") 知識圖譜基礎(chǔ)知識應(yīng)用和學(xué)術(shù)前沿趨勢
知識圖譜基礎(chǔ)知識應(yīng)用和學(xué)術(shù)前沿趨勢
作者簡介
作者:gaojing
針對于知識圖譜基礎(chǔ)知識,領(lǐng)域應(yīng)用和學(xué)術(shù)前沿趨勢進(jìn)行介紹。
知識圖譜介紹
知識圖譜(Knowledge Graph)以結(jié)構(gòu)化的形式描述客觀世界中概念、實體及其關(guān)系。是融合了認(rèn)知計算、知識表示與推理、信息檢索與抽取、自然語言處理、Web技術(shù)、機(jī)器學(xué)習(xí)與大數(shù)據(jù)挖掘等等方向的交叉學(xué)科。人工智能是以傳統(tǒng)符號派與目前流行的深度神經(jīng)網(wǎng)路為主,如下圖所示,知識圖譜發(fā)展史。
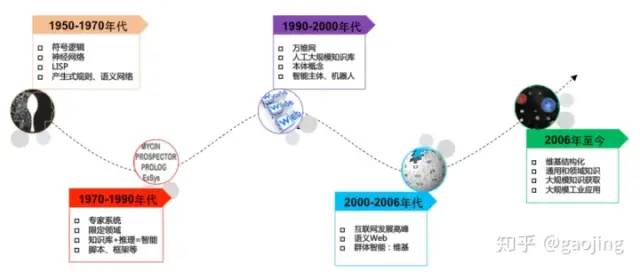
知識圖譜發(fā)展史
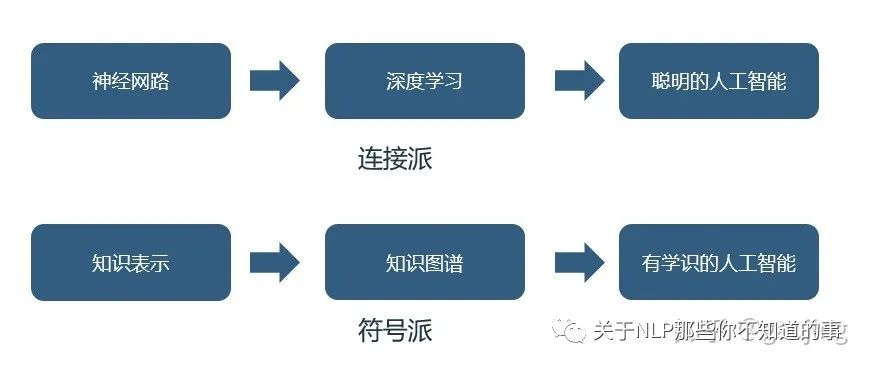
知識表示與深度學(xué)習(xí)表示
各大公司布局知識圖譜
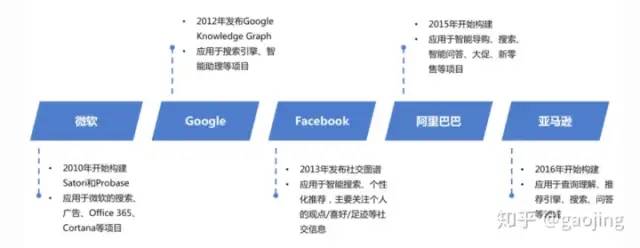
補(bǔ)充其中還包括國內(nèi)的京東與美團(tuán)(美團(tuán)的AI大腦,數(shù)十億知識圖譜構(gòu)建)
知識圖譜應(yīng)用模式(來之美團(tuán)的Ai大會報告)
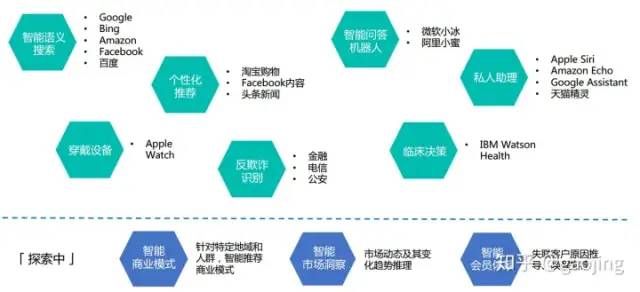
知識圖譜技術(shù)鏈
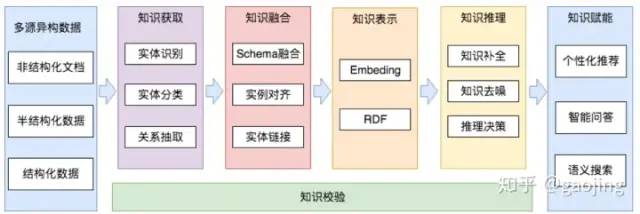
知識圖譜賦能
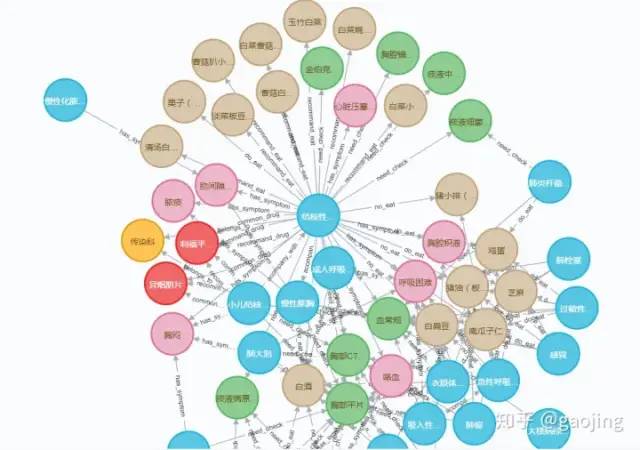
知識圖譜應(yīng)用非常廣泛,目前主要應(yīng)用到搜索引擎、智能問答、大數(shù)據(jù)分析、語言翻譯和語言理解及輔助設(shè)備互聯(lián)(Iot領(lǐng)域),如下圖所示,知識圖譜在搜索引擎的應(yīng)用。
通用知識圖譜與垂直領(lǐng)域知識圖譜對比
