 關于轉碼系統優化原理與實踐
關于轉碼系統優化原理與實踐
編者按
轉碼主要有三個目的:提高碼流的兼容性、改善畫質和降碼率省帶寬。轉碼系統對公司的帶寬和體驗是非常重要的,尤其在降本增效大背景下。LiveVideoStackCon 2023 深圳站邀請到嗶哩嗶哩公司蔡春磊老師講解B站降低碼率相關的原理和實踐。
文/蔡春磊
大家好,我是蔡春磊。今天和大家分享一些關于轉碼系統優化原理的思考。我畢業后加入嗶哩嗶哩,主要從事傳統實用轉碼系統的設計和優化。同時我對深度學習編碼也有過研究,我經常思考它們之間本質上的聯系,今天和大家探討一下。
01
廣義轉碼框架
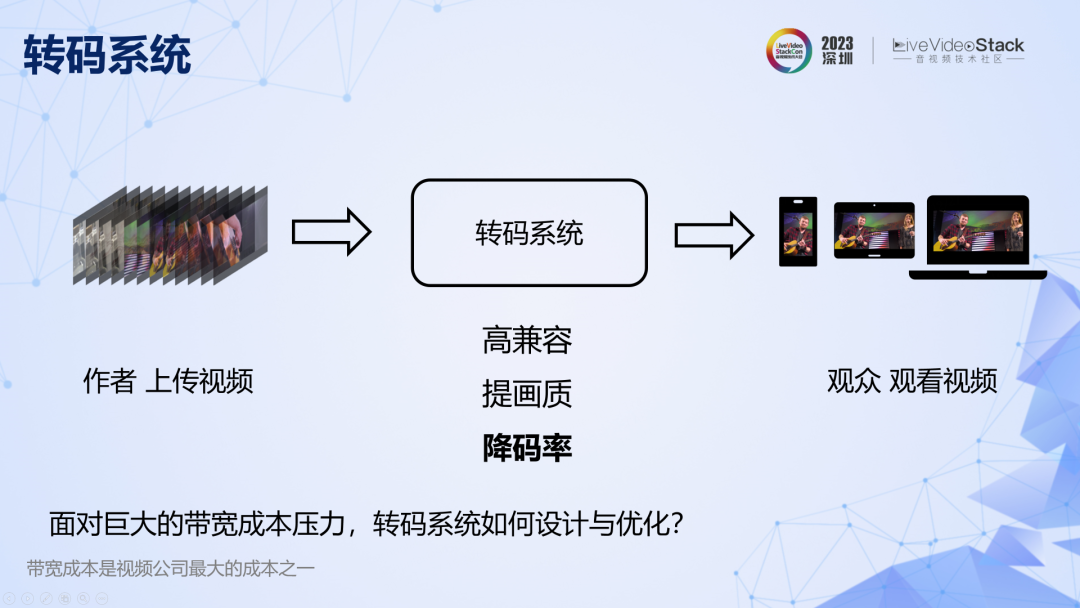
我們從轉碼系統切入。轉碼主要有三個目的:提高碼流的兼容性、改善畫質和降碼率省帶寬。今天主要探討降低碼率相關的原理和實踐,因為帶寬成本是視頻公司最沉重的負擔之一。
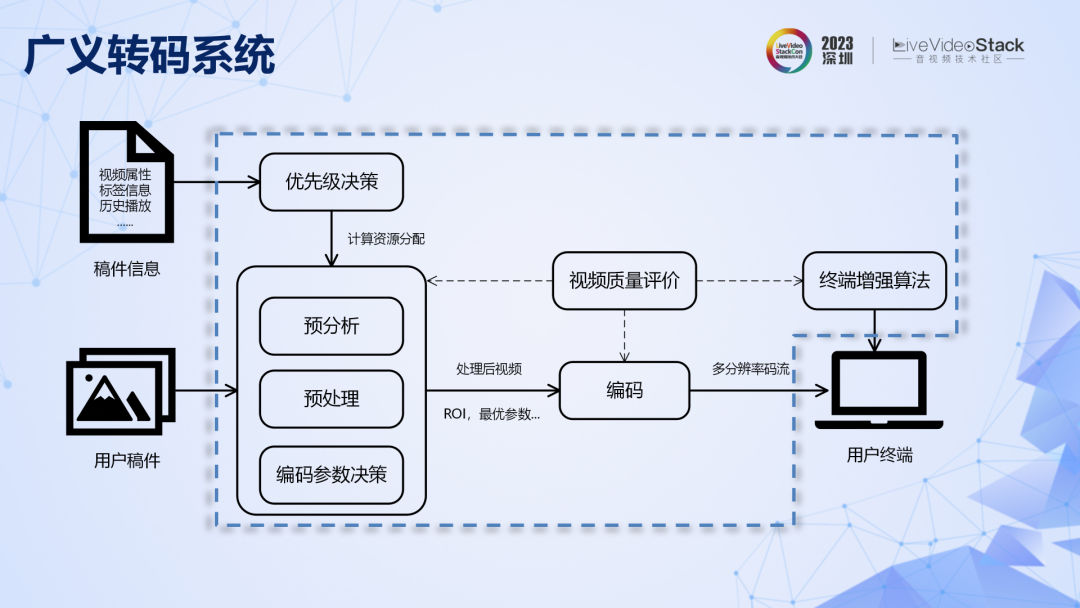
現在的轉碼系統不僅僅是簡單的解碼再編碼,而是包括了預分析、前處理、參數決策、終端增強和質量評價等模塊的龐大系統。其基本原理是在更大的系統尺度上,對壓縮率進行聯合優化,用更多算力換取更高的壓縮率,可以稱之為廣義轉碼系統。

廣義轉碼系統具體表現形式非常多,不同公司的實現方法不同,叫法也不同。例如,內容自適應轉碼系統、窄帶高清轉碼系統等。上面列出了全球部分代表性公司對轉碼系統各個模塊的投入,從投入力度上可以發現,轉碼系統對公司的帶寬和體驗是非常重要的,在降本增效的大背景下更是如此。

B站在轉碼系統優化上起步較晚,那我們該如何做才能迅速追趕行業先進水平呢?首先,不能著急投入到具體的技術實踐當中,因為不同的應用場景對轉碼系統的要求截然不同,比如適合 OGV 內容為主的轉碼系統不適合直接用在 UGV 為主的應用中,反之亦然。我們首先要做的是找到底層的優化原理。

