 頂刊TPAMI最全綜述!深入自動駕駛BEV感知的魔力!
頂刊TPAMI最全綜述!深入自動駕駛BEV感知的魔力!
1. 寫在前面
今天筆者為大家推薦一篇BEV感知的最新綜述,分析了BEV感知的核心難點,回顧了關于BEV感知的最新工作,并對不同的解決方案進行了深入分析,還描述了來自工業界的幾種BEV方法的系統設計。
下面一起來閱讀一下這項工作~
2. 摘要
在鳥瞰圖( bird ' s-eye-view,BEV )中學習強大的表征用于感知任務是一種趨勢,并引起了工業界和學術界的廣泛關注。大多數自動駕駛算法的傳統方法在前方或視角視圖中執行檢測、分割、跟蹤等。隨著傳感器配置越來越復雜,集成來自不同傳感器的多源信息并在統一視圖中表示特征變得至關重要。BEV感知繼承了幾個優點,因為在BEV中表示周圍的場景是直觀的和融合友好的;而在BEV中表示對象是后續模塊在規劃和/或控制中最需要的。BEV感知的核心問題在于:( a )如何通過視角到BEV的視角轉換來重建丟失的三維信息;( b )如何獲取BEV網格中的真實標注;( c )如何制定管線以納入來自不同來源和視圖的特征;( d )隨著傳感器配置在不同場景中的變化,如何適應和推廣算法。在這項調查中,我們回顧了關于BEV感知的最新工作,并對不同的解決方案進行了深入分析。此外,還描述了來自工業界的幾種BEV方法的系統設計。此外,我們還介紹了一套完整的實用指南,以提高BEV感知任務的性能,包括相機、激光雷達和融合輸入。最后,指出了該領域未來的研究方向。我們希望本報告能給社區帶來一些啟示,并鼓勵更多關于BEV感知的研究工作。
