 深入淺出Yolov3和Yolov4
深入淺出Yolov3和Yolov4
因為工作原因,項目中經常遇到目標檢測的任務,因此對目標檢測算法會經常使用和關注,比如Yolov3、Yolov4算法。
當然,實際項目中很多的第一步,也都是先進行目標檢測任務,比如人臉識別、多目標追蹤、REID、客流統計等項目。因此目標檢測是計算機視覺項目中非常重要的一部分。
從2018年Yolov3年提出的兩年后,在原作者聲名放棄更新Yolo算法后,俄羅斯的Alexey大神扛起了Yolov4的大旗。
在此,大白將項目中,需要了解的Yolov3、Yolov4系列相關知識點以及相關代碼進行完整的匯總,希望和大家共同學習探討。
1.論文匯總
Yolov3論文名:《Yolov3: An Incremental Improvement》 Yolov3論文地址:arxiv.org/pdf/1804.0276 Yolov4論文名:《Yolov4: Optimal Speed and Accuracy of Object Detection》 Yolov4論文地址:arxiv.org/pdf/2004.1093
2.YoloV3核心基礎內容
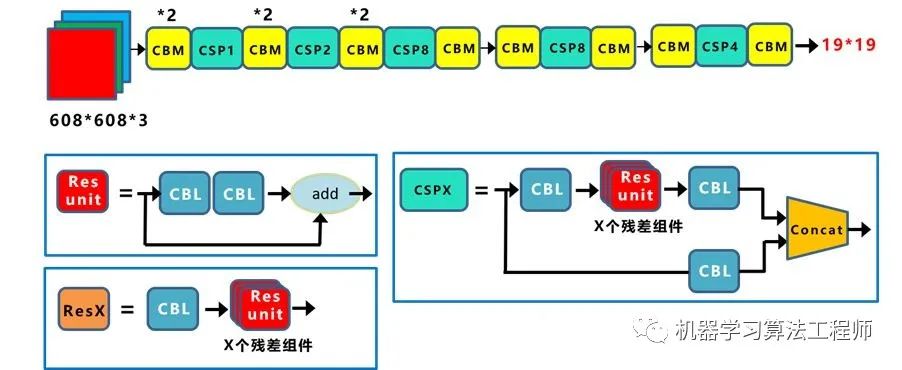
2.1 網絡結構可視化
Yolov3是目標檢測Yolo系列非常非常經典的算法,不過很多同學拿到Yolov3或者Yolov4的cfg文件時,并不知道如何直觀的可視化查看網絡結構。如果純粹看cfg里面的內容,肯定會一臉懵逼。 其實可以很方便的用netron查看Yolov3的網絡結構圖,一目了然。 這里不多說,如果需要安裝,可以移步大白的另一篇文章:《網絡可視化工具netron詳細安裝流程》。 如果不想安裝,也可以直接點擊此鏈接,查看Yolov3可視化流程圖。
2.2 網絡結構圖
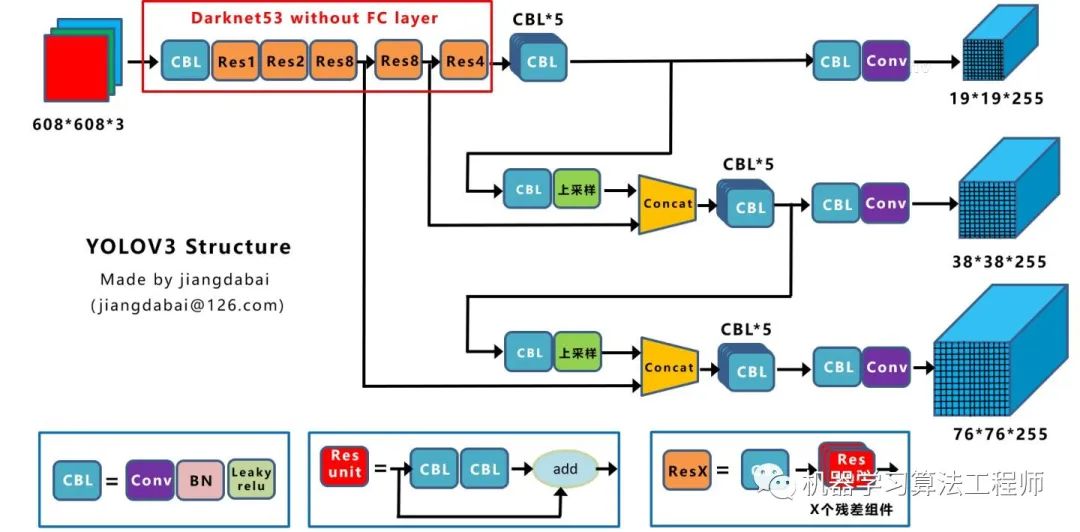
繪制網絡結構圖受到Yolov3另一位作者文章的啟發,包括下面Yolov4的結構圖,確實,從總體框架上先了解了Yolov3的流程,再針對去學習每一小塊的知識點,會事半功倍。 上圖三個藍色方框內表示Yolov3的三個基本組件:
CBL:Yolov3網絡結構中的最小組件,由Conv+Bn+Leaky_relu激活函數三者組成。
Res unit:借鑒Resnet網絡中的殘差結構,讓網絡可以構建的更深。
ResX:由一個CBL和X個殘差組件構成,是Yolov3中的大組件。每個Res模塊前面的CBL都起到下采樣的作用,因此經過5次Res模塊后,得到的特征圖是608->304->152->76->38->19大小。
其他基礎操作:
Concat:張量拼接,會擴充兩個張量的維度,例如26*26*256和26*26*512兩個張量拼接,結果是26*26*768。Concat和cfg文件中的route功能一樣。
add:張量相加,張量直接相加,不會擴充維度,例如104*104*128和104*104*128相加,結果還是104*104*128。add和cfg文件中的shortcut功能一樣。
Backbone中卷積層的數量: 每個ResX中包含1+2*X個卷積層,因此整個主干網絡Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一個FC全連接層,即可以組成一個Darknet53分類網絡。不過在目標檢測Yolov3中,去掉FC層,不過為了方便稱呼,仍然把Yolov3的主干網絡叫做Darknet53結構。
2.3核心基礎內容
Yolov3是2018年發明提出的,這成為了目標檢測one-stage中非常經典的算法,包含Darknet-53網絡結構、anchor錨框、FPN等非常優秀的結構。 本文主要目的在于描述Yolov4和Yolov3算法的不同及創新之處,對Yolov3的基礎不過多描述。 不過大白也正在準備Yolov3算法非常淺顯易懂的基礎視頻課程,讓小白也能簡單清楚的了解Yolov3的整個過程及各個算法細節,制作好后會更新到此處,便于大家查看。 在準備課程過程中,大白搜集查看了網絡上幾乎所有的Yolov3資料,在此整理幾個非常不錯的文章及視頻,大家也可以點擊查看,學習相關知識。 (1)視頻:吳恩達目標檢測Yolo入門講解 https://www.bilibili.com/video/BV1N4411J7Y6?from=search&seid=18074481568368507115 (2)文章:Yolo系列之Yolov3【深度解析】 https://blog.csdn.net/leviopku/article/details/82660381 (3)文章:一文看懂Yolov3 https://blog.csdn.net/litt1e/article/details/88907542 相信大家看完,對于Yolov3的基礎知識點會有一定的了解。
