 視覺模型weak-to-strong的實現
視覺模型weak-to-strong的實現
幾天前,OpenAI「超級對齊」(Superalignment)團隊發布了成立以來的首篇論文,聲稱開辟了對超人類模型進行實證對齊的新研究方向。GPT-2能監督GPT-4,Ilya帶頭OpenAI超級對齊首篇論文來了:AI對齊AI取得實證結果
可能是為了讓大家更容易實現論文中的思路,也可能是為了讓自己的研究更加接地氣,不再被調侃為“CloseAI”。在公布這篇論文的同時,OpenAI也在GitHub開源了論文提出的"weak-to-strong"框架的代碼[1]
在觀察了倉庫中的代碼之后我們有了如下發現:
既有NLP版本也有CV版本
主代碼倉庫是一個對二元分類(binary classification)任務的“weak-to-strong”方法的實現。包含用于微調預訓練語言模型的代碼(訓練弱模型,生成若標簽),以及針對來自另一種語言模型的標簽進行訓練的代碼(使用弱標簽,訓練強學生)。
Vision目錄中則包含視覺模型"weak-to-strong"的實現(AlexNet -> DINO)。
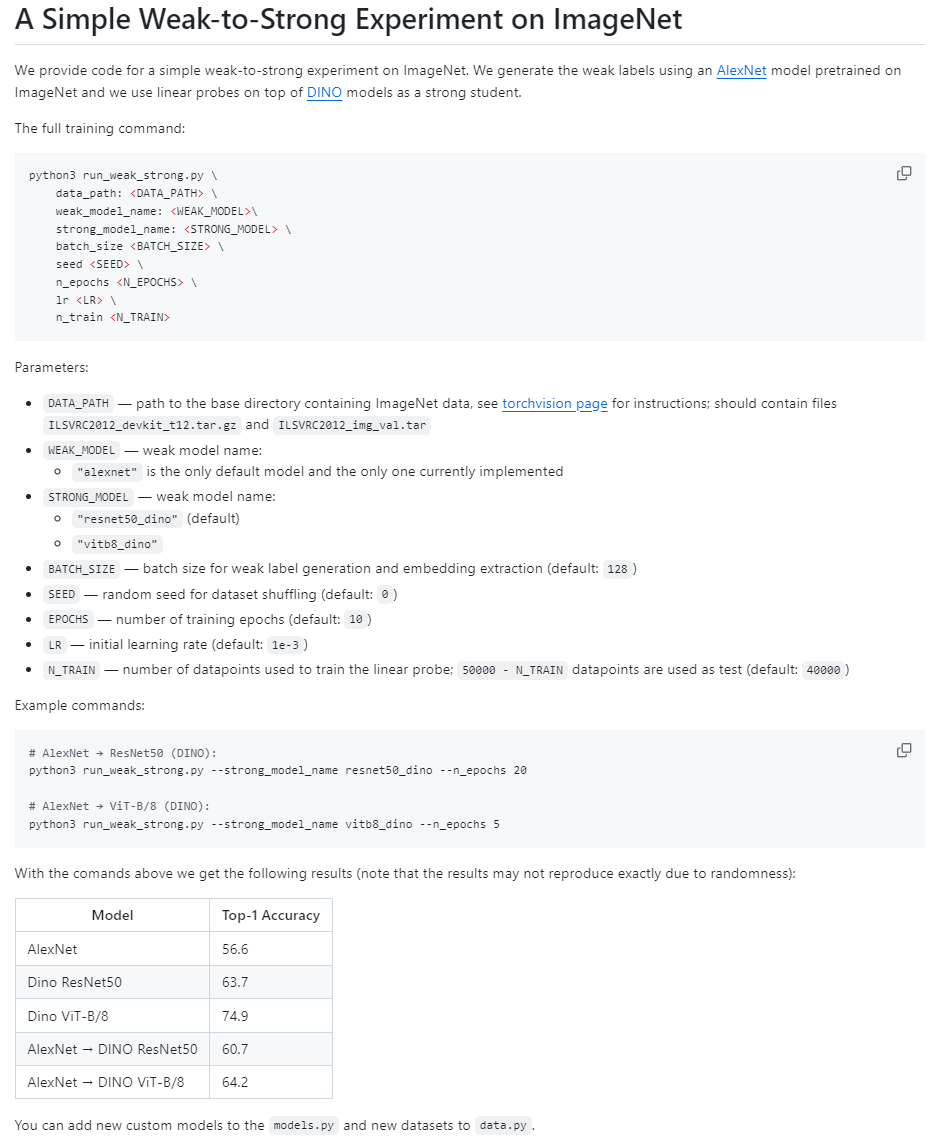
支持論文中描述的各種損失函數,如置信度輔助損失函數,也可以自己定義損失函數,見weak_to_strong/loss.py。
#Customlossfunction classxent_loss(LossFnBase): def__call__( self,logits:torch.Tensor,labels:torch.Tensor,step_frac:float )->torch.Tensor: """ Thisfunctioncalculatesthecrossentropylossbetweenlogitsandlabels. Parameters: logits:Thepredictedvalues. labels:Theactualvalues. step_frac:Thefractionoftotaltrainingstepscompleted. Returns: Themeanofthecrossentropyloss. """ loss=torch.nn.functional.cross_entropy(logits,labels) returnloss.mean() classproduct_loss_fn(LossFnBase): ... returnloss.mean() classlogconf_loss_fn(LossFnBase): ... returnloss.mean()
Qwen(千問)模型出現在代碼中
在主文件train_weak_to_strong.py中,OpenAI以自己的GPT2模型,和國產的Qwen(千問)模型為例
ModelConfig(
name="gpt2",
default_lr=5e-5,
eval_batch_size=32,
custom_kwargs={
"bf16":torch.cuda.is_bf16_supported(),
"fp32":nottorch.cuda.is_bf16_supported(),
},
),
ModelConfig(
name="gpt2-medium",
default_lr=5e-5,
eval_batch_size=32,
custom_kwargs={
"bf16":torch.cuda.is_bf16_supported(),
"fp32":nottorch.cuda.is_bf16_supported(),
},
),
...