相比較DBpedia、Yago、Wikidata、百度和谷歌等通用知識圖譜,+特定領(lǐng)域內(nèi)的知識圖譜在知識表示、知識結(jié)構(gòu)、知識質(zhì)量及知識應(yīng)用更高的要求(關(guān)于領(lǐng)域知識圖譜與通用知識圖譜之間的問題可以查看復(fù)旦肖仰華)。

國內(nèi)外知識圖譜項目
國外:早期的常識知識庫Cyc、WordNet、ConceptNet等;互聯(lián)網(wǎng)知識圖譜,主要有FreeBase、DBpedia、Schema、Wikidata 、BableNet、Microsofot ConceptGraph,醫(yī)療領(lǐng)域Linked Life Data等
國內(nèi):中文知識圖譜OpenKG,CN-DBpedia,中醫(yī)藥知識圖譜,阿里電商知識圖譜、美團(tuán)知識圖譜、XLore(清華大學(xué))、Belief-Eigen(中科院)、PKUPie(北京大學(xué)),開放類的中文百科知識圖譜,zhishi.me
知識圖譜技術(shù)模塊
知識表示
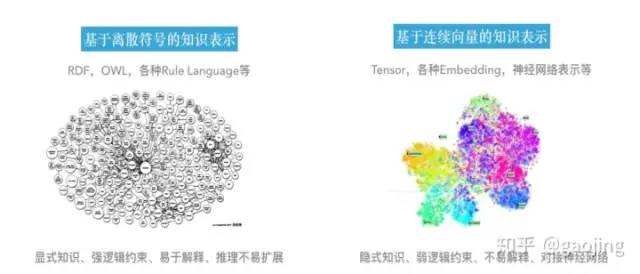
如何利用計算符號運算來表示人腦中的知識和推理過程,知識表示主要有兩種,基于離散符號的知識表示法和基于連續(xù)向量的知識表示。
基于離散符號的知識表示法
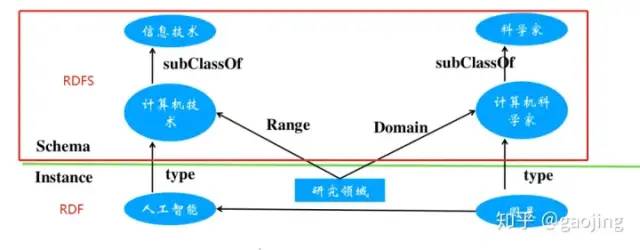
RDF(Triple-based Assertion Model) 三元組模型,構(gòu)建方式主要是主-謂-賓有向標(biāo)記圖和RDFS(simple Vocabularty and schema)
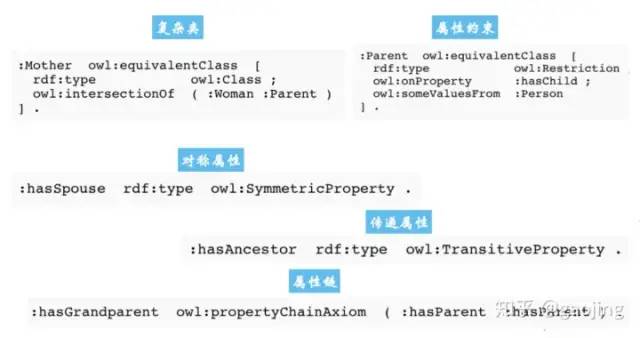
OWL(Web Ontology language):是一種W3C開發(fā)的網(wǎng)路本體語言,用于對本體進(jìn)行語義描述。
SPARQL(Protocol and RDF Query Language) :RDF的查詢語言,支持主流圖形數(shù)據(jù)庫。下圖URI/IRI為主要網(wǎng)絡(luò)協(xié)議,主要數(shù)據(jù)存儲格式是RDF與XML