3.YoloV3相關代碼
3.1 python代碼
代碼地址:https://github.com/ultralytics/Yolov3
3.2 C++代碼
這里推薦Yolov4作者的darknetAB代碼,代碼和原始作者代碼相比,進行了很多的優化,如需要運行Yolov3網絡,加載cfg時,使用Yolov3.cfg即可 代碼地址:https://github.com/AlexeyAB/darknet
3.3 python版本的Tensorrt代碼
除了算法研究外,實際項目中還需要將算法落地部署到工程上使用,比如GPU服務器使用時還需要對模型進行tensorrt加速。
(1)Tensort中的加速案例
強烈推薦tensort軟件中,自帶的Yolov3加速案例,路徑位于tensorrt解壓文件夾的TensortX/samples/python/Yolov3_onnx中 針對案例中的代碼,如果有不明白的,也可參照下方文章上的詳細說明: 代碼地址:https://www.cnblogs.com/shouhuxianjian/p/10550262.html
(2)Github上的tensorrt加速
除了tensorrt軟件中的代碼, github上也有其他作者的開源代碼 代碼地址:https://github.com/lewes6369/TensorRT-Yolov3
3.4C++版本的Tensorrt代碼
項目的工程部署上,如果使用C++版本進行Tensorrt加速,一方面可以參照Alexey的github代碼,另一方面也可以參照下面其他作者的開源代碼 代碼地址:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov3
4.YoloV4核心基礎內容
4.1 網絡結構可視化
Yolov4的網絡結構也可以使用netron工具查看,大白也是對照其展示的可視化流程圖繪制的下方網絡結構圖。 netron可視化顯示Yolov4網絡結構可以參照大白的另一篇文章:《netron可視化網絡結構詳細安裝流程》 如果不想安裝,也可以直接點擊此鏈接,查看Yolov4可視化流程圖。
4.2 網絡結構圖
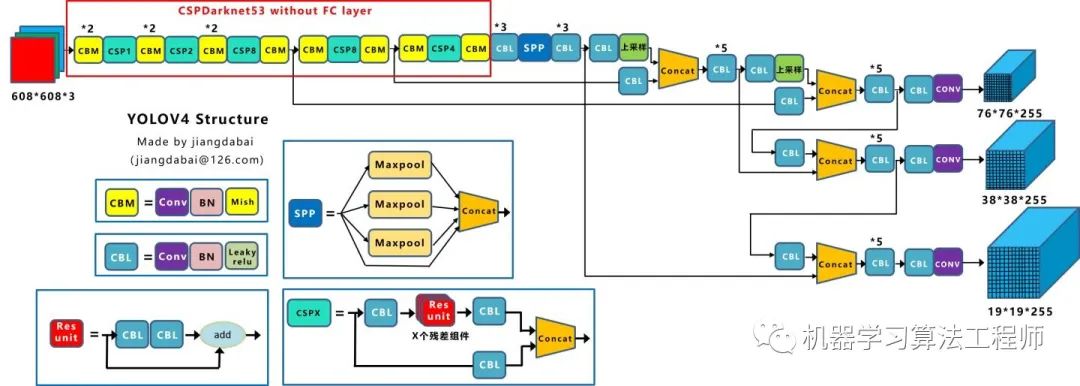
Yolov4的結構圖和Yolov3相比,因為多了CSP結構,PAN結構,如果單純看可視化流程圖,會覺得很繞,不過在繪制出上面的圖形后,會覺得豁然開朗,其實整體架構和Yolov3是相同的,不過使用各種新的算法思想對各個子結構都進行了改進。 先整理下Yolov4的五個基本組件:
CBM:Yolov4網絡結構中的最小組件,由Conv+Bn+Mish激活函數三者組成。
CBL:由Conv+Bn+Leaky_relu激活函數三者組成。
Res unit:借鑒Resnet網絡中的殘差結構,讓網絡可以構建的更深。
CSPX:借鑒CSPNet網絡結構,由三個卷積層和X個Res unint模塊Concate組成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,進行多尺度融合。
其他基礎操作:
Concat:張量拼接,維度會擴充,和Yolov3中的解釋一樣,對應于cfg文件中的route操作。
add:張量相加,不會擴充維度,對應于cfg文件中的shortcut操作。
Backbone中卷積層的數量: 和Yolov3一樣,再來數一下Backbone里面的卷積層數量。 每個CSPX中包含3+2*X個卷積層,因此整個主干網絡Backbone中一共包含2+(3+2*1)+2+(3+2*2)+2+(3+2*8)+2+(3+2*8)+2+(3+2*4)+1=72。 這里大白有些疑惑,按照Yolov3設計的傳統,這么多卷積層,主干網絡不應該叫CSPDaeknet73嗎????