3. 文章結構
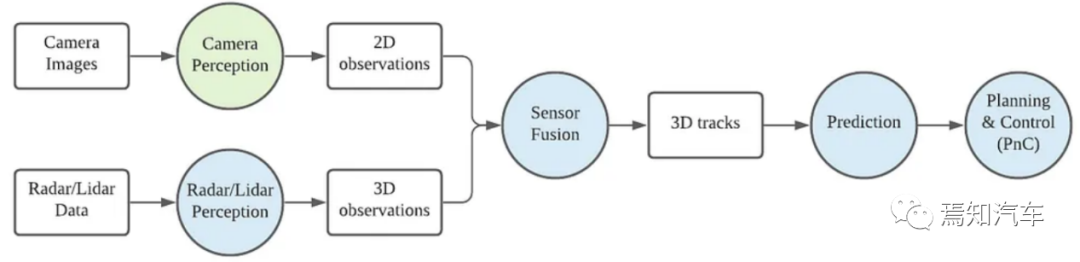
BEV感知的任務總結,包括輸入數據總結、底層任務總結,還有核心任務總結。
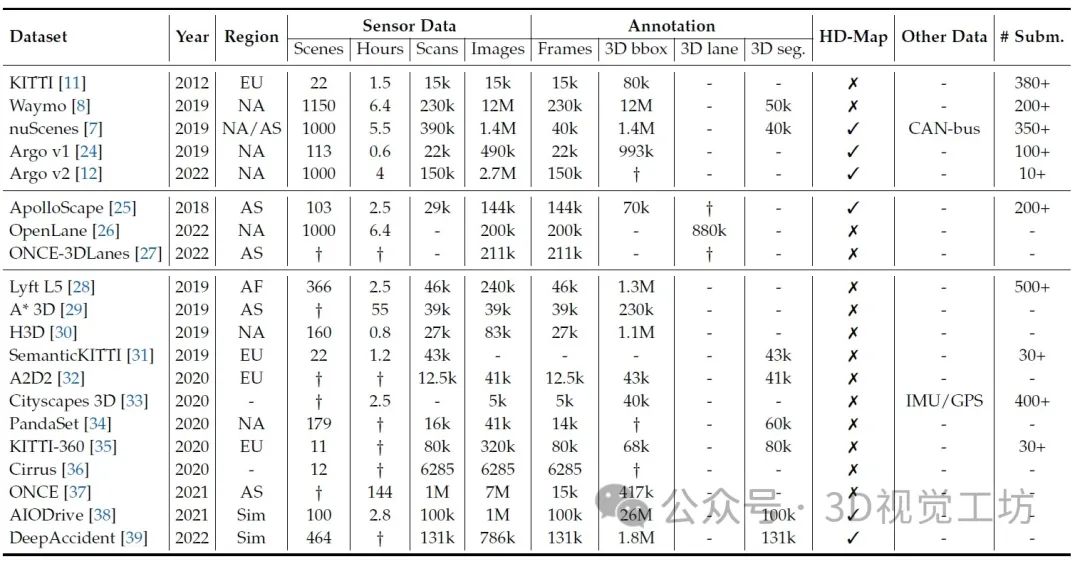
BEV感知數據集總結。
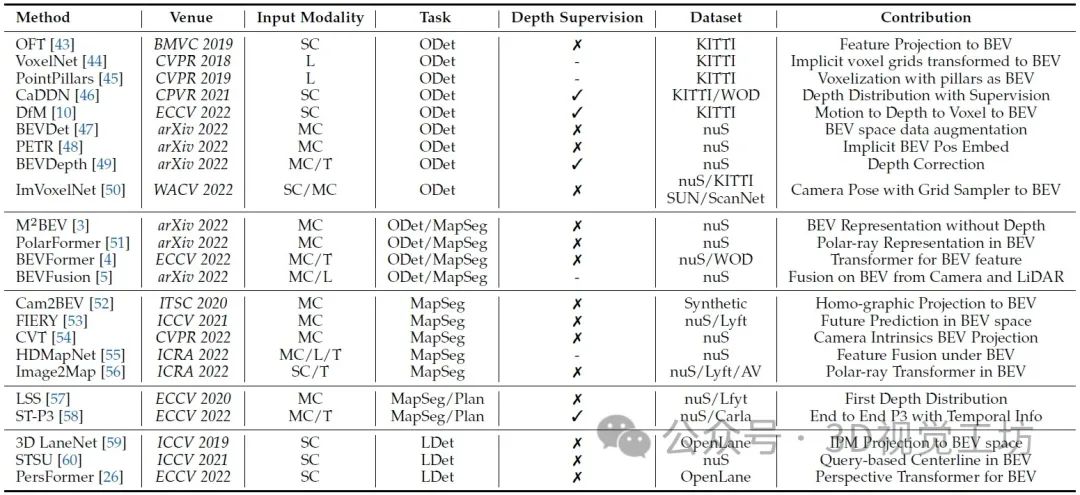
BEV感知的主要工作。在輸入模態下," L "為LiDAR," SC "為單相機," MC "為多相機," T "為時間信息。在Task下,' ODet '用于3D目標檢測,' LDet '用于3D車道線檢測,' MapSeg '用于地圖分割,' Plan '用于運動規劃,' MOT '用于多目標跟蹤。
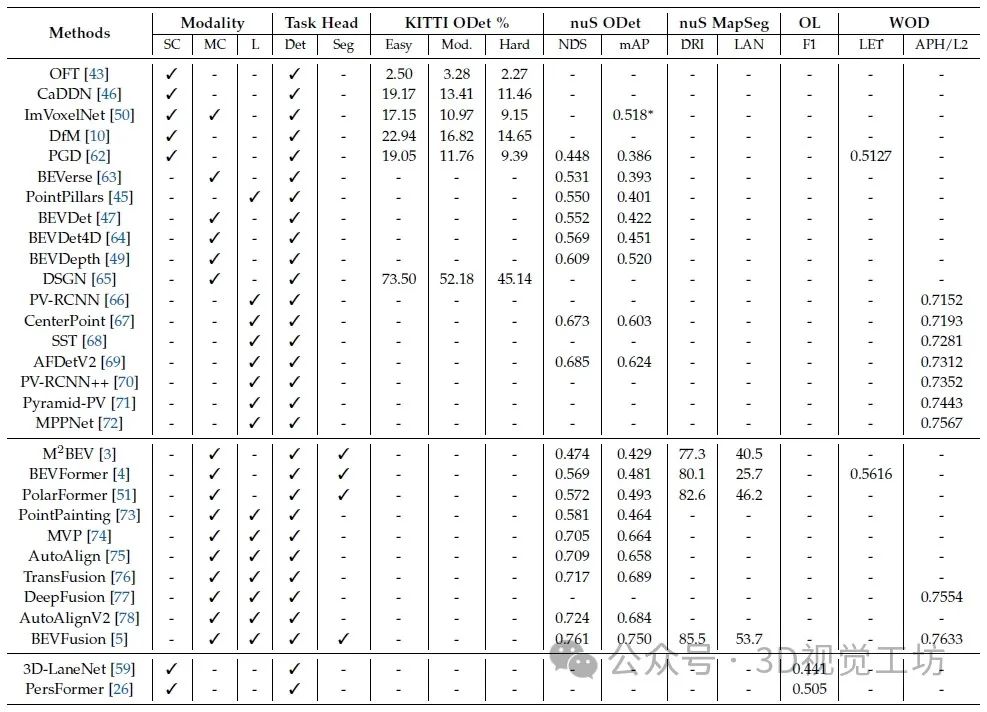
BEV感知算法在主流基準上的性能比較。
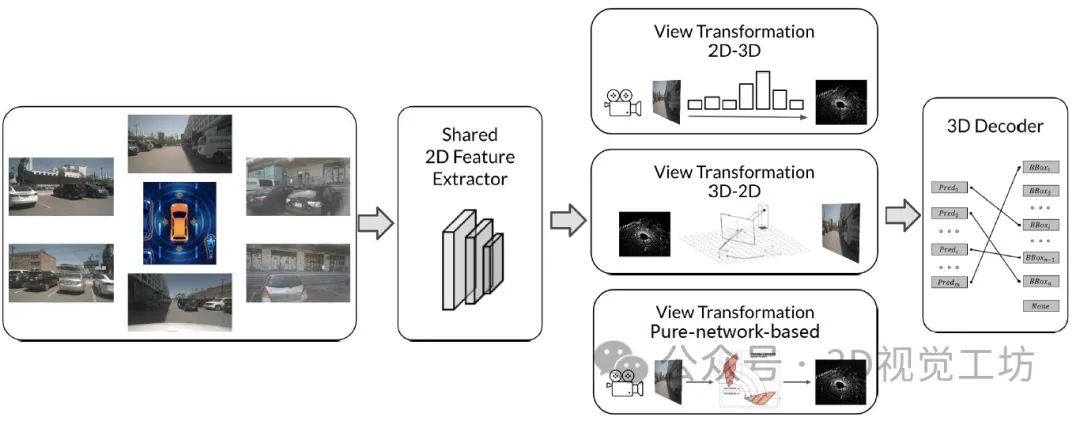
視覺BEV感知的通用框架。包括2D特征提取器、視圖轉換和3D解碼器3個部分。在視圖轉換中,有兩種方式對3D信息進行編碼- -一種是從2D特征中預測深度信息;另一種是從3D空間采樣2D特征。
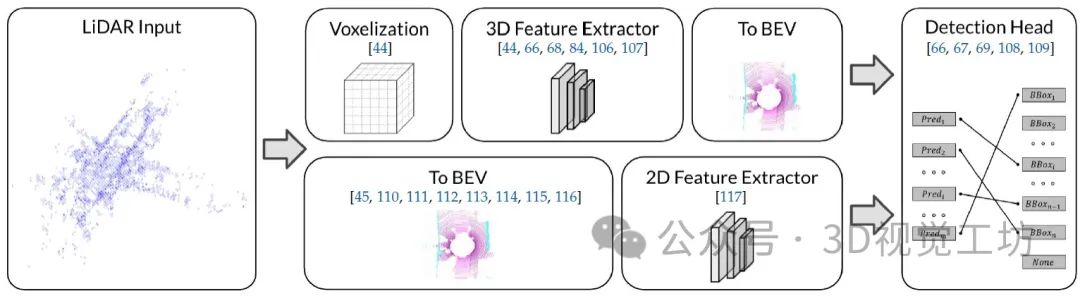
LiDAR BEV感知的通用框架。將點云數據轉換為BEV表示主要有兩個分支。上層分支提取三維空間中的點云特征,提供更準確的檢測結果。下層分支在2D空間中提取BEV特征,提供更高效的網絡。
視覺BEV感知檢測任務。

