 YOLOv8自定義數據集訓練實現安全帽檢測
YOLOv8自定義數據集訓練實現安全帽檢測
數據集地址
該圖像數據集包含8000張圖像,兩個類別分別是安全帽與人、以其中200多張圖像為驗證集,其余為訓練集。
模型訓練
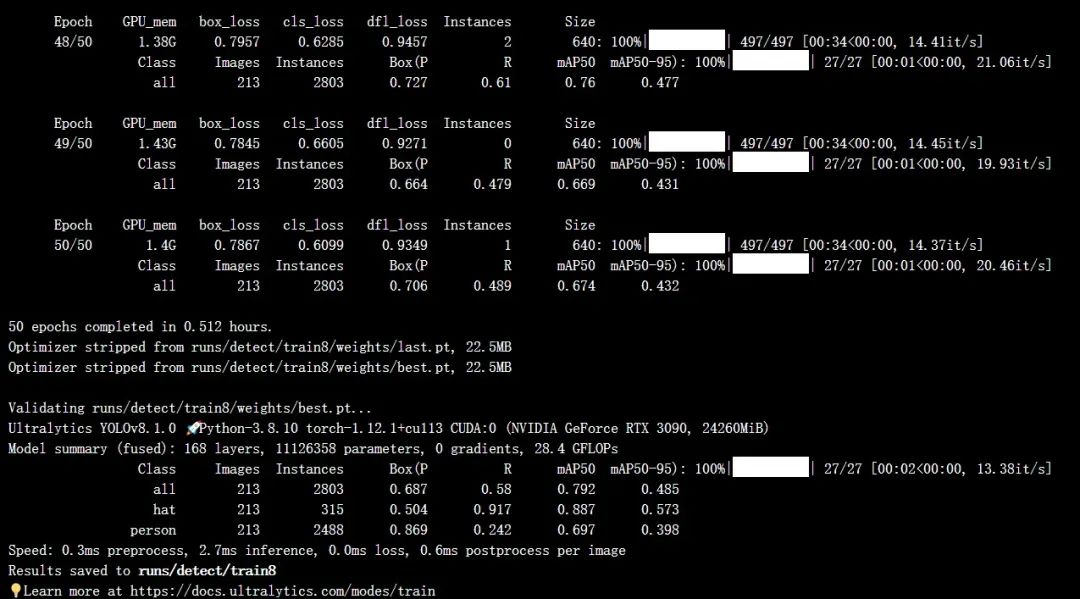
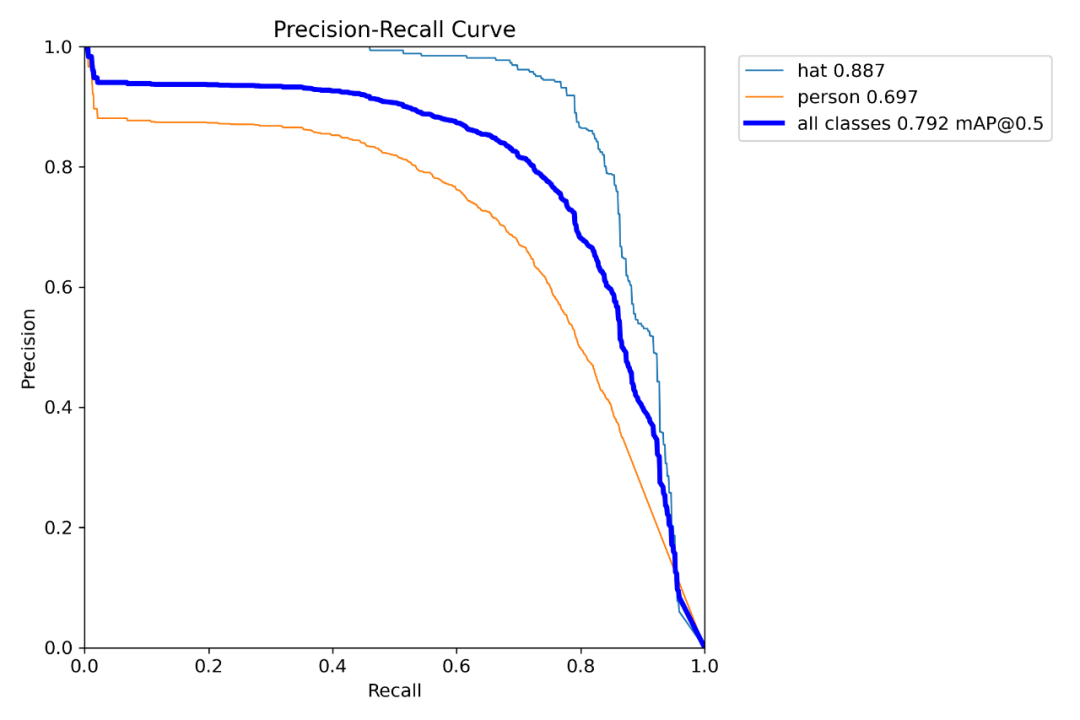
準備好數據集以后,直接按下面的命令行運行即可:
yolotrainmodel=yolov8s.ptdata=hat_dataset.yamlepochs=50imgsz=640batch=4
導出與測試
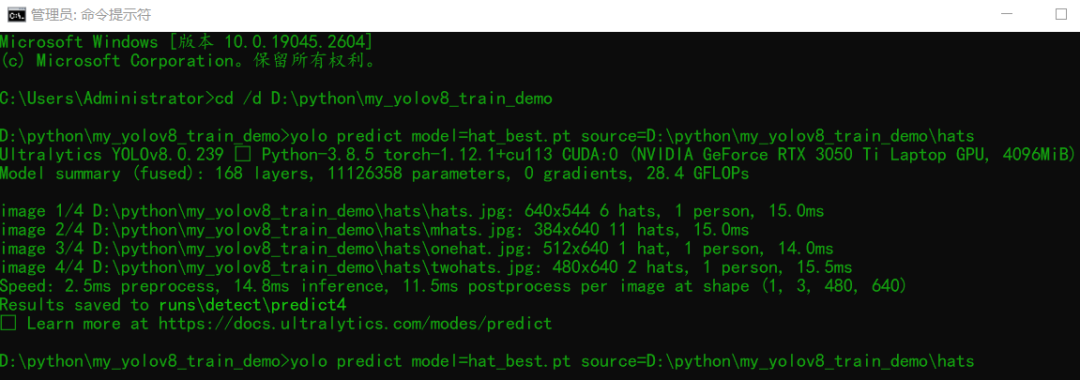
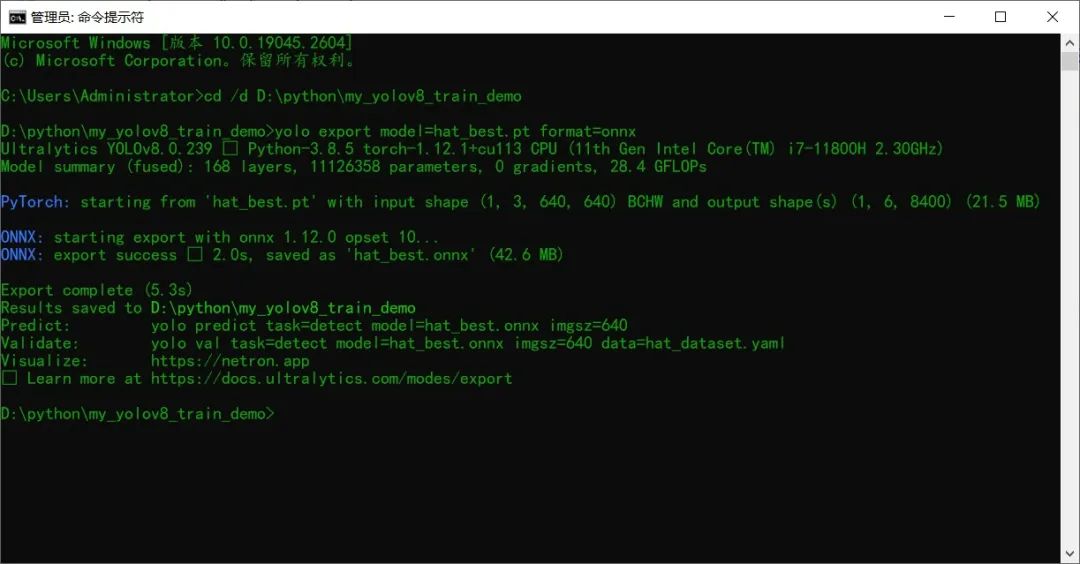
模型導出與測試
yolo export model=hat_best.pt format=onnx yolo predict model=hat_best.pt source=./hats
部署推理
轉成ONNX格式文件以后,基于OpenVINO-Python部署推理,相關代碼如下
#ReadIR model=ie.read_model(model="hat_best.onnx") compiled_model=ie.compile_model(model=model,device_name="CPU") output_layer=compiled_model.output(0) capture=cv.VideoCapture("D:/images/video/hat_test.mp4") whileTrue: _,frame=capture.read() ifframeisNone: print("Endofstream") break bgr=format_yolov8(frame) img_h,img_w,img_c=bgr.shape start=time.time() image=cv.dnn.blobFromImage(bgr,1/255.0,(640,640),swapRB=True,crop=False) res=compiled_model([image])[output_layer]#1x84x8400 rows=np.squeeze(res,0).T class_ids=[] confidences=[] boxes=[] x_factor=img_w/640 y_factor=img_h/640 