具體來講,就是要先思考上述這些技術點,有沒有共同的優化原則。
02
壓縮的信息論原理
我先嘗試構建一套基于信息論的優化理論框架,然后對其合理性進行驗證。
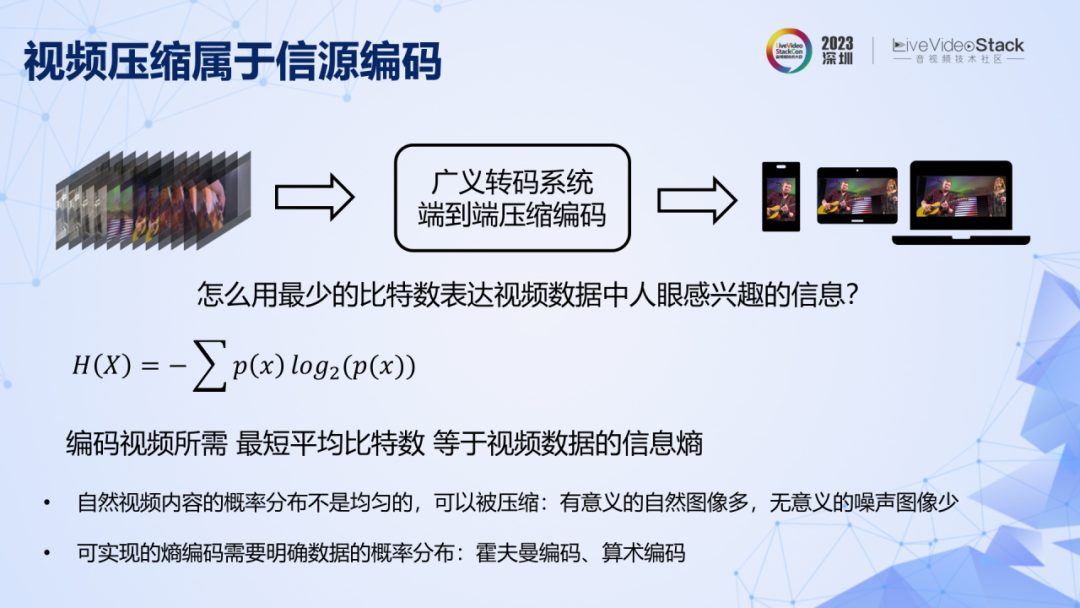
先忽略轉碼系統復雜多變的表現形式。轉碼本質是一個信源編碼系統,目的是用最少的比特數表達視頻數據中人眼感興趣的信息,最短平均比特數等于視頻數據的信息熵。在實際應用中,有意義的自然視頻多,無意義的噪聲視頻少,概率分布不均勻,所以信息熵小于像素數據無損表示所需要的比特數,因此視頻數據可以被壓縮。計算信息熵,前提是要明確視頻中所有像素取值的聯合概率分布。我們先用信息熵的概念作為基座,再看兩條定理,它們構成了理論框架的支柱。
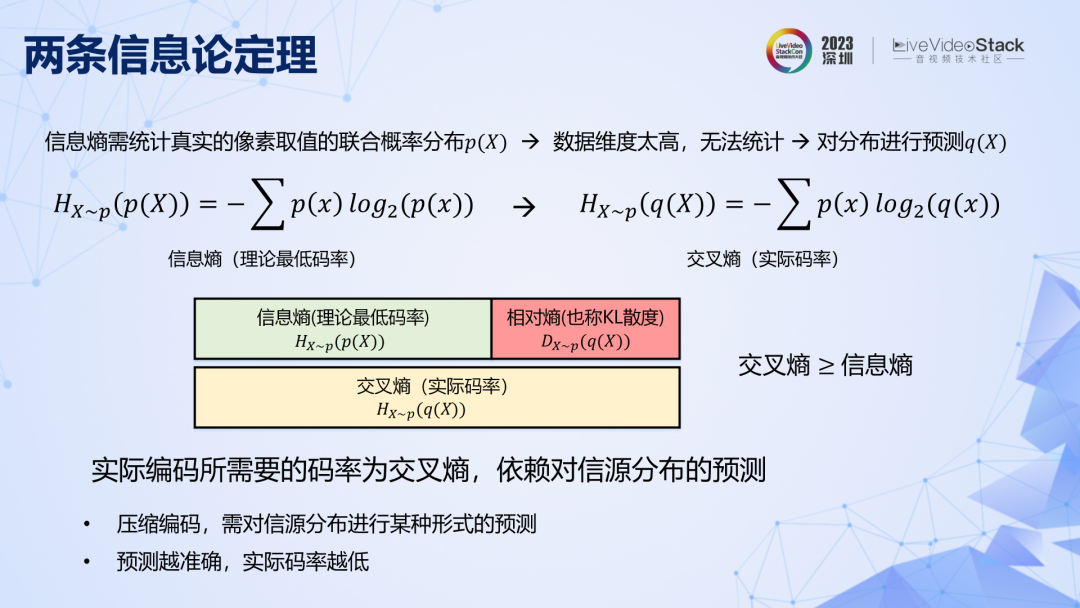
第一條定理是說,真實視頻的像素聯合取值空間非常大,其概率分布不可能通過統計得到。所以在實際編碼時,是基于對概率分布的預測,由此進行實際熵編碼得到的碼率叫做交叉熵,可以證明交叉熵≥信息熵。對分布預測得越準確,所能達到的實際碼率越低。
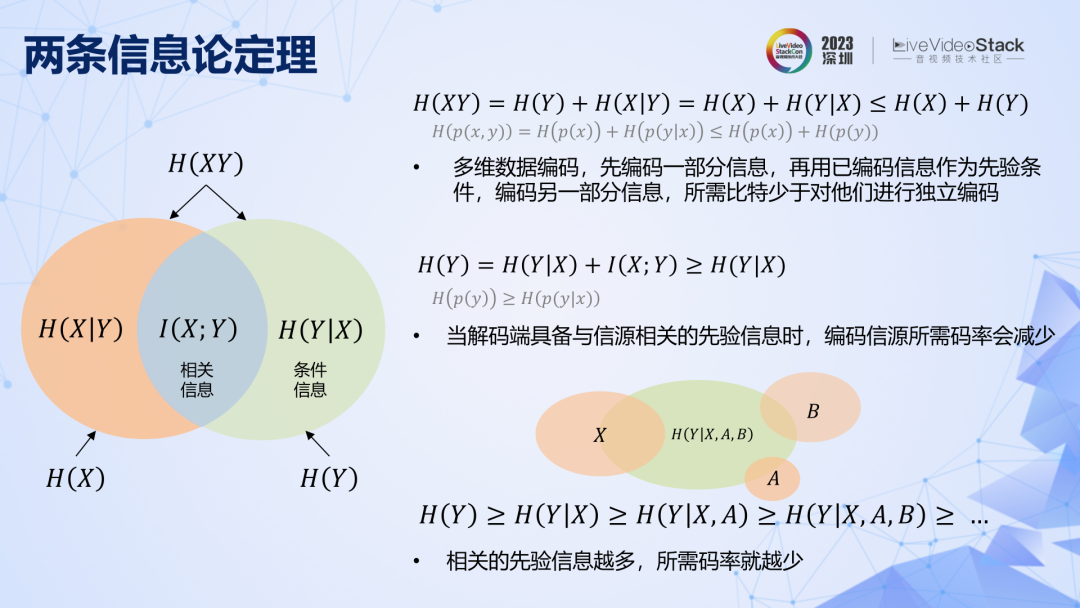
第二條定理可以用以上圖直觀表示,它有多種理解方式:1. 編碼多維數據,可以先編碼一部分信息,再用已編碼信息作為先驗條件來編碼另一部分信息,這樣所需比特數要少于對他們進行獨立編碼。2. 當解碼端事先已具備與信源相關的先驗信息(相關信息)時,編碼信源所需碼率(條件信息)可以減少。3. 相關的先驗信息越多,所需碼率越少。

這就是一套關于轉碼優化的理論框架了,非常簡潔:一條信息熵的基本概念、兩條信息論定理。檢驗此框架的合理性,可以用此來解釋轉碼系統中各個模塊的設計原理以及優化路徑,如果能解釋明白,那就可以認為此框架是合理的。

我們先以傳統編碼的發展為例。如果從技術角度來理解我們所熟悉的變換和預測混合編碼方法,門檻是很高的,因為里面涉及了太多的模塊。現在我嘗試從理論角度出發,對傳統編碼框架的設計原理和優化路徑進行重新梳理。
對視頻像素數據進行壓縮,前提是要明確像素取值的聯合概率分布,但視頻由時域上很多幀組成,其像素數量極其龐大,數據間聯合取值的范圍幾乎無窮。所以首先對數據進行降維處理,也就是一幀一幀地去編碼。上面的公式表明,為了保持理論上的最低碼率,在編碼時要充分利用已經編碼幀給未編碼幀提供相關信息。但在實際標準中,由于復雜度問題,采用的都是有限數量的參考幀結構,這是傳統編碼中幀間編碼的概念。原理上幀間參考信息越多,碼率越低,所以隨著標準的發展,逐漸出現了 P 幀、B 幀,同時封閉式的 GOP 結構向開放式 GOP 結構發展。