ModelConfig( name="Qwen/Qwen-7B", default_lr=1e-5, eval_batch_size=2, gradient_checkpointing=True, model_parallel=True, #note:youwillprobablynotbeabletorunthiswithoutmanygpus custom_kwargs={ "trust_remote_code":True, "bf16":torch.cuda.is_bf16_supported(), "fp32":nottorch.cuda.is_bf16_supported(), }, ), ModelConfig( name="Qwen/Qwen-14B", default_lr=1e-5, eval_batch_size=2, gradient_checkpointing=True, model_parallel=True, #note:youwillprobablynotbeabletorunthiswithoutbf16supportandmanygpus custom_kwargs={ "trust_remote_code":True, "bf16":torch.cuda.is_bf16_supported(), "fp32":nottorch.cuda.is_bf16_supported(), }, ), ...
兩階段訓練
Weak-to-strong關注的重點是:一個弱監督者如何監督一個比它聰明得多的模型?為此,OpenAI提出了一個兩階段的訓練方法:
對于一個給定的任務:
構建弱監督者。通過在一半訓練數據上微調較小的預訓練模型來構造弱監督者,他們把弱監督者的表現稱為弱表現,并通過弱模型的預測來生成弱標簽。(Stage 1)
#Traintheweakmodelonthefirsthalfofthetrainingdata
print(f"Trainingweakmodel,size{weak_model_size}")
weak_test_results,weak_ds=train_model(
weak_model_config,
train1_ds,
test_ds,
loss_type="xent",
label="weak",
subpath=os.path.join("weak_model_gt",weak_model_size.replace("/","_")),
lr=weak_lr,
eval_batch_size=weak_eval_batch_size,
inference_ds=train2_ds,
epochs=gt_epochs,
linear_probe=linear_probe,
optimizer_name=weak_optim,
)
訓練一個用于比較的性能上限的強模型。在另一半訓練數據上以Ground Truth作為標簽訓練一個較大的模型作為比較的上限。(Upper bound)
#Trainthestrongmodelonthesecondhalfofthetrainingdata
print(f"Trainingstrongmodel,size{strong_model_size}")
strong_test_results,_=train_model(
strong_model_config,
train2_ds,
test_ds,
loss_type="xent",
label="strong",
subpath=os.path.join("strong_model_gt",strong_model_size.replace("/","_")),
lr=strong_lr,
eval_batch_size=strong_eval_batch_size,
epochs=gt_epochs,
linear_probe=linear_probe,
optimizer_name=strong_optim,
)
通過第一步中的弱監督訓練強學生模型。本文使用生成的弱標簽微調強模型,并將該模型稱為強學生模型,將其產生的性能稱為從弱到強(weak-to-strong)的性能。(Stage 2)
#Trainthestrongmodelonthesecondhalfofthetrainingdatawithlabelsgeneratedbytheweakmodel
all_transfer_test_results={}
fortlossintransfer_losses:
print(
f"Trainingtransfermodel,size{strong_model_size}onlabelsfrom{weak_model_size},withloss{tloss}"
)
transfer_test_results,_=train_model(
strong_model_config,
weak_ds,
test_ds,
loss_type=tloss,
label="weak2strong",
subpath=os.path.join(
"strong_model_transfer",
f"{weak_model_size.replace('/','_')}_{strong_model_size.replace('/','_')}_{tloss}",
),
lr=transfer_lr,
eval_batch_size=strong_eval_batch_size,
epochs=transfer_epochs,
linear_probe=linear_probe,
optimizer_name=transfer_optim,
)
all_transfer_test_results[tloss]=transfer_test_results
deltransfer_test_results
復刻版本,并非源碼
OpenAI在倉庫中提到,目前開源的代碼并非與論文實驗部分完全一致,不過是結果相近的。
"STATUS: This codebase is not well tested and does not use the exact same settings we used in the paper, but in our experience gives qualitatively similar results when using large model size gaps and multiple seeds. Expected results can be found for two datasets below. We may update the code significantly in the coming week."
這次開源的weak-to-strong實現代碼較為簡單,感興趣的朋友可以去嘗試一下,結合論文也許會有不一樣的感受。OpenAI正在大力研究超級對齊(Superalignment),不僅僅放出論文,開源代碼,同時也宣布了一項高達1000萬美金的資助計劃,我們將在之后的文章中為您帶來詳細解讀,敬請期待!
-
開源
+關注
關注
3文章
3309瀏覽量
42471 -
模型
+關注
關注
1文章
3226瀏覽量
48807 -
OpenAI
+關注
關注
9文章
1079瀏覽量
6481
原文標題:OpenAI開源"weak-to-strong"方法代碼框架!我們帶你一探究竟
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
__attribute__((weak)) __weak_symbol在idf4.4庫中無效的原因?
在Fast-Strong情況下是否會出現過多的過沖
keil中__weak的功能和應用是什么
__attribute__((weak)) __weak_symbol在idf4.4庫中無效,要怎么操作才能起作用呢?
目標跟蹤的視覺注意計算模型
【MCU】Keil編譯無法識別__WEAK問題

keil中__weak的功能和應用
輕量級視覺模型設計的新啟發
OpenCV中支持的非分類與檢測視覺模型
基于可變形卷積的大規模視覺基礎模型
Strong ARM比較器電路的工作原理





 工商網監
工商網監
評論