


對于開發者而言,我們將整個ExecuTorch技術棧分為兩個階段。首先,我們從一個PyTorch模型開始,這在大多數情況下是一個torch.in.module。然后我們從中捕獲圖形,并將其lowering并序列化為額外的torch二進制文件。這完成了我們的提前編譯階段。然后我們將二進制文件放入device并使用ExecuTorch運行時來運行。
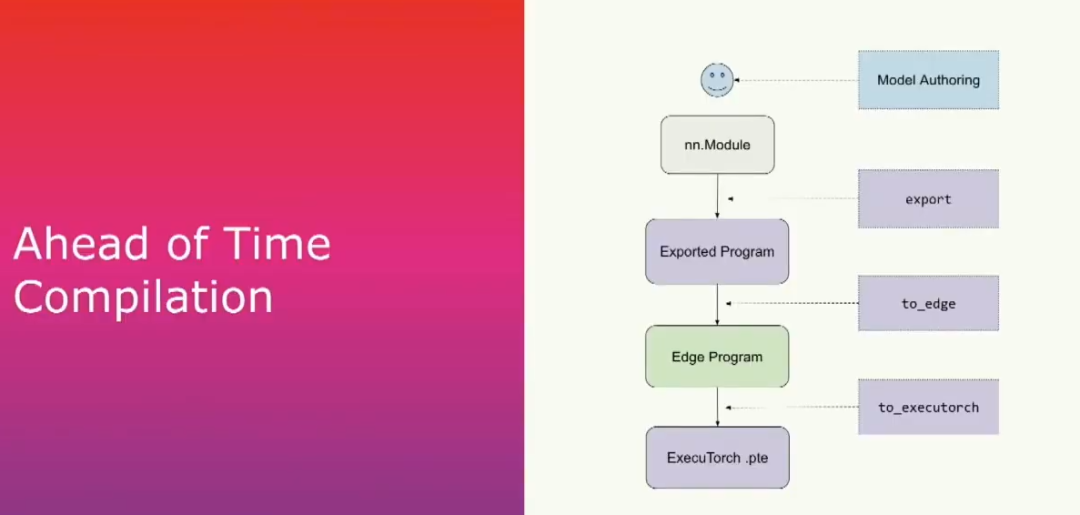
提前編譯主要有三個步驟。首先是導出(export),將給定的模型(如NN模塊或其他可調用對象)通過PyTorch2的torch export獲取計算圖。在這個模塊內部,我們要列出所有正在進行的操作的列表,并且這將產生一個exported program,我們將在以后更詳細地介紹它。
第二步是調用to edge,它將產生這個edge program,這是大多數執行器用戶運行優化和轉換的入口點。最后一步,我們將使用to_executorch來執行,它會將其變為一個擴展名為.pt的二進制文件。然后我們將把它傳遞給運行時。

所以更近一步,第一步是導出模型,在這一步中,我們將創建這個模型的圖形表示。這個圖形表示是一個fx圖形,你們中的一些人可能對此很熟悉,但它不包含任何Python語義,允許我們在沒有Python運行時的環境下運行。這個圖形只包含操作符調用。所以如果你熟悉fx圖,就沒有像調用模塊或調用方法那樣的東西。所以對我們來說,這是一個非常簡單的圖形。導出產生的結果是一個exported program,它與torch的NN模塊非常相似,