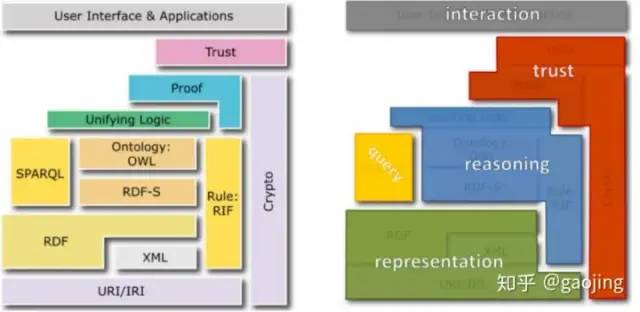
基于連續(xù)向量的知識表示
KG embedding 主要是KG中實體與關(guān)系映射到一個低維的向量空間,主要的方法有張量分解、NN、距離模型(現(xiàn)有的詞向量模型基于連續(xù)向量空間來表示)(Embedding projector)
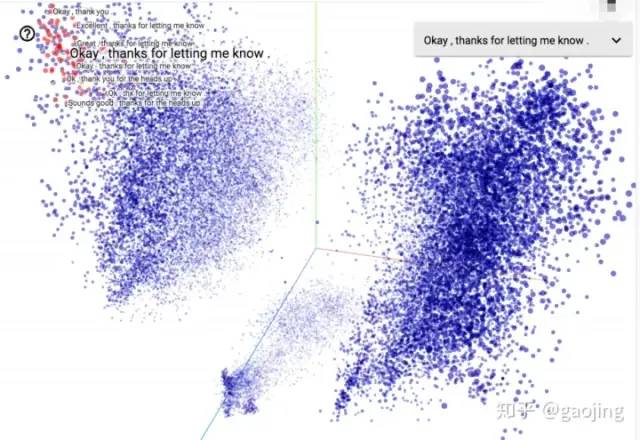
兩種方法對比
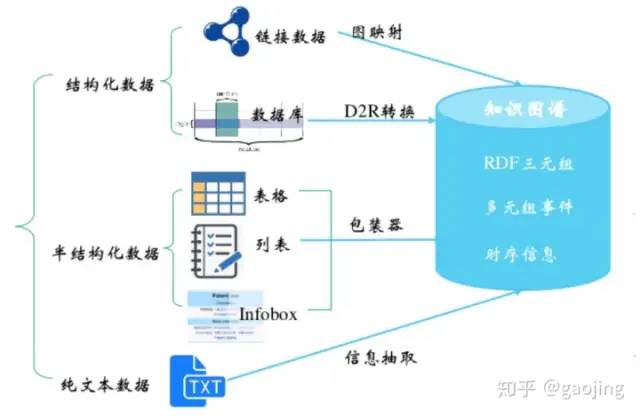
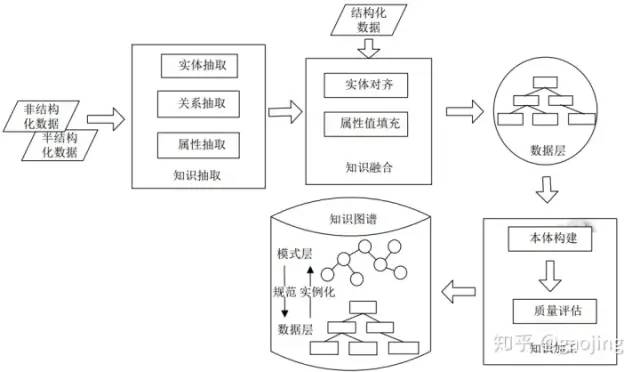
知識抽取
KG中知識抽取主要從結(jié)構(gòu)化、半結(jié)構(gòu)化、結(jié)構(gòu)化數(shù)據(jù)中轉(zhuǎn)為三元組表示的標(biāo)準(zhǔn)知識形態(tài)。
主要處理流程
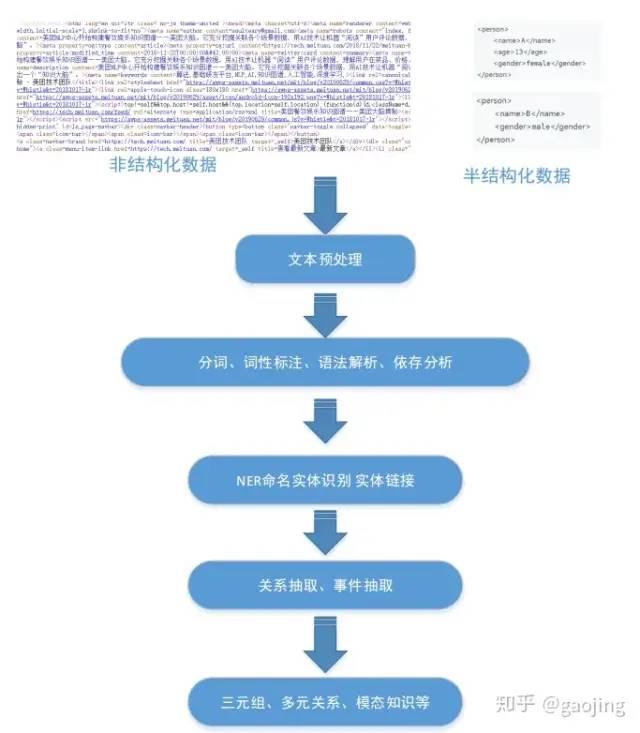
實體抽取(NER命名實體識別)
目的是識別文本中指定類別的實體,主要包括人 名、 地名、 機(jī)構(gòu)名、 專有名詞等的任務(wù)“ 姚明(Yao Ming),1980年9月12日出生于上海市徐匯區(qū),祖籍江蘇省蘇州市吳江區(qū)震澤鎮(zhèn),前中國職業(yè)籃球運動員,司職中鋒,現(xiàn)任中職聯(lián)公司董事長兼總經(jīng)理“。如下圖所示,命名實體識別主要包含兩個部分:實體邊界識別與實體分類。傳統(tǒng)方法(HMM(隱馬爾科夫模型) CRF(條件隨機(jī)場) SVM、最大熵分類模型等方法進(jìn)行處理。現(xiàn)在能采用深度學(xué)習(xí),比如CNNRNNLSTM及LSTM-CRF。采用的工具可以有Jiagu、jieba、Stanford CoreNLP等。

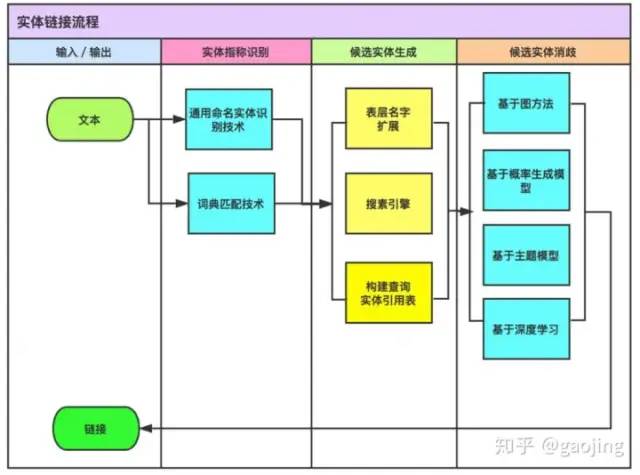
實體鏈接
