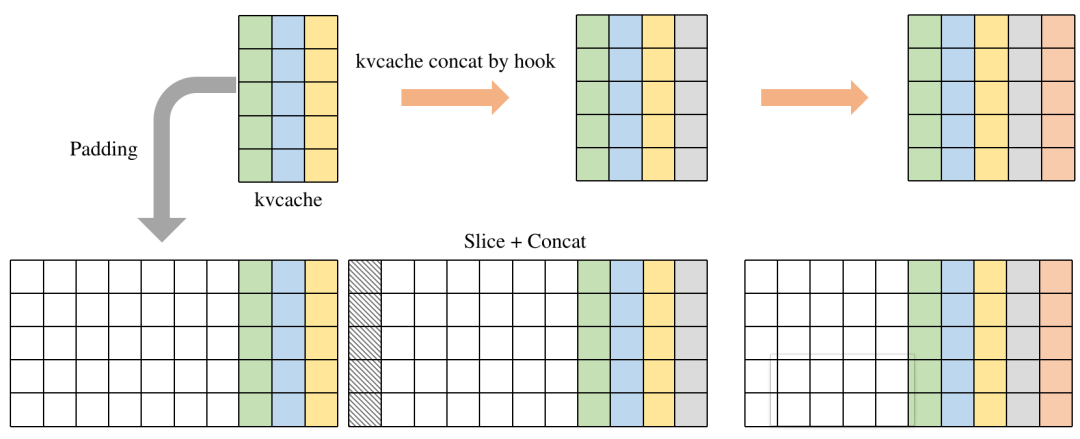
KVCache動態轉靜態
由于模型結構是基于Transformer模型結構構建的,KVCache的使用是比較常見的,對于使用KVCache的模型,我們的做法是,將KVCache作為模型的輸入和輸出。但在推理過程中KVCache會不斷增長,呈現一定的動態性,這就使得有一些數據需要PCIe重復搬運;內存管理比較復雜。通過padding將動態模型轉換為輸入和輸出為固定大小的靜態模型,并且在內部利用Slice和Concat算子自動完成數據拼接,減少外部內存處理復雜性,而且通過優化runtime過程避免多余的PCIe搬運。
Permute算子消除
完成上面兩步優化后,通過觀察Profile時序圖和分析final.MLIR文件發現,這一部分的網絡被分為了兩個LayerGroup,之間還存在許多Global Layer,這些都會導致額外的數據搬運。追溯這一現象的原因,很大可能是由于Slice、Concat和Permute三種操作的存在阻斷了LayerGroup的劃分。