之后生成的graph,我們將其稱為Aten Dialect graph。因此,通過Dialect,我們指的是此exported program的變體,其由其操作符集和一些其他graph屬性定義。所以,通過Aten,我們指的是該圖表僅包含torch.ops.aten操作符。而且,這些操作符僅為functional操作符,意味著沒有副作用或突變。這涉及到約2000個左右的操作符。一些graph屬性是graph包含元數據,例如指向原始模型的原始堆棧跟蹤指針,還有graph內每個節點的輸出data類型和形狀。我們還可以通過這些特殊的高階操作符在特定輸入上表達動態性和控制流。如需了解更多信息,您可以在下午聽Torch Expert的演講。

對量化而言,量化實際上在導出的中間階段運行,因為它需要在更高級的opset上工作,這對于訓練等一般情況也更安全。因此,工作流程是我們首先導出到Pre-Autograd,此東西訓練是安全的,然后運行量化,然后降低到之前提到的Aten Dialect,然后傳遞到執行器 pipeline 的其余部分。因此,這個API看起來像是準備PT2E,用戶傳入一個量化器,然后轉換PT2E,然后將其傳遞給堆棧的其余部分。所以,量化器是特定于后端實現的東西,它告訴用戶在特定后端上可以量化什么以及如何對這些進行量化。它還公開了方法,允許用戶表達他們想要如何量化這個后端。

下一步是lower到Edge程序,這是Executorch用戶運行他們的目標不可知轉換的入口點。此時,我們正在處理這個Edge Dialect,其中只包含一組核心的aten運算符。大約只有180個運算符。因此,如果你是一個新的后端,正在嘗試實現Executorch,你只需要實現這180個運算符就可以運行大多數模型,而不是之前來自Aten類的大約2000個運算符。