現在我們將問題拆解成對一幀進行編碼。但是,一幀 1080P 圖像就有百萬數量級的像素,它們之間的聯合取值范圍也近乎無窮大。繼續降低維度,把圖像拆成一個一個塊進行編碼,原理上在編碼時為了保證盡可能低的碼率,要充分利用已編碼圖像塊,給未編碼塊提供相關信息來降低碼率。但由于復雜度原因,在實際發展過程中首先出現的是諸如 H.264 中 16×16 的小塊,且僅參考相鄰域圖像塊的邊緣像素。從公式可以輕松推導出,當 LCU 越大的時候,對具體的 CU,能參考的信息就越多,理論上碼率就會越低。所以編碼標準一定是朝著編碼塊越來越大的方向去發展,同時還會引入更多的鄰域相關信息,比如多行參考。
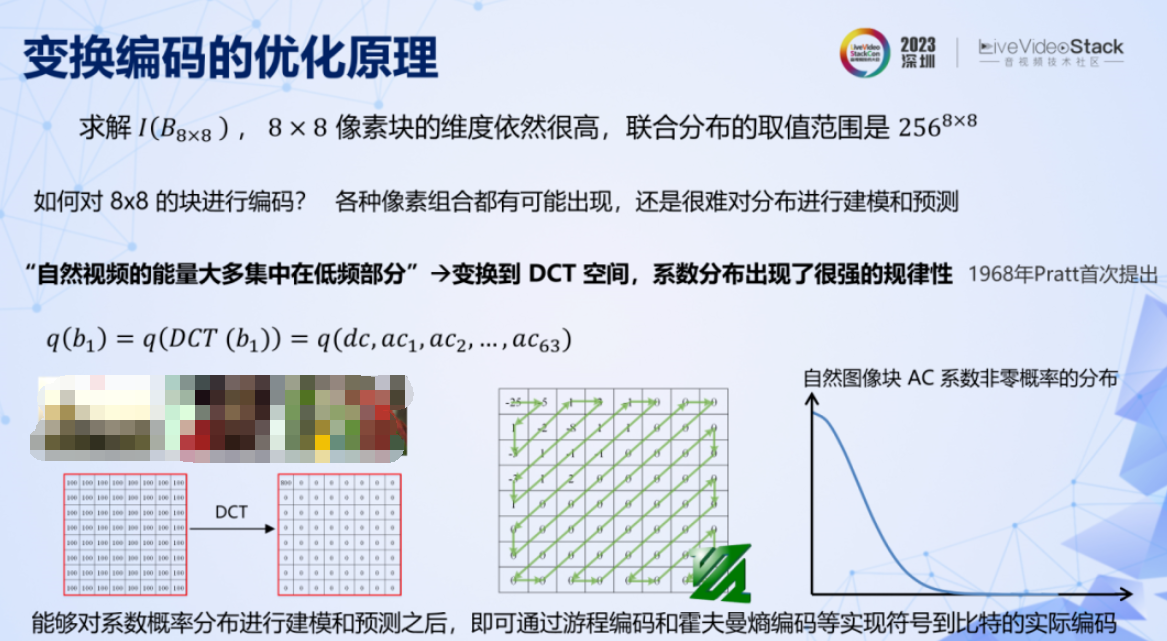
假設已經將圖像拆成了 8×8 的像素塊,但是其維度依然很高,聯合分布的取值范圍仍然極大。而且其取值非常分散,很難對其分布進行建模預測。對像素數據的分布進行預測,換句話說,其實是在問,自然圖像塊有沒有共同規律?
其實這個規律早在 1968 年就被發現了:自然視頻能量大多集中在低頻部分,圖像塊經過 DCT 變換后,系數會呈現很強的規律性,非零系數不多,且集中在低頻部分。根據這個規律,就可以對系數的分布進行建模預測,如右邊曲線所示。同時由于這個規律性很強,也就是說預測可以很準確,所以交叉熵就會很低,編碼所需碼率就低。再結合 zigzag、熵編碼等工具就能實現壓縮的目的。DCT 變換編碼這個天才般的發明,直到現在依然是傳統編碼中最核心的模塊。而 zigzag 則成了 FFmpeg 的 logo。
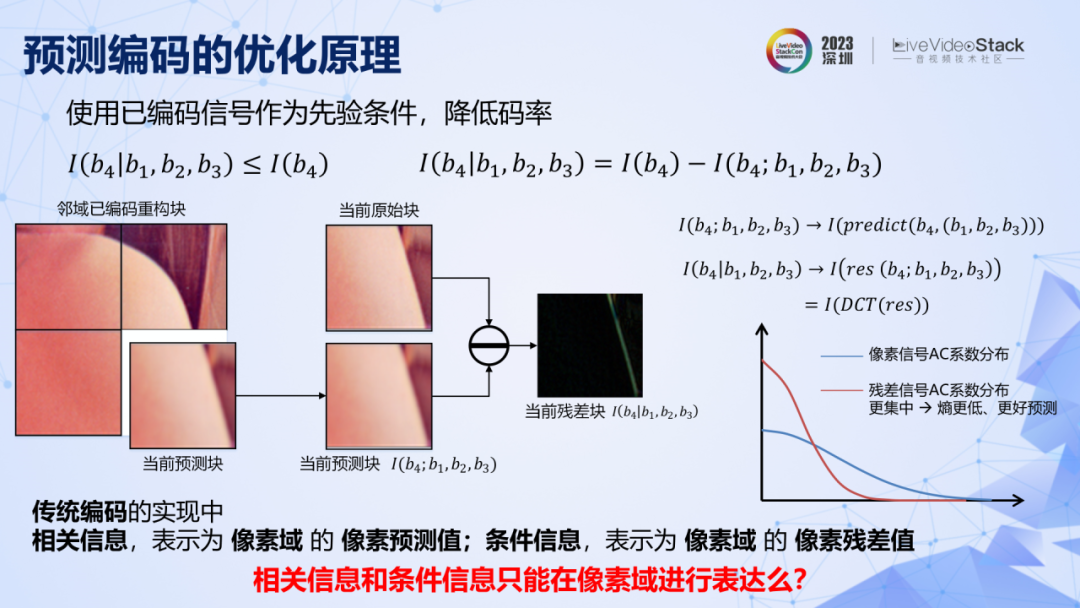
分塊加變換編碼,就構成了 JPEG 的基本框架。想要進一步降低碼率,原理表明,可以用相鄰的圖像塊給當前圖像塊提供先驗的相關信息,那么當前塊所需要編碼的就剩下了條件信息,而條件信息比自信息低,所以碼率就低。
在傳統編碼中,相對信息的表達方式是周圍圖像塊對當前圖像塊在像素域上的預測值。條件信息的表達方式是當前塊的像素預測殘差。而條件信息比自信息更低,則表現為預測殘差經過 DCT 變換之后,其系數會變得更加集中,非零系數更少,對其進行概率預測,所取得的交叉熵會更低,實際碼率也就更低。這就是傳統編碼中另一個核心技術:預測編碼。
在這里先拋出一個問題,在傳統編碼中,相關信息和條件信息都是在像素域進行表達的,那么它們是否只能在像素域進行表達呢?
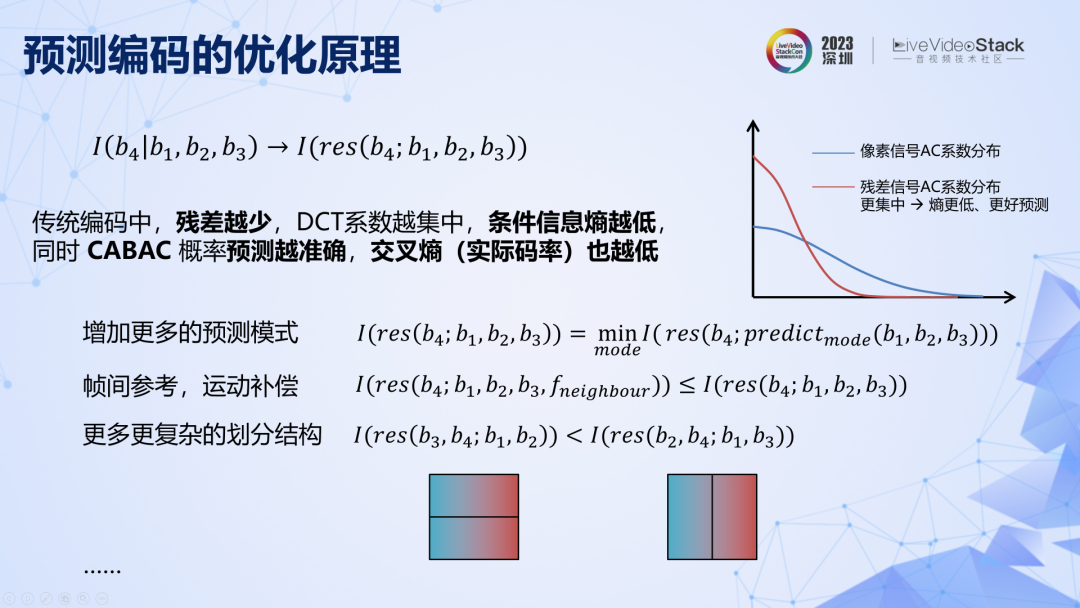
在傳統編碼中,預測殘差越少,DCT 系數越集中,交叉熵越低。所以傳統編碼中一個重要的優化方向是不斷引入更多的相關信息來提高對當前圖像塊的預測準確率,降低殘差,從而降低碼率。從這個角度看,就可以對很多傳統編碼工具的設計和發展路徑進行解釋,例如幀間參考的原理就是在參考當前幀圖像塊的基礎上增加相鄰幀圖像的參考,本質是引入更多相關信息從而減少條件信息,可以降低碼率。至此,我們已經從原理出發,重新推導了傳統的基于變換與預測的混合編碼框架,以及各個模塊的優化路徑。

編碼模式信息同樣不可忽視,上圖第一行公式成立的前提是解碼器提前知道劃分模式,但是通用解碼器預先是不知道具體編碼模式的,所以模式信息也要編碼,也要消耗碼率。同樣,模式信息也是可以引入更多先驗條件來降低碼率的。實際編碼時,不同模式的概率預測難度不同,其實際碼率也不同,且無法提前得知,所以需要嘗試不同模式并計算各自的碼率,從而搜索到碼率最低的模式,這就是模式搜索的概念。

上述都是無損編碼,但實際用的大多是有損編碼。有損編碼的原理可以解釋為:為編碼提供了一個先驗條件,即允許在編碼過程中對部分像素數據進行丟棄。在這個條件之下,編碼可以減少數據量來降低碼率。率失真優化 RDO 就是綜合考慮了失真和碼率的模式搜索,在實際標準發展過程中,編碼模式及其之間的組合急劇增加,模式搜索的空間不斷增大,因此實用編碼必須要引入一門重要的技術——快速算法。