4.3 核心基礎內容
Yolov4本質上和Yolov3相差不大,可能有些人會覺得失望。 但我覺得算法創新分為三種方式:
第一種:面目一新的創新,比如Yolov1、Faster-RCNN、Centernet等,開創出新的算法領域,不過這種也是最難的
第二種:守正出奇的創新,比如將圖像金字塔改進為特征金字塔
第三種:各種先進算法集成的創新,比如不同領域發表的最新論文的tricks,集成到自己的算法中,卻發現有出乎意料的改進
Yolov4既有第二種也有第三種創新,組合嘗試了大量深度學習領域最新論文的20多項研究成果,而且不得不佩服的是作者Alexey在github代碼庫維護的頻繁程度。 目前Yolov4代碼的star數量已經1萬多,據我所了解,目前超過這個數量的,目標檢測領域只有Facebook的Detectron(v1-v2)、和Yolo(v1-v3)官方代碼庫(已停止更新)。 所以Yolov4中的各種創新方式,大白覺得還是很值得仔細研究的。 為了便于分析,將Yolov4的整體結構拆分成四大板塊:
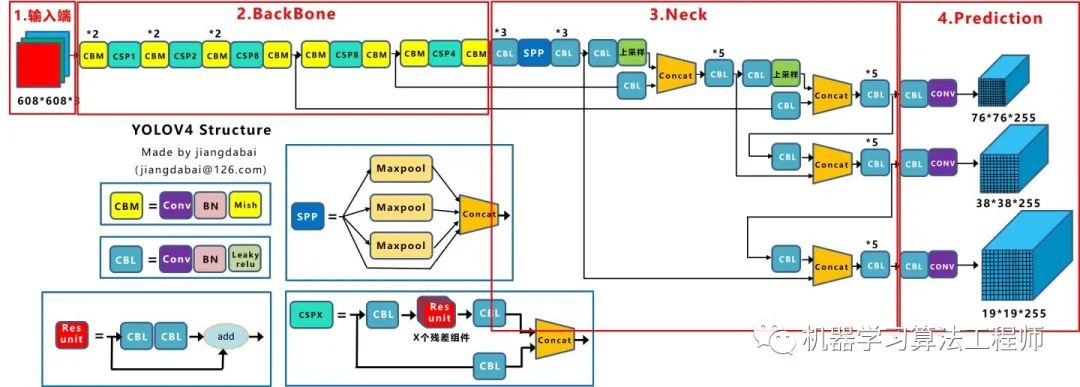
大白主要從以上4個部分對YoloV4的創新之處進行講解,讓大家一目了然。
輸入端:這里指的創新主要是訓練時對輸入端的改進,主要包括Mosaic數據增強、cmBN、SAT自對抗訓練
BackBone主干網絡:將各種新的方式結合起來,包括:CSPDarknet53、Mish激活函數、Dropblock
Neck:目標檢測網絡在BackBone和最后的輸出層之間往往會插入一些層,比如Yolov4中的SPP模塊、FPN+PAN結構
Prediction:輸出層的錨框機制和Yolov3相同,主要改進的是訓練時的損失函數CIOU_Loss,以及預測框篩選的nms變為DIOU_nms
總體來說,Yolov4對Yolov3的各個部分都進行了改進優化,下面丟上作者的算法對比圖。
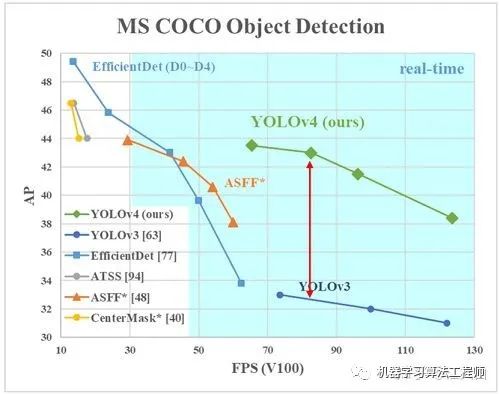
僅對比Yolov3和Yolov4,在COCO數據集上,同樣的FPS等于83左右時,Yolov4的AP是43,而Yolov3是33,直接上漲了10個百分點。 不得不服,當然可能針對具體不同的數據集效果也不一樣,但總體來說,改進效果是很優秀的,下面大白對Yolov4的各個創新點繼續進行深挖。
4.3.1 輸入端創新
考慮到很多同學GPU顯卡數量并不是很多,Yolov4對訓練時的輸入端進行改進,使得訓練在單張GPU上也能有不錯的成績。比如數據增強Mosaic、cmBN、SAT自對抗訓練。 但感覺cmBN和SAT影響并不是很大,所以這里主要講解Mosaic數據增強。
(1)Mosaic數據增強
Yolov4中使用的Mosaic是參考2019年底提出的CutMix數據增強的方式,但CutMix只使用了兩張圖片進行拼接,而Mosaic數據增強則采用了4張圖片,隨機縮放、隨機裁剪、隨機排布的方式進行拼接。
這里首先要了解為什么要進行Mosaic數據增強呢? 在平時項目訓練時,小目標的AP一般比中目標和大目標低很多。而Coco數據集中也包含大量的小目標,但比較麻煩的是小目標的分布并不均勻。 首先看下小、中、大目標的定義:
2019年發布的論文《Augmentation for small object detection》對此進行了區分:
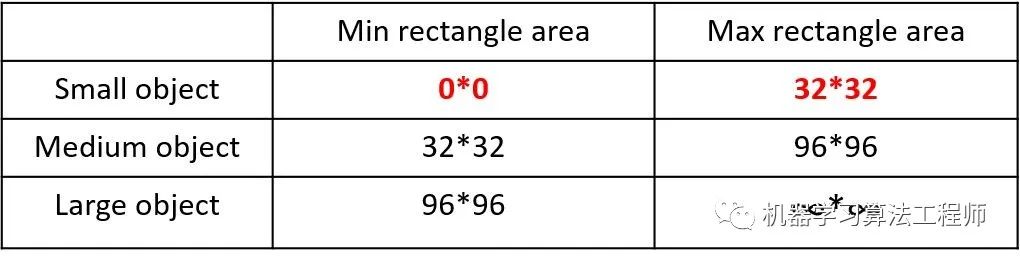
可以看到小目標的定義是目標框的長寬0×0~32×32之間的物體。

但在整體的數據集中,小、中、大目標的占比并不均衡。
如上表所示,Coco數據集中小目標占比達到41.4%,數量比中目標和大目標都要多。 但在所有的訓練集圖片中,只有52.3%的圖片有小目標,而中目標和大目標的分布相對來說更加均勻一些。 針對這種狀況,Yolov4的作者采用了Mosaic數據增強的方式。 主要有幾個優點:
豐富數據集:隨機使用4張圖片,隨機縮放,再隨機分布進行拼接,大大豐富了檢測數據集,特別是隨機縮放增加了很多小目標,讓網絡的魯棒性更好。
減少GPU:可能會有人說,隨機縮放,普通的數據增強也可以做,但作者考慮到很多人可能只有一個GPU,因此Mosaic增強訓練時,可以直接計算4張圖片的數據,使得Mini-batch大小并不需要很大,一個GPU就可以達到比較好的效果。
此外,發現另一研究者的訓練方式也值得借鑒,采用的數據增強和Mosaic比較類似,也是使用4張圖片(不是隨機分布),但訓練計算loss時,采用“缺啥補啥”的思路: 如果上一個iteration中,小物體產生的loss不足(比如小于某一個閾值),則下一個iteration就用拼接圖;否則就用正常圖片訓練,也很有意思。 參考鏈接:https://www.zhihu.com/question/390191723?rf=390194081
4.3.2 BackBone創新
(1)CSPDarknet53
CSPDarknet53是在Yolov3主干網絡Darknet53的基礎上,借鑒2019年CSPNet的經驗,產生的Backbone結構,其中包含了5個CSP模塊。
這里因為CSP模塊比較長,不放到本處,大家也可以點擊Yolov4的netron網絡結構圖,對比查看,一目了然。 每個CSP模塊前面的卷積核的大小都是3*3,因此可以起到下采樣的作用。 因為Backbone有5個CSP模塊,輸入圖像是608*608,所以特征圖變化的規律是:608->304->152->76->38->19 經過5次CSP模塊后得到19*19大小的特征圖。 而且作者只在Backbone中采用了Mish激活函數,網絡后面仍然采用Leaky_relu激活函數。 我們再看看下作者為啥要參考2019年的CSPNet,采用CSP模塊? CSPNet論文地址:arxiv.org/pdf/1911.1192 CSPNet全稱是Cross Stage Paritial Network,主要從網絡結構設計的角度解決推理中從計算量很大的問題。 CSPNet的作者認為推理計算過高的問題是由于網絡優化中的梯度信息重復導致的。 因此采用CSP模塊先將基礎層的特征映射劃分為兩部分,然后通過跨階段層次結構將它們合并,在減少了計算量的同時可以保證準確率。 因此Yolov4在主干網絡Backbone采用CSPDarknet53網絡結構,主要有三個方面的優點: 優點一:增強CNN的學習能力,使得在輕量化的同時保持準確性。 優點二:降低計算瓶頸 優點三:降低內存成本