此外,這個方言還具有數據類型的專門化,這將允許executorch根據特定的dtype類型構建內核,以實現更優化的運行時。我們還通過將所有標量轉換為張量來對輸入進行歸一化,從而使這些運算符內核不必隱式地進行這種歸一化。
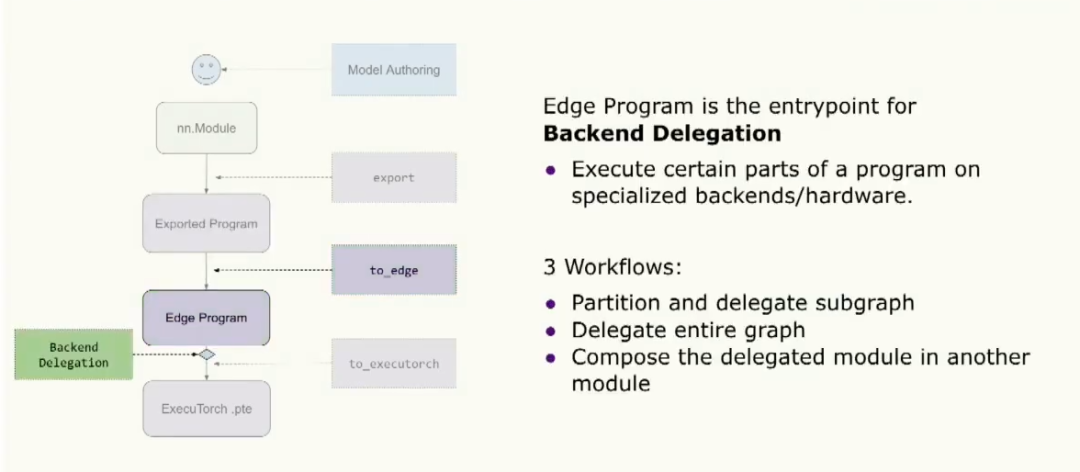
這個邊緣程序的另一個入口是backend delegation,在這里用戶可以選擇在專門的硬件或后端上優化和處理部分或全部程序。通過這種方式,他們可以利用這些專用硬件來處理graph的某些部分。對于此,有大約三種工作流程。第一種是分割和delegation graph的部分。或者我們可以delegation整個圖。或者我們可以做兩者的組合,將這個delegation模塊組合到更top的模塊中。
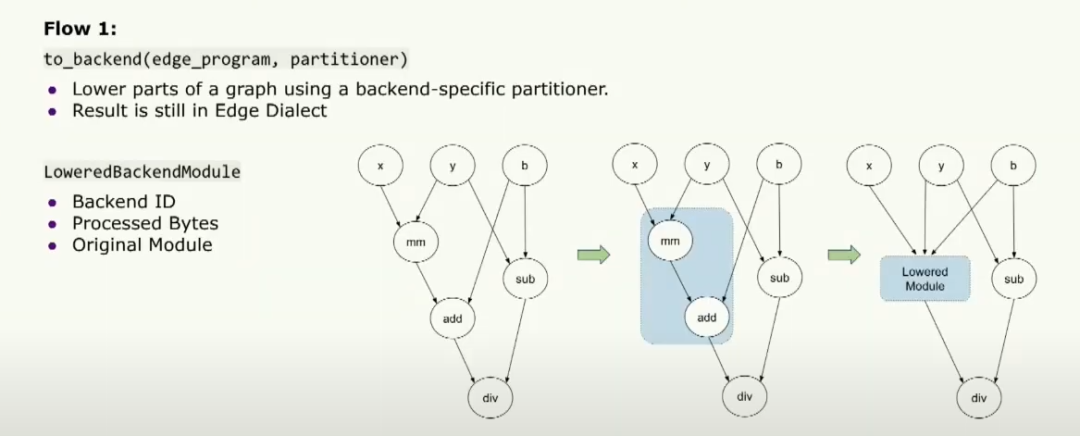
仔細看這一點,第一步是用戶可以傳遞一個特定于后端的patitioner,它將告訴用戶哪些操作符能在特定的后端上運行。然后,to_backend API 將根據這個分區器對圖進行分區,然后lower這些部分為一個較低層的后端模塊。然后將該模塊傳遞給運行時,以告訴后端需要運行的確切內容。它包含后端的ID,告訴我們正在運行的后端是哪個,并且包含一組處理過的片段,告訴專用硬件需要運行的內容。同時,它還包含用于調試目的的原始模塊。
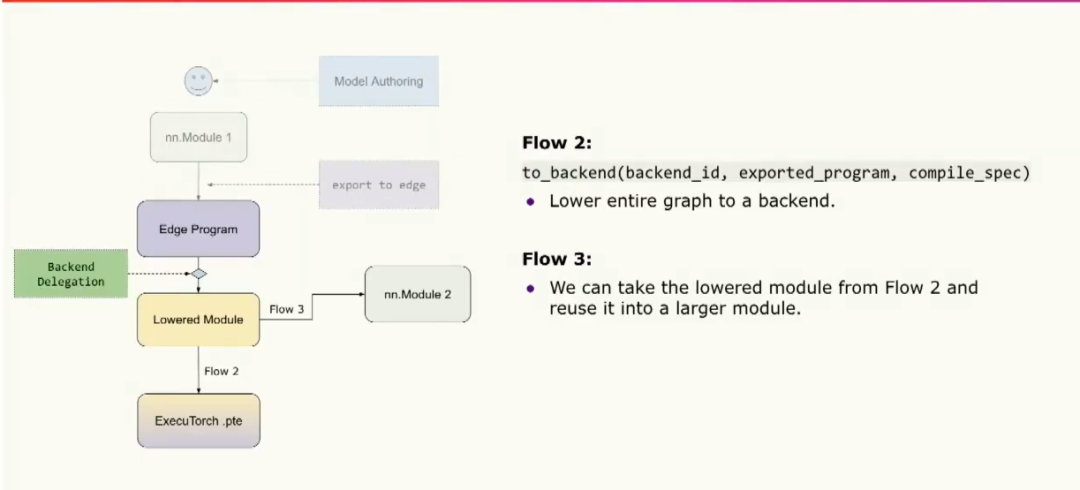
第二個流程是將整個graph lower到您的backend中,然后直接將其轉換為二進制文件,然后傳遞給運行時在專用硬件上運行。第三個流程是我們將完全delegation的模塊組合到其他模塊中,以便在其他地方重用。
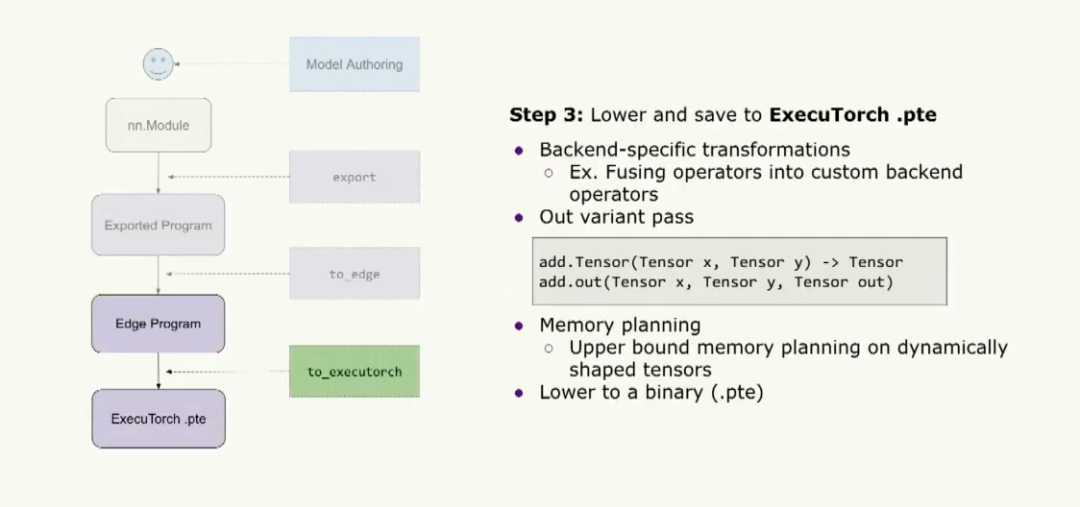