而且Permute、Concat和Slice的GDMA操作帶寬利用率低,浪費了較多時間。下面從這三個算子入手進行優化。
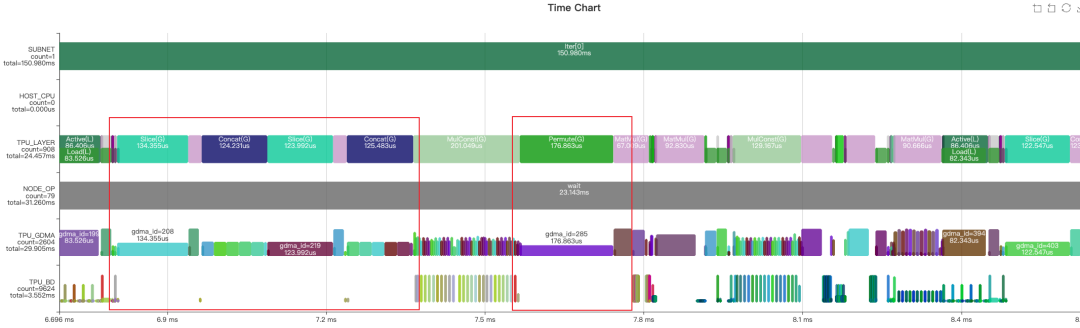
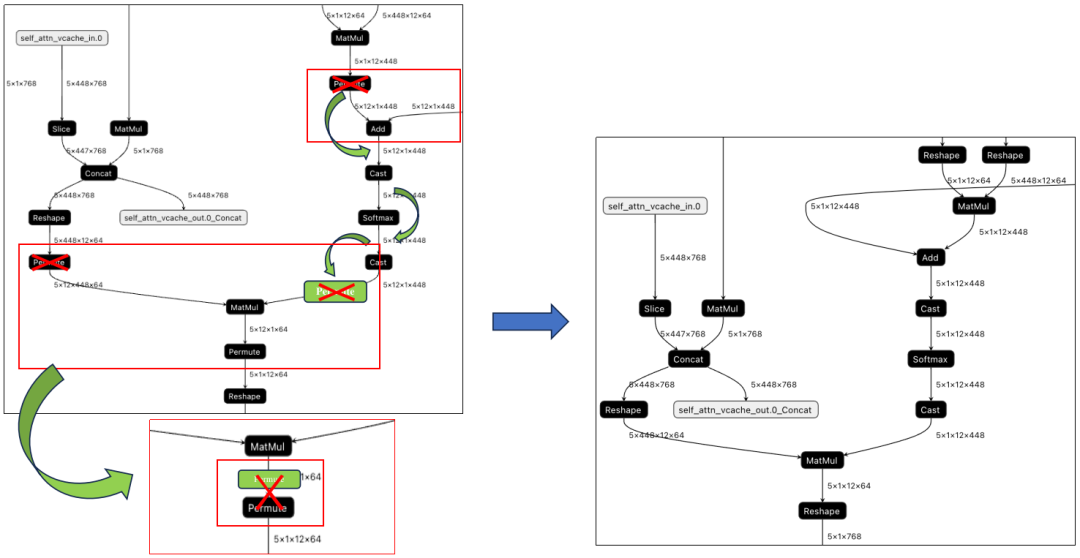
在Transformer類的模型里,由于數據需要維度翻轉整理,造成模型里有很多的Permute操作,但是通過算子的實現,一些運行前后的Permute是可以相互抵消的。如下圖所示,MatMul算子輸入和輸出的Permut是可以消除的,主要步驟是將輸入的Permute算子移動到輸出,MatMul利用TPU指令的特性,實現轉置的矩陣乘法,并在輸出處與原來的Permute抵消掉。最終結果下圖右側所示。
Slice+Concat算子融合