(2)Mish激活函數
Mish激活函數是2019年下半年提出的激活函數 論文地址:arxiv.org/abs/1908.0868 和Leaky_relu激活函數的圖形對比如下:
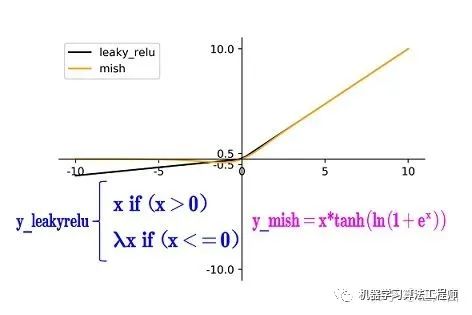
Yolov4的Backbone中都使用了Mish激活函數,而后面的網絡則還是使用leaky_relu函數。

Yolov4作者實驗測試時,使用CSPDarknet53網絡在ImageNet數據集上做圖像分類任務,發現使用了Mish激活函數的TOP-1和TOP-5的精度比沒有使用時都略高一些。 因此在設計Yolov4目標檢測任務時,主干網絡Backbone還是使用Mish激活函數。
(3)Dropblock
Yolov4中使用的Dropblock,其實和常見網絡中的Dropout功能類似,也是緩解過擬合的一種正則化方式。 Dropblock在2018年提出,論文地址:arxiv.org/pdf/1810.1289 傳統的Dropout很簡單,一句話就可以說的清:隨機刪除減少神經元的數量,使網絡變得更簡單。
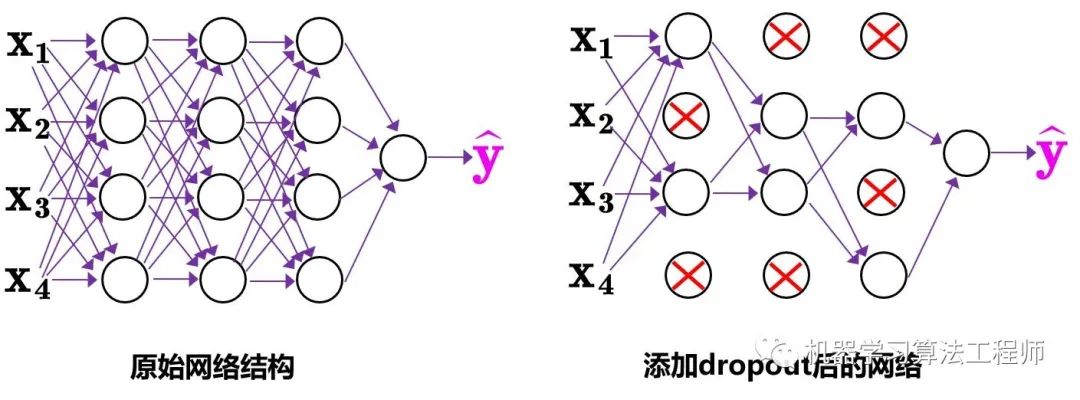
中間Dropout的方式會隨機的刪減丟棄一些信息,但Dropblock的研究者認為,卷積層對于這種隨機丟棄并不敏感,因為卷積層通常是三層連用:卷積+激活+池化層,池化層本身就是對相鄰單元起作用。而且即使隨機丟棄,卷積層仍然可以從相鄰的激活單元學習到相同的信息。 因此,在全連接層上效果很好的Dropout在卷積層上效果并不好。 所以右圖Dropblock的研究者則干脆整個局部區域進行刪減丟棄。 這種方式其實是借鑒2017年的cutout數據增強的方式,cutout是將輸入圖像的部分區域清零,而Dropblock則是將Cutout應用到每一個特征圖。而且并不是用固定的歸零比率,而是在訓練時以一個小的比率開始,隨著訓練過程線性的增加這個比率。
Dropblock的研究者與Cutout進行對比驗證時,發現有幾個特點: 優點一:Dropblock的效果優于Cutout 優點二:Cutout只能作用于輸入層,而Dropblock則是將Cutout應用到網絡中的每一個特征圖上 優點三:Dropblock可以定制各種組合,在訓練的不同階段可以修改刪減的概率,從空間層面和時間層面,和Cutout相比都有更精細的改進。 Yolov4中直接采用了更優的Dropblock,對網絡的正則化過程進行了全面的升級改進。
4.3.3 Neck創新
在目標檢測領域,為了更好的提取融合特征,通常在Backbone和輸出層,會插入一些層,這個部分稱為Neck。相當于目標檢測網絡的頸部,也是非常關鍵的。 Yolov4的Neck結構主要采用了SPP模塊、FPN+PAN的方式。
(1)SPP模塊