最后,我們可以將其轉換并保存為ExecuTorch二進制文件。因此,用戶可以開始運行特定于后端的轉換,例如將運算符融合到特定的自定義后端運算符中。然后,我們將提前運行自定義內存規劃過程,以確定此程序需要多少內存。為了準備graph執行此操作,我們首先將運行一個out variant pass,其目的是把所有運算符變成 out variant.這樣做可以使內存規劃變得更加容易,因為對于一個典型的算子(例如add.tensor),它會在內核中為輸出的張量分配內存。但是如果我們想要進行內存規劃,我們可以使用out variant ,它期望傳入一個預分配的張量,并在內核中將結果張量賦值給這個預分配的張量。因此,我們可以運行內存規劃,非常輕松地計算張量的生命周期,并提前確定這個程序需要多少內存,這樣我們就不需要在運行時動態地進行內存分配。最后,我們可以將它轉換為擴展名為.pte的二進制文件,并將其傳遞給運行時。
現在,孟煒將告訴我們運行時發生了什么。希望在完成所有這些步驟后,我們能夠得到一個.pte文件。我們準備深入探討運行時的過程。
到目前為止,我們假設開發人員能夠按照Angela介紹的所有步驟進行操作。希望就像打個響指,我們就能夠獲取Executorch的二進制文件。現在我們要考慮一些需求,比如我們該如何運行這個二進制文件。從開發者的角度來看,他們可能會問的第一個自然問題是:它真的能在我的目標設備上運行嗎?其中一些可能有CPU,或者一些可能有…甚至是微控制器。我們需要確保Executorch Runtime能夠在所有這些平臺上編譯和運行。