Slice和Concat本質上是將已經計算好但放置位置錯誤的結果進行截取或搬運。如果我們能提前知道結果應該放到哪里,就可以完全去掉這兩種操作。下面是一個典型的Slice+Concat的Pattern。通過分析右圖,可以看到為了將數據排到前面,Slice將Load后的數據進行搬運,之后Concat將MatMul的結果搬運到Slice后數據后面。其實這兩次搬運如果提前知道了放置位置,是可以去掉的。
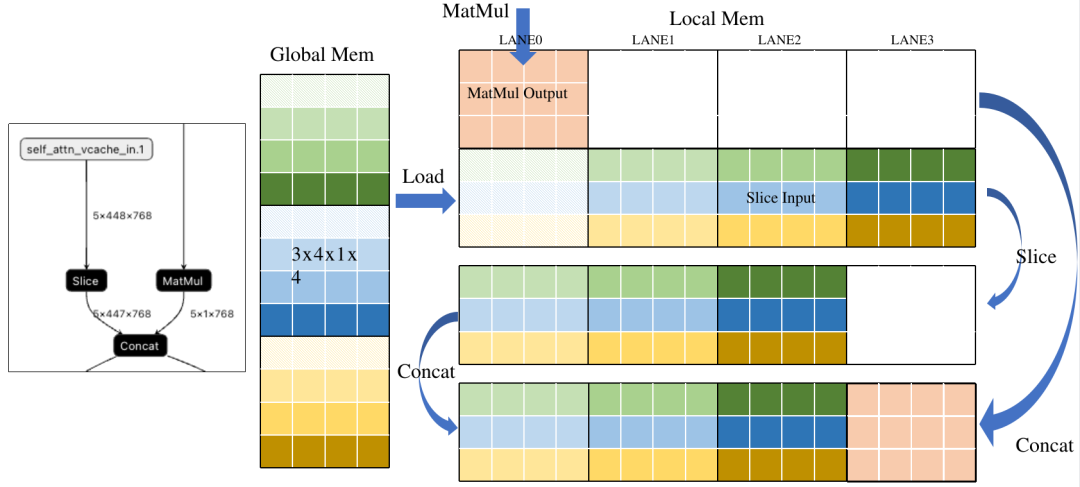
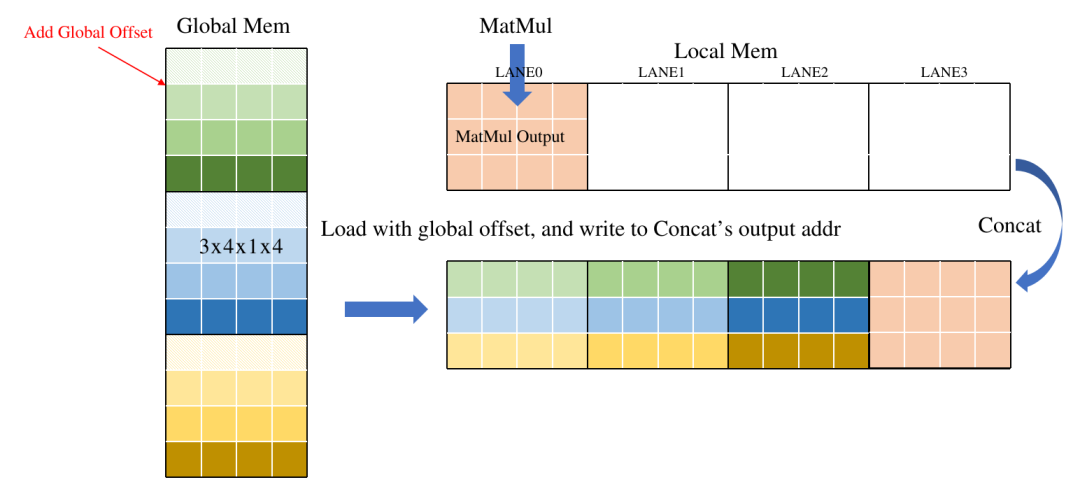
下圖示意了簡單的優化方法,在Load操作中引入一個Offset參數,表示數據在Global中的偏移,相當于在Load時直接做Slice, 減少了重復數據搬運,另外直接將Concat的輸出地址分配給Load,將數據直接寫在Concat的輸出地址,省去Concat的GDMA搬運時間。
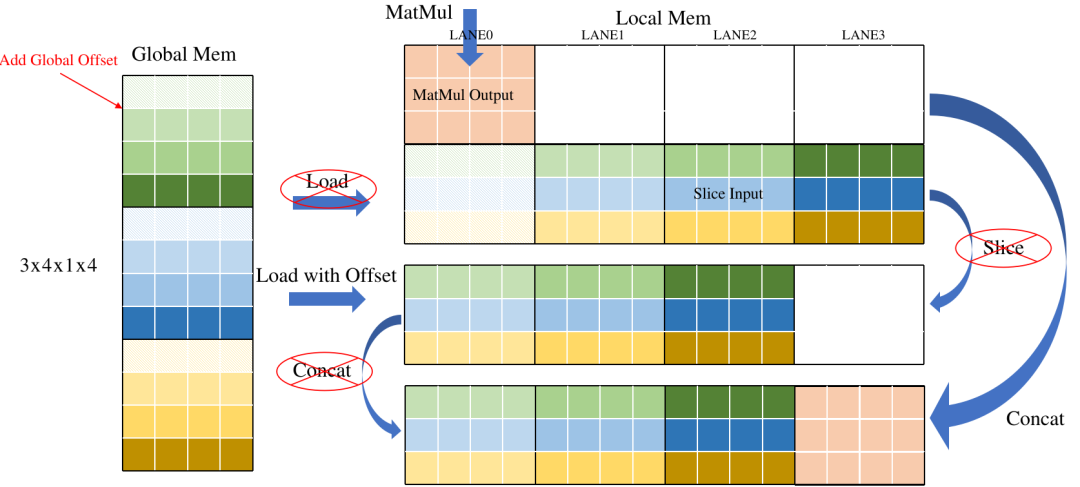
最終效果如下:
可以對比下優化前后的final.MLIR文件