SPP模塊,其實在Yolov3中已經存在了,在Yolov4的C++代碼文件夾中有一個Yolov3_spp版本,但有的同學估計從來沒有使用過,在Yolov4中,SPP模塊仍然是在Backbone主干網絡之后:
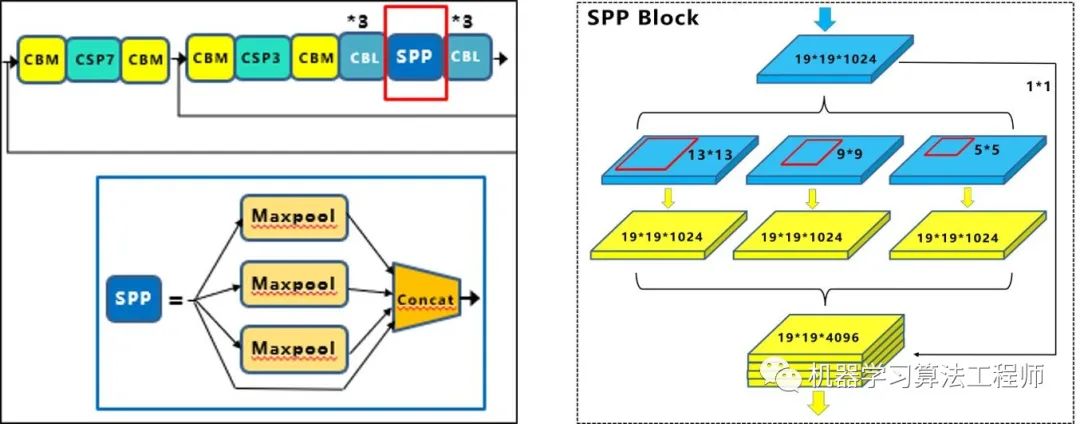
作者在SPP模塊中,使用k={1*1,5*5,9*9,13*13}的最大池化的方式,再將不同尺度的特征圖進行Concat操作。
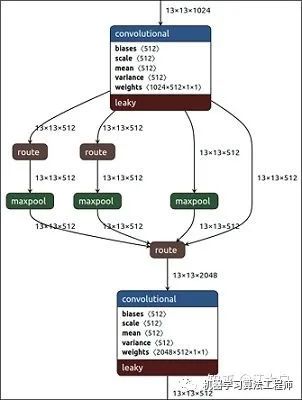
在《DC-SPP-Yolo》文章: 也對Yolo目標檢測的SPP模塊進行了對比測試。 和Yolov4作者的研究相同,采用SPP模塊的方式,比單純的使用k*k最大池化的方式,更有效的增加主干特征的接收范圍,顯著的分離了最重要的上下文特征。 Yolov4的作者在使用608*608大小的圖像進行測試時發現,在COCO目標檢測任務中,以0.5%的額外計算代價將AP50增加了2.7%,因此Yolov4中也采用了SPP模塊。
(2)FPN+PAN
PAN結構比較有意思,看了網上Yolov4關于這個部分的講解,大多都是講的比較籠統的,而PAN是借鑒圖像分割領域PANet的創新點,有些同學可能不是很清楚。 下面大白將這個部分拆解開來,看下Yolov4中是如何設計的。 Yolov3結構: 我們先來看下Yolov3中Neck的FPN結構
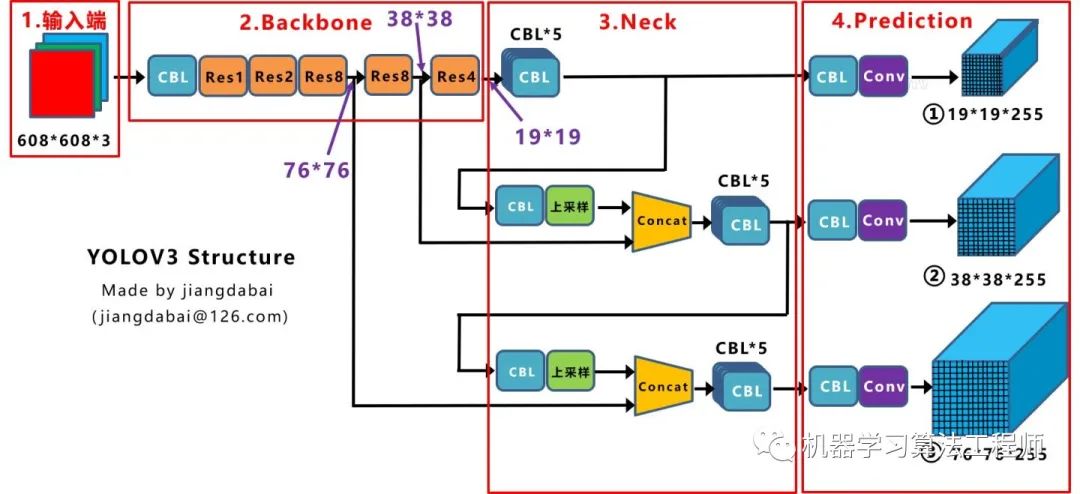
可以看到經過幾次下采樣,三個紫色箭頭指向的地方,輸出分別是76*76、38*38、19*19。 以及最后的Prediction中用于預測的三個特征圖①19*19*255、②38*38*255、③76*76*255。 我們將Neck部分用立體圖畫出來,更直觀的看下兩部分之間是如何通過FPN結構融合的。
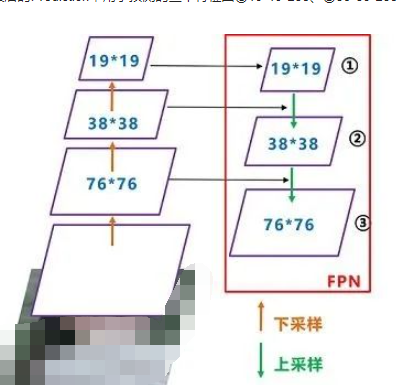
如圖所示,FPN是自頂向下的,將高層的特征信息通過上采樣的方式進行傳遞融合,得到進行預測的特征圖。 Yolov4結構: 而Yolov4中Neck這部分除了使用FPN外,還在此基礎上使用了PAN結構:
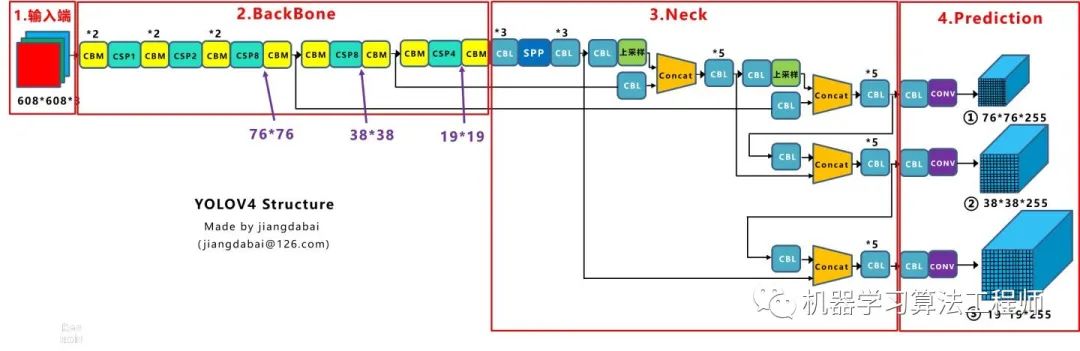
前面CSPDarknet53中講到,每個CSP模塊前面的卷積核都是3*3大小,相當于下采樣操作。 因此可以看到三個紫色箭頭處的特征圖是76*76、38*38、19*19。 以及最后Prediction中用于預測的三個特征圖:①76*76*255,②38*38*255,③19*19*255。 我們也看下Neck部分的立體圖像,看下兩部分是如何通過FPN+PAN結構進行融合的。
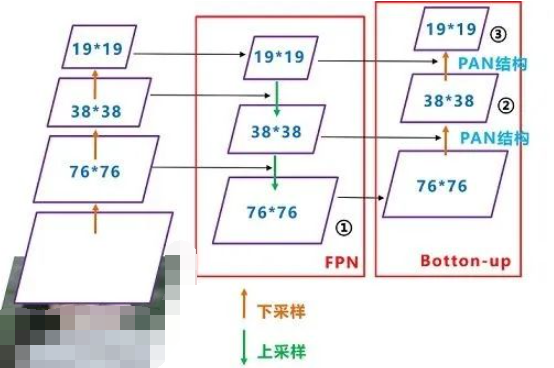