現在我們能夠在目標設備上編譯Executorch Runtime后,開發者可能會提出一個后續問題。我的目標設備有一個非常特殊的地方…它包含兩個內存緩沖區。一個速度非常快但很小,但另一個很慢但非常龐大。Executorch Runtime是否支持這種硬件配置呢?我認為這就是提出了我們的第二個需求,我們應該能夠支持開發者想要的定制性,支持我們的開發人員想要的所有自定義。
好了,現在Executorch程序能夠在目標設備上運行了。開發人員可能并不在意性能問題。請注意,設備上的AI處于資源受限的環境中。這意味著效率和性能至關重要。因此,我們需要確保Executorch Runtime具備高性能。因此,讓我向您介紹一些我們為滿足這些要求而所做的工作。

讓我們談談可移植性。我們如何滿足可移植性要求?目標設備包括不同的操作系統、不同的體系結構,甚至不同的工具鏈。我們解決所有這些要求的方法是隱藏系統級細節。我們通過提供一個平臺抽象層來實現。這一層提供了一組統一的API,用于基本功能,如日志記錄、時鐘,并抽象了許多平臺特定的實現細節。同樣,我們還提供了數據加載器和內存分配器。訪問Executorch runtime以與操作系統進行通信。最后但并非最不重要的是,我們確保我們的Executorch runtime遵循C++11標準,這是大多數工具鏈所接受的。
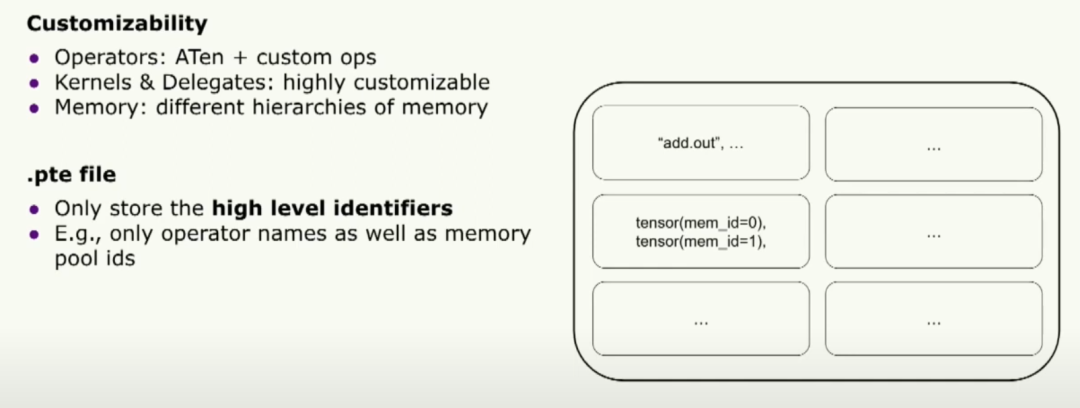
好的,接下來讓我們談談可定制性。Executorch 二進制文件是編譯和運行時之間的唯一橋梁。從這個意義上說,為了支持可定制性,我們必須設計二進制文件的架構。它只存儲高級標識符。我們只存儲運算符名稱和內存池ID,但對此沒有任何意見。實際上,它是在運行時上運行的內核。
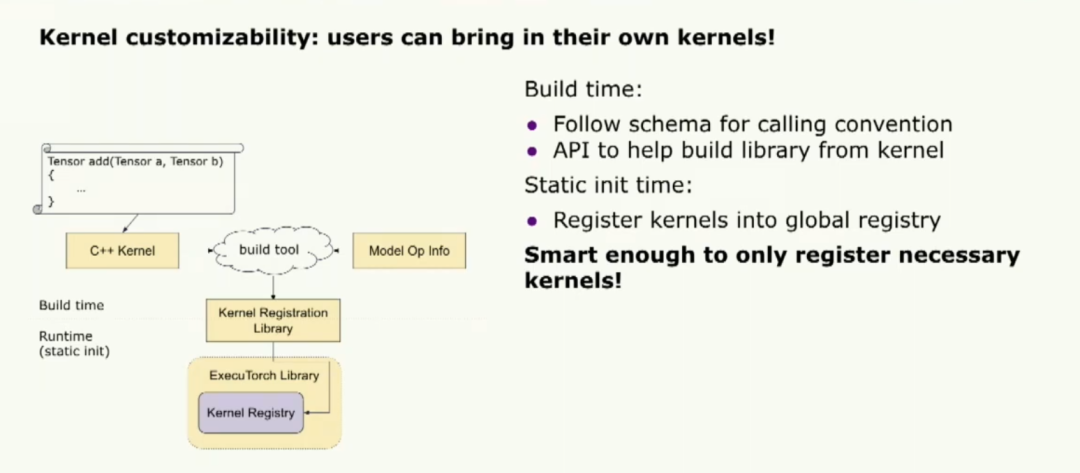