比較上面兩圖,可以看到Concat和Slice, Permute大部分都去掉了。從下面的Profile也可以看出明顯的提升:
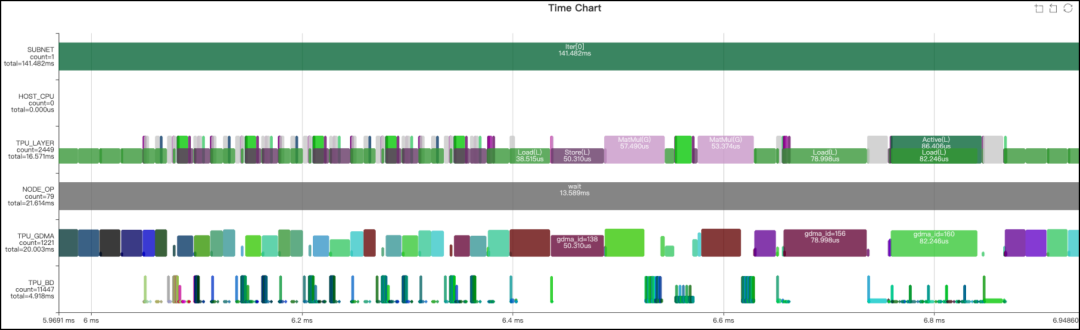
優化結果
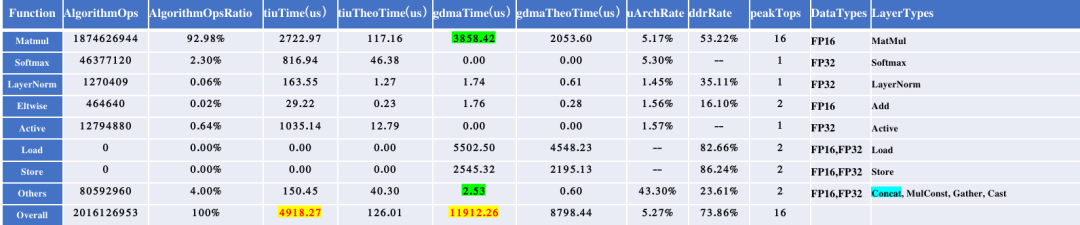
經過上述優化,模型的運行時間由原來的23.143ms變為13.589ms。為方便定量分析,下面提供了優化前后的算子性能統計結果。
優化前性能統計

優化后性能統計
部署代碼
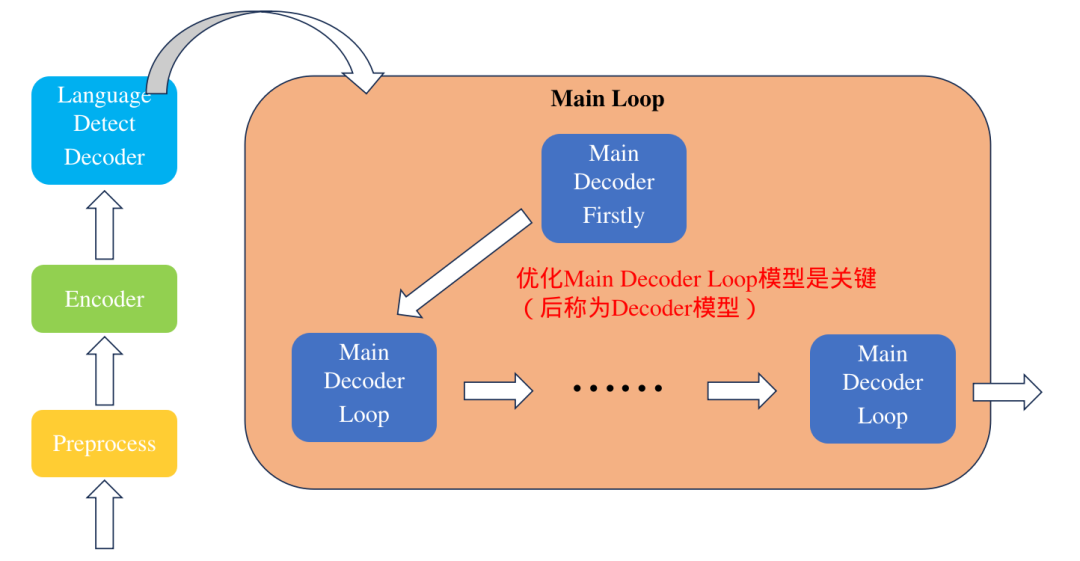
部署代碼目前已經開源(https://github.com/JKay0327/whisper-TPU_pyd)。本Whisper應用整體是由多個環節串聯起來的,包括前處理、Encoder、Language Detect Decoder、以及主循環中的Decoder迭代過程。上面優化的主要是針對主循環中的Decoder模型進行的。具體運行過程如下圖所示。