和Yolov3的FPN層不同,Yolov4在FPN層的后面還添加了一個自底向上的特征金字塔。 其中包含兩個PAN結構。 這樣結合操作,FPN層自頂向下傳達強語義特征,而特征金字塔則自底向上傳達強定位特征,兩兩聯手,從不同的主干層對不同的檢測層進行參數聚合,這樣的操作確實很皮。 FPN+PAN借鑒的是18年CVPR的PANet,當時主要應用于圖像分割領域,但Alexey將其拆分應用到Yolov4中,進一步提高特征提取的能力。 不過這里需要注意幾點: 注意一: Yolov3的FPN層輸出的三個大小不一的特征圖①②③直接進行預測 但Yolov4的FPN層,只使用最后的一個76*76特征圖①,而經過兩次PAN結構,輸出預測的特征圖②和③。 這里的不同也體現在cfg文件中,這一點有很多同學之前不太明白, 比如Yolov3.cfg最后的三個Yolo層, 第一個Yolo層是最小的特征圖19*19,mask=6,7,8,對應最大的anchor box。 第二個Yolo層是中等的特征圖38*38,mask=3,4,5,對應中等的anchor box。 第三個Yolo層是最大的特征圖76*76,mask=0,1,2,對應最小的anchor box。 而Yolov4.cfg則恰恰相反 第一個Yolo層是最大的特征圖76*76,mask=0,1,2,對應最小的anchor box。 第二個Yolo層是中等的特征圖38*38,mask=3,4,5,對應中等的anchor box。 第三個Yolo層是最小的特征圖19*19,mask=6,7,8,對應最大的anchor box。 注意點二: 原本的PANet網絡的PAN結構中,兩個特征圖結合是采用shortcut操作,而Yolov4中則采用concat(route)操作,特征圖融合后的尺寸發生了變化。
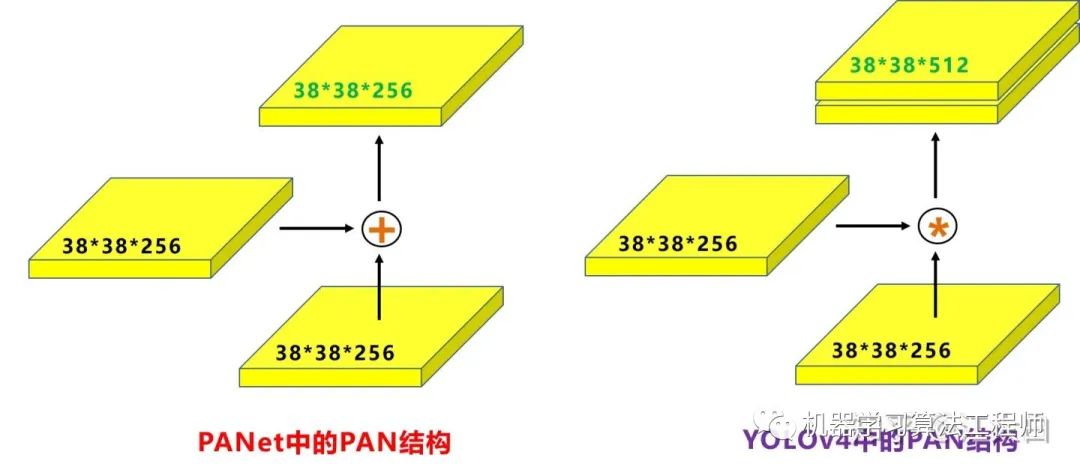
這里也可以對應Yolov4的netron網絡圖查看,很有意思。
5.YoloV4相關代碼
5.1 python代碼
代碼地址:https://github.com/Tianxiaomo/pytorch-Yolov4 作者的訓練和測試推理代碼都已經完成
5.2 C++代碼
Yolov4作者Alexey的代碼,俄羅斯的大神,應該是個獨立研究員,更新算法的頻繁程度令人佩服。 在Yolov3作者Joseph Redmon宣布停止更新Yolo算法之后,Alexey憑借對于Yolov3算法的不斷探索研究,贏得了Yolov3作者的認可,發布了Yolov4。 代碼地址:https://github.com/AlexeyAB/darknet
5.3 python版本的Tensorrt代碼
目前測試有效的有tensorflow版本:weights->pb->trt 代碼地址:https://github.com/hunglc007/tensorflow-Yolov4-tflite
5.4 C++版本的Tensorrtrt代碼
代碼地址:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov4 作者自定義了mish激活函數的plugin層,Tensorrt加速后速度還是挺快的。
6.相關數據集下載
項目中,目標檢測算法應該的非常多非常多,比如人臉識別,比如疫情期間的口罩人臉識別,比如車流統計,人流統計等等。 因此大白也會將不錯的值得一試的目標檢測數據集匯總到此處,方便需要的同學進行下載。