這樣,我們為定制開啟了很多機會。讓我們談談內核的可定制性。我想要強調的一件事是允許用戶帶入他們自己的內核。我們提供了一個內部的可移植內核庫。但它并不旨在優化性能。因此,我們允許用戶帶入他們自己的內核。注冊自定義內核的方法非常簡單,開發者只需要按照核心 aten 運算符的命名約定。然后,他們可以使用一個構建工具為它們的庫注冊內核。這個庫將幫助將他們的內核注冊到 Executorch 運行時中。
還有一件事我想提一下,如果開發者提供了模型級操作符信息,構建工具會智能地只注冊必要的信息,這樣我們可以縮小二進制文件的大小。
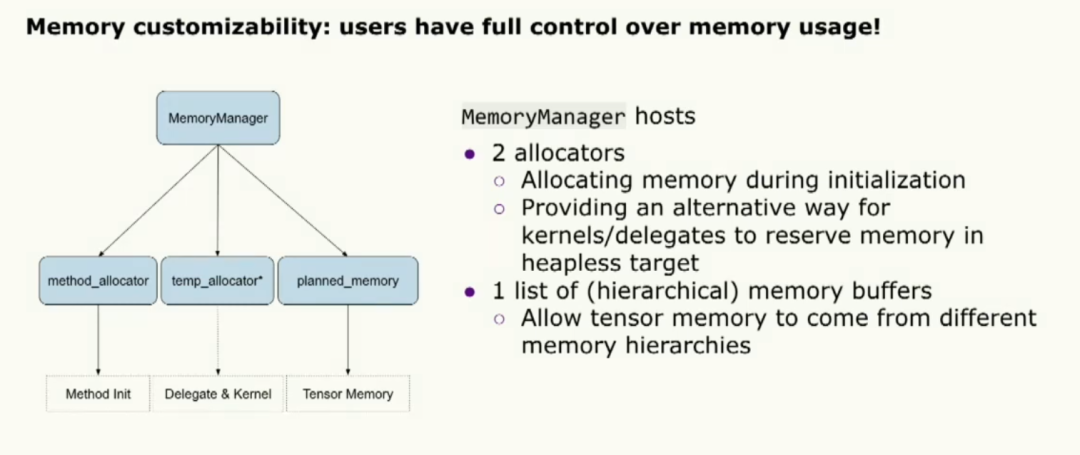
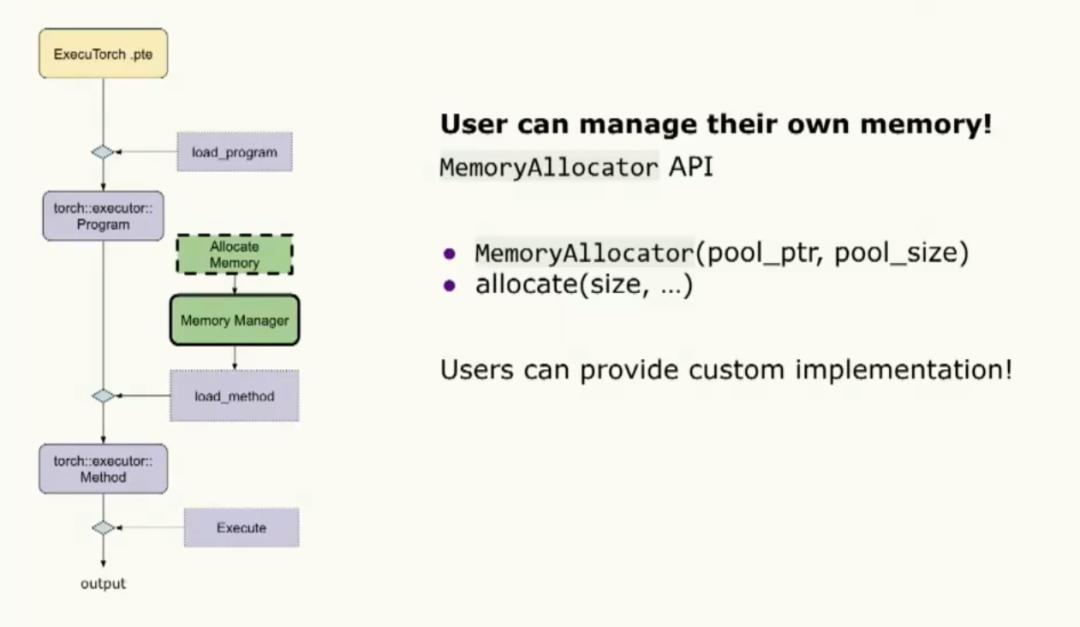
不同的環境對內存有非常特殊的需求,所以我們提供了名為MemoryManager的對象,允許用戶進行大量的自定義配置。內存管理器由兩個內存分配器組成。其中一個用于初始化過程,另一個用于內核和委托執行過程。除此之外,我們還為張量內存分配提供了一系列內存緩沖區。這樣就完成了定制功能。

現在讓我們稍微談談性能以及我們如何滿足性能需求。我們確保我們的Executorch Torch運行時在內核和委托調用之間的開銷非常低。這是通過在執行之前準備輸入和輸出張量來實現的。而用戶只需要付出一次代價,即使他們想多次運行該模型。我們確保ExecuteTorch運行時的第二個原則是保持一個非常小的二進制文件大小以及內存占用,這是通過將復雜邏輯和動態性推移到提前編譯器中來實現的,并確保Executorch運行時邏輯。
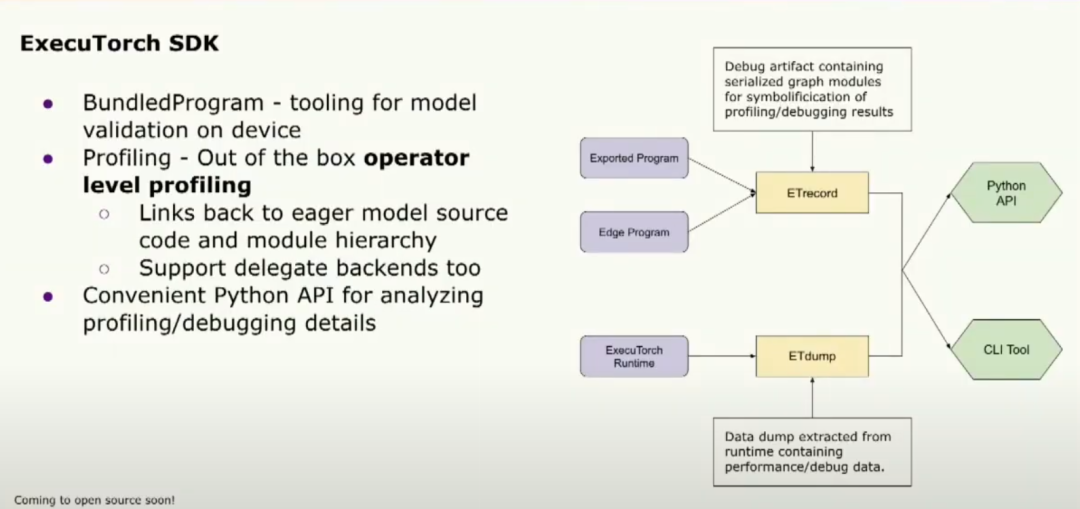