目的是將實體提及與知識庫中對應(yīng)實體進(jìn)行鏈接 ,主要解決實體名的歧義性與多樣性問題,是文本中實體名指向真實世界實體的任務(wù)。傳統(tǒng)模型是計算實體提及與知識庫中實體的相似度,并選取特定的實體提及的目標(biāo)實體,比如“蘋果發(fā)布新的手機(jī)‘IphoneX11’”,[蘋果(水果)、蘋果(電影)、蘋果(公司)等候選實體],主要使用包括實體統(tǒng)計信息、名字統(tǒng)計信息、上下文詞語分布、實體關(guān)聯(lián)度、文章主題等信息,同時,考慮到一段文本中實體之間的相互關(guān)聯(lián),相關(guān)的全局推理算法也被提出來尋找全局最優(yōu)決策。目前深度學(xué)習(xí)方法,構(gòu)建多類型多模態(tài)上下文及知識的統(tǒng)一表示,并建模不同信息、不同證據(jù)之間的相互交互 通過將不同類型的信息映射到相同的特征空間,并提供高效的端到端訓(xùn)練算法。包括多源異構(gòu)證據(jù)的向量表示學(xué)習(xí)、以及不同證據(jù)之間相似度的學(xué)習(xí)等工作[Ganea & Hofmann, 2017] [Gupta et al., 2017] [Sil et al 2018] 。開源工具dexter2
實體關(guān)系抽取
實體關(guān)系抽取是知識圖譜構(gòu)建與信息提取的關(guān)鍵環(huán)節(jié),主要提取兩個或者多個實體之間的某種聯(lián)系。格式,三元組(實體1,關(guān)系,實體2),"北京是中國的首都、政治中心和文化中心 "中實體關(guān)系可以表示為(中國、首都、北京)(中國 政治中心 北京)(中國 文化中心 北京)。
限定關(guān)系抽取:采用弱監(jiān)督/監(jiān)督機(jī)器學(xué)習(xí)進(jìn)行預(yù)定義的實體關(guān)系知識抽取,一般為多分類問題,可以直接抽取三元組關(guān)系。一般會采用基于特征向量的方法、基于核函數(shù)的方法和基于神經(jīng)網(wǎng)絡(luò)的方法 。
開發(fā)域關(guān)系抽取:預(yù)先不進(jìn)行預(yù)定義,系統(tǒng)本身自動抽取實體之間的關(guān)系,一般采用無監(jiān)督學(xué)習(xí)方法進(jìn)行自動提取實體之間的關(guān)系(三元組)。缺點是抽取的知識缺乏語義化、很難做歸一化處理,弱監(jiān)督學(xué)習(xí)可以自動生成大規(guī)模的訓(xùn)練醫(yī)療庫,但是會產(chǎn)生噪音數(shù)據(jù)。