傳統編碼的原理解釋先到這里,希望能為大家帶來一些啟發。接下來,繼續用此框架來梳理深度學習編碼的發展歷程。
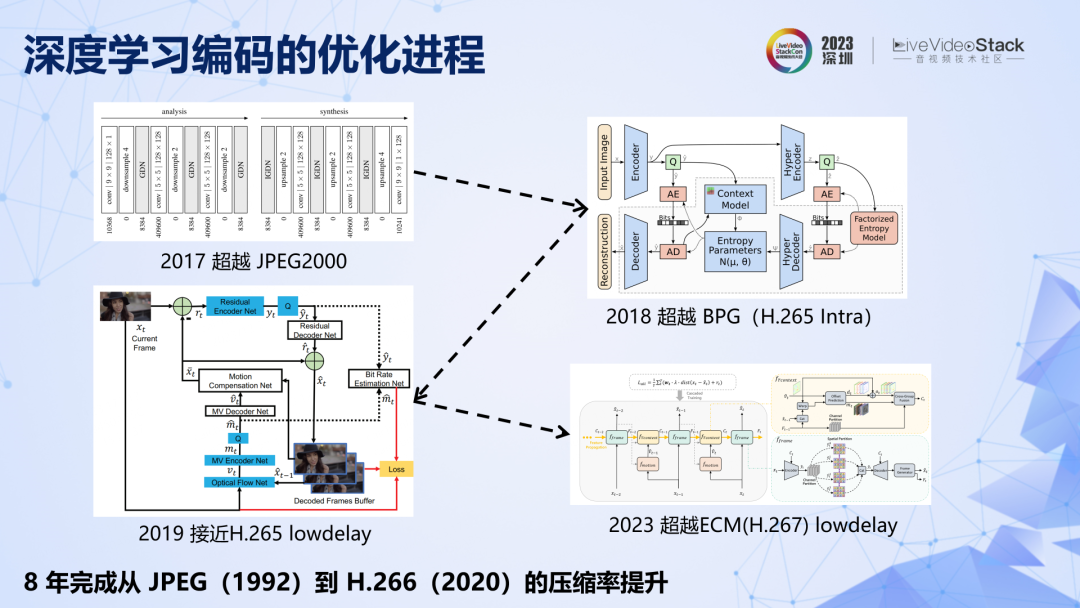
介紹一下深度學習的發展背景。約翰內斯巴萊最早提出了基于 CNN 的端到端圖像編碼,該方法具有開創性,為編碼領域開辟了一條全新的賽道,并掀起了全球對深度學習編碼的研究熱潮。深度學習編碼性能快速發展,如果對標傳統標準,8 年時間就從 JPEG 發展到 H.266,甚至下一代標準的水平,走完了傳統編碼約 30 年的性能提升之路。
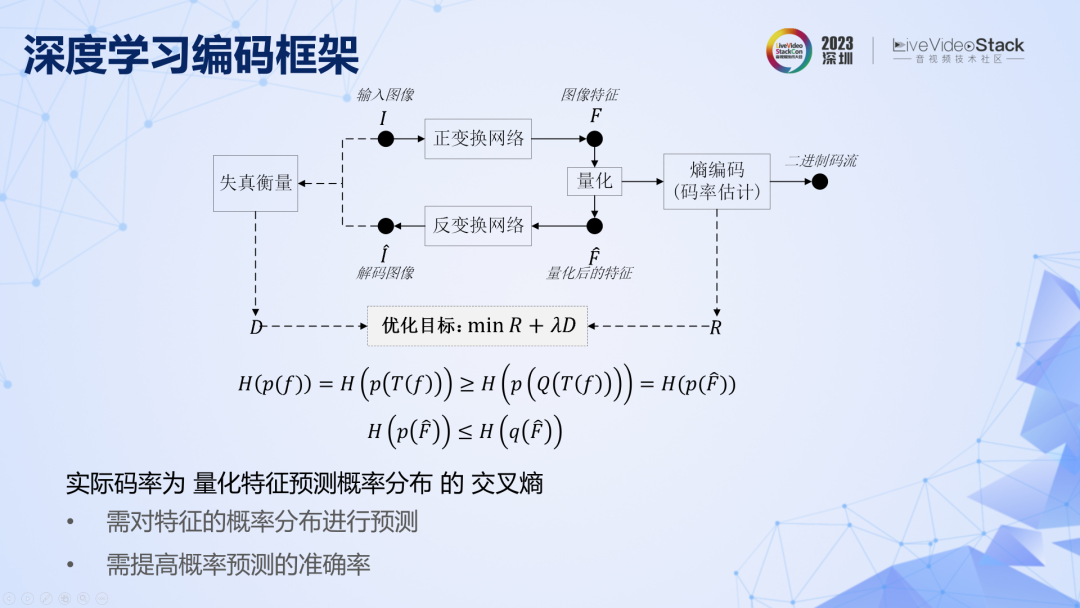
回顧一下深度學習圖像編碼的基本框架,和傳統編碼遇到的問題一樣,對像素域的分布預測很難,也要變換到分布更加有規律的特征域,以進行更加準確的預測。
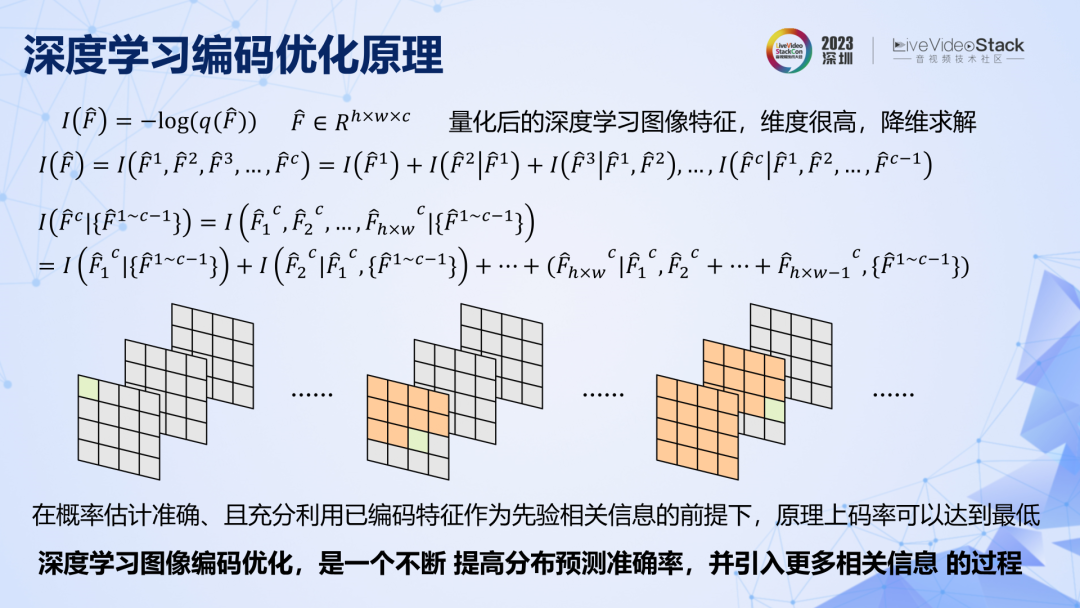
問題轉變成了對特征進行編碼,特征的聯合概率分布空間依然很大,也需要先降維,拆解成一個一個通道,一個一個特征去編碼。原理上要想取得盡可能低的碼率,需要充分利用已編碼的特征給未編碼特征提供相關信息。接下來要回顧的深度學習圖像編碼,其實就是一個不斷提高特征預測準確率,同時引入更多相關信息的過程。
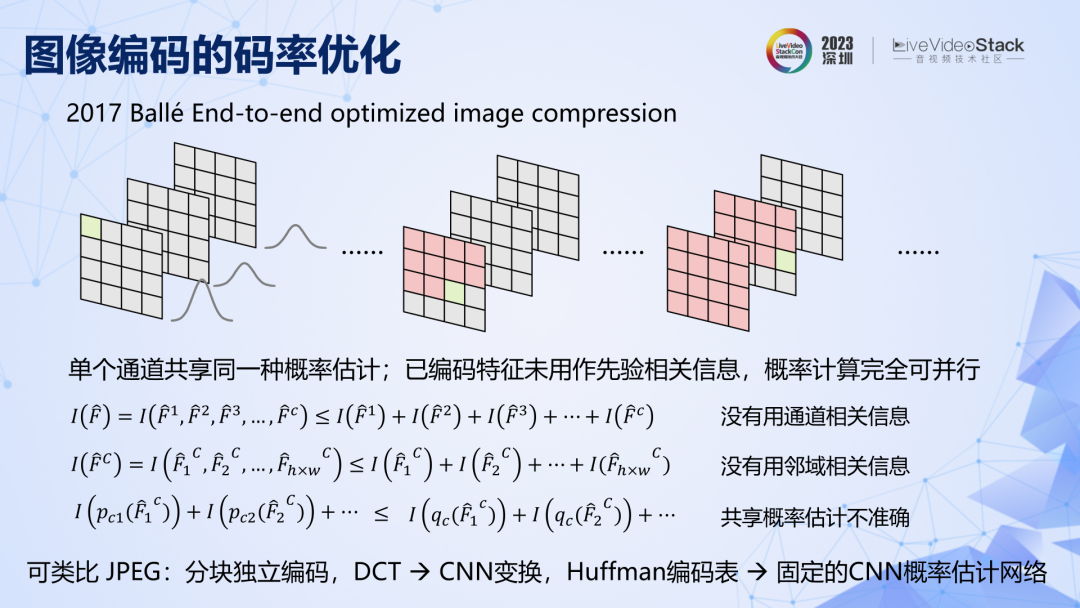
看幾個關鍵節點,2017 年第一個 CNN 圖像編碼,有兩個關鍵點,一是相同通道內的特征共享同一個固定的概率分布表,二是已編碼特征沒有用來給未編碼特征做參考。由于這兩個特點,在公式上很容易證明,該方法的壓縮率是有限的,概率預測準確率不高,相關信息利用不夠充分,碼率就不可能很低。原理上有二個優化方向,一是提高特征分布的預測準確率,二是利用已編碼特征提供相關信息。