最后但并非最不重要的是,我們還提供了一套非常方便的性能調試工具,它在這個SDK中。讓我多談一點,我們提供了幾個非常有用的API。其中之一是捆綁程序,我們可以將示例輸入綁定到模型中。這樣就能實現非常快速的執行。我們還提供調試和分析工具。分析器能夠將統計數據連接到運算符上。為我們的程序確定瓶頸非常有幫助。所有這些都提供了Python API,以確保開發人員能夠輕松使用它們。我談了很多關于我們運行時的組件,但是我們如何將它們連接在一起并確保其正常工作呢?
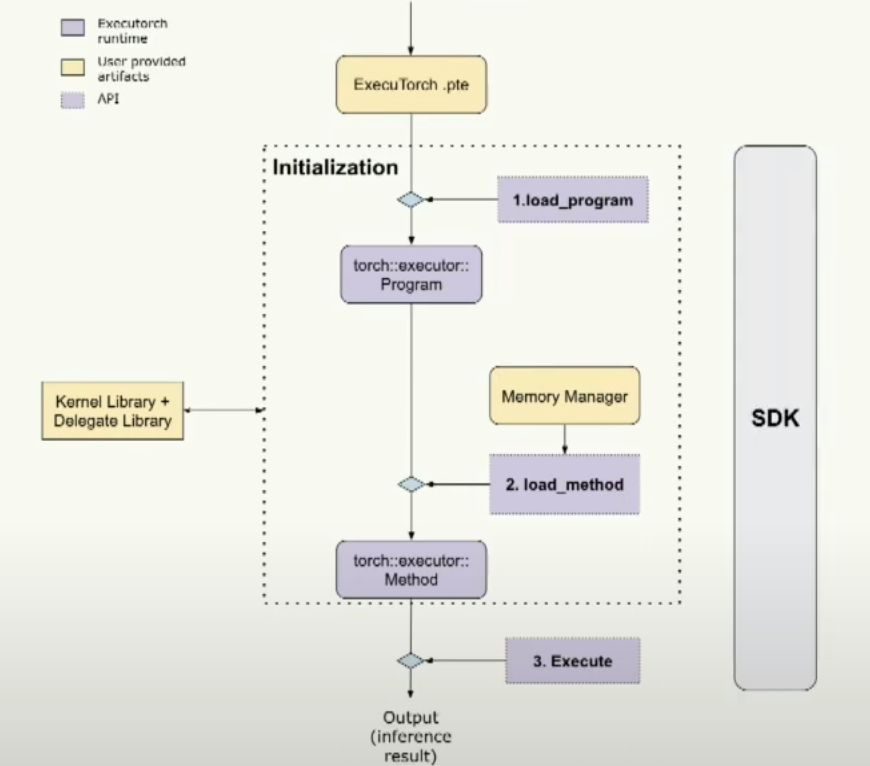
這是一個圖表。基本上,我們加載Executorch的.pte文件。然后我們進行一些初始化,包括加載程序和加載方法。最后,我們可以執行它。使用SDK工具來覆蓋整個流程,確保每一步都是正確的。

那么在初始化階段,我們在做什么呢?基本上,我們為PyTorch模型的概念創建了C++對象。如您所見,根抽象稱為program,類似于nn.module模塊。一個program可以有多個方法。一個方法可能具有多個操作符,即kernel對象。
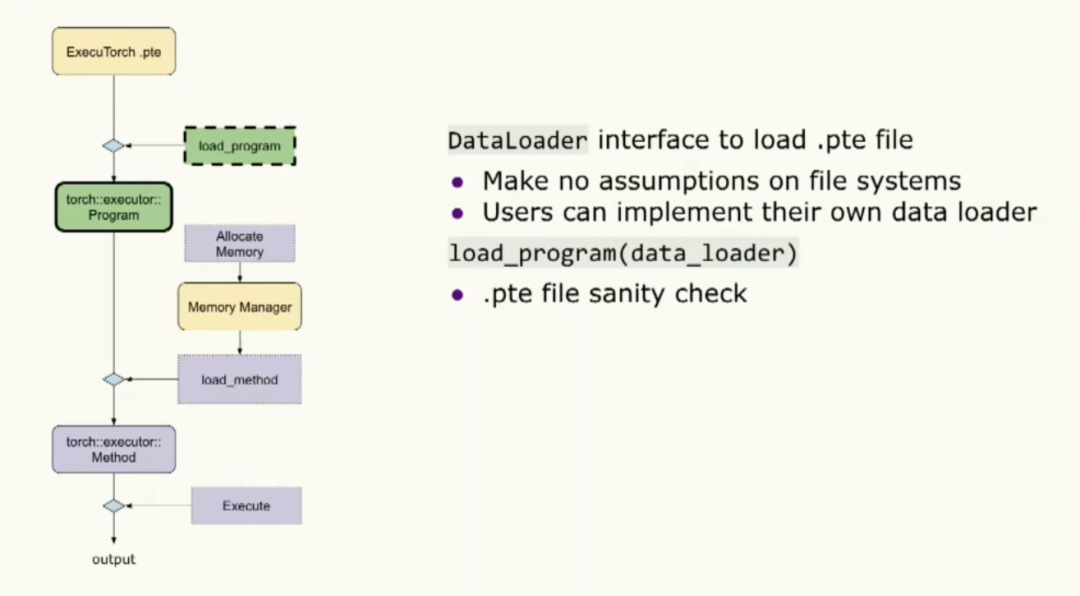
當我們加載程序時,實際上我們提供了數據加載器接口以便能夠加載二進制文件。請注意,我們對文件系統不做任何假設,所以用戶可以自由實現這個接口并在目標設備上加載程序。加載程序將使用該數據加載器進行二進制文件的合法性檢查。同時,用戶也可以在初始化階段提供內存管理器。我想要強調的一點是用戶可以管理自己的內存。
初始化的最后一步是調用加載方法,開發者需要提供他們想要執行的方法名稱,還有內存管理器。

最后進入到執行的階段:這是很簡單的循環遍歷所有指令,執行能夠通過跳轉到特定的指令來處理控制流,并且每個指令參數都是Evalue(wrap all arg types).我們可以把他 unboxex 到不同的基礎類型(tensor,scalar),我們還有一個內核運行時上下文可以處理一些事情。