LiDAR BEV感知分割任務。
4. 總結
這篇綜述對近年來的BEV感知進行了全面的回顧,作者認為未來的發展趨勢是:( a )如何設計一個更精確的深度估計器;( b )如何在一種新的融合機制中更好地對齊來自多個傳感器的特征表示;( c )如何設計一個無參數的網絡,使得算法的性能不受姿態變化或傳感器位置的影響,從而在各種場景中獲得更好的泛化能力;以及( d )如何從基礎模型中整合成功的知識,以促進BEV的感知。
-
傳感器
+關注
關注
2550文章
51035瀏覽量
753084 -
算法
+關注
關注
23文章
4607瀏覽量
92840 -
自動駕駛
+關注
關注
784文章
13784瀏覽量
166397
原文標題:頂刊TPAMI最全綜述!深入自動駕駛BEV感知的魔力!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺析基于自動駕駛的4D-bev標注技術

標貝科技:自動駕駛中的數據標注類別分享

標貝科技:自動駕駛中的數據標注類別分享

自動駕駛中一直說的BEV+Transformer到底是個啥?

聊聊自動駕駛離不開的感知硬件
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
自動駕駛識別技術有哪些
深度學習在自動駕駛中的關鍵技術
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
黑芝麻智能開發多重亮點的BEV算法技術 助力車企高階自動駕駛落地

BEV感知算法:下一代自動駕駛的核心技術
BEV和Occupancy自動駕駛的作用

自動駕駛領域中,什么是BEV?什么是Occupancy?

自動駕駛感知算法提升處理策略





 工商網監
工商網監
評論