使用方法如下: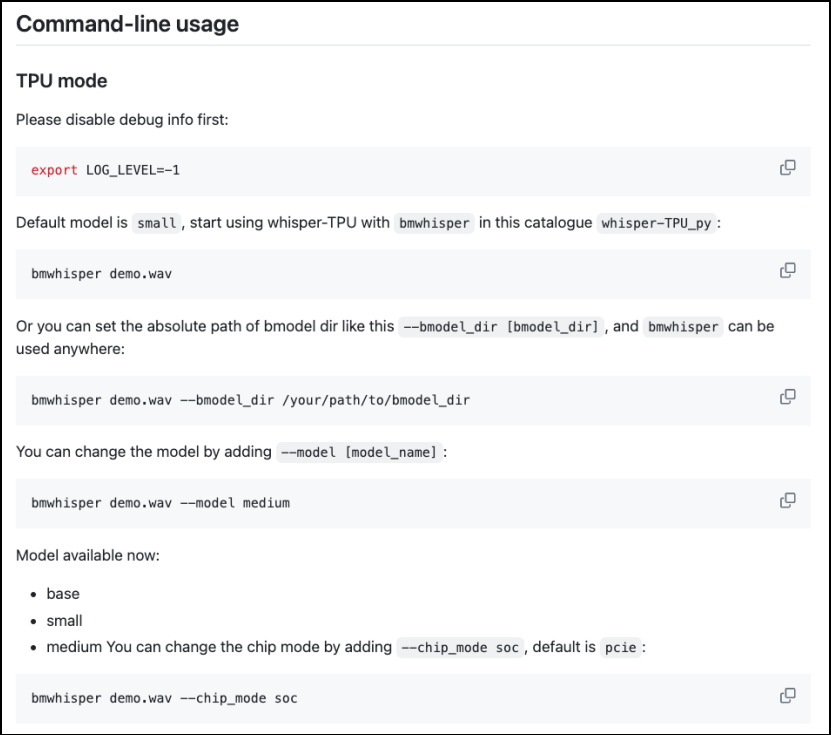
下面是實際的運行結果展示: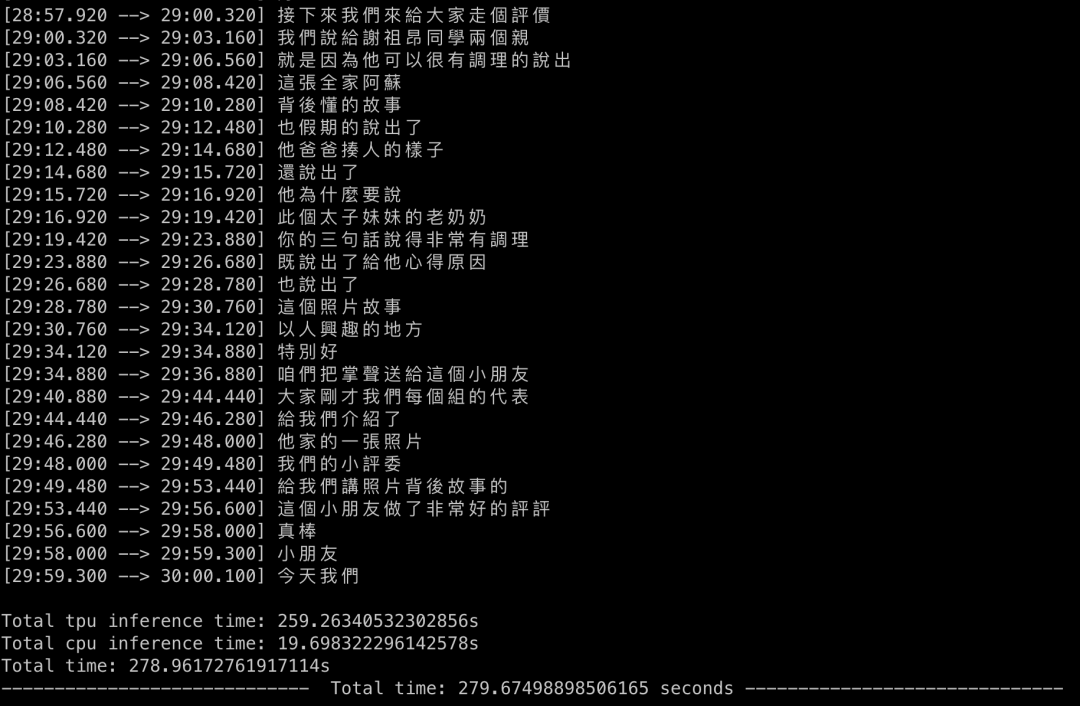
結論
本文是對在Whisper模型應用過程中的總結,說明了在模型優化過程中采用的各種思路和方法,最終將模型的性能翻倍。Whisper模型是一個很有價值的應用,可以實現各種語音任務,期待大家借助算能產品進行更多功能的開發。
-
語音識別
+關注
關注
38文章
1758瀏覽量
113274 -
模型
+關注
關注
1文章
3415瀏覽量
49475 -
音頻數據
+關注
關注
0文章
13瀏覽量
10018
發布評論請先 登錄
相關推薦
語音識別的現狀如何?
【HarmonyOS HiSpark AI Camera】基于圖像的手語識別機器人系統
語音識別技術的發展歷程,語音識別是如何工作的?語音識別資料概述
用英特爾CPU及GPU運行OpenAI-whisper模型語音識別





 工商網監
工商網監
評論