2018 年,他們實現了這兩個優化。具體來說,從通道級固定概率表發展到元素級可變的概率估計,同時空間相鄰元素之間有參考。這兩點改進使壓縮率從 JPEG2000一下子就發展到了 2013 年 HEVC。如果繼續梳理,站在原理框架的視角去看,接下來的發展脈絡其實非常清晰,就是不斷引入更多已編碼特征提供相關信息的過程。不過在實踐中,利用的相關信息越多,復雜度就越高,并行性越弱,速度和壓縮率之間需要有取舍。
有一點需要注意,在深度學習圖像編碼中,相關信息和條件信息的表達已經不在像素域,而在特征域了,這些方法都在特征域進行元素間的參考預測和殘差編碼。所以,之前問題的答案,相關信息和條件信息,并不是只能在像素域進行表達。我認為這個本質的差別,決定了深度學習編碼的性能天花板要比傳統方法高得多。
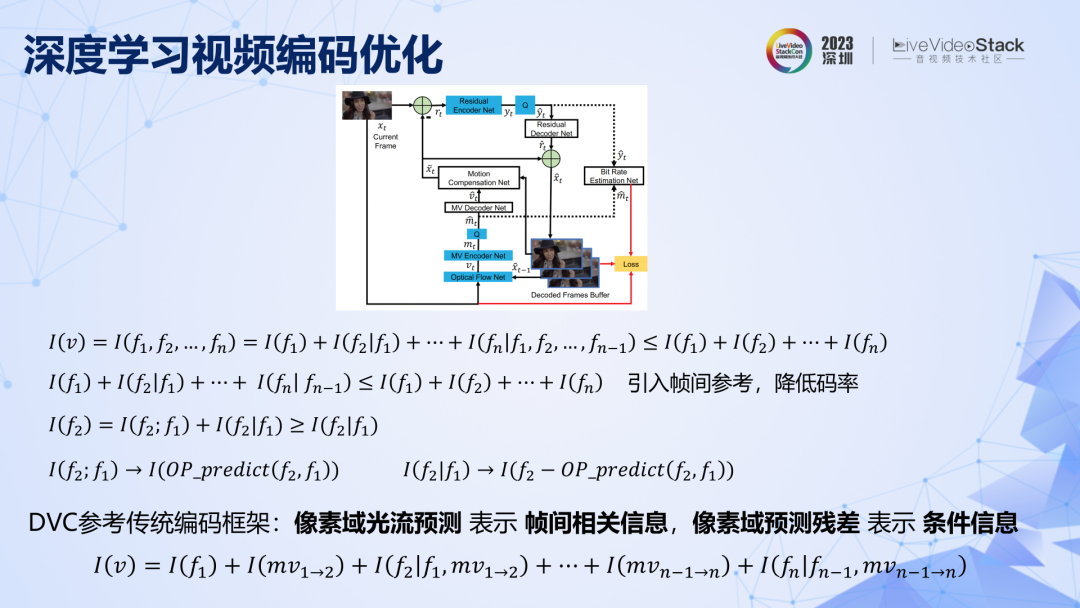
繼續來到深度學習的視頻編碼,上面第一行公式,表明如果對視頻進行一幀一幀編碼是不高效的,需要引入幀間參考,提供相關信息來降低碼率。第一個深度學習視頻編碼 DVC 在圖像編碼基礎上,引入了前向幀間參考,完全遵循了傳統的編碼框架,用像素域光流預測表達幀間相關信息,用像素域預測殘差表達條件信息。雖然用光流替代了傳統運動估計,但這在原理上,DVC 和傳統方法并沒有本質差別,所以 DVC 框架的性能天花板其實是有限的。
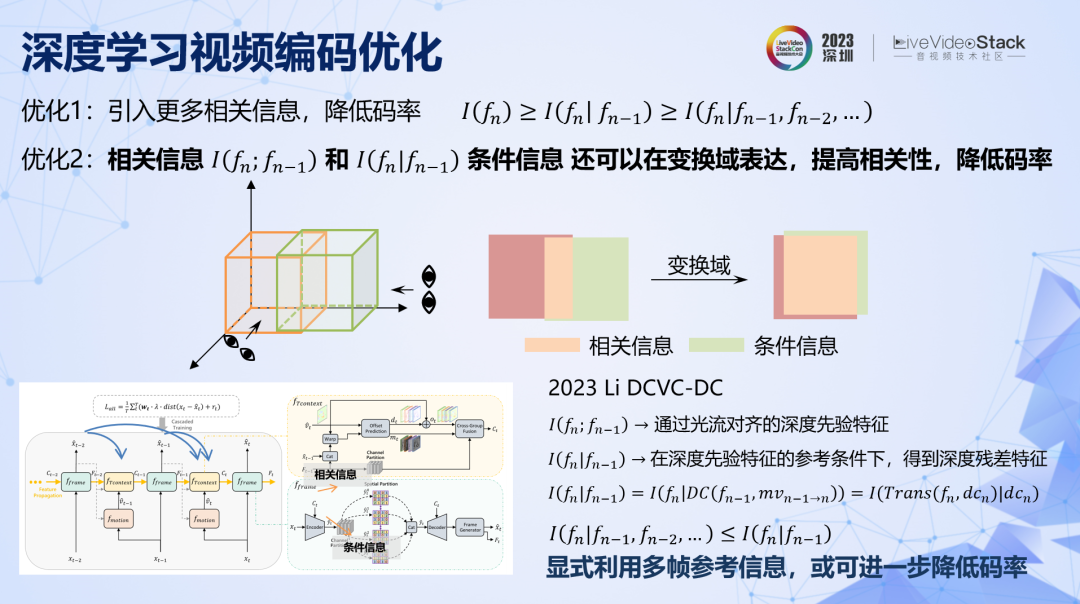
有兩個優化方向:一是引入更多相關信息,降低碼率。二是將相關信息和條件信息在更有效的變換域內進行表達。
第一條好理解,就是引入更多的參考幀。第二條用上面的示意圖可以直觀地解釋,同樣兩組數據,可以從不同維度去觀察它們的相關性,在不同空間內,他們之間的相關信息量是不一樣的。所以總是存在更有效的空間,它們之間的相關信息更多,條件信息更少,那么在這個域上編碼條件信息,碼率就會更低。傳統方法都是在像素域內表達相關信息和條件信息,這是最容易實現的,但未必是最優的,深度學習圖像編碼全面超越傳統方法已經證明了這一點,那么深度學習視頻編碼同樣可以這樣去優化。
目前最新也是最好的方法 DCVC-DC,實現了這兩點優化。具體來說,一是利用深度學習特征的傳導,引入了前向多幀的相關信息。二是幀間參考信息和當前條件信息都是在特征域進行表達的,而不是在像素域。該方法比目前正在研發的下一代 ECM(可以認為 H.267)在相同 GOP 結構下的性能更好。該方法對于前向非相鄰幀的參考還是比較隱蔽的,如果使用更加顯式的方法,引入更多相關信息,或許可以進一步提升壓縮率。
總結一下深度學習編碼,原理是利用深度神經網絡強大的優化能力和巨大的算力,對編碼問題中概率預測的問題進行更加直接的求解,所以深度學習編碼的性能發展速度遠遠快于傳統編碼。可以預見的是,在未來本就激烈的編碼標準競爭格局中,深度學習編碼必將以強勢的姿態加入競爭,并取得重要的席位。

沿著編碼發散一下,一是用大模型給解碼端提供更多先驗知識,二是相關信息和條件信息在內容語義層面進行更高效的表達。例如,英偉達提出在會議場景下的極低碼率編碼。原理是在解碼端利用面部重建模型,提供了從關鍵點和共享紋理構造人臉的先驗知識。同時該方法對幀間相關信息表達為共享的面部紋理和參考關鍵點,條件信息表達為當前幀人臉的關鍵點信息,所以只需要對人臉關鍵點信息進行編碼,而關鍵點可以以極低的碼率去表示。
還有最近比較火的“郭德綱說英文”的有趣應用,如果從轉碼角度去看這項技術,其實可以實現對同一視頻內容的不同語言版本進行極其高效的壓縮和傳輸,這能夠在對視頻內容進行全球化分發的業務中節省大量的成本。假設我們先用傳統方法分發一個中文和英文版的視頻,盡管只有嘴型不同,但是傳統方法需要單獨編碼兩個視頻,碼率成倍上升。
換個思路,如果提前給解碼端幾個大模型,如翻譯模型、文字轉語音模型、語音驅動嘴唇的模型。此時就只需要編碼傳輸一個英文版本的視頻,其他語言版本的視頻可以通過解碼端的大模型完全重構出來,此時對其他所有版本的視頻編碼所需要的比特數為零,這就實現了極其高效的壓縮。

沿著編碼繼續發散,原理上解碼端擁有相關信息越多,碼率就越低。可以推測有兩個發展方向,一是專用場景下的編碼,這相當于提供了一個非常強的場景先驗信息,比如英偉達的會議場景下的編碼。專用編碼目前還很難推廣,是因為傳統標準依賴專用解碼芯片,不同標準無法共享高效的芯片核心,限制了解碼的效率。但假設未來深度學習編碼能夠普及,那么各類專用編碼器的差異可能就在于模型結構和參數的不同,而底層推理芯片是一樣的,也就不存在解碼效率差異的問題了,安裝專用場景的硬件解碼器只需要像安裝軟件一樣,下發解碼模型文件即可。
二是用世界大模型進行視頻編碼,其原理是用更龐大的算力和更海量的數據,對編碼中的概率估計問題進行更加直接有效的求解,從而取得更低的交叉熵。此時,大模型會學習海量關于視頻數據的先驗信息,對視頻的壓縮表示會轉變成視頻在大模型中的概率表索引,這個索引可能就是我們所熟知的 prompt,對保真度的要求越高,prompt 就要越準確越具體,或者額外傳輸一些語義級別的殘差信息。最近有學者認為大模型本質就是壓縮模型,從我們的原理框架出發,也演繹出了類似的結論。