6.1 口罩遮擋人臉數據集
數據集詳情:由武漢大學多媒體研究中心發起,目前是全球最大的口罩遮擋人臉數據集。 分為真實口罩人臉和模擬口罩人臉兩部分,真實口罩人臉包含525人的5000張口罩人臉和9萬張正常人臉。模擬口罩人臉包含1萬個人共50萬張模擬人臉數據集。 應用項目:人臉檢測、人臉識別 數據集地址:https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset
6.2 Wider Face人臉數據集
數據集詳情:香港中文大學發起的,包含3萬張圖片共40萬張人臉。 應用項目:人臉檢測 數據集地址:http://shuoyang1213.me/WIDERFACE/WiderFace_Results.html
6.3 Wider Person擁擠場景行人數據集
數據集詳情:多種場景比較擁擠場景的行人檢測數據集,包含13382張圖片,共計40萬個不同遮擋程度的人體。 應用項目:人體檢測 數據集地址:http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/ 因為工作原因,會搜集大量的各類公開應用場景數據集,如果有同學需要其他場景或者其他項目的,也可以留言,或者發送郵件到jiangdabai@126.com,也會將對應的數據集更新到此處。
7.不斷更新ing
在深度學習的圖像領域,肯定會涉及目標檢測,而在目標檢測中,Yolov3是非常經典,必須要學習的算法,有些同學,特別新接觸的同學,剛學習時會覺得yolo算法很繁瑣。 但我發現,網上很多的教程其實講的還是比較籠統,并不適合小白學習。 所以大白也在耗盡洪荒之力,在準備Yolov3和Yolov4及相關的基礎入門視頻,讓大家看完就能明白整體的流程和各種算法細節,大家可以先收藏,后期制作好后會更新到此處。 希望和大家一起努力,在人工智能深度學習領域一起進步,一起提升,一起變強!
審核編輯:黃飛
-
算法
+關注
關注
23文章
4607瀏覽量
92828 -
網絡結構
+關注
關注
0文章
48瀏覽量
11077 -
python
+關注
關注
56文章
4792瀏覽量
84627 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:深入淺出Yolov3和Yolov4
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于YOLOv3的紅綠燈檢測識別(Python源碼可直接運行)
labview調用yolo 目標檢測速度太慢?yolov4:速度和精度的完美結合,性能和精度碾壓yolov3
LabVIEW調用YoloV4類庫Demo
yolov3 GPU加速 AI 目標檢測
基于Tengine實現yolov4的cpu推理講解
基于Tengine實現yolov4的cpu推理

Yolov3&Yolov4核心基礎知識
Nvidia Jetson Nano面罩Yolov4探測器





 工商網監
工商網監
評論