forrinrange(rows.shape[0]): row=rows[r] classes_scores=row[4:] _,_,_,max_indx=cv.minMaxLoc(classes_scores) class_id=max_indx[1] if(classes_scores[class_id]>.25): confidences.append(classes_scores[class_id]) class_ids.append(class_id) x,y,w,h=row[0].item(),row[1].item(),row[2].item(),row[3].item() left=int((x-0.5*w)*x_factor) top=int((y-0.5*h)*y_factor) width=int(w*x_factor) height=int(h*y_factor) box=np.array([left,top,width,height]) boxes.append(box) indexes=cv.dnn.NMSBoxes(boxes,confidences,0.25,0.45) forindexinindexes: box=boxes[index] color=colors[int(class_ids[index])%len(colors)] cv.rectangle(frame,box,color,2) cv.rectangle(frame,(box[0],box[1]-20),(box[0]+box[2],box[1]),color,-1) cv.putText(frame,class_list[class_ids[index]],(box[0],box[1]-10),cv.FONT_HERSHEY_SIMPLEX,.5,(0,0,0)) end=time.time() inf_end=end-start fps=1/inf_end fps_label="FPS:%.2f"%fps cv.putText(frame,fps_label,(20,45),cv.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2) cv.imshow("YOLOv8hatDetection",frame) cc=cv.waitKey(1) ifcc==27: break cv.destroyAllWindows()
審核編輯:湯梓紅
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
模型
+關注
關注
1文章
3226瀏覽量
48809 -
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
命令行
+關注
關注
0文章
77瀏覽量
10385
原文標題:YOLOv8自定義數據集訓練實現安全帽檢測
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于YOLOv8實現自定義姿態評估模型訓練
Hello大家好,今天給大家分享一下如何基于YOLOv8姿態評估模型,實現在自定義數據集上,完成自定義姿態評估模型的