編碼先說這么多。那么轉碼系統中其他模塊的優化原理是什么呢?其他模塊都可以歸納為一個范式:為轉碼系統提供和人眼視覺感知系統相關的先驗信息,就可以減少編碼人眼感知信息所需要的條件信息。這些先驗信息包括人眼更關注人臉、人眼對復雜紋理的失真不敏感等,先驗信息與人眼視覺系統越匹配,能夠給轉碼系統賦予的相關信息就越多,剩余條件信息越少,碼率越低。在實際系統中,前處理和 ROI、JND 等預分析的目的就是確保這些先驗條件能夠充分而準確的實現。
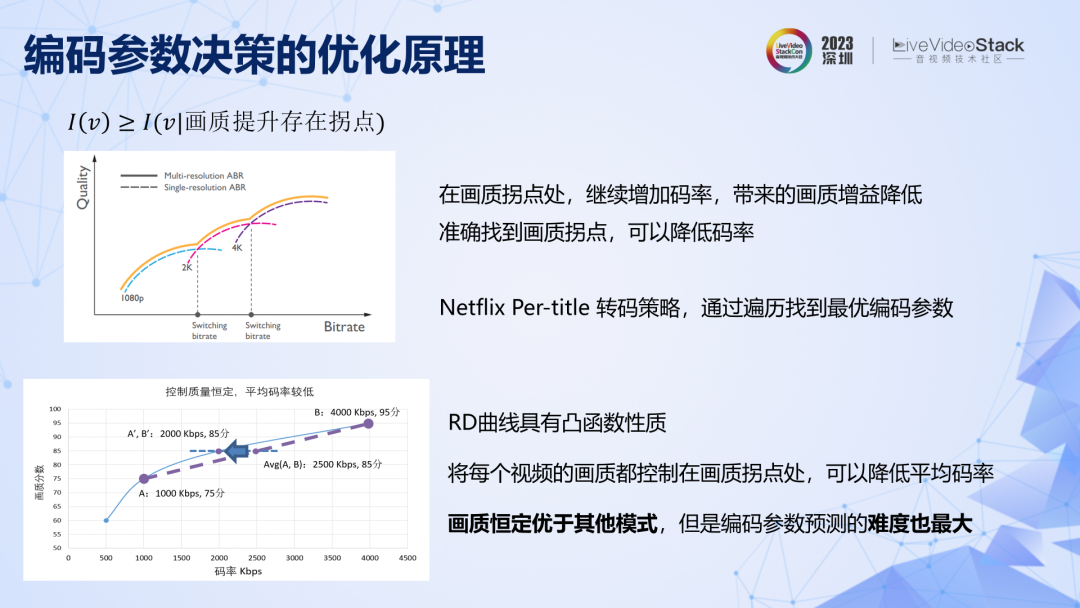
再看編碼參數決策,其原理也是給轉碼過程提供了先驗信息,比如人眼對畫質存在拐點,畫質達到一定水平后,再增加碼率對主觀畫質提升是有限的。還有對一批視頻進行編碼時,如果能夠保持每個視頻的畫質足夠穩定,那么對用戶體驗的提升是有幫助的。參數決策的目的也是確保這些先驗條件能夠準確而充分的實現,比如通過參數決策保持視頻編碼后的畫質恒定。
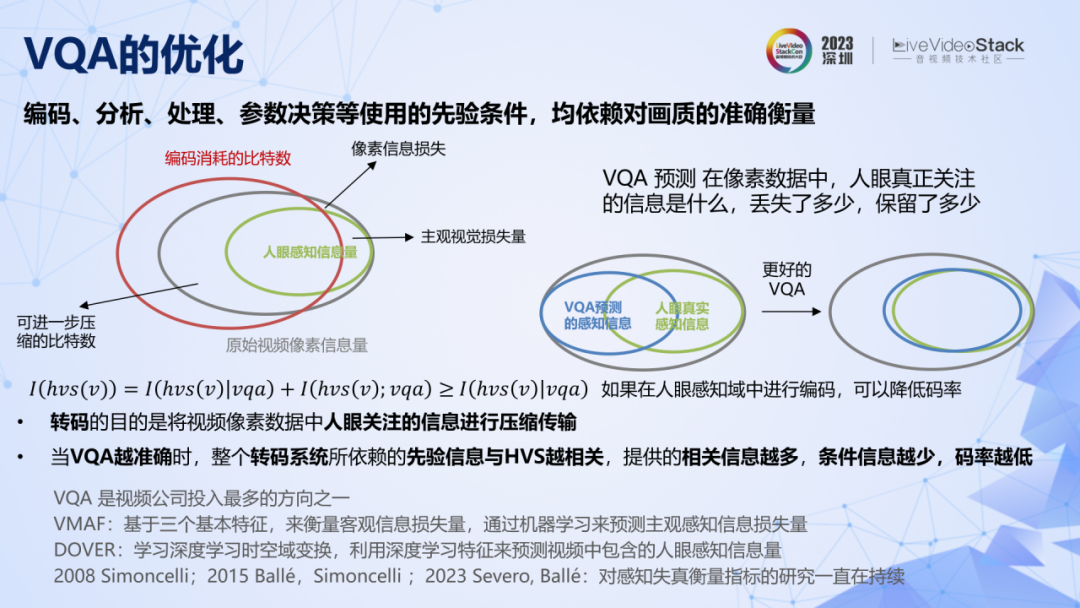
我們為轉碼系統提供的先驗信息,具備有效性的前提是符合人眼視覺系統 HVS,那么視頻質量評價 VQA 的目的,就是確保這個前提的成立。VQA 評價了一個視頻中有多少人眼真正感興趣的信息,或者相比于源視頻丟失了多少人眼感知信息。當 VQA 越準確的時候,整個轉碼系統所依賴的先驗信息就與 HVS 越相關,所能提供的相關信息就越多,條件信息越少,碼率越低。
只要是從事過轉碼系統相關工作的人,應該都會發現,整個轉碼系統中的各個模塊,對 VQA 都有很強的依賴。所以 VQA 是如此得重要,以至于 VQA 是整個視頻行業投入最多的方向之一。但是 HVS 非常復雜,所以對 VQA 的研究也一直在持續。