你可以查看安卓和ios的演示,github教程可用。到此結束,謝謝。
審核編輯:劉清
-
二進制
+關注
關注
2文章
807瀏覽量
42350 -
可穿戴設備
+關注
關注
55文章
3847瀏覽量
168730 -
pytorch
+關注
關注
2文章
809瀏覽量
13989
原文標題:《PytorchConference2023 翻譯系列》15-PyTorch-Edge-在邊緣設備上部署AI模型的開發者之旅
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI模型部署邊緣設備的奇妙之旅:如何實現手寫數字識別
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
介紹在STM32cubeIDE上部署AI模型的系列教程
通過Cortex來非常方便的部署PyTorch模型
ST MCU邊緣AI開發者云 - STM32Cube.AI
將Pytorch模型轉換為DeepViewRT模型時出錯怎么解決?
【KV260視覺入門套件試用體驗】Vitis AI 構建開發環境,并使用inspector檢查模型
NVIDIA 舉辦 Jetson Edge AI 開發者大賽,建立開放的開發者社區


Arm推出GitHub平臺AI工具,簡化開發者AI應用開發部署流程
在設備上利用AI Edge Torch生成式API部署自定義大語言模型

打通邊緣智能之路:面向嵌入式設備的開源AutoML正式發布----加速邊緣AI創新





 工商網監
工商網監

評論