RK3399pro實現安全帽識別
省了。
這個數據中把沒戴安全帽的頭標注為 head, 把戴了安全帽的頭標注為 helmet, 沒戴在頭上的安全帽沒有標注。這樣算法就不會把沒戴在頭上的
發表于 05-11 16:09
ZLG安全帽佩戴檢測方案的解讀
安全帽佩戴檢測是工地安防的重中之重,但人為主觀檢測的方式時效性差且不能全程監控。AI技術的日漸成熟催生了安全帽佩戴檢測方案,成為了監督佩戴
發表于 03-13 15:32
?1506次閱讀
TensorRT 8.6 C++開發環境配置與YOLOv8實例分割推理演示
對YOLOv8實例分割TensorRT 推理代碼已經完成C++類封裝,三行代碼即可實現YOLOv8對象檢測與實例分割模型推理,不需要改任何代碼即可支持
YOLOv8實現任意目錄下命令行訓練
當你使用YOLOv8命令行訓練模型的時候,如果當前執行的目錄下沒有相關的預訓練模型文件,YOLOv8就會自動下載模型權重文件。這個是一個正常操作,但是你還會發現,當你在參數model中
用自己的數據集訓練YOLOv8實例分割模型
YOLOv8 于 2023 年 1 月 10 日推出。截至目前,這是計算機視覺領域分類、檢測和分割任務的最先進模型。該模型在準確性和執行時間方面都優于所有已知模型。


基于YOLOv8的自定義醫學圖像分割
YOLOv8是一種令人驚嘆的分割模型;它易于訓練、測試和部署。在本教程中,我們將學習如何在自定義數據集上使用YOLOv8。但在此之前,我想告

如何基于深度學習模型訓練實現圓檢測與圓心位置預測
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現圓檢測與圓心位置預測,主要是通過對YOLOv8姿態評估模型在自定義的

如何基于深度學習模型訓練實現工件切割點位置預測
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現工件切割點位置預測,主要是通過對YOLOv8姿態評估模型在自定義的數據集上

YOLOv8實現旋轉對象檢測
YOLOv8框架在在支持分類、對象檢測、實例分割、姿態評估的基礎上更近一步,現已經支持旋轉對象檢測(OBB),基于DOTA數據集,支持航拍圖像的15個類別對象





 工商網監
工商網監
評論