我們對傳統編碼和深度學習編碼以及其他模塊的優化原理進行了重新梳理,目前看來,我們的原理框架是合理的。現在我們就可以用此框架來指導實際轉碼系統的設計。
03
B站轉碼優化實踐
接下來,介紹一些B站轉碼優化的實踐經驗。
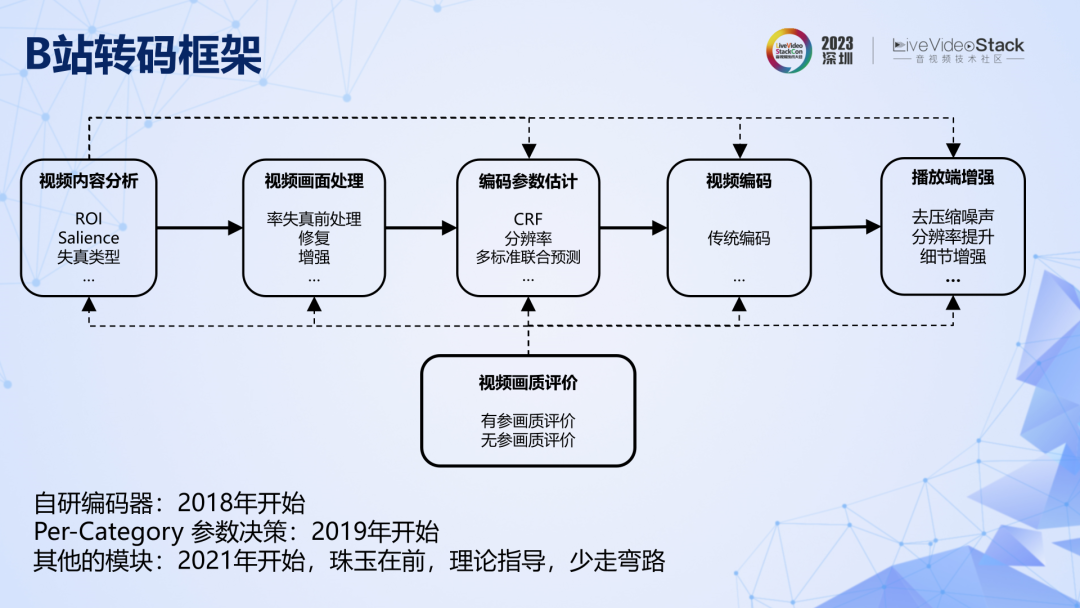
這是B站規劃的廣義轉碼系統的框架圖,有些模塊還在研發中。我們最開始投入的自研編碼器,然后是 Per-Category 級別的參數決策。
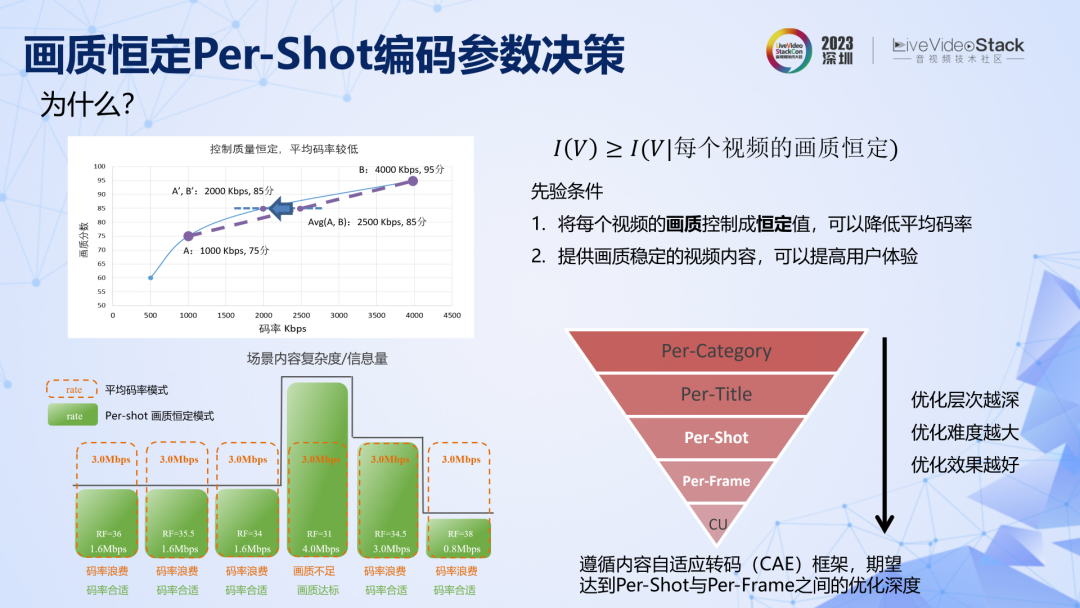
參數決策方面。我們提出了一種場景級別的畫質恒定的轉碼方法,原理是利用了一個先驗條件:如果能將每個視頻的畫質控制成恒定值,那么既可以避免碼率浪費,同時畫質穩定的視頻內容,也有助于提高總體的用戶體驗。實際落地中,系統遵循了內容自適應轉碼(CAE)框架,期望達到 Per-Shot 與 Per-Frame 之間的優化層次,即在場景級別和幀級別實現畫質控制。
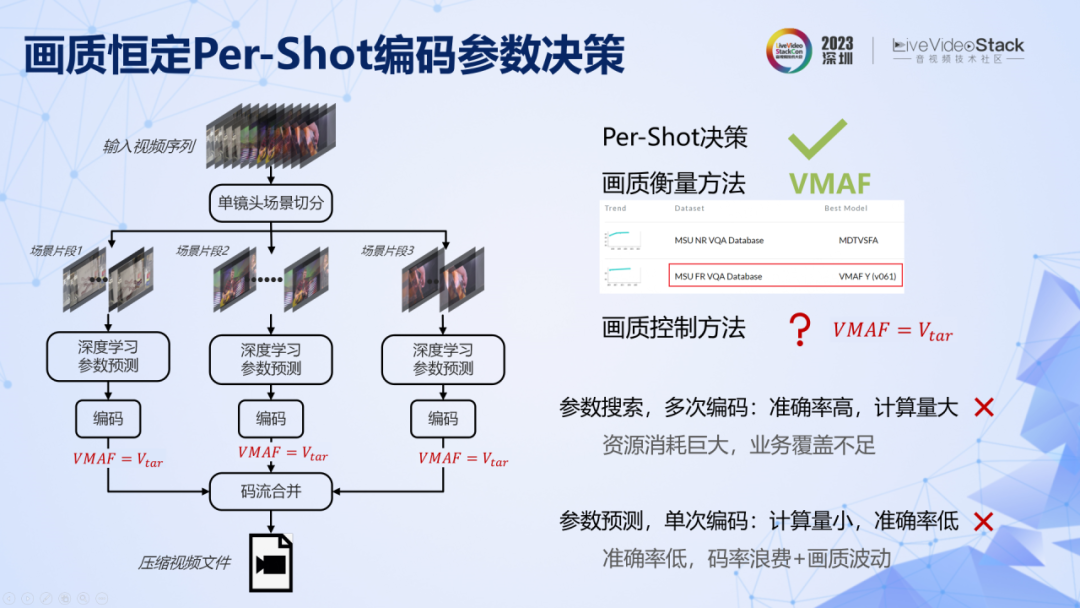
這是具體的實現框架。具體來說,需要解決三個問題:一是場景切換,我們直接調用了 x264 中的 scenecut 算法實現了高效的場景切分。二是如何對畫質進行衡量,在轉碼應用中,我們發現 VMAF 依然是目前最準確最穩定的方法,此外還引入了另一個先驗假設,即 VMAF 值一樣情況下,我們認為畫質是接近的。第三個問題,就是在這個假設之下,怎樣保證編碼之后的 VMAF 值等于統一的預設值,不能高也不能低。
有兩個實現思路,一是進行參數搜索,多次編碼,多次驗證,搜索得到最優參數,這個方法準確率很高,但是算力很大,不適合 UGC 場景。第二種方法是單次參數預測,訓練機器學習模型,將視頻特征作為輸入,直接預測滿足 VMAF 的編碼參數。這種方法計算簡單,算力不高,但是準確率難以保證,而當準確率不高的時候,轉碼所依賴的先驗信息就不準確,也就無法提供足夠多的相關信息,碼率也就不夠低。
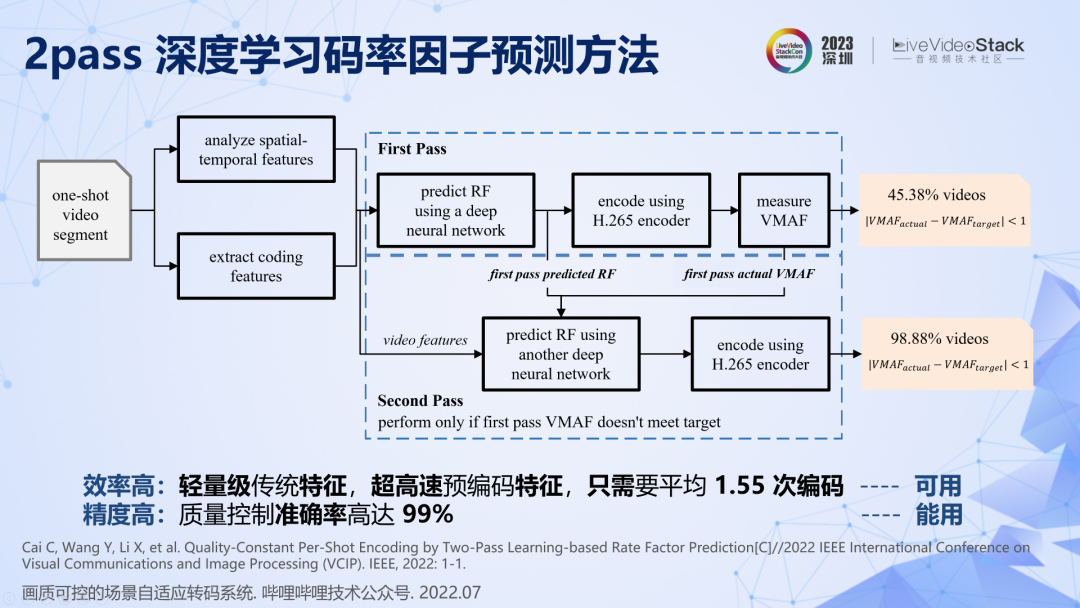
在有限復雜度的約束下,我們提出了一種基于深度學習的 2pass 碼率因子預測方法。首先用簡單高效的傳統特征,訓練一個非常簡單的神經網絡進行單次參數預測,首次能夠達到 45%的準確率。然后對剩下 55%畫質不達標的片段進行第二次預測,第二次預測引入第一次預測的結果作為錨定信息,此時會驚喜地發現能夠達到 99% 的準確率。所以,該方法可以以平均 1.55 次編碼和 1 次 VMAF 的復雜度實現 99% 準確率的場景級畫質控制。
在該系統中,我們利用了一個先驗條件:認為編碼后 VMAF 恒定的情況下,畫質是一樣的。這個先驗條件和人眼主觀系統的匹配程度直接決定了轉碼系統的實際表現。在實踐中,我們發現對于大部分視頻,這個條件是成立的,但是對有一些動畫、三明治、大背景小前景等視頻類型,VMAF 不夠準確,普遍虛高,這就造成了實際表現不及預期。
在沒有找到更準確的畫質評價方法之前,我們只能先打補丁,提高畫質恒定這個先驗條件的準確率。一種方法是 ROI 編碼,其原理是利用了一個很強的先驗:人眼對人臉和人體的失真非常敏感。編碼之前先檢測人臉、人體、背景三個部分,然后在碼率分配時設置不同的優先級。在運用了很多類似的補丁之后,系統的畫質穩定性得到了顯著增強,率失真表現也得到了明顯提升。
未來對參數決策的優化方向依然是不斷提高先驗條件的準確率,包括嘗試再深入一層達到幀級別的質量控制、探索更合理的畫質評價方法等,確保給系統提供更多更準確的先驗信息。
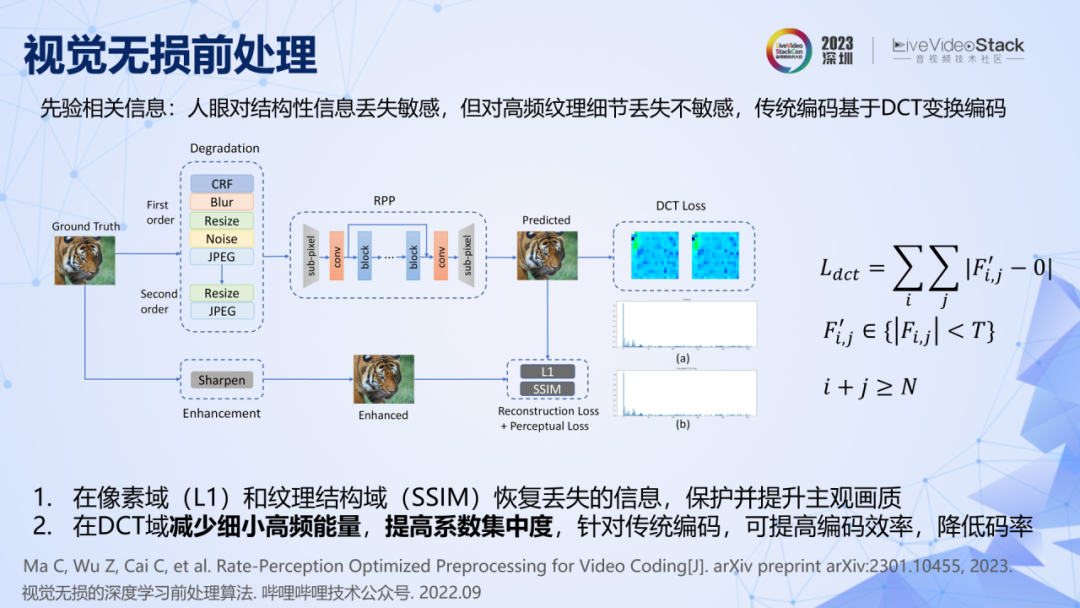
我們還利用了視覺無損前處理來進一步降低碼率,其原理是利用了三個先驗條件,一是人眼對結構性信息的丟失很敏感,例如編碼后如果人臉、眼睛、鼻子等輪廓模糊,人眼能感知出來。二是人眼對高頻紋理細節的丟失不敏感,例如對草地紋理失真是不敏感的。三是站在轉碼系統的尺度下,利用了編碼器的一個先驗信息,即傳統編碼都基于 DCT 變換編碼,非零系數越少,零系數越多的時候,碼率就會越低。
實際落地要做的就是找到一個方法將這三個條件充分準確地實現。我們設計了一種損失函數和訓練策略,訓練了一個簡單的 CNN 網絡來實現這三個條件。具體來說,用降質和增強的圖像對,結合 L1 Loss 和 SSIM Loss ,讓網絡學會對結構信息進行恢復和保護。同時引入 DCT Loss,對處理后圖像的 DCT 高頻能量進行約束,使其盡可能出現更多的零系數,減少非零系數。這樣做的目的之一是減少視覺不敏感的細碎紋理信息,二是適配傳統的 DCT 變換編碼器,從而降低碼率。使用該方法訓練好神經網絡之后,可以直接運用在各類傳統編碼器之前,都能取得 15%的碼率節省。