事件關(guān)系抽取
識別文本中關(guān)于事件的信息,并以結(jié)構(gòu)化的形式呈現(xiàn),核心概念包括:事件描述、事件觸發(fā)詞(動詞或者名詞)、事件元素(實體、時間和屬性等表達(dá)語義的細(xì)粒度單位組成)、元素角色(角色在某件事情上面的語義關(guān)系)、事件類型(事件元素和觸發(fā)詞決定事件的類別),如下圖所示
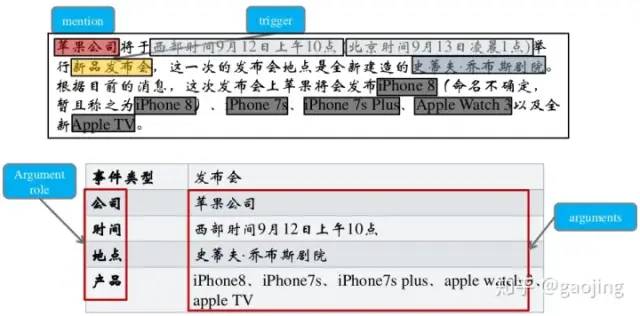
基于模式匹配的方法:對于某一個事件的識別與抽取是在一些模式的指導(dǎo)下進(jìn)行的,主要有兩個步驟:模式獲取和模式匹配,有可分為基于人工標(biāo)注語料和弱監(jiān)督學(xué)習(xí)
基于機(jī)器學(xué)習(xí)的方法:把事件建模成多分類問題,可以分為基于特征、基于結(jié)構(gòu)和基于神經(jīng)網(wǎng)路。
基于特征:該方法多用管道式事件抽取
基于結(jié)構(gòu)預(yù)測:將事件結(jié)構(gòu)看做是依存樹結(jié)構(gòu)預(yù)測。基于結(jié)構(gòu)感知機(jī)的聯(lián)合模型可同時完成觸發(fā)詞與事件元素識別的兩個子任務(wù)。
基于神經(jīng)網(wǎng)路:利用RNN進(jìn)行事件檢測及聯(lián)合模型與RNN相結(jié)合進(jìn)行預(yù)測觸發(fā)詞和事件元素
基于弱監(jiān)督:在學(xué)術(shù)上,[Chen and Ji, 2009] [Liao and Grishman, 2011a; 2011b] [Liu et.al., 2016b] 等,但是由于該方法無法直接映射到結(jié)構(gòu)化數(shù)據(jù)中,無法直接構(gòu)建三元組。
中文事件抽取
中文與英文事件抽取區(qū)別較大,主要是缺乏統(tǒng)一、公認(rèn)的事件語料庫及公開評測系統(tǒng)(上海大學(xué)CEC(Chinese Event Corpus))
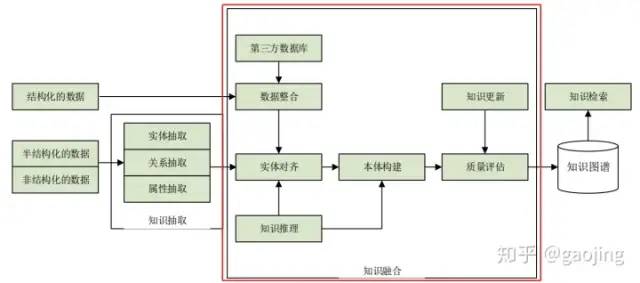
知識融合
知識融合是指合并兩個知識圖譜,本體可以讓用戶非常方便和靈活的根據(jù)自己的業(yè)務(wù)建立或者修改數(shù)據(jù)模型。通過數(shù)據(jù)映射技術(shù)建立本體中術(shù)語和不同數(shù)據(jù)源抽取知識中詞匯的映射關(guān)系,進(jìn)而將不同數(shù)據(jù)源的數(shù)據(jù)融合在一起。同時不同源的實體可能會指向現(xiàn)實世界的同一個客體,這時需要使用實體匹配將不同數(shù)據(jù)源相同客體的數(shù)據(jù)進(jìn)行融合。不同本體間也會存在某些術(shù)語描述同一類數(shù)據(jù),那么對這些本體間則需要本體融合技術(shù)把不同的本體融合。
知識融合-異構(gòu)問題
語言層不匹配:RDF OWL OWL2等本體語言之間不兼容。
實體對齊問題:由于多源、異構(gòu)、跨語言知識圖譜差異性較大,比如結(jié)構(gòu)化不可比、實體名稱表述差別較大、外部工具不穩(wěn)定等,可訓(xùn)練數(shù)據(jù)較少。方法:可以基于圖神經(jīng)網(wǎng)路的實體結(jié)構(gòu)語義表示及匹配(關(guān)于知識融合中實體對齊在學(xué)術(shù)上有很多研究)
知識存儲
知識圖譜的知識存儲一般是采用圖形數(shù)據(jù)庫進(jìn)行存儲,主要有兩種圖數(shù)據(jù)模型:RDF圖和屬性圖
查詢語言:RDF圖---SPARQL;屬性圖:Cypher 和 Gremlin
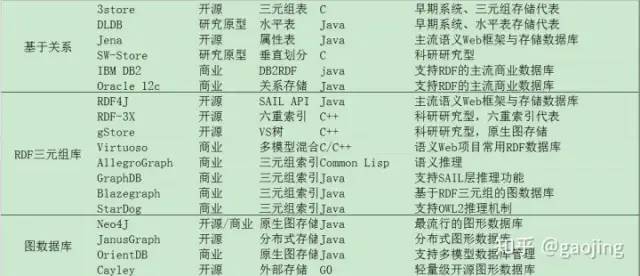
常見知識圖譜存儲方式
基于關(guān)系數(shù)據(jù)庫的存儲方案
主要是三元組表(3store)、水平表(DLDB)、屬性表(JENA)、垂直劃分(SW-Store)、DB2RDF和六重索引(RDFX-3X、Hexastore)
面向RDF的三元組數(shù)據(jù)庫
Jena RDF4J RDF-3X gStore
原生圖數(shù)據(jù)庫
Neo4j
分布式圖形數(shù)據(jù)庫 JanusGraph
OrientDB
Cayley
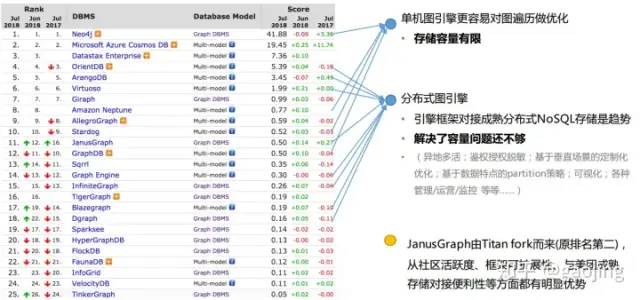
圖形數(shù)據(jù)庫對比
來之DB-Engiens圖引擎和美團(tuán)知識圖譜報告,美團(tuán)采用JanusGraph分布式圖形引擎
知識推理
根據(jù)已有的知識圖譜中的事實或者關(guān)系推斷出新的事實與關(guān)系,一般是考察實體、關(guān)系和圖譜結(jié)構(gòu)三個方面的信息特征
基于演繹的知識圖譜推理
基于歸納的知識圖譜推理
基于圖結(jié)構(gòu)
基于規(guī)則學(xué)習(xí)
基于表示學(xué)習(xí)
新的方法
時序法
基于強(qiáng)化學(xué)習(xí)
基于圖神經(jīng)網(wǎng)路
開源工具
Jena和Drools
知識圖譜構(gòu)建流程
主要介紹主流的知識圖譜構(gòu)建流程,實體圖譜的構(gòu)建主要有自底向上、自頂向下和二則混合的方法,如下圖所示,分別為自底向上和自頂向下
自底向上
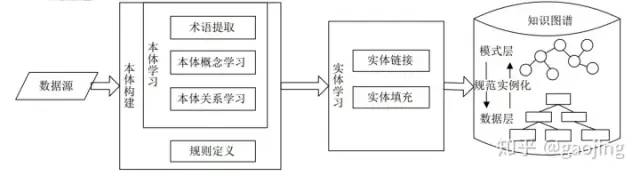
自頂向下
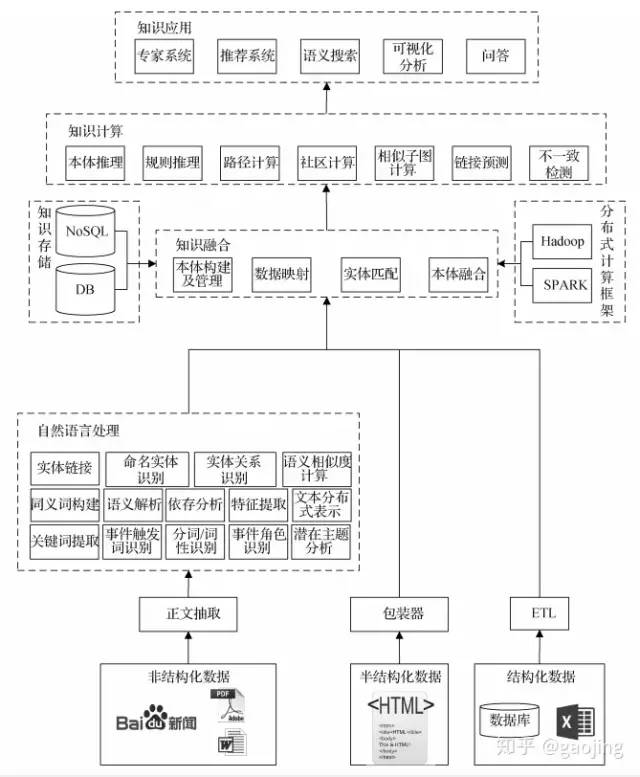
知識圖譜整體構(gòu)建流程
審核編輯:黃飛
-
網(wǎng)絡(luò)協(xié)議
+關(guān)注
關(guān)注
3文章
267瀏覽量
21534 -
數(shù)據(jù)存儲
+關(guān)注
關(guān)注
5文章
970瀏覽量
50894 -
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238261 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7703
原文標(biāo)題:知識圖譜入門系列
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
NLPIR大數(shù)據(jù)知識圖譜完美展現(xiàn)文本數(shù)據(jù)內(nèi)容
KGB知識圖譜基于傳統(tǒng)知識工程的突破分析
KGB知識圖譜技術(shù)能夠解決哪些行業(yè)痛點?
知識圖譜的三種特性評析
知識圖譜是什么?與傳統(tǒng)知識表示的區(qū)別
知識圖譜已經(jīng)取得了哪些學(xué)術(shù)與技術(shù)成果,產(chǎn)業(yè)與應(yīng)用發(fā)生了哪些變化?
一文帶你讀懂知識圖譜
知識圖譜劃分的相關(guān)算法及研究

知識圖譜在工程應(yīng)用中的關(guān)鍵技術(shù)、應(yīng)用及案例

通用知識圖譜構(gòu)建技術(shù)的應(yīng)用及發(fā)展趨勢

知識圖譜是NLP的未來嗎?

什么是知識圖譜?人工智能世界知識圖譜的發(fā)展
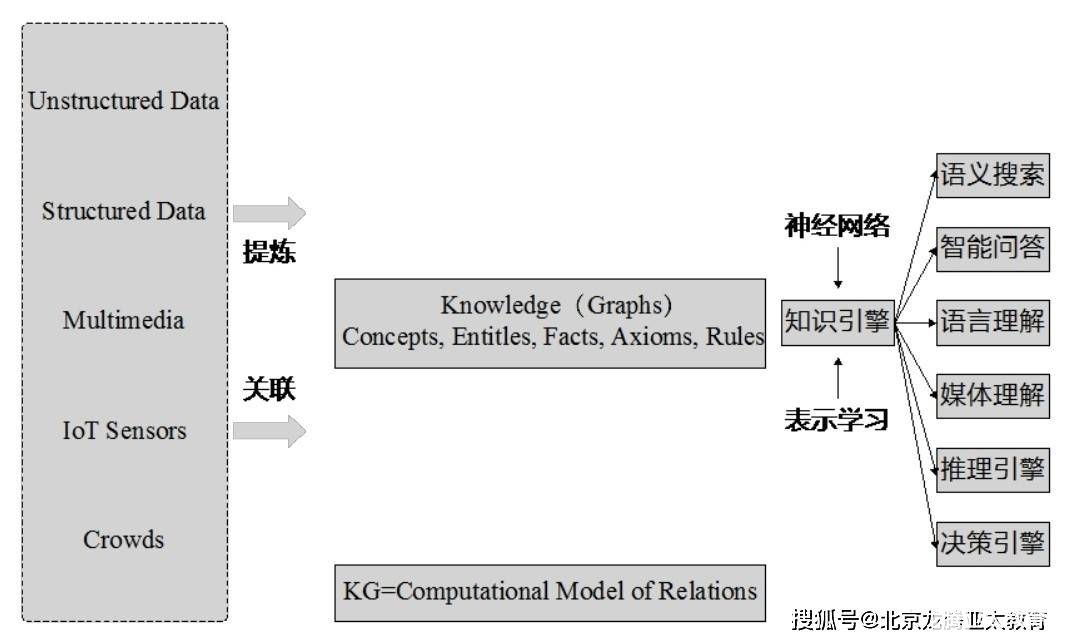
知識圖譜Knowledge Graph構(gòu)建與應(yīng)用
知識圖譜:知識圖譜的典型應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論