回顧一下這個過程,我們剛開始并沒有在神經網絡結構上做努力,因為從原理上還不能推導出神經網絡的結構優化與降低碼率之間的聯系。但是原理告訴我們引入更多和系統相關的先驗條件,一定可以降低碼率,因此我們僅僅利用 Loss 函數和訓練策略的設計就實現了碼率的降低。
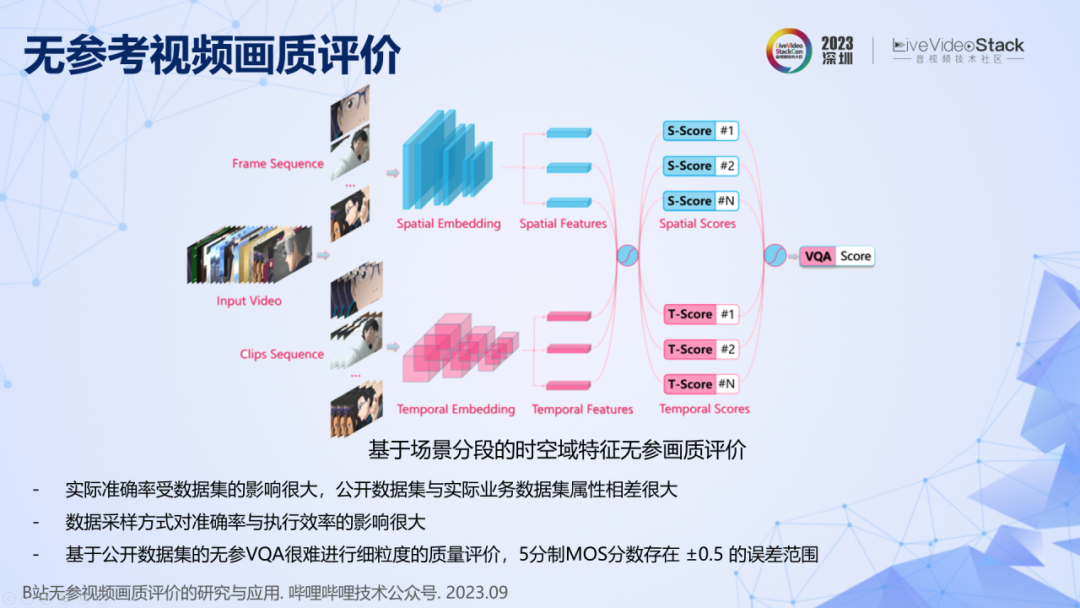
最后再介紹兩個工作。無參考視頻畫質評價,已經上線了一個模型,用于檢測大盤的視頻畫質,但我們發現用其來指導轉碼還存在一些問題。分享三個發現,一是無參 VQA 實際準確率受數據集的影響很大,公開數據集與實際業務數據集屬性相差很大,直接將開源模型用在實際業務中,準確率不高。二是視頻數據的時空域采樣方式對準確率和執行效率的影響很大,在實際系統中,需要進行仔細的設計。三是基于公開數據集的無參 VQA 很難進行細粒度的質量評價,我理解這是因為人眼本身就存在不確定性,不同的人對同一個視頻的評價不同,即使同一個人在不同時間對同一個視頻的評價也會有差異,所以 5 分制 MOS 分數本身就存在超過±0.5 的誤差。
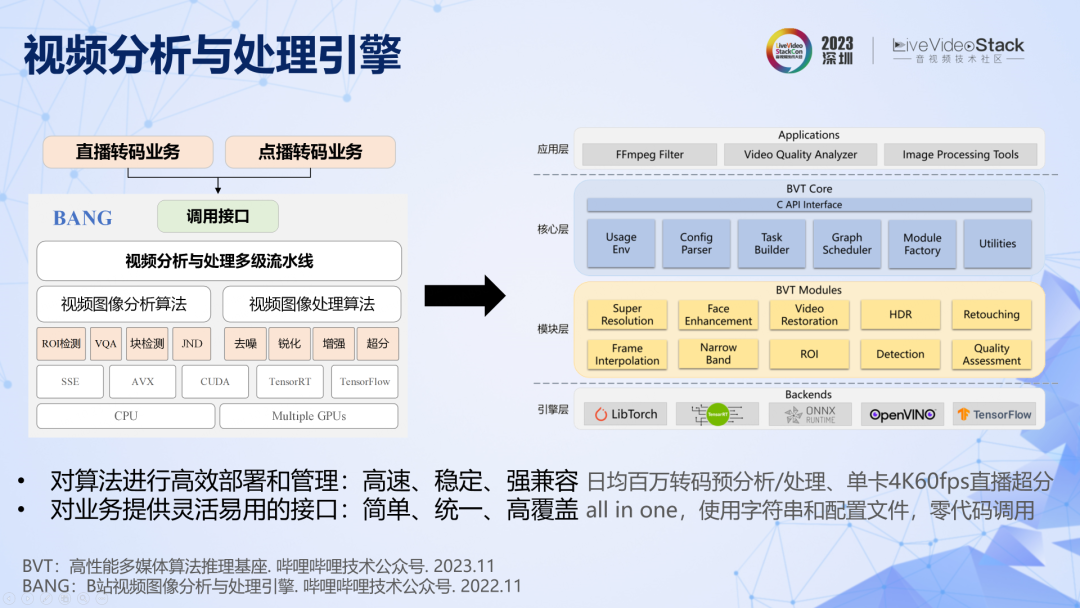
另外,為了讓算法能夠快速部署和高效執行,我們開發了一套強大的視頻分析與處理引擎,最近已經升級到第二代了。
今天分享就到這里,感謝大家!
審核編輯:黃飛
-
視頻編碼
+關注
關注
2文章
113瀏覽量
21018 -
視頻轉碼
+關注
關注
0文章
14瀏覽量
7495
原文標題:B站蔡春磊:轉碼系統究竟在優化什么?
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Altium Designer Cadence 格式轉碼
如何使用API提交轉碼任務?
【MPS最佳實踐】媒體工作流轉碼
音視頻轉碼技術指南:國內主流云轉碼服務提供商對比測評
如何在視頻工程中使用轉碼技術?
視頻轉碼技術與系統要求相匹配

阿里云視頻點播轉碼多場景化最佳實踐

轉碼技術在視頻領域內的應用分析
linux系統支持硬件轉碼,真正告別GPU+CPU轉碼時代
如何在視頻領域使用轉碼技術,有何優勢





 工商網監